

Меня зовут Павел Пархоменко, я ML-разработчик. В этой статье я хотел бы рассказать об устройстве сервиса Яндекс.Дзен и поделиться техническими улучшениями, внедрение которых позволило увеличить качество рекомендаций. Из поста вы узнаете, как всего за несколько миллисекунд находить среди миллионов документов наиболее релевантные для пользователя; как делать непрерывное разложение большой матрицы (состоящей из миллионов столбцов и десятков миллионов строк), чтобы новые документы получали свой вектор за десятки минут; как переиспользовать разложение матрицы пользователь-статья, чтобы получить хорошее векторное представление для видео.
Наша рекомендательная база содержит миллионы документов разного формата: текстовые статьи, созданные на нашей платформе и взятые с внешних сайтов, видео, нарративы и короткие посты. Развитие подобного сервиса связано с большим числом технических вызовов. Вот некоторые из них:
- Разделить вычислительные задачи: все тяжелые операции делать в офлайне, а в реальном времени выполнять только быстрое применение моделей, чтобы отвечать за 100-200 мс.
- Быстро учитывать действия пользователя. Для этого необходимо, чтобы все события моментально доставлялись в рекоммендер и влияли на результат работы моделей.
- Сделать ленту такой, чтобы у новых пользователей она быстро подстраивалась под их поведение. Только что пришедшие в систему люди должны ощущать, что их фидбек влияет на рекомендации.
- Быстро понимать, кому порекомендовать новую статью.
- Оперативно реагировать на постоянное появление нового контента. Десятки тысяч статей выходят каждый день, и многие из них имеют ограниченный срок жизни (скажем, новости). В этом их отличие от фильмов, музыки и другого долгоживущего и дорогого для создания контента.
- Переносить знания с одной доменной области на другую. Если в рекомендательной системе есть обученные модели для текстовых статей и мы добавляем в нее видео, можно переиспользовать существующие модели, чтобы контент нового типа лучше ранжировался.
Я расскажу, как мы решали эти задачи.
Отбор кандидатов
Как за несколько миллисекунд сократить множество рассматриваемых документов в тысячи раз, практически не ухудшив качество ранжирования?
Предположим, мы обучили много ML-моделей, сгенерировали на их основе признаки и обучили еще одну модель, которая ранжирует документы для пользователя. Всё бы хорошо, но нельзя просто так взять и посчитать все признаки для всех документов в реальном времени, если этих документов миллионы, а рекомендации нужно строить за 100-200 мс. Задача — выбрать из миллионов некое подмножество, которое и будет ранжироваться для пользователя. Этот этап обычно называют отбором кандидатов. К нему предъявляется несколько требований. Во-первых, отбор должен происходить очень быстро, чтобы на само ранжирование оставалось как можно больше времени. Во-вторых, сильно сократив количество документов для ранжирования, мы должны максимально полно сохранить релевантные для пользователя документы.
Наш принцип отбора кандидатов эволюционно развивался, и на данный момент мы пришли к многоступенчатой схеме:
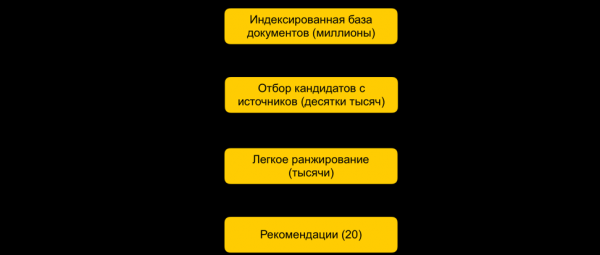
Сначала все документы разбиваются на группы, и из каждой группы берутся самые популярные документы. Группами могут быть сайты, темы, кластеры. Для каждого пользователя на основе его истории подбираются наиболее близкие ему группы и уже из них берутся лучшие документы. Также мы используем kNN-индекс для подбора наиболее близких пользователю документов в реальном времени. Существует несколько методов построения kNN-индекса, у нас лучше всего заработал (Hierarchical Navigable Small World graphs). Это иерархическая модель, позволяющая за несколько миллисекунд находить N ближайших векторов для пользователя из миллионной базы. Предварительно мы в офлайне индексируем всю нашу базу документов. Так как поиск в индексе работает довольно быстро, то при наличии нескольких сильных эмбеддингов можно сделать несколько индексов (по одному индексу на каждый эмбеддинг) и обращаться к каждому из них в реальном времени.
У нас остаются десятки тысяч документов для каждого пользователя. Это по-прежнему много для подсчета всех признаков, так что на этом этапе мы применяем легкое ранжирование — облегченную модель тяжелого ранжирования с меньшим количеством признаков. Задача — предсказать, какие документы будут у тяжелой модели в топе. Документы с наибольшим предиктом будут использованы в тяжелой модели, то есть на последнем этапе ранжирования. Этот подход позволяет за десятки миллисекунд сократить базу рассматриваемых для пользователя документов с миллионов до тысяч.
Шаг ALS в рантайме
Как учитывать фидбек пользователя сразу после клика?
Важный фактор в рекомендациях — время отклика на фидбек пользователя. Это особенно важно для новых пользователей: когда человек только начинает пользоваться рекомендательной системой, он получает неперсонализированную ленту разнообразных по тематике документов. Как только он совершает первый клик, необходимо сразу учесть это и подстроиться под его интересы. Если вычислять все факторы в офлайне, быстрая реакция системы станет невозможной из-за задержки. Так что необходимо в реальном времени обрабатывать действия пользователя. Для этих целей мы используем шаг ALS в рантайме для построения векторного представления пользователя.
Предположим, для всех документов у нас есть векторное представление. К примеру, мы можем в офлайне на основе текста статьи построить эмбеддинги с помощью ELMo, BERT или других моделей машинного обучения. Как можно получить векторное представление пользователей в этом же пространстве на основе их взаимодействия в системе?
Общий принцип формирования и разложения матрицы пользователь-документПусть у нас есть m пользователей и n документов. Для некоторых пользователей известно их отношение к некоторым документам. Тогда эту информацию можно представить в виде матрицы m x n: строки соответствуют пользователям, а столбцы — документам. Поскольку большинство документов человек не видел, то бо́льшая часть клеток матрицы останутся пустыми, а другие будут заполнены. Для каждого события (лайка, дизлайка, клика) в матрице предусмотрено какое-то значение — но рассмотрим упрощенную модель, в которой лайку соответствует 1, а дизлайку –1.
Разложим матрицу на две: P (m x d) и Q (d x n), где d — размерность векторного представления (обычно это небольшое число). Тогда каждому объекту будет соответствовать d-мерный вектор (пользователю — строка в матрице P, документу — столбец в матрице Q). Эти векторы и будут эмбеддингами соответствующих объектов. Чтобы предсказать, понравится ли пользователю документ, можно просто перемножить их эмбеддинги.

Один из возможных способов разложения матрицы — ALS (Alternating Least Squares). Будем оптимизировать следующую функцию потерь:

Здесь rui — взаимодействие пользователя u с документом i, qi — вектор документа i, pu — вектор пользователя u.
Тогда оптимальный с точки зрения среднеквадратической ошибки вектор пользователя (при фиксированных векторах документов) находится аналитически с помощью решения соответствующей линейной регрессии.
Это называется «шаг ALS». А сам алгоритм ALS заключается в том, что мы попеременно фиксируем одну из матриц (пользователей и статей) и обновляем другую, находя оптимальное решение.
К счастью, нахождение векторного представления пользователя — довольно быстрая операция, которую можно делать в рантайме, используя векторные инструкции. Этот трюк позволяет сразу же учитывать фидбек пользователя в ранжировании. Такой же эмбеддинг можно использовать и в kNN-индексе для улучшения отбора кандидатов.
Распределенная коллаборативная фильтрация
Как делать инкрементальную распределенную матричную факторизацию и быстро находить векторное представление новых статей?
Контент — не единственный источник сигналов для рекомендаций. Другим важный источником служит коллаборативная информация. Хорошие признаки в ранжировании традиционно можно получить из разложения матрицы пользователь-документ. Но при попытке сделать такое разложение мы столкнулись с проблемами:
1. У нас миллионы документов и десятки миллионов пользователей. Матрица не помещается на одной машине целиком, и разложение будет очень долгим.
2. У бо́льшей части контента в системе короткое время жизни: документы остаются актуальными лишь несколько часов. Поэтому необходимо как можно быстрее построить их векторное представление.
3. Если строить разложение сразу после публикации документа, его не успеют оценить достаточное число пользователей. Поэтому его векторное представление с большой вероятностью будет не очень хорошим.
4. Если пользователь поставил лайк или дизлайк, мы не сможем сразу же учесть это в разложении.
Чтобы решить перечисленные проблемы, мы реализовали распределенное разложение матрицы пользователь-документ с частым инкрементальным апдейтом. Как именно это работает?
Предположим, у нас есть кластер из N машин (N исчисляется сотнями) и мы хотим сделать на них распределенное разложение матрицы, которая не помещается на одной машине. Вопрос — как выполнить это разложение, чтобы, с одной стороны, на каждой машине было достаточно данных и, с другой, чтобы вычисления были независимыми?
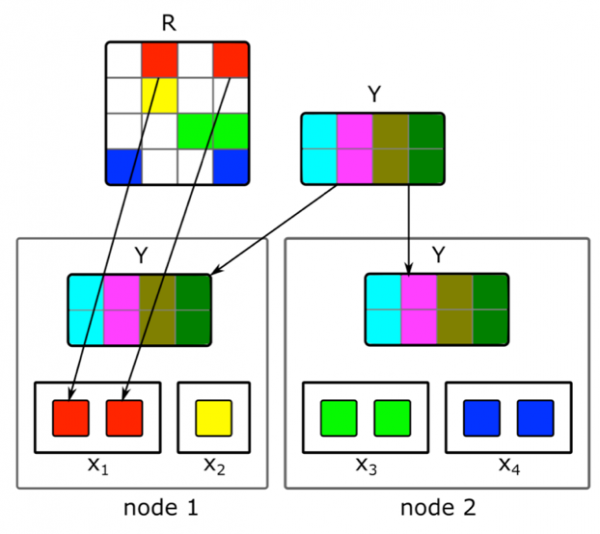
Будем использовать описанный выше алгоритм разложения ALS. Рассмотрим, как распределенно выполнить один шаг ALS — остальные шаги будут похожими. Допустим, у нас зафиксирована матрица документов и мы хотим построить матрицу пользователей. Для этого разобьем ее на N частей по строкам, каждая часть будет содержать примерно одинаковое количество строк. Разошлем на каждую машину непустые ячейки соответствующих строк, а также матрицу эмбеддингов документов (целиком). Так как у нее не очень большой размер, а матрица пользователь-документ обычно сильно разрежена, эти данные поместятся на обычной машине.
Такой трюк можно повторять в течение нескольких эпох до сходимости модели, поочередно меняя фиксированную матрицу. Но даже тогда разложение матрицы может длиться несколько часов. И это не решает проблему того, что нужно быстро получать эмбеддинги новых документов и обновлять эмбеддинги тех из них, о которых было мало информации при построении модели.
Нам помогло внедрение быстрого инкрементального апдейта модели. Предположим, у нас есть текущая обученная модель. С момента ее обучения появились новые статьи, с которыми повзаимодействовали наши пользователи, а также статьи, которые при обучении имели мало взаимодействий. Для быстрого получения эмбеддинга таких статей мы используем эмбеддинги пользователей, полученные во время первого большого обучения модели, и делаем один шаг ALS, чтобы вычислить матрицу документов при фиксированной матрице пользователей. Это позволяет получать эмбеддинги довольно быстро — в течение нескольких минут после публикации документа — и часто обновлять эмбеддинги свежих документов.
Чтобы для рекомендаций сразу учитывались действия человека, в рантайме мы не используем эмбеддинги пользователей, полученные в офлайне. Вместо этого мы делаем шаг ALS и получаем актуальный вектор пользователя.
Перенос на другую доменную область
Как использовать фидбек пользователя к текстовым статьям, чтобы построить векторное представление видео?
Изначально мы рекомендовали только текстовые статьи, поэтому многие наши алгоритмы заточены на этот тип контента. Но при добавлении контента другого типа мы сталкивались с потребностью в адаптации моделей. Как мы решали эту задачу на примере видео? Один из вариантов — переобучить все модели с нуля. Но это долго, к тому же часть алгоритмов требовательны к объему обучающей выборки, которой еще нет в нужном количестве для контента нового типа в первые моменты его жизни на сервисе.
Мы пошли другим путем и переиспользовали модели текстов для видео. В создании векторных представлений видео нам помог все тот же трюк с ALS. Мы взяли векторное представление пользователей на основе текстовых статей и сделали шаг ALS, используя информацию о просмотрах видео. Так мы без труда получили векторное представление видео. А в рантайме мы просто вычисляем близость между вектором пользователя, полученным на основе текстовых статей, и вектором видео.
Conclusione
Разработка ядра реалтаймовой рекомендательной системы сопряжена с множеством задач. Нужно быстро обрабатывать данные и применять ML-методы для эффективного использования этих данных; строить сложные распределенные системы, способные за минимальное время обрабатывать пользовательские сигналы и новые единицы контента; и много других задач.
В текущей системе, устройство которой я описал, качество рекомендаций для пользователя растет вместе с его активностью и длительностью пребывания на сервисе. Но конечно, здесь же кроется и главная сложность: системе тяжело сходу понять интересы человека, который мало взаимодействовал с контентом. Улучшение рекомендаций для новых пользователей — наша ключевая задача. Мы продолжим оптимизировать алгоритмы, чтобы релевантный человеку контент быстрее попадал в его ленту, а нерелевантный не показывался.
Fonte: habr.com
