

Ciao, residenti di Khabrovsk. Oggi iniziano le lezioni del primo gruppo del corso . A questo proposito vogliamo raccontarvi come si è svolto il webinar aperto su questo corso.

В abbiamo parlato delle sfide che i database SQL devono affrontare nell'era dei cloud e di Kubernetes. Allo stesso tempo, abbiamo esaminato il modo in cui i database SQL si adattano e mutano sotto l’influenza di queste sfide.
Si è svolto il webinar , Responsabile della distribuzione delle pratiche di Google Cloud presso EPAM Systems.
Quando gli alberi erano piccoli...
Per prima cosa ricordiamo come è iniziata la scelta del DBMS alla fine del secolo scorso. Tuttavia, questo non sarà difficile, perché la scelta di un DBMS in quei giorni iniziò e finì Oracle.

Alla fine degli anni ’90 e all’inizio degli anni 2, non c’era praticamente alcuna scelta quando si trattava di database scalabili a livello industriale. Sì, c'erano IBM DBXNUMX, Sybase e alcuni altri database che andavano e venivano, ma in generale non erano così evidenti sullo sfondo di Oracle. Di conseguenza, le competenze degli ingegneri di quei tempi erano in qualche modo legate all'unica scelta esistente.
Oracle DBA doveva essere in grado di:
- installare Oracle Server dal kit di distribuzione;
- configurare Oracle Server:
- init.ora;
- ascoltatore.ora;
- creare:
- spazi tabella;
- schema;
- utenti;
— eseguire il backup e il ripristino;
— effettuare il monitoraggio;
— gestire richieste non ottimali.
Allo stesso tempo, Oracle DBA non aveva requisiti speciali:
- essere in grado di scegliere il DBMS ottimale o altra tecnologia per l'archiviazione e l'elaborazione dei dati;
- fornire elevata disponibilità e scalabilità orizzontale (questo non è sempre stato un problema del DBA);
- buona conoscenza della materia, dell'infrastruttura, dell'architettura applicativa, del sistema operativo;
- caricare e scaricare dati, migrare dati tra diversi DBMS.
In generale, se parliamo della scelta di quei giorni, assomiglia alla scelta in un negozio sovietico alla fine degli anni '80:

Il nostro tempo
Da allora, ovviamente, gli alberi sono cresciuti, il mondo è cambiato ed è diventato qualcosa del genere:

Anche il mercato dei DBMS è cambiato, come si vede chiaramente dall’ultimo report di Gartner:
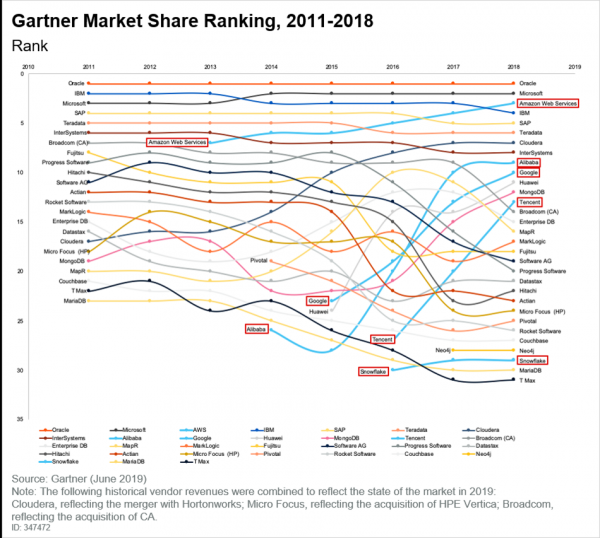
E qui va notato che le nuvole, la cui popolarità è in crescita, hanno occupato la loro nicchia. Se leggiamo lo stesso rapporto Gartner, vedremo le seguenti conclusioni:
- Molti clienti sono sulla buona strada per spostare le applicazioni nel cloud.
- Le nuove tecnologie compaiono per la prima volta nel cloud e non è un dato di fatto che si sposteranno mai verso un'infrastruttura non cloud.
- Il modello di prezzo a consumo è diventato un luogo comune. Tutti vogliono pagare solo per quello che consumano, e questa non è nemmeno una tendenza, ma semplicemente un dato di fatto.
E adesso?
Oggi siamo tutti nel cloud. E le domande che ci si pongono sono domande di scelta. Ed è enorme, anche se parliamo solo della scelta delle tecnologie DBMS in formato On-premises. Disponiamo anche di servizi gestiti e SaaS. Pertanto, la scelta diventa ogni anno più difficile.
Insieme alle domande sulla scelta, ci sono anche fattori limitanti:
- prezzo. Molte tecnologie costano ancora;
- навыки. Se parliamo di software libero, allora sorge la questione delle competenze, poiché il software libero richiede competenze sufficienti da parte delle persone che lo implementano e lo utilizzano;
- funzionale. Non tutti i servizi disponibili nel cloud e creati, ad esempio, anche sullo stesso Postgres, hanno le stesse funzionalità di Postgres On-premises. Questo è un fattore essenziale che deve essere conosciuto e compreso. Inoltre, questo fattore diventa più importante della conoscenza di alcune capacità nascoste di un singolo DBMS.
Cosa ci si aspetta da DA/DE adesso:
- buona conoscenza dell'area tematica e dell'architettura applicativa;
- la capacità di selezionare correttamente la tecnologia DBMS appropriata, tenendo conto del compito da svolgere;
- la capacità di selezionare il metodo ottimale per implementare la tecnologia selezionata nel contesto delle limitazioni esistenti;
- capacità di eseguire il trasferimento e la migrazione dei dati;
- capacità di implementare e gestire soluzioni selezionate.
Di seguito l'esempio basato su GCP dimostra come la scelta dell'una o dell'altra tecnologia per lavorare con i dati funziona a seconda della sua struttura:
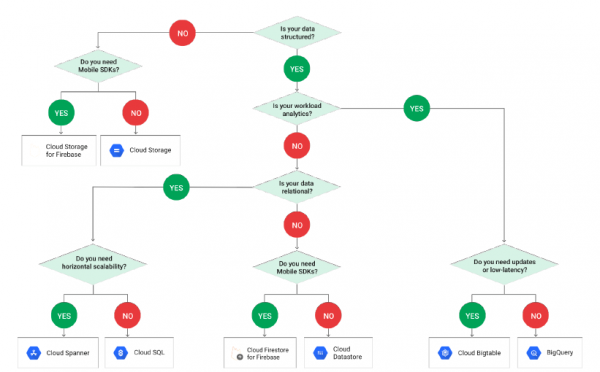
Tieni presente che PostgreSQL non è incluso nello schema e questo perché è nascosto sotto la terminologia Cloud SQL. E quando arriviamo a Cloud SQL, dobbiamo fare nuovamente una scelta:
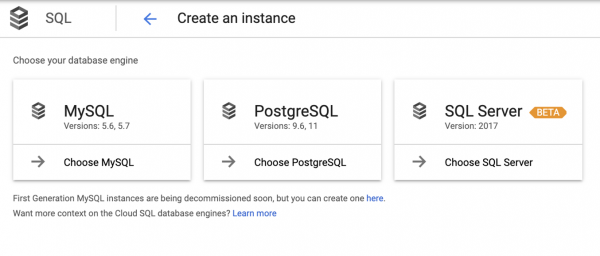
Va notato che questa scelta non è sempre chiara, quindi gli sviluppatori di applicazioni sono spesso guidati dall'intuizione.
Totale:
- Più si va avanti, più diventa urgente la questione della scelta. E anche se guardi solo a GCP, servizi gestiti e SaaS, qualche menzione di RDBMS appare solo al 4 ° passaggio (e lì Spanner è nelle vicinanze). In più, nel 5° passo appare la scelta di PostgreSQL, e accanto ci sono anche MySQL e SQL Server, cioè c'è molto di tutto, ma devi scegliere.
- Non dobbiamo dimenticare le restrizioni sullo sfondo delle tentazioni. Fondamentalmente tutti vogliono una chiave inglese, ma è costosa. Di conseguenza, una richiesta tipica assomiglia a questa: "Per favore, fateci una chiave inglese, ma per il prezzo di Cloud SQL, siete dei professionisti!"

Cosa fare?
Senza pretendere di essere la verità ultima, diciamo quanto segue:
Dobbiamo cambiare il nostro approccio all’apprendimento:
- non ha senso insegnare il modo in cui venivano insegnati i DBA prima;
- la conoscenza di un prodotto non è più sufficiente;
- ma conoscerne dozzine al livello di uno è impossibile.
Devi sapere non solo e non quanto costa il prodotto, ma:
- caso d'uso della sua applicazione;
- diversi metodi di distribuzione;
- vantaggi e svantaggi di ciascun metodo;
- prodotti simili ed alternativi per effettuare una scelta informata ed ottimale e non sempre a favore di un prodotto familiare.
È inoltre necessario essere in grado di migrare i dati e comprendere i principi di base dell'integrazione con ETL.
Caso reale
Nel recente passato è stato necessario creare un backend per un'applicazione mobile. Quando è iniziato il lavoro, il backend era già stato sviluppato ed era pronto per l'implementazione, e il team di sviluppo ha dedicato circa due anni a questo progetto. Sono stati fissati i seguenti compiti:
- creare CI/CD;
- rivedere l'architettura;
- mettere tutto in funzione.
L'applicazione stessa era costituita da microservizi e il codice Python/Django è stato sviluppato da zero e direttamente in GCP. Per quanto riguarda il pubblico di destinazione, si presumeva che ci sarebbero state due regioni: Stati Uniti e UE, e il traffico veniva distribuito tramite il bilanciatore del carico globale. Tutti i carichi di lavoro e il carico di lavoro di calcolo venivano eseguiti su Google Kubernetes Engine.
Per quanto riguarda i dati, c'erano 3 strutture:
- Archiviazione nel cloud;
- Archivio dati;
- CloudSQL (PostgreSQL).
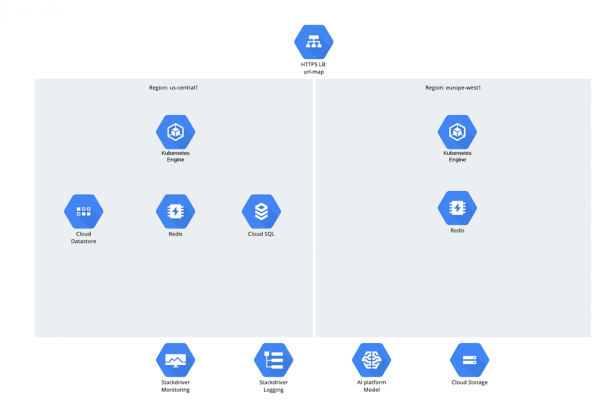
Ci si potrebbe chiedere perché è stato scelto Cloud SQL? A dire il vero, una domanda del genere ha causato una sorta di pausa imbarazzante negli ultimi anni: c'è la sensazione che le persone siano diventate timide nei confronti dei database relazionali, ma tuttavia continuano a utilizzarli attivamente ;-).
Nel nostro caso, è stato scelto Cloud SQL per i seguenti motivi:
- Come accennato, l'applicazione è stata sviluppata utilizzando Django e dispone di un modello per la mappatura di dati persistenti da un database SQL a oggetti Python (Django ORM).
- Il framework stesso supportava un elenco abbastanza finito di DBMS:
- PostgreSQL;
- MariaDB;
- MySQL;
- Oracolo;
- SQLite.
Di conseguenza, PostgreSQL è stato scelto da questo elenco in modo piuttosto intuitivo (beh, non è Oracle a scegliere, in realtà).
Cosa mancava:
- l'applicazione è stata distribuita solo in 2 regioni e nei piani ne è apparsa una terza (Asia);
- Il database era situato nella regione del Nord America (Iowa);
- da parte del cliente c'erano preoccupazioni circa possibili ritardi di accesso dall'Europa e dall'Asia e interruzioni in servizio in caso di inattività del DBMS.
Nonostante il fatto che Django stesso possa lavorare con diversi database in parallelo e dividerli in lettura e scrittura, nell'applicazione non c'era molta scrittura (più del 90% sta leggendo). E in generale, e in generale, se fosse possibile farlo replica della base principale in Europa e Asia, questa sarebbe una soluzione di compromesso. Ebbene, cosa c'è di così complicato?
La difficoltà era che il cliente non voleva rinunciare a utilizzare i servizi gestiti e Cloud SQL. Inoltre, le funzionalità di Cloud SQL sono attualmente limitate. Cloud SQL supporta l'alta disponibilità (HA) e la replica di lettura (RR), ma lo stesso RR è supportato solo in una regione. Avendo creato un database nella regione americana, non puoi effettuare una replica di lettura nella regione europea utilizzando Cloud SQL, sebbene Postgres stesso non ti impedisca di farlo. La corrispondenza con i dipendenti di Google non ha portato a nulla e si è conclusa con promesse del tipo “conosciamo il problema e ci stiamo lavorando, un giorno il problema sarà risolto”.
Se elenchiamo brevemente le funzionalità di Cloud SQL, sarà simile a questo:
1. Alta disponibilità (HA):
- all'interno di una regione;
- tramite replica del disco;
- Non vengono utilizzati motori PostgreSQL;
- possibilità di controllo automatico e manuale - failover/failback;
- Durante il passaggio, il DBMS non è disponibile per diversi minuti.
2. Leggi la replica (RR):
- all'interno di una regione;
- standby caldo;
- Replica in streaming PostgreSQL.
Inoltre, come è consuetudine, quando si sceglie una tecnologia ci si trova sempre di fronte ad alcune restrizioni:
- il cliente non voleva creare entità e utilizzare IaaS, se non tramite GKE;
- il cliente non vorrebbe implementare PostgreSQL/MySQL self-service;
- Bene, in generale Google Spanner sarebbe abbastanza adatto se non fosse per il suo prezzo, tuttavia Django ORM non può funzionare con esso, ma è una buona cosa.
Considerata la situazione, il cliente ha ricevuto una domanda di follow-up: "Puoi fare qualcosa di simile in modo che sia come Google Spanner, ma funzioni anche con Django ORM?"
Opzione di soluzione n. 0
La prima cosa che mi è venuta in mente:
- rimanere all'interno di CloudSQL;
- non ci sarà alcuna replica integrata tra le regioni in alcuna forma;
- provare ad allegare una replica a un Cloud SQL esistente tramite PostgreSQL;
- avvia un'istanza PostgreSQL da qualche parte e in qualche modo, ma almeno non toccare master.
Purtroppo, si è scoperto che ciò non può essere fatto, perché non c'è accesso all'host (è in un progetto completamente diverso) - pg_hba e così via, e non c'è accesso nemmeno con il superutente.
Opzione di soluzione n. 1
Dopo un’ulteriore riflessione e tenendo conto delle circostanze precedenti, il filo del pensiero è leggermente cambiato:
- Stiamo ancora cercando di rimanere all'interno di CloudSQL, ma stiamo passando a MySQL, perché Cloud SQL di MySQL ha un master esterno che:
— è un proxy per MySQL esterno;
- sembra un'istanza MySQL;
- inventato per la migrazione dei dati da altri cloud o On-premise.
Poiché l'impostazione della replica MySQL non richiede l'accesso all'host, in linea di principio tutto funzionava, ma era molto instabile e scomodo. E quando siamo andati oltre, è diventato davvero spaventoso, perché abbiamo distribuito l'intera struttura con terraform e all'improvviso si è scoperto che il master esterno non era supportato da terraform. Sì, Google ha una CLI, ma per qualche motivo qui ogni tanto funzionava tutto: a volte viene creato, a volte non viene creato. Forse perché la CLI è stata inventata per la migrazione dei dati esterni e non per le repliche.
In realtà a questo punto è diventato chiaro che Cloud SQL non è affatto adatto. Come si suol dire, abbiamo fatto tutto il possibile.
Opzione di soluzione n. 2
Poiché non è stato possibile rimanere all'interno del framework Cloud SQL, abbiamo cercato di formulare i requisiti per una soluzione di compromesso. I requisiti risultarono essere i seguenti:
- lavorare in Kubernetes, massimo utilizzo delle risorse e delle capacità di Kubernetes (DCS, ...) e GCP (LB, ...);
- mancanza di zavorra da un mucchio di cose non necessarie nel cloud come il proxy HA;
- la possibilità di eseguire PostgreSQL o MySQL nella regione HA principale; in altre regioni - HA dalla RR della regione principale più la sua copia (per affidabilità);
- multi master (non volevo contattarlo, ma non era molto importante)
.
A seguito di queste richieste, pDBMS adatti e opzioni di collegamento:
- MySQL Galera;
- Scarafaggio DB;
- Strumenti PostgreSQL
:
- pgpool-II;
— Patroni.
MySQL Galera
La tecnologia MySQL Galera è stata sviluppata da Codership ed è un plugin per InnoDB. Peculiarità:
- multimaster;
- replica sincrona;
- lettura da qualsiasi nodo;
- registrazione su qualsiasi nodo;
- meccanismo HA integrato;
- C'è un grafico Helm di Bitnami.
scarafaggioDB
Secondo la descrizione, la cosa è assolutamente bomba ed è un progetto open source scritto in Go. Il partecipante principale è Cockroach Labs (fondato da persone di Google). Questo DBMS relazionale è stato originariamente progettato per essere distribuito (con scalabilità orizzontale immediata) e tollerante ai guasti. Gli autori dell'azienda hanno delineato l'obiettivo di "combinare la ricchezza delle funzionalità SQL con l'accessibilità orizzontale familiare alle soluzioni NoSQL".
Un bel vantaggio è il supporto per il protocollo di connessione post-gress.
Pgpool
Questo è un componente aggiuntivo di PostgreSQL, infatti, una nuova entità che prende in carico tutte le connessioni e le elabora. Ha il proprio bilanciatore del carico e parser, concesso in licenza con la licenza BSD. Fornisce ampie opportunità, ma sembra un po' spaventoso, perché la presenza di una nuova entità potrebbe diventare la fonte di alcune avventure aggiuntive.
patrono
Questa è l'ultima cosa su cui i miei occhi sono caduti e, come si è scoperto, non invano. Patroni è un'utilità open source, che è essenzialmente un demone Python che consente di mantenere automaticamente i cluster PostgreSQL con vari tipi di replica e cambio automatico di ruolo. La cosa si è rivelata molto interessante, poiché si integra bene con il cuber e non introduce nessuna nuova entità.
Cosa hai scelto alla fine?
La scelta non è stata facile:
- scarafaggioDB - fuoco, ma buio;
- MySQL Galera - inoltre non male, è usato in molti posti, ma MySQL;
- Pgpool - molte entità non necessarie, integrazione così così con il cloud e K8;
- patrono - ottima integrazione con K8, nessuna entità non necessaria, si integra bene con GCP LB.
La scelta è quindi caduta su Patroni.
risultati
È il momento di riassumere brevemente. Sì, il mondo dell'infrastruttura IT è cambiato in modo significativo e questo è solo l'inizio. E se prima i cloud erano solo un altro tipo di infrastruttura, ora è tutto diverso. Inoltre, le innovazioni nei cloud appaiono costantemente, appariranno e, forse, appariranno solo nei cloud e solo allora, grazie agli sforzi delle startup, verranno trasferite in locale.
Per quanto riguarda SQL, SQL sopravvivrà. Ciò significa che è necessario conoscere PostgreSQL e MySQL ed essere in grado di lavorarci, ma ancora più importante è saperli utilizzare correttamente.
Fonte: habr.com
