

Меня зовут Антон Бадерин. Я работаю в Центре Высоких Технологий и занимаюсь системным администрированием. Месяц назад завершилась наша корпоративная конференция, где мы делились накопленным опытом с IT-сообществом нашего города. Я рассказывал про мониторинг веб-приложений. Материал предназначался для уровня junior или middle, которые не выстраивали этот процесс с нуля.

Краеугольный камень, лежащий в основе любой системы мониторинга — решение задач бизнеса. Мониторинг ради мониторинга никому не интересен. А чего хочет бизнес? Чтобы все работало быстро и без ошибок. Бизнес хочет проактивности, чтобы мы сами выявляли проблемы в работе сервиса и максимально быстро их устраняли. Это, по сути, и есть задачи, которые я решал весь прошлый год на проекте одного из наших заказчиков.
О проекте
Проект — одна из крупнейших в стране программ лояльности. Мы помогаем розничным сетям увеличивать частоту продаж за счёт различных маркетинговых инструментов вроде бонусных карт. В общей сложности в проект входят 14 приложений, которые работают на десяти серверах.
В процессе ведения собеседований я неоднократно замечал, что админы далеко не всегда правильно подходят к мониторингу веб-приложений: до сих пор многие останавливаются на метриках операционной системы, изредка мониторят сервисы.
В моём случаем прежде в основе системы мониторинга заказчика лежала Icinga. Она никак не решала указанные выше задачи. Часто клиент сам сообщал нам о проблемах и не реже нам просто не хватало данных, чтобы докопаться до причины.
Кроме того, было чёткое понимание бесперспективности её дальнейшего развития. Я думаю, те кто знаком с Icinga меня поймут. Итак, мы решили полностью переработать систему мониторинга веб-приложений на проекте.
Prometheus
Мы выбрали Prometheus, исходя из трех основных показателей:
- Огромное количество доступных метрик. В нашем случае их 60 тысяч. Конечно, стоит отметить, что подавляющее большинство из них мы не используем (наверно, около 95%). С другой стороны, они все относительно дешевы. Для нас эта другая крайность, по сравнению с ранее использовавшейся Icinga. В ней добавление метрик доставляло особую боль: имеющиеся доставались дорого (достаточно посмотреть на исходники любого плагина). Любой плагин представлял собой скрипт на Bash или Python, запуск которых недешёвый с точки зрения потребляемых ресурсов.
- Эта система потребляет относительно небольшое количество ресурсов. На все наши метрики хватает 600 Мб оперативной памяти, 15% одного ядра и пару десятков IOPS. Конечно, приходится запускать экспортёры метрик, но все они написаны на Go и тоже не отличаются прожорливостью. Не думаю, что в современных реалиях это проблема.
- Даёт возможность перехода в Kubernetes. Учитывая планы заказчика — выбор очевиден.
ELK
Ранее мы логи не собирали и не обрабатывали. Недостатки ясны всем. Мы выбрали ELK, поскольку опыт работы с этой системой у нас уже был. Храним там только логи приложений. Основными критериями выбора стали полнотекстовый поиск и его скорость.
Сlickhouse
Изначально выбор пал на InfluxDB. Мы осознавали необходимость сбора логов Nginx, статистики из pg_stat_statements, хранения исторических данных Prometheus. Influx нам не понравился, так как он периодически начинал потреблять большое количество памяти и падал. Кроме того, хотелось группировать запросы по remote_addr, а группировка в этой СУБД только по тэгам. Тэги дороги (память), их количество условно ограничено.
Мы начали поиски заново. Нужна была аналитическая база с минимальным потреблением ресурсов, желательно со сжатием данных на диске.
Clickhouse удовлетворяет всем этим критериям, и о выборе мы ни разу не пожалели. Мы не пишем в него каких-то выдающихся объёмов данных (количество вставок всего около пяти тысяч в минуту).
NewRelic
NewRelic исторически был с нами, так как это был выбор заказчика. У нас он используется в качестве APM.
Zabbix
Мы используем Zabbix исключительно для мониторинга Black Box различных API.
Определение подхода к мониторингу
Нам хотелось декомпозировать задачу и тем самым систематизировать подход к мониторингу.
Для этого я разделил нашу систему на следующие уровни:
- «железо» и VMS;
- операционная система;
- системные сервисы, стек ПО;
- приложение;
- бизнес-логика.
Чем удобен такой подход:
- мы знаем, кто ответственен за работу каждого из уровней и, исходя из этого, можем высылать алертов;
- мы можем использовать структуру при подавлении алертов — было бы странно отсылать алерт о недоступности базы данных, когда в целом виртуальная машина недоступна.
Так как наша задача выявлять нарушения в работе системы, мы должны на каждом уровне выделить некий набор метрик, на которые стоит обращать внимание при написании правил алертинга. Далее пройдемся по уровням «VMS», «Операционная система» и «Системные сервисы, стек ПО».
Macchine virtuali
Hosting выделяет нам процессор, диск, память и сеть. И с первыми двумя у нас были проблемы. Итак, метрики:
CPU stolen time — когда вы покупаете виртуалку на Amazon (t2.micro, к примеру), следует понимать, что вам выделяется не целое ядро процессора, а лишь квота его времени. И когда вы её исчерпаете, процессор у вас начнут забирать.
Эта метрика позволяет отслеживать такие моменты и принимать решения. Например, надо ли взять тариф пожирнее или разнести обработку фоновых задач и запросов в API на разные server.
IOPS + CPU iowait time — почему-то многие облачные хостинги грешат тем, что недодают IOPS. Более того, график с низкими IOPS для них не аргумент. Поэтому стоит собирать и CPU iowait. С этой парой графиков — с низкими IOPS и высоким ожиданием ввода-вывода — уже можно разговаривать с хостингом и решать проблему.
Il sistema operativo
Метрики операционной системы:
- количество доступной памяти в %;
- активность использования swap: vmstat swapin, swapout;
- количество доступных inode и свободного места на файловой системе в %
- средняя загрузка;
- количество соединений в состоянии tw;
- заполненность таблицы conntrack;
- качество работы сети можно мониторить с помощью утилиты ss, пакетом iproute2 — получать из её вывода показатель RTT-соединений и группировать по dest-порту.
Также на уровне операционной системы у нас появляется такая сущность, как процессы. Важно выделить в системе набор процессов, которые играют важную роль в её работе. Если, к примеру, у вас есть несколько pgpool, то необходимо собирать информацию по каждому из них.
Набор метрик следующий:
- CPU;
- память — в первую очередь, резидентная;
- IO — желательно в IOPS;
- FileFd — открытые и лимит;
- существенные отказы страницы — так вы сможете понять, какой процесс свапается.
Весь мониторинг у нас развернут в Docker, для сбора данных метрик мы используем Сadvisor. На остальных машинах применяем process-exporter.
Системные сервисы, стек ПО
У каждого приложения есть своя специфика, и сложно выделить какой-то набор метрик.
Универсальным набором являются:
- рейт запросов;
- количество ошибок;
- латентность;
- saturation.
Наиболее яркие примеры мониторинга данного уровня у нас — Nginx и PostgreSQL.
Самый нагруженный сервис в нашей системе — база данных. Раньше у нас достаточно часто возникали проблемы с тем, чтобы выяснить, чем занимается база данных.
Мы видели высокую нагрузку на диски, но слоулоги ничего толком не показывали. Эту проблему мы решили с помощью pg_stat_statements, представления, в котором собирается статистика по запросам.
Это всё, что нужно админу.
Строим графики активности запросов на чтение и запись:
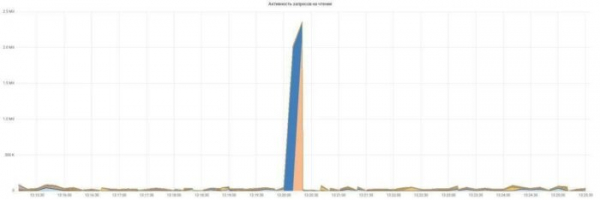
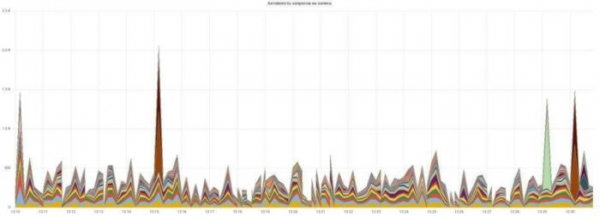
Всё просто и понятно, каждому запросу — свой цвет.
Не менее яркий пример — Nginx-логи. Не удивительно, что мало кто их парсит или упоминает в списке обязательных. Стандартный формат не очень информативен и его нужно расширять.
Лично я добавил request_time, upstream_response_time, body_bytes_sent, request_length, request_id.Строим графики времени ответа и количества ошибок:
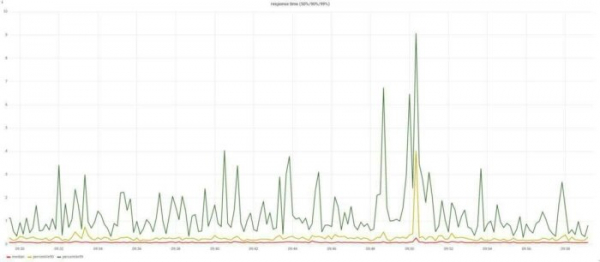
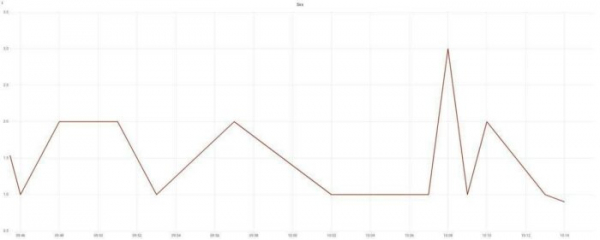
Строим графики времени ответа и количества ошибок. Помните? я говорил про задачи бизнеса? Чтоб быстро и без ошибок? Мы уже двумя графиками эти вопросы закрыли. И по ним уже можно звонить дежурным админам.
Но осталась ещё одна проблема — обеспечить быстрое устранение причин инцидента.
Устранение инцидентов
Весь процесс от выявления до решения проблемы можно разбить на ряд шагов:
- выявление проблемы;
- уведомление дежурного администратора;
- реакция на инцидент;
- устранение причин.
Важно, что мы должны это делать максимально быстро. И если на этапах выявления проблемы и отправки уведомления мы особо времени выиграть не можем — две минуты на них уйдут в любом случае, то последующие — просто непаханное поле для улучшений.
Давайте просто представим, что у дежурного зазвонил телефон. Что он будет делать? Искать ответы на вопросы — что сломалось, где сломалось, как реагировать? Вот каким образом мы отвечаем на эти вопросы:
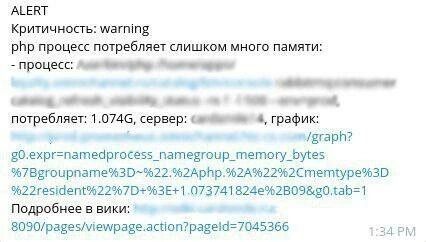
Мы просто включаем всю эту информацию в текст уведомления, даем в нем ссылку на страницу в вики, где описано, как на эту проблему реагировать, как её решать и эскалировать.
Я до сих пор ничего не сказал про уровень приложения и бизнес логики. К сожалению, в наших приложениях пока не реализован сбор метрик. Единственный источник хоть какой то информации с этих уровней — логи.
Пара моментов.
Во-первых, пишите структурированные логи. Не надо включать контекст в текст сообщения. Это затрудняет их группировку и анализ. Logstash требует много времени, чтобы всё это нормализовать.
Во-вторых, правильно используйте severity-уровни. У каждого языка свой стандарт. Лично я выделяю четыре уровня:
- ошибки нет;
- ошибка на стороне клиента;
- ошибка на нашей стороне, не теряем денег, не несём риски;
- ошибка на нашей стороне, теряем деньги.
Резюмирую. Нужно стараться выстраивать мониторинг именно от бизнес-логики. Стараться замониторить само приложение и оперировать уже такими метриками, как количество продаж, количество новых регистраций пользователей, количество активных в данный момент пользователей и так далее.
Если весь ваш бизнес — одна кнопка в браузере, необходимо мониторить, прожимается ли она, работает ли должным образом. Всё остальное не важно.
Если у вас этого нет, вы можете попытаться это наверстать в логах приложения, Nginx-логах и так далее, как это сделали мы. Вы должны быть как можно ближе к приложению.
Метрики операционной системы конечно же важны, но бизнесу они не интересны, нам платят не за них.
Fonte: habr.com
