

Introduzione
È tempo di acquistare un sistema di archiviazione. Quale scegliere e di chi fidarsi? Il fornitore A parla del fornitore B, ma c'è anche l'integratore C, che racconta il contrario e consiglia il fornitore D. In questa situazione, anche un architetto esperto di sistemi di archiviazione si sentirà confuso, soprattutto con tutti i nuovi fornitori e le attuali tendenze come SDS e l'iperconvergenza.
Quindi, come orientarsi in tutto questo e non trovarsi in difficoltà? Noi ( Anton Zhbankov e Evgeny Elizarov) cercheremo di spiegarlo in modo semplice.
L'articolo è in gran parte correlato ed è infatti un'estensione di “” per quanto riguarda la scelta dei sistemi di archiviazione e una panoramica delle tecnologie per i sistemi di archiviazione. Daremo un'occhiata alla teoria generale, ma vi consigliamo di consultare anche l'articolo menzionato.
Perché
Spesso si osserva la situazione in cui un nuovo arrivato entra in un forum o in una chat specializzata, come ad esempio Storage Discussions, e pone la domanda: “mi vengono offerti due sistemi di archiviazione — ABC SuperStorage S600 e XYZ HyperOcean 666v4, quale consigliate?”
E inizia a emergere chi ha quali caratteristiche di implementazione di funzioni spaventose e incomprensibili, che per una persona non preparata sono del tutto come la grammatica cinese.
Quindi, la domanda chiave e la prima a cui bisogna rispondere molto prima di confrontare le specifiche nelle offerte commerciali è: PERCHÉ? A cosa serve questo sistema di archiviazione?

La risposta sarà inaspettata e molto nello stile di Tony Robbins: per archiviare i dati. Grazie, capitano! Tuttavia, a volte ci immergiamo così tanto nel confronto dei dettagli che dimentichiamo perché stiamo facendo tutto questo.
Dunque, l'obiettivo di un sistema di archiviazione dei dati è quello di memorizzare e fornire accesso ai DATI con determinate prestazioni. Iniziamo dai dati.
Dati
Tipo di dato
Quali dati intendiamo conservare? È una domanda molto importante che può escludere molte soluzioni di storage dalla considerazione. Ad esempio, è prevista la memorizzazione di video e fotografie. Possiamo quindi escludere i sistemi progettati per accesso casuale a piccoli blocchi, o sistemi con funzionalità proprietarie in compressione / deduplicazione. Questi possono essere ottimi sistemi, non vogliamo dire nulla di negativo. Ma in questo caso i loro punti di forza potrebbero diventare anzi punti deboli (video e foto non possono essere compressi) o semplicemente aumentare notevolmente il costo del sistema.
E viceversa, se l'uso previsto è un sistema di database transazionale carico, allora ottimi sistemi di streaming per multimedia, in grado di erogare gigabyte al secondo, saranno una cattiva scelta.
Volume dei dati
Quanti dati prevediamo di conservare? La quantità si trasforma sempre in qualità, e questo non va mai dimenticato, soprattutto in un'epoca di crescita esponenziale del volume dei dati. I sistemi di classe petabyte non sono più una rarità, ma più il volume in petabyte aumenta, più il sistema diventa specifico, limitando le funzionalità abituali dei sistemi di accesso casuale a bassa e media capacità. Questo avviene perché solo le tabelle delle statistiche di accesso per blocchi diventano più grandi della memoria RAM disponibile nei controller. Senza contare la compressione / tiering. Supponiamo di voler passare a un algoritmo di compressione più potente e comprimere 20 petabyte di dati. Quanto tempo ci vorrà: sei mesi, un anno?
D'altra parte, perché complicare le cose se dobbiamo conservare e gestire solo 500 GB di dati? Solo 500. Gli SSD consumer (con un basso DWPD) di tale capacità hanno costi irrisori. Perché costruire una fabbrica Fiber Channel e acquistare un'archiviazione SAN esterna di alta classe, spendendo quanto un ponte in ghisa?
Qual è la percentuale di dati caldi rispetto al volume totale? Quanto è irregolare il carico in funzione del volume dei dati? La tecnologia di archiviazione multi-livello o Flash Cache può essere molto utile se il volume dei dati caldi è trascurabile rispetto al totale. D'altra parte, in caso di un carico uniforme su tutto il volume, spesso presente nei sistemi in streaming (videosorveglianza, alcuni sistemi di analisi), tali tecnologie non apporteranno benefici e aumenteranno solo i costi / la complessità del sistema.
IS
Il retro dei dati è il sistema informativo che utilizza questi dati. L'IS ha un insieme di requisiti che derivano dai dati. Maggiori dettagli sull'IS si trovano in "Progettazione del Data Center virtualizzato".
Requisiti di tolleranza ai guasti / disponibilità
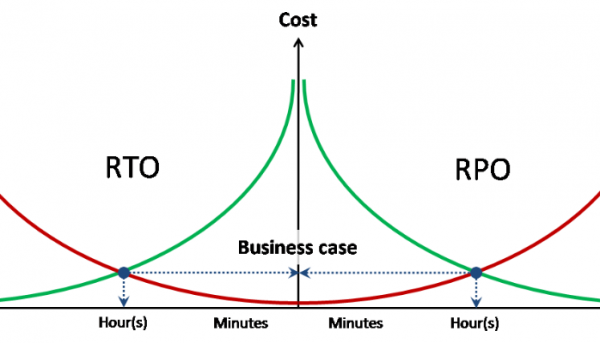
I requisiti di tolleranza ai guasti / disponibilità dei dati vengono ereditati dall'IS che li utilizza e sono espressi in tre numeri — RPO, RTO, disponibilità.
Disponibilità — percentuale di tempo durante il quale i dati sono disponibili per l'elaborazione. È generalmente espressa in numero di 9. Ad esempio, due nove in un anno означano che la disponibilità è del 99%, ossia è consentito un massimo di 95 ore di inattività all'anno. Tre nove corrispondono a 9,5 ore all'anno.
RPO / RTO — questi indicatori non sono cumulativi, ma si riferiscono a ciascun incidente (guasto), a differenza della disponibilità.
RPO — volume di dati persi in caso di incidente (in ore). Ad esempio, se il backup avviene una volta al giorno, RPO = 24 ore. Cioè, in caso di guasto e completa perdita dello storage, possono andare persi dati fino a 24 ore (dalla data dell'ultimo backup). Sulla base del RPO definito per il sistema informatico, si redige anche un regolamento per il backup. Inoltre, in base al RPO, si può determinare se è necessaria una replica dati sincrona / asincrona.
RTO — tempo necessario per ripristinare il servizio (accesso ai dati) dopo un guasto. In base al valore RTO definito, possiamo capire se è necessario un metrocluster, o se è sufficiente una replica unidirezionale. È necessaria anche una storage ad elevate prestazioni con controllori multipli?
Requisiti di prestazioni
Nonostante sia una questione piuttosto ovvia, è proprio qui che sorgono la maggior parte delle difficoltà. A seconda che si disponga già di un'infrastruttura o meno, si definiranno i percorsi per raccogliere le statistiche necessarie.
Se già possedete uno storage e state cercando una sostituzione o desiderate acquistarne un'altra per espandere la vostra capacità, la situazione è chiara. Siete a conoscenza dei servizi che già avete e di quelli che prevedete di implementare a breve. Basandovi sui servizi attuali, potete raccogliere statistiche sulle prestazioni. Dovete capire quanti IOPS sono necessari e quali sono i tempi di latenza attuali: sono sufficienti per le vostre esigenze? È possibile ottenere queste informazioni sia dal sistema di storage che dai server ad esso connessi.
È importante monitorare non solo il carico attuale, ma anche su un certo periodo (meglio se un mese). Controlla quali sono i picchi massimi durante il giorno, quale carico genera il backup, ecc. Se il tuo sistema di archiviazione o il software non ti forniscono un set completo di questi dati, puoi utilizzare il gratuito RRDtool, che è in grado di lavorare con la maggior parte dei sistemi di archiviazione e degli switch più popolari e ti fornirà statistiche dettagliate sulle prestazioni. È anche utile controllare il carico sugli host che lavorano con questo sistema di archiviazione, riguardo a specifiche macchine virtuali o cosa sta funzionando su quel host.
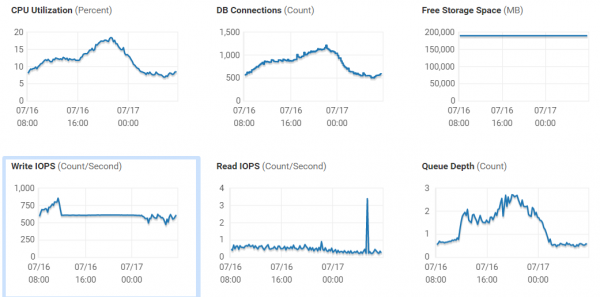
Vale la pena sottolineare che se i ritardi nel volume e nel datastore associato a questo volume differiscono notevolmente, è opportuno prestare attenzione alla tua rete SAN; c'è un'alta probabilità che ci siano problemi e, prima di acquistare un nuovo sistema, è meglio risolvere questa questione, poiché c'è una forte possibilità di migliorare le prestazioni del sistema attuale.
Stai costruendo un'infrastruttura da zero o stai acquisendo un sistema per un nuovo servizio di cui non conosci i carichi. Ci sono diverse opzioni: parlare con i colleghi su risorse specializzate per cercare di capire e prevedere i carichi, contattare un integratore che ha esperienza nell'implementazione di servizi simili e che può calcolare i carichi per te. E la terza opzione (di solito la più complessa, soprattutto se riguarda applicazioni personalizzate o rare) è cercare di scoprire i requisiti di prestazione dai programmatori del sistema.
E, attenzione, l'opzione più corretta dal punto di vista pratico è un pilotaggio sull'attuale attrezzatura o su attrezzatura fornita per la prova dal venditore/integratore.
Requisiti speciali
I requisiti speciali sono tutte quelle specifiche che non rientrano nei requisiti di prestazione, disponibilità e funzionalità per l'elaborazione diretta e la fornitura dei dati.
Uno dei requisiti speciali più semplici per un sistema di archiviazione dati è quello dei "supporti di informazione trasferibili". È quindi chiaro che questo sistema di archiviazione deve includere una libreria a nastro o un semplice streamer, su cui viene effettuato un backup. Dopo di che, un operatore appositamente addestrato firma il nastro e lo porta con orgoglio in una cassaforte speciale.
Un altro esempio di requisito speciale è l'esecuzione resistente agli urti e protetta.
Dove
Il secondo elemento fondamentale nella scelta di un certo tipo di SХD è l'informazione su DOVE sarà posizionata questa SХD. Partendo dalla geografia o dalle condizioni climatiche, fino al personale.
Committente
Per chi è prevista questa SХD? Questa domanda si basa sui seguenti motivi:
Committente pubblico / commerciale.
Il committente commerciale non ha alcuna restrizione e non è nemmeno obbligato a svolgere gare, tranne che per le proprie normative interne.
Il committente pubblico è un'altra questione. 44 FZ e altre complessità con le gare e i requisiti tecnici, che possono essere contestati.
Committente soggetto a sanzioni
La questione è molto semplice: la scelta si limita solo alle offerte disponibili per questo cliente.
Regolamenti interni / fornitori autorizzati / modelli
Anche la domanda è estremamente semplice, ma è importante tenerne conto.
Dove fisicamente
In questa parte consideriamo tutte le questioni relative alla geografia, ai canali di comunicazione e al microclima nel luogo di collocazione.
Personale
Chi lavorerà con questo sistema di archiviazione dei dati? Questo è altrettanto importante quanto le funzionalità del sistema stesso.
Nonostante le potenzialità e la qualità del sistema del fornitore A, potrebbe non avere senso utilizzarlo se il personale sa lavorare solo con il fornitore B e non sono previsti acquisti futuri o collaborazioni con A.
E ovviamente, c'è l'altra faccia della medaglia: quanto è disponibile in questa posizione geografica il personale qualificato direttamente in azienda e potenzialmente sul mercato del lavoro. Per le regioni potrebbe avere un significato rilevante scegliere soluzioni di storage con interfacce semplici o la possibilità di gestione centralizzata remota. Altrimenti, a un certo punto potrebbe diventare un reale problema. Internet è pieno di storie su come un nuovo dipendente, un neolaureato, ha configurato in modo tale che l'intera azienda sia andata in crisi.

Ambiente
E naturalmente, una questione altrettanto importante è: in quale ambiente funzionerà questo sistema di storage.
- Che dire dell'alimentazione elettrica / raffreddamento?
- Quale connessione?
- Dove sarà installato?
- E così via.
Spesso queste domande sono considerate ovvie e non esaminate in modo particolare, ma a volte sono proprio queste a poterci stravolgere tutto di 180 gradi.
Cosa
Fornitore
Ad oggi (metà 2019) il mercato russo dei sistemi di storage può essere diviso in 5 categorie convenzionali:
- Divisione superiore: aziende consolidate con una vasta gamma che va dalle semplici unità disco fino a soluzioni hi-end (HPE, DellEMC, Hitachi, NetApp, IBM / Lenovo)
- Second division — companies with a limited product range, niche players, serious SDS vendors, or emerging newcomers (Fujitsu, Datacore, Infinidat, Huawei, Pure, etc.)
- Third division — niche solutions in the low-end range, cheap SDS, improvised builds on Ceph and other open projects (Infortrend, Starwind, etc.)
- SOHO segment — small and ultra-small storage systems designed for home or small office use (Synology, QNAP, etc.)
- Import-substituted storage systems — this includes first division hardware with rebranded labels as well as some rare second division representatives (RAIDIX, we’ll give them a head start in the second division), but mainly this falls within the third division (Aerodisk, Baum, Depo, etc.)
The division is quite conditional, and does not imply that the third or SOHO segments are inferior or unusable. In specific projects with a clearly defined data set and workload profile, they can perform very well, greatly surpassing the first division in terms of price/quality ratio. It is important to first determine the tasks, growth prospects, and required functionality — and then Synology will serve you faithfully, making your hair soft and silky.
Uno dei fattori importanti nella scelta di un fornitore è l'ambiente attuale. Quanti e quali sistemi di storage hai già, con quali sistemi possono lavorare gli ingegneri? Hai bisogno di un altro fornitore, di un altro punto di contatto? Prevedi di migrare gradualmente tutto il carico dal fornitore A al fornitore B?
Non bisognerebbe generare entità oltre il necessario.
iSCSI / FC / File
Non esiste un'opinione univoca tra gli ingegneri riguardo ai protocolli di accesso, e le dispute assomigliano più a discussioni teologiche che a dibattiti ingegneristici. Tuttavia, si possono sottolineare i seguenti punti:
FCoE è più morto che vivo.
FC vs iSCSI. Uno dei vantaggi chiave di FC nel 2019 rispetto agli storage IP, una rete dedicata per l'accesso ai dati, è annullato da una rete IP dedicata. Non ci sono vantaggi globali di FC rispetto alle reti IP e su IP si possono costruire storage di qualsiasi livello di carico, fino ai sistemi per database pesanti per la core banking di grandi banche. D'altra parte, la morte di FC è stata profetizzata per anni, ma qualcosa sembra sempre opporsi a questo. Oggi, ad esempio, alcuni attori del mercato storage stanno attivamente sviluppando lo standard NVMEoF. Se questo dividerà il destino di FCoE, solo il tempo potrà dirlo.
Accesso ai file non è affatto trascurabile. NFS / CIFS si comportano benissimo in ambienti produttivi e, se progettati correttamente, presentano non più problemi rispetto ai protocolli a blocchi.
Ibridi / All Flash Array
Le SAN classiche sono di 2 tipi:
- AFA (All Flash Array) — sistemi ottimizzati per l'utilizzo di SSD.
- Ibridi — che permettono di utilizzare sia HDD che SSD o una loro combinazione.
La principale differenza tra queste tecnologie è l'efficienza di archiviazione supportata e il massimo livello di prestazioni (elevati valori di IOPS e basse latenze). Entrambi i sistemi (nella maggior parte dei loro modelli, esclusi i segmenti low-end) possono funzionare sia come dispositivi a blocchi che come file. Il livello del sistema determina le funzionalità supportate, e nei modelli inferiori, esse sono spesso ridotte al minimo. È importante prestare attenzione a questo aspetto quando si esaminano le specifiche di un determinato modello, piuttosto che limitarsi a considerare le capacità dell'intera gamma. Anche le specifiche tecniche del sistema, come il processore, la quantità di memoria, la cache, il numero e i tipi di porte, dipendono dal livello del sistema. Dal punto di vista della gestione dello storage, gli AFA si differenziano dai sistemi ibridi (disk-based) solo nelle modalità di implementazione dei meccanismi di lavoro con gli SSD, e anche se si usano SSD in un sistema ibrido, ciò non significa che si possa ottenere il livello di prestazioni tipico di un sistema AFA. Inoltre, nella maggior parte dei casi, i meccanismi inline di archiviazione efficace nei sistemi ibridi sono disattivati, e la loro attivazione porta a una perdita di prestazioni.
Storage specializzati
Oltre agli storage di uso generale, progettati principalmente per l'elaborazione dei dati in tempo reale, esistono storage specializzati con principi chiave fondamentalmente diversi da quelli abituali (bassa latenza, alto numero di IOPS):
Media.
Questi sistemi sono progettati per l'archiviazione e l'elaborazione di file multimediali, caratterizzati da dimensioni elevate. Di conseguenza, la latenza diventa praticamente irrilevante, mentre la capacità di inviare e ricevere dati con un'ampia larghezza di banda in molti flussi paralleli assume un'importanza primaria.
Storage deduplicati per backup.
Poiché i backup tendono ad avere una somiglianza rara in condizioni normali (un backup medio si differenzia da quello di ieri dell'1-2%), questa classe di sistemi comprime estremamente in modo efficiente i dati registrati su un numero relativamente ridotto di supporti fisici. In alcuni casi, i tassi di compressione dei dati possono raggiungere 200 a 1.
Storage a oggetti.
Questi sistemi di archiviazione non presentano volumi tradizionali con accesso a blocchi e file condivisi, ma più che altro somigliano a un enorme database. L'accesso a un oggetto memorizzato in un sistema del genere avviene tramite un identificatore unico o metadati (ad esempio, tutti gli oggetti in formato JPEG, con data di creazione tra XX-XX-XXXX e YY-YY-YYYY).
Sistemi di compliance.
Non sono così comuni in Russia al giorno d'oggi, ma è utile menzionarli. Lo scopo di tali sistemi di archiviazione è la conservazione garantita dei dati per rispettare le politiche di sicurezza o i requisiti dei regolatori. In alcuni sistemi (ad esempio, EMC Centera) è stata implementata una funzione di divieto di cancellazione dei dati: una volta che la chiave è stata ruotata e il sistema è passato a questa modalità, né l'amministratore né chiunque altro possono fisicamente eliminare i dati già registrati.
Tecnologie proprietarie
Cache Flash
Flash Cache è un termine generico per tutte le tecnologie proprietarie che utilizzano la memoria flash come cache di secondo livello. L'uso della cache flash negli sistemi di archiviazione è generalmente progettato per gestire il carico stabilito dai dischi magnetici, mentre i picchi sono gestiti dalla cache.
È importante comprendere il profilo del carico e il grado di localizzazione delle richieste ai blocchi dei volumi di archiviazione. La flash cache è una tecnologia per carichi con alta localizzazione delle richieste, e praticamente non è applicabile per volumi uniformemente caricati (come ad esempio nei sistemi di analisi).
Nel mercato sono disponibili due implementazioni della cache flash:
- Sola lettura. In questo caso vengono memorizzati nella cache solo i dati in lettura, mentre la scrittura avviene direttamente sui dischi. Alcuni produttori, come NetApp, ritengono che la scrittura sui loro sistemi di archiviazione avvenga già in modo ottimale, e che la cache non offra alcun vantaggio.
- Lettura/Scrittura. Viene memorizzato nella cache non solo il caricamento, ma anche la scrittura, permettendo di bufferizzare il flusso e ridurre l'impatto del RAID Penalty, aumentando così le prestazioni complessive per sistemi di archiviazione con meccanismi di scrittura non ottimali.
Tiering
Lo storage a più livelli (tiering) è una tecnologia che combina in un'unica pool di dischi livelli con prestazioni differenti, come SSD e HDD. In caso di forti disomogenità negli accessi ai blocchi di dati, il sistema sarà in grado di riequilibrare automaticamente i blocchi di dati, spostando quelli sovraccarichi a un livello ad alte prestazioni, mentre quelli meno utilizzati su uno più lento.
I sistemi ibridi di fascia bassa e media utilizzano lo storage multistrato con il movimento dei dati tra i livelli programmato. In questo contesto, la dimensione del blocco di storage multistrato nei migliori modelli è di 256 MB. Queste caratteristiche non permettono di considerare la tecnologia dello storage multistrato come una tecnologia per migliorare le prestazioni, come erroneamente pensano in molti. Lo storage multistrato nei sistemi di fascia bassa e media è una tecnologia di ottimizzazione dei costi di storage per sistemi con carico di lavoro chiaramente irregolare.
Snapshot
Per quanto ne parliamo, la resilienza dei sistemi di archiviazione offre molteplici opportunità di perdere dati che non dipendono da problemi hardware. Questi possono includere virus, hacker o qualsiasi altra cancellazione/danneggiamento accidentale dei dati. Per questo motivo, il backup dei dati produttivi è una parte integrante del lavoro di un ingegnere.
Uno snapshot è un'immagine di un volume in un dato momento. Quando lavoriamo con la maggior parte dei sistemi, come la virtualizzazione e i database, è necessario creare uno snapshot da cui copieremo i dati nel backup, mentre i nostri sistemi informatici possono continuare a lavorare tranquillamente con quel volume. Tuttavia, è importante ricordare che non tutti gli snapshot sono ugualmente utili. I vari fornitori adottano approcci diversi per la creazione di snapshot, legati alla loro architettura.
CoW (Copy-On-Write). Quando si tenta di registrare un blocco di dati, il suo contenuto originale viene copiato in un'area speciale, dopodiché la registrazione avviene normalmente. In questo modo si previene il danneggiamento dei dati all'interno dello snapshot. Naturalmente, tutte queste manovre «parassitarie» sui dati comportano un carico aggiuntivo sullo storage e, per questo motivo, i fornitori con tale implementazione sconsigliano l'uso di più di dieci snapshot, e di non usarli affatto su volumi ad alta domanda.
RoW (Redirect-on-Write). In questo caso, il volume originale viene naturalmente congelato, e quando si tenta di registrare un blocco di dati, lo storage scrive i dati in un'area speciale dello spazio libero, modificando la posizione di questo blocco nella tabella delle meta-dati. Ciò consente di ridurre il numero di operazioni di riscrittura, il che alla fine mitiga la caduta delle prestazioni e rimuove le limitazioni sugli snapshot e sul loro numero.
Gli snapshot possono anche essere di due tipi in relazione alle applicazioni:
Application consistent. Al momento della creazione dello snapshot, il sistema di archiviazione interpella l'agente nel sistema operativo del consumatore, il quale fornisce forzatamente il rilascio delle cache su disco e costringe l'applicazione a farlo. In questo caso, al ripristino dallo snapshot, i dati saranno coerenti.
Coerenza in caso di crash. In questo caso, non accade nulla di simile e lo snapshot viene creato così com'è. Al ripristino da tale snapshot, la situazione è identica a quando si interrompe improvvisamente l'alimentazione e potrebbero esserci alcune perdite di dati, bloccati nelle cache e mai scritti su disco. Questi snapshot sono più facili da implementare e non causano cali di prestazioni nelle applicazioni, ma sono meno affidabili.
A cosa servono gli snapshot nei sistemi di archiviazione dati?
- Backup senza agente direttamente dallo storage
- Creazione di ambienti di test basati su dati reali
- Nel caso degli storage a file, può essere utilizzato per creare ambienti VDI utilizzando snapshot dello storage anziché ipervisor
- Garantire RPO bassi tramite la creazione di snapshot programmati con una frequenza significativamente superiore a quella del backup
Clonazione
Il cloning del volume funziona secondo principi simili a quelli degli snapshot, ma non si limita alla lettura dei dati, bensì consente una gestione completa degli stessi. Possiamo ottenere una copia esatta del nostro volume, con tutti i dati in esso contenuti, senza realizzare una copia fisica, il che permette di risparmiare spazio. Di solito, il cloning dei volumi viene utilizzato in contesti di Test & Dev o se si desidera verificare la funzionalità di alcuni aggiornamenti sulla propria infrastruttura. Il cloning consente di farlo in modo rapido ed economico in termini di risorse di disco, poiché verranno registrati solo i blocchi di dati modificati.
Replicazione / Journaling
La replicazione è un meccanismo per creare copie dei dati su un'altra unità di archiviazione fisica. Di norma, ogni fornitore ha una tecnologia proprietaria che funziona solo all'interno della sua linea di prodotti. Tuttavia, esistono anche soluzioni di terze parti, comprese quelle che operano a livello di hypervisor, come ad esempio VMware vSphere Replication.
Le funzionalità delle tecnologie proprietarie e la loro facilità d'uso superano di gran lunga quelle universali, ma risultano inapplicabili quando, ad esempio, è necessario replicare da NetApp a HP MSA.
La replica si suddivide in due tipi:
Sincrona. Nel caso della replica sincrona, l'operazione di scrittura viene inviata immediatamente al secondo sistema di archiviazione e l'esecuzione non viene confermata fino a quando il sistema remoto non conferma. Ciò aumenta la latenza, ma abbiamo una copia speculare esatta dei dati. Quindi, RPO = 0 in caso di perdita del sistema principale.
Asincrona. Le operazioni di scrittura vengono eseguite solo sul sistema principale e vengono confermate immediatamente, accumulandosi nel contempo in un buffer per la trasmissione a pacchetto al sistema remoto. Questo tipo di replica è pertinente per dati meno critici o per canali a bassa capacità o con alta latenza (tipico per distanze superiori ai 100 km). Di conseguenza, RPO = in base alla frequenza di invio a pacchetto.
Spesso, insieme alla replica, esiste un meccanismo di journalizzazione operazioni disco. In questo caso viene riservata un'area speciale per il logging e vengono memorizzate le operazioni di scrittura a una certa profondità temporale o limitate dalla dimensione del log. Per alcune tecnologie proprietarie, come EMC RecoverPoint, esiste un'integrazione con il software di sistema che consente di associare specifici segnalibri a una particolare registrazione nel log. Grazie a ciò è possibile ripristinare lo stato del volume (o crearne un clone) non solo al 23 aprile alle 11 ore 59 minuti 13 millisecondi, ma a un momento precedente a “DROP ALL TABLES; COMMIT”.
Metro cluster
Il metro cluster è una tecnologia che consente di creare una replicazione bidirezionale sincrona tra due SAN in modo tale che questa coppia appaia come un'unica SAN. Viene utilizzato per creare cluster con bracci geograficamente separati su distanze metropolitane (meno di 100 km).
Ad esempio, utilizzando l'ambiente di virtualizzazione, il metrocluster consente di creare uno datastore con macchine virtuali accessibile in scrittura da due data center contemporaneamente. In questo caso, si crea un cluster a livello di ipervisori, composto da host situati in diversi data center fisici, connessi a questo datastore. Questo consente di ottenere quanto segue:
- Automazione completa del processo di ripristino dopo il fallimento di uno dei data center. Senza alcun mezzo aggiuntivo, tutte le VM che operavano nel data center andato offline verranno automaticamente riavviate in quello rimanente. RTO = timeout del cluster ad alta disponibilità (15 secondi per VMware) + tempo di avvio del sistema operativo e avvio dei servizi.
- Disaster avoidance, o in italiano, evitare catastrofi. Se sono programmati lavori di alimentazione nel data center 1, abbiamo la possibilità di migrare in anticipo, prima dell'inizio dei lavori, tutto il carico critico nel data center 2 senza interruzioni.
Virtualizzazione
La virtualizzazione dello storage è l'uso tecnico di volumi di un altro storage come dischi. Un virtualizzatore di storage può semplicemente dedicare un volume esterno all'utente come proprio, specchiandolo su un altro storage o addirittura creare un RAID da volumi esterni.
I rappresentanti classici della virtualizzazione dello storage sono EMC VPLEX e IBM SVC. E naturalmente, gli storage con funzionalità di virtualizzazione come NetApp, Hitachi, IBM / Lenovo Storwize.
A cosa può servire?
- Riserva a livello di storage. Viene creato uno specchio tra i volumi, con una metà su HP 3Par e l'altra su NetApp. E il virtualizzatore di EMC.
- Migrazione dei dati con un minimo di inattività tra storage di diversi produttori. Supponiamo che i dati debbano essere migrati da un vecchio 3Par, che sarà dismesso, a un nuovo Dell. In questo caso, gli utenti vengono disconnessi dal 3Par, i volumi vengono dedicati al VPLEX e poi presentati di nuovo agli utenti. Poiché non è stata modificata alcuna informazione nel volume, il lavoro continua. In background, viene avviato il processo di specchiatura del volume sul nuovo Dell e, al termine, lo specchio viene distrutto e il 3Par disconnesso.
- Organizzazione di metacluster.
Compressione / deduplicazione
La compressione e la deduplicazione sono tecnologie che consentono di risparmiare spazio su disco nel tuo sistema di archiviazione. È importante notare che non tutti i dati possono essere compressi e/o deduplicati; alcuni tipi di dati si comprimono e si deduplicano meglio, mentre altri fanno il contrario.
La compressione e la deduplicazione possono essere di 2 tipi:
Inline — la compressione e la deduplicazione dei blocchi di dati avviene prima della loro scrittura su disco. In questo modo, il sistema calcola solo l'hash del blocco e lo confronta con la tabella contenente quelli già esistenti. Questo processo è più veloce rispetto alla semplice scrittura su disco e ci permette di risparmiare spazio su disco.
Post — quando queste operazioni vengono eseguite sui dati già registrati, che si trovano sul disco. Dunque, i dati vengono prima scritti su disco e solo successivamente viene calcolato l'hash e avviene l'eliminazione dei blocchi superflui, liberando risorse di archiviazione.
È importante notare che la maggior parte dei fornitori utilizza entrambi i tipi, il che consente di ottimizzare questi processi e aumentarne l'efficienza. La maggior parte dei fornitori di storage ha disponibili strumenti che permettono di analizzare i vostri set di dati. Questi strumenti funzionano secondo la stessa logica implementata nello storage, quindi il livello di valutazione dell'efficienza sarà coincidente. Non va dimenticato che molti fornitori offrono programmi di garanzia dell'efficienza, che promettono un livello non inferiore a quello dichiarato per un certo (o per tutti) tipi di dati. Non sottovalutate questi programmi, poiché progettando un sistema per le vostre esigenze, tenendo conto del coefficiente di efficienza della specifica soluzione, potrete risparmiare sul volume. Dobbiamo anche considerare che questi programmi sono progettati per sistemi AFA, ma grazie all'acquisto di un volume inferiore di SSD rispetto agli HDD nei sistemi tradizionali, questo contribuerà a ridurre i costi, e se non equiparerà il costo del sistema di archiviazione, sicuramente si avvicinerà notevolmente ad esso.
Modello
E qui arriviamo alla domanda correttamente posta.
“Mi vengono proposti due modelli di storage — ABC SuperStorage S600 e XYZ HyperOcean 666v4, quale mi consigliereste?”
Si trasforma in “Mi vengono proposti due modelli di storage — ABC SuperStorage S600 e XYZ HyperOcean 666v4, quale mi consigliereste?”
Carico target misto di macchine virtuali VMware con segmenti di produttivo / test / sviluppo. Test = produttivo. 150 TB per ciascuno con una prestazione di picco di 80.000 IOPS a blocchi di 8kb, 50% di accesso casuale, 80/20 lettura-scrittura. 300 TB per sviluppo, dove 50.000 IOPS saranno sufficienti, 80% casuale, 80% scrittura.
Produttivo presumibilmente in metrocluster RPO = 15 minuti, RTO = 1 ora, sviluppo in replica asincrona RPO = 3 ore, test su un'unica sede.
Avremo 50 TB di DB, sarebbe utile per loro il log.
Abbiamo server Dell ovunque, storage Hitachi vecchi, che a malapena riescono a far fronte, prevediamo un aumento del 50% del carico per volume e prestazioni.
Come si suol dire, in una domanda ben formulata ci sono l'80% delle risposte.
Informazioni aggiuntive
Quali sono le ulteriori letture consigliate dagli autori?
Libri
- Oлiфер e Oлiфер “Reti informatiche”. Il libro aiuterà a sistematizzare e a comprendere meglio come funziona l'ambiente di trasmissione dei dati per i sistemi di storage IP / Ethernet.
- “EMC Information Storage and Management”. Un ottimo libro sulle basi dello storage, perché, come e perché.
Forum e chat
Raccomandazioni generali
Prezzi
Per quanto riguarda i prezzi — in generale, i prezzi per le soluzioni di storage si trovano soprattutto come List price, da cui ogni cliente riceve uno sconto individuale. La dimensione dello sconto dipende da molti fattori, quindi è impossibile prevedere quale sarà il prezzo finale per la vostra azienda senza una richiesta al distributore. Tuttavia, recentemente, i modelli low-end sono iniziati a comparire nei normali negozi di computer, come ad esempio o . Qui è possibile acquistare direttamente il sistema che vi interessa a un prezzo fisso, come qualsiasi componente di computer.
Va però sottolineato fin da subito che il confronto diretto in TB/$ non è corretto. Se si considera questa prospettiva, la soluzione più economica sarà un semplice JBOD + server, che non offrirà né la flessibilità né l'affidabilità fornite da un sistema di archiviazione di rete completo con doppio controller. Questo non significa affatto che il JBOD sia una scelta cattiva o problematica; è fondamentale comprendere molto chiaramente come e per quali scopi si utilizzerà questa soluzione. Spesso si sente dire che in un JBOD non c'è nulla che possa rompersi, dato che c'è solo un backplane. Tuttavia, anche i backplane possono guastarsi. Tutto si rompe, prima o poi.
Totale
È necessario confrontare i sistemi non solo in base al prezzo o solo in base alle prestazioni, ma considerando la somma di tutti i parametri.
Acquistate HDD solo se siete certi di averne bisogno. Per carichi di lavoro leggeri e tipi di dati non comprimibili, altrimenti vale la pena considerare i programmi di garanzia di efficienza di archiviazione su SSD, che ora offrono la maggior parte dei fornitori (e funzionano davvero, anche in Russia), ma tutto dipende dalle applicazioni e dai dati che saranno archiviati su questo sistema di archiviazione.
Non inseguire il risparmio. Spesso, dietro a queste scelte si nascondono numerosi inconvenienti, uno dei quali è stato descritto da Evgeny Elizarov nei suoi articoli su . E alla fine, questo risparmio potrebbe ritorcersi contro di te. Non dimenticare: «chi risparmia, spende due volte».
Fonte: habr.com
