

Cercando R o Python su Internet, troverai milioni di articoli e chilometri di discussioni sull'argomento su quale sia migliore, più veloce e più conveniente per lavorare con i dati. Ma sfortunatamente tutti questi articoli e controversie non sono particolarmente utili.

Lo scopo di questo articolo è confrontare le tecniche di elaborazione dati di base nei pacchetti più diffusi di entrambi i linguaggi. E aiuta i lettori a padroneggiare rapidamente qualcosa che ancora non conoscono. Per chi scrive in Python, scopri come fare la stessa cosa in R, e viceversa.
Durante l'articolo analizzeremo la sintassi dei pacchetti più diffusi in R. Questi sono i pacchetti inclusi nella libreria tidyversee anche il pacchetto data.table. E confronta la loro sintassi con pandas, il pacchetto di analisi dei dati più popolare in Python.
Seguiremo passo dopo passo l'intero percorso dell'analisi dei dati, dal caricamento all'esecuzione delle funzioni della finestra analitica utilizzando Python e R.
contenuto
Questo articolo può essere utilizzato come un riassunto se hai dimenticato come eseguire alcune operazioni di elaborazione dati in uno dei pacchetti in questione.

1.1
1.2
1.3
1.4
1.5
1.6
2.1
2.2
2.3
Se sei interessato all'analisi dei dati, potresti trovare il mio и canali. La maggior parte del contenuto è dedicata al linguaggio R.
Principali differenze di sintassi tra R e Python
Per semplificarti il passaggio da Python a R, o viceversa, fornirò alcuni punti principali a cui devi prestare attenzione.
Accesso alle funzioni del pacchetto
Una volta caricato un pacchetto in R, non è necessario specificare il nome del pacchetto per accedere alle sue funzioni. Nella maggior parte dei casi questo non è comune in R, ma è accettabile. Non devi affatto importare un pacchetto se hai bisogno di una delle sue funzioni nel tuo codice, ma chiamalo semplicemente specificando il nome del pacchetto e il nome della funzione. Il separatore tra i nomi dei pacchetti e delle funzioni in R è un doppio punto. package_name::function_name().
In Python, al contrario, è considerato classico chiamare le funzioni di un pacchetto specificandone esplicitamente il nome. Quando un pacchetto viene scaricato, solitamente gli viene assegnato un nome abbreviato, ad es. pandas di solito viene utilizzato uno pseudonimo pd. Si accede a una funzione del pacchetto tramite un punto package_name.function_name().
Incarico
In R, è comune utilizzare una freccia per assegnare un valore a un oggetto. obj_name <- value, sebbene sia consentito un singolo segno di uguale, il singolo segno di uguale in R viene utilizzato principalmente per passare valori agli argomenti della funzione.
In Python, l'assegnazione viene eseguita esclusivamente con un singolo segno di uguale obj_name = value.
indicizzazione
Anche qui ci sono differenze piuttosto significative. In R, l'indicizzazione inizia da uno e include tutti gli elementi specificati nell'intervallo risultante,
In Python, l'indicizzazione inizia da zero e l'intervallo selezionato non include l'ultimo elemento specificato nell'indice. Quindi progettazione x[i:j] in Python non includerà l'elemento j.
Ci sono anche differenze nell'indicizzazione negativa, nella notazione R x[-1] restituirà tutti gli elementi del vettore tranne l'ultimo. In Python, una notazione simile restituirà solo l'ultimo elemento.
Metodi e OOP
R implementa l'OOP a modo suo, ne ho scritto nell'articolo . In generale, R è un linguaggio funzionale e tutto in esso è basato su funzioni. Pertanto, ad esempio, per gli utenti di Excel, vai a tydiverse sarà più facile di pandas. Anche se questa potrebbe essere la mia opinione soggettiva.
In breve, gli oggetti in R non hanno metodi (se parliamo di classi S3, ma ci sono altre implementazioni OOP molto meno comuni). Esistono solo funzioni generalizzate che li elaborano in modo diverso a seconda della classe dell'oggetto.
Condotte
Forse questo è il nome per pandas Non sarà del tutto corretto, ma cercherò di spiegarne il significato.
Per non salvare calcoli intermedi e non produrre oggetti non necessari nell'ambiente di lavoro, è possibile utilizzare una sorta di pipeline. Quelli. passare il risultato di un calcolo da una funzione a quella successiva e non salvare i risultati intermedi.
Prendiamo il seguente esempio di codice, in cui memorizziamo i calcoli intermedi in oggetti separati:
temp_object <- func1()
temp_object2 <- func2(temp_object )
obj <- func3(temp_object2 )Abbiamo eseguito 3 operazioni in sequenza e il risultato di ciascuna è stato salvato in un oggetto separato. Ma in realtà non abbiamo bisogno di questi oggetti intermedi.
O anche peggio, ma più familiare agli utenti di Excel.
obj <- func3(func2(func1()))In questo caso non abbiamo salvato i risultati dei calcoli intermedi, ma leggere il codice con funzioni annidate è estremamente scomodo.
Esamineremo diversi approcci all'elaborazione dei dati in R ed eseguono operazioni simili in modi diversi.
Condutture in biblioteca tidyverse implementato dall'operatore %>%.
obj <- func1() %>%
func2() %>%
func3()Prendiamo quindi il risultato del lavoro func1() e passarlo come primo argomento a func2(), quindi passiamo il risultato di questo calcolo come primo argomento func3(). E alla fine scriviamo tutti i calcoli eseguiti nell'oggetto obj <-.
Tutto quanto sopra è illustrato meglio delle parole da questo meme:

В data.table le catene vengono utilizzate in modo simile.
newDT <- DT[where, select|update|do, by][where, select|update|do, by][where, select|update|do, by]In ciascuna delle parentesi quadre è possibile utilizzare il risultato dell'operazione precedente.
В pandas tali operazioni sono separate da un punto.
obj = df.fun1().fun2().fun3()Quelli. prendiamo il nostro tavolo df e usa il suo metodo fun1(), quindi applichiamo il metodo al risultato ottenuto fun2()dopo fun3(). Il risultato risultante viene salvato in un oggetto obj .
Strutture dati
Le strutture dati in R e Python sono simili, ma hanno nomi diversi.
Descrizione
Nome in R
Nome in Python/panda
Struttura della tabella
data.frame, data.table, tibble
dataframe
Elenco di valori unidimensionale
R'RμRєS, RѕSЂ
Serie in panda o elenco in puro Python
Struttura multilivello non tabellare
Elenco
Dizionario (dict)
Di seguito esamineremo alcune altre funzionalità e differenze nella sintassi.
Qualche parola sui pacchetti che utilizzeremo
Per prima cosa ti parlerò un po’ dei pacchetti con cui acquisirai familiarità durante questo articolo.
tidyverse
Sito ufficiale:
Biblioteca tidyverse scritto da Hedley Wickham, ricercatore senior presso RStudio. tidyverse è costituito da un insieme impressionante di pacchetti che semplificano l'elaborazione dei dati, 5 dei quali sono inclusi nei primi 10 download dal repository CRAN.
Il nucleo della libreria è costituito dai seguenti pacchetti: ggplot2, dplyr, tidyr, readr, purrr, tibble, stringr, forcats. Ciascuno di questi pacchetti è mirato a risolvere un problema specifico. Per esempio dplyr creato per la manipolazione dei dati, tidyr per riportare i dati in una forma ordinata, stringr semplifica il lavoro con le stringhe e ggplot2 è uno degli strumenti di visualizzazione dei dati più popolari.
Il vantaggio tidyverse è la semplicità e la sintassi di facile lettura, che è per molti versi simile al linguaggio di query SQL.
tabella dati
Sito ufficiale:
Autore data.table è Matt Dole di H2O.ai.
Il primo rilascio della libreria è avvenuto nel 2006.
La sintassi del pacchetto non è così comoda come in tidyverse e ricorda più i classici dataframe in R, ma allo stesso tempo ha funzionalità notevolmente ampliate.
Tutte le manipolazioni con la tabella in questo pacchetto sono descritte tra parentesi quadre e se traduci la sintassi data.table in SQL, ottieni qualcosa del genere: data.table[ WHERE, SELECT, GROUP BY ]
Il punto di forza di questo pacchetto è la velocità di elaborazione di grandi quantità di dati.
panda
Sito ufficiale:
Il nome della biblioteca deriva dal termine econometrico “panel data”, utilizzato per descrivere insiemi strutturati multidimensionali di informazioni.
Autore pandas è l'americano Wes McKinney.
Quando si tratta di analisi dei dati in Python, uguale pandas NO. Un pacchetto molto multifunzionale e di alto livello che consente di eseguire qualsiasi manipolazione dei dati, dal caricamento dei dati da qualsiasi fonte alla visualizzazione.
Installazione di pacchetti aggiuntivi
I pacchetti discussi in questo articolo non sono inclusi nelle distribuzioni R e Python di base. Anche se c'è un piccolo avvertimento, se hai installato la distribuzione Anaconda, installala ulteriormente pandas non richiesto
Installazione di pacchetti in R
Se hai aperto almeno una volta l'ambiente di sviluppo RStudio, probabilmente sai già come installare il pacchetto richiesto in R. Per installare i pacchetti, usa il comando standard install.packages() eseguendolo direttamente in R stesso.
# установка пакетов
install.packages("vroom")
install.packages("readr")
install.packages("dplyr")
install.packages("data.table")Dopo l'installazione è necessario connettere i pacchetti, operazione per la quale nella maggior parte dei casi viene utilizzato il comando library().
# подключение или импорт пакетов в рабочее окружение
library(vroom)
library(readr)
library(dplyr)
library(data.table)Installazione di pacchetti in Python
Quindi, se hai installato Python puro, allora pandas è necessario installarlo manualmente. Apri una riga di comando, o un terminale, a seconda del tuo sistema operativo e inserisci il seguente comando.
pip install pandasQuindi torniamo a Python e importiamo il pacchetto installato con il comando import.
import pandas as pdCaricamento dati
Il data mining è uno dei passaggi più importanti nell’analisi dei dati. Sia Python che R, se lo desideri, offrono ampie opportunità per ottenere dati da qualsiasi fonte: file locali, file da Internet, siti Web, tutti i tipi di database.

In tutto l'articolo utilizzeremo diversi set di dati:
- Due download da Google Analytics.
- Set di dati sui passeggeri del Titanic.
Tutti i dati sono sul mio sotto forma di file CSV e TSV. Da dove li richiederemo?
Caricamento dei dati in R: tidyverse, vroom, readr
Per caricare i dati in una libreria tidyverse Ci sono due pacchetti: vroom, readr. vroom più moderni, ma in futuro i pacchetti potranno essere combinati.
Citazione da vroom.
vroom vs lettore
Cosa significa il rilascio divroomsignifica perreadr? Per ora prevediamo di far evolvere i due pacchetti separatamente, ma probabilmente li uniremo in futuro. Uno svantaggio della lettura pigra di vroom è che alcuni problemi relativi ai dati non possono essere segnalati in anticipo, quindi il modo migliore per unificarli richiede una certa riflessione.vroom vs lettore
Cosa significa rilascio?vroomperreadr? Al momento prevediamo di sviluppare entrambi i pacchetti separatamente, ma probabilmente li combineremo in futuro. Uno degli svantaggi della lettura pigravroomè che alcuni problemi con i dati non possono essere segnalati in anticipo, quindi è necessario pensare a come combinarli al meglio.
In questo articolo esamineremo entrambi i pacchetti di caricamento dati:
Caricamento dei dati nel pacchetto R: vroom
# install.packages("vroom")
library(vroom)
# Чтение данных
## vroom
ga_nov <- vroom("https://raw.githubusercontent.com/selesnow/publications/master/data_example/r_python_data/ga_nowember.csv")
ga_dec <- vroom("https://raw.githubusercontent.com/selesnow/publications/master/data_example/r_python_data/ga_december.csv")
titanic <- vroom("https://raw.githubusercontent.com/selesnow/publications/master/data_example/r_python_data/titanic.csv")Caricamento dei dati in R: readr
# install.packages("readr")
library(readr)
# Чтение данных
## readr
ga_nov <- read_tsv("https://raw.githubusercontent.com/selesnow/publications/master/data_example/r_python_data/ga_nowember.csv")
ga_dec <- read_tsv("https://raw.githubusercontent.com/selesnow/publications/master/data_example/r_python_data/ga_december.csv")
titanic <- read_csv("https://raw.githubusercontent.com/selesnow/publications/master/data_example/r_python_data/titanic.csv")Nel pacchetto vroom, indipendentemente dal formato dei dati csv/tsv, il caricamento viene effettuato dalla funzione omonima vroom(), nel pacchetto readr utilizziamo una funzione diversa per ogni formato read_tsv() и read_csv().
Caricamento dei dati in R: data.table
В data.table c'è una funzione per caricare i dati fread().
Caricamento dei dati nel pacchetto R: data.table
# install.packages("data.table")
library(data.table)
## data.table
ga_nov <- fread("https://raw.githubusercontent.com/selesnow/publications/master/data_example/r_python_data/ga_nowember.csv")
ga_dec <- fread("https://raw.githubusercontent.com/selesnow/publications/master/data_example/r_python_data/ga_december.csv")
titanic <- fread("https://raw.githubusercontent.com/selesnow/publications/master/data_example/r_python_data/titanic.csv")Caricamento dei dati in Python: panda
Se confrontiamo con i pacchetti R, in questo caso la sintassi è la più vicina a pandas volontà readrperché pandas può richiedere dati da qualsiasi luogo e in questo pacchetto è presente un'intera famiglia di funzioni read_*().
read_csv()read_excel()read_sql()read_json()read_html()
E tante altre funzioni pensate per leggere dati da vari formati. Ma per i nostri scopi è sufficiente read_table() o read_csv() utilizzando l'argomento settembre per specificare il separatore di colonna.
Caricamento dei dati in Python: panda
import pandas as pd
ga_nov = pd.read_csv("https://raw.githubusercontent.com/selesnow/publications/master/data_example/russian_text_in_r/ga_nowember.csv", sep = "t")
ga_dec = pd.read_csv("https://raw.githubusercontent.com/selesnow/publications/master/data_example/russian_text_in_r/ga_december.csv", sep = "t")
titanic = pd.read_csv("https://raw.githubusercontent.com/selesnow/publications/master/data_example/russian_text_in_r/titanic.csv")Creazione di frame di dati
Tavolo titanico, che abbiamo caricato, c'è un campo Sesso, che memorizza l'identificatore di genere del passeggero.
Tuttavia, per una presentazione più comoda dei dati in termini di sesso dei passeggeri, è necessario utilizzare il nome anziché il codice sesso.
Per fare ciò creeremo una piccola directory, una tabella in cui ci saranno solo 2 colonne (codice e nome del genere) e 2 righe rispettivamente.
Creazione di un dataframe in R: tidyverse, dplyr
Nell'esempio di codice seguente, creiamo il dataframe desiderato utilizzando la funzione tibble() .
Creazione di un dataframe in R: dplyr
## dplyr
### создаём справочник
gender <- tibble(id = c(1, 2),
gender = c("female", "male"))Creazione di un dataframe in R: data.table
Creazione di un dataframe in R: data.table
## data.table
### создаём справочник
gender <- data.table(id = c(1, 2),
gender = c("female", "male"))
Creazione di un dataframe in Python: panda
В pandas La creazione dei frame viene eseguita in più fasi, prima creiamo un dizionario e poi convertiamo il dizionario in un dataframe.
Creazione di un dataframe in Python: panda
# создаём дата фрейм
gender_dict = {'id': [1, 2],
'gender': ["female", "male"]}
# преобразуем словарь в датафрейм
gender = pd.DataFrame.from_dict(gender_dict)Selezione delle colonne
Le tabelle con cui lavori possono contenere dozzine o addirittura centinaia di colonne di dati. Ma per eseguire l'analisi, di norma, non sono necessarie tutte le colonne disponibili nella tabella di origine.
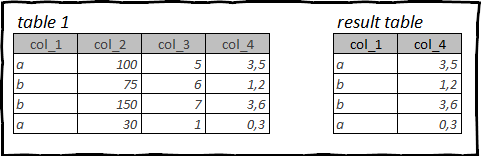
Pertanto, una delle prime operazioni che eseguirai con la tabella di origine sarà quella di cancellarla dalle informazioni non necessarie e liberare la memoria occupata da queste informazioni.
Selezione delle colonne in R: tidyverse, dplyr
sintassi dplyr è molto simile al linguaggio di query SQL, se lo conosci imparerai rapidamente a padroneggiare questo pacchetto.
Per selezionare le colonne, utilizzare la funzione select().
Di seguito sono riportati esempi di codice con cui è possibile selezionare le colonne nei seguenti modi:
- Elencare i nomi delle colonne richieste
- Fare riferimento ai nomi delle colonne utilizzando le espressioni regolari
- Per tipo di dati o qualsiasi altra proprietà dei dati contenuti nella colonna
Selezione delle colonne in R: dplyr
# Выбор нужных столбцов
## dplyr
### выбрать по названию столбцов
select(ga_nov, date, source, sessions)
### исключь по названию столбцов
select(ga_nov, -medium, -bounces)
### выбрать по регулярному выражению, стобцы имена которых заканчиваются на s
select(ga_nov, matches("s$"))
### выбрать по условию, выбираем только целочисленные столбцы
select_if(ga_nov, is.integer)Selezione delle colonne in R: data.table
Le stesse operazioni in data.table vengono eseguiti in modo leggermente diverso, all'inizio dell'articolo ho fornito una descrizione di quali argomenti sono racchiusi tra parentesi quadre data.table.
DT[i,j,by]
Dove:
io - dove, cioè filtraggio per righe
j - seleziona|aggiorna|esegui, cioè selezionando le colonne e convertendole
per - raggruppamento dei dati
Selezione delle colonne in R: data.table
## data.table
### выбрать по названию столбцов
ga_nov[ , .(date, source, sessions) ]
### исключь по названию столбцов
ga_nov[ , .SD, .SDcols = ! names(ga_nov) %like% "medium|bounces" ]
### выбрать по регулярному выражению
ga_nov[, .SD, .SDcols = patterns("s$")]Переменная .SD ti consente di accedere a tutte le colonne e .SDcols filtra le colonne richieste utilizzando espressioni regolari o altre funzioni per filtrare i nomi delle colonne che ti servono.
Selezione di colonne in Python, panda
Per selezionare le colonne per nome in pandas è sufficiente fornire un elenco dei loro nomi. E per selezionare o escludere colonne per nome utilizzando le espressioni regolari, è necessario utilizzare le funzioni drop() и filter()e argomento asse = 1, con cui si indica che è necessario elaborare le colonne anziché le righe.
Per selezionare un campo per tipo di dati, utilizzare la funzione select_dtypes()e in argomenti includere o escludere passare un elenco di tipi di dati corrispondenti ai campi che è necessario selezionare.
Selezione delle colonne in Python: panda
# Выбор полей по названию
ga_nov[['date', 'source', 'sessions']]
# Исключить по названию
ga_nov.drop(['medium', 'bounces'], axis=1)
# Выбрать по регулярному выражению
ga_nov.filter(regex="s$", axis=1)
# Выбрать числовые поля
ga_nov.select_dtypes(include=['number'])
# Выбрать текстовые поля
ga_nov.select_dtypes(include=['object'])Filtraggio delle righe
Ad esempio, la tabella di origine può contenere diversi anni di dati, ma è necessario analizzare solo il mese scorso. Anche in questo caso, righe aggiuntive rallenteranno il processo di elaborazione dei dati e ostruiranno la memoria del PC.
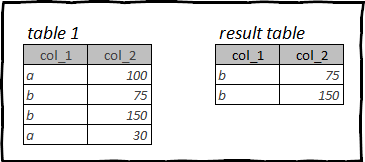
Filtraggio delle righe in R: tydyverse, dplyr
В dplyr la funzione viene utilizzata per filtrare le righe filter(). Richiede un dataframe come primo argomento, quindi elenchi le condizioni di filtraggio.
Quando si scrivono espressioni logiche per filtrare una tabella, in questo caso, specificare i nomi delle colonne senza virgolette e senza dichiarare il nome della tabella.
Quando si utilizzano più espressioni logiche per filtrare, utilizzare i seguenti operatori:
- & o virgola: AND logico
- | - OR logico
Filtraggio delle righe in R: dplyr
# фильтрация строк
## dplyr
### фильтрация строк по одному условию
filter(ga_nov, source == "google")
### фильтр по двум условиям соединённым логическим и
filter(ga_nov, source == "google" & sessions >= 10)
### фильтр по двум условиям соединённым логическим или
filter(ga_nov, source == "google" | sessions >= 10)Filtraggio delle righe in R: data.table
Come ho già scritto sopra, in data.table la sintassi di conversione dei dati è racchiusa tra parentesi quadre.
DT[i,j,by]
Dove:
io - dove, cioè filtraggio per righe
j - seleziona|aggiorna|esegui, cioè selezionando le colonne e convertendole
per - raggruppamento dei dati
L'argomento viene utilizzato per filtrare le righe i, che ha la prima posizione tra parentesi quadre.
È possibile accedere alle colonne in espressioni logiche senza virgolette e senza specificare il nome della tabella.
Le espressioni logiche sono correlate tra loro allo stesso modo di in dplyr tramite gli operatori & e |.
Filtraggio delle righe in R: data.table
## data.table
### фильтрация строк по одному условию
ga_nov[source == "google"]
### фильтр по двум условиям соединённым логическим и
ga_nov[source == "google" & sessions >= 10]
### фильтр по двум условиям соединённым логическим или
ga_nov[source == "google" | sessions >= 10]Filtrare le stringhe in Python: panda
Filtra per righe in pandas simile al filtraggio data.table, ed è racchiuso tra parentesi quadre.
In questo caso l'accesso alle colonne avviene necessariamente indicando il nome del dataframe; poi il nome della colonna può essere indicato anche tra virgolette tra parentesi quadre (esempio df['col_name']), o senza virgolette dopo il punto (esempio df.col_name).
Se è necessario filtrare un dataframe in base a diverse condizioni, ciascuna condizione deve essere inserita tra parentesi. Le condizioni logiche sono collegate tra loro tramite operatori & и |.
Filtrare le stringhe in Python: panda
# Фильтрация строк таблицы
### фильтрация строк по одному условию
ga_nov[ ga_nov['source'] == "google" ]
### фильтр по двум условиям соединённым логическим и
ga_nov[(ga_nov['source'] == "google") & (ga_nov['sessions'] >= 10)]
### фильтр по двум условиям соединённым логическим или
ga_nov[(ga_nov['source'] == "google") | (ga_nov['sessions'] >= 10)]Raggruppamento e aggregazione dei dati
Una delle operazioni più comunemente utilizzate nell'analisi dei dati è il raggruppamento e l'aggregazione.
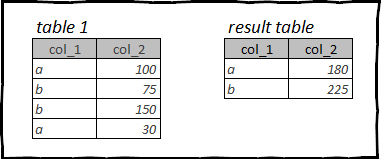
La sintassi per eseguire queste operazioni è sparsa in tutti i pacchetti che esaminiamo.
In questo caso, prenderemo come esempio un dataframe titanicoe calcola il numero e il costo medio dei biglietti a seconda della classe di cabina.
Raggruppamento e aggregazione di dati in R: tidyverse, dplyr
В dplyr la funzione viene utilizzata per il raggruppamento group_by()e per aggregazione summarise(). Infatti, dplyr c'è un'intera famiglia di funzioni summarise_*(), ma lo scopo di questo articolo è confrontare la sintassi di base, quindi non entreremo in questa giungla.
Funzioni di aggregazione di base:
sum()- sommatoriamin()/max()– valore minimo e massimomean()- mediamedian()– medianolength()- quantità
Raggruppamento e aggregazione in R: dplyr
## dplyr
### группировка и агрегация строк
group_by(titanic, Pclass) %>%
summarise(passangers = length(PassengerId),
avg_price = mean(Fare))In funzione group_by() abbiamo passato la tabella come primo argomento titanico, e poi ha indicato il campo Classe P, con il quale raggrupperemo la nostra tabella. Il risultato di questa operazione utilizzando l'operatore %>% passato come primo argomento alla funzione summarise()e ho aggiunto altri 2 campi: passeggeri и prezzo_avg. Nel primo, utilizzando la funzione length() calcolato il numero di biglietti, e nel secondo utilizzando la funzione mean() ricevuto il prezzo medio del biglietto.
Raggruppamento e aggregazione di dati in R: data.table
В data.table l'argomento viene utilizzato per l'aggregazione j che ha una seconda posizione tra parentesi quadre e per il raggruppamento by o keyby, che occupano la terza posizione.
L'elenco delle funzioni di aggregazione in questo caso è identico a quello descritto in dplyr, Perché queste sono funzioni della sintassi R di base.
Raggruppamento e aggregazione in R: data.table
## data.table
### фильтрация строк по одному условию
titanic[, .(passangers = length(PassengerId),
avg_price = mean(Fare)),
by = Pclass]Raggruppamento e aggregazione di dati in Python: panda
Raggruppamento pandas simile a dplyr, ma l'aggregazione non è simile a dplyr Non sopra data.table.
Per raggruppare, utilizzare il metodo groupby(), in cui è necessario passare un elenco di colonne in base alle quali verrà raggruppato il dataframe.
Per l'aggregazione è possibile utilizzare il metodo agg()che accetta un dizionario. Le chiavi del dizionario sono le colonne su cui applicherai le funzioni di aggregazione e i valori sono i nomi delle funzioni di aggregazione.
Funzioni di aggregazione:
sum()- sommatoriamin()/max()– valore minimo e massimomean()- mediamedian()– medianocount()- quantità
Funzione reset_index() nell'esempio seguente viene utilizzato per reimpostare gli indici nidificati that pandas per impostazione predefinita viene effettuata dopo l'aggregazione dei dati.
simbolo consente di passare alla riga successiva.
Raggruppamento e aggregazione in Python: panda
# группировка и агрегация данных
titanic.groupby(["Pclass"]).
agg({'PassengerId': 'count', 'Fare': 'mean'}).
reset_index()Unione verticale delle tabelle
Un'operazione in cui si uniscono due o più tabelle della stessa struttura. I dati che abbiamo caricato contengono tabelle ga_nov и ga_dec. Queste tabelle sono identiche nella struttura, cioè hanno le stesse colonne e i tipi di dati in queste colonne.
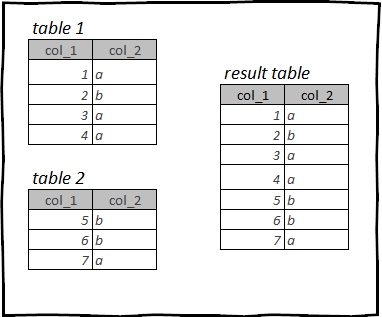
Questo è un caricamento da Google Analytics per il mese di novembre e dicembre, in questa sezione combineremo questi dati in un'unica tabella.
Unire verticalmente i tavoli in R: tidyverse, dplyr
В dplyr Puoi combinare 2 tabelle in una utilizzando la funzione bind_rows(), passando le tabelle come argomenti.
Filtraggio delle righe in R: dplyr
# Вертикальное объединение таблиц
## dplyr
bind_rows(ga_nov, ga_dec)Unione verticale di tabelle in R: data.table
Inoltre non è niente di complicato, usiamolo rbind().
Filtraggio delle righe in R: data.table
## data.table
rbind(ga_nov, ga_dec)Unione verticale di tabelle in Python: panda
В pandas la funzione viene utilizzata per unire le tabelle concat(), in cui è necessario passare un elenco di frame per combinarli.
Filtrare le stringhe in Python: panda
# вертикальное объединение таблиц
pd.concat([ga_nov, ga_dec])Unione orizzontale dei tavoli
Un'operazione in cui le colonne della seconda vengono aggiunte alla prima tabella tramite chiave. Viene spesso utilizzato quando si arricchisce una tabella fattuale (ad esempio una tabella con dati di vendita) con alcuni dati di riferimento (ad esempio il costo di un prodotto).
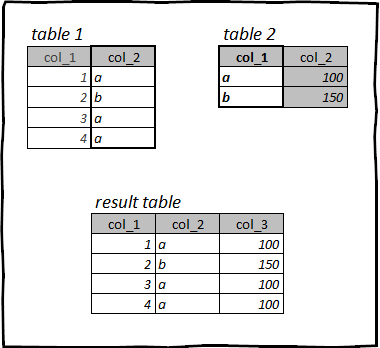
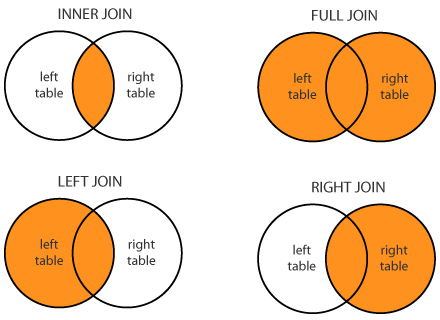
Esistono diversi tipi di join:
Nella tabella precedentemente caricata titanico abbiamo una colonna Sesso, che corrisponde al codice genere del passeggero:
1 - femmina
2 - maschio
Inoltre, abbiamo creato una tabella: un libro di consultazione genere. Per una presentazione più comoda dei dati sul sesso dei passeggeri, dobbiamo aggiungere il nome del genere dalla directory genere al tavolo titanico.
Unione del tavolo orizzontale in R: tidyverse, dplyr
В dplyr Esiste un'intera famiglia di funzioni per l'unione orizzontale:
inner_join()left_join()right_join()full_join()semi_join()nest_join()anti_join()
Il più comunemente usato nella mia pratica è left_join().
Come primi due argomenti, le funzioni elencate sopra accettano due tabelle da unire e come terzo argomento by è necessario specificare le colonne da unire.
Il tavolo orizzontale si unisce a R: dplyr
# объединяем таблицы
left_join(titanic, gender,
by = c("Sex" = "id"))Unione orizzontale di tabelle in R: data.table
В data.table È necessario unire le tabelle per chiave utilizzando la funzione merge().
Argomenti per la funzione merge() in data.table
- x, y — Tabelle per l'unione
- by — Colonna che rappresenta la chiave da unire se ha lo stesso nome in entrambe le tabelle
- by.x, by.y — Nomi delle colonne da unire, se hanno nomi diversi nelle tabelle
- all, all.x, all.y — Tipo di join, all restituirà tutte le righe di entrambe le tabelle, all.x corrisponde all'operazione LEFT JOIN (lascerà tutte le righe della prima tabella), all.y — corrisponde all'operazione Operazione RIGHT JOIN (lasceranno tutte le righe della seconda tabella).
Unione orizzontale di tabelle in R: data.table
# объединяем таблицы
merge(titanic, gender, by.x = "Sex", by.y = "id", all.x = T)Unione tabella orizzontale in Python: panda
Così come dentro data.tableIn pandas la funzione viene utilizzata per unire le tabelle merge().
Argomenti della funzione merge() nei panda
- come — Tipo di connessione: sinistra, destra, esterna, interna
- on — Colonna che è una chiave se ha lo stesso nome in entrambe le tabelle
- left_on, right_on — Nomi delle colonne chiave, se hanno nomi diversi nelle tabelle
Unione tabella orizzontale in Python: panda
# объединяем по ключу
titanic.merge(gender, how = "left", left_on = "Sex", right_on = "id")Funzioni di base della finestra e colonne calcolate
Le funzioni finestra hanno un significato simile alle funzioni di aggregazione e vengono spesso utilizzate anche nell'analisi dei dati. Ma a differenza delle funzioni di aggregazione, le funzioni finestra non modificano il numero di righe del dataframe in uscita.
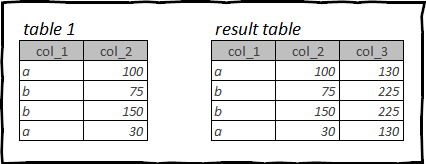
Essenzialmente, utilizzando la funzione window, dividiamo il dataframe in arrivo in parti secondo alcuni criteri, ad es. dal valore di un campo o di più campi. Ed eseguiamo operazioni aritmetiche su ciascuna finestra. Il risultato di queste operazioni verrà restituito in ogni riga, ad es. senza modificare il numero totale di righe nella tabella.
Prendiamo ad esempio il tavolo titanico. Possiamo calcolare la percentuale del costo di ciascun biglietto all'interno della sua classe di cabina.
Per fare ciò, dobbiamo ottenere in ciascuna riga il costo totale di un biglietto per la classe di cabina corrente a cui appartiene il biglietto in questa riga, quindi dividere il costo di ciascun biglietto per il costo totale di tutti i biglietti della stessa classe di cabina .
Funzioni finestra in R: tidyverse, dplyr
Per aggiungere nuove colonne, senza utilizzare il raggruppamento di righe, in dplyr serve alla funzione mutate().
Puoi risolvere il problema sopra descritto raggruppando i dati per campo Classe P e sommando il campo in una nuova colonna tariffa. Successivamente, separa la tabella e dividi i valori dei campi tariffa a quanto accaduto nel passaggio precedente.
Funzioni della finestra in R: dplyr
group_by(titanic, Pclass) %>%
mutate(Pclass_cost = sum(Fare)) %>%
ungroup() %>%
mutate(ticket_fare_rate = Fare / Pclass_cost)Funzioni della finestra in R: data.table
L'algoritmo di soluzione rimane lo stesso di dplyr, dobbiamo dividere la tabella in finestre per campo Classe P. Emetti in una nuova colonna l'importo per il gruppo corrispondente a ciascuna riga e aggiungi una colonna in cui calcoliamo la quota del costo di ciascun biglietto nel suo gruppo.
Per aggiungere nuove colonne a data.table operatore presente :=. Di seguito è riportato un esempio di risoluzione di un problema utilizzando il pacchetto data.table
Funzioni della finestra in R: data.table
titanic[,c("Pclass_cost","ticket_fare_rate") := .(sum(Fare), Fare / Pclass_cost),
by = Pclass]Funzioni della finestra in Python: panda
Un modo per aggiungere una nuova colonna a pandas - utilizzare la funzione assign(). Per riepilogare il costo dei biglietti per classe di cabina, senza raggruppare righe, utilizzeremo la funzione transform().
Di seguito è riportato un esempio di soluzione in cui aggiungiamo alla tabella titanico le stesse 2 colonne.
Funzioni della finestra in Python: panda
titanic.assign(Pclass_cost = titanic.groupby('Pclass').Fare.transform(sum),
ticket_fare_rate = lambda x: x['Fare'] / x['Pclass_cost'])Tabella di corrispondenza funzioni e metodi
Di seguito è riportata una tabella di corrispondenza tra i metodi per eseguire varie operazioni con i dati nei pacchetti che abbiamo considerato.
Descrizione
tidyverse
tabella dati
panda
Caricamento dati
vroom()/ readr::read_csv() / readr::read_tsv()
fread()
read_csv()
Creazione di frame di dati
tibble()
data.table()
dict() + from_dict()
Selezione delle colonne
select()
discussione j, seconda posizione tra parentesi quadre
passiamo l'elenco delle colonne richieste tra parentesi quadre / drop() / filter() / select_dtypes()
Filtraggio delle righe
filter()
discussione i, prima posizione tra parentesi quadre
Elenchiamo le condizioni di filtraggio tra parentesi quadre / filter()
Raggruppamento e aggregazione
group_by() + summarise()
argomenti j + by
groupby() + agg()
Unione verticale dei tavoli (UNION)
bind_rows()
rbind()
concat()
Unione orizzontale delle tabelle (JOIN)
left_join() / *_join()
merge()
merge()
Funzioni di base della finestra e aggiunta di colonne calcolate
group_by() + mutate()
discussione j utilizzando l'operatore := + argomento by
transform() + assign()
conclusione
Forse nell'articolo non ho descritto le implementazioni più ottimali dell'elaborazione dei dati, quindi sarò felice se correggi i miei errori nei commenti o semplicemente integri le informazioni fornite nell'articolo con altre tecniche per lavorare con i dati in R / Python.
Come ho scritto sopra, lo scopo dell’articolo non era imporre la propria opinione su quale lingua sia migliore, ma semplificare l’opportunità di apprendere entrambe le lingue o, se necessario, di migrare tra di loro.
Se ti è piaciuto l'articolo, sarò felice di avere nuovi abbonati al mio и canali.
Опрос
Quale dei seguenti pacchetti utilizzi nel tuo lavoro?
Nei commenti puoi scrivere il motivo della tua scelta.
Solo gli utenti registrati possono partecipare al sondaggio. Per favore.
Quale pacchetto di elaborazione dati utilizzi (puoi selezionare diverse opzioni)
-
45,2%tidyverse19
-
33,3%dati.tabella14
-
54,8%panda23
42 utenti hanno votato. 9 utenti si sono astenuti.
Fonte: habr.com
