


Ciao, Habr! Sono Artem Karamyshev, capo del team di amministrazione del sistema . Abbiamo avuto molti lanci di nuovi prodotti nell'ultimo anno. Volevamo garantire che i servizi API fossero facilmente scalabili, tolleranti agli errori e pronti per una rapida crescita del carico degli utenti. La nostra piattaforma è implementata su OpenStack e voglio dirti quali problemi di tolleranza agli errori dei componenti abbiamo dovuto risolvere per ottenere un sistema tollerante agli errori. Penso che questo sarà interessante per coloro che sviluppano prodotti anche su OpenStack.
La tolleranza agli errori complessiva di una piattaforma consiste nella resilienza dei suoi componenti. Quindi attraverseremo gradualmente tutti i livelli in cui abbiamo identificato i rischi e li abbiamo chiusi.
Versione video di questa storia, la cui fonte principale era un rapporto alla conferenza Uptime day 4, organizzata da , Puoi vedere .
Resilienza dell'architettura fisica
La parte pubblica del cloud MCS è ora basata su due data center Tier III, tra i quali si trova la propria fibra spenta, riservata a livello fisico da percorsi diversi, con un throughput di 200 Gbit/s. Il livello III fornisce il livello necessario di tolleranza ai guasti per l'infrastruttura fisica.
La fibra scura è riservata sia a livello fisico che logico. Il processo di prenotazione dei canali è stato iterativo, sono sorti problemi e miglioriamo costantemente la comunicazione tra i data center.
Ad esempio, non molto tempo fa, mentre lavorava in un pozzo vicino a uno dei data center, un escavatore ha rotto un tubo e all'interno di questo tubo c'erano sia il cavo ottico principale che quello ottico di riserva. Il nostro canale di comunicazione tollerante ai guasti con il data center si è rivelato vulnerabile a un certo punto, nel pozzo. Di conseguenza, abbiamo perso parte dell’infrastruttura. Abbiamo tratto delle conclusioni e intrapreso una serie di azioni, inclusa l'installazione di ottiche aggiuntive nel pozzo adiacente.
Nei data center ci sono punti di presenza di fornitori di comunicazione ai quali trasmettiamo i nostri prefissi tramite BGP. Per ciascuna direzione della rete viene selezionata la metrica migliore che consente di fornire ai diversi client la migliore qualità di connessione. Se la comunicazione attraverso un provider si interrompe, ricostruiamo il nostro routing attraverso i provider disponibili.
Se un fornitore fallisce, passiamo automaticamente a quello successivo. In caso di guasto di uno dei data center, nel secondo data center disponiamo di una copia speculare dei nostri servizi, che si assume l'intero carico.
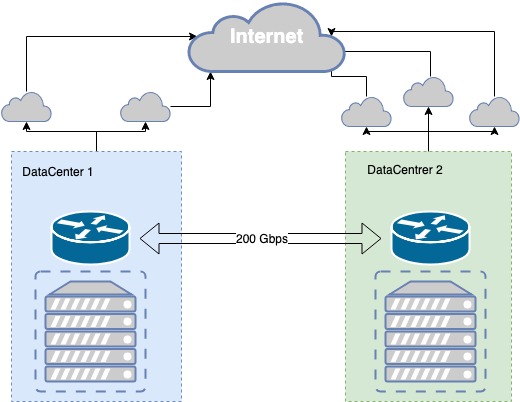
Resilienza delle infrastrutture fisiche
Cosa utilizziamo per la tolleranza agli errori a livello di applicazione
Il nostro servizio si basa su una serie di componenti open source.
ExaBGP è un servizio che implementa una serie di funzioni utilizzando il protocollo di routing dinamico basato su BGP. Lo utilizziamo attivamente per pubblicizzare i nostri indirizzi IP inseriti nella whitelist attraverso i quali gli utenti accedono all'API.
HAProxy è un bilanciatore ad alto carico che consente di configurare regole di bilanciamento del traffico molto flessibili a diversi livelli del modello OSI. Lo utilizziamo per bilanciare tutti i servizi: database, broker di messaggi, servizi API, servizi web, i nostri progetti interni: tutto è dietro HAProxy.
Applicazione API — un'applicazione web scritta in python, con la quale l'utente gestisce la propria infrastruttura e il proprio servizio.
Applicazione del lavoratore (di seguito semplicemente lavoratore) - nei servizi OpenStack, si tratta di un demone dell'infrastruttura che consente di trasmettere comandi API all'infrastruttura. Ad esempio, la creazione del disco avviene nel lavoratore e la richiesta di creazione avviene nell'API dell'applicazione.
Architettura dell'applicazione OpenStack standard
La maggior parte dei servizi sviluppati per OpenStack tenta di seguire un unico paradigma. Un servizio è solitamente composto da 2 parti: API e lavoratori (esecutori backend). Di norma, un'API è un'applicazione WSGI in Python, che viene avviata come processo indipendente (daemon) o utilizzando un server Web Nginx o Apache già pronto. L'API elabora la richiesta dell'utente e trasmette ulteriori istruzioni all'applicazione lavoratore per l'esecuzione. Il trasferimento avviene utilizzando un broker di messaggi, solitamente RabbitMQ, gli altri sono scarsamente supportati. Quando i messaggi raggiungono il broker, vengono elaborati dai lavoratori e, se necessario, restituiscono una risposta.
Questo paradigma coinvolge punti comuni isolati di fallimento: RabbitMQ e il database. Ma RabbitMQ è isolato all'interno di un servizio e, in teoria, può essere individuale per ciascun servizio. Quindi in MCS separiamo questi servizi il più possibile; per ogni singolo progetto creiamo un database separato, un RabbitMQ separato. Questo approccio è positivo perché in caso di incidente in alcuni punti vulnerabili non si interrompe l'intero servizio, ma solo una parte.
Il numero di applicazioni lavoratore è illimitato, quindi l'API può facilmente scalare orizzontalmente dietro i bilanciatori per aumentare le prestazioni e la tolleranza agli errori.
Alcuni servizi richiedono il coordinamento all'interno del servizio quando si verificano operazioni sequenziali complesse tra API e lavoratori. In questo caso si utilizza un unico centro di coordinamento, un sistema cluster come Redis, Memcache, ecc., che permette ad un lavoratore di dire ad un altro che questo compito gli è assegnato (“per favore non prenderlo”). Usiamo etcd. Di norma, i lavoratori comunicano attivamente con il database, scrivono e leggono informazioni da lì. Usiamo mariadb come database, che si trova in un cluster multimaster.
Questo classico servizio unico è organizzato in un modo generalmente accettato per OpenStack. Può essere considerato come un sistema chiuso, per il quale i metodi di scalabilità e di tolleranza agli errori sono abbastanza ovvi. Ad esempio, per la tolleranza agli errori API, è sufficiente mettere davanti a loro un bilanciatore. Il ridimensionamento dei lavoratori si ottiene aumentandone il numero.
Il punto debole dell'intero schema è RabbitMQ e MariaDB. La loro architettura merita un articolo a parte, in questo articolo voglio concentrarmi sulla tolleranza agli errori delle API.
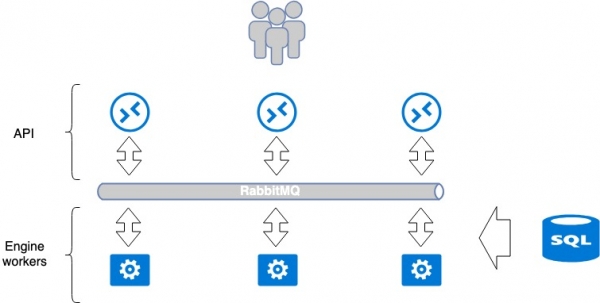
Architettura dell'applicazione OpenStack. Bilanciamento e tolleranza ai guasti della piattaforma cloud
Rendere il sistema di bilanciamento HAProxy tollerante agli errori utilizzando ExaBGP
Per rendere le nostre API scalabili, veloci e tolleranti ai guasti, mettiamo loro a disposizione un bilanciatore del carico. Abbiamo scelto HAProxy. Secondo me ha tutte le caratteristiche necessarie per il nostro compito: bilanciamento a più livelli OSI, interfaccia di gestione, flessibilità e scalabilità, un gran numero di metodi di bilanciamento, supporto per tabelle di sessione.
Il primo problema da risolvere era la tolleranza ai guasti del bilanciatore stesso. Anche la semplice installazione di un bilanciatore crea un punto di guasto: il bilanciatore si rompe e il servizio si blocca. Per evitare che ciò accada, abbiamo utilizzato HAProxy insieme a ExaBGP.
ExaBGP consente di implementare un meccanismo per verificare lo stato di un servizio. Abbiamo utilizzato questo meccanismo per verificare la funzionalità di HAProxy e, in caso di problemi, disabilitare il servizio HAProxy da BGP.
Schema ExaBGP+HAProxy
- Installiamo il software necessario, ExaBGP e HAProxy, su tre server.
- Creiamo un'interfaccia di loopback su ciascun server.
- Su tutti e tre i server assegniamo a questa interfaccia lo stesso indirizzo IP bianco.
- Un indirizzo IP bianco viene pubblicizzato su Internet tramite ExaBGP.
La tolleranza agli errori si ottiene pubblicizzando lo stesso indirizzo IP da tutti e tre i server. Dal punto di vista della rete, lo stesso indirizzo è accessibile da tre diversi hop successivi. Il router vede tre percorsi identici, seleziona quello con la priorità più alta in base alla propria metrica (di solito è la stessa opzione) e il traffico va solo a uno dei server.
In caso di problemi con il funzionamento di HAProxy o di guasto del server, ExaBGP smette di annunciare il percorso e il traffico passa senza problemi a un altro server.
Pertanto, abbiamo raggiunto la tolleranza ai guasti del bilanciatore.
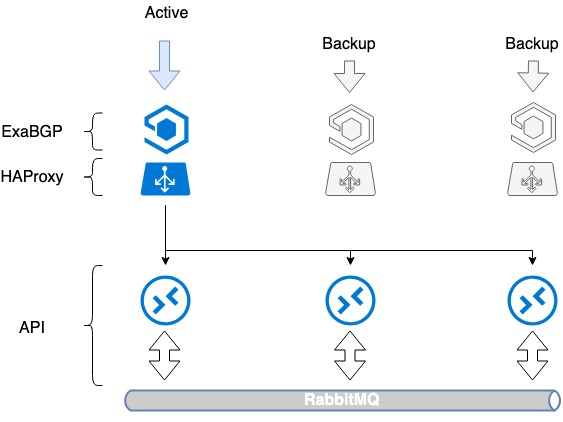
Tolleranza agli errori dei bilanciatori HAProxy
Lo schema si è rivelato imperfetto: abbiamo imparato a prenotare HAProxy, ma non abbiamo imparato a distribuire il carico all'interno dei servizi. Pertanto, abbiamo leggermente ampliato questo schema: siamo passati al bilanciamento tra diversi indirizzi IP bianchi.
Bilanciamento basato su DNS più BGP
La questione del bilanciamento del carico per il nostro HAProxy rimane irrisolta. Tuttavia, il problema può essere risolto in modo molto semplice, come abbiamo fatto qui.
Per bilanciare tre server avrai bisogno di 3 indirizzi IP bianchi e del buon vecchio DNS. Ciascuno di questi indirizzi viene determinato sull'interfaccia di loopback di ciascun HAProxy e pubblicizzato su Internet.
In OpenStack, per gestire le risorse, viene utilizzata una directory di servizio, che specifica l'API endpoint di un particolare servizio. In questa directory registriamo un nome di dominio - public.infra.mail.ru, che viene risolto tramite DNS da tre diversi indirizzi IP. Di conseguenza, otteniamo la distribuzione del carico tra tre indirizzi tramite DNS.
Ma poiché quando annunciamo gli indirizzi IP bianchi non controlliamo le priorità di selezione del server, questo non è ancora bilanciato. In genere, verrà selezionato solo un server in base all'anzianità dell'indirizzo IP e gli altri due saranno inattivi poiché non è specificata alcuna metrica in BGP.
Abbiamo iniziato a inviare percorsi tramite ExaBGP con metriche diverse. Ogni bilanciatore pubblicizza tutti e tre gli indirizzi IP bianchi, ma uno di essi, quello principale per questo bilanciatore, è pubblicizzato con la metrica minima. Quindi, mentre tutti e tre i bilanciatori sono in funzione, le chiamate al primo indirizzo IP vanno al primo bilanciatore, le chiamate al secondo al secondo e le chiamate al terzo al terzo.
Cosa succede quando uno dei bilanciatori cade? Se un bilanciatore si guasta, il suo indirizzo principale viene comunque pubblicizzato dagli altri due e il traffico viene ridistribuito tra di loro. Pertanto, forniamo all'utente più indirizzi IP contemporaneamente tramite DNS. Bilanciando tramite DNS e parametri diversi, otteniamo una distribuzione uniforme del carico su tutti e tre i bilanciatori. E allo stesso tempo non perdiamo la tolleranza agli errori.
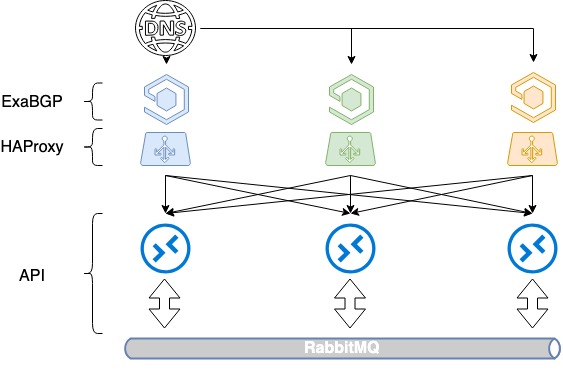
Bilanciamento HAProxy basato su DNS + BGP
Interazione tra ExaBGP e HAProxy
Quindi, abbiamo implementato la tolleranza agli errori nel caso in cui il server se ne vada, basandosi sull'interruzione dell'annuncio dei percorsi. Ma HAProxy può spegnersi per ragioni diverse dal guasto del server: errori di amministrazione, guasti all'interno del servizio. Anche in questi casi vogliamo rimuovere il bilanciatore rotto da sotto il carico e abbiamo bisogno di un meccanismo diverso.
Pertanto, espandendo lo schema precedente, abbiamo implementato l'heartbeat tra ExaBGP e HAProxy. Questa è un'implementazione software dell'interazione tra ExaBGP e HAProxy, quando ExaBGP utilizza script personalizzati per verificare lo stato delle applicazioni.
Per fare ciò, è necessario configurare un controllo dello stato nella configurazione ExaBGP, che può controllare lo stato di HAProxy. Nel nostro caso, abbiamo configurato il backend sanitario in HAProxy e dal lato ExaBGP controlliamo con una semplice richiesta GET. Se l'annuncio non viene più visualizzato, molto probabilmente HAProxy non funziona e non è necessario pubblicizzarlo.
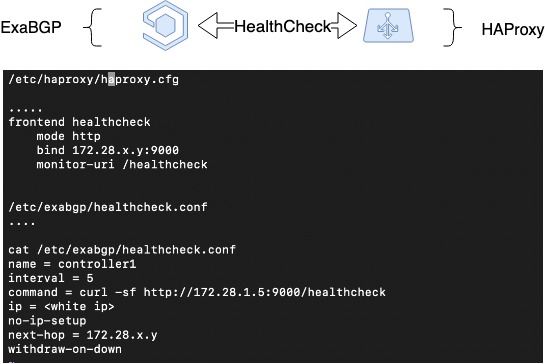
Controllo dello stato del proxy HA
HAProxy Peers: sincronizzazione della sessione
La cosa successiva da fare era sincronizzare le sessioni. Quando si lavora tramite bilanciatori distribuiti, è difficile organizzare l'archiviazione delle informazioni sulle sessioni client. Ma HAProxy è uno dei pochi bilanciatori che può farlo grazie alla funzionalità Peers: la capacità di trasferire tabelle di sessione tra diversi processi HAProxy.
Esistono diversi metodi di bilanciamento: quelli semplici come , ed esteso, quando la sessione del client viene ricordata e ogni volta che finisce sullo stesso server di prima. Volevamo implementare la seconda opzione.
HAProxy utilizza stick-table per salvare le sessioni client di questo meccanismo. Salvano l'indirizzo IP originale del cliente, l'indirizzo di destinazione selezionato (backend) e alcune informazioni sul servizio. In genere, le tabelle stick vengono utilizzate per memorizzare una coppia IP di origine + IP di destinazione, il che è particolarmente utile per le applicazioni che non possono trasferire il contesto della sessione utente quando si passa a un altro bilanciatore, ad esempio in modalità di bilanciamento RoundRobin.
Se a una tabella stick viene insegnato a spostarsi tra diversi processi HAProxy (tra i quali avviene il bilanciamento), i nostri bilanciatori saranno in grado di funzionare con un pool di tabelle stick. Ciò consentirà di cambiare senza problemi la rete del cliente se uno dei bilanciatori fallisce; il lavoro con le sessioni del cliente continuerà sugli stessi backend selezionati in precedenza.
Per un corretto funzionamento è necessario risolvere il problema dell'indirizzo IP di origine del bilanciatore da cui è stata stabilita la sessione. Nel nostro caso si tratta di un indirizzo dinamico sull'interfaccia di loopback.
Il corretto lavoro dei pari si ottiene solo a determinate condizioni. Cioè, i timeout TCP devono essere sufficientemente grandi o il passaggio deve essere sufficientemente veloce in modo che la sessione TCP non abbia il tempo di terminare. Tuttavia, consente un passaggio senza interruzioni.
In IaaS abbiamo un servizio costruito utilizzando la stessa tecnologia. Questo , che si chiama Ottavia. Si basa su due processi HAProxy e include inizialmente il supporto per i peer. Si sono dimostrati eccellenti in questo servizio.
L'immagine mostra schematicamente lo spostamento delle tabelle peer tra tre istanze HAProxy, viene proposta una configurazione su come configurarlo:
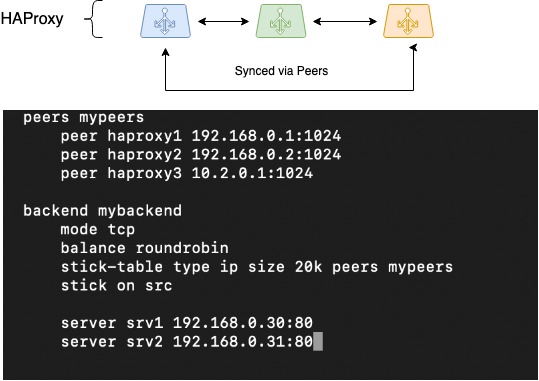
HAProxy Peers (sincronizzazione della sessione)
Se si implementa lo stesso schema, il suo funzionamento deve essere attentamente testato. Non è un dato di fatto che funzionerà allo stesso modo il 100% delle volte. Ma almeno non perderai le tabelle stick quando dovrai ricordare l'IP di origine del client.
Limitare il numero di richieste simultanee dallo stesso client
Tutti i servizi disponibili al pubblico, comprese le nostre API, possono essere soggetti a valanghe di richieste. Le ragioni possono essere completamente diverse, dagli errori degli utenti agli attacchi mirati. Periodicamente subiamo attacchi DDoS da parte degli indirizzi IP. I clienti spesso commettono errori nei loro script e ci forniscono mini-DDoS.
In un modo o nell'altro, è necessario fornire una protezione aggiuntiva. La soluzione ovvia è limitare il numero di richieste API e non sprecare tempo della CPU elaborando richieste dannose.
Per implementare tali restrizioni, utilizziamo limiti di velocità, organizzati sulla base di HAProxy, utilizzando le stesse tabelle stick. L'impostazione dei limiti è abbastanza semplice e consente di limitare l'utente in base al numero di richieste all'API. L'algoritmo ricorda l'IP di origine da cui vengono effettuate le richieste e limita il numero di richieste simultanee da parte di un utente. Naturalmente, abbiamo calcolato il profilo di carico API medio per ciascun servizio e fissato un limite di ≈ 10 volte questo valore. Continuiamo a monitorare da vicino la situazione e a tenere il passo con il polso della situazione.
Come si presenta in pratica? Abbiamo clienti che utilizzano continuamente le nostre API di scalabilità automatica. Al mattino creano dalle due alle trecento macchine virtuali e la sera le cancellano. Per OpenStack la creazione di una macchina virtuale, anche con servizi PaaS, richiede almeno 1000 richieste API, poiché l'interazione tra i servizi avviene anche tramite API.
Tale trasferimento di compiti provoca un carico abbastanza grande. Abbiamo valutato questo carico, raccolto i picchi giornalieri, li abbiamo decuplicati e questo è diventato il nostro limite di velocità. Teniamo il dito sul polso. Spesso vediamo bot e scanner che cercano di esaminarci per vedere se abbiamo script CGA che possono essere eseguiti, li stiamo tagliando attivamente.
Come aggiornare la tua codebase senza che gli utenti se ne accorgano
Implementiamo anche la tolleranza agli errori a livello dei processi di distribuzione del codice. Potrebbero verificarsi problemi durante le implementazioni, ma il loro impatto sulla disponibilità del servizio può essere ridotto al minimo.
Aggiorniamo costantemente i nostri servizi e dobbiamo garantire che la base di codice venga aggiornata senza influire sugli utenti. Siamo riusciti a risolvere questo problema utilizzando le funzionalità di gestione di HAProxy e l'implementazione di Graceful Shutdown nei nostri servizi.
Per risolvere questo problema era necessario garantire il controllo del bilanciatore e la “corretta” chiusura dei servizi:
- Nel caso di HAProxy, il controllo viene eseguito tramite un file di statistiche, che è essenzialmente un socket ed è definito nella configurazione di HAProxy. Puoi inviargli comandi tramite stdio. Ma il nostro principale strumento di controllo della configurazione è Ansible, quindi dispone di un modulo integrato per la gestione di HAProxy. Che utilizziamo attivamente.
- La maggior parte dei nostri servizi API e motori supportano tecnologie di arresto graduale: quando si spengono, attendono il completamento dell'attività corrente, che si tratti di una richiesta http o di un'attività di servizio. La stessa cosa accade con il lavoratore. Conosce tutte le attività che sta svolgendo e termina quando ha completato tutto con successo.
Grazie a questi due punti, l'algoritmo sicuro per la nostra distribuzione si presenta così.
- Lo sviluppatore assembla un nuovo pacchetto di codice (per noi questo è RPM), lo testa nell'ambiente di sviluppo, lo testa nello stage e lo lascia nel repository dello stage.
- Lo sviluppatore imposta l'attività di distribuzione con la descrizione più dettagliata degli "artefatti": la versione del nuovo pacchetto, una descrizione della nuova funzionalità e altri dettagli sulla distribuzione, se necessario.
- L'amministratore di sistema avvia l'aggiornamento. Avvia il playbook Ansible, che a sua volta esegue le seguenti operazioni:
- Prende un pacchetto dal repository dello stage e lo utilizza per aggiornare la versione del pacchetto nel repository del prodotto.
- Compila un elenco di backend del servizio aggiornato.
- Arresta il primo servizio da aggiornare in HAProxy e attende il completamento dell'esecuzione dei relativi processi. Grazie all'arresto graduale, siamo certi che tutte le richieste attuali dei clienti verranno completate con successo.
- Dopo che l'API e i lavoratori sono stati completamente arrestati e HAProxy è stato disattivato, il codice viene aggiornato.
- Ansible gestisce i servizi.
- Per ciascun servizio vengono attivate alcune "maniglie" che eseguono test unitari su una serie di test chiave predefiniti. Viene effettuato un controllo di base del nuovo codice.
- Se non sono stati rilevati errori nel passaggio precedente, il backend viene attivato.
- Passiamo al backend successivo.
- Dopo che tutti i backend sono stati aggiornati, vengono avviati i test funzionali. Se mancano, lo sviluppatore esamina eventuali nuove funzionalità che ha creato.
Questo completa la distribuzione.
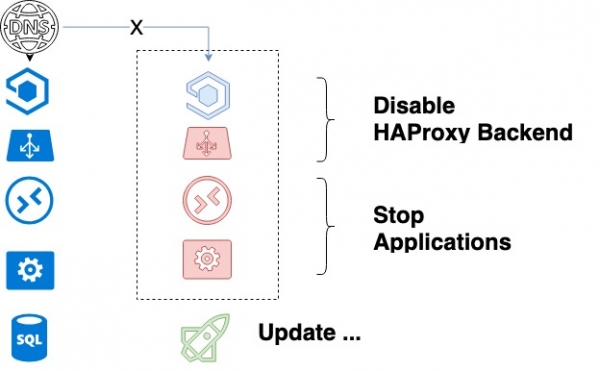
Ciclo di aggiornamento del servizio
Questo schema non funzionerebbe se non avessimo una regola. Supportiamo sia la vecchia che la nuova versione in battaglia. In anticipo, nella fase di sviluppo del software, viene stabilito che anche se vengono apportate modifiche al database del servizio, queste non interromperanno il codice precedente. Di conseguenza, la base di codice viene gradualmente aggiornata.
conclusione
Condividendo i miei pensieri su un'architettura WEB tollerante ai guasti, vorrei sottolineare ancora una volta i suoi punti chiave:
- tolleranza ai guasti fisici;
- tolleranza ai guasti di rete (bilanciatori, BGP);
- tolleranza agli errori del software utilizzato e sviluppato.
Tempo di attività stabile per tutti!
Fonte: habr.com
