

Hai passato mesi a riprogettare il tuo monolite trasformandolo in microservizi e finalmente tutti si sono riuniti per invertire la rotta. Vai alla prima pagina web... e non succede nulla. Lo ricarichi e ancora una volta niente di buono, il sito è così lento che non risponde per diversi minuti. Quello che è successo?
Nel suo intervento, Jimmy Bogard condurrà un’analisi “post mortem” su un disastro di microservizi nella vita reale. Mostrerà i problemi di modellazione, sviluppo e produzione che ha scoperto e come il suo team ha lentamente trasformato il nuovo monolite distribuito nell'immagine finale della sanità mentale. Sebbene sia impossibile prevenire completamente gli errori di progettazione, è possibile almeno identificare i problemi nelle prime fasi del processo di progettazione per garantire che il prodotto finale diventi un sistema distribuito affidabile.

Ciao a tutti, sono Jimmy e oggi sentirete come evitare mega disastri durante la creazione di microservizi. Questa è la storia di un'azienda per cui ho lavorato per circa un anno e mezzo per evitare che la loro nave entrasse in collisione con un iceberg. Per raccontare adeguatamente questa storia, dovremo tornare indietro nel tempo e parlare di dove è nata questa azienda e di come la sua infrastruttura IT è cresciuta nel tempo. Per proteggere i nomi degli innocenti coinvolti in questo disastro, ho cambiato il nome di questa azienda in Bell Computers. La diapositiva successiva mostra come appariva l'infrastruttura IT di tali aziende a metà degli anni '90. Questa è un'architettura tipica di un grande server mainframe HP Tandem universale con tolleranza agli errori per la gestione di un negozio di hardware.

Avevano bisogno di creare un sistema per gestire tutti gli ordini, le vendite, i resi, i cataloghi di prodotti e la base clienti, quindi hanno scelto la soluzione mainframe più comune in quel momento. Questo gigantesco sistema conteneva ogni piccola informazione sull'azienda, tutto il possibile, e ogni transazione veniva eseguita tramite questo mainframe. Tenevano tutte le uova nello stesso paniere e pensavano che fosse normale. L'unica cosa che non è inclusa qui sono i cataloghi per corrispondenza e gli ordini telefonici.
Nel corso del tempo, il sistema è diventato sempre più grande e al suo interno si è accumulata un'enorme quantità di spazzatura. Inoltre, COBOL non è il linguaggio più espressivo al mondo, quindi il sistema ha finito per essere un grosso pezzo di spazzatura monolitico. Nel 2000, videro che molte aziende avevano siti web attraverso i quali conducevano tutte le loro attività e decisero di costruire il loro primo sito web commerciale dot-com.
Il design iniziale sembrava piuttosto carino e consisteva in un sito di primo livello bell.com e una serie di sottodomini per singole applicazioni: catalog.bell.com, account.bell.com, ordini.bell.com, ricerca prodotto search.bell. com. Ciascun sottodominio utilizzava il framework ASP.Net 1.0 e i propri database e tutti comunicavano con il backend del sistema. Tuttavia, tutti gli ordini continuavano a essere elaborati ed eseguiti all'interno di un unico enorme mainframe, in cui rimaneva tutta la spazzatura, ma il front-end era costituito da siti Web separati con applicazioni individuali e database separati.
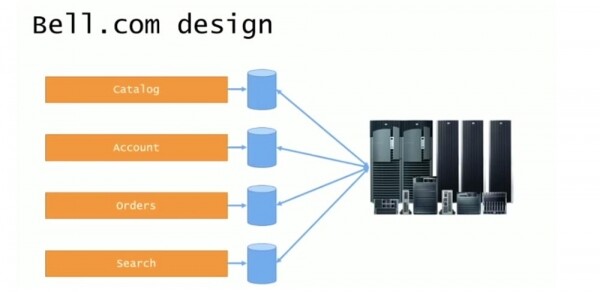
Quindi la progettazione del sistema sembrava ordinata e logica, ma il sistema reale era quello mostrato nella diapositiva successiva.
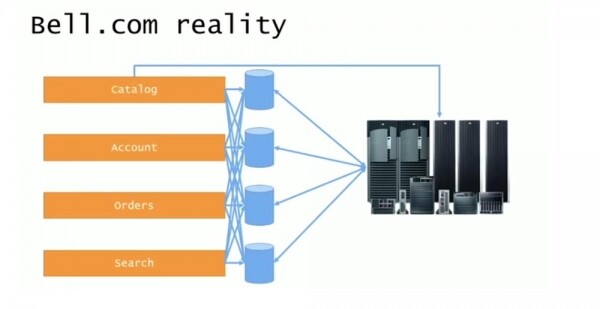
Tutti gli elementi indirizzavano chiamate reciproche, API accessibili, DLL incorporate di terze parti e simili. Accadeva spesso che i sistemi di controllo della versione prendessero il codice di qualcun altro, lo infilassero nel progetto e poi tutto si rompesse. MS SQL Server 2005 utilizzava il concetto di server di collegamento e, sebbene non mostrassi le frecce nella diapositiva, ciascuno dei database comunicava anche tra loro, perché non c'è niente di sbagliato nel costruire tabelle basate sui dati ottenuti da diversi database.
Dato che ora avevano una certa separazione tra le diverse aree logiche del sistema, queste diventavano macchie di sporcizia distribuite, con la parte più grande di spazzatura che rimaneva ancora nel backend del mainframe.
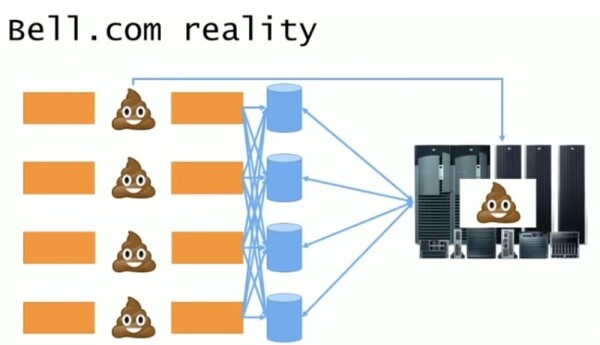
La cosa divertente era che questo mainframe era stato costruito dai concorrenti della Bell Computers ed era ancora gestito dai loro consulenti tecnici. Convinta delle prestazioni insoddisfacenti delle sue applicazioni, l'azienda ha deciso di sbarazzarsene e di riprogettare il sistema.
L'applicazione esistente era in produzione da 15 anni, un record per le applicazioni basate su ASP.Net. Il servizio accettava ordini da tutto il mondo e il fatturato annuo derivante da questa singola applicazione raggiungeva il miliardo di dollari. Una parte significativa del profitto è stata generata dal sito bell.com. Durante i Black Friday, il numero di ordini effettuati tramite il sito ha raggiunto diversi milioni. L’architettura esistente però non permetteva alcuno sviluppo, poiché le rigide interconnessioni degli elementi del sistema praticamente non permettevano di apportare alcuna modifica al servizio.
Il problema più serio era l'incapacità di effettuare un ordine da un paese, pagarlo in un altro e inviarlo a un terzo, nonostante tale schema commerciale sia molto comune nelle aziende globali. Il sito web esistente non consentiva nulla del genere, quindi dovevano accettare ed effettuare questi ordini per telefono. Ciò ha portato l’azienda a pensare sempre più a cambiare l’architettura, in particolare al passaggio ai microservizi.
Hanno fatto la cosa intelligente guardando altre aziende per vedere come avevano risolto un problema simile. Una di queste soluzioni era l’architettura del servizio Netflix, che consiste in microservizi collegati tramite un’API e un database esterno.
La direzione di Bell Computers ha deciso di costruire proprio un'architettura di questo tipo, aderendo ad alcuni principi di base. Innanzitutto, hanno eliminato la duplicazione dei dati utilizzando un approccio basato su database condiviso. Nessun dato veniva inviato; al contrario, tutti coloro che ne avevano bisogno dovevano rivolgersi ad una fonte centralizzata. Seguì l'isolamento e l'autonomia: ogni servizio era indipendente dagli altri. Hanno deciso di utilizzare l'API Web assolutamente per tutto: se volevi ottenere dati o apportare modifiche a un altro sistema, tutto veniva fatto tramite l'API Web. L'ultima grande novità è stata un nuovo mainframe chiamato "Bell on Bell" in contrapposizione al mainframe "Bell" basato sull'hardware della concorrenza.
Quindi, nel corso di 18 mesi, hanno costruito il sistema attorno a questi principi fondamentali e lo hanno portato alla pre-produzione. Tornati al lavoro dopo il fine settimana, gli sviluppatori si sono riuniti e hanno acceso tutti i server a cui era connesso il nuovo sistema. 18 mesi di lavoro, centinaia di sviluppatori, l'hardware Bell più moderno - e nessun risultato positivo! Ciò ha deluso molte persone perché hanno eseguito questo sistema sui loro laptop molte volte e tutto andava bene.
Sono stati intelligenti nell'investire tutti i loro soldi per risolvere questo problema. Hanno installato i rack di server più moderni con switch, hanno utilizzato la fibra ottica gigabit, l'hardware del server più potente con una quantità folle di RAM, hanno collegato tutto, configurato - e ancora, niente! Poi hanno iniziato a sospettare che il motivo potesse essere il timeout, quindi sono entrati in tutte le impostazioni web, in tutte le impostazioni API e hanno aggiornato l'intera configurazione del timeout ai valori massimi, in modo che tutto ciò che potevano fare era sedersi e aspettare che succedesse qualcosa al sito. Hanno aspettato, aspettato e aspettato per 9 minuti e mezzo finché il sito web non è stato finalmente caricato.
Successivamente hanno capito che la situazione attuale necessitava di un’analisi approfondita e ci hanno invitato. La prima cosa che abbiamo scoperto è che durante tutti i 18 mesi di sviluppo non è stato creato un solo vero "micro": tutto è solo diventato più grande. Successivamente, abbiamo iniziato a scrivere un’autopsia, detta anche “retrospettiva”, o “retrospettiva triste”, detta anche “blame storm”, simile a una “tempesta cerebrale”, per comprendere la causa del disastro.
Avevamo diversi indizi, uno dei quali era la completa saturazione del traffico al momento della chiamata API. Quando utilizzi un'architettura di servizio monolitica, puoi capire immediatamente cosa è andato storto esattamente perché hai un'unica analisi dello stack che segnala tutto ciò che potrebbe aver causato l'errore. Nel caso in cui più servizi accedano contemporaneamente alla stessa API, non c'è modo di tracciarne la traccia se non utilizzare strumenti aggiuntivi di monitoraggio della rete come WireShark, grazie al quale è possibile esaminare una singola richiesta e scoprire cosa è successo durante la sua implementazione. Quindi abbiamo preso una pagina web e abbiamo trascorso quasi 2 settimane a mettere insieme i pezzi del puzzle, facendo una serie di chiamate e analizzando ciò a cui ciascuno di essi portava.
Guarda questa immagine. Mostra che una richiesta esterna richiede al servizio di effettuare molte chiamate interne che ritornano indietro. Risulta che ogni chiamata interna fa ulteriori salti per poter soddisfare autonomamente questa richiesta, perché non può rivolgersi altrove per ottenere le informazioni necessarie. Questa immagine sembra una cascata di chiamate senza senso, poiché la richiesta esterna chiama servizi aggiuntivi, che chiamano altri servizi aggiuntivi e così via, quasi all'infinito.

Il colore verde in questo diagramma mostra un semicerchio in cui i servizi si chiamano tra loro: il servizio A chiama il servizio B, il servizio B chiama il servizio C e chiama di nuovo il servizio A. Di conseguenza, otteniamo un "deadlock distribuito". Una singola richiesta creava un migliaio di chiamate API di rete e, poiché il sistema non disponeva di tolleranza agli errori incorporata e protezione dai loop, la richiesta falliva se anche una sola di queste chiamate API falliva.
Abbiamo fatto un po' di conti. Ogni chiamata API aveva uno SLA non superiore a 150 ms e un tempo di attività del 99,9%. Una richiesta ha causato 200 chiamate diverse e, nel migliore dei casi, la pagina potrebbe essere visualizzata in 200 x 150 ms = 30 secondi. Naturalmente questo non andava bene. Moltiplicando il tempo di attività del 99,9% per 200, abbiamo ottenuto una disponibilità dello 0%. Si scopre che questa architettura era destinata al fallimento fin dall'inizio.
Abbiamo chiesto agli sviluppatori come non sono riusciti a riconoscere questo problema dopo 18 mesi di lavoro? Si è scoperto che contavano solo lo SLA per il codice eseguito, ma se il loro servizio chiamava un altro servizio, quel tempo non veniva conteggiato nello SLA. Tutto ciò che veniva avviato all'interno di un processo rispettava il valore di 150 ms, ma l'accesso ad altri processi di servizio aumentava di molte volte il ritardo totale. La prima lezione appresa è stata: "Hai il controllo del tuo SLA o è lo SLA ad avere il controllo su di te?" Nel nostro caso è stato quest'ultimo.
La cosa successiva che scoprimmo fu che conoscevano il concetto errato di calcolo distribuito, formulato da Peter Deitch e James Gosling, ma ne ignoravano la prima parte. Afferma che le affermazioni “la rete è affidabile”, “latenza zero” e “velocità effettiva infinita” sono idee sbagliate. Altri malintesi includono le affermazioni “la rete è sicura”, “la topologia non cambia mai”, “c’è sempre un solo amministratore”, “il costo del trasferimento dei dati è pari a zero” e “la rete è omogenea”.
Hanno commesso un errore perché hanno testato il loro servizio su macchine locali e non si sono mai collegati a servizi esterni. Durante lo sviluppo locale e l'utilizzo di una cache locale, non hanno mai riscontrato hop di rete. In tutti i 18 mesi di sviluppo, non si sono mai chiesti cosa sarebbe potuto accadere se i servizi esterni fossero stati colpiti.

Se osservi i limiti del servizio nell'immagine precedente, puoi vedere che sono tutti errati. Esistono numerose fonti che forniscono consigli su come definire i limiti del servizio e la maggior parte lo fa in modo errato, come Microsoft nella diapositiva successiva.

Questa immagine proviene dal blog MS sull'argomento "Come creare microservizi". Questo mostra una semplice applicazione web, un blocco di logica aziendale e un database. La richiesta arriva direttamente, probabilmente c'è un server per il web, un server per l'azienda e uno per il database. Se aumenti il traffico, l'immagine cambierà leggermente.
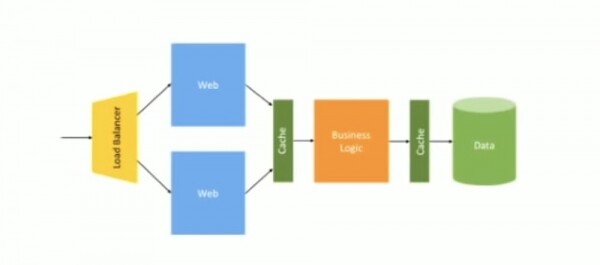
Ecco un bilanciatore del carico per distribuire il traffico tra due server web, una cache situata tra il servizio web e la logica aziendale e un'altra cache tra la logica aziendale e il database. Questa è esattamente l'architettura utilizzata da Bell per il bilanciamento del carico e l'applicazione di distribuzione blu/verde a metà degli anni 2000. Fino a qualche tempo tutto ha funzionato bene, poiché questo schema era destinato a una struttura monolitica.
L'immagine seguente mostra come MS consiglia di passare da un monolite ai microservizi: è sufficiente dividere ciascuno dei servizi principali in microservizi separati. Fu durante l'implementazione di questo schema che Bell commise un errore.
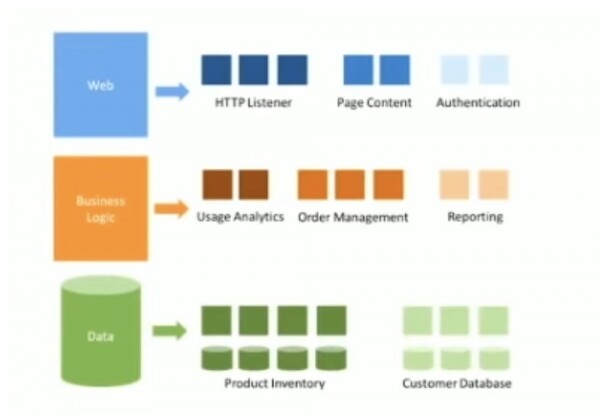
Hanno diviso tutti i loro servizi in diversi livelli, ognuno dei quali consisteva in molti servizi individuali. Ad esempio, il servizio web includeva microservizi per il rendering e l'autenticazione dei contenuti, il servizio di logica aziendale consisteva in microservizi per l'elaborazione degli ordini e delle informazioni sull'account, il database era suddiviso in un gruppo di microservizi con dati specializzati. Sia il web, la logica aziendale e il database erano servizi stateless.
Tuttavia, questa immagine era completamente sbagliata perché non mappava alcuna business unit al di fuori del cluster IT dell’azienda. Questo schema non teneva conto di alcun collegamento con il mondo esterno, quindi non era chiaro come, ad esempio, ottenere analisi aziendali da terze parti. Noto che hanno anche inventato diversi servizi semplicemente per sviluppare la carriera di singoli dipendenti che cercavano di gestire quante più persone possibile per ottenere più soldi.
Credevano che passare ai microservizi fosse facile come prendere la loro infrastruttura interna a livello fisico a più livelli e installarvi Docker. Diamo un'occhiata a come appare la tradizionale architettura a più livelli.
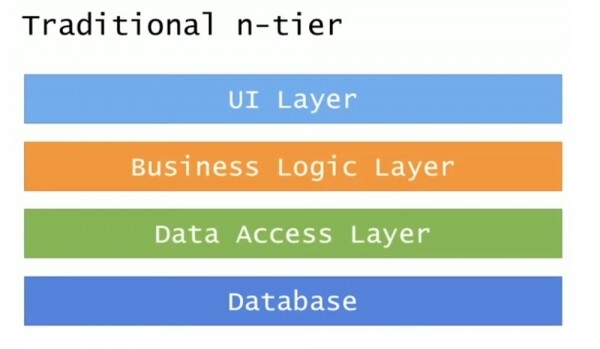
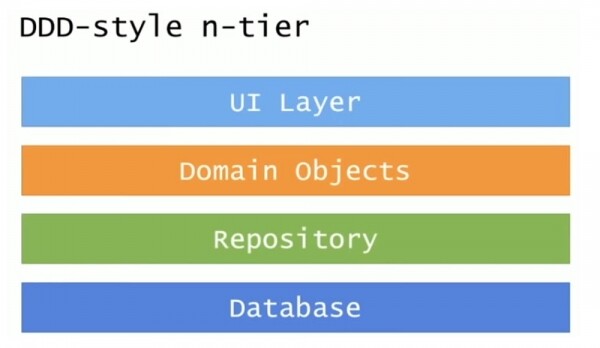
È composto da 4 livelli: il livello dell'interfaccia utente dell'interfaccia utente, il livello della logica aziendale, il livello di accesso ai dati e il database. Più progressista è DDD (Domain-Driven Design), o architettura orientata al software, in cui i due livelli intermedi sono oggetti di dominio e un repository.
Ho provato a guardare alle diverse aree di cambiamento, alle diverse aree di responsabilità in questa architettura. In una tipica applicazione N-tier vengono classificate diverse aree di cambiamento che permeano la struttura verticalmente dall'alto verso il basso. Si tratta del Catalogo, delle impostazioni di configurazione eseguite sui singoli computer e dei controlli di pagamento, gestiti dal mio team.
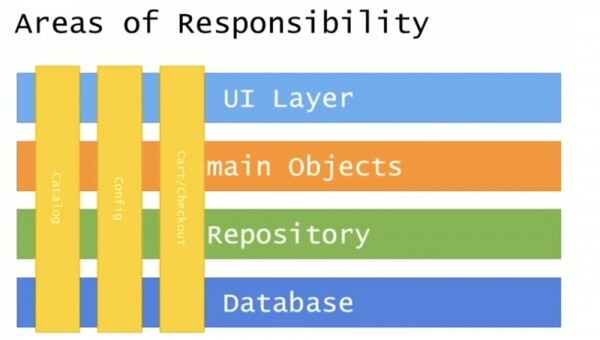
La particolarità di questo schema è che i confini di queste aree di cambiamento influenzano non solo il livello della logica aziendale, ma si estendono anche al database.
Vediamo cosa significa essere un servizio. Esistono 6 proprietà caratteristiche di una definizione di servizio: è un software che:
- creato e utilizzato da un'organizzazione specifica;
- è responsabile del contenuto, dell'elaborazione e/o della fornitura di un certo tipo di informazioni all'interno del sistema;
- può essere costruito, distribuito e gestito in modo indipendente per soddisfare esigenze operative specifiche;
- comunica con i consumatori e altri servizi, fornendo informazioni sulla base di accordi o garanzie contrattuali;
- si protegge da accessi non autorizzati e le sue informazioni dalla perdita;
- gestisce gli errori in modo tale da non causare danni alle informazioni.
Tutte queste proprietà possono essere espresse in una sola parola “autonomia”. I servizi operano indipendentemente l'uno dall'altro, soddisfano determinate restrizioni e definiscono contratti in base ai quali le persone possono ricevere le informazioni di cui hanno bisogno. Non ho menzionato tecnologie specifiche, il cui utilizzo è evidente.
Ora diamo un'occhiata alla definizione di microservizi:
- un microservizio è di piccole dimensioni e progettato per risolvere un problema specifico;
- Il microservizio è autonomo;
- Quando si crea un'architettura a microservizi, viene utilizzata la metafora dell'urbanistica. Questa è la definizione tratta dal libro di Sam Newman, Building Microservices.
La definizione di contesto delimitato è tratta dal libro Domain-Driven Design di Eric Evans. Questo è un modello fondamentale in DDD, un centro di progettazione architettonica che lavora con modelli architettonici volumetrici, dividendoli in diversi contesti delimitati e definendo esplicitamente le interazioni tra loro.
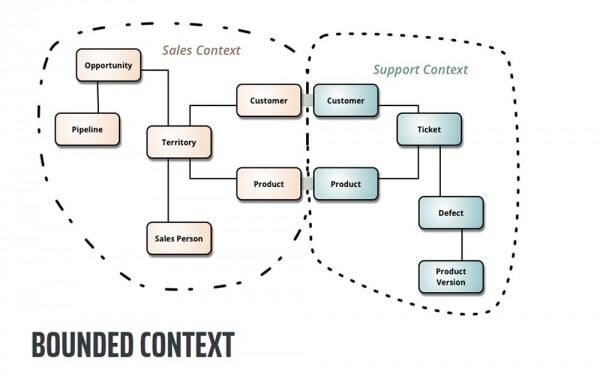
In poche parole, un contesto delimitato denota l'ambito in cui un particolare modulo può essere utilizzato. In questo contesto c'è un modello logicamente unificato che può essere visto, ad esempio, nel vostro dominio aziendale. Se chiedi “chi è cliente” al personale addetto alle commesse ti verrà data una definizione, se lo chiedi a chi si occupa delle vendite ne avrai un'altra, e gli esecutori ti daranno una terza definizione.
Quindi, Bounded Context dice che se non possiamo dare una definizione chiara di cosa sia un consumatore dei nostri servizi, definiamo i confini entro i quali possiamo parlare del significato di questo termine, e quindi definiamo i punti di transizione tra queste diverse definizioni. Cioè, se parliamo di un cliente dal punto di vista dell'effettuazione degli ordini, questo significa questo e quello, e se dal punto di vista delle vendite significa questo e quello.
La successiva definizione di microservizio è l'incapsulamento di qualsiasi tipo di operazione interna, impedendo la “perdita” dei componenti del processo di lavoro nell'ambiente. Poi arriva la “definizione di contratti espliciti per interazioni esterne, o comunicazioni esterne”, che è rappresentata dall’idea di contratti che ritornano dagli SLA. L'ultima definizione è la metafora di una cellula, o cellula, che significa il completo incapsulamento di un insieme di operazioni all'interno di un microservizio e la presenza in esso di recettori per la comunicazione con il mondo esterno.

Così abbiamo detto ai ragazzi della Bell Computers: "Non possiamo risolvere il caos che avete creato perché semplicemente non avete i soldi per farlo, ma sistemeremo un solo servizio per far sì che tutto si realizzi." senso." A questo punto inizierò col raccontarvi come abbiamo sistemato il nostro unico servizio in modo che rispondesse alle richieste più velocemente di 9 minuti e mezzo.
22:30 min
Continua molto presto...

Qualche pubblicità
Grazie per stare con noi. Ti piacciono i nostri articoli? Vuoi vedere contenuti più interessanti? Sostienici effettuando un ordine o raccomandando agli amici, , un analogo unico dei server entry-level, che è stato inventato da noi per te: (disponibile con RAID1 e RAID10, fino a 24 core e fino a 40 GB DDR4).
Dell R730xd 2 volte più economico nel data center Equinix Tier IV ad Amsterdam? Solo qui In Olanda! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - da $99! Leggi
Fonte: habr.com
