


In molti si imbattono in Elasticsearch. Ma cosa succede quando si desidera utilizzarlo per memorizzare i log "in grande quantità"? E come affrontare senza difficoltà il guasto di uno dei numerosi data center? Quale architettura si dovrebbe realizzare e quali insidie si possono incontrare?
Noi di Odnoklassniki abbiamo deciso di affrontare la questione della gestione dei log usando Elasticsearch e ora condividiamo la nostra esperienza su Habr: parliamo sia di architettura che di possibili problematiche.
Sono Pëtr Zaicev, lavoro come amministratore di sistema presso Odnoklassniki. In precedenza, ho lavorato come amministratore per Manticore Search, Sphinx Search ed Elasticsearch. Se dovesse sorgere un altro ...search, probabilmente lavorerò anche con quello. Partecipo anche a vari progetti open source su base volontaria.
Quando sono arrivato in Odnoklassniki, ho avventatamente affermato durante il colloquio che sapevo lavorare con Elasticsearch. Dopo aver preso confidenza e aver completato alcuni compiti semplici, mi è stata assegnata una grande sfida: riformare il sistema di gestione dei log esistente in quel momento.
Requisiti
I requisiti del sistema sono stati formulati come segue:
- Come front-end doveva essere utilizzato Graylog. Questo perché l'azienda aveva già esperienza nell'uso di questo prodotto, e programmatori e tester lo conoscevano, era familiare e comodo per loro.
- Volume dei dati: in media 50-80 mila messaggi al secondo, ma se qualcosa va storto, il traffico non è limitato, può arrivare a 2-3 milioni di righe al secondo.
- Discutendo con i clienti i requisiti per la velocità di elaborazione delle richieste di ricerca, abbiamo capito che il modello tipico di utilizzo di un sistema simile è questo: le persone cercano i log della loro applicazione degli ultimi due giorni e non vogliono aspettare più di un secondo per i risultati della richiesta formulata.
- Gli amministratori insistevano affinché il sistema potesse facilmente scalare, se necessario, senza richiedere loro una profonda comprensione di come fosse strutturato.
- L'unica operazione di manutenzione di cui questi sistemi avevano bisogno periodicamente era la sostituzione dell'hardware.
- Inoltre, in Odnoklassniki c'è una splendida tradizione tecnica: qualsiasi servizio che lanciamo deve resistere all'interruzione di un data center (improvvisa, imprevista e in qualsiasi momento).
L'ultimo requisito nella realizzazione di questo progetto ci è costato molto, di cui parlerò più in dettaglio.
Ambiente
Operiamo su quattro data center, mentre i nodi dati Elasticsearch possono trovarsi solo in tre (per una serie di motivi non tecnici).
In questi quattro data center ci sono circa 18.000 diverse sorgenti di log: hardware, container, macchine virtuali.
Una caratteristica importante: il cluster viene avviato in container non su macchine fisiche, ma su . Ai container vengono garantiti 2 core, equivalenti a 2.0Ghz v4, con la possibilità di utilizzare gli altri core in caso di inattività.
In altre parole:

Topologia
L'aspetto generale della soluzione mi era inizialmente apparso nel seguente modo:
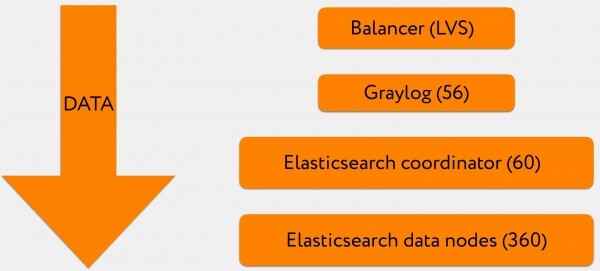
- 3-4 VIP sono dietro il record A del dominio Graylog, è l'indirizzo al quale vengono inviati i log.
- ogni VIP è un bilanciatore LVS.
- Dopo di ciò, i log arrivano a una batteria Graylog, parte dei dati è in formato GELF, parte in formato syslog.
- Successivamente, tutto questo viene scritto in grandi batch in una batteria di coordinatori Elasticsearch.
- E loro, a loro volta, inviano richieste di scrittura e lettura ai nodi dati pertinenti.
Terminologia
È possibile che non tutti abbiano familiarità con la terminologia, quindi vorremmo soffermarci un momento su di essa.
In Elasticsearch ci sono diversi tipi di nodi: master, coordinatore e nodo dati. Esistono anche altri due tipi per diverse trasformazioni dei log e per la connessione tra diversi cluster, ma noi abbiamo utilizzato solo quelli elencati.
Master
Controlla tutti i nodi presenti nel cluster, mantiene la mappa del cluster aggiornata e la distribuisce tra i nodi, gestisce la logica degli eventi e si occupa di vari aspetti della manutenzione del cluster.
Coordinatore
Svolge un compito unico: accetta richieste dai clienti per la lettura o la scrittura e smista questo traffico. Nel caso di una richiesta di scrittura, probabilmente chiederà al master in quale shard del relativo indice deve collocarlo e reindirizzerà la richiesta.
Nodo dati
Memorizza i dati ed esegue le ricerche e le operazioni sugli shard ad essa associati.
Graylog
Si tratta di una sorta di fusione tra Kibana e Logstash nell'ELK stack. Graylog combina un'interfaccia utente e una pipeline per l'elaborazione dei log. Sotto il cofano, Graylog utilizza Kafka e Zookeeper, che garantiscono la connettività del cluster Graylog. Graylog è in grado di memorizzare in cache i log (Kafka) in caso di indisponibilità di Elasticsearch e ripetere le richieste di lettura e scrittura non riuscite, raggruppando e contrassegnando i log in base a regole predefinite. Proprio come Logstash, Graylog offre funzionalità per modificare le stringhe prima di scriverle in Elasticsearch.
Inoltre, Graylog ha un service discovery integrato che consente, partendo da un nodo Elasticsearch disponibile, di ottenere l'intera mappa del cluster e di filtrarla in base a un determinato tag, permettendo di indirizzare le richieste verso contenitori specifici.
Visualmente, appare più o meno così:

Questo è uno screenshot di un'istanza specifica. Qui costruiamo un istogramma in base alla query di ricerca, mostrando le righe pertinenti.
Indici
Tornando all'architettura del sistema, vorrei soffermarmi più dettagliatamente su come abbiamo costruito il modello degli indici affinché tutto funzionasse correttamente.
Nello schema mostrato in precedenza, questo è il livello più basso: i nodi dati di Elasticsearch.
L'indice è una grande entità virtuale composta da shard Elasticsearch. Ogni shard, a sua volta, non è altro che un indice Lucene. E ogni indice Lucene, a sua volta, è composto da uno o più segmenti.
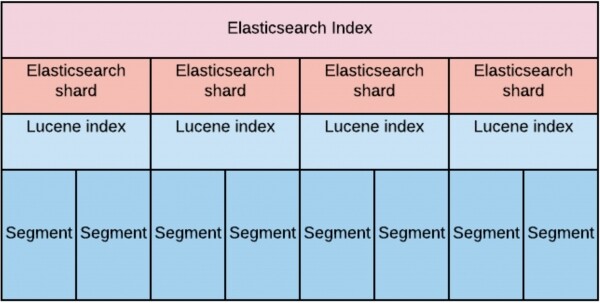
Nella progettazione, abbiamo stimato che per soddisfare il requisito di velocità di lettura su un grande volume di dati, fosse necessario 'spalmare' uniformemente questi dati sui data node.
Questo si è tradotto nel fatto che il numero di shard per indice (con repliche) deve essere strettamente uguale al numero di data node. In primo luogo, per garantire un fattore di replica pari a due (cioè possiamo perdere metà del cluster). In secondo luogo, per elaborare le richieste di lettura e scrittura, almeno su metà del cluster.
Il tempo di conservazione inizialmente è stato definito in 30 giorni.
La distribuzione degli shard può essere rappresentata graficamente come segue:

L'intero rettangolo grigio scuro rappresenta l'indice. Il quadrato rosso a sinistra è il primary shard, il primo nell'indice. Il quadrato blu è il replica shard. Si trovano in diversi data center.
Quando aggiungiamo un'altra shard, questa va nel terzo data center. E, alla fine, otteniamo una struttura come questa, che garantisce la possibilità di perdere un DC senza compromettere la coerenza dei dati:

Abbiamo impostato la rotazione degli indici, ovvero la creazione di un nuovo indice e la rimozione di quello più vecchio, a 48 ore (in base al modello di utilizzo dell'indice: nelle ultime 48 ore le ricerche avvengono più frequentemente).
Questo intervallo di rotazione degli indici è legato alle seguenti ragioni:
Quando una richiesta di ricerca arriva a una specifica data node, dal punto di vista delle prestazioni è più vantaggioso interrogare un solo shard, a condizione che la sua dimensione sia comparabile a quella della memoria della node. Questo consente di tenere la parte 'calda' dell'indice in memoria e accedervi rapidamente. Quando ci sono molte 'parti calde', la velocità di ricerca nell'indice ne risente.
Quando il nodo inizia a eseguire una query di ricerca su uno shard, assegna un numero di thread pari al numero di core fisici con hyper-threading nel server. Se la query di ricerca coinvolge un gran numero di shard, il numero di thread aumenta proporzionalmente. Questo influisce negativamente sulla velocità di ricerca e compromette l'indicizzazione di nuovi dati.
Per garantire la latenza necessaria per la ricerca, abbiamo deciso di utilizzare SSD. Per una rapida elaborazione delle richieste, le macchine su cui erano ospitati questi contenitori dovevano avere almeno 56 core. Il numero 56 è stato scelto come valore condizionalmente sufficiente, che determina il numero di thread che Elasticsearch genererà durante il suo funzionamento. In Elasticsearch molti parametri del thread pool dipendono direttamente dal numero di core disponibili, il che a sua volta influisce direttamente sul numero necessario di nodi nel cluster secondo il principio 'meno core — più nodi'.
Alla fine, abbiamo ottenuto che in media uno shard pesa circa 20 gigabyte, e per 1 indice ci sono 360 shard. Di conseguenza, se li ruotiamo ogni 48 ore, ne abbiamo 15. Ogni indice contiene dati per 2 giorni.
Schema di scrittura e lettura dei dati
Vediamo come vengono registrati i dati in questo sistema.
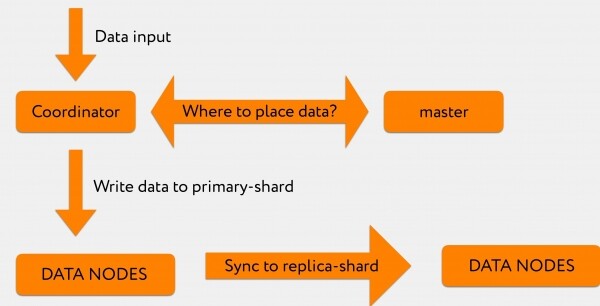
Supponiamo di ricevere una richiesta da Graylog nel coordinatore. Ad esempio, vogliamo indicizzare 2-3 mila righe.
Il coordinatore, ricevuta la richiesta da Graylog, interroga il master: "Nella richiesta di indicizzazione è stato specificato un indice, ma non è stato indicato in quale shard scrivere".
Il Master risponde: "Scrivi queste informazioni nello shard numero 71", dopodiché vengono inviate direttamente al nodo dati rilevante, dove si trova il primary-shard numero 71.
Successivamente, il log delle transazioni viene replicato sul replica-shard, che si trova già in un altro data center.
Da Graylog arriva una richiesta di ricerca al coordinatore. Il coordinatore la reindirizza in base all'indice, mentre Elasticsearch distribuisce le richieste tra primary-shard e replica-shard secondo il principio del round-robin.
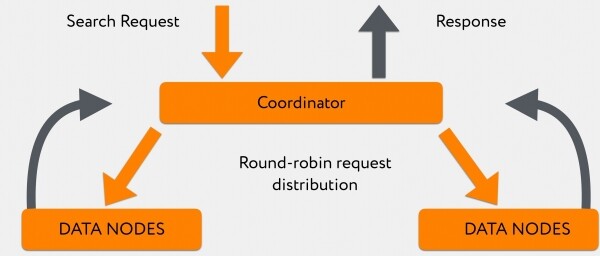
Le nodi, in numero di 180, rispondono in modo non uniforme, e mentre rispondono, il coordinatore accumula informazioni che già gli sono state "spit out" da nodi dati più veloci. Dopo che tutte le informazioni sono arrivate o quando è scaduto il timeout della richiesta, restituisce tutto direttamente al cliente.
L'intero sistema gestisce in media le richieste di ricerca negli ultimi 48 ore in 300-400 ms, escludendo quelle con carattere jolly iniziale.
«Fiorellini» con Elasticsearch: configurazione di Java

Affinché tutto questo funzionasse come volevamo inizialmente, abbiamo dedicato molto tempo a risolvere vari problemi nel cluster.
La prima parte dei problemi riscontrati riguardava la configurazione predefinita di Java in Elasticsearch.
Primo problema
Abbiamo osservato un numero molto elevato di messaggi che indicavano che, a livello di Lucene, quando venivano eseguiti i job in background, i merge dei segmenti di Lucene terminavano con un errore. Nei log si poteva vedere che si trattava di un errore OutOfMemoryError. Dalla telemetria abbiamo verificato che l'heap era libero e non era chiaro perché questa operazione fallisse.
Si è scoperto che i merge degli indici di Lucene avvenivano al di fuori dell'heap. Inoltre, i container sono piuttosto rigidamente limitati nelle risorse consumate. Queste risorse rientravano solo nell'heap (il valore heap.size era approssimativamente uguale alla RAM), mentre alcune operazioni off-heap fallivano con errori di allocazione di memoria se, per qualche motivo, non rientravano nei ~500 MB che rimanevano fino al limite.
La soluzione è stata piuttosto semplice: abbiamo aumentato la quantità di RAM disponibile per il container, dopodiché abbiamo smesso di avere problemi di questo tipo.
Problema due
Dopo circa 4-5 giorni dal lancio del cluster, abbiamo notato che i nodi di dati cominciavano a disconnettersi periodicamente dal cluster, per poi riconnettersi dopo circa 10-20 secondi.
Quando abbiamo iniziato a indagare, ci siamo resi conto che la memoria off-heap in Elasticsearch non è praticamente controllata. Quando abbiamo dato più memoria al container, abbiamo potuto riempire i pool di buffer diretti con varie informazioni, e veniva liberata solo dopo l'attivazione di un GC esplicito da parte di Elasticsearch.
In alcuni casi, questa operazione avveniva piuttosto lentamente, e nel frattempo il cluster riusciva a contrassegnare quel nodo come già disconnesso. Questo problema è ben documentato. .
La soluzione è stata la seguente: abbiamo limitato a Java la possibilità di utilizzare la maggior parte della memoria fuori dal heap per queste operazioni. L'abbiamo limitata a 16 gigabyte (-XX:MaxDirectMemorySize=16g), ottenendo così che il GC esplicito venisse attivato molto più frequentemente e si esaurisse molto più rapidamente, stabilizzando il cluster.
Il terzo problema
Se pensi che i problemi con i "nodi che abbandonano il cluster nel momento più inaspettato" siano finiti, ti sbagli.
Quando abbiamo configurato il lavoro con gli indici, abbiamo scelto mmapfs per sui nuovi shard con alta segmentazione. Questo si è rivelato un errore piuttosto grossolano, perché con mmapfs il file viene mappato in memoria RAM, e poi lavoriamo già con il file mappato. Di conseguenza, quando il garbage collector cerca di fermare i thread nell'applicazione, impieghiamo molto tempo per raggiungere il safepoint, e lungo il percorso l'applicazione smette di rispondere alle richieste del master riguardo alla sua disponibilità. Pertanto, il master considera che il nodo non sia più presente nel cluster. Dopo circa 5-10 secondi, il garbage collector entra in azione, il nodo si riprende, rientra nel cluster e inizia l'inizializzazione degli shard. Tutto questo ricordava molto il “produzione che ci meritavamo” e non era adatto per nulla di serio.
Per risolvere questo comportamento, abbiamo prima migrato su standard niofs e poi, quando siamo passati dalle versioni 5 a quelle 6 di Elastic, abbiamo provato hybridfs, dove questo problema non si è ripresentato. Puoi leggere di più sui tipi di storage. .
Il quarto problema
Poi c'è stato un problema molto intrigante, che abbiamo affrontato per un tempo record. Lo abbiamo inseguito per 2-3 mesi, perché il suo schema era assolutamente incomprensibile.
A volte i nostri coordinatori andavano in Full GC, solitamente dopo pranzo, e non tornavano più. Durante il logging delle latenze GC, sembrava che tutto andasse bene, bene, bene, e poi all'improvviso — tutto andava male.
All'inizio pensavamo che avessimo un utente malintenzionato, che lanciava qualche richiesta che interrompeva il coordinatore dallo stato di lavoro. Abbiamo registrato le richieste a lungo, cercando di capire cosa stesse succedendo.
Alla fine si è scoperto che nel momento in cui un utente invia una grande richiesta, e questa arriva su un coordinatore Elasticsearch specifico, alcune nodi rispondono più lentamente delle altre.
E durante il tempo in cui il coordinatore attende la risposta da tutti i nodi, accumula in sé i risultati inviati dai nodi che hanno già risposto. Per il GC, questo significa che il nostro pattern di utilizzo della heap cambia molto rapidamente. E il GC che abbiamo utilizzato non riusciva a gestire questo compito.
L'unica soluzione che abbiamo trovato per cambiare il comportamento del cluster in questa situazione è stata la migrazione a JDK13 e l'utilizzo del garbage collector Shenandoah. Questo ha risolto il problema, e i coordinatori hanno smesso di cadere.
In questo modo, i problemi con Java si sono conclusi e sono iniziati i problemi con la capacità di elaborazione.
«Bacche» con Elasticsearch: capacità di elaborazione

I problemi con la capacità di elaborazione significano che il nostro cluster funziona in modo stabile, ma nei picchi del numero di documenti indicizzati e nei momenti di manovra, le prestazioni non sono sufficienti.
Il primo sintomo riscontrato: durante alcuni «esplosioni» in produzione, quando viene generata improvvisamente una grande quantità di log, in Graylog inizia a comparire frequentemente l'errore di indicizzazione es_rejected_execution.
Questo accade perché il thread_pool.write.queue su un nodo dati, fino a quando Elasticsearch riesce a elaborare la richiesta di indicizzazione e inviare le informazioni al shard su disco, per impostazione predefinita può cacheare solo 200 richieste. E in si parla ben poco di questo parametro. Viene indicato solo il numero massimo di thread e la dimensione predefinita.
Naturalmente, abbiamo deciso di modificare questo valore e abbiamo scoperto quanto segue: specificamente nella nostra configurazione, è possibile cacheare fino a 300 richieste, mentre un valore più elevato comporta di nuovo il rischio di entrare in Full GC.
Inoltre, poiché si tratta di blocchi di messaggi che arrivano all'interno di una sola richiesta, è stato necessario anche regolare Graylog affinché scrivesse non frequentemente e in piccoli blocchi, ma in blocchi grandi o ogni 3 secondi, se il blocco non è ancora completo. In questo caso, le informazioni che scriviamo in Elasticsearch diventano disponibili non dopo due secondi, ma dopo cinque (cosa che ci va bene), ma diminuisce il numero di retry necessari per inviare un grande pacchetto di informazioni.
Questo è particolarmente importante nei momenti in cui qualcosa è andato in crash e ci manda notifiche accanite, per evitare di sovraccaricare completamente Elastic, e dopo un po' di tempo avere nodi Graylog non funzionanti a causa di buffer pieni.
Inoltre, nel momento in cui abbiamo avuto queste esplosioni in produzione, ci sono arrivate lamentele da parte di programmatori e tester: quando avevano davvero bisogno di quei log, venivano forniti a loro con grande lentezza.
Abbiamo iniziato a indagare. Da un lato, era chiaro che le query di ricerca e le richieste di indicizzazione venivano elaborate, sostanzialmente, sulle stesse macchine fisiche, e ci sarebbero state, in un modo o nell'altro, delle cali di prestazioni.
Ma questo poteva essere in parte aggirato grazie al fatto che nelle versioni sei di Elasticsearch è stato introdotto un algoritmo che consente di distribuire le richieste tra nodi data rilevanti non in base a un principio casuale round-robin (il container che si occupa dell'indicizzazione e tiene il primary-shard potrebbe essere molto occupato, e non ci sarebbe la possibilità di rispondere rapidamente), ma di indirizzare questa richiesta su un container meno carico con replica-shard, che risponderà significativamente più velocemente. In altre parole, siamo arrivati a use_adaptive_replica_selection: true.
I quadri di lettura cominciano a presentarsi così:
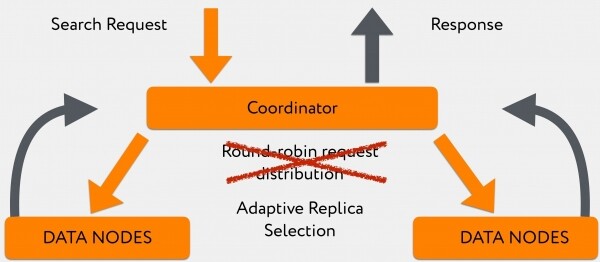
Il passaggio a questo algoritmo ha permesso di migliorare notevolmente il tempo di query nei momenti in cui avevamo un grande flusso di log in scrittura.
Finalmente, il problema principale riguardava la gestione indolore del data center.
Cosa volevamo dal cluster subito dopo la perdita di connessione con un DC:
- Se il master attuale si trova nel data center disconnesso, verrà ripristinato e trasferito come ruolo su un altro nodo in un altro DC.
- Il master rimuoverà rapidamente dal cluster tutti i nodi non disponibili.
- Sulla base di quelli rimanenti, comprenderà: nel data center perso avevamo spazi primari di questo tipo, promuoverà rapidamente gli shard replica complementari nei data center rimanenti, e continueremo a indicizzare i dati.
- Di conseguenza, la capacità del cluster in scrittura e lettura degraderà gradualmente, tuttavia in generale tutto funzionerà, anche se lentamente, ma stabilmente.
Come si è scoperto, volevamo qualcosa del genere:

E abbiamo ottenuto quanto segue:

Come è potuto accadere?
Nel momento della caduta del data center, il collo di bottiglia è diventato il master.
Perché?
La questione è che nel master c'è un TaskBatcher, responsabile della distribuzione di determinate attività ed eventi nel cluster. Qualsiasi uscita di un nodo, qualsiasi promozione di uno shard da replica a primary, qualsiasi attività di creazione di uno shard da qualche parte — tutto questo passa prima nel TaskBatcher, dove viene elaborato in sequenza e in un unico flusso.
Nel momento in cui un data center viene disconnesso, si verificava che tutti i data node nei data center sopravvissuti si sentissero obbligati a comunicare al master: «abbiamo perso tali shard e tali data node».
A questo punto, i data node sopravvissuti inviavano tutte queste informazioni al master attuale e cercavano di attendere una conferma che le avesse ricevute. Non ricevevano mai questa conferma, poiché il master riceveva le attività più rapidamente di quanto riuscisse a rispondere. I nodi ripetevano le richieste dopo un timeout, mentre il master in quel momento non cercava nemmeno di rispondere, essendo completamente assorbito dall'attività di ordinamento delle richieste per priorità.
Nei log sono emerse problematiche in cui i nodi dati sovraccaricavano il master fino a causare un garbage collection completo. Successivamente, il ruolo del master veniva spostato su un altro nodo, e accadeva esattamente la stessa cosa, portando infine al completo crollo del cluster.
Abbiamo effettuato delle misurazioni e fino alla versione 6.4.0, dove questo problema è stato risolto, ci bastava disattivare simultaneamente solo 10 nodi dati su 360 per mandare completamente in crash il cluster.
A questo punto, si presentava all'incirca in questo modo:

Dopo la versione 6.4.0, dove è stato risolto quel fastidioso bug, i nodi dati hanno smesso di sovraccaricare il master. Tuttavia, non è diventato «più intelligente». In particolare: quando disattiviamo 2, 3 o 10 (qualunque numero diverso da uno) nodi dati, il master riceve un primo messaggio che informa che il nodo A è fuori servizio e cerca di comunicare questo nodo B, nodo C, nodo D.
Al momento, l'unico modo per affrontare questo problema è impostare un timeout per i tentativi di comunicazione, pari a circa 20-30 secondi, gestendo così la velocità di disattivazione del data center dal cluster.
In linea di principio, questo rientra nei requisiti che erano stati inizialmente forniti per il prodotto finale all'interno del progetto, ma da un punto di vista di 'pura scienza', si tratta di un bug. Che, tra l'altro, è stato risolto con successo dagli sviluppatori nella versione 7.2.
Infatti, quando un nodo datale si disconnetteva, risultava che diffondere l'informazione riguardo alla sua disconnessione fosse più importante che comunicare a tutto il cluster che su di esso si trovavano tali primary-shard (per promuovere il replica-shard in un altro data center come primary, e poterci scrivere informazioni).
Pertanto, quando tutto si è 'calmato', i nodi datale fuori servizio non vengono immediatamente etichettati come stale. Di conseguenza, siamo costretti ad aspettare che tutti i ping ai nodi datale disconnessi timeout e solo dopo ciò il nostro cluster inizia a comunicare che là, là e là è necessario continuare a scrivere informazioni. Maggiori dettagli possono essere letti qui. .
Alla fine, l'operazione di disconnessione del data center oggi ci richiede circa 5 minuti durante l'ora di punta. Per una macchina così grande e ingombrante, è un risultato piuttosto buono.
Di conseguenza, siamo giunti alla seguente soluzione:
- Abbiamo 360 nodi datale con dischi da 700 gigabyte.
- 60 coordinatori per il routing del traffico verso questi nodi di dati.
- 40 nodi che ci sono rimasti come un'eredità dalle versioni precedenti alla 6.4.0 — per affrontare la chiusura del data center, eravamo moralmente pronti a perdere alcune macchine, per garantire di avere un quorum di nodi anche nel peggiore dei scenari.
- Qualsiasi tentativo di combinare ruoli su un singolo container si è scontrato con il fatto che prima o poi un nodo si rompeva sotto carico.
- In tutto il cluster viene utilizzato un heap.size pari a 31 gigabyte: tutti i tentativi di ridurre la dimensione portavano al fatto che durante pesanti query di ricerca con leading wildcard o si danneggiavano alcuni nodi, oppure si attivava il circuito di protezione in Elasticsearch stesso.
- Inoltre, per garantire le prestazioni di ricerca, cercavamo di mantenere il numero di oggetti nel cluster il più minimo possibile, in modo da gestire il minor numero di eventi nel punto più critico che abbiamo individuato nel master.
Infine, sul monitoraggio
Per far funzionare tutto come previsto, monitoriamo quanto segue:
- Ogni nodo di dati comunica al nostro cloud la sua presenza e quali shard ospita. Quando spegniamo qualcosa, il cluster riporta entro 2-3 secondi che nel centro A abbiamo spento i nodi 2, 3 e 4 — questo significa che non possiamo in alcun modo spegnere i nodi in altri data center che ospitano shard in singolo esemplare.
- Conoscendo il comportamento del master, monitoriamo attentamente il numero di task pending. Perché anche un singolo task bloccato, se non viene timeoutato in tempo, potrebbe teoricamente in una situazione critica diventare la causa per cui non riusciremo ad effettuare, ad esempio, la promozione dello shard replica in primario, il che interromperebbe l'indicizzazione.
- Inoltre, prestiamo particolare attenzione ai ritardi del garbage collector, poiché in passato abbiamo avuto grandi difficoltà con l'ottimizzazione in questo ambito.
- Il monitoraggio dei reject per i thread, per comprendere in anticipo dove si trova il "coll bottleneck".
- E le metriche standard, come heap, RAM e I/O.
Quando si costruisce il monitoraggio, è fondamentale considerare le peculiarità del Thread Pool in Elasticsearch. descrive le opzioni di configurazione e i valori predefiniti per la ricerca e l'indicizzazione, ma non menziona affatto thread_pool.management. Questi thread elaborano, in particolare, richieste tipo _cat/shards e altre simili, che sono utili per scrivere monitoraggi. Più grande è il cluster, più richieste di questo tipo vengono eseguite in un dato momento, e il thread_pool.management menzionato sopra non solo non è presente nella documentazione ufficiale, ma è anche limitato di default a 5 thread, che vengono rapidamente utilizzati, dopo di che il monitoraggio smette di funzionare correttamente.
Cosa voglio dire in conclusione: ce l'abbiamo fatta! Siamo riusciti a fornire ai nostri programmatori e sviluppatori uno strumento che può fornire rapidamente e accuratamente informazioni su ciò che sta accadendo in produzione in quasi ogni situazione.
Sì, è stato piuttosto complicato, ma, tuttavia, siamo riusciti a racchiudere le nostre richieste nei prodotti già esistenti, senza doverli patchare o riscrivere per le nostre esigenze.

Fonte: habr.com
