

Ciao! Mi chiamo Alexey P'yankov e sono uno sviluppatore per l'azienda Sportmaster. In questo ho raccontato come è iniziato il lavoro sul sito di Sportmaster nel 2012, quali iniziative siamo riusciti a "spingere" e, al contrario, quali difficoltà abbiamo affrontato.
Oggi voglio condividere alcune riflessioni che seguono un'altra trama: la scelta del sistema di caching per il backend Java nell'amministratore del sito. Questo tema ha un significato speciale per me: sebbene la storia si sia sviluppata in soli 2 mesi, in questi 60 giorni abbiamo lavorato 12-16 ore al giorno senza un giorno di riposo. Non avevo mai pensato né immaginato di poter lavorare così tanto.
Pertanto, dividerò il testo in 2 parti per non sovraccaricare. Anzi, la prima parte sarà molto leggera: una preparazione, un'introduzione, alcune riflessioni su cosa sia il caching. Se siete già sviluppatori esperti o avete lavorato con i cache, dal punto di vista tecnico probabilmente non troverete nulla di nuovo in questo articolo. Ma per un junior, una piccola panoramica del genere potrebbe suggerire in quale direzione orientarsi, qualora si trovasse a un bivio del genere.
Quando la nuova versione del sito di Sportmaster è stata lanciata in produzione, i dati venivano forniti in un modo, per così dire, non molto conveniente. Erano utilizzate tabelle preparate per la versione precedente del sito (Bitrix), che dovevano essere integrate in ETL, ristrutturate e arricchite con vari dettagli provenienti da una decina di sistemi. Per far sì che una nuova immagine o una descrizione del prodotto apparissero sul sito, bisognava aspettare fino al giorno dopo — l'aggiornamento avveniva solo di notte, una volta al giorno.
All'inizio c'erano così tante preoccupazioni nelle prime settimane di lancio in produzione che tali disagi per i content manager erano un dettaglio trascurabile. Ma, non appena tutto si è stabilizzato, lo sviluppo del progetto è continuato — dopo alcuni mesi, all'inizio del 2015, abbiamo iniziato a sviluppare attivamente il pannello di amministrazione. Nel 2015 e 2016 tutto andava bene, pubblicavamo regolarmente, il pannello di amministrazione copriva una parte sempre maggiore della preparazione dei dati e ci preparavamo a ciò che presto sarebbe stato affidato al nostro team: la gestione completa dei prodotti (preparazione e monitoraggio dei dati su tutti i prodotti). Ma nell'estate del 2017, proprio prima del lancio della gestione dei prodotti, il progetto si trovò in una situazione molto difficile — proprio a causa di problemi di caching. Questo episodio è quello di cui voglio parlare nella seconda parte di questa pubblicazione in due serie.
Ma in questo post voglio partire da lontano, riassumendo alcune riflessioni — idee sul caching, che sarebbe stato utile approfondire prima di avviare un grande progetto.
Quando si presenta la necessità di caching
Il problema della cache non si presenta da solo. Noi siamo sviluppatori, creiamo un prodotto software e desideriamo che sia richiesto. Se il prodotto è richiesto e ha successo, gli utenti arrivano. E arrivano ancora e ancora. E così, ci sono molti utenti e il prodotto diventa ad alta capacità di carico.
Nelle fasi iniziali non pensiamo all'ottimizzazione e alle prestazioni del codice. La cosa più importante è la funzionalità, lanciare rapidamente un prototipo e testare le ipotesi. E se il carico aumenta, potenziamo l'hardware. Aumentiamo di due, tre, cinque, lasciate che sia dieci volte. A un certo punto, le finanze non lo permetteranno più. E di quanto aumenterà il numero di utenti? Non sarà solo 2-5-10, ma nel caso di successo, sarà da 100-1000 fino a 100.000 volte. Quindi, prima o poi, dovremo affrontare l'ottimizzazione.
Supponiamo che una parte di codice (chiamiamola funzione) stia impiegando un tempo incredibilmente lungo per l'esecuzione e vogliamo ridurre il tempo necessario. La funzione può essere un accesso a un database, un’esecuzione di una logica complessa: l'importante è che sia quello a risultare lungo. Di quanto possiamo ridurre il tempo di esecuzione? Teoricamente, fino a zero, non oltre. Ma come possiamo ridurre il tempo di esecuzione a zero? Risposta: eliminando completamente l'esecuzione. Invece, restituiamo immediatamente il risultato. Ma come possiamo sapere qual è il risultato? Risposta: o calcolandolo o osservandolo da qualche parte. Calcolarlo richiede tempo. E osservarlo significa, ad esempio, ricordare il risultato fornito dalla funzione l'ultima volta che è stata chiamata con gli stessi parametri.
Cioè, l'implementazione della funzione non è importante per noi. È sufficiente sapere da quali parametri dipende il risultato. Allora, se i valori dei parametri vengono presentati come un oggetto che può essere utilizzato come chiave in un certo archivio, possiamo salvare il risultato del calcolo e al prossimo accesso leggerlo. Se queste operazioni di scrittura e lettura del risultato avvengono più rapidamente dell'esecuzione della funzione, abbiamo un guadagno in termini di velocità. L'entità del guadagno può arrivare a 100, 1000, e anche 100.000 volte (10^5 è più un'eccezione, ma nel caso di un database che lagga significativamente, è del tutto possibile).
Requisiti principali per il sistema di caching
La prima cosa che può diventare un requisito per il sistema di caching è la rapida velocità di lettura e, in misura leggermente minore, la velocità di scrittura. È vero, ma solo fino a quando non distribuiamo il sistema in produzione.
Giocando un caso come questo.
Supponiamo di aver attrezzato l'hardware per il carico attuale e ora stiamo gradualmente implementando la cache. Il numero di utenti cresce lentamente, aumentando il carico: aggiungiamo un po' di cache qui e là. Questo continua per un certo periodo, e ora le funzioni pesanti praticamente non vengono più chiamate: tutto il carico principale ricade sulla cache. Durante questo tempo, il numero di utenti è aumentato di N volte.
E se l'approvvigionamento iniziale dell'hardware poteva essere 2-5 volte, grazie alla cache possiamo aumentare le prestazioni fino a 10 volte o, nei migliori casi, anche 100 volte, a volte, forse anche 1000. Cioè, con lo stesso hardware, gestiamo 100 volte più richieste. Fantastico, meritato un premio!
Ma ora, a un certo punto, per caso, il sistema ha subito un guasto e la cache è crollata. Niente di particolare: infatti, la cache è stata scelta con la richiesta di 'alta velocità di lettura e scrittura, il resto non importa'.
Rispetto al carico di avvio, la nostra capacità hardware era 2-5 volte superiore, mentre nel frattempo il carico è aumentato di 10-100 volte. Con la cache abbiamo evitato le chiamate per le funzioni pesanti e quindi tutto funzionava senza problemi. Ora, senza cache, di quanto si ridurrà il nostro sistema? Cosa succederà? Il sistema va in crash.
Anche se la nostra cache non è crollata, ma si è solo svuotata temporaneamente, sarà necessario riscaldarla, e questo richiederà un certo tempo. Durante questo periodo, il carico principale ricadrà sulle funzionalità.
Conclusione: i progetti a elevato carico in produzione richiedono dal sistema di caching non solo un'elevata velocità di lettura e scrittura, ma anche integrità dei dati e resilienza ai guasti.
Il tormento della scelta
Nel progetto con l'interfaccia di amministrazione, la scelta è stata la seguente: inizialmente abbiamo implementato Hazelcast, poiché eravamo già familiari con questo prodotto grazie all'esperienza del sito principale. Tuttavia, questa scelta si è rivelata infelice: per il nostro profilo di carico, Hazelcast non solo funziona lentamente, ma è incredibilmente lento. E per i tempi di rilascio in produzione, a quel punto avevamo già firmato.
Spoiler: vi racconterò nella seconda parte come si sono svolti gli eventi che ci hanno portato a perdere una tale opportunità e come ci siamo ritrovati in una situazione difficile e tesa – e come ne siamo usciti. Ma per ora dirò solo che è stato un grande stress, e 'pensare – non si riesce a pensare, scuotiamo la bottiglia'. 'Scuotiamo la bottiglia' è anche uno spoiler, di questo parlerò più avanti.
Cosa abbiamo fatto:
- Abbiamo stilato un elenco di tutti i sistemi suggeriti da Google e StackOverflow. Un po' più di 30.
- Scriviamo test con un carico tipico per l'ambiente di produzione. Per questo abbiamo registrato dati che passano attraverso il sistema in un ambiente di produzione — una sorta di sniffer per dati non in rete, ma all'interno del sistema. Nei test abbiamo utilizzato proprio questi dati.
- Tutta la squadra, ognuno sceglie il prossimo sistema dall'elenco, lo configura, esegue i test. Se il test non va a buon fine, non regge il carico – lo scartiamo e passiamo al successivo in coda.
- Alla 17ª sistemazione è diventato chiaro che tutto era senza speranza. Basta 'scuotere la bottiglia', è tempo di pensare seriamente.
Questa è l'opzione quando si deve scegliere un sistema che «eccelle in velocità» nei test preparati. Ma se non ci sono ancora test e si desidera scegliere qualcosa di più veloce?
Immaginiamo un tale scenario (è difficile pensare che uno sviluppatore di livello intermedio viva in un vacuum, e al momento della scelta non abbia già espresso una preferenza su quale prodotto provare per primo — quindi, le riflessioni successive sono più teoriche/filosofiche/riguardanti un junior).
Dopo aver definito i requisiti, cominciamo a scegliere una soluzione out-of-the-box. Perché reinventare la ruota: andremo a prendere un sistema di caching già pronto.
Se stai appena cominciando a cercare su Google, avrai un'idea generale dell'ordine, ma in sostanza, i riferimenti saranno questi. Per prima cosa, ti imbatterai in Redis, che è molto noto. Poi scoprirai che esiste EhCache, come il sistema più longevo e collaudato. Successivamente si parlerà di Tarantool — una soluzione nazionale con un aspetto unico. E ci sarà anche Ignite, poiché attualmente sta guadagnando popolarità e gode del supporto di SberTech. Infine, Hazelcast, poiché nel mondo enterprise spesso appare tra le grandi aziende.
Questo elenco non è esaustivo, esistono decine di sistemi. Ne prenderemo solo uno. Selezioniamo 5 sistemi per un "concorso di bellezza" e procederemo con la selezione. Chi sarà il vincitore?
Redis
Leggiamo cosa scrivono sul sito ufficiale.
— progetto open-source. Offre uno storage dei dati in memoria, la possibilità di salvataggio su disco, partizionamento automatico, alta disponibilità e ripristino dopo interruzioni di rete.
Sembra tutto fantastico, possiamo prenderlo e integrarlo — fa tutto ciò di cui hai bisogno. Ma daremo un'occhiata anche agli altri candidati, per curiosità.
EhCache
— "il cache più ampiamente utilizzato per Java" (traduzione dello slogan dal sito ufficiale). Anche questo è open-source. Qui comprendiamo che Redis non è specifico per Java, è generico, e ha bisogno di un wrapper per interagire con esso. EhCache risulta essere più comodo. Cosa promette ancora il sistema? Affidabilità, comprovata esperienza, funzionalità complete. Inoltre, è anche il più diffuso. E cachea terabyte di dati.
Redis è dimenticato, sono pronto a scegliere EhCache.
Ma un senso di patriottismo mi spinge a scoprire perché Tarantool sia buono.
Tarantool
— si presenta come "Piattaforma di integrazione dati in tempo reale". Suona molto complicato, quindi leggiamo la pagina con attenzione per trovare l'affermazione audace: "Memorizza il 100% dei dati nella RAM". Questo dovrebbe sollevare domande, poiché i dati possono essere significativamente più numerosi della memoria disponibile. La spiegazione è che qui si intende che per registrare i dati su disco dalla memoria, Tarantool non esegue la serializzazione. Invece, sfrutta caratteristiche a basso livello del sistema, in cui la memoria è semplicemente mappata sul file system con indicatori di I/O piuttosto buoni. Insomma, hanno fatto qualcosa di davvero straordinario e interessante.
Guardiamo le implementazioni: Mail.ru, la rete aziendale, Avito, Beeline, MegaFon, Alfa-Bank, Gazprom…
Se ci fossero ancora dei dubbi riguardo a Tarantool, il caso di implementazione in Mastercard mi convince del tutto. Prendo Tarantool.
Ma comunque…
Ignite
… c'è ancora , dichiarato come «piattaforma di calcolo in-memory... velocità in-memory su petabyte di dati». Ci sono anche molti vantaggi: caching in-memory distribuito, il più veloce sistema di memorizzazione chiave-valore e caching, scalabilità orizzontale, alta disponibilità, integrità rigorosa. In sostanza, si rivela che il più veloce è Ignite.
Implementazioni: Sberbank, American Airlines, Yahoo! Japan. E poi scopro anche che Ignite non è solo implementato in Sberbank, ma il team di SberTech invia le proprie persone nel team di Ignite per migliorare il prodotto. Questo mi conquista completamente e sono pronto a scegliere Ignite.
Non capisco affatto perché, guardo il quinto punto.
Hazelcast
Visito il sito , leggo. E si scopre che la soluzione più veloce per la memorizzazione cache distribuita è Hazelcast. È di gran lunga più veloce rispetto a tutte le altre soluzioni ed è, in effetti, il leader nel campo dei data grid in-memory. In questo contesto, scegliere qualcos'altro sarebbe mancarsi di rispetto. Inoltre, utilizza la memorizzazione ridondante dei dati per garantire il funzionamento continuo del cluster senza perdita di dati.
Bene, sono pronto a scegliere Hazelcast.
Confronto
Ma se guardiamo, tutti e cinque i candidati sono presentati in modo tale che ognuno di loro è il migliore. Come scegliere? Possiamo vedere quale è il più popolare, cercare confronti e così il mal di testa svanisce.
Troviamo questo , scegliamo i nostri 5 sistemi.
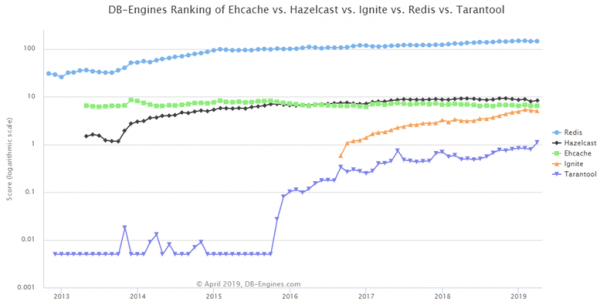
Qui sono ordinati: in cima Redis, al secondo posto — Hazelcast, stanno guadagnando popolarità Tarantool e Ignite, EhCache rimane com'era.
Ma diamo un'occhiata al : link ai siti web, interesse generale per il sistema, offerte di lavoro — fantastico! Cioè, quando il mio sistema fallirà, dirò: «No, è affidabile! Ecco quante offerte di lavoro…». Un confronto così semplice non basta.
Tutti questi sistemi non sono solo sistemi di caching. Hanno anche molte altre funzionalità, compreso il caso in cui non siano i dati a essere trasferiti al cliente per l'elaborazione, ma viceversa: il codice che deve essere eseguito sui dati si sposta sul server, viene eseguito lì e il risultato viene restituito. E come sistema separato per il caching non viene considerato molto spesso.
Bene, non ci arrendiamo, troviamo un confronto diretto tra i sistemi. Prendiamo i due primi varianti — Redis e Hazelcast. Siamo interessati alla velocità, confronteremo in base a questo parametro.
Hz vs Redis
Troviamo qualcosa :
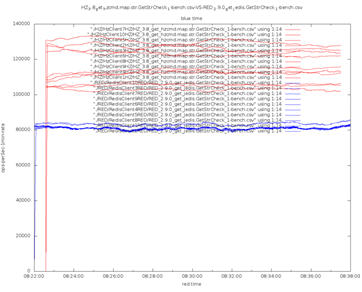
Blu è Redis, rosso è Hazelcast. Hazelcast vince ovunque, e questo è giustificato: è multithreading, altamente ottimizzato, ogni thread lavora con la propria partizione, quindi non ci sono blocchi. Redis, invece, è monothread, e non sfrutta i moderni CPU multicore. Hazelcast utilizza I/O asincrono, mentre Redis-Jedis ha socket bloccanti. Infine, Hazelcast utilizza un protocollo binario, mentre Redis è orientato al testo, il che significa che è inefficiente.
Per sicurezza, diamo un'occhiata a un'altra fonte di confronto. Cosa ci mostrerà?
Redis vs Hz
Un'altra cosa :
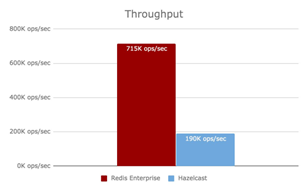
Qui è il contrario, rosso è Redis. Cioè, Redis ha prestazioni migliori rispetto a Hazelcast. Nel primo confronto ha vinto Hazelcast, nel secondo Redis. hanno spiegato esattamente perché nel precedente confronto ha vinto Hazelcast.
Si scopre che il risultato del primo è stato in realtà manipolato: Redis è stato preso in un pacchetto base, mentre Hazelcast è stato ottimizzato per il caso di test. Quindi, in primo luogo, non si può credere a nessuno, in secondo luogo, quando infine scegliamo un sistema, dobbiamo ancora configurarlo correttamente. Queste configurazioni comprendono decine, quasi centinaia di parametri.
Scuotiamo la bottiglia
E l'intero processo che abbiamo appena svolto lo posso spiegare usando la metafora "Scuotere la bottiglia". In altre parole, in questo momento non è necessario programmare, ciò che conta è sapere leggere stackoverflow. E nella mia squadra c'è una persona, un professionista, che lavora esattamente in questo modo nei momenti critici.
Cosa fa? Vede un oggetto non funzionante, osserva lo stack trace, prende alcune parole da esso (quali esattamente è la sua competenza nel programma), cerca su Google, trova Stack Overflow tra le risposte. Senza leggere né riflettere, tra le risposte alla domanda, sceglie qualcosa di simile alla proposta «fare questo e quello» (scegliere una risposta del genere è il suo talento, poiché non sempre è quella che ha ricevuto il maggior numero di like), applica, osserva: se qualcosa è cambiato, ottimo. Se non è cambiato, ripristiniamo. E ripetiamo l'esecuzione-verifica-ricerca. E in questo modo intuitivo, riesce a far funzionare il codice dopo un certo tempo. Non sa perché, non sa cosa ha fatto, non riesce a spiegare. Ma! Questa cosa funziona. E «l'incendio è spento». Ora cerchiamo di capire cosa abbiamo fatto. Quando il programma funziona, è molto più facile. E fa risparmiare un sacco di tempo.
Questo metodo è ben spiegato con un esempio del genere.
Un tempo era molto popolare costruire una nave in bottiglia. La nave è grande e fragile, mentre il collo della bottiglia è molto stretto, non può essere spinto dentro. Come si può assemblare?

C'è un metodo, molto veloce e molto efficace.
La nave è composta da tante piccole cose: bastoncini, corde, vele, colla. Tutto questo lo mettiamo nella bottiglia.
Prendiamo la bottiglia con entrambe le mani e iniziamo a scuoterla. La scuotiamo e scuotiamo. E di solito – viene fuori un pasticcio, certo. Ma a volte. A volte esce una nave! Piuttosto, qualcosa che assomiglia a una nave.
Mostriamo questa cosa a qualcuno: «Serjoga, vedi!?». E davvero, da lontano – sembra una nave. Ma oltre a questo non si può andare.
C'è un altro modo. I ragazzi più esperti, tipo i 'hacker', lo usano.
Ho dato a un tipo come questo un compito, ha fatto tutto ed è andato. E guardi – sembra fatto. Ma dopo un po', quando bisogna rielaborare il codice – le cose iniziano a complicarsi a causa sua... Buono che era già lontano. Sono quei ragazzi che prendono l'esempio della bottiglia e fanno così: vedete, dove c'è il fondo – il vetro si piega. E non è proprio chiaro se è trasparente o meno. Allora i 'hacker' tagliano via quel fondo, infilano la nave, poi riattaccano il fondo e sembra che sia così che deve essere.
Dal punto di vista della formulazione del problema sembra tutto corretto. Ma prendiamo l'esempio delle navi: perché realizzare questa nave, a chi serve davvero? Non ha alcuna funzionalità pratica. Di solito, queste navi sono regali per persone di alto rango, che le posizionano su uno scaffale come simbolo o segno distintivo. E se una tale persona, un grande imprenditore o un alto funzionario, dovesse avere come vessillo un lavoro di questo tipo, con il collo rotto? È meglio che non lo scopra mai. Ma come vengono davvero realizzate queste navi che possono essere donate a persone importanti?
L'unico aspetto, cruciale, su cui non si può fare nulla è il corpo della nave. Ed è proprio il corpo della nave a passare attraverso il collo della bottiglia. Mentre la nave viene assemblata al di fuori della bottiglia. Ma non si tratta semplicemente di assemblare la nave, è un vero e proprio lavoro di precisione artigianale. Si aggiungono leve speciali ai componenti, che permettono poi di sollevarli. Ad esempio, le vele vengono piegate, inserite con cura all'interno e poi, con l'aiuto di pinzette, vengono tirate su con grande precisione. Alla fine, si ottiene un'opera d'arte che può essere regalata con grande orgoglio e senza esitazione.
E se vogliamo che il progetto abbia successo, nella squadra deve esserci almeno una persona artigiana. Qualcuno che si prende cura della qualità del prodotto e considera tutti gli aspetti, senza sacrificare nulla, nemmeno nei momenti di stress, quando è necessario fare qualcosa di urgente a discapito dell'importante. Tutti i progetti di successo, quelli che sono resistenti, che hanno superato la prova del tempo, sono basati su questo principio. In essi c'è qualcosa di molto preciso e unico, qualcosa che utilizza tutte le opportunità disponibili. Nell'esempio della nave nella bottiglia si gioca sul fatto che lo scafo della nave passa attraverso il collo.
Tornando al compito di scegliere il nostro server di caching, come si potrebbe applicare questo metodo? Propongo di non scuotere la bottiglia, non di selezionare, ma di guardare cosa c'è in esse che merita attenzione nella scelta del sistema.
Dove cercare il collo di bottiglia
Proviamo a non scuotere la bottiglia e non a esaminare tutto quello che abbiamo uno dopo l'altro, ma vediamo quali problemi potrebbero sorgere se dovessimo progettare un sistema del genere da soli. Certo, non ci metteremo a costruire una bicicletta, ma utilizzeremo questo schema per orientarci sui punti da considerare nelle descrizioni dei prodotti. Creiamo uno schema del genere.
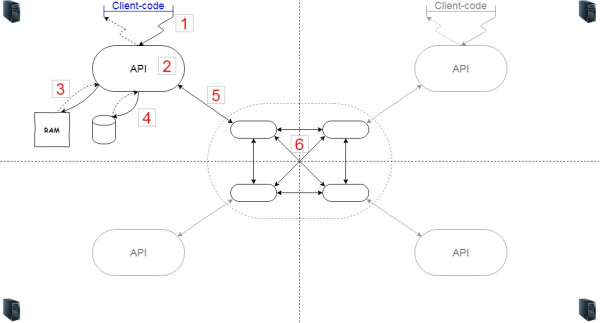
Se il sistema è distribuito, avremo diversi server (6). Supponiamo quattro (è comodo rappresentarli in un'immagine, ma ovviamente possono essere quanti ne vogliamo). Se i server sono su nodi diversi, significa che su di essi gira il codice che fa in modo che questi nodi formino un cluster e, in caso di disconnessione, si ricolleghino e riconoscano tra loro.
Abbiamo anche bisogno di codice-logica (2) per il caching. Con questo codice interagiscono i clienti attraverso un certo API. Il codice client (1) può trovarsi all'interno della stessa JVM o accedervi tramite rete. La logica implementata internamente riguarda quali oggetti mantenere nella cache e quali eliminare. Per memorizzare la cache utilizziamo la memoria (3), ma se necessario, possiamo anche salvare parte dei dati su disco (4).
Vediamo in quali parti si andrà a generare il carico. In effetti, ogni freccia e ogni nodo saranno sotto pressione. Prima di tutto, tra il codice client e l'API, se si tratta di interazione di rete, il calo delle prestazioni può essere piuttosto evidente. In secondo luogo, all'interno dell'API stessa — se si esagera con logiche complesse, possiamo incappare nel CPU. Sarebbe meglio se la logica non usasse la memoria inutilmente. Rimane poi l'interazione con il file system – in una situazione normale si tratta di serializzare / ripristinare e scrivere / leggere.
Poi c'è l'interazione con il cluster. Probabilmente sarà nella stessa infrastruttura, ma potrebbe anche essere separata. Anche qui è necessario considerare il trasferimento dei dati, la velocità di serializzazione e l'interazione tra i cluster.
Ora, da un lato – possiamo immaginare "quali ingranaggi gireranno" nel sistema di cache durante l'elaborazione delle richieste dal nostro codice, e dall'altro lato – possiamo stimare quante e quali richieste il nostro codice genererà verso questo sistema. Queste informazioni sono sufficienti per fare una scelta ragionata – selezionare un sistema adatto al nostro caso d'uso.
Hazelcast
Vediamo come applicare questa decomposizione alla nostra lista. Ad esempio, Hazelcast.
Per inserire/recuperare dati da Hazelcast, il codice client si riferisce (1) all'api. Hz consente di avviare il server come embedded e, in questo caso, la chiamata all'api è una chiamata a un metodo all'interno della JVM, quindi può essere considerata gratuita.
Per il funzionamento della logica in (2), Hz si basa sull'hash di un array di byte serializzato della chiave, ovvero la serializzazione della chiave avverrà in ogni caso. Questo è un overhead inevitabile per Hz.
Le strategie di eviction sono ben implementate, ma in casi particolari è possibile collegare le proprie. Non è necessario preoccuparsi di questa parte.
Il repository (4) può essere collegato. Ottimo. L'interazione (5) per l'embedded può essere considerata istantanea. Lo scambio di dati tra i nodi nel cluster (6) – sì, c'è. Questo contribuisce alla resilienza sacrificando la velocità. Hz ha la funzionalità Near-cache che riduce i costi: i dati ottenuti da altri nodi del cluster verranno memorizzati nella cache.
Cosa si può fare in queste condizioni per aumentare la velocità?
Ad esempio, per evitare la serializzazione della chiave in (2) – sopra Hazelcast si può aggiungere un altro cache, per i dati più critici. In Sportmaster, per questo scopo, è stato scelto Caffeine.
Per la configurazione a livello (6), in Hz sono disponibili due tipi di archiviazione: IMap e ReplicatedMap.
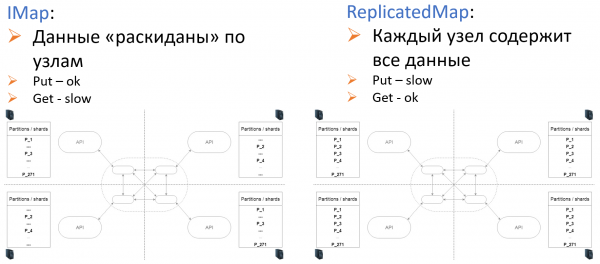
È interessante vedere come Hazelcast sia entrato nel stack tecnologico di Sportmaster.
Nel 2012, mentre lavoravamo al primo prototipo del futuro sito, Hazelcast è stato il primo risultato fornito dal motore di ricerca. Il suo utilizzo è stato immediato — ci ha colpito il fatto che dopo solo due ore dall'integrazione di Hz nel sistema, funzionava. E funzionava bene. Entro la fine della giornata avevamo scritto un certo numero di test e ci eravamo soddisfatti. Quella spinta iniziale è stata sufficiente per superare le sorprese che Hz ha presentato nel tempo. Ora il team di Sportmaster non ha motivi per rinunciare a Hazelcast.
Tuttavia, argomenti come ‘primo link nel motore di ricerca’ e ‘abbiamo rapidamente creato HelloWorld’ sono, naturalmente, eccezioni e particolarità del momento in cui è avvenuta la scelta. Le vere sfide per il sistema scelto iniziano con il passaggio alla produzione, ed è a questo stadio che bisogna prestare attenzione quando si sceglie qualsiasi sistema, incluso il caching. In effetti, nel nostro caso si può dire che abbiamo scelto Hazelcast per caso, ma alla fine si è rivelato essere la scelta giusta.
Per il production, è molto più importante: monitoraggio, gestione dei guasti su nodi singoli, replicazione dei dati e costo di scalabilità. Vale a dire, è fondamentale prestare attenzione alle sfide che emergeranno durante la gestione del sistema: quando il carico supererà di decine di volte le previsioni, quando caricheremo accidentalmente qualcosa di sbagliato e in un posto sbagliato, e quando sarà necessario rilasciare una nuova versione del codice, sostituire i dati, e farlo senza che i clienti se ne accorgano.
Per tutte queste esigenze, Hazelcast è senza dubbio adatto.
Continua...
Ma Hazelcast non è una panacea. Nel 2017 abbiamo scelto Hazelcast per la cache nell'interfaccia amministrativa, semplicemente basandoci sulla buona impressione del passato. Questo ha giocato un ruolo chiave in una spiacevole situazione, dalla quale siamo emersi "eroicamente" dopo 60 giorni. Ma di questo parleremo nella prossima parte.
Nel frattempo… Happy New Code!
Fonte: habr.com
