

Ciao a tutti, mi chiamo Alessandro, lavoro presso CIAN come ingegnere e mi occupo di amministrazione di sistema e automazione dei processi infrastrutturali. Nei commenti a uno degli articoli precedenti, ci è stato chiesto di dire dove prendiamo 4 TB di log al giorno e cosa ne facciamo. Sì, disponiamo di molti log e per elaborarli è stato creato un cluster infrastrutturale separato, che ci consente di risolvere rapidamente i problemi. In questo articolo parlerò di come lo abbiamo adattato nel corso di un anno per lavorare con un flusso di dati in continua crescita.
Da dove abbiamo iniziato?
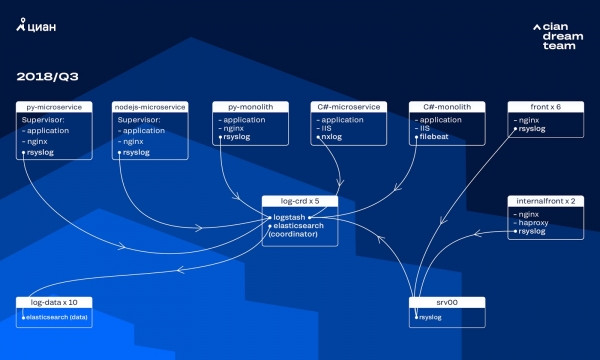
Negli ultimi anni, il carico su cian.ru è cresciuto molto rapidamente e nel terzo trimestre del 2018 il traffico delle risorse ha raggiunto 11.2 milioni di utenti unici al mese. A quel tempo, nei momenti critici perdevamo fino al 40% dei registri, motivo per cui non potevamo gestire rapidamente gli incidenti e dedicavamo molto tempo e sforzi alla loro risoluzione. Inoltre, spesso non riuscivamo a trovare la causa del problema e questo si ripresentava dopo un po' di tempo. Era un inferno e bisognava fare qualcosa al riguardo.
A quel tempo, utilizzavamo un cluster di 10 nodi di dati con ElasticSearch versione 5.5.2 con impostazioni di indice standard per archiviare i log. È stata introdotta più di un anno fa come una soluzione popolare e conveniente: quindi il flusso di registri non era così ampio, non aveva senso inventare configurazioni non standard.
L'elaborazione dei log in entrata è stata fornita da Logstash su diverse porte su cinque coordinatori ElasticSearch. Un indice, indipendentemente dalle dimensioni, era costituito da cinque frammenti. È stata organizzata una rotazione oraria e giornaliera, di conseguenza, ogni ora nel cluster apparivano circa 100 nuovi frammenti. Anche se non c’erano molti log, il cluster se la cavava bene e nessuno prestava attenzione alle sue impostazioni.
Le sfide di una crescita rapida
Il volume dei log generati è cresciuto molto rapidamente, poiché due processi si sono sovrapposti. Da un lato è cresciuto il numero degli utenti del servizio. D'altra parte, abbiamo iniziato a passare attivamente a un'architettura a microservizi, segando i nostri vecchi monoliti in C# e Python. Diverse dozzine di nuovi microservizi che hanno sostituito parti del monolite hanno generato un numero significativamente maggiore di log per il cluster dell’infrastruttura.
È stato il ridimensionamento a portarci al punto in cui il cluster è diventato praticamente ingestibile. Quando i log iniziarono ad arrivare a una velocità di 20mila messaggi al secondo, la rotazione frequente e inutile aumentò il numero di shard a 6mila e c'erano più di 600 shard per nodo.
Ciò ha portato a problemi con l'allocazione della RAM e, quando un nodo si bloccava, tutti gli shard migravano simultaneamente, aumentando il traffico e caricando i nodi rimanenti, rendendo praticamente impossibile la scrittura dei dati sul cluster. E durante questo periodo, siamo rimasti senza log. E se si verificava un problema con server Stavamo perdendo 1/10 del cluster complessivo. L'elevato numero di indici di piccole dimensioni aumentava la complessità.
Senza registri, non abbiamo compreso le ragioni dell'incidente e prima o poi avremmo potuto salire di nuovo sullo stesso rastrello, e nell'ideologia del nostro team questo era inaccettabile, poiché tutti i nostri meccanismi di lavoro sono progettati per fare esattamente l'opposto: non ripetere mai gli stessi problemi. Per fare ciò, avevamo bisogno dell'intero volume di log e della loro consegna quasi in tempo reale, poiché un team di ingegneri in servizio monitorava gli avvisi non solo dalle metriche, ma anche dai log. Per comprendere la portata del problema, all’epoca il volume totale di log era di circa 2 TB al giorno.
Ci siamo posti l'obiettivo di eliminare completamente la perdita di log e di ridurre il tempo di consegna al cluster ELK a un massimo di 15 minuti in caso di forza maggiore (in seguito abbiamo fatto affidamento su questa cifra come KPI interno).
Nuovo meccanismo di rotazione e nodi caldo-caldo
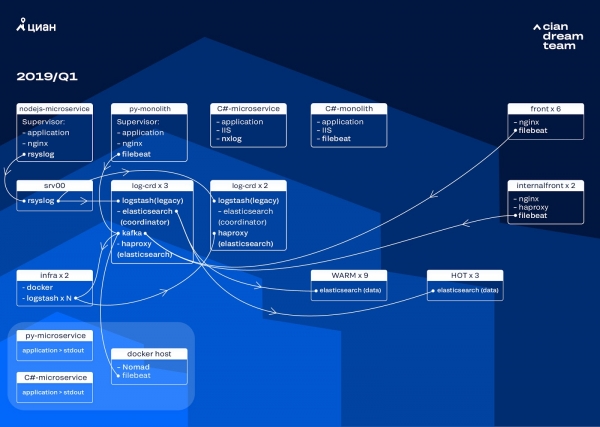
Abbiamo avviato la conversione del cluster aggiornando la versione ElasticSearch dalla 5.5.2 alla 6.4.3. Ancora una volta il nostro cluster della versione 5 è morto e abbiamo deciso di disattivarlo e aggiornarlo completamente: non ci sono ancora registri. Quindi abbiamo effettuato questa transizione in appena un paio d'ore.
La trasformazione più grande in questa fase è stata l’implementazione di Apache Kafka su tre nodi con un coordinatore come buffer intermedio. Il broker di messaggi ci ha salvato dalla perdita di registri durante problemi con ElasticSearch. Allo stesso tempo, abbiamo aggiunto 2 nodi al cluster e siamo passati a un'architettura hot-warm con tre nodi “hot” posizionati in rack diversi nel data center. Abbiamo reindirizzato loro i registri utilizzando una maschera che non dovrebbe essere persa in nessuna circostanza: nginx, nonché i registri degli errori dell'applicazione. I registri minori sono stati inviati ai nodi rimanenti: debug, avvisi, ecc., e dopo 24 ore sono stati trasferiti i registri "importanti" dai nodi "attivi".
Per non aumentare il numero di piccoli indici, siamo passati dalla rotazione temporale al meccanismo di rollover. Nei forum c'erano molte informazioni secondo cui la rotazione in base alla dimensione dell'indice è molto inaffidabile, quindi abbiamo deciso di utilizzare la rotazione in base al numero di documenti nell'indice. Abbiamo analizzato ciascun indice e registrato il numero di documenti dopo il quale dovrebbe funzionare la rotazione. Pertanto, abbiamo raggiunto la dimensione ottimale del frammento: non più di 50 GB.
Ottimizzazione dei cluster
Tuttavia, non abbiamo eliminato completamente i problemi. Sfortunatamente, apparivano ancora indici di piccole dimensioni: non raggiungevano il volume specificato, non venivano ruotati e venivano eliminati dalla pulizia globale degli indici più vecchi di tre giorni, poiché abbiamo rimosso la rotazione per data. Ciò ha portato alla perdita di dati dovuta al fatto che l'indice del cluster è scomparso completamente e il tentativo di scrivere su un indice inesistente ha rotto la logica del curatore che abbiamo utilizzato per la gestione. L'alias per la scrittura è stato convertito in un indice e ha rotto la logica del rollover, provocando una crescita incontrollata di alcuni indici fino a 600 GB.
Ad esempio, per la configurazione della rotazione:
сurator-elk-rollover.yaml
---
actions:
1:
action: rollover
options:
name: "nginx_write"
conditions:
max_docs: 100000000
2:
action: rollover
options:
name: "python_error_write"
conditions:
max_docs: 10000000
Se non era presente alcun alias di rollover, si è verificato un errore:
ERROR alias "nginx_write" not found.
ERROR Failed to complete action: rollover. <type 'exceptions.ValueError'>: Unable to perform index rollover with alias "nginx_write".
Abbiamo lasciato la soluzione a questo problema per l'iterazione successiva e abbiamo affrontato un altro problema: siamo passati alla logica pull di Logstash, che elabora i log in entrata (rimuovendo e arricchendo le informazioni non necessarie). Lo abbiamo inserito nella finestra mobile, che lanciamo tramite docker-compose, e lì abbiamo anche inserito logstash-exporter, che invia parametri a Prometheus per il monitoraggio operativo del flusso di log. In questo modo ci siamo dati l'opportunità di modificare agevolmente il numero di istanze di logstash responsabili dell'elaborazione di ciascun tipo di log.
Mentre miglioravamo il cluster, il traffico di cian.ru è aumentato fino a 12,8 milioni di utenti unici al mese. Di conseguenza, si è scoperto che le nostre trasformazioni erano leggermente indietro rispetto ai cambiamenti nella produzione e ci siamo trovati di fronte al fatto che i nodi "caldi" non potevano far fronte al carico e hanno rallentato l'intera consegna dei tronchi. Abbiamo ricevuto dati “caldi” senza errori, ma abbiamo dovuto intervenire nella consegna del resto ed eseguire un rollover manuale per distribuire uniformemente gli indici.
Allo stesso tempo, il ridimensionamento e la modifica delle impostazioni delle istanze logstash nel cluster erano complicati dal fatto che si trattava di un docker-compose locale e tutte le azioni venivano eseguite manualmente (per aggiungere nuove estremità, era necessario eseguire manualmente tutte le operazioni i server ed esegui docker-compose up -d ovunque).
Ridistribuzione dei registri
Nel settembre di quest'anno stavamo ancora tagliando il monolite, il carico sul cluster aumentava e il flusso di log si avvicinava ai 30mila messaggi al secondo.
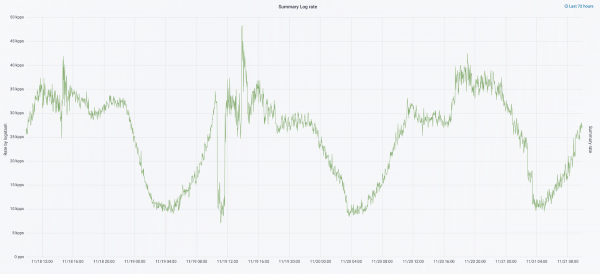
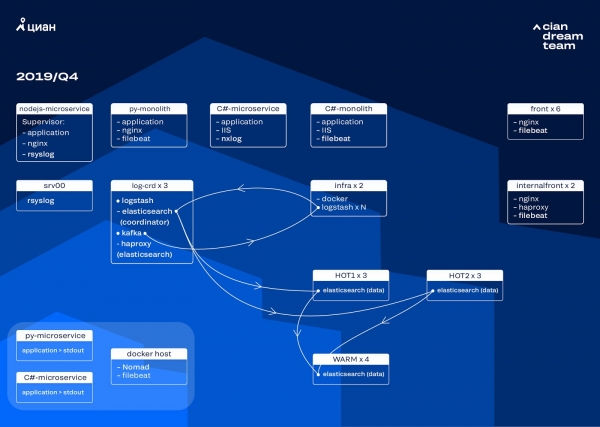
Abbiamo iniziato l'iterazione successiva con un aggiornamento hardware. Siamo passati da cinque a tre coordinatori, abbiamo sostituito i nodi dati e abbiamo vinto in termini di denaro e spazio di archiviazione. Per i nodi utilizziamo due configurazioni:
- Per i nodi “hot”: E3-1270 v6 / SSD da 960 Gb / 32 Gb x 3 x 2 (3 per Hot1 e 3 per Hot2).
- Per i nodi “caldi”: E3-1230 v6 / 4Tb SSD / 32 Gb x 4.
In questa iterazione, abbiamo spostato l’indice con i log di accesso dei microservizi, che occupa lo stesso spazio dei log nginx in prima linea, nel secondo gruppo di tre nodi “caldi”. Ora memorizziamo i dati sui nodi “caldi” per 20 ore, quindi li trasferiamo sui nodi “caldi” al resto dei log.
Abbiamo risolto il problema della scomparsa degli indici piccoli riconfigurandone la rotazione. Ora gli indici vengono ruotati in ogni caso ogni 23 ore, anche se ci sono pochi dati. Ciò ha leggermente aumentato il numero di frammenti (erano circa 800), ma dal punto di vista delle prestazioni del cluster è tollerabile.
Di conseguenza, nel cluster erano presenti sei nodi “caldi” e solo quattro “caldi”. Ciò provoca un leggero ritardo nelle richieste su lunghi intervalli di tempo, ma l'aumento del numero di nodi in futuro risolverà questo problema.
Questa iterazione ha anche risolto il problema della mancanza di ridimensionamento semiautomatico. Per fare ciò, abbiamo implementato un cluster Nomad dell'infrastruttura, simile a quello che abbiamo già implementato in produzione. Per ora la quantità di Logstash non cambia automaticamente a seconda del carico, ma arriveremo a questo.
Progetti per il futuro
La configurazione implementata si adatta perfettamente e ora memorizziamo 13,3 TB di dati, tutti i registri per 4 giorni, necessari per l'analisi di emergenza degli avvisi. Convertiamo alcuni log in metriche, che aggiungiamo a Graphite. Per facilitare il lavoro degli ingegneri, disponiamo di metriche per il cluster dell'infrastruttura e script per la riparazione semiautomatica dei problemi comuni. Dopo aver aumentato il numero di nodi dati, previsto per il prossimo anno, passeremo all'archiviazione dei dati da 4 a 7 giorni. Questo sarà sufficiente per il lavoro operativo, poiché cerchiamo sempre di indagare sugli incidenti il prima possibile e per le indagini a lungo termine ci sono i dati telemetrici.
Nell'ottobre 2019, il traffico su cian.ru era già cresciuto fino a raggiungere 15,3 milioni di utenti unici al mese. Questo è diventato un test serio per la soluzione architetturale per la distribuzione dei log.
Ora ci stiamo preparando ad aggiornare ElasticSearch alla versione 7. Tuttavia, per questo dovremo aggiornare la mappatura di molti indici in ElasticSearch, poiché sono passati dalla versione 5.5 e sono stati dichiarati deprecati nella versione 6 (semplicemente non esistono nella versione 7). Ciò significa che durante il processo di aggiornamento si verificherà sicuramente qualche tipo di forza maggiore, che ci lascerà senza log mentre il problema viene risolto. Della versione 7, non vediamo l'ora che arrivi Kibana con un'interfaccia migliorata e nuovi filtri.
Abbiamo raggiunto il nostro obiettivo principale: abbiamo smesso di perdere log e ridotto i tempi di inattività del cluster infrastrutturale da 2-3 arresti anomali a settimana a un paio d'ore di lavoro di manutenzione al mese. Tutto questo lavoro nella produzione è quasi invisibile. Tuttavia, ora possiamo determinare esattamente cosa sta succedendo al nostro servizio, possiamo farlo rapidamente in modalità silenziosa e senza preoccuparci che i registri vadano persi. In generale siamo soddisfatti, felici e ci prepariamo a nuove imprese, di cui parleremo più avanti.
Fonte: habr.com
