


In questo articolo sono raccolti alcuni modelli comuni che aiutano gli ingegneri a lavorare con servizi su larga scala, ai quali accedono milioni di utenti.
Dall'esperienza dell'autore, non si tratta di un elenco esaustivo, ma certamente consigli efficaci. Iniziamo.
Tradotto grazie al supporto di .
Livello base
Le misure elencate di seguito sono relativamente semplici da attuare, ma forniscono un alto ritorno. Se non le hai mai adottate prima, rimarrai sorpreso dai miglioramenti significativi.
Infrastruttura come codice
La prima parte dei consigli consiste nell'implementare l'infrastruttura come codice. Ciò significa che devi avere un modo programmatico per distribuire tutta l'infrastruttura. Sembra complicato, ma in realtà stiamo parlando del seguente codice:
Distribuzione di 100 macchine virtuali
- con Ubuntu
- 2 GB di RAM ciascuna
- avranno il seguente codice
- con queste impostazioni
Puoi monitorare le modifiche all'infrastruttura e tornare rapidamente ad esse utilizzando un sistema di controllo della versione.
Il modernista che è in me dice che puoi utilizzare Kubernetes/Docker per fare tutto quanto sopra, e ha ragione.
Inoltre, puoi garantire l'automazione utilizzando Chef, Puppet o Terraform.
Integrazione continua e consegna
Per creare un servizio scalabile, è fondamentale avere una pipeline di build e test per ogni pull request. Anche se il test è semplice, garantisce almeno che il codice che stai distribuendo venga compilato.
Ogni volta in questa fase ti poni la domanda: la mia build si compilerà e supererà i test, è valida? Può sembrare un punto di partenza basso, ma risolve molti problemi.
Non c'è niente di più bello che vedere questi segni di spunta.
Per questa tecnologia puoi valutare Github, CircleCI o Jenkins.
Bilanciatori di carico
Quindi, vogliamo avviare un bilanciatore di carico per reindirizzare il traffico e garantire un carico uguale su tutti i nodi o la continuità del servizio in caso di malfunzionamento:
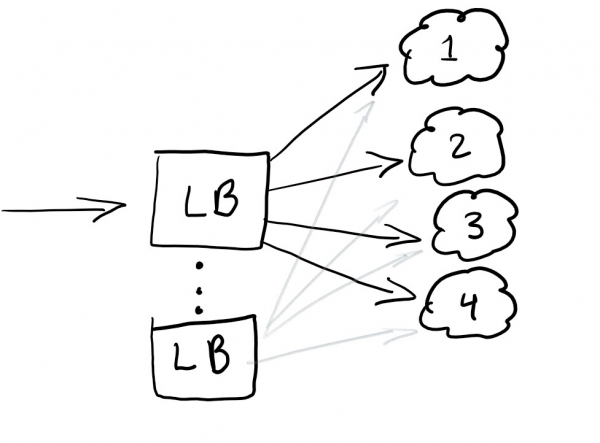
Il bilanciatore di carico aiuta generalmente a distribuire il traffico. La migliore pratica è avere una bilanciatura ridondante, in modo da non avere un unico punto di fallimento.
Di solito i bilanciatori di carico vengono configurati nel cloud che stai utilizzando.
RayID, correlation ID o UUID per le richieste
Hai mai incontrato un errore nell'app con un messaggio del tipo: «Qualcosa è andato storto. Salva questo id e invialo al nostro supporto»?
Un identificatore unico, correlation ID, RayID o qualsiasi delle sue varianti è un identificatore unico che consente di tracciare la richiesta durante il suo ciclo di vita. Questo permette di seguire l'intero percorso della richiesta nei log.
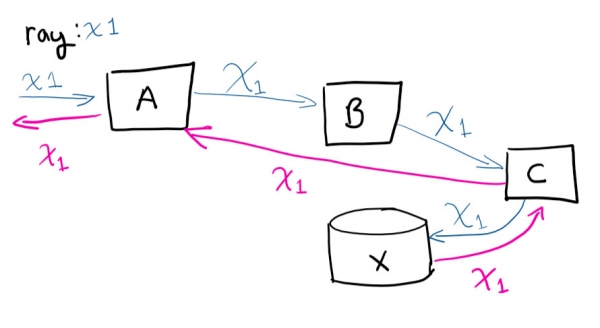
L'utente effettua una richiesta al sistema A, poi A si collega a B, che si connette a C, salva in X e poi la richiesta torna ad A
Se ti collegassi in remoto alle macchine virtuali e cercassi di tracciare il percorso della richiesta (e correlare manualmente quali chiamate avvengono), impazziresti. Avere un identificatore unico rende tutto molto più semplice. È una delle cose più semplici che puoi fare per risparmiare tempo man mano che il servizio cresce.
Livello medio
Qui i consigli sono più complessi rispetto ai precedenti, ma gli strumenti giusti semplificano il compito, garantendo un ritorno sull'investimento anche per le piccole e medie imprese.
Centralizzazione dei log
Congratulazioni! Hai distribuito 100 macchine virtuali. Il giorno successivo, il CEO arriva e si lamenta di un errore che ha ricevuto durante il test del servizio. Riporta l'identificativo corrispondente di cui abbiamo parlato sopra, ma dovrai esaminare i log di 100 macchine per trovare quella che ha causato il fallimento. E deve essere trovata prima della presentazione di domani.
Anche se sembra un'avventura divertente, è meglio assicurarsi di avere la possibilità di cercare in tutti i log da un unico luogo. Ho risolto il problema della centralizzazione dei log utilizzando la funzionalità integrata del stack ELK: qui è supportata la raccolta dei log con capacità di ricerca. Questo aiuterà davvero a risolvere il problema di trovare un log specifico. Come bonus, puoi creare diagrammi e altre cose divertenti.
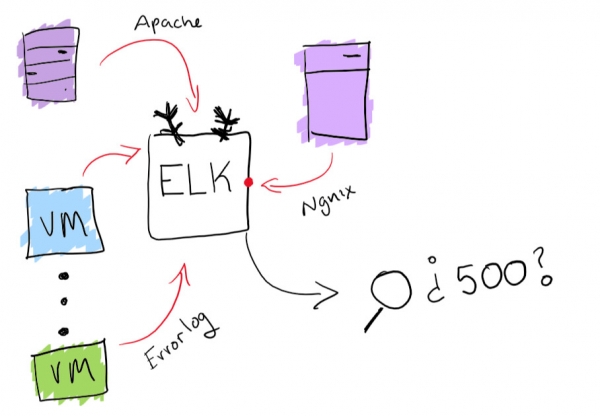
Funzionalità del stack ELK
Agenti di monitoraggio
Ora che il tuo servizio è operativo, devi assicurarti che funzioni senza interruzioni. Il modo migliore per farlo è avviare diversi agenti, che lavorano in parallelo e controllano che funzioni e che le operazioni di base vengano eseguite.
In questa fase, verifichi che la build avviata funzioni correttamente e operi senza problemi..
Per piccoli e medi progetti, consiglio Postman per il monitoraggio e la documentazione delle API. In generale, è importante avere un modo per sapere quando si verifica un errore e ricevere notifiche tempestive.
Autoscaling basato sul carico
È molto semplice. Se hai una macchina virtuale che gestisce le richieste e si avvicina all'80% della memoria occupata, puoi aumentare le sue risorse o aggiungere più macchine virtuali al cluster. L'automazione di queste operazioni è perfetta per il cambiamento elastico della potenza in base al carico. Ma devi sempre prestare attenzione a quanto spendi e impostare limiti ragionevoli.
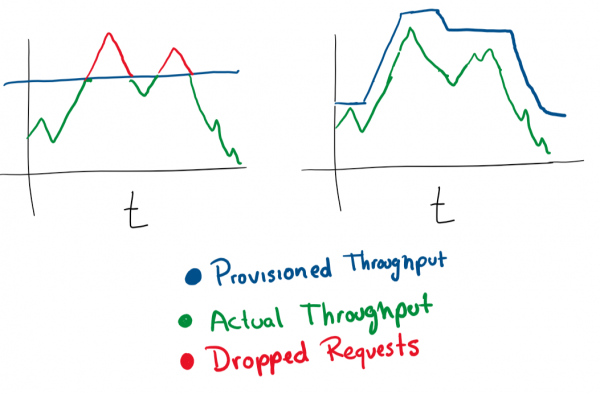
Nella maggior parte dei servizi cloud, puoi configurare l'autoscaling utilizzando un numero maggiore di server o server più potenti.
Sistema di esperimenti
Un buon modo per implementare aggiornamenti in modo sicuro è la possibilità di testare qualcosa per l'1% degli utenti in un'ora. Avrete sicuramente visto meccanismi simili in azione. Ad esempio, Facebook mostra a una parte del pubblico un colore diverso o cambia la dimensione del carattere per vedere come gli utenti percepiscono le modifiche. Questo è noto come A/B testing.
Anche il rilascio di una nuova funzionalità può essere avviato come esperimento e poi si può determinare come rilasciarla. Inoltre, si ha la possibilità di «ricordare» o modificare la configurazione al volo in base a una funzione che causa degrado del servizio.
Livello avanzato
Qui ci sono consigli che sono piuttosto difficili da realizzare. Probabilmente avrete bisogno di un po' più di risorse, quindi sarà difficile per una piccola o media azienda gestirli.
Distribuzioni blue-green
Questo è ciò che chiamo il modo «Erlang» di distribuire. Erlang è stato ampiamente utilizzato con l'emergere delle compagnie telefoniche. I commutatori software sono stati impiegati per la gestione delle chiamate telefoniche. La principale funzione del software di questi commutatori era quella di non interrompere le chiamate durante l’aggiornamento del sistema. Erlang ha un ottimo modo di caricare un nuovo modulo senza far cadere quello precedente.
Questo passaggio dipende dalla disponibilità di un bilanciatore di carico. Immaginiamo di avere la versione N del vostro software e di voler distribuire la versione N+1.
Tu potresti semplicemente fermare il servizio e distribuire la versione successiva nel momento che ritieni più conveniente per i tuoi utenti, ricevendo così un certo tempo di inattività. Ma supponiamo di avere davvero condizioni SLA rigorose. Un SLA del 99,99% significa che puoi essere offline solo per 52 minuti all'anno.
Se desideri veramente raggiungere tali risultati, sono necessarie due distribuzioni contemporaneamente:
- quella attuale (N);
- la versione successiva (N+1).
Indicate to the load balancer to redirect a percentage of traffic to the new version (N+1), while actively monitoring for regressions.
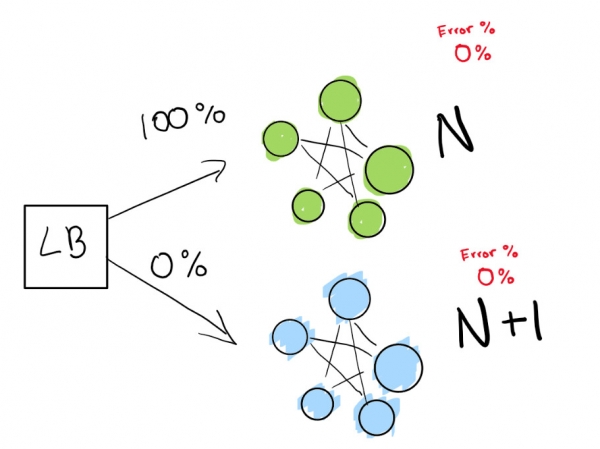
Here we have a green deployment N that is functioning normally. We are trying to transition to the next version of this deployment.
First, we send a really small test to see if our deployment N+1 works with a small amount of traffic:
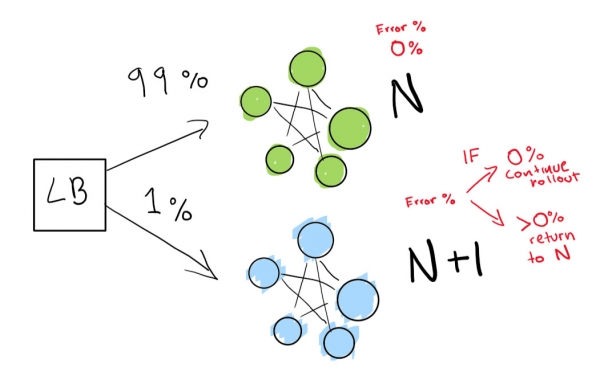
Finally, we have a set of automated checks that we ultimately run until our deployment is complete. If you are very, very cautious, you can also keep your deployment N forever for a quick rollback in case of a bad regression:
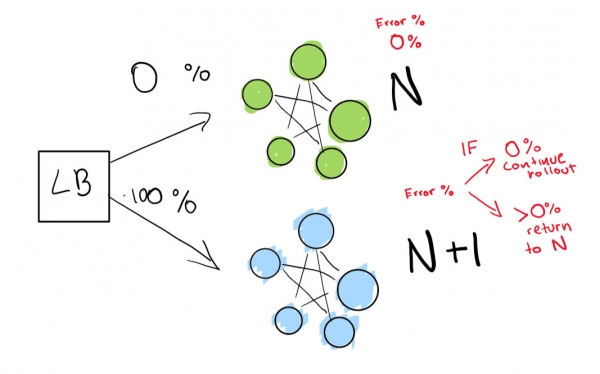
If you want to elevate to an even more advanced level, let everything in the blue-green deployment run automatically.
Anomaly detection and automatic mitigation.
Considerando che avete una gestione centralizzata dei log e una buona raccolta dei log, potete già puntare a obiettivi più ambiziosi. Ad esempio, prevedere proattivamente i guasti. Sulle dashboard e nei log vengono monitorati i vari aspetti e costruiti diversi grafici, permettendo di prevedere in anticipo cosa potrebbe andare storto:
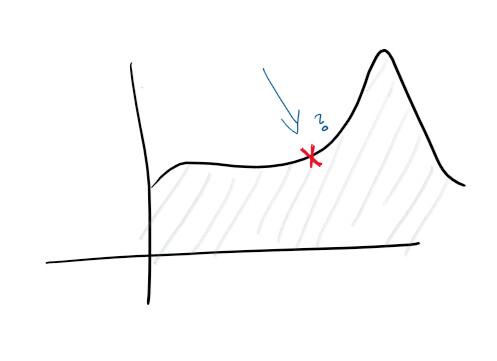
Con la rilevazione delle anomalie iniziate ad esplorare alcuni indizi forniti dal servizio. Ad esempio, un picco nel carico della CPU può indicare che il disco rigido sta fallendo, mentre un aumento nel numero delle richieste significa che è necessario scalare. Questo tipo di dati statistici rende il servizio proattivo.
Ricevendo queste informazioni analitiche, potete scalare in qualsiasi dimensione, modificare proattivamente e reattivamente le caratteristiche delle macchine, dei database, delle connessioni e di altre risorse.
Ecco fatto!
Questa lista di priorità vi aiuterà a evitare molti problemi se state avviando un servizio cloud.
L'autore dell'articolo originale invita i lettori a lasciare i propri commenti e apportare modifiche. L'articolo è distribuito come open source, le pull request dell'autore .
Cosa leggere ancora sull'argomento:
Fonte: habr.com
