

Ciao a tutti, mi chiamo Sergey Emelyanchik. Sono il fondatore dell'azienda Audit-Telecom, principale sviluppatore e autore del sistema Veliam. Ho deciso di scrivere un articolo su come io e un amico abbiamo creato un'azienda di outsourcing, sviluppato software per noi stessi e successivamente iniziato a distribuirlo a chiunque volesse tramite un sistema SaaS. Parlerò di come fossi categoricamente scettico riguardo alla possibilità che ciò accadesse. Nell'articolo non ci sarà solo un racconto, ma anche dettagli tecnici su come è stato creato il prodotto Veliam, inclusi alcuni pezzi di codice sorgente. Condividerò gli errori che abbiamo fatto e come li abbiamo poi corretti. Avevo dei dubbi sul pubblicare un articolo del genere. Ma ho pensato che fosse meglio farlo, ricevere feedback e migliorare, piuttosto che non pubblicare nulla e chiedermi cosa sarebbe successo se…
Contesto
Ho lavorato in un'azienda come dipendente IT. L'azienda era piuttosto grande, con una struttura di rete ramificata. Non mi soffermerò sulle mie mansioni, dirò solo che non includevano la creazione di nulla.
Avevamo un monitoraggio, ma per puro interesse accademico volevo provare a scrivere il mio semplice sistema. L'idea era di creare qualcosa di web-based, in modo che fosse facile accedervi senza dover installare alcun client e poter vedere cosa stesse accadendo nella rete da qualsiasi dispositivo, compresi i dispositivi mobili tramite Wi-Fi. Volevo anche capire rapidamente in quale stanza si trovava l'hardware che aveva problemi, poiché c'erano requisiti molto rigorosi per i tempi di reazione a tali problemi. Alla fine, ho elaborato un piano per scrivere una semplice pagina web, con uno sfondo JPEG che mostrava lo schema della rete, ritagliando i dispositivi stessi con i loro indirizzi IP su quell'immagine, e sovrapponendo contenuti dinamici in coordinate specifiche sotto forma di indirizzi IP verdi o lampeggianti in rosso. Compito assegnato, iniziamo.
In passato mi sono occupato di programmazione in Delphi, PHP, JS e molto superficialmente di C++. Conosco abbastanza bene il funzionamento delle reti: VLAN, Routing (OSPF, EIGRP, BGP), NAT. Questo è stato sufficiente per scrivere autonomamente un prototipo di monitoraggio primitivo.
Ho scritto quello che avevo in mente in PHP. Il server Apache e PHP erano su Windows poiché Linux, a quel tempo, mi sembrava qualcosa di incomprensibile e molto difficile; come si è rivelato in seguito, mi sbagliavo di grosso e in molti aspetti Linux è molto più semplice di Windows, ma questo è un tema a parte e sappiamo tutti quanti dibattiti ci siano su questo argomento. L'Utilità di pianificazione di Windows richiamava con un intervallo breve (non ricordo esattamente, ma era qualcosa come una volta ogni tre secondi) uno script PHP che interrogava tutti gli oggetti con un semplice ping e salvava lo stato in un file.
system("ping -n 3 -w 100 {$ip_address}");
Sì, in quel momento anche lavorare con il database non era ancora una mia competenza. Non sapevo che fosse possibile parallelizzare i processi e il passaggio attraverso tutti i nodi della rete richiedeva molto tempo, poiché avveniva in un solo flusso. I problemi si presentavano soprattutto quando diversi nodi erano non disponibili, in quanto ognuno di essi ritardava lo script di 300 ms. Dallato cliente, c'era una semplice funzione ciclica che ogni pochi secondi scaricava le informazioni aggiornate dal server con una richiesta Ajax e aggiornava l'interfaccia. Inoltre, dopo 3 ping consecutivi non riusciti, se sul computer era aperta una pagina web con il monitoraggio, si avviava una musica allegra.
Quando tutto è andato a buon fine, sono stato molto ispirato dal risultato e ho pensato che si potesse aggiungere ancora qualcosa (in base alle mie conoscenze e possibilità). Ma non mi sono mai piaciuti i sistemi con un milione di grafici, che, come allora ritenevo e considero tuttora, nella maggior parte dei casi sono superflui. Volevo integrare solo ciò che mi avrebbe realmente aiutato nel lavoro. Questo principio rimane fondamentale nello sviluppo di Veliam. Successivamente, ho capito che sarebbe stato fantastico non dover tenere aperto il monitoraggio e sapere dei problemi; quando si verificava un problema, avrei potuto aprire la pagina e vedere dove si trovava il nodo problematico e cosa fare in seguito. Non leggevo per niente l'email, semplicemente non la usavo. Ho trovato online che esistono gateway SMS a cui è possibile inviare richieste GET o POST, e loro mi avrebbero inviato un SMS sul telefono con il testo che avrei scritto. Ho subito capito che lo volevo molto. E ho iniziato a studiare la documentazione. Dopo un po' di tempo, ci sono riuscito, e ora ricevevo SMS sui problemi della rete sul cellulare, con il nome dell'"oggetto" che era andato in crash. Anche se il sistema era primitivo, era stato creato da me e ciò che mi motivava a svilupparlo era il fatto che fosse un programma applicativo che realmente mi aiutava nel lavoro.
E così è arrivato il giorno in cui uno dei canali internet al lavoro è crollato, e il mio monitoraggio non mi ha dato alcun segnale. I DNS di Google continuavano a rispondere perfettamente. Era giunto il momento di riflettere su come verificare che il canale di comunicazione fosse attivo. C'erano varie idee su come farlo. Non avevo accesso a tutto l'hardware. Dovevo trovare un modo per determinare quale dei canali fosse attivo, senza avere la possibilità di controllare direttamente l'attrezzatura di rete. Un collega ha suggerito che potrebbe essere utile eseguire un traceroute verso server pubblici, poiché gli itinerari potrebbero variare a seconda del canale utilizzato per accedere a Internet. Ho fatto un controllo e così è stato. I percorsi erano diversi durante la traceroute.
system(“tracert -d -w 500 8.8.8.8”);
Così è nato un altro script, e più precisamente, la tracciatura è stata aggiunta alla fine dello stesso script che pingava tutti i dispositivi nella rete. Si trattava di un ulteriore processo lungo che veniva eseguito nello stesso thread e rallentava l'esecuzione dell'intero script. Ma all'epoca non era così evidente. In ogni caso, svolgeva il suo compito, poiché nel codice era specificato rigidamente quale dovesse essere la tracciatura per ognuno dei canali. Così ha cominciato a funzionare un sistema che monitorava (un'espressione forse esagerata, poiché non veniva raccolto alcun dato, ma solo ping) i dispositivi di rete (router, switch, wi-fi, ecc.) e le connessioni con il mondo esterno. Le SMS arrivavano regolarmente e nello schema era sempre chiaro dove si trovasse il problema.
In seguito, nel lavoro quotidiano, mi sono trovato a dover gestire il crosslinking. Ed è diventato noioso dover accedere ai switch Cisco ogni volta per vedere quale interfaccia utilizzare. Sarebbe fantastico poter cliccare sull'oggetto nel monitoraggio e vedere un elenco delle sue interfacce con relative descrizioni. Questo mi farebbe risparmiare tempo. Inoltre, in questo schema non dovrei avviare Putty o SecureCRT per inserire credenziali e comandi. Semplicemente cliccherei nel monitoraggio, vedrei cosa mi serve e tornerei a fare il mio lavoro. Ho iniziato a cercare come interagire con gli switch. A colpo d'occhio, ci sono subito venuti in mente due opzioni: SNMP o accedere allo switch via SSH, inserire i comandi necessari e analizzare i risultati. Ho scartato SNMP per via della complessità di implementazione; non vedevo l'ora di ottenere un risultato. Con SNMP avrei dovuto rummare a lungo nei MIB, e sulla base di questi dati generare informazioni sulle interfacce. C'è un comando fantastico in CISCO
show interface statusMostra esattamente ciò di cui ho bisogno per le cross-reference. Perché complicarsi la vita con SNMP, quando voglio semplicemente visualizzare l'output di quel comando, ho pensato. Dopo un po' di tempo, ho implementato questa funzionalità. Cliccavo sulla pagina web sull'oggetto. Scattava un evento, per cui il client effettuava una richiesta al server tramite AJAX, e questo, a sua volta, si collegava via SSH allo switch di cui avevo bisogno (le credenziali erano hardcoded nel codice, non avevo voglia di rendere le cose più eleganti, di creare dei menu separati per cambiare le credenziali dall'interfaccia, avevo bisogno di un risultato e rapidamente) inseriva il comando sopra menzionato e lo restituiva al browser. Così ho iniziato a vedere le informazioni sulle interfacce con un semplice clic. Era estremamente comodo, specialmente quando dovevo controllare queste informazioni su diversi switch contemporaneamente.
Monitorare i canali basandosi sul tracciamento si è rivelata non essere la migliore idea, poiché a volte venivano effettuati lavori sulla rete e il tracciamento poteva cambiare, portando il monitoraggio a segnalarmi problemi con il canale. Dopo aver investito molto tempo nell'analisi, mi rendevo conto che tutti i canali funzionavano e il mio monitoraggio mi stava ingannando. Alla fine, ho chiesto ai colleghi che gestivano gli switch per la creazione dei canali di inviarmi semplicemente il syslog quando cambiava lo stato della visibilità dei vicini (neighbor). Questo si è rivelato molto più semplice, veloce e veritiero rispetto al tracciamento. Quando arrivava un evento del tipo neighbor lost, inviavo subito un avviso di caduta del canale.
Poi, sono emerse nuove funzioni cliccando sugli oggetti, sono state aggiunte alcune squadre e SNMP per la raccolta di alcune metriche; insomma, per ora è tutto. Il sistema non si è evoluto ulteriormente. Ha fatto tutto ciò di cui avevo bisogno, era uno strumento utile. Molti lettori probabilmente mi diranno che ci sono già tanti software in rete per risolvere questi problemi. Ma in realtà, all'epoca non ho trovato prodotti gratuiti simili e avevo davvero voglia di migliorare le mie abilità di programmazione; quale modo migliore per farlo se non attraverso una sfida pratica? Così si è conclusa la prima versione del monitoraggio, che non è stata ulteriormente modificata.
Creazione dell'azienda Audit-Telecom
Col tempo, ho iniziato a lavorare anche per altre aziende, fortunatamente il mio orario di lavoro me lo permetteva. Lavorando in diverse aziende, le competenze crescono rapidamente in vari ambiti, ampliando notevolmente il tuo orizzonte. Ci sono aziende in cui, come si suol dire, sei sia calzolaio, sia mietitore, e anche musicista. Da un lato è difficile, dall'altro se non sei pigro, diventi un professionista versatile, il che ti consente di affrontare le sfide in modo più rapido ed efficace, poiché conosci anche il funzionamento di aree correlate.
Il mio amico Pavel (anche lui nel settore IT) ha cercato costantemente di convincermi a intraprendere un'attività. Ci sono state innumerevoli idee con vari progetti imprenditoriali. Ne abbiamo discusso per anni. E alla fine non siamo arrivati a nulla perché io sono uno scettico, mentre Pavel è un sognatore. Ogni volta che proponeva un'idea, io non ci credevo mai e rifiutavo di partecipare. Ma ci sarebbe piaciuto molto avviare una nostra attività.
Finalmente, siamo riusciti a trovare un'opzione che soddisfacesse entrambi e a dedicarci a ciò che sappiamo fare. Nel 2016, abbiamo deciso di creare un'azienda IT che aiutasse le imprese a risolvere le loro problematiche informatiche. Questo include l'implementazione di sistemi IT (1C, server terminali, server di posta, ecc.), il loro supporto, un classico HelpDesk per gli utenti e l'amministrazione di rete.
A dirla francamente, all'epoca della creazione della società, non credevo in essa per circa il 99,9%. Ma in qualche modo Pavel è riuscito a convincermi a provarci, e per anticipare gli eventi, aveva ragione. Io e Pavel abbiamo investito 300.000 rubli ciascuno, abbiamo registrato una nuova LLC "Audit-Telecom", affittato un piccolo ufficio, fatto delle bellissime visite, insomma, come probabilmente tanti imprenditori inesperti all'inizio, abbiamo iniziato a cercare clienti. La ricerca di clienti è tutta un'altra storia. Potremmo scrivere un articolo separato nel nostro blog aziendale, se interessa a qualcuno. Chiamate a freddo, volantini e altro. Questo non portava a risultati. Come leggo ora in molte storie di business, molto dipende dalla fortuna. Noi abbiamo avuto fortuna. E letteralmente dopo un paio di settimane dalla creazione della ditta, contattò mio fratello Vladimir, che ci portò il nostro primo cliente. Non voglio annoiarvi con i dettagli del lavoro con i clienti, l'articolo non riguarda questo, dirò solo che siamo andati a fare un audit, abbiamo identificato i punti critici e questi punti si sono guastati mentre si prendeva la decisione di collaborare con noi su base continuativa come fornitori esterni. Subito dopo è stata presa una decisione positiva.
In seguito, principalmente attraverso il passaparola, sono iniziate a comparire altre aziende da servire. Il sistema Helpdesk era in un'unica piattaforma. Le connessioni all'hardware di rete e ai server erano su un'altra, a seconda di chi come operava. Alcuni conservavano collegamenti rapidi, altri usavano rubrica RDP. Il monitoraggio era un ulteriore sistema separato. Lavorare per il team in sistemi disgiunti è molto scomodo. Le informazioni importanti sfuggono di vista. Per esempio, il server terminale di un cliente diventa non disponibile. Subito arrivano le richieste dagli utenti di quel cliente. Uno specialista del supporto apre una richiesta (che è arrivata per telefono). Se gli incidenti e le richieste fossero registrati in un unico sistema, lo specialista del supporto vedrebbe immediatamente qual è il problema per l'utente e glielo comunicherebbe, mentre si connetterebbe già all'oggetto necessario per risolvere la situazione. Tutti sarebbero al corrente della situazione tattica e lavorerebbero in modo coordinato. Non abbiamo trovato un sistema in cui tutto questo sia integrato. È diventato chiaro che era tempo di creare il nostro prodotto.
Continuazione del lavoro sul nostro sistema di monitoraggio
Era chiaro che il sistema sviluppato in precedenza non fosse affatto adatto alle attuali esigenze, né per quanto riguarda le funzionalità né per la qualità. È stata quindi presa la decisione di costruire un sistema da zero. Dal punto di vista grafico, doveva avere un aspetto completamente diverso. Doveva essere un sistema gerarchico, che permettesse di aprire rapidamente e comodamente l'oggetto necessario per ciascun cliente. Lo schema della prima versione si rivelava assolutamente inadeguato in questo caso, poiché i clienti erano diversi e non importava affatto in quali spazi fosse installata l'attrezzatura. Questo era già stato trasferito nella documentazione.
Quindi, le esigenze:
- Struttura gerarchica;
- Una parte server che può essere posizionata presso il cliente sotto forma di macchina virtuale per raccogliere le metriche necessarie e inviarle al server centrale, che le aggrega e le visualizza per noi;
- Notifiche. Quelle che non si possono perdere, poiché non c'era la possibilità che qualcuno rimanesse ad osservare il monitor tutto il tempo;
- Sistema di richieste. Sono iniziati ad arrivare clienti per i quali gestivamo non solo l'attrezzatura server e di rete, ma anche i posti di lavoro;
- Possibilità di connettersi rapidamente ai server e all'hardware dal sistema;
I compiti sono stati assegnati, iniziamo a scrivere. Nel frattempo, gestiamo le richieste dei clienti. A quel tempo eravamo già in quattro. Abbiamo iniziato a scrivere entrambe le parti: il server centrale e il server per l'installazione sui client. A quel punto, Linux non ci era più estraneo ed è stata presa la decisione che le macchine virtuali presso i clienti sarebbero state su Debian. Non ci sarebbero stati installer, semplicemente avremmo fatto il progetto della parte server su una specifica macchina virtuale e poi l'avremmo clonato per il cliente necessario. Questo si è rivelato un altro errore. In seguito è diventato chiaro che in questo schema il meccanismo degli aggiornamenti non era affatto studiato. Cioè, aggiungevamo qualche nuova funzionalità e poi c'era un'intera problematica per distribuirla su tutti i server dei clienti, ma torneremo su questo punto più avanti, tutto per ordine.
Abbiamo creato il primo prototipo. Era in grado di eseguire il ping ai dispositivi di rete dei clienti e ai server e di inviare questi dati al nostro server centrale. A sua volta, quest'ultimo aggiornavano questi dati nel database centrale. Qui scriverò non solo la storia di come e cosa siamo riusciti a fare, ma anche quali errori da dilettanti sono stati commessi e come poi abbiamo dovuto pagarne il prezzo in termine di tempo. Dunque, tutta la struttura ad albero degli oggetti era conservata in un unico file come oggetto serializzato. Finché collegammo alcuni clienti al sistema, tutto andava più o meno bene, anche se a volte c'erano artefatti del tutto incomprensibili. Ma quando collegammo una decina di server al sistema, cominciarono a verificarsi delle stranezze. A volte, per motivi sconosciuti, tutti gli oggetti nel sistema scomparivano. È importante notare che i server dei clienti inviavano dati al server centrale ogni pochi secondi tramite richiesta POST. Un lettore attento e un programmatore esperto avranno già intuito che si stava verificando un problema di accesso concorrente a quel file in cui era conservato l'oggetto serializzato da diversi thread contemporaneamente. E proprio quando ciò accadeva, si manifestavano le stranezze con la scomparsa degli oggetti. Il file diventava semplicemente vuoto. Tuttavia, tutto ciò non è stato scoperto subito, ma solo durante l'utilizzo con più server. Durante questo tempo è stata aggiunta la funzionalità di scansione delle porte (i server inviavano al centrale non solo informazioni sulla disponibilità dei dispositivi, ma anche sulle porte aperte). Questo è stato fatto tramite la chiamata al comando:
$connection = @fsockopen($ip, $port, $errno, $errstr, 0.5);
i risultati erano spesso errati e la scansione richiedeva molto tempo. Ho completamente dimenticato il ping, che veniva eseguito tramite fping:
system("fping -r 3 -t 100 {$this->ip}");
Anche questo non era parallelizzato, quindi il processo era molto lungo. Successivamente, in fping veniva passato subito l'intero elenco degli indirizzi IP da controllare e abbiamo ricevuto indietro un elenco pronto di quelli che hanno risposto. A differenza di noi, fping era in grado di parallelizzare i processi.
Un altro compito routinario era la configurazione di certi servizi tramite WEB. Ad esempio, l'ECP di MS Exchange. In sostanza, si tratta solo di un link. Abbiamo deciso che era necessario fornirci la possibilità di aggiungere tali collegamenti direttamente nel sistema, per non dover cercare nella documentazione o in altre schede come accedere all'ECP di un cliente specifico. Così è nato il concetto di collegamenti di risorse per il sistema, la cui funzionalità è ancora disponibile e non ha subito cambiamenti, o quasi.
Funzionamento dei collegamenti di risorse in Veliam
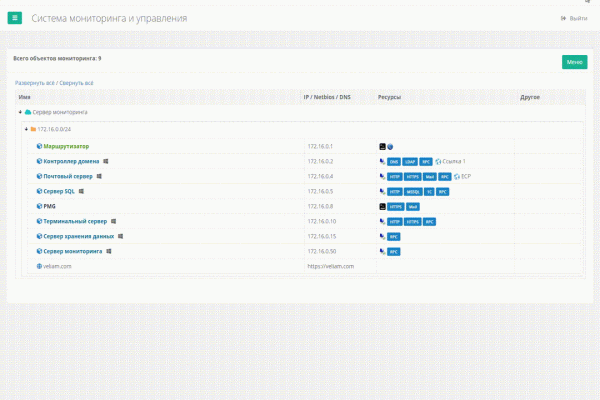
Connessioni remote
Ecco come appare in azione nella versione attuale di Veliam
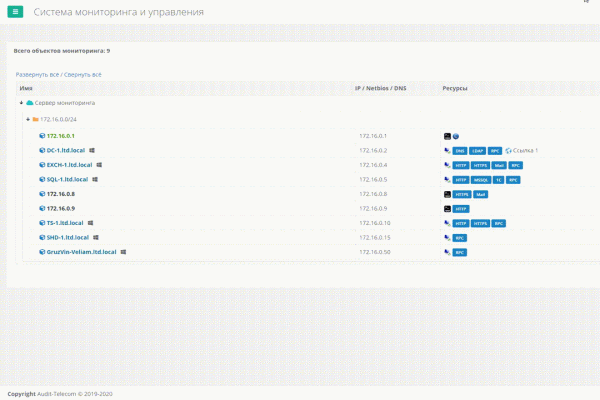
Uno dei problemi era la necessità di collegarsi rapidamente e facilmente a server, che sono ormai molti (più di cento), e passare attraverso milioni di collegamenti RDP salvati è estremamente scomodo. Era necessario uno strumento. Esistono programmi su internet che fungono da rubriche per tali connessioni RDP, ma non sono integrati con il sistema di monitoraggio e non conservano le credenziali. Dovendo inserire ogni volta le credenziali per diversi clienti, diventa davvero frustrante quando ti connetti diverse volte al giorno a server differenti. La situazione con SSH è leggermente migliore, ci sono molti buoni software che consentono di organizzare questi collegamenti in cartelle e di memorizzare le credenziali. Tuttavia, ci sono 2 problemi. Il primo: per le connessioni RDP e SSH non abbiamo trovato un programma unificato. Il secondo: se in un momento non mi trovo davanti al mio computer e ho bisogno di collegarmi rapidamente, o se ho semplicemente reinstallato il sistema, dovrò consultare la documentazione per trovare le credenziali di quel cliente. Questo è scomodo e una perdita di tempo.
La struttura gerarchica necessaria per i server dei clienti era già presente nel nostro prodotto interno. Dovevamo solo pensare a come collegare rapidamente l'attrezzatura necessaria. Per cominciare, almeno all'interno della nostra rete.
Dato che il cliente nel nostro sistema era rappresentato da un browser che non aveva accesso alle risorse locali del computer, per avviare l'applicazione necessaria con un semplice comando, è stata proposta l'implementazione di uno "Schema URI personalizzato di Windows". Così è nato un certo "plugin" per il nostro sistema, che includeva semplicemente Putty e Remote Desktop Plus e, durante l'installazione, registrava lo schema URI in Windows. Ora, quando volevamo collegarci a un oggetto tramite RDP o SSH, cliccavamo su questa azione nel nostro sistema e si attivava il lavoro del URI personalizzato. Si avviava mstsc.exe, il programma standard integrato in Windows, o Putty, che faceva parte del "plugin". Utilizzo il termine plugin tra virgolette, poiché non si tratta di un plugin browser nel senso classico.
Era già qualcosa. Un'utile rubrica. Nel caso di Putty, tutto andava davvero bene; era possibile fornire come parametri di ingresso sia l'IP di connessione che il login e la password. Cioè, ci collegavamo ai server Linux nella nostra rete con un solo clic, senza dover inserire le password. Ma con RDP le cose non sono così semplici. Nel mstsc standard non è possibile fornire le credenziali come parametri. È qui che entra in gioco Remote Desktop Plus. Questo software consentiva di farlo. Ora ci siamo già liberati di lui, ma per molto tempo è stato un fedele alleato nel nostro sistema. Per quanto riguarda i siti HTTP(S), la situazione era semplice; questi oggetti si aprivano semplicemente nel browser e basta. Comodo e pratico. Ma questa era una felicità valida solo per la rete interna.
Poiché la stragrande maggioranza dei problemi li risolvevamo da remoto dall'ufficio, la cosa più semplice era creare VPN verso i clienti. In questo modo, dalla nostra sistemazione, potevamo collegarci anche a loro. Tuttavia, era comunque un po' scomodo. Per ogni cliente era necessario tenere su ogni computer un sacco di informazioni memorizzate VPN Le connessioni e prima di collegarsi a qualsiasi, era necessario attivare il corrispondente VPN. Abbiamo utilizzato questa soluzione per un periodo di tempo piuttosto lungo. Tuttavia, con l'aumento del numero di clienti e dei VPN, la situazione è diventata insostenibile e bisognava fare qualcosa al riguardo. Le lacrime iniziavano a scorrere dopo la reinstallazione del sistema, quando dovevo reinserire decine di connessioni VPN nel nuovo profilo di Windows. Basta sopportare, ho detto, e ho cominciato a pensare a come affrontare questo problema.
È consuetudine che tutti i clienti utilizzino dispositivi di notissima marca, Mikrotik, come router. Sono molto funzionali e pratici per quasi tutte le esigenze. Tra i lati negativi, c'è il rischio di "intrusione". Abbiamo risolto questo problema semplicemente chiudendo tutti gli accessi dall'esterno. Ma dovevamo trovare un modo per accedervi senza doverci recare fisicamente dal cliente, poiché ciò richiederebbe troppo tempo. Abbiamo semplicemente creato tunnel per ciascun Mikrotik e li abbiamo raggruppati in un pool separato, senza alcuna routazione, affinché non ci fosse un'unione della nostra rete con quelle dei clienti e tra loro stesse.
È nata l'idea di fare in modo che, cliccando sull'oggetto giusto nel sistema, il server centrale di monitoraggio, conoscendo le credenziali SSH di tutti i router MikroTik dei clienti, si connettesse all'oggetto specifico, creando una regola di port forwarding verso l'host desiderato con la porta corrispondente. Qui ci sono subito diverse questioni. La soluzione non è universale: funzionerà solo per MikroTik, poiché la sintassi dei comandi varia tra i router. Inoltre, queste configurazioni di port forwarding dovevano poi essere rimosse in qualche modo, e la parte server del nostro sistema essenzialmente non poteva monitorare se avevo terminato la mia sessione di lavoro RDP. Inoltre, un simile forwarding rappresenta una falla per il cliente. E non eravamo nemmeno orientati verso l'universalità, poiché il prodotto veniva utilizzato esclusivamente all'interno della nostra azienda e non c'erano nemmeno pensieri di renderlo pubblico.
Ogni problema è stato risolto a modo suo. Quando è stata creata la regola, il passaggio era consentito solo per un singolo indirizzo IP esterno specifico (da cui è stata inizializzata la connessione). In questo modo, si è riusciti ad evitare falle di sicurezza. Tuttavia, ad ogni connessione di questo tipo, veniva aggiunta una regola sul Mikrotik nella pagina NAT e non veniva mai rimossa. È ben noto che più sono le regole, maggiore è il carico sul processore del router. In generale, non potevo accettare di accedere una volta a un Mikrotik e trovare centinaia di regole morte e inutilizzate.
Dal momento che il nostro server non può monitorare lo stato della connessione, lascia che sia il Mikrotik a monitorarlo da solo. Ho scritto uno script che controlla costantemente tutte le regole di passaggio con una descrizione specifica e verifica se esiste una connessione TCP corrispondente alla regola. Se non c'era da un po' di tempo, probabilmente la connessione era già terminata e il passaggio poteva essere rimosso. Funzionava bene, lo script ha dato buoni risultati.
A proposito, eccolo qui:
global atmonrulecounter {"dontDelete"="dontDelete"}
:foreach i in=[/ip firewall nat find comment~"atmon_script_main"] do={
local dstport [/ip firewall nat get value-name="dst-port" $i]
local dstaddress [/ip firewall nat get value-name="dst-address" $i]
local dstaddrport "$dstaddress:$dstport"
#log warning message=$dstaddrport
local thereIsCon [/ip firewall connection find dst-address~"$dstaddrport"]
if ($thereIsCon = "") do={
set ($atmonrulecounter->$dstport) ($atmonrulecounter->$dstport + 1)
#:log warning message=($atmonrulecounter->$dstport)
if (($atmonrulecounter->$dstport) > 5) do={
#log warning message="Removing nat rules added automaticaly by atmon_script"
/ip firewall nat remove [/ip firewall nat find comment~"atmon_script_main_$dstport"]
/ip firewall nat remove [/ip firewall nat find comment~"atmon_script_sub_$dstport"]
set ($atmonrulecounter->$dstport) 0
}
} else {
set ($atmonrulecounter->$dstport) 0
}
}
Sicuramente si poteva fare in modo più bello, veloce ecc., ma funzionava, non sovraccaricava i Mikrotik e gestiva tutto alla grande. Finalmente siamo riusciti a connetterci ai server e all'hardware di rete dei clienti semplicemente con un clic del mouse. Senza avviare VPN e senza inserire password. Lavorare con il sistema è diventato davvero molto conveniente. Il tempo per la manutenzione è diminuito, e tutti noi trascorrevamo il tempo a lavorare, piuttosto che a connetterci agli oggetti necessari.
Backup Mikrotik
Avevamo configurato il backup di tutti i Mikrotik su FTP. E in generale andava tutto bene. Ma quando dovevamo recuperare il backup, dovevamo aprire quell'FTP e cercarlo lì. Abbiamo un sistema dove sono registrati tutti i router e sappiamo comunicare con i dispositivi tramite SSH. Perché non fare in modo che il sistema prenda automaticamente i backup da tutti i Mikrotik ogni giorno? Ho pensato. E ho iniziato a implementarlo. Ci siamo connessi, abbiamo fatto il backup e l'abbiamo trasferito nello storage.
Codice dello script PHP per eseguire il backup da Mikrotik:
<?php
$IP = '0.0.0.0';
$LOGIN = 'admin';
$PASSWORD = '';
$BACKUP_NAME = 'test';
$connection = ssh2_connect($IP, 22);
if (!ssh2_auth_password($connection, $LOGIN, $PASSWORD)) exit;
ssh2_exec($connection, '/system backup save name="atmon" password="atmon"');
stream_get_contents($connection);
ssh2_exec($connection, '/export file="atmon.rsc"');
stream_get_contents($connection);
sleep(40); // Waiting bakup makes
$sftp = ssh2_sftp($connection);
// Download backup file
$size = filesize("ssh2.sftp://$sftp/atmon.backup");
$stream = fopen("ssh2.sftp://$sftp/atmon.backup", 'r');
$contents = '';
$read = 0;
$len = $size;
while ($read < $len && ($buf = fread($stream, $len - $read))) {
$read += strlen($buf);
$contents .= $buf;
}
file_put_contents ($BACKUP_NAME . '.backup',$contents);
@fclose($stream);
sleep(3);
// Download RSC file
$size = filesize("ssh2.sftp://$sftp/atmon.rsc");
$stream = fopen("ssh2.sftp://$sftp/atmon.rsc", 'r');
$contents = '';
$read = 0;
$len = $size;
while ($read
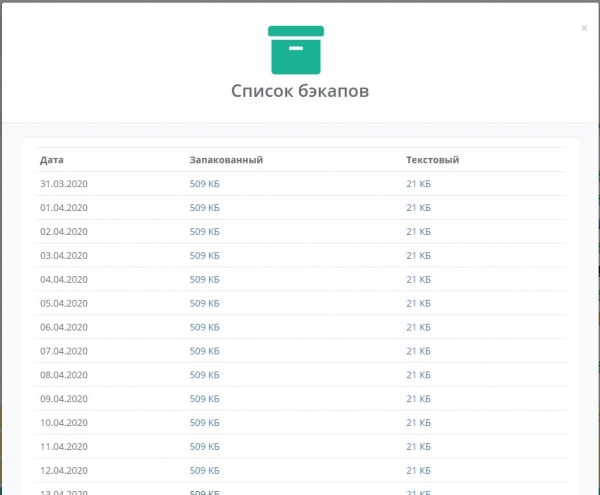
Il backup viene effettuato in due modalità: binario e configurazione testuale. Il binario consente un ripristino rapido della configurazione necessaria, mentre la configurazione testuale aiuta a capire cosa fare in caso di sostituzione forzata dell'hardware, quando non è possibile caricare il binario. In questo modo, abbiamo aggiunto un ulteriore funzionalità utile al sistema. Inoltre, quando si aggiungono nuovi microtik, non è necessario configurare nulla; basta aggiungere l'oggetto al sistema e impostare l'account SSH per esso. Successivamente, il sistema si occupa automaticamente dei backup. Attualmente, questa funzionalità non è ancora presente nell'ultima versione di SaaS Veliam, ma la porteremo presto.
Screenshot di come appariva nel sistema interno
Transizione a uno storage appropriato nel database
In precedenza ho già scritto che c'erano artefatti. A volte scompariva completamente l'elenco degli oggetti nel sistema, altre volte, durante la modifica di un oggetto, le informazioni non venivano salvate e dovevo rinominare l'oggetto anche tre volte. Questo era estremamente frustrante per tutti. La scomparsa degli oggetti avveniva raramente ed era facilmente recuperabile ripristinando quel file, mentre il fallimento durante la modifica degli oggetti era un problema frequente. Probabilmente non ho inizialmente utilizzato un database perché non riuscivo a concepire come mantenere un albero con tutte le relazioni in una tabella piatta. Essa è piatta, mentre l'albero è gerarchico. Ma la buona soluzione per l'accesso multiplo, e successivamente (con la complessità crescente del sistema) anche per le transazioni, è un DBMS. Di certo non sono stato il primo a incontrare questo problema. Ho iniziato a cercare su Google. Si è scoperto che avevano già pensato a tutto prima di me e ci sono diversi algoritmi che costruiscono un albero da una tabella piatta. Dopo aver esaminato ciascuno di essi, ho implementato uno di questi. Ma questa era già una nuova versione del sistema, poiché in sostanza ho dovuto riscrivere moltissimo per questo motivo. Il risultato è stato prevedibile: i problemi di comportamento casuale del sistema sono scomparsi. Qualcuno potrebbe dire che gli errori erano piuttosto dilettantistici (script a thread singolo, memorizzazione di informazioni a cui era necessario un accesso simultaneo da vari thread in un file, ecc.) nel campo dello sviluppo software. Potrebbe anche essere così, ma il mio lavoro principale era l'amministrazione, mentre la programmazione era un'attività secondaria per passione, e non avevo semplicemente esperienza di lavoro in un team di programmatori, dove tali cose elementari sarebbero state suggerite immediatamente dai colleghi più esperti. Perciò, ho accumulato tutte queste esperienze da solo, ma ho assorbito molto bene il materiale. Inoltre, il mio lavoro comporta incontri con i clienti, azioni mirate a cercare di promuovere l'azienda, una serie di questioni amministrative interne e molto, molto altro. Ma in ogni caso, ciò che c'era già era richiesto. I ragazzi e io stesso utilizzavamo il prodotto nel nostro lavoro quotidiano. Ci sono state idee palesemente infelici e soluzioni su cui è stato speso tempo, e alla fine ci siamo resi conto che si trattava di uno strumento non funzionante e che nessuno lo utilizzava, e ciò non è stato incluso in Veliam.
Servizio di assistenza — HelpDesk
È utile menzionare come è stato sviluppato HelpDesk. Questa è di per sé un'altra storia, poiché in Veliam si tratta già della terza versione completamente nuova, che si distingue da tutte le precedenti. Ora è un sistema semplice, intuitivo, senza fronzoli, con la possibilità di integrarsi con il dominio e la possibilità di accedere a questo stesso profilo utente da qualsiasi luogo tramite un link nell'email. E cosa più importante, c'è la possibilità di connettersi al richiedente tramite VNC direttamente dalla richiesta, senza VPN o port forwarding. Racconterò come abbiamo raggiunto questo risultato, cosa c'era prima e quali orribili soluzioni abbiamo affrontato.
Ci siamo collegati agli utenti tramite il noto TeamViewer. Su tutti i computer degli utenti di cui ci prendiamo cura è installato TV. La prima cosa che abbiamo fatto male, e successivamente abbiamo abbandonato, è stata l'associazione di ogni cliente all'HD tramite hardware. Come entrava l'utente nel sistema HD per fare una richiesta? Accanto a TV, su tutti i computer era installata un'utilità speciale scritta in Lazarus (qui molti alzeranno gli occhi e forse andranno a cercare cos'è, ma il linguaggio di programmazione compilato che conoscevo meglio era Delphi, e Lazarus è quasi lo stesso, solo gratuito). In sintesi, l'utente avviava un file batch speciale che eseguiva quest'utilità, la quale leggeva l'HWID del sistema, dopodiché veniva aperto il browser e avveniva l'autenticazione. Perché è stato fatto questo? In alcune aziende, il conteggio degli utenti assistiti è effettuato singolarmente, e il costo del servizio per ogni mese è determinato in base al numero di persone. Questo è chiaro, direte voi, ma perché l'associazione all'hardware? Molto semplice, alcuni individui tornavano a casa e facevano richieste dal loro laptop domestico con richieste del tipo "fate tutto bello qui". Oltre a leggere l'HWID del sistema, l'utilità estraeva dall registro l'ID attuale di TeamViewer e lo trasmetteva a noi. TeamViewer ha un'API per l'integrazione. Abbiamo realizzato questa integrazione. Ma c'era un problema. Con queste API non è possibile collegarsi al computer dell'utente quando non avvia esplicitamente questa sessione, e dopo aver cercato di collegarsi a lui, deve anche premere “confermare”. A quel tempo, ci sembrava logico che senza il consenso dell'utente nessuno dovesse collegarsi, e poiché la persona si trova davanti al computer, deve avviare la sessione e rispondere affermativamente alla richiesta di connessione remota. Tuttavia, non è andata così. I richiedenti si dimenticavano di avviare la sessione, e dovevamo dirlo a loro durante la conversazione telefonica. Questo faceva perdere tempo e infastidiva entrambe le parti del processo. Inoltre, non era affatto raro che una persona lasciasse una richiesta, ma consentisse di collegarsi solo quando andava a pranzo, perché il problema non era critico e non voleva interrompere il proprio lavoro. Di conseguenza, non avrebbe premuto alcun pulsante per consentire la connessione. È così che è emersa una funzionalità aggiuntiva durante l'autenticazione in HelpDesk: la lettura dell'ID di TeamViewer. Sapevamo che c'era una password fissa utilizzata durante l'installazione di TeamViewer. In realtà, solo il sistema la conosceva, poiché era incorporata nell'installatore e nel nostro sistema. Di conseguenza, c'era un pulsante per collegarsi dalla richiesta, premendo il quale non c'era bisogno di aspettare nulla, si apriva immediatamente TeamViewer e avveniva la connessione. Alla fine, c'erano due tipi di connessioni possibili. Attraverso l'API ufficiale di TeamViewer e il nostro fai-da-te. Con mia sorpresa, il primo è stato quasi subito abbandonato, anche se c'era l'indicazione di utilizzarlo solo in casi particolari e quando l'utente dava il suo consenso. Tuttavia, la sicurezza è ora la priorità. Ma si è scoperto che non era necessario per i richiedenti. Erano tutti assolutamente d'accordo sul fatto che si potesse collegarsi a loro senza dover confermare. E se è così, anche in futuro la funzionalità di connessione tramite API è stata abolita per mancanza di necessità.
Transizione alla multithreading in Linux
La questione di come accelerare la scansione di rete per verificare l'apertura di un elenco predefinito di porte e la semplice esecuzione di ping agli oggetti di rete si fa sempre più pressante. La prima soluzione che viene in mente è la multithreading. Infatti, il tempo principale che si dedica al ping è l'attesa del ritorno del pacchetto, e il successivo ping non può iniziare fino a quando non ritorna il pacchetto precedente; per aziende con 20+ server e attrezzature di rete, questo già diventa piuttosto lento. Il punto è che un pacchetto può anche andare perso, e non si può notificare immediatamente l'amministratore di sistema. Questo tipo di spam verrà ignorato molto rapidamente. Pertanto, è necessario pingare ogni oggetto più di una volta prima di concludere che è irraggiungibile. Senza entrare troppo nei dettagli, è necessario parallelizzare, perché se non si fa, è probabile che l'amministratore di sistema venga a sapere del problema dal cliente, piuttosto che dal sistema di monitoraggio.
Di per sé, PHP non supporta la multithreading. Supporta la multiprocesing, è possibile effettuare il fork. Ma, avevo già in sostanza scritto un meccanismo di polling e volevo fare in modo che un'unica volta leggessi tutti i nodi necessari dal database, facessi il ping a tutti contemporaneamente, aspettassi la risposta di ciascuno e solo dopo scrivessi i dati. Questo consente di risparmiare sul numero di richieste di lettura. L'idea si adattava perfettamente alla multithreading. Per PHP esiste il modulo PThreads, che permette di realizzare una vera multithreading; certo, è stata una vera sfida configurarlo su PHP 7.2, ma è stato fatto. La scansione delle porte e il ping sono diventati veloci. E invece, ad esempio, di 15 secondi per ciclo, questo processo ora richiede 2 secondi. È stato un ottimo risultato.
Audit rapido delle nuove aziende
Come è nato il funzionamento della raccolta di metriche e caratteristiche dell'hardware? È semplice. A volte ci viene richiesto di effettuare semplicemente un audit dell'attuale infrastruttura IT. Ed è necessario fare lo stesso per accelerare l'audit di un nuovo cliente. Avevamo bisogno di qualcosa che ci permettesse di entrare in una media o grande azienda e capire rapidamente cosa avessero in dotazione. A mio avviso, solo coloro che vogliono complicarsi la vita bloccano il ping nella rete interna, e secondo la nostra esperienza, sono pochi. Tuttavia, ne incontriamo alcuni. Di conseguenza, è possibile scansionare rapidamente le reti per la presenza di dispositivi usando un semplice ping. Poi possiamo aggiungerli e scansionarli per porte aperte che ci interessano. In sostanza, questa funzionalità esisteva già; era necessario soltanto aggiungere un comando dal server centrale al server subordinato, affinché quest'ultimo scansionasse le reti designate e aggiungesse all'elenco tutto ciò che trovava. Ho dimenticato di menzionare che si presuppone avessimo già un'immagine pronta con il sistema configurato (server di monitoraggio subordinato) che potevamo semplicemente distribuire al cliente durante l'audit e connetterlo al nostro cloud.
Il risultato dell'audit di solito include una serie di informazioni diverse, una delle quali è quali dispositivi sono presenti nella rete. In primo luogo, eravamo interessati ai server Windows e alle stazioni di lavoro Windows all'interno del dominio. Infatti, nelle aziende di medie e grandi dimensioni, l'assenza di un dominio è, probabilmente, un'eccezione alla regola. Per mettere tutto in chiaro, nel mio concetto, una media aziendale si aggira attorno ai 100+ dipendenti. Dovevamo trovare un modo per raccogliere dati da tutte le macchine e i server Windows, conoscendo i loro indirizzi IP e l'account dell'amministratore di dominio, senza però dover installare alcun software su ciascuno di essi. Qui entra in gioco l'interfaccia WMI. La Windows Management Instrumentation (WMI) è, letteralmente, uno strumento di gestione di Windows. WMI è una delle tecnologie fondamentali per la gestione centralizzata e il monitoraggio delle varie parti dell'infrastruttura informatica gestita dalla piattaforma Windows. Questo è ciò che si trova nella wiki. Dopo, è stato necessario lavorare nuovamente per raccogliere wmic (il client WMI) per Debian. Una volta che tutto era pronto, restava solo da interrogare attraverso wmic i nodi necessari per avere le informazioni richieste. Con WMI è possibile estrarre da un computer Windows quasi tutte le informazioni e, inoltre, tramite esso è anche possibile gestire il computer, per esempio, inviandolo in riavvio. Così è iniziata la raccolta di informazioni sulle stazioni e i server Windows nel nostro sistema. Inoltre, avevamo anche informazioni aggiornate sui parametri di carico del sistema. Questi li richiediamo più frequentemente, mentre le informazioni sull'hardware le richiediamo meno spesso. Dopo questo, è diventato un po' più piacevole condurre l'audit.
Decision to Distribute Software
Utilizziamo il sistema ogni giorno e è sempre accessibile a ogni membro del nostro team tecnico. Abbiamo pensato che potremmo condividere ciò che abbiamo con altri. Il sistema non era ancora pronto per essere distribuito. Era necessario rielaborare molti aspetti affinché la versione locale si trasformasse in SaaS. Questo includeva modifiche a vari aspetti tecnici del funzionamento del sistema (connessioni remote, servizio di supporto), analisi dei moduli per la licenza, sharding dei database dei clienti, scalabilità di ciascun servizio e sviluppo di sistemi di aggiornamento automatico per tutte le parti. Ma ne parlerò nel secondo articolo.
Update
Fonte: habr.com
