

Qualche tempo fa ci siamo trovati di fronte alla necessità di scegliere uno strumento ETL per lavorare con Big Data. La soluzione precedente, Informatica BDM, non ci soddisfaceva a causa delle sue funzionalità limitate. Il suo utilizzo si era ridotto a un framework per l'esecuzione di comandi spark-submit. Sul mercato non c'erano molti analoghi in grado di gestire il volume di dati con cui abbiamo a che fare ogni giorno. Alla fine, abbiamo scelto Ab Initio. Durante le dimostrazioni pilota, il prodotto ha dimostrato di avere una velocità di elaborazione molto elevata. Le informazioni su Ab Initio in lingua russa sono quasi assenti, quindi abbiamo deciso di condividere la nostra esperienza su Habra.
Ab Initio offre molte trasformazioni classiche e insolite, il cui codice può essere esteso utilizzando il proprio linguaggio PDL. Per le piccole imprese, uno strumento così potente potrebbe essere eccessivo, con la maggior parte delle sue funzionalità che potrebbero risultare costose e non richieste. Ma se le tue operazioni si avvicinano a quelle di Sberbank, Ab Initio potrebbe interessarti.
Aiuta le aziende a raccogliere conoscenze globalmente e a sviluppare ecosistemi, mentre consente agli sviluppatori di migliorare le proprie competenze in ETL, approfondire le proprie conoscenze in shell, offre la possibilità di apprendere il linguaggio PDL, fornisce una visione visiva dei processi di caricamento e semplifica lo sviluppo grazie a una vasta gamma di componenti funzionali.
In questo articolo parlerò delle funzionalità di Ab Initio e fornirò caratteristiche comparative del suo funzionamento con Hive e GreenPlum.
- Descrizione del framework MDW e dei lavori di personalizzazione per GreenPlum
- Caratteristiche comparative delle prestazioni di Ab Initio nell'interazione con Hive e GreenPlum
- Funzionamento di Ab Initio con GreenPlum in modalità Near Real Time
La funzionalità di questo prodotto è molto ampia e richiede tempo per essere studiata. Tuttavia, con le giuste abilità e impostazioni di prestazione, i risultati dell'elaborazione dei dati possono essere davvero impressionanti. L'uso di Ab Initio per uno sviluppatore può fornire un'esperienza interessante, rappresentando una nuova prospettiva sullo sviluppo ETL, una fusione tra un ambiente visivo e lo sviluppo di caricamenti in un linguaggio simile a uno script.
Le aziende stanno sviluppando i propri ecosistemi e questo strumento si rivela più utile che mai. Con Ab Initio è possibile accumulare conoscenze sul business attuale e utilizzare queste conoscenze per espandere le attività esistenti e aprire nuove. Alternative ad Ab Initio includono gli ambienti di sviluppo visivi come Informatica BDM e quelli non visivi come Apache Spark.
Descrizione di Ab Initio
Ab Initio, come altri strumenti ETL, è un insieme di prodotti.

Ab Initio GDE (Graphical Development Environment) è l'ambiente per gli sviluppatori, in cui configurano le trasformazioni dei dati e le collegano tramite flussi di dati rappresentati con frecce. Questo insieme di trasformazioni è chiamato grafo:
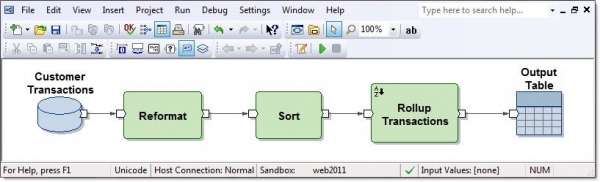
Le connessioni in ingresso e in uscita dei componenti funzionali sono porte e contengono campi calcolati all'interno delle trasformazioni. Più grafi collegati tramite flussi di dati in un ordine di esecuzione sono chiamati piano.
Ci sono diverse centinaia di componenti funzionali, il che è notevole. Molti di loro sono specializzati. Le possibilità delle trasformazioni classiche in Ab Initio sono più ampie rispetto ad altri strumenti ETL. Ad esempio, il Join ha più output. Oltre al risultato della fusione dei dataset, è possibile ottenere in output le registrazioni dei dataset di input per le chiavi che non sono riuscite a unirsi. Inoltre, è possibile ottenere rejects, errors e il log del lavoro di trasformazione, che può essere letto in quel grafico come file di testo e lavorato con altre trasformazioni:
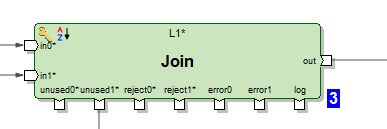
Oppure, ad esempio, è possibile materializzare il ricevitore dati come una tabella e leggere i dati da essa in quel grafico.
Ci sono trasformazioni originali. Ad esempio, la trasformazione Scan ha funzionalità simili a quelle delle funzioni analitiche. Ci sono trasformazioni con nomi parlanti: Create Data, Read Excel, Normalize, Sort within Groups, Run Program, Run SQL, Join with DB, e altre. I grafi possono utilizzare parametri di runtime, compresa la possibilità di passare parametri dal sistema operativo o al sistema operativo. I file con un set predefinito di parametri da passare al grafo vengono chiamati set di parametri (psets).
Come da prassi, Ab Initio GDE ha il suo repository, denominato EME (Enterprise Meta Environment). Gli sviluppatori possono lavorare con versioni locali del codice e fare check-in delle loro modifiche nel repository centrale.
È possibile, durante o dopo l'esecuzione del grafo, cliccare su qualsiasi flusso che collega le trasformazioni e visualizzare i dati che sono passati tra queste trasformazioni:
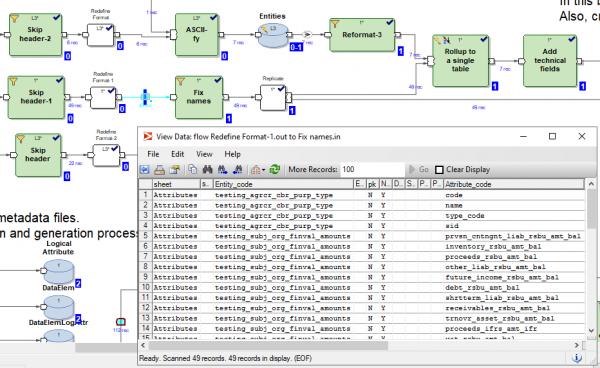
È anche possibile cliccare su qualsiasi flusso e visualizzare i dettagli del tracciamento: quante parallelismi ha lavorato la trasformazione, quante righe e byte sono stati caricati in ciascuna delle parallelismi:
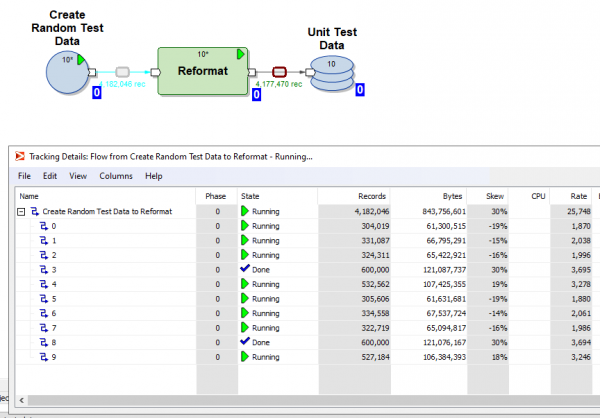
Si può suddividere l'esecuzione del grafo in fasi e indicare quali trasformazioni devono essere eseguite per prime (nella fase zero), le successive nella prima fase, le successive nella seconda fase e così via.
Per ogni trasformazione è possibile scegliere il cosiddetto layout (dove verrà eseguita): senza parallelismi o in flussi paralleli, il cui numero può essere specificato. In questo caso, i file temporanei creati da Ab Initio durante l'esecuzione delle trasformazioni possono essere collocati sia nel file system server, sia in HDFS.
In ogni trasformazione basata sul template predefinito, è possibile creare il proprio script in PDL, che ricorda un po' il shell.
Con il linguaggio PDL puoi estendere le funzionalità delle trasformazioni e, in particolare, puoi generare dinamicamente (durante l'esecuzione) frammenti di codice arbitrari in base ai parametri di runtime.
In Ab Initio è anche molto sviluppata l'integrazione con il sistema operativo tramite shell. In particolare, in Sberbank si utilizza il linux ksh. È possibile scambiare variabili con la shell e usarle come parametri per i grafici. Dalla shell è possibile avviare l'esecuzione dei grafi di Ab Initio e gestire Ab Initio.
Oltre ad Ab Initio GDE, la fornitura include molti altri prodotti. C'è il proprio Co>Operation System che ambisce a essere un sistema operativo. C'è Control>Center, in cui è possibile pianificare e monitorare i flussi di caricamento. Ci sono prodotti per lo sviluppo a un livello più primitivo di quanto consentito da Ab Initio GDE.
Descrizione del framework MDW e dei lavori di personalizzazione per GreenPlum
Insieme ai propri prodotti, il fornitore offre il prodotto MDW (Metadata Driven Warehouse), che funge da configuratore di grafi, progettato per assistere nelle tipiche attività di popolamento di data warehouse o data vault.
Include parser di metadati personalizzati (specifici per il progetto) e generatori di codice pronti all'uso.
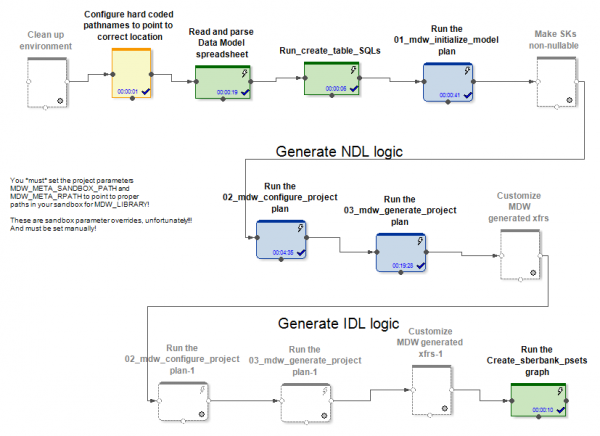
MDW riceve in input un modello di dati, un file di configurazione per impostare la connessione al database (Oracle, Teradata o Hive) e alcune altre impostazioni. La parte specifica del progetto, ad esempio, distribuisce il modello nel database. La parte standard del prodotto genera grafi e file di configurazione per questi ultimi in base al caricamento dei dati nelle tabelle del modello. Vengono creati grafi (e psets) per diverse modalità di lavoro iniziale e incrementale per l'aggiornamento delle entità.
Nei casi di Hive e RDBMS, vengono generati grafi differenti per l'aggiornamento iniziale e incrementale dei dati.
Nel caso di Hive, i dati della delta in arrivo vengono uniti tramite Ab Initio Join con i dati che erano nella tabella prima dell'aggiornamento. I caricamenti dei dati in MDW (sia in Hive che in RDBMS) non solo inseriscono nuovi dati dalla delta, ma chiudono anche i periodi di validità dei dati basati sulle chiavi primarie tramite le quali è arrivata la delta. Inoltre, è necessario riscrivere nuovamente la parte di dati che non è cambiata. Questo è necessario poiché in Hive non ci sono operazioni di delete o update.
Nel caso degli RDBMS, le colonne per l'aggiornamento incrementale dei dati appaiono più ottimizzate, poiché gli RDBMS hanno vere capacità di aggiornamento.
La delta in arrivo viene caricata in una tabella intermedia nel database. Dopo di che, la delta viene unita con i dati che erano nella tabella prima dell'aggiornamento. Questo avviene tramite SQL tramite una query SQL generata. Successivamente, utilizzando i comandi SQL delete+insert, vengono inseriti i nuovi dati dalla delta nella tabella di destinazione e chiusi i periodi di validità dei dati basati sulle chiavi primarie tramite le quali è arrivata la delta.
Non è necessario riscrivere i dati invariati.
Pertanto, siamo giunti alla conclusione che nel caso di Hive, MDW deve procedere alla riscrittura dell'intera tabella, poiché Hive non dispone di funzionalità di aggiornamento. Non esiste soluzione migliore della completa riscrittura dei dati durante un aggiornamento. Nel caso degli RDBMS, al contrario, i creatori del prodotto hanno ritenuto opportuno affidare la connessione e l'aggiornamento delle tabelle all'uso di SQL.
Per il progetto presso Sberbank, abbiamo creato una nuova implementazione di caricatore di database riutilizzabile per GreenPlum. Questo è stato fatto sulla base di una versione generata da MDW per Teradata. È stata proprio Teradata, e non Oracle, la scelta migliore, poiché è anch'essa un sistema MPP. Le modalità operative, così come la sintassi di Teradata e GreenPlum, si sono rivelate simili.
Ecco alcuni esempi di differenze critiche per MDW tra diversi RDBMS. In GreenPlum, a differenza di Teradata, quando si creano tabelle è necessario scrivere la clausola
distributed byIn Teradata si scrive
elimina <table> all, mentre in GreenPlum si scrive
elimina da <table>In Oracle, a scopo di ottimizzazione si scrive
delete from t where rowid in (), mentre in Teradata e GreenPlum si scrive
delete from t where exists (select * from delta where delta.pk=t.pk)Inoltre, va notato che per l'utilizzo di Ab Initio con GreenPlum è stata necessaria l'installazione del client GreenPlum su tutti i nodi del cluster Ab Initio. Questo perché ci siamo connessi a GreenPlum contemporaneamente da tutti i nodi del nostro cluster. E affinché la lettura da GreenPlum fosse parallela e ogni thread parallelo di Ab Initio leggesse la propria porzione di dati da GreenPlum, è stato necessario inserire nella sezione "where" delle query SQL una costruzione comprensibile da Ab Initio.
where ABLOCAL(), e definire il valore di questa costruzione, specificando come parametro della trasformazione che legge dal DB
ablocal_expr="string_concat("mod(t.", string_filter_out("{$TABLE_KEY}","{}"), ",", (decimal(3))(number_of_partitions()),")=", (decimal(3))(this_partition()))", che viene compilata in qualcosa come
mod(sk,10)=3, ovvero è necessario fornire a GreenPlum un filtro esplicito per ogni partizione. Per altri database (Teradata, Oracle) Ab Initio può eseguire questa parallelizzazione automaticamente.
Caratteristiche comparative delle prestazioni di Ab Initio nell'interazione con Hive e GreenPlum
In Sberbank, an experiment was conducted to compare the performance of generated MDW graphs related to Hive and GreenPlum. In the experiment, Hive utilized 5 nodes on the same cluster as Ab Initio, while GreenPlum had 4 nodes on a separate cluster. Thus, Hive had a slight hardware advantage over GreenPlum.
Two pairs of graphs were examined, performing the same data update task in Hive and GreenPlum. The graphs generated by the MDW configurator were launched:
- initial loading + incremental loading of randomly generated data into the Hive table
- initial loading + incremental loading of randomly generated data into the equivalent GreenPlum table
In both cases (Hive and GreenPlum), the loads were executed in 10 parallel streams on the same Ab Initio cluster. Intermediate data for calculations was stored in HDFS (in Ab Initio terms, MFS layout using HDFS was used). One line of randomly generated data occupied 200 bytes in both cases.
The result was as follows:
Hive:
Initial loading in Hive
Rows inserted
6 000 000
60 000 000
600 000 000
Durata del caricamento iniziale
in secondi
41
203
1 601
Caricamento incrementale in Hive
Numero di righe presenti nella
tabella di destinazione all'inizio dell'esperimento
6 000 000
60 000 000
600 000 000
Numero di righe delta applicate alla
tabella di destinazione durante l'esperimento
6 000 000
6 000 000
6 000 000
Durata del caricamento incrementale
in secondi
88
299
2 541
GreenPlum:
Caricamento iniziale in GreenPlum
Rows inserted
6 000 000
60 000 000
600 000 000
Durata del caricamento iniziale
in secondi
72
360
3 631
Caricamento incrementale in GreenPlum
Numero di righe presenti nella
tabella di destinazione all'inizio dell'esperimento
6 000 000
60 000 000
600 000 000
Numero di righe delta applicate alla
tabella di destinazione durante l'esperimento
6 000 000
6 000 000
6 000 000
Durata del caricamento incrementale
in secondi
159
199
321
Si osserva che la velocità del caricamento iniziale sia in Hive che in GreenPlum dipende linearmente dal volume dei dati e, a causa di un hardware migliore, è leggermente più veloce per Hive rispetto a GreenPlum.
Il caricamento incrementale in Hive dipende anch'esso linearmente dal volume dei dati precedentemente caricati nella tabella di destinazione e avviene piuttosto lentamente con l'aumento del volume. Questo è causato dalla necessità di riscrivere completamente la tabella di destinazione. Ciò significa che applicare piccole modifiche a tabelle enormi non è un buon utilizzo per Hive.
Il caricamento incrementale in GreenPlum dipende scarsamente dal volume dei dati precedentemente caricati nella tabella di destinazione ed avviene piuttosto rapidamente. Questo è possibile grazie alle SQL Joins e all'architettura di GreenPlum, che consente l'operazione di delete.
Quindi, GreenPlum inserisce la delta tramite il metodo delete+insert, mentre in Hive non ci sono operazioni di delete o update, quindi l'intero insieme di dati durante l'aggiornamento incrementale deve essere riscritto completamente. È particolarmente significativo il confronto delle celle evidenziate in grassetto, poiché rappresentano la modalità di utilizzo più comune per carichi di lavoro ad alta intensità. Possiamo osservare che GreenPlum ha ottenuto un vantaggio rispetto a Hive in questo test di 8 volte.
Funzionamento di Ab Initio con GreenPlum in modalità Near Real Time
In questo esperimento verificheremo la capacità di Ab Initio di aggiornare la tabella GreenPlum con porzioni casuali di dati in modalità simile al tempo reale. Consideriamo la tabella GreenPlum dev42_1_db_usl.TESTING_SUBJ_org_finval, su cui lavoreremo.
Utilizzeremo tre grafi di Ab Initio per lavorarci:
1) Grafo Create_test_data.mp – crea file di dati in HDFS con 6.000.000 righe in 10 flussi paralleli. I dati sono casuali e la loro struttura è organizzata per l'inserimento nella nostra tabella.
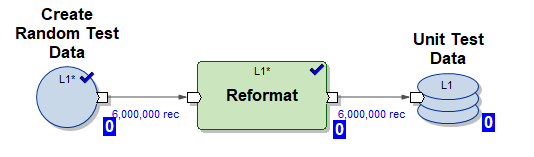

2) Grafico mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset – grafico MDW generato dall'inserimento iniziale dei dati nella nostra tabella in 10 flussi paralleli (sono usati dati di test generati dal grafico (1))

3) Grafico mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset – grafico MDW generato dall'aggiornamento incrementale della nostra tabella in 10 flussi paralleli utilizzando porzioni di nuovi dati in arrivo (delta), generati dal grafico (1)
Eseguiremo lo scenario riportato di seguito in modalità NRT:
- generare 6.000.000 righe di test
- effettuare un caricamento iniziale per inserire 6.000.000 righe di test in una tabella vuota
- ripetere 5 volte il caricamento incrementale
- generare 6.000.000 righe di test
- effettuare un'inserzione incrementale di 6.000.000 righe di test nella tabella (i dati vecchi vengono dotati di un tempo di scadenza valid_to_ts e nuovi dati con la stessa chiave primaria vengono inseriti)
Questo scenario emula il funzionamento reale di un sistema aziendale: in tempo reale arriva una sufficiente quantità di nuovi dati e viene subito immessa in GreenPlum.
Ora diamoci un'occhiata al registro dell'esecuzione dello scenario:
Inizio Create_test_data.input.pset il 2020-06-04 11:49:11
Fine Create_test_data.input.pset il 2020-06-04 11:49:37
Inizio mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset il 2020-06-04 11:49:37
Fine mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset il 2020-06-04 11:50:42
Inizio Create_test_data.input.pset il 2020-06-04 11:50:42
Fine Create_test_data.input.pset il 2020-06-04 11:51:06
Inizio mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset il 2020-06-04 11:51:06
Fine mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset il 2020-06-04 11:53:41
Inizio Create_test_data.input.pset il 2020-06-04 11:53:41
Fine Create_test_data.input.pset il 2020-06-04 11:54:04
Inizio mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset il 2020-06-04 11:54:04
Fine mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset il 2020-06-04 11:56:51
Inizio Create_test_data.input.pset il 2020-06-04 11:56:51
Fine Create_test_data.input.pset il 2020-06-04 11:57:14
Inizio mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset il 2020-06-04 11:57:14
Fine mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset il 2020-06-04 11:59:55
Inizio Create_test_data.input.pset il 2020-06-04 11:59:55
Fine Create_test_data.input.pset il 2020-06-04 12:00:23
Inizio mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset il 2020-06-04 12:00:23
Fine mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset il 2020-06-04 12:03:23
Inizio Create_test_data.input.pset il 2020-06-04 12:03:23
Fine Create_test_data.input.pset il 2020-06-04 12:03:49
Inizio mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset il 2020-06-04 12:03:49
Fine mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset il 2020-06-04 12:06:46
Questa è la situazione:
Grafico
Start time
Tempo di fine
Lunghezza
Create_test_data.input.pset
04.06.2020 11:49:11
04.06.2020 11:49:37
00:00:26
mdw_load.day_one.current.
dev42_1_db_usl_testing_subj_org_finval.pset
04.06.2020 11:49:37
04.06.2020 11:50:42
00:01:05
Create_test_data.input.pset
04.06.2020 11:50:42
04.06.2020 11:51:06
00:00:24
mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset
04.06.2020 11:51:06
04.06.2020 11:53:41
00:02:35
Create_test_data.input.pset
04.06.2020 11:53:41
04.06.2020 11:54:04
00:00:23
mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset
04.06.2020 11:54:04
04.06.2020 11:56:51
00:02:47
Create_test_data.input.pset
04.06.2020 11:56:51
04.06.2020 11:57:14
00:00:23
mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset
04.06.2020 11:57:14
04.06.2020 11:59:55
00:02:41
Create_test_data.input.pset
04.06.2020 11:59:55
04.06.2020 12:00:23
00:00:28
mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset
04.06.2020 12:00:23
04.06.2020 12:03:23
00:03:00
Create_test_data.input.pset
04.06.2020 12:03:23
04.06.2020 12:03:49
00:00:26
mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset
04.06.2020 12:03:49
04.06.2020 12:06:46
00:02:57
È evidente che 6.000.000 righe di incremento vengono elaborate in 3 minuti, il che è abbastanza veloce.
I dati nella tabella di destinazione si sono distribuiti nel seguente modo:
select valid_from_ts, valid_to_ts, count(1), min(sk), max(sk) from dev42_1_db_usl.TESTING_SUBJ_org_finval group by valid_from_ts, valid_to_ts order by 1,2; 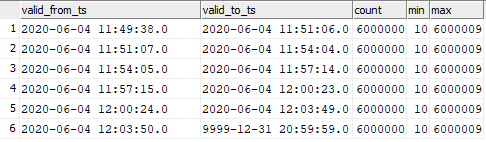
Si può notare la corrispondenza dei dati inseriti con i momenti di avvio dei grafi.
Questo significa che è possibile avviare in Ab Initio un caricamento incrementale dei dati in GreenPlum con una frequenza molto elevata e osservare l'alta velocità di inserimento di questi dati in GreenPlum. Certamente, non sarà possibile avviarlo ogni secondo, poiché Ab Initio, come qualsiasi strumento ETL, richiede tempo per 'mettersi in moto' all'avvio.
Conclusione
Attualmente Ab Initio è utilizzato da Sberbank per la creazione di un Unico Layer Semantico dei Dati (USSD). Questo progetto prevede la costruzione di una versione unica dello stato di diverse entità aziendali bancarie. Le informazioni provengono da varie fonti, le cui repliche vengono preparate su Hadoop. In base alle esigenze del business, viene preparato un modello di dati e vengono descritte le trasformazioni dei dati. Ab Initio carica le informazioni nell'USSD e i dati caricati non solo sono di interesse per il business stessi, ma servono anche come fonte per la creazione di data warehouse. Inoltre, la funzionalità del prodotto consente di utilizzare diversi sistemi (Hive, Greenplum, Teradata, Oracle) come destinatari, facilitando così la preparazione dei dati in vari formati richiesti dal business.
Le possibilità di Ab Initio sono ampie; ad esempio, il framework MDW incluso consente di costruire la storicità dei dati in ambito tecnico e business 'out of the box'. Per gli sviluppatori, Ab Initio offre l'opportunità di 'non reinventare la ruota', ma di utilizzare numerosi componenti funzionali già disponibili, che essenzialmente fungono da librerie necessarie per lavorare con i dati.
L'autore è un esperto della comunità professionale Sberbank SberProfi DWH/BigData. La comunità professionale SberProfi DWH/BigData si occupa dello sviluppo delle competenze in ambiti quali l'ecosistema Hadoop, Teradata, Oracle DB, GreenPlum, e anche negli strumenti BI come Qlik, SAP BO, Tableau, e altro.
Fonte: habr.com
