

Contesto
Essendo un appassionato di retro computing, un giorno ho acquistato da un venditore del Regno Unito un ZX Spectrum+. Insieme al computer, mi sono stati forniti diverse audiocassette contenenti giochi (nella confezione originale con istruzioni), oltre a programmi registrati su cassette senza particolari identificazioni. Sorprendentemente, i dati delle cassette di 40 anni fa si leggeva bene e sono riuscito a caricare quasi tutti i giochi e i programmi da esse.

Tuttavia, su alcune cassette ho trovato registrazioni che chiaramente non erano fatte dal computer ZX Spectrum. Suonavano completamente diverse e, a differenza delle registrazioni del computer menzionato, non iniziavano con un breve caricatore BASIC, che di solito è presente in tutte le registrazioni di programmi e giochi.
Per un certo periodo non riuscivo a togliermi dalla testa questa curiosità: volevo sapere cosa si nascondesse in esse. Se fossi riuscito a leggere il segnale audio come una sequenza di byte, avrei potuto cercare simboli o qualcosa che indicasse l'origine del segnale. Una sorta di retro-archeologia.
Ora che ho percorso tutto questo cammino e guardo le etichette delle cassette stesse, sorrido perché
la risposta era proprio di fronte ai miei occhi tutto questo tempo.
Sull'etichetta della cassetta di sinistra c'è il nome del computer TRS-80 e, un po' più in basso, il nome del produttore: «Manufactured by Radio Shack in USA»
(Se vuoi mantenere l'intrigo fino alla fine, non entrare nel spoiler)
Confronto dei segnali audio
Per prima cosa digitalizziamo le registrazioni audio. Possiamo ascoltare come suona:
E come suona di solito la registrazione del computer ZX Spectrum:
In entrambi i casi, all'inizio della registrazione è presente il cosiddetto tono pilota — un suono a una frequenza (nella prima registrazione è molto breve <1 sec, ma comunque distinguibile). Il tono pilota serve come segnale al computer che deve prepararsi a ricevere dati. Di solito ogni computer riconosce solo il suo «proprio» tono pilota in base alla forma del segnale e alla sua frequenza.
Devo dire qualcosa sulla forma del segnale. Per esempio, sul ZX Spectrum la sua forma è rettangolare:
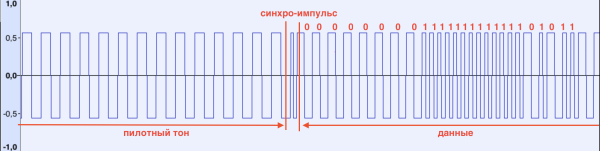
Quando viene rilevato il tono pilota, lo ZX Spectrum visualizza strisce rosso-blu alternate nella parte bordata dello schermo, mostrando che il segnale è stato riconosciuto. Il tono pilota termina con un impulso di sincronizzazione., che segnala al computer di iniziare a ricevere dati. Si caratterizza per una durata inferiore (rispetto al tono pilota e ai dati successivi) (vedi figura)
Dopo aver ricevuto l'impulso di sincronizzazione, il computer registra ogni salita/discesa del segnale, misurandone la durata. Se la durata è inferiore a un certo limite, viene memorizzato il bit 1, altrimenti 0. I bit vengono raccolti in byte e il processo si ripete fino a quando non vengono ricevuti N byte. Il numero N viene generalmente prelevato dall'intestazione del file caricato. La sequenza di caricamento è la seguente:
- tono pilota
- intestazione (di lunghezza fissa), contiene la dimensione dei dati caricati (N), il nome e il tipo di file
- tono pilota
- i dati stessi
Per assicurarsi che i dati siano stati caricati correttamente, ZX Spectrum legge l'ultimo byte, noto come byte di parità (byte di parità), calcolato durante il salvataggio del file tramite l'operazione XOR su tutti i byte dei dati scritti. Durante la lettura del file, il computer calcola il byte di parità dai dati ricevuti e, se il risultato è diverso da quello salvato, mostra il messaggio di errore «R Tape loading error». Tecnicamente, il computer può visualizzare questo messaggio anche prima, se durante la lettura non riesce a riconoscere l'impulso (saltato o se la sua durata non rientra nei limiti definiti).
Ora vediamo come appare un segnale sconosciuto:
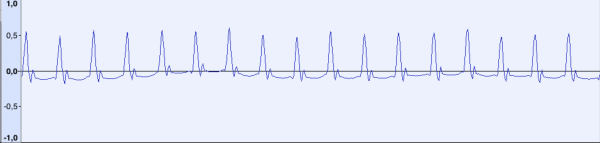
Questo è un tono pilota. La forma del segnale è significativamente diversa, ma è evidente che il segnale è composto da impulsi corti ripetitivi di una certa frequenza. Con una frequenza di campionamento di 44100 Hz, la distanza tra i «picchi» è di circa 48 campioni (corrispondente a una frequenza di ~918 Hz). Ricordiamo questo numero.
Esaminiamo ora un frammento di dati:
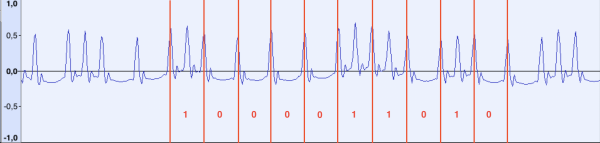
Se misuriamo la distanza tra i singoli impulsi, risulta che tra gli impulsi "lunghi" la distanza è ancora di circa 48 campioni, mentre tra quelli brevi è di circa 24. Anticipando un po', posso dire che alla fine si è scoperto che gli impulsi "di riferimento" a una frequenza di 918 Hz seguono in modo continuo, dall'inizio alla fine del file. Si può ipotizzare che durante la trasmissione dei dati, se tra gli impulsi di riferimento compare un impulso aggiuntivo, consideriamo questo come il bit 1, altrimenti 0.
E per quanto riguarda l'impulso di sincronizzazione? Diamo un'occhiata all'inizio dei dati:
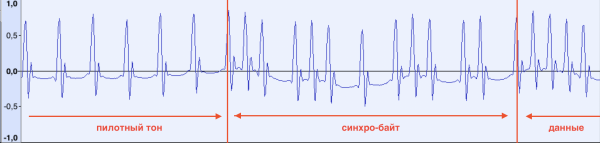
Il tono pilota termina e subito iniziano i dati. Un po' più tardi, analizzando diverse registrazioni audio, è stato possibile rilevare che il primo byte di dati è sempre lo stesso (10100101b, A5h). È possibile che il computer cominci a leggere i dati dopo averlo ricevuto.
Si può anche notare lo spostamento del primo impulso di riferimento subito dopo l'ultima cifra 1 nel byte di sincronizzazione. Questo è stato rilevato molto più tardi durante lo sviluppo del programma per il riconoscimento dei dati, quando i dati all'inizio del file non potevano essere letti in modo stabile.
Ora proviamo a descrivere l'algoritmo che elaborerà il file audio e caricherà i dati.
Caricamento dati
Iniziamo considerando alcune ipotesi per non complicare l'algoritmo:
- Considereremo file solo nel formato WAV;
- Il file audio deve iniziare con un tono pilota e non deve contenere silenzi all'inizio.
- Il file sorgente deve avere una frequenza di campionamento di 44100 Hz. In tal modo, la distanza tra gli impulsi di riferimento in 48 campioni è già definita e non è necessario calcolarla programmaticamente.
- Il formato dei campioni può essere qualsiasi (8/16 bit/float) poiché durante la lettura possiamo convertirlo nel formato necessario;
- Supponiamo che il file sorgente sia normalizzato in ampiezza, il che dovrebbe stabilizzare il risultato;
L'algoritmo di lettura sarà il seguente:
- Leggiamo il file in memoria, convertendo contemporaneamente il formato dei campioni in 8 bit;
- Determiniamo la posizione del primo impulso nei dati audio. Per fare ciò, è necessario calcolare il numero del campione con l'ampiezza massima. Per semplicità, lo calcoliamo una volta manualmente. Salviamo nella variabile prev_pos;
- Aggiungiamo alla posizione dell'ultimo impulso 48 (pos := prev_pos + 48)
- Poiché l'aumento della posizione di 48 non garantisce che entreremo nella posizione dell'impulso di riferimento successivo (difetti della nastro, funzionamento instabile del meccanismo di trasporto del nastro e altro), è necessario correggere la posizione dell'impulso pos. Per fare ciò, prenderemo un breve segmento di dati (pos-8; pos+8) e troveremo il massimo del valore dell'ampiezza su di esso. La posizione corrispondente al massimo verrà salvata in pos. Qui, 8 = 48/6 — una costante ottenuta sperimentalmente, che garantisce che identificheremo il massimo corretto e non influenzeremo altri impulsi che potrebbero essere vicini. Nei casi molto gravi, quando la distanza tra gli impulsi è molto inferiore o superiore a 48, è possibile implementare una ricerca forzata dell'impulso, ma nel contesto di questo articolo non descriverò questo algoritmo;
- Nel passaggio precedente è necessario anche verificare che l'impulso di riferimento sia stato effettivamente trovato. Cioè, se cerchiamo semplicemente il massimo, non è garantito che l'impulso sia presente in questo segmento. Nella mia ultima implementazione del programma di lettura, controllo la differenza tra il valore massimo e quello minimo dell'ampiezza nel segmento e, se supera una certa soglia, considero presente l'impulso. Resta da capire cosa fare se l'impulso di riferimento non viene trovato. Qui ci sono due opzioni: o i dati sono finiti e poi segue un silenzio, o è da considerarsi come un errore di lettura. Tuttavia, per semplificare l'algoritmo, tralasciamo questo.
- Nel passaggio successivo bisogna determinare la presenza dell'impulso dei dati (bit 0 o 1). Per fare ciò, prendiamo il punto medio del segmento (prev_pos; pos) con middle_pos definito come middle_pos := (prev_pos + pos) / 2 e, in un certo intervallo attorno a middle_pos nel segmento (middle_pos-8; middle_pos+8), calcoliamo il massimo e il minimo dell'ampiezza. Se la differenza tra di essi è superiore a 10, registriamo 1 nel risultato altrimenti 0. 10 è una costante ottenuta empiricamente.
- Salviamo la posizione attuale in prev_pos (prev_pos := pos).
- Ripetiamo a partire dal passo 3, fino a quando non leggiamo l'intero file.
- La matrice di bit ottenuta deve essere salvata come un insieme di byte. Poiché non abbiamo considerato il byte di sincronizzazione durante la lettura, il numero di bit potrebbe non essere multiplo di 8 e non è noto il necessario offset in bit. Nella mia prima implementazione dell'algoritmo, non sapevo dell'esistenza del byte di sincronizzazione e quindi salvavo semplicemente 8 file con un diverso numero di bit di offset. Uno di essi conteneva dati corretti. Nell'algoritmo finale, elimino semplicemente tutti i bit fino a A5h, il che consente di ottenere immediatamente un file corretto in uscita.
Algoritmo in Ruby, per chi è interessato.
Ho scelto Ruby come linguaggio per la scrittura del programma, poiché la maggior parte del tempo programma in esso. Questa versione non è ad alte prestazioni, tuttavia l'obiettivo di rendere la velocità di lettura massima non è prioritario.
# Используем gem 'wavefile'
require 'wavefile'
reader = WaveFile::Reader.new('input.wav')
samples = []
format = WaveFile::Format.new(:mono, :pcm_8, 44100)
# Читаем WAV файл, конвертируем в формат Mono, 8 bit
# Массив samples будет состоять из байт со значениями 0-255
reader.each_buffer(10000) do |buffer|
samples += buffer.convert(format).samples
end
# Позиция первого импульса (вместо 0)
prev_pos = 0
# Расстояние между импульсами
distance = 48
# Значение расстояния для окрестности поиска локального максимума
delta = (distance / 6).floor
# Биты будем сохранять в виде строки из "0" и "1"
bits = ""
loop do
# Рассчитываем позицию следующего импульса
pos = prev_pos + distance
# Выходим из цикла если данные закончились
break if pos + delta >= samples.size
# Корректируем позицию pos обнаружением максимума на отрезке [pos - delta;pos + delta]
(pos - delta..pos + delta).each { |p| pos = p if samples[p] > samples[pos] }
# Находим середину отрезка [prev_pos;pos]
middle_pos = ((prev_pos + pos) / 2).floor
# Берем окрестность в середине
sample = samples[middle_pos - delta..middle_pos + delta]
# Определяем бит как "1" если разница между максимальным и минимальным значением на отрезке превышает 10
bit = sample.max - sample.min > 10
bits += bit ? "1" : "0"
end
# Определяем синхро-байт и заменяем все предшествующие биты на 256 бит нулей (согласно спецификации формата)
bits.gsub! /^[01]*?10100101/, ("0" * 256) + "10100101"
# Сохраняем выходной файл, упаковывая биты в байты
File.write "output.cas", [bits].pack("B*")
Risultato
Dopo aver provato diverse varianti dell'algoritmo e costanti, ho avuto la fortuna di ottenere qualcosa di estremamente interessante:
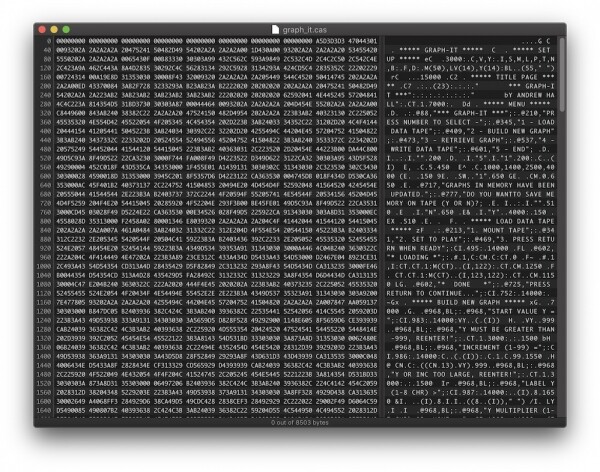
Quindi, a giudicare dalle stringhe di caratteri, abbiamo un programma per la creazione di grafici. Tuttavia, nel testo del programma mancano le parole chiave. Tutte le parole chiave sono codificate come byte (valore superiore a 80h). Ora è necessario scoprire quale computer degli anni '80 potesse salvare i programmi in questo formato.
In effetti, sembra molto simile a un programma in linguaggio BASIC. Circa nello stesso formato, il computer ZX Spectrum memorizza e salva i programmi su nastro. Per scrupolo, ho controllato le parole chiave per vedere se corrispondessero a . Tuttavia, chiaramente il risultato è stato negativo.
Ho anche controllato le parole chiave BASIC dei computer Atari, Commodore 64 e di alcuni altri di quel tempo per cui sono riuscito a trovare documentazione, ma senza successo: le mie conoscenze sulle varietà di retrocomputer non erano così ampie.
Allora ho deciso di seguire , e qui il mio sguardo è caduto sul marchio Radio Shack e sul computer TRS-80. Questi nomi erano scritti sulle etichette delle cassette che avevo sulla scrivania! Non conoscevo precedentemente questi nomi e non ero familiare con il computer TRS-80, quindi pensavo che Radio Shack fosse un produttore di cassette audio, come BASF, Sony o TDK, e che TRS-80 fosse la durata di riproduzione. Perché no?
Computer Tandy/Radio Shack TRS-80
È molto probabile che la registrazione audio considerata, che ho citato come esempio all'inizio dell'articolo, sia stata fatta su un tale computer:

Si è scoperto che questo computer e le sue varianti (Model I/Model III/Model IV, ecc.) erano molto popolari al loro tempo (ovviamente, non in Russia). È notevole che il processore utilizzato in essi fosse anch'esso Z80. Si possono trovare . Negli anni '80, le informazioni su questo computer venivano diffuse in . Attualmente esistono diversi del computer per diverse piattaforme.
Ho scaricato l'emulatore E per la prima volta ho potuto vedere come funzionava questo computer. Certo, il computer non supportava l'uscita a colori, la risoluzione dello schermo era solo di 128x48 pixel, ma esistevano molte estensioni e modifiche che potevano aumentare la risoluzione dello schermo. C'erano anche molte varianti di sistemi operativi per questo computer e varianti dell'implementazione del linguaggio BASIC (che, a differenza dello ZX Spectrum, in alcuni modelli non era nemmeno «inciso» nella ROM e qualsiasi versione poteva essere caricata da un floppy disk, proprio come il sistema operativo stesso)
Ho anche trovato per convertire registrazioni audio nel formato CAS, supportato dagli emulatori, tuttavia per qualche motivo non sono riuscito a leggere le registrazioni dalle mie cassette con il loro aiuto.
Dopo aver compreso il formato del file CAS (che si è rivelato essere semplicemente una copia bit per bit dei dati dalla cassetta, che avevo già in mio possesso, ad eccezione dell'intestazione con la presenza del byte di sincronizzazione), ho apportato alcune modifiche al mio programma e sono riuscito a ottenere un file CAS funzionante, che ha funzionato nell'emulatore (TRS-80 Model III):
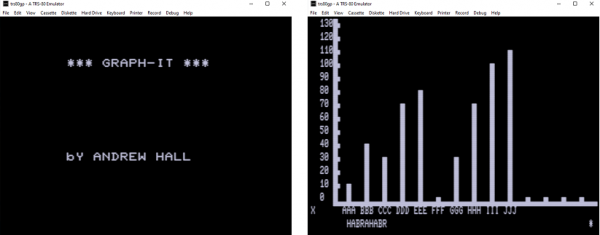
L'ultima versione dell'utilità per la conversione con rilevamento automatico del primo impulso e della distanza tra gli impulsi di riferimento è stata realizzata come pacchetto GEM, il codice sorgente è disponibile su .
Conclusione
Il percorso intrapreso si è rivelato un viaggio affascinante nel passato, e sono contento di aver trovato la soluzione. Inoltre, ho:
- Comprendere il formato di salvataggio dei dati su ZX Spectrum e studiare le sottoprogrammi integrate nella ROM per il salvataggio/lettura dei dati da nastri audio
- Familiarizzare con il computer TRS-80 e le sue varianti, studiare il sistema operativo, esaminare esempi di programmi e persino avere l'opportunità di lavorare sul debugging in codici macchina (le mnemoniche Z80 mi sono comunque ben note)
- Scrivere un'utilità completa per la conversione di registrazioni audio nel formato CAS, che può leggere dati non riconosciuti dall'utilità 'ufficiale'
Fonte: habr.com
