

Il materiale dell'articolo è tratto dal mio .

Meccanismo di trasferimento dei dati
- Blocco dati dblk_t
- Messaggio mblk_t
- Funzioni per la gestione dei messaggi mblk_t
- Coda queue_t
- Funzioni per la gestione delle code queue_t
- Collegamento dei filtri
- Punto di segnale del grafo di elaborazione dei dati
- Attività dietro le quinte del ticker
- Bufferizzatore (MSBufferizer)
- Funzioni per la gestione di MSBufferizer
Nel passato Abbiamo sviluppato il nostro filtro. Questo articolo è dedicato alla struttura del meccanismo interno di trasferimento dei dati tra i filtri del media streamer. Ciò permetterà in futuro di scrivere filtri sofisticati con minori sforzi.
Meccanismo di trasferimento dei dati
Il trasferimento dei dati nel media streamer avviene tramite le code descritte dalla struttura queue_t. Attraverso le code si muovono le sequenze di messaggi di tipo mblk_t, che di per sé non contengono dati del segnale, ma solo collegamenti al messaggio precedente, successivo e al blocco dati. In aggiunta, vorrei sottolineare che c'è anche un campo per collegare un messaggio dello stesso tipo, il che permette di organizzare una lista concatenata di messaggi. Gruppo di messaggi uniti da tale lista sarà chiamato tupla. Pertanto, qualsiasi elemento della coda può essere un singolo messaggio. mblk_t, o forse la testa del gruppo di messaggi mblk_t. Ogni messaggio del gruppo può avere il proprio blocco di dati associato. Discuteremo perché sono necessari i gruppi di messaggi un po' più tardi.
Come detto sopra, un messaggio di per sé non contiene un blocco di dati, ma solo un puntatore all'area di memoria dove è memorizzato il blocco. In questo contesto, l'immagine generale del funzionamento del media streamer ricorda il magazzino di porte nel cartone animato "Monsters, Inc.", dove le porte (collegamenti ai dati — stanze) si muovono a grande velocità su nastri trasportatori sospesi, mentre le stanze stesse rimangono ferme.
Ora, procedendo attraverso la gerarchia dal basso verso l'alto, esaminiamo in dettaglio le entità del meccanismo di trasmissione dei dati nel media streamer.
Blocco di dati dblk_t
Un blocco di dati è composto da un'intestazione e un buffer di dati. L'intestazione è descritta dalla seguente struttura,
typedef struct datab
{
unsigned char *db_base; // Puntatore all'inizio del buffer di dati.
unsigned char *db_lim; // Puntatore alla fine del buffer di dati.
void (*db_freefn)(void*); // Funzione di liberazione della memoria quando si elimina il blocco.
int db_ref; // Contatore dei riferimenti.
} dblk_t;I campi della struttura contengono puntatori all'inizio del buffer, alla fine del buffer e a una funzione per eliminare il buffer dati. L'ultimo elemento nell'intestazione db_ref — è un contatore dei riferimenti; quando raggiunge zero, funge da segnale per la rimozione di questo blocco dalla memoria. Se il blocco dati è stato creato con la funzione datab_alloc() , il buffer dati sarà allocato in memoria immediatamente dopo l'intestazione. In tutti gli altri casi, il buffer può trovarsi separatamente. Nel buffer dati si troveranno le letture del segnale o altri dati che vogliamo elaborare con i filtri.
Una nuova istanza di un blocco dati viene creata con la funzione:
dblk_t *datab_alloc(int size);Il parametro di input è la dimensione dei dati che il blocco dovrà contenere. Viene allocata più memoria per collocare all'inizio della memoria allocata l'intestazione — la struttura datab. Tuttavia, quando vengono utilizzate altre funzioni, ciò non avviene sempre; in alcuni casi, il buffer dati può trovarsi separato dall'intestazione del blocco dati. I campi della struttura, al momento della creazione, sono configurati in modo tale che il suo campo db_base punte alla fine dell'area dati, mentre db_lim punta alla sua fine. Contatore dei riferimenti db_ref viene impostato a zero. Il puntatore della funzione di pulizia dei dati viene impostato a zero.
Messaggio mblk_t
Come già detto, gli elementi della coda sono di tipo mblk_t, è definito come segue:
typedef struct msgb
{
struct msgb *b_prev; // Puntatore all'elemento precedente della lista.
struct msgb *b_next; // Puntatore all'elemento successivo della lista.
struct msgb *b_cont; // Puntatore per collegare altri messaggi a un messaggio, per creare una tupla di messaggi.
struct datab *b_datap; // Puntatore alla struttura del blocco dati.
unsigned char *b_rptr; // Puntatore all'inizio dell'area dati per leggere i dati del buffer b_datap.
unsigned char *b_wptr; // Puntatore all'inizio dell'area dati per scrivere i dati del buffer b_datap.
uint32_t reserved1; // Campo riservato 1, il media streamer vi inserisce informazioni di servizio.
uint32_t reserved2; // Campo riservato 2, il media streamer vi inserisce informazioni di servizio.
#if defined(ORTP_TIMESTAMP)
struct timeval timestamp;
#endif
ortp_recv_addr_t recv_addr;
} mblk_t;Struttura mblk_t inizialmente contiene puntatori b_prev, b_next, necessari per organizzare una lista doppiamente collegata (che è la coda queue_t).
Poi c'è il puntatore b_cont, che viene utilizzato solo quando il messaggio entra nella tupla. Per l'ultimo messaggio nella tupla, questo puntatore rimane nullo.
Successivamente vediamo un puntatore al blocco dati b_datap, per il quale esiste il messaggio. Dopo di esso ci sono puntatori all'area all'interno del buffer dati del blocco. Il campo b_rptr indica il luogo da cui verranno letti i dati dal buffer. Il campo b_wptr indica il luogo da cui verrà eseguita la scrittura nel buffer.
I campi rimanenti hanno carattere consultivo e non riguardano il funzionamento del meccanismo di trasferimento dati.
Di seguito è mostrato un singolo messaggio con il nome m1 e il blocco dati d1.
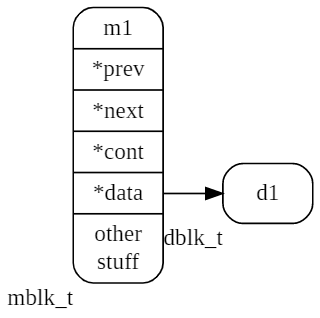
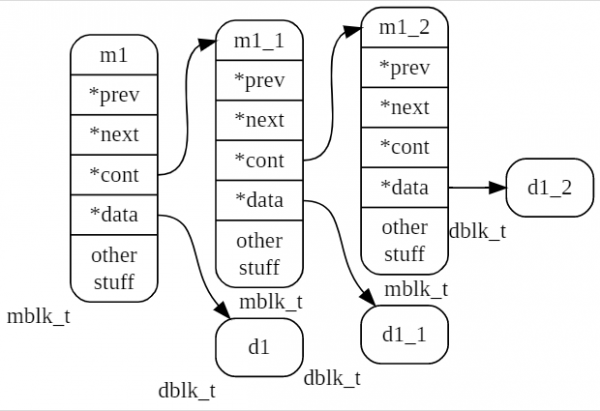
Nella figura successiva è raffigurata una tupla di tre messaggi m1, m1_1, m1_2.
Le funzioni che lavorano con i messaggi mblk_t
Un nuovo messaggio mblk_t viene creato dalla funzione:
mblk_t *allocb(int size, int pri); essa alloca in memoria un nuovo messaggio mblk_t con un blocco dati di dimensione specificata dimensione, il secondo argomento — pri non è utilizzato nella versione della libreria considerata. Deve rimanere nullo. Durante l'esecuzione della funzione verrà allocata memoria per la struttura del nuovo messaggio e verrà chiamata la funzione mblk_init(), che azzererà tutti i campi dell'istanza creata della struttura e poi, utilizzando quanto detto sopra, datab_alloc(), creerà un buffer di dati. Dopo di che verrà eseguita la configurazione dei campi nella struttura:
mp->b_datap=datab;
mp->b_rptr=mp->b_wptr=datab->db_base;
mp->b_next=mp->b_prev=mp->b_cont=NULL;In uscita otteniamo un nuovo messaggio con i campi inizializzati e un buffer di dati vuoto. Per aggiungere dati al messaggio, è necessario copiarli nel buffer del blocco dati:
memcpy(msg->b_rptr, data, size);dove data — puntatore alla fonte dei dati, e dimensione — la loro dimensione.
Dopodiché è necessario aggiornare il puntatore alla posizione di scrittura, affinché punti di nuovo all'inizio dell'area libera nel buffer:
msg->b_wptr = msg->b_wptr + sizeSe è necessario creare un messaggio da un buffer esistente, senza copia, si utilizza la funzione:
mblk_t *esballoc(uint8_t *buf, int size, int pri, void (*freefn)(void*)); La funzione, dopo aver creato il messaggio e la struttura del blocco dati, imposterà i puntatori ai dati all'indirizzo buf. Cioè, in questo caso il buffer dati non si trova immediatamente dopo i campi dell'intestazione del blocco dati, come avveniva durante la creazione del blocco dati tramite la funzione. datab_alloc(). Il buffer di dati passato alla funzione resterà dov'è, ma con l'uso dei puntatori verrà collegato all'intestazione del blocco di dati appena creato, che a sua volta sarà collegato al messaggio.
A un messaggio mblk_t possono essere concatenati più blocchi di dati consecutivamente. Questo viene fatto dalla funzione:
mblk_t * appendb(mblk_t *mp, const char *data, int size, bool_t pad); mp è il messaggio a cui verrà aggiunto un altro blocco di dati;
data è il puntatore al blocco, la cui copia sarà aggiunta al messaggio;
dimensione è la dimensione dei dati;
pad è il flag che indica che la dimensione della memoria allocata deve essere allineata a un confine di 4 byte (l'integrazione sarà eseguita con zeri).
Se nel buffer di dati del messaggio c'è spazio sufficiente, i nuovi dati verranno incollati a quelli già presenti. Se lo spazio nel buffer di dati del messaggio è inferiore a dimensione, verrà creato un nuovo messaggio con una dimensione del buffer adeguata e i dati saranno copiati nel suo buffer. Questo nuovo messaggio verrà collegato a quello originale tramite il puntatore b_cont. In questo caso, il messaggio si trasforma in una tupla.
Se si desidera aggiungere un altro blocco di dati alla tupla, è necessario utilizzare la funzione:
void msgappend(mblk_t *mp, const char *data, int size, bool_t pad);troverà l'ultimo messaggio nella tupla (sarà b_cont nullo) e chiamerà la funzione per quel messaggio appendb().
Puoi scoprire la dimensione dei dati nel messaggio o nella tupla tramite la funzione:
int msgdsize(const mblk_t *mp);scorrerà tutti i messaggi della tupla e restituirà il numero totale di dati nei buffer dati di questi messaggi. Per ogni messaggio, la quantità di dati viene calcolata in questo modo:
mp->b_wptr - mp->b_rptrPer unire due tuple si utilizza la funzione:
mblk_t *concatb(mblk_t *mp, mblk_t *newm);aggiunge la tupla newm alla fine della tupla mp e restituisce un puntatore all'ultimo messaggio della tupla risultante.
Se necessario, la tupla può essere convertita in un singolo messaggio con un blocco di dati unico, questo si fa con la funzione:
void msgpullup(mblk_t *mp,int len);se l'argomento len è uguale a -1, allora la dimensione del buffer allocato viene determinata automaticamente. Se len se è un numero positivo, verrà creato un buffer di questa dimensione e i dati dei messaggi della tupla verranno copiati in esso. Se il buffer si esaurisce, la copia si interromperà. Il primo messaggio della tupla riceverà un buffer di nuova dimensione con i dati copiati. I messaggi rimanenti verranno eliminati e la memoria restituita al heap.
Durante l'eliminazione della struttura mblk_t si considera il contatore dei riferimenti del blocco dati, se alla chiamata freeb() risulta zero, il buffer dati viene eliminato insieme all'istanza mblk_t, alla quale fa riferimento.
Inizializzazione dei campi del nuovo messaggio:
void mblk_init(mblk_t *mp);Aggiunta a un messaggio di un ulteriore insieme di dati:
mblk_t * appendb(mblk_t *mp, const char *data, size_t size, bool_t pad);Se i nuovi dati non si adattano nello spazio libero del buffer dati del messaggio, un messaggio creato separatamente con un buffer della dimensione necessaria sarà allegato al messaggio (nel primo messaggio verrà impostato un puntatore verso il messaggio aggiunto), trasformando così il messaggio in una tupla.
Aggiunta di un insieme di dati alla tupla:
void msgappend(mblk_t *mp, const char *data, size_t size, bool_t pad); La funzione chiama appendb() in un ciclo.
Unione di due tuple in una sola:
mblk_t *concatb(mblk_t *mp, mblk_t *newm);Messaggio newm verrà allegato a mp.
Creazione di una copia di un singolo messaggio:
mblk_t *copyb(const mblk_t *mp);Copia completa della tupla con tutti i blocchi dati:
mblk_t *copymsg(const mblk_t *mp);Gli elementi della tupla vengono copiati dalla funzione copyb().
Creazione di una copia leggera del messaggio mblk_t. In questo caso, il blocco dati non viene copiato, ma il suo contatore di riferimenti viene incrementato. db_ref:
mblk_t *dupb(mblk_t *mp);Creazione di una copia leggera della tupla. I blocchi dati non vengono copiati, ma solo i loro contatori di riferimenti vengono incrementati. db_ref:
mblk_t *dupmsg(mblk_t* m);Unione di tutti i messaggi della tupla in un unico messaggio:
void msgpullup(mblk_t *mp,size_t len);Se l'argomento len è uguale a -1, la dimensione del buffer riservato viene determinata automaticamente.
Rimozione del messaggio, della tupla:
void freemsg(mblk_t *mp);Il contatore di riferimenti del blocco dati viene decrementato di uno. Se raggiunge zero, il blocco dati viene anche eliminato.
Calcolo del volume totale dei dati nel messaggio o nella tupla.
size_t msgdsize(const mblk_t *mp);Estrazione del messaggio dalla coda:
mblk_t *ms_queue_peek_last(q);Copia del contenuto dei campi riservati di un messaggio in un altro messaggio (in realtà in questi campi si trovano flag utilizzati dallo streamer):
mblk_meta_copy(const mblk_t *source, mblk *dest);Coda queue_t
La coda dei messaggi nel media streamer è implementata come una lista doppiamente collegata circolare. Ogni elemento della lista contiene un puntatore a un blocco di dati con i campionamenti del segnale. In questo modo, vengono spostati solo i puntatori ai blocchi di dati, mentre i dati stessi rimangono fissi. Vale a dire, si spostano solo i riferimenti ad essi.
Struttura che descrive la coda queue_t, mostrata di seguito:
typedef struct _queue
{
mblk_t _q_stopper; /* "Elemento vuoto" della coda, non punta a dati, utilizzato solo per gestire la coda. Durante l'inizializzazione della coda (qinit()), i suoi puntatori vengono impostati in modo che puntino a se stesso. */
int q_mcount; // Numero di elementi nella coda.
} queue_t;La struttura contiene un campo – un puntatore _q_stopper di tipo *mblk_t, che punta al primo elemento (messaggio) nella coda. Il secondo campo della struttura è un contatore dei messaggi presenti nella coda.
Nell'immagine seguente è mostrata la coda con il nome q1, che contiene 4 messaggi m1, m2, m3, m4.
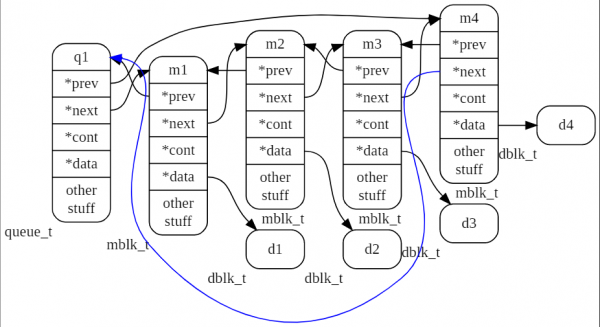
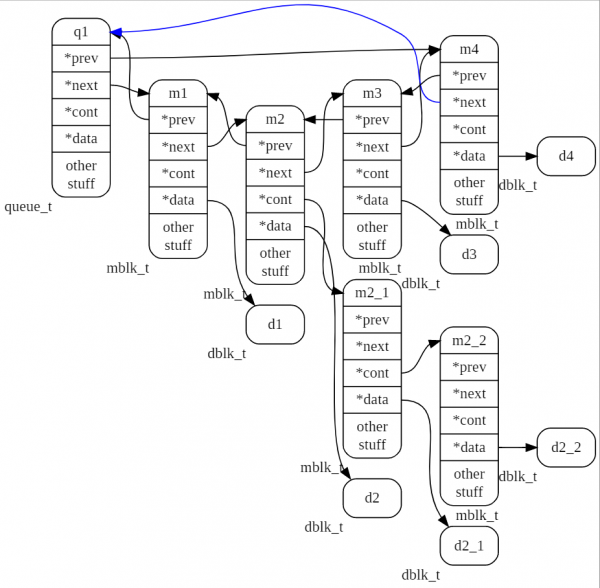
Nell'immagine successiva è mostrata la coda con il nome q1, che contiene 4 messaggi m1, m2, m3, m4. Il messaggio m2 è la testa della tupla, a cui si collegano altri due messaggi m2_1 e m2_2.
Funzioni per la gestione delle code queue_t
Inizializzazione della coda:
void qinit(queue_t *q);Campo _q_stopper (di seguito chiamato "stop") è inizializzato dalla funzione mblk_init(), il puntatore al precedente e al successivo elemento sono impostati in modo tale da puntare a se stesso. Il contatore degli elementi della coda viene azzerato.
Aggiunta di un nuovo elemento (messaggio):
void putq(queue_t *q, mblk_t *m);Il nuovo elemento m viene aggiunto alla fine della lista, i puntatori dell'elemento sono impostati in modo tale che lo stop diventi il suo successivo, e lui diventi il precedente dello stop. Il contatore degli elementi della coda viene incrementato.
Estrazione di un elemento dalla coda:
mblk_t * getq(queue_t *q); viene estratto il messaggio che si trova dopo lo stop, il contatore degli elementi viene decrementato. Se nella coda, oltre allo stop, non ci sono altri elementi, viene restituito 0.
Inserimento di un messaggio nella coda:
void insq(queue_t *q, mblk_t *emp, mblk_t *mp); Elemento mp viene inserito prima dell'elemento emp. Se emp=0, il messaggio viene aggiunto alla coda.
Estrazione del messaggio dalla testa della coda:
void remq(queue_t *q, mblk_t *mp); Il contatore degli elementi viene decrementato.
Lettura del puntatore al primo elemento nella coda:
mblk_t * peekq(queue_t *q); Rimozione di tutti gli elementi dalla coda con la cancellazione degli stessi elementi:
void flushq(queue_t *q, int how);Argomento how non utilizzato. Il contatore degli elementi della coda è impostato a zero.
Macro per leggere il puntatore all'ultimo elemento della coda:
mblk_t * qlast(queue_t *q);Quando si lavora con le code dei messaggi, si deve tenere presente che chiamando ms_queue_put(q, m) con un puntatore nullo al messaggio, la funzione entra in un ciclo infinito. Il tuo programma si bloccherà. Si comporta in modo simile ms_queue_next(q, m).
Collegamento dei filtri
La coda descritta sopra è utilizzata per trasmettere messaggi da un filtro a un altro, o da uno a più filtri. I filtri e le loro connessioni formano un grafo diretto. L'ingresso o l'uscita di un filtro sarà chiamato con il termine generale "pin". Per descrivere l'ordine delle connessioni tra i filtri, nel mediastreamer viene utilizzato il concetto di "punto di segnale". Un punto di segnale è una struttura _MSCPoint, che contiene un puntatore al filtro e il numero di uno dei suoi pin, descrivendo quindi la connessione di uno degli ingressi o uscite del filtro.
Punto di segnale del grafo di elaborazione dei dati
typedef struct _MSCPoint{
struct _MSFilter *filter; // Puntatore al filtro del mediastreamer.
int pin; // Numero di uno degli ingressi o uscite del filtro, ovvero il pin.
} MSCPoint;
I pin dei filtri sono numerati a partire da zero.
La connessione di due pin attraverso una coda di messaggi è descritta dalla struttura _MSQueue, che contiene una coda di messaggi e puntatori a due punti di segnale che essa collega:
typedef struct _MSQueue
{
queue_t q;
MSCPoint prev;
MSCPoint next;
}MSQueue;
Chiameremo questa struttura il link di segnale. Ogni filtro del media streamer contiene una tabella di link di ingresso e una tabella di link di uscita (MSQueue). Le dimensioni delle tabelle sono definite al momento della creazione del filtro, come abbiamo già fatto utilizzando la variabile esportata di tipo MSFilterDesc, quando abbiamo sviluppato il nostro filtro. Di seguito è mostrata la struttura che descrive qualsiasi filtro nel media streamer, MSFilter:
struct _MSFilter{
MSFilterDesc *desc; /* Puntatore al descrittore del filtro. */
/* Attributi protetti, non possono essere spostati o rimossi altrimenti il funzionamento con i plugin sarà compromesso. */
ms_mutex_t lock; /* Semaforo. */
MSQueue **inputs; /* Tabella dei collegamenti in ingresso. */
MSQueue **outputs; /* Tabella dei collegamenti in uscita. */
struct _MSFactory *factory; /* Puntatore alla fabbrica che ha creato questa istanza del filtro. */
void *padding; /* Non utilizzato, sarà utilizzato se verranno aggiunti campi protetti. */
void *data; /* Puntatore a una struttura arbitraria per memorizzare lo stato interno del filtro e calcoli intermedi. */
struct _MSTicker *ticker; /* Puntatore all'oggetto tick, che non deve essere nullo quando viene chiamata la funzione process(). */
/* attributi privati, possono essere spostati e cambiati in qualsiasi momento */
MSList *notify_callbacks; /* Lista dei callback utilizzati per gestire gli eventi del filtro. */
uint32_t last_tick; /* Numero dell'ultimo tick in cui è stata eseguita la chiamata a process(). */
MSFilterStats *stats; /* Statistiche di funzionamento del filtro. */
int postponed_task; /* Numero di attività posticipate. Alcuni filtri possono posticipare l'elaborazione dei dati (chiamata a process()) per diversi tick. */
bool_t seen; /* Flag utilizzato dal ticker per contrassegnare che questa istanza del filtro è già stata gestita in questo tick. */
};
typedef struct _MSFilter MSFilter;
Dopo che abbiamo collegato i filtri nel programma C secondo il nostro progetto (ma senza collegare il ticker), abbiamo creato un grafo diretto, i cui nodi sono istanze della struttura MSFilter, mentre i bordi sono istanze dei link MSQueue.
Attività dietro le quinte del ticker
Quando ti ho detto che il ticker è un filtro fonte di impulsi, non era l'unica verità su di esso. Il ticker è un oggetto che esegue l'avvio delle funzioni process() di tutti i filtri dello schema (grafo) a cui è collegato. Quando nel programma C colleghiamo il ticker al filtro del grafo, mostriamo al ticker il grafo di cui gestirà, fino a quando non lo disconnettiamo. Dopo il collegamento, il ticker inizia a esaminare il grafo a lui affidato, compilando un elenco dei filtri di cui fa parte. Per non "contare" lo stesso filtro due volte, segna i filtri rilevati impostando un flag seen. La ricerca avviene attraverso le tabelle dei link, che sono presenti in ogni filtro.
Durante il suo tour di introduzione, il ticker verifica se tra i filtri ce n'è almeno uno che funge da sorgente di blocchi di dati. Se non si trova nulla, il grafo è considerato errato e il ticker termina l'esecuzione.
Se il grafo risulta "corretto", per ogni filtro trovato viene chiamata la funzione di inizializzazione preprocess(). Quando arriva il momento per il prossimo ciclo di elaborazione (ogni 10 millisecondi per impostazione predefinita), il ticker invoca la funzione process() per tutti i filtri sorgente precedentemente trovati e poi per gli altri filtri nella lista. Se un filtro ha collegamenti in ingresso, l'esecuzione della funzione process() si ripete finché le code dei collegamenti in ingresso non sono vuote. Dopodiché, si sposta al successivo filtro nella lista e "scorre" fino a liberare i collegamenti in ingresso dai messaggi. Il ticker passa da un filtro all'altro finché non termina la lista. A questo punto, si conclude il ciclo di elaborazione.
Ora torniamo alle tuple e parliamo del motivo per cui è stata aggiunta una tale entità nel media streamer. In generale, il volume di dati necessario per l'algoritmo che opera all'interno del filtro non corrisponde e non è multiplo delle dimensioni dei buffer di dati in ingresso. Ad esempio, scriviamo un filtro che esegue una trasformata di Fourier veloce, che per definizione può elaborare solo blocchi di dati la cui dimensione è una potenza di due. Supponiamo che siano 512 campioni. Se i dati vengono generati tramite un canale telefonico, allora il buffer dei dati di ciascun messaggio in ingresso ci porterà 160 campioni di segnale. C'è la tentazione di non prelevare dati dall'ingresso finché non ci sarà la quantità necessaria. Ma in questo caso si verificherebbe una collisione con il ticker, che tenterebbe invano di far scorrere il filtro fino a svuotare il link in ingresso. In precedenza abbiamo definito questa regola come il terzo principio di funzionamento del filtro. Secondo questo principio, la funzione process() del filtro deve prelevare tutti i dati dalle code di ingresso.
Oltre a ciò, non sarà possibile prelevare solo 512 campioni dall'ingresso, poiché è necessario prelevare interi blocchi, ovvero il filtraggio dovrà prelevare 640 campioni e utilizzare 512 di essi, mantenendo il resto fino al raggiungimento di un nuovo lotto di dati. Così, il nostro filtro, oltre al suo compito principale, deve garantire azioni ausiliarie per la memorizzazione temporanea dei dati in ingresso. Gli sviluppatori del media streamer e della soluzione a questo problema comune hanno progettato un oggetto speciale: MSBufferizer, che affronta questa sfida tramite le tuple.
Bufferizzatore (MSBufferizer)
Questo oggetto accumulerà i dati in ingresso all'interno del filtro e inizierà a restituirli per l'elaborazione non appena la quantità di informazioni sarà sufficiente per eseguire l'algoritmo del filtro. Mentre il buffer accumula dati, il filtro funzionerà in modalità idle, senza utilizzare la capacità di calcolo della CPU. Ma non appena la funzione di lettura dal buffer restituirà un valore diverso da zero, la funzione process() del filtro inizia a prelevare e a elaborare i dati dal buffer in porzioni della dimensione richiesta, fino al loro esaurimento.
I dati non ancora utilizzati rimangono nel buffer come primo elemento della tupla a cui si collegano i successivi blocchi di input.
Struttura che descrive il buffer:
struct _MSBufferizer{
queue_t q; /* Coda dei messaggi. */
int size; /* Dimensione totale dei dati attualmente nel buffer. */
};
typedef struct _MSBufferizer MSBufferizer;Funzioni per la gestione di MSBufferizer
Creazione di una nuova istanza del buffer:
MSBufferizer * ms_bufferizer_new(void);Viene allocata memoria, inizializzata in ms_bufferizer_init() e RESTITUISCE un puntatore.
Funzione di inizializzazione:
void ms_bufferizer_init(MSBufferizer *obj); Viene inizializzata la coda q, campo dimensione impostata a zero.
Aggiunta di un messaggio:
void ms_bufferizer_put(MSBufferizer *obj, mblk_t *m); Il messaggio m viene aggiunto alla coda. La dimensione calcolata dei blocchi di dati viene sommata a dimensione.
Trasferimento al buffer di tutti i messaggi nella coda dei dati del link q:
void ms_bufferizer_put_from_queue(MSBufferizer *obj, MSQueue *q); Il trasferimento dei messaggi dal link q nel buffer avviene tramite la funzione ms_bufferizer_put().
Lettura dal buffer:
int ms_bufferizer_read(MSBufferizer *obj, uint8_t *data, int datalen); Se la dimensione dei dati accumulati nel buffer è inferiore a quella richiesta (datalen), la funzione restituisce zero, la copia dei dati in data non viene effettuata. Altrimenti, avviene la copia sequenziale dei dati dai tuple presenti nel buffer. Dopo la copia, il tuple viene rimosso e la memoria viene liberata. La copia termina nel momento in cui vengono copiati datalen byte. Se lo spazio si esaurisce a metà di un blocco di dati, in questo caso, il blocco di dati verrà troncato alla parte rimanente non copiato. Alla successiva chiamata, la copia continuerà da questo punto.
Lettura della quantità di dati disponibili in questo momento nel buffer:
int ms_bufferizer_get_avail(MSBufferizer *obj); Restituisce il campo dimensione del buffer.
Scarto di una parte dei dati presenti nel buffer:
void ms_bufferizer_skip_bytes(MSBufferizer *obj, int bytes);La quantità specificata di byte di dati viene estratta e scartata. Vengono scartati i dati più vecchi.
Rimozione di tutti i messaggi presenti nel buffer:
void ms_bufferizer_flush(MSBufferizer *obj); Il contatore dei dati viene azzerato.
Rimozione di tutti i messaggi presenti nel buffer:
void ms_bufferizer_uninit(MSBufferizer *obj); L'azzeramento del contatore non viene effettuato.
Rimozione del buffer e liberazione della memoria:
void ms_bufferizer_destroy(MSBufferizer *obj); Esempi di utilizzo del buffer possono essere trovati nel codice sorgente di diversi filtri del media streamer. Ad esempio, nel filtro MS_L16_ENC, che esegue la permutazione dei byte nei campioni dall'ordine di rete all'ordine dell'host:
Nell'articolo seguente, esamineremo la questione della valutazione del carico sul ticker e i modi per affrontare un'eccessiva carico computazionale nel media streamer.
Fonte: habr.com
