

Abbiamo sviluppato un design di rete dei data center che consente di implementare cluster di calcolo con oltre 100.000 server, con una larghezza di banda di picco (bisection bandwidth) superiore a un petabyte al secondo.
Dalla relazione di Dmitry Afanasyev, apprenderai i principi fondamentali del nuovo design, le topologie di scaling, i problemi che ne derivano, le soluzioni possibili, le caratteristiche del routing e lo scaling delle funzioni del forwarding plane nei moderni dispositivi di rete in topologie 'densamente collegate' (densely connected) con un elevato numero di percorsi ECMP. Inoltre, Dima ha brevemente parlato dell'organizzazione della connettività esterna, del livello fisico, del sistema di cablaggio e delle modalità per aumentare ulteriormente la capacità.
— Buongiorno a tutti! Mi chiamo Dmitry Afanasyev, sono un architetto di rete di Yandex e mi occupo principalmente del design delle reti dei data center.

La mia presentazione riguarderà la rete di data center aggiornata di Yandex. Si tratta in gran parte di un'evoluzione del design che avevamo, ma ci sono anche alcuni elementi nuovi. Questa è una presentazione panoramica, poiché dovevamo inserire molte informazioni in poco tempo. Inizieremo con la scelta della topologia logica. Poi ci sarà una panoramica del control plane e dei problemi di scalabilità del data plane, la scelta di ciò che accadrà a livello fisico e daremo un'occhiata ad alcune caratteristiche dei dispositivi. Accenneremo anche a ciò che sta accadendo nel data center con MPLS, di cui abbiamo parlato qualche tempo fa.

Quindi, cos'è Yandex in termini di carichi e servizi? Yandex è un tipico iperscalatore. Se guardiamo agli utenti, ci occupiamo prima di tutto dell'elaborazione delle richieste degli utenti. Ci sono anche vari servizi di streaming e distribuzione di dati, poiché abbiamo anche servizi di storage. Se ci spostiamo verso il backend, emergono carichi di infrastruttura e servizi come archiviazione distribuita, replica dei dati e, naturalmente, code persistenti. Uno dei principali tipi di carichi è MapReduce e sistemi simili, elaborazione in tempo reale, machine learning, ecc.

Come è strutturata l'infrastruttura su cui si basa tutto questo? Ancora una volta, siamo un tipico hyperscaler, anche se potremmo essere un po' più vicini a quel lato dello spettro che comprende gli hyperscaler più piccoli. Ma abbiamo tutte le caratteristiche. Utilizziamo hardware di commodity e scalabilità orizzontale ovunque sia possibile. Abbiamo una gestione delle risorse a pieno regime: non lavoriamo con singole macchine o rack, ma le uniamo in un grande pool di risorse intercambiabili con servizi aggiuntivi che si occupano della pianificazione e dell'allocazione, gestendo tutto questo pool.
Quindi, abbiamo il livello successivo — un sistema operativo di livello cluster computazionale. È molto importante che noi controlliamo completamente lo stack tecnologico che utilizziamo. Controlliamo gli endpoint (host), la rete e lo stack software.
Abbiamo diversi grandi data center in Russia e all'estero. Questi sono collegati da un backbone che utilizza la tecnologia MPLS. La nostra infrastruttura interna è praticamente completamente basata su IPv6, ma poiché dobbiamo gestire il traffico esterno, che arriva principalmente tramite IPv4, dobbiamo in qualche modo instradare le richieste che arrivano tramite IPv4 fino al frontend-server, e un po' di ulteriore accesso all'IPv4 pubblico — ad esempio, per l'indicizzazione.
Le ultime iterazioni del design delle reti dei data center utilizzano topologie Clos multilivello, applicando esclusivamente L3. Ci siamo allontanati da L2 già da tempo e ne siamo sollevati. Finalmente, la nostra infrastruttura comprende centinaia di migliaia di istanze di calcolo (server). La dimensione massima del cluster era di circa 10.000 server qualche tempo fa. Questo è dovuto in gran parte a come possono funzionare i sistemi operativi di livello cluster, i programmatori, l'allocazione delle risorse, e così via. Con i progressi nel software infrastrutturale, ora l'obiettivo è una dimensione di circa 100.000 server in un unico cluster di calcolo, e ci siamo posti l'obiettivo di costruire fabbriche di rete che consentano un'efficace pooling delle risorse in un tale cluster.

Cosa vogliamo dalla rete del data center? In primo luogo, molta larghezza di banda economica e abbastanza uniformemente distribuita. Perché la rete è la base su cui possiamo fare pooling delle risorse. La nuova dimensione obiettivo è di circa 100.000 server in un unico cluster.
Naturalmente, abbiamo bisogno di un control plane scalabile e stabile, perché su un'infrastruttura così ampia ci sono molteplici problemi, anche da eventi casuali, e non vogliamo che il control plane ci porti ulteriore stress. Inoltre, vogliamo minimizzare lo stato al suo interno. Meno stato c'è, meglio funziona tutto, rendendo più semplice la diagnostica.
Certo, abbiamo bisogno di automazione, poiché gestire manualmente un'infrastruttura del genere è impossibile, e lo è già da un po' di tempo. Abbiamo bisogno, per quanto possibile, di supporto per le operazioni e per CI/CD, nella misura in cui è fattibile.
Con dimensioni così grandi per i data center e i cluster, diventa fondamentale supportare il dispiegamento incrementale e l'espansione senza interrompere il servizio. Se per cluster di mille macchine, probabilmente vicine alle diecimila macchine, era ancora possibile effettuare il dispiegamento come un'unica operazione — ovvero pianificare l'espansione dell'infrastruttura e aggiungere diverse migliaia di macchine in un'unica operazione — per un cluster di quasi cento mila macchine, la situazione non è così semplice. Questo si costruisce nel corso del tempo. È importante che durante tutto questo tempo l'infrastruttura già dispiegata rimanga accessibile.
E c'è un requisito che avevamo e che è scomparso: il supporto per il multitenancy, ovvero la virtualizzazione o segmentazione della rete. Ora non dobbiamo più farlo a livello di rete, perché la segmentazione è passata agli host, e questo ha semplificato notevolmente la nostra scalabilità. Grazie all'IPv6 e al grande spazio di indirizzamento, non abbiamo dovuto utilizzare indirizzi duplicati nella nostra infrastruttura interna; tutta la nostra assegnazione degli indirizzi era già unica. Inoltre, spostando la filtrazione e la segmentazione della rete sugli host, non dobbiamo creare entità di rete virtuali nelle reti dei data center.

C'è un aspetto molto importante: cose di cui non abbiamo bisogno. Se alcune funzioni possono essere rimosse dalla rete, la vita diventa molto più semplice e, di solito, amplia la scelta di apparecchiature e software disponibili, semplificando notevolmente anche la diagnostica.
Quindi, cosa non ci serve, da cosa siamo riusciti a liberarci, non sempre con gioia nel momento in cui è avvenuto, ma con grande sollievo quando il processo si è concluso?
In primo luogo, abbandoniamo L2. Non abbiamo bisogno di L2, né reale né emulato. Non viene utilizzato in larga misura grazie al fatto che controlliamo il stack delle applicazioni. Le nostre applicazioni sono scalabili orizzontalmente, funzionano con indirizzamento L3 e non si preoccupano molto se un'istanza singola smette di funzionare; semplicemente ne distribuiamo una nuova, senza bisogno di farla partire sul vecchio indirizzo, perché c'è un livello separato di service discovery e monitoraggio delle macchine nel cluster. Non trasferiamo questo compito sulla rete. Il compito della rete è quello di consegnare pacchetti da punto A a punto B.
Non ci sono situazioni in cui gli indirizzi si spostano all'interno della rete, e questo deve essere monitorato. In molte configurazioni, questo è generalmente necessario per supportare la mobilità delle VM. Non utilizziamo la mobilità delle macchine virtuali nella nostra infrastruttura interna di Yandex e, inoltre, riteniamo che, anche se viene implementata, non dovrebbe avvenire con il supporto della rete. Se è davvero necessario farlo, dev'essere gestito a livello degli host, e introdurre indirizzi che possono migrare in overlay, in modo da non intervenire e non apportare troppi cambiamenti dinamici al sistema di routing dell'underlay (rete di trasporto).
Un'altra tecnologia che non utilizziamo è il multicast. Posso spiegare in dettaglio perché a chiunque lo desideri. Questo semplifica notevolmente la vita, perché se qualcuno ha avuto a che fare con esso e ha visto come appare il piano di controllo del multicast — in tutte le installazioni, tranne le più semplici, è un grande mal di testa. Inoltre, è difficile trovare una soluzione open-source ben funzionante, per esempio.
Infine, progettiamo le nostre reti in modo che non ci siano troppi cambiamenti. Possiamo contare sul fatto che il flusso di eventi esterni nel sistema di routing è limitato.

Quali problemi e quali limiti dobbiamo considerare quando sviluppiamo una rete di data center? Il costo, naturalmente. La scalabilità, ovvero fino a che punto vogliamo crescere. La necessità di espansione senza interrompere il servizio. La larghezza di banda, la disponibilità. La visibilità di ciò che accade nella rete per i sistemi di monitoraggio e per le squadre operative. Il supporto all'automazione — di nuovo, per quanto possibile, poiché diverse attività possono essere gestite a livelli diversi, inclusa l'introduzione di ulteriori strati. E, infine, la dipendenza dai fornitori, sebbene in diversi periodi storici, a seconda di quale aspetto si consideri, questa indipendenza sia stata più o meno raggiungibile. Se prendiamo in considerazione i chip dei dispositivi di rete, fino a tempi recenti, parlare di indipendenza dai fornitori, soprattutto se volevamo chip ad alta capacità, era molto relativo.
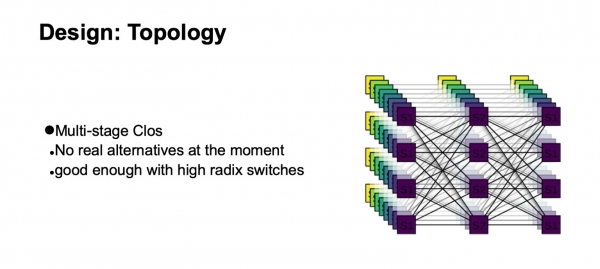
Quale topologia logica utilizzeremo per costruire la nostra rete? Sarà una topologia Clos multilivello. In realtà, al momento non ci sono alternative reali. E la topologia Clos è sufficientemente buona, anche se confrontata con varie topologie avanzate che si trovano principalmente nell'ambito dell'interesse accademico, se abbiamo switch con grandi radix.
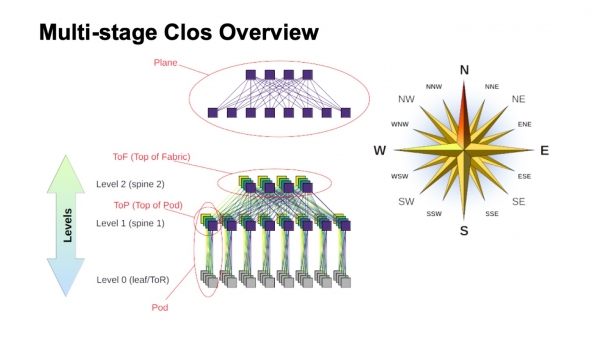
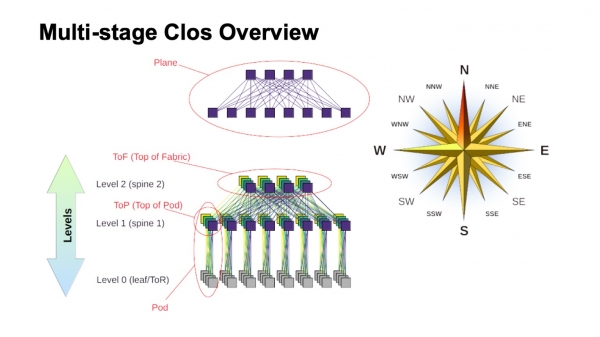
Come funziona approssimativamente una rete Clos multilivello e come vengono chiamati i suoi vari elementi? In primo luogo, è utile avere una rosa dei venti per orientarsi: dove si trova il nord, il sud, l'est e l'ovest. Questo tipo di reti è solitamente costruito da chi ha un traffico molto elevato da ovest a est. Per quanto riguarda gli altri elementi, in alto è raffigurato uno switch virtuale, composto da switch più piccoli. Questa è l'idea fondamentale della costruzione ricorsiva delle reti Clos. Prendiamo elementi con un certo radix e li colleghiamo in modo che ciò che otteniamo possa essere considerato come uno switch con un radix più grande. Se necessario, la procedura può essere ripetuta.
In cases such as dual-level Clos, where the components that I have outlined in my diagram are clearly vertical, they are commonly referred to as planes. If we were building a Clos with three levels of spine switches (all of which are neither boundary nor ToR switches and are used solely for transit), the planes would appear more complex; the dual-level ones look like this. The block of ToR or leaf switches and the associated first-level spine switches are called a Pod. The spine switches at the top of the Pod are the top of Pod. The switches located at the very top of the entire fabric represent the upper layer of the fabric, known as the Top of fabric.

Certo, sorge la questione: le reti Clos esistono da un po' di tempo e l'idea stessa risale ai tempi della telefonia classica, delle reti TDM. Può essere che sia emerso qualcosa di migliore, o che si possa fare in modo diverso? Sì e no. Teoricamente sì, ma nella pratica non è affatto così a breve termine. Esistono alcune topologie interessanti, alcune delle quali vengono persino utilizzate in produzione; ad esempio, Dragonfly è impiegato in applicazioni HPC; ci sono anche topologie interessanti come Xpander, FatClique e Jellyfish. Se si guardano le presentazioni a conferenze come SIGCOMM o NSDI negli ultimi tempi, si possono trovare un numero ragguardevole di lavori su topologie alternative con proprietà (in un modo o nell'altro) migliori rispetto alle reti Clos.
Tuttavia, tutte queste topologie presentano una caratteristica interessante. Essa ostacola la loro implementazione nelle reti dei data center che cerchiamo di costruire su hardware standard e che hanno un costo ragionevole. In tutte queste topologie alternative, la maggior parte della larghezza di banda, purtroppo, non è disponibile tramite le strade più brevi. Pertanto, perdiamo immediatamente la possibilità di utilizzare un tradizionale control plane.
Teoricamente, la soluzione al problema è nota. Si tratta, ad esempio, di modifiche allo stato del link utilizzando il k-shortest path, ma, di nuovo, non ci sono protocolli che siano stati implementati in produzione e disponibili su larga scala sull'hardware.
Inoltre, poiché gran parte della capacità non è disponibile attraverso i percorsi più brevi, dobbiamo modificare non solo il piano di controllo affinché selezioni tutti questi percorsi (e, per inciso, si tratta di uno stato molto più complesso nel piano di controllo). Dobbiamo anche modificare il piano di forwarding, e in genere sono necessarie almeno due funzionalità aggiuntive. Questa è la possibilità di prendere tutte le decisioni sul forwarding dei pacchetti contemporaneamente, ad esempio, su un host. In effetti, si tratta di routing sorgente; a volte nella letteratura sulle interconnessioni di rete viene chiamato decisioni di forwarding all-at-once. E poi c'è il routing adattivo — questa è una funzione necessaria nei nostri elementi di rete, che consiste ad esempio nel scegliere il prossimo hop sulla base delle informazioni sulla minore congestione della coda. Come esempio, ci sono altre opzioni possibili.
Pertanto, la direzione è interessante, ma, sfortunatamente, al momento non possiamo applicarla.

Ok, ci siamo fermati sulla topologia logica Clos. Come la scaleremo? Diamo un'occhiata a come è strutturata e cosa possiamo fare.
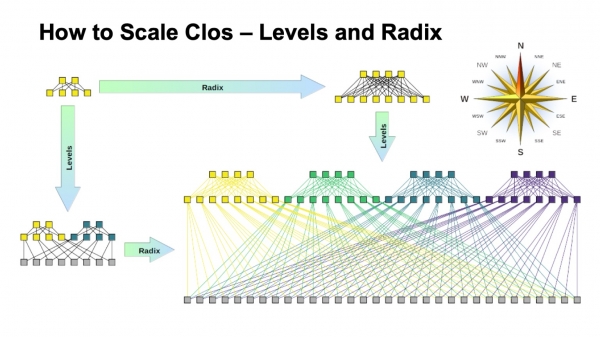
Nella rete Clos ci sono due parametri principali che possiamo variare per ottenere risultati diversi: il radix degli elementi e il numero di livelli nella rete. Ho rappresentato schematicamente come entrambi influenzano le dimensioni. Idealmente, combiniamo entrambi.

Si può notare che la larghezza finale della rete Clos è il prodotto dei switch spine del radix sud e del numero di link verso il basso, così come di come si ramifica. Ecco come scaldiamo le dimensioni della rete.
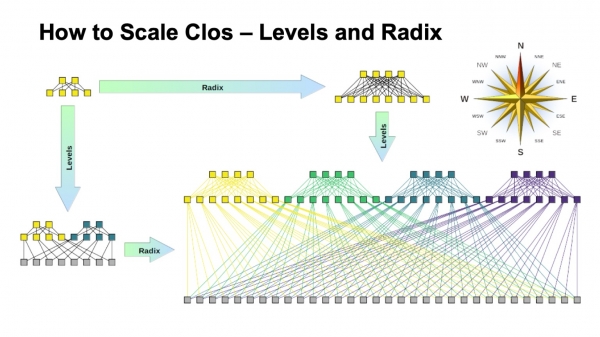
Per quanto riguarda la capacità, specialmente sugli switch ToR, ci sono due opzioni di scalabilità. Possiamo usare link più veloci, mantenendo la topologia generale, oppure possiamo aggiungere un numero maggiore di piani.
Se guardiamo la versione espansa della rete Clos (in basso a destra) e torniamo a questa immagine con la rete Clos in basso…
… è esattamente la stessa topologia, ma in questa slide è compressa in modo più compatto e i piani della fabbrica sono sovrapposti. È la stessa cosa.

Come si presenta la scalabilità della rete Clos in numeri? Qui vi fornisco dati su quale larghezza massima può ottenere la rete, quale numero massimo di rack, switch ToR o switch leaf possiamo ottenere, a seconda del tipo di switch radix utilizzati per i livelli spine e di quanti livelli utilizziamo.
Qui è indicato quanti rack possono esserci, quanti server e approssimativamente quanto può consumare tutto ciò, calcolando 20 kW per rack. Poco prima ho menzionato che puntiamo a una dimensione del cluster di circa 100.000 server.
È evidente che in tutta questa costruzione ci siano due e mezzo varianti di interesse. C'è una variante con due strati di spine e switch da 64 porte, che è un po' al di sotto delle aspettative. Poi ci sono le ottime varianti per switch spine da 128 porte (con radix 128) con due livelli, oppure switch con radix 32 con tre livelli. E in tutti i casi in cui c'è un radix maggiore e più livelli, si può creare una rete molto grande, ma se si guarda al consumo previsto, in genere, sono gigawatt. I cavi possono essere installati, ma è difficile ottenere così tanta elettricità in un'unica sede. Se si guarda alle statistiche, i dati pubblici sui data center mostrano che ci sono pochissimi data center con una potenza nominale superiore a 150 MW. Quelli maggiori sono solitamente campus di data center, con diversi grandi data center situati abbastanza vicini l'uno all'altro.
C'è un altro parametro importante. Se guardate la colonna sinistra, troverete la larghezza di banda utilizzabile. Non è difficile notare che nella rete Clos una parte significativa delle porte è dedicata a collegare gli switches tra loro. La larghezza di banda utilizzabile è ciò che possiamo destinare verso l'esterno, verso i server. Naturalmente, mi riferisco alle porte condizionali e alla larghezza di banda. Di norma, i collegamenti all'interno della rete sono più veloci dei collegamenti verso i server, ma per ogni unità di larghezza di banda che possiamo fornire alla nostra attrezzatura server ci sono ancora altre unità di larghezza di banda all'interno della rete stessa. E più livelli creiamo, maggiori sono i costi per fornire questa larghezza di banda verso l'esterno.
Inoltre, anche questa larghezza di banda aggiuntiva non è del tutto uniforme. Finché i salti sono brevi, possiamo utilizzare qualcosa come il DAC (copper direct attach, ovvero cavi twinax), o la fibra multimodale, che ha un costo relativamente ragionevole. Non appena ci spostiamo su salti più lunghi — di norma, si tratta di fibra monomodale, e il costo di questa larghezza di banda aggiuntiva aumenta notevolmente.
E tornando ancora al diapositiva precedente, se creiamo una rete Clos senza riconfigurazione, è facile dare un'occhiata allo schema e vedere come viene costruita la rete: aggiungendo ogni livello di switch spina, ripetiamo tutta la banda che era in basso. In più, a ogni livello — si aggiunge la stessa fascia, ancora altrettanta rispetto al livello precedente, porte sugli switch, altrettanti trasceiver. Quindi è molto desiderabile minimizzare il numero di livelli di switch spina.
Sulla base di questa immagine, è evidente che siamo molto interessati a costruire su qualcosa come switch con un radix di 128.

In sostanza, è tutto lo stesso che ho appena spiegato; questa diapositiva è più che altro per una futura considerazione.

Quali opzioni abbiamo a disposizione per questi switch? È una notizia molto positiva per noi sapere che ora è finalmente possibile costruire tali reti con switch a chip singolo. È davvero fantastico, poiché presentano molte caratteristiche vantaggiose. Ad esempio, quasi non hanno una struttura interna. Questo significa che è più probabile che si rompano. Si rompono, questo è inevitabile, ma per fortuna si rompono completamente. Negli apparecchi modulari ci sono numerosi guasti (molto fastidiosi) in cui, dal punto di vista dei vicini e del piano di controllo, sembrano funzionare, ma ad esempio, una parte della fabbrica è andata persa, e non operano a piena capacità. Il traffico è bilanciato assumendo che siano completamente funzionali, e ciò può portare a un sovraccarico.
Oppure, ad esempio, si verificano problemi con il backplane, perché all'interno del dispositivo modulare ci sono anche SerDes ad alta velocità— è davvero complesso all'interno. Oppure le tabelle si sincronizzano o non si sincronizzano tra gli elementi di forwarding. In generale, ogni dispositivo modulare ad alte prestazioni, composto da un gran numero di elementi, di solito contiene la stessa rete Clos, solo che è molto difficile da diagnosticare. Spesso anche al fornitore stesso risulta difficile diagnosticare.
E ha un gran numero di scenari di guasto, in cui il dispositivo degrada ma non esce completamente dalla topologia. Poiché abbiamo una rete grande, utilizziamo attivamente il bilanciamento tra elementi identici; la rete è molto regolare, ovvero un percorso, in cui tutto va bene, non si distingue affatto da un altro percorso. Ci conviene semplicemente perdere parte dei dispositivi dalla topologia, piuttosto che trovarci in una situazione in cui alcuni di essi sembrano funzionare, mentre altri no.

Una caratteristica interessante dei dispositivi a chip singolo è che evolvono meglio e più velocemente. Inoltre, tendono ad avere una capacità migliore. Se consideriamo grandi strutture assemblate che abbiamo, in generale, la capacità per unità rack per porte alla stessa velocità risulta quasi due volte migliore rispetto a quella dei dispositivi modulari. I dispositivi costruiti attorno a un singolo chip risultano significativamente più economici rispetto ai modulari e consumano meno energia.
Tuttavia, ovviamente, non è tutto roseo e ci sono degli svantaggi. In primo luogo, quasi sempre hanno un radix inferiore rispetto ai dispositivi modulari. Se possiamo ottenere un dispositivo costruito attorno a un singolo chip con 128 porte, per quello modulare possiamo già avere senza particolari problemi diverse centinaia di porte.
È una dimensione nettamente inferiore per le tabelle di forwarding e, in generale, per quanto riguarda la scalabilità del data plane. Buffer poco profondi. E, in generale, funzionalità piuttosto limitata. Tuttavia, si scopre che se si conoscono queste limitazioni e ci si preoccupa di aggirarle o semplicemente di tenerle in considerazione, non è poi così spaventoso. Il fatto che il radix sia più piccolo non è più un problema con i dispositivi recenti dotati di radix 128, possiamo costruirci in due livelli di spine. Ma non si può costruire nulla di interessante con una dimensione inferiore a due. Con un livello solo si ottengono solo cluster molto piccoli. Anche i nostri progetti e requisiti precedenti li superavano comunque.
In realtà, se una soluzione si trova in una situazione critica, c'è un altro modo per scalare. Poiché l'ultimo (o il primo) livello, a cui sono collegati i server, sono gli switch ToR o gli switch leaf, non siamo obbligati a collegare un solo armadio a essi. Quindi, se la soluzione è insufficiente di due volte, si può considerare l'opzione di utilizzare uno switch con un radismo maggiore a livello inferiore e collegare, ad esempio, due o tre armadi a uno switch. Anche questa è un'opzione, ha i suoi costi, ma funziona e può rivelarsi una buona soluzione quando è necessario raddoppiare le dimensioni.
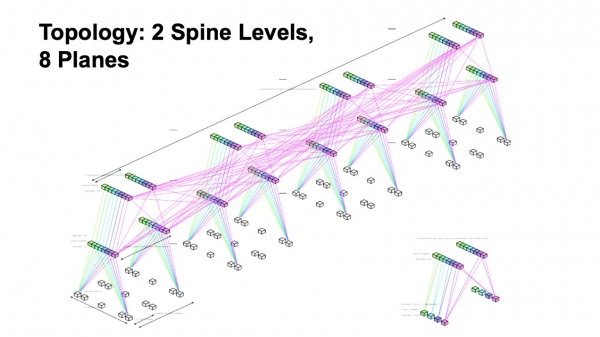
In sintesi, ci costruiamo su una topologia con due livelli di spine, con otto strati di fabbrica.

Cosa succederà alla fisica? Calcoli molto semplici. Se abbiamo due livelli di spine, allora abbiamo in totale tre livelli di switch, e ci aspettiamo che nella rete ci siano tre segmenti di cavo: dai server agli switch leaf, verso lo spine 1, e verso lo spine 2. Le opzioni che possiamo utilizzare sono twinax, multimodale, e singolo modo. Qui dobbiamo tener conto della larghezza disponibile, del costo, delle dimensioni fisiche, delle distanze che possiamo coprire, e di come ci aggiorneremo.
In termini di costi, tutto può essere organizzato in una sequenza. I twinax sono sensibilmente più economici rispetto all'ottica attiva, più economici rispetto ai trasmettitori multimodali, se consideriamo la distanza finale, un po' più economici rispetto a una porta da 100 gigabit di uno switch. E, attenzione, sono più economici rispetto all'ottica di singolo modo, perché nelle distanze dove è richiesto il singolo modo, nei data center per diverse ragioni ha senso utilizzare CWDM; lavorare con il singolo modo parallelo (PSM) non è molto conveniente, si hanno grandi quantità di fibra, e se ci si attiene a queste tecnologie, si ha una gerarchia di prezzi simile.
Un'ulteriore osservazione: purtroppo, non è molto pratico utilizzare i porti multimodali suddivisi 100 in 4x25. A causa delle peculiarità della costruzione, i trasmettitori SFP28 costano solo leggermente meno dei QSFP28 da 100 Gbit. E questa suddivisione per multimodo non funziona molto bene.
Un'altra limitazione è che, a causa delle dimensioni dei cluster di calcolo e del numero di server, i nostri data center risultano fisicamente grandi. Questo significa che almeno un corridoio dovrà essere realizzato con la tecnologia single mode. Ancora una volta, a causa delle dimensioni fisiche, i Pods non potranno attraversare due corridoi twinax (cavi in rame).
In definitiva, se ottimizziamo in base al prezzo e consideriamo la geometria di questa costruzione, otteniamo un corridoio twinax, un corridoio multimodale e un corridoio single mode utilizzando CWDM. Questo tiene conto dei possibili percorsi di aggiornamento.
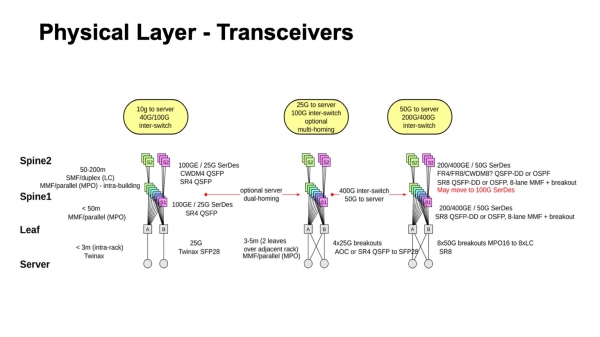
Questo è un esempio di ciò che è successo di recente, dove stiamo andando e cosa potrebbe essere possibile. È chiaro, almeno, come procedere verso i SerDes da 50 gigabit, sia per multimode che per singlemode. Inoltre, se si osserva ciò che è attualmente disponibile nei trasmettitori singlemode e le prospettive future per il 400G, spesso, anche quando arrivano SerDes da 50G con l'interfaccia elettrica, nell'ottica si possono già raggiungere i 100 Gbps per lane. Quindi è del tutto possibile che, anziché passare ai 50G, ci sarà un passaggio ai SerDes da 100 gigabit e 100 Gbps per lane, poiché molti fornitori prevedono che saranno disponibili a breve. Il periodo in cui i SerDes da 50G sono stati i più veloci sembra non essere molto lungo, poiché i primi esemplari dei 100G verranno lanciati quasi l'anno prossimo. E dopo un po', potrebbero anche diventare disponibili a un prezzo ragionevole.

Un altro aspetto riguardo alla scelta della fisica. In linea di massima, possiamo già applicare porte da 400 o 200 gigabit utilizzando 50G SerDes. Tuttavia, si scopre che non ha molto senso, perché, come ho detto in precedenza, vogliamo un radix sufficientemente grande sugli switch, entro limiti ragionevoli, ovviamente. Ci piacerebbe avere 128. E se la capacità del chip è limitata e aumentiamo la velocità del link, il radix, naturalmente, diminuisce, non ci sono miracoli.
Possiamo aumentare la capacità totale grazie ai piani, senza alcun costo significativo, possiamo aggiungere il numero di piani. Se perdiamo il radix, dovremo introdurre un livello aggiuntivo, quindi, con gli attuali calcoli, e la massima capacità disponibile per un chip, si scopre che è più efficace utilizzare porte da 100 gigabit, perché consentono di ottenere un radix maggiore.

La prossima domanda riguarda come è organizzata la fisica, ma già dal punto di vista dell'infrastruttura cablata. Si scopre che è organizzata in modo piuttosto interessante. Il cablaggio tra gli switch leaf e i spine di primo livello — non ci sono molti collegamenti, è tutto relativamente semplice. Ma se prendiamo un piano, ciò che avviene all'interno — è necessario collegare tutti i spine di primo livello con tutti i spine di secondo livello.
Inoltre, di solito ci sono alcune preferenze su come dovrebbe apparire all'interno del data center. Ad esempio, ci tenevamo molto a raggruppare i cavi in bundle e a farli passare in modo che un'unica patch panel ad alta densità andasse interamente in un'altra patch panel, per evitare un'intreccio di lunghezze. Siamo riusciti a risolvere questo compito. Se inizialmente si guarda alla topologia logica, si vede che i piani sono indipendenti, ogni piano può essere costruito autonomamente. Ma quando aggiungiamo questo bundling e vogliamo tirare completamente una patch panel in un'altra patch panel, dobbiamo mescolare piani diversi all'interno di un unico bundle e introdurre una struttura intermedia sotto forma di cross-connection ottiche, per ripacchettarle da come sono state assemblate su un segmento a come verranno assemblate su un altro segmento. Grazie a questo, otteniamo una piacevole caratteristica: tutta la complessa commutazione non esce dai confini dei rack. Quando è necessario intrecciare molto, "sviluppare i piani", come viene talvolta chiamato nelle reti Clos, tutto è concentrato all'interno di un unico rack. Non abbiamo commutazioni disordinate, fino ai collegamenti individuali, tra i rack.
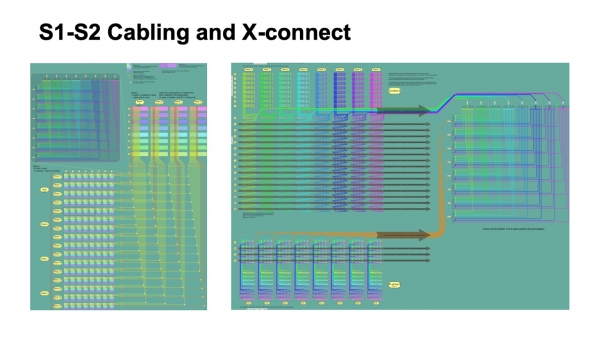
Ecco come si presenta dal punto di vista dell'organizzazione logica dell'infrastruttura cablata. Nell'immagine a sinistra, i blocchi colorati rappresentano i blocchi di spine switch di primo livello, otto in totale, e da questi quattro bundle di cavi che si incrociano con i bundle provenienti dai blocchi di spine-2 switch.
I piccoli quadrati indicano le intersezioni. In alto a sinistra, c'è una rappresentazione di ciascuna intersezione; si tratta effettivamente di un modulo di cross-connect 512 su 512 porte, che riorganizza i cavi in modo da arrivare a occupare completamente un solo rack, dove c'è solo un piano di spine-2. A destra, la rappresentazione di quest'immagine è leggermente più dettagliata riguardo a diversi Pods a livello spine-1, e come viene impacchettato nel cross-connect, e come arriva al livello spine-2.

Ecco come si presenta. Un rack spine-2 non completamente assemblato (a sinistra) e un rack di cross-connect. Sfortunatamente, non c'è molto da vedere. Tutta questa struttura è attualmente in fase di distribuzione in uno dei nostri grandi data center in espansione. È un lavoro in corso, apparirà meglio e sarà riempita più efficacemente.

Una domanda importante: abbiamo scelto una topologia logica e costruito la topologia fisica. Cosa succede al control plane? È ben noto dall'esperienza operativa che ci sono diverse opinioni sul fatto che i protocolli link state siano buoni e facili da usare, ma sfortunatamente in una topologia strettamente connessa hanno problemi di scalabilità. C'è un fattore principale che ne impedisce il funzionamento efficace: il modo in cui funziona il flooding nei protocolli link state. Se prendiamo semplicemente l'algoritmo di flooding e osserviamo la nostra rete, si vede che ad ogni passo ci sarà un fanout molto grande, inondando il control plane di aggiornamenti. In particolare, tali topologie con l'algoritmo di flooding tradizionale nei protocolli link state si mescolano molto male.
La scelta è utilizzare BGP. Come prepararlo correttamente è descritto nella RFC 7938 riguardo all'uso di BGP nei grandi data center. Le idee di base sono semplici: il numero minimo di prefissi per host e, in generale, il numero minimo di prefissi nella rete, utilizzare l'aggregazione, se possibile, e sopprimere la ricerca dei percorsi. Vogliamo una diffusione degli aggiornamenti molto controllata e precisa, ciò che viene chiamato valley free. Vogliamo che gli aggiornamenti, passando attraverso la rete, si espandano esattamente una volta. Se originano in basso, ci si dirigono verso l'alto, espandendosi non più di una volta. Non devono esserci zigzag. Gli zigzag sono molto dannosi.
Per farlo, utilizziamo uno schema piuttosto semplice per sfruttare i meccanismi di base di BGP. Cioè, utilizziamo eBGP, operante su link local, e i sistemi autonomi sono assegnati nel seguente modo: un sistema autonomo sul ToR, un sistema autonomo per l'intero blocco di spine switch-1 di un Pod, e un sistema autonomo generale per l'intero Top of Fabric. Non è difficile vedere e confermare che, in questo modo, anche il normale comportamento di BGP ci fornisce la diffusione degli aggiornamenti che desideriamo.

Naturalmente, è necessario progettare l'indirizzamento e l'aggregazione degli indirizzi in modo che siano compatibili con il modo in cui è costruita la routing, per garantire la stabilità del control plane. L'indirizzamento L3 nel trasporto è legato alla topologia, perché senza di essa non si può ottenere l'aggregazione; senza di essa, gli indirizzi singoli passerebbero nel sistema di routing. E un'altra cosa è che l'aggregazione, sfortunatamente, non si mescola molto bene con il multi-path, perché quando abbiamo il multi-path e l'aggregazione, tutto funziona bene finché l'intera rete è operativa e non ci sono guasti. Sfortunatamente, non appena ci sono guasti nella rete e la simmetria della topologia si perde, possiamo arrivare a un punto dal quale è stato annunciato l'aggregato, da cui non possiamo proseguire dove ci serve. Quindi è meglio aggregare dove non c'è multi-path, nel nostro caso è sugli switch ToR.

In realtà, è possibile aggregare, ma con cautela. Se possiamo effettuare una disaggregazione controllata in caso di guasti nella rete. Tuttavia, si tratta di un compito piuttosto complesso; abbiamo persino valutato se fosse fattibile, se potessimo aggiungere automazione supplementare e stati finali che possano gestire correttamente BGP, per ottenere il comportamento desiderato. Purtroppo, la gestione dei casi limite è molto poco chiara e complicata, e l'integrazione di hardware esterno con BGP non risolve bene questo problema.
È stato fatto un lavoro molto interessante in questo riguardo con il protocollo RIFT, di cui si parlerà nella prossima presentazione.

Un'altra cosa importante è come si scalano i data plane in topologie dense, dove abbiamo un gran numero di percorsi alternativi. In questo caso vengono utilizzate diverse ulteriori strutture dati: i gruppi ECMP, che descrivono a loro volta i gruppi di Next Hop.
In una rete che funziona normalmente, senza interruzioni, quando seguiamo la topologia Clos verso l'alto, è sufficiente utilizzare solo un gruppo, poiché tutto ciò che non è locale è descritto per impostazione predefinita e possiamo procedere verso l'alto. Quando ci dirigiamo verso il basso a sud, tutti i percorsi non sono ECMP, ma sono percorsi singoli. Va tutto bene. Il problema e la peculiarità della classica topologia Clos è che se guardiamo al Top of fabric, per qualsiasi elemento, c'è un solo percorso verso qualsiasi elemento in basso. Se lungo questo percorso si verificano guasti, quell'elemento specifico in cima alla fabbrica diventa non valido proprio per quei prefissi che si trovano dietro il percorso rotto. Tuttavia, per gli altri, è valido, e dobbiamo discutere i gruppi ECMP e introdurre un nuovo stato.
Come appare la scalabilità del data plane sui dispositivi moderni? Se eseguiamo il LPM (longest prefix match), tutto funziona abbastanza bene, con oltre 100.000 prefissi. Se parliamo dei gruppi Next Hop, la situazione è peggiore, con soli 2-4 mila. Se consideriamo la tabella che contiene la descrizione dei Next Hop (o adiacenze), il numero va da 16.000 a 64.000. E questo può diventare un problema. Qui ci avviciniamo a un'interessante digressione: cosa è successo all'MPLS nei data center? Fondamentalmente, volevamo implementarlo.

Sono accadute due cose. Abbiamo effettuato la microsegmentazione sugli host, quindi non era più necessario farlo sulla rete. La compatibilità con i diversi fornitori non era molto buona, tanto meno con le implementazioni aperte sui white boxes con MPLS. Inoltre, l'MPLS, almeno nelle sue implementazioni tradizionali, purtroppo non si combina bene con l'ECMP. Ed ecco perché.
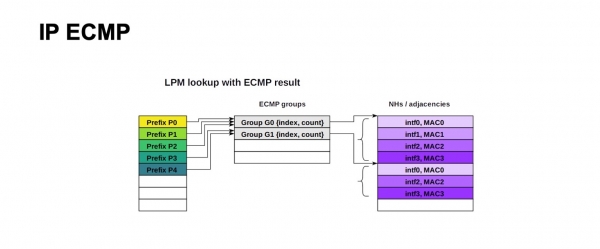
Questa è la struttura del forwarding ECMP per IP. Un gran numero di prefissi può utilizzare lo stesso gruppo e lo stesso blocco di Next Hops (o adiacenze, a seconda della documentazione di vari dispositivi potrebbero essere denominati in modo diverso). Il concetto è che questo viene descritto come porta di uscita e a cosa riscrivere l'indirizzo MAC per raggiungere il corretto Next Hop. Per l'IP, tutto sembra semplice, è possibile utilizzare un numero molto elevato di prefissi per lo stesso gruppo, lo stesso blocco di Next Hops.
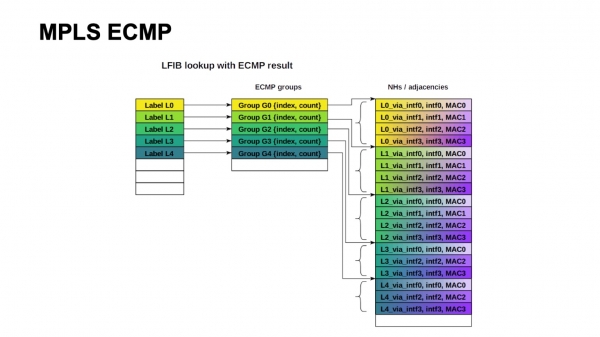
L'architettura classica MPLS implica che, a seconda dell'interfaccia di uscita, il tag può essere riscritto in valori diversi. Pertanto, dobbiamo mantenere un gruppo e un blocco di Next Hops per ogni etichetta in ingresso. E purtroppo questo non scala.
Non è difficile vedere che nella nostra configurazione avevamo bisogno di circa 4000 switch ToR, con una larghezza massima di 64 percorsi ECMP, se ci allontaniamo dallo spina-1 verso spina-2. Ci riusciamo a malapena, siamo al limite, in una tabella di gruppi ECMP, se solo un prefisso con ToR passa, e non entriamo affatto nella tabella Next Hops.

Non è tutto perduto, perché architetture come il Segment Routing implicano etichette globali. Formalmente, si potrebbero riunire nuovamente tutti questi blocchi di Next Hop. Per farlo, è necessaria un'operazione di tipo wild card: prendere un'etichetta e riscriverla con lo stesso valore senza un valore specifico. Sfortunatamente, però, nelle implementazioni disponibili questo non è molto presente.
Infine, dobbiamo portare il traffico esterno nel data center. Come possiamo farlo? In passato, il traffico veniva gestito nelle reti Clos dall'alto. Ciò significa che c'erano router di confine che si collegavano a tutti i dispositivi nella parte superiore della fabric. Questa soluzione funziona piuttosto bene per dimensioni ridotte e medie. Sfortunatamente, per gestire il traffico in modo simmetrico in tutta la rete, è necessario che tutti gli elementi della parte superiore della fabric siano connessi simultaneamente, e quando questi superano il centinaio, ci si rende conto che servono grandi radici anche nei router di confine. In generale, ciò ha un costo, poiché i router di confine sono più funzionali, i loro porti costeranno di più e il risultato finale non è molto elegante.
Un'altra opzione è generare il traffico dal basso. Non è difficile notare che la topologia Clos è progettata in modo che il traffico che arriva dal basso, ovvero dal lato ToR, venga distribuito uniformemente attraverso i livelli su tutto il Top of Fabric in due iterazioni, caricando l'intera rete. Per questo motivo, introduciamo un tipo speciale di Pod, l'Edge Pod, che garantisce la connettività esterna.
C'è un'altra possibilità. Ad esempio, così fa Facebook. Lo chiamano Fabric Aggregator o HGRID. Viene aggiunto un ulteriore livello spine per connettere più data center. Questa struttura è possibile se non abbiamo funzioni aggiuntive o cambi di incapsulamento nei punti di giunzione. Se ci sono, questi sono touch points aggiuntivi, il che rende tutto più complesso. Di solito, sorgono più funzioni e una sorta di membrana che separa le diverse parti del data center. Non conviene rendere questa membrana troppo grande e, se è davvero necessaria, ha senso valutare la possibilità di spostarla, farla il più ampia possibile e trasferirla sugli host. Questo è ciò che fanno, ad esempio, molti operatori cloud. Hanno overlays che iniziano dagli host.

Quali opportunità di sviluppo vediamo? Prima di tutto, un miglioramento del supporto per il pipeline CI/CD. Vogliamo volare come testiamo, e testare come voliamo. Al momento non ci riesce molto bene, poiché l'infrastruttura è grande e duplicarla per i test non è possibile. È necessario comprendere come integrare gli elementi di test nell'infrastruttura operativa senza comprometterla.
Un miglior strumentazione e un monitoraggio ottimale sono sempre utili. La questione riguarda l'equilibrio tra sforzi e risultati. Se è possibile aggiungere in modo ragionevole, è molto positivo.
Sistemi operativi open-source per dispositivi di rete. I migliori protocolli e le migliori sistemi di routing, per esempio RIFT. Sono necessarie anche ricerche sull'applicazione dei migliori schemi di congestion control e, possibilmente, l'introduzione, almeno in alcuni punti, del supporto RDMA all'interno del cluster.
Se si guarda al futuro a lungo termine, sono necessarie topologie avanzate e, possibilmente, reti con minore overhead. Tra le novità recenti, ci sono state pubblicazioni sulla tecnologia delle fabbriche per HPC Cray Slingshot, che si basa su Ethernet commoditizzato, ma con un'opzione per utilizzare intestazioni molto più brevi. Di conseguenza, l'overhead diminuisce.

Tutto dovrebbe essere fatto il più semplice possibile, ma non più semplice. La complessità è il nemico della scalabilità. La semplicità e le strutture regolari sono i nostri amici. Se è possibile fare scale out in qualche modo, fatelo. In generale, è un ottimo momento per lavorare nelle tecnologie di rete. Stanno accadendo molte cose interessanti. Grazie.
Fonte: habr.com
