


Negli ultimi anni, i database di serie temporali (Time-series databases) sono passati da una curiosità (applicata specificamente nei sistemi di monitoraggio aperti e legata a soluzioni specifiche, o nei progetti di Big Data) a un "bene di consumo comune". In Russia, un particolare ringraziamento va a Yandex e ClickHouse. Prima di questo momento, se avevi bisogno di memorizzare una grande quantità di dati di serie temporali, dovevi accontentarti di dover gestire un imponente stack Hadoop e mantenerlo, oppure interagire con protocolli specifici per ogni sistema.
Potrebbe sembrare che nel 2019 un articolo su quale TSDB utilizzare consisterà in una sola frase: "usa semplicemente ClickHouse". Ma... ci sono delle complessità.
In effetti, ClickHouse si sta sviluppando attivamente, la base utenti sta crescendo e il supporto è molto attivo, ma non siamo diventati prigionieri del successo pubblico di ClickHouse, che ha oscurato altri possibili soluzioni più efficienti/affidabili?
All'inizio dell'anno scorso, ci siamo dedicati alla riprogettazione del nostro sistema di monitoraggio. Durante questo processo, è emersa la questione della scelta della base adatta per la memorizzazione dei dati. Qui voglio raccontare la storia di quella scelta.
Definizione del compito
Prima di tutto, è necessario un'introduzione. Perché abbiamo bisogno di un sistema di monitoraggio e come era strutturato?
Abbiamo iniziato a offrire servizi di supporto nel 2008 e nel 2010 è diventato chiaro che aggregare i dati sui processi all'interno delle infrastrutture dei clienti utilizzando le soluzioni disponibili all'epoca era diventato complicato (parliamo di, per non dire altro, Cacti, Zabbix e il nascente Graphite).
I nostri requisiti principali erano:
- gestire (all'epoca decine, e in futuro centinaia) di clienti all'interno di un unico sistema e allo stesso tempo avere un sistema di gestione degli avvisi centralizzato;
- flessibilità nella gestione del sistema di avvisi (escalation degli avvisi tra i custodi, gestione del calendario, base di conoscenza);
- possibilità di avere un’analisi approfondita dei grafici (Zabbix all'epoca disegnava i grafici come immagini);
- archiviazione a lungo termine di grandi volumi di dati (un anno o più) e possibilità di un rapido recupero.
In questo articolo ci interessa l'ultimo punto.
Parlando di archiviazione, i requisiti erano i seguenti:
- il sistema deve lavorare rapidamente;
- è preferibile che il sistema abbia un'interfaccia SQL;
- il sistema deve essere stabile e avere una base utenti attiva e supporto (ci siamo già trovati ad affrontare la necessità di mantenere sistemi come MemcacheDB, che non vengono più sviluppati, o lo storage distribuito MooseFS, il cui tracker di bug era gestito in cinese: non volevamo ripetere questa storia per il nostro progetto);
- rispettare il teorema CAP: Consistency (necessario) - i dati devono essere aggiornati, non vogliamo che il sistema di gestione delle notifiche non riceva nuovi dati e continui a inviare allerta per l'assenza di dati su tutti i progetti; Partition Tolerance (necessario) - non vogliamo generare un sistema Split Brain; Availability (non critico, in caso di esistenza di una replica attiva) - possiamo passare al sistema di riserva in caso di emergenza, tramite codice.
Stranamente, in quel momento la soluzione ideale per noi si rivelò essere MySQL. La nostra struttura dati era estremamente semplice: id del server, id del contatore, timestamp e valore; un'estrazione veloce dei dati correnti era garantita da una grande dimensione del buffer pool, mentre l'estrazione dei dati storici avveniva tramite SSD.
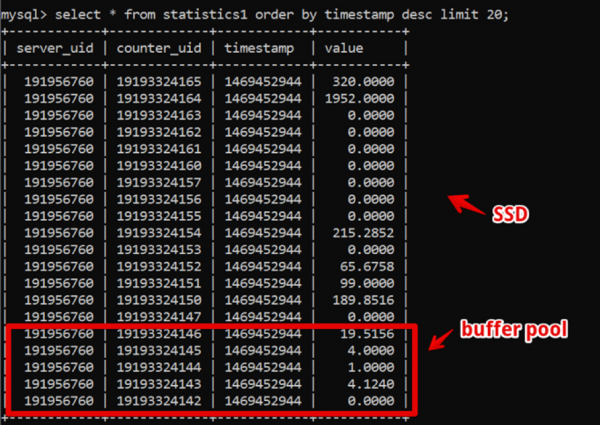
Così siamo riusciti ad estrarre dati freschi di due settimane, con una risoluzione fino al secondo, in 200 ms prima del completo rendering dei dati, e abbiamo vissuto in questo sistema per un lungo periodo.
Nel frattempo, il tempo passava e la quantità di dati aumentava. Entro il 2016, i volumi di dati raggiungevano decine di terabyte, il che rappresentava una spesa significativa considerando gli SSD affittati.
A questo punto, i database colonne avevano iniziato a diffondersi, e cominciammo a considerarli attivamente: nei database colonne i dati sono memorizzati, come si può intuire, in colonne, e se guardiamo ai nostri dati, è facile notare un grande numero di duplicati che potrebbero essere compressi, nel caso si utilizzasse un database colonne.
Tuttavia, il sistema chiave per il funzionamento dell'azienda continuava a funzionare stabilmente, e non volevamo sperimentare il passaggio a qualcos'altro.
Nel 2017, durante la conferenza Percona Live a San José, gli sviluppatori di Clickhouse si sono fatti conoscere per la prima volta. A prima vista, il sistema sembrava pronto per la produzione (d'altronde, Yandex.Metrica è un vero sistema di produzione), il supporto era rapido e semplice, e, soprattutto, la gestione era agevole. Dal 2018 abbiamo avviato il processo di migrazione. Ma nel frattempo erano comparsi molti sistemi TSDB 'maturi' e consolidati, e abbiamo deciso di dedicare un tempo significativo per confrontare le alternative, per assicurarci che non ci fossero soluzioni alternative a Clickhouse che soddisfacessero i nostri requisiti.
In aggiunta ai requisiti già indicati per il database, sono emersi requisiti freschi:
- il nuovo sistema deve garantire almeno le stesse prestazioni di MySQL, con la stessa quantità di hardware;
- il database del nuovo sistema deve occupare significativamente meno spazio;
- il DBMS deve continuare a essere semplice da gestire;
- si voleva modificare il meno possibile l'applicazione durante il cambio del DBMS.
Quali sistemi abbiamo iniziato a considerare
Apache Hive/Apache Impala
Un vecchio e collaudato stack Hadoop. In sostanza, è un'interfaccia SQL costruita sopra lo storage dei dati nei propri formati su HDFS.
Vantaggi.
- Con un funzionamento stabile, è molto facile scalare i dati.
- Esistono soluzioni column-oriented per l'archiviazione dei dati (occupano meno spazio).
- Esecuzione molto rapida di task parallelizzati, se si dispone delle risorse.
Contro.
- Questo è Hadoop, ed è complesso da gestire. Se non siamo pronti a prendere una soluzione pronta nel cloud (e non lo siamo per i costi), l'intero stack dovrà essere assemblato e mantenuto dai sistemisti, e questo è qualcosa che si vorrebbe evitare.
- I dati vengono aggregati .
Tuttavia:

La velocità si ottiene aumentando il numero di server di calcolo. In altre parole, se siamo una grande azienda, ci occupiamo di analisi e per il nostro business è cruciale aggregare le informazioni nel minor tempo possibile (anche a costo di utilizzare un gran numero di risorse di calcolo), questo potrebbe essere la nostra scelta. Ma non eravamo pronti a moltiplicare il parco hardware per aumentare la velocità di esecuzione delle operazioni.
Druid/Pinot
Già molto di più su TSDB specificamente, ma ancora una volta — stack Hadoop.
Sì .
In poche parole: Druid/Pinot sembrano migliori rispetto a Clickhouse nei casi in cui:
- Hai un carattere eterogeneo dei dati (nel nostro caso registriamo solo le serie temporali delle metriche del server e, di fatto, si tratta di una sola tabella. Ma potrebbero esserci altri casi: serie temporali delle apparecchiature, serie temporali economiche, ecc. — ciascuna con la propria struttura, che devono essere aggregate e trattate).
- In questo caso, ci sono davvero molti dati.
- Le tabelle e i dati delle serie temporali appaiono e scompaiono (cioè un certo insieme di dati arriva, viene analizzato e poi eliminato).
- Non esiste un chiaro criterio secondo il quale i dati possono essere partizionati.
Nei casi opposti, ClickHouse si dimostra superiore, e questo è il nostro caso.
ClickHouse
- Simile a SQL.
- Facile da gestire.
- La gente dice che funziona.
Rientra nella short list per i test.
InfluxDB
Alternativa estera a ClickHouse. Tra i contro: l'alta disponibilità è presente solo nella versione commerciale, ma va confrontata.
Rientra nella short list per i test.
Cassandra
Da un lato, sappiamo che viene utilizzato per memorizzare serie temporali metriche in sistemi di monitoraggio come, ad esempio, o OkMeter. Tuttavia, ci sono specificità.
Cassandra non è un database a colonne nel senso tradizionale del termine. Sembra più un database a righe, ma in ogni riga può esserci un numero variabile di colonne, il che consente di organizzare facilmente una rappresentazione a colonne. In questo senso, è chiaro che con un limite di 2 miliardi di colonne si possono memorizzare alcuni dati specificamente in colonne (come le serie temporali). Ad esempio, in MySQL c'è un limite di 4096 colonne e si rischia facilmente di imbattersi in un errore con codice 1117 se si tenta di fare la stessa cosa.
Il motore di Cassandra è progettato per la gestione di grandi volumi di dati in un sistema distribuito senza master, e nella suddetta teoria CAP Cassandra è più orientata verso l'AP, cioè verso la disponibilità dei dati e la resilienza alla partizione. Pertanto, questo strumento può essere molto utile se è necessario scrivere frequentemente nel database e leggere solo raramente. In questo caso, è logico utilizzare Cassandra come archivio “freddo”. Si tratta di uno spazio di archiviazione affidabile e a lungo termine per grandi quantità di dati storici, che vengono richiesti raramente, ma che possono essere recuperati se necessario. Tuttavia, per completezza, la testeremo. Ma, come ho già detto, non c'è voglia di riscrivere attivamente il codice per l'opzione DB scelta, quindi la testeremo in modo limitato — senza adattare la struttura del database alle specifiche di Cassandra.
Prometheus
E, per curiosità, abbiamo deciso di testare le prestazioni del data store Prometheus — semplicemente per capire se è più veloce delle soluzioni attuali o più lento, e quanto.
Metodologia e risultati del test
Abbiamo testato 5 database nelle seguenti 6 configurazioni: ClickHouse (1 nodo), ClickHouse (tabella distribuita su 3 nodi), InfluxDB, Mysql 8, Cassandra (3 nodi) e Prometheus. Il piano di test è il seguente:
- carichiamo i dati storici di una settimana (840 milioni di valori al giorno; 208 mila metriche);
- generiamo un carico di scrittura (abbiamo considerato 6 modalità di carico, vedi sotto);
- parallelamente alla scrittura, estraiamo campioni periodicamente, emulando le richieste di un utente che lavora con i grafici. Per non rendere troppo complesso, abbiamo scelto dati su 10 metriche (esattamente quante ce ne sono nel grafico CPU) per una settimana.
Carichiamo, emulando il comportamento dell'agente del nostro monitoraggio, che invia valori a ciascuna metrica ogni 15 secondi. In questo caso vogliamo variare:
- il numero totale di metriche in cui vengono scritti i dati;
- l'intervallo di invio dei valori a una metrica;
- la dimensione del batch.
Riguardo alla dimensione del batch. Poiché quasi tutti i nostri database sperimentali non sono raccomandati per carichi con singoli inserti, avremo bisogno di un relay che raccoglie le metriche in arrivo e le raggruppa, scrivendole nel database tramite un inserimento in batch.
Inoltre, per comprendere meglio come interpretare successivamente i dati ottenuti, immaginiamo di non inviare semplicemente un insieme di metriche, ma metriche organizzate in server — con 125 metriche per server. Qui il server è un'entità virtuale — giusto per capire che, ad esempio, 10.000 metriche corrispondono a circa 80 server.
Ecco quindi i nostri 6 modi di carico del database per la scrittura:
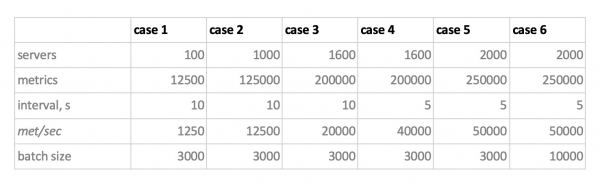
Ci sono due aspetti da considerare. In primo luogo, per Cassandra, queste dimensioni dei batch si sono rivelate troppo grandi, lì abbiamo utilizzato valori di 50 o 100. In secondo luogo, poiché Prometheus funziona esclusivamente in modalità pull, ovvero estrae autonomamente i dati dalle fonti metriche (e anche il pushgateway, nonostante il nome, non cambia la situazione), i carichi corrispondenti sono stati realizzati tramite una combinazione di static configs.
I risultati dei test sono i seguenti:
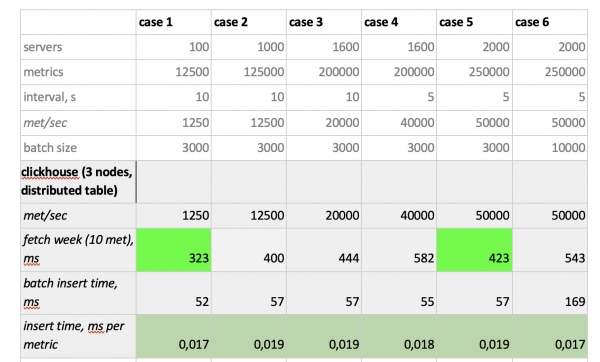
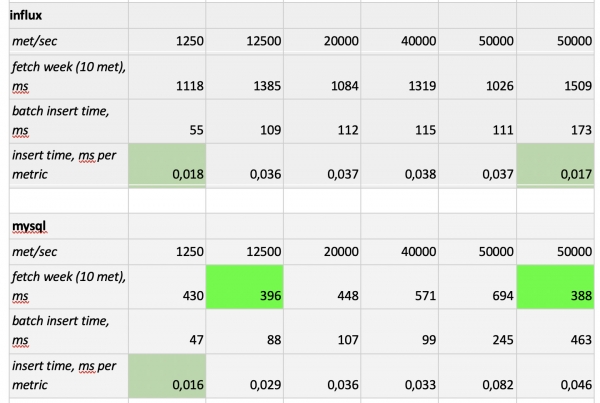
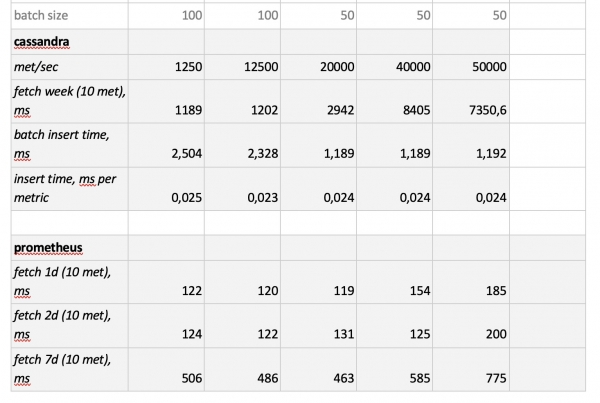
Vale la pena notare: estrazioni estremamente veloci da Prometheus, estrazioni terribilmente lente da Cassandra, estrazioni inaccettabilmente lente da InfluxDB; per quanto riguarda la velocità di scrittura, ClickHouse ha prevalso su tutti, mentre Prometheus non partecipa alla competizione, poiché esegue le inserzioni al suo interno e noi non misuriamo nulla.
In conclusione: ClickHouse e InfluxDB si sono distinti al meglio, ma un cluster di Influx può essere costruito solo sulla versione Enterprise, che ha un costo, mentre ClickHouse è gratuito ed è sviluppato in Russia. È logico che negli Stati Uniti la scelta ricada probabilmente su InfluxDB, mentre da noi si preferisca ClickHouse.
Fonte: habr.com
