

Привет, меня зовут Дмитрий Краснов. Уже более пяти лет я занимаюсь администрированием кластеров Kubernetes и построением сложных микросервисных архитектур. В начале этого года мы запустили сервис по управлению кластерами Kubernetes на базе Containerum. Пользуясь поводом расскажу, что представляет собой этот самый Kubernetes и чем интеграция с вендором отличается от open source.
Для начала, что такое . Это система для управления контейнерами на большом количестве хостов. С греческого, кстати, переводится как «пилот» или «рулевой». Изначально разработана Google, после чего в качестве технологического вклада передана Cloud Native Computing Foundation, международной некоммерческой организации, которая объединяет ведущих мировых разработчиков, конечных пользователей и поставщиков контейнерных технологий.

Рулить большим числом контейнеров
Теперь разберемся, что это еще за контейнеры. Это приложение со всем его окружением – в основном, библиотеками, от которых зависит работа программы. Все это запаковано в архивы и представлено в виде образа, который можно запускать вне зависимости от операционной системы, тестировать и не только. Но есть проблема — управлять контейнерами на большом количестве хостов очень сложно. Поэтому и был создан Kubernetes.
Образ контейнера представляет собой приложение плюс его зависимости. Приложение, его зависимости и образ файловой системы ОС располагаются в разных частях образа, так называемых слоях. Слои могут переиспользоваться для разных контейнеров. Например, для всех приложений в компании может использоваться базовый слой Ubuntu. При запуске контейнеров нет нужды хранить на хосте множество копий одного базового слоя. Это позволяет оптимизировать хранение и доставку образов.
Когда мы хотим запустить приложение из контейнера, нужные слои накладываются друг на друга и образуется оверлейная файловая система. Сверху накладывается слой для записи, который, при остановке контейнера, удаляется. Это гарантирует, что при запуске контейнера у приложения всегда будет одинаковое окружение, которое не может быть изменено. Это гарантирует воспроизводимость окружения на разных хостовых ОС. Будь то Ubuntu или CentOS, — окружение всегда будет одинаковым. К тому же контейнер изолирован от хоста при помощи встроенных в ядро Linux механизмов. Приложения в контейнере не видят файлы, процессы хоста и соседних контейнеров. Такая изоляция приложений от хостовой ОС даёт дополнительный слой безопасности.
Для управления контейнерами на хосте есть множество инструментов. Самый популярный из них, — это Docker. Он позволяет обеспечить полный жизненный цикл работы контейнеров. Однако он работает только на одном хосте. При необходимости управления контейнерами на множестве хостов Docker может превратить жизнь инженеров в ад. Потому и был создан Kubernetes.
Востребованность Kubernetes как раз и обусловлена возможностью рулить группами контейнеров на множестве хостов как некими едиными сущностями. Популярность системе обеспечивает возможность построить DevOps или Development Operations, в которых Kubernetes используется для запуска процессов этого самого DevOps.
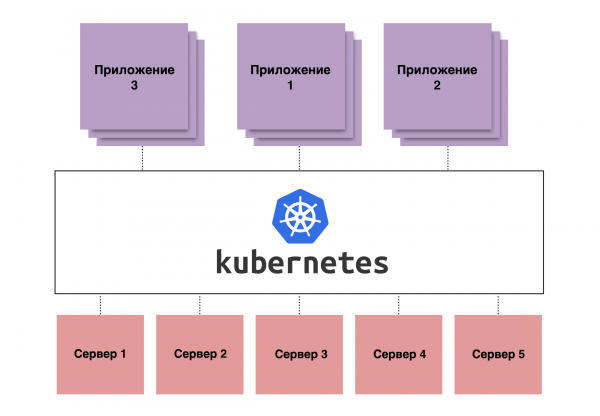
Рисунок 1. Схематичное изображение принципа работы Kubernetes
Полная автоматизация
DevOps, в принципе, представляет собой автоматизацию процесса разработки. Грубо говоря, разработчики пишут код, который заливается в репозиторий. Затем этот код может автоматически собираться сразу в контейнер со всеми библиотеками, тестироваться и «выкатываться» на следующую стадию – Staging, а затем сразу и на Production.
Вместе с Kubernetes DevOps позволяет автоматизировать этот процесс, чтобы он протекал практически без участия самих разработчиков. За счет этого значительно ускоряется сборка, поскольку разработчику не приходится заниматься этим у себя на компьютере — он просто пишет кусок кода, пушит код в репозиторий, после чего запускается pipeline, который может включать в себя процесс сборки, тестирования, выкатки. И так происходит с каждым коммитом, поэтому тестирование происходит непрерывно.
При этом использование контейнера позволяет быть уверенным в том, что все окружение этой программы выйдет в production именно в том виде, в котором тестировалось. То есть не возникнет проблем из разряда «на тесте были одни версии, в production – другие, а поставили – все упало». А поскольку сегодня мы имеем тренд на микросервисную архитектуру, когда вместо одного огромного приложения есть сотни маленьких, то для того чтобы администрировать их вручную, — потребуется огромный штат сотрудников. Поэтому мы и используем Kubernetes.
Плюсы, плюсы, плюсы
Если говорить о достоинствах Kubernetes как платформы, то у него существенные плюсы с точки зрения управления микросервисной архитектурой.
- Управление множеством реплик. Самое главное — это управление контейнерами на множестве хостов. И что более важно, — управление множеством реплик приложений в контейнерах как единой сущностью. Благодаря этому инженерам не нужно заботиться о каждом отдельном контейнере. Если один из контейнеров упадёт, то Kubernetes увидит это и перезапустит его снова.
- Кластерная сеть. Также у Kubernetes есть так называемая кластерная сеть с собственным адресным пространством. Благодаря этому каждый под имеет свой адрес. Под подом понимается минимальная структурная единица кластера, в которой непосредственно запускаются контейнеры. К тому же у Kubernetes есть функционал, который совмещает в себе балансировщик нагрузки и Service Discovery. Это позволяет избавиться от ручного управления IP-адресами и возложить эту задачу на плечи Kubernetes. А автоматические health check`и помогут обнаружить проблемы и перенаправить трафик на рабочие поды.
- Управление конфигурациями. При управлении большим количеством приложений становится сложно управлять конфигурацией приложений. Для этого в Kubernetes есть специальные ресурсы ConfigMap`ы. Они позволяют централизованно хранить конфигурации и подставлять их в поды при запуске приложений. Такой механизм позволяет гарантировать консистентность конфигурации хоть в десяти, хоть в сотне реплик приложений.
- Persistent Volumes. Контейнеры по своей сути иммутабельны и при остановке контейнера все данные, записанные на файловую систему, будут уничтожены. Но некоторые приложения хранят данные прямо на диске. Для решения этой проблемы в Kubernetes есть функционал управления дисковым хранилищем — Persistent Volumes. Этот механизм использует внешнее хранилище для данных, может прокидывать в контейнеры постоянное хранилище, блочное или файловое. Такое решение позволяет хранить данные отдельно от воркеров, что спасает их при поломке этих самых воркеров.
- Load Balancer. Несмотря на то, что в Kubernetes мы управляем абстрактными сущностями типа Deployment, StatefulSet и т.д., в конечном счёте контейнеры запускаются на обычных macchine virtuali или железных серверах. Они не идеальны и могут упасть в любой момент. Kubernetes это увидит и перенаправит внутренний трафик на другие реплики. Но что делать с трафиком, который приходит извне? Если просто направить трафик на один из воркеров, что в случае его падения сервис станет недоступен. Для решения этой проблемы в Kubernetes есть сервисы типа Load Balancer. Они предназначены для автоматической настройки внешнего облачного балансировшика на все воркеры в кластере. Этот внешний балансировщик направляет внешний трафик на воркеры и сам следит за их статусом. Если один или несколько воркеров становятся недоступны, то трафик перенаправляется на другие. Это позволяет создавать высокодоступные сервисы с помощью Kubernetes.
Лучше всего Kubernetes себя проявляет именно при запуске микросервисных архитектур. Внедрять систему в классическую архитектуру можно, но бессмысленно. Если приложение не может работать в нескольких репликах, то какая суть разница – в Kubernetes или нет?
Open source Kubernetes
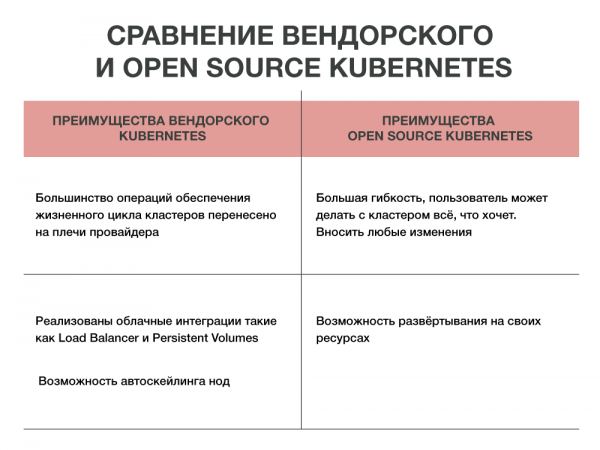
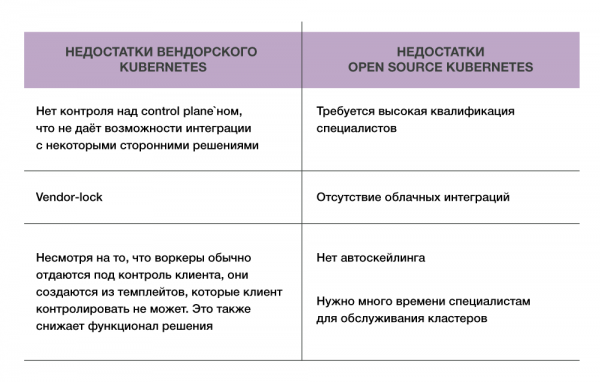
Open source Kubernetes – отличная вещь: поставил и работает. Можно развернуть на своих железных серверах, на своей инфраструктуре, поставить мастера и воркеры, на которых будут запускаться все приложения. А главное — все это бесплатно. Однако есть нюансы.
- Первый – требовательность к знаниям и опыту администраторов и инженеров, которые будут все это разворачивать и сопровождать. Поскольку клиент получает полную свободу действий в кластере, то ответственность за работоспособность кластера он несет сам. А сломать здесь все очень просто.
- Второй – отсутствие интеграций. Если запускать Kubernetes, не имея какой-то популярной платформы виртуализации, то не получите всех преимуществ программы. Таких как использование Persistent Volumes и сервисов Load balancer.
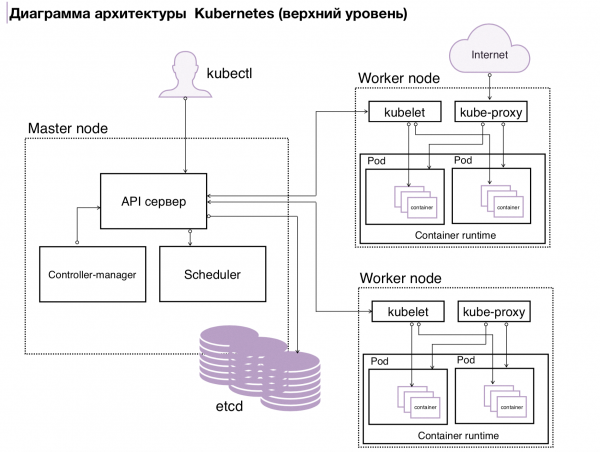
Рисунок 2. Архитектура k8s
Kubernetes от вендора
Интеграция с облачным провайдером дает две возможности:
- Во-первых, человек может просто нажать на кнопку «создать кластер» и получить уже настроенный и готовый к работе кластер.
- Во-вторых, вендор сам ставит кластер и настраивает интеграцию с облаком.
Как это происходит у нас. Инженер, который запускает кластер, указывает, сколько ему нужно воркеров и с какими параметрами (например, 5 воркеров, каждый на 10 ЦПУ, 16 ГБ оперативной памяти и, скажем, 100 ГБ диска). После чего получает доступ в уже сформированный кластер. При этом воркеры, на которых запускается нагрузка, полностью отдаются клиенту, но весь management plane остается в зоне ответственности вендора (в случае, если сервис предоставляется по модели managed service).
Однако такая схема имеет свои недостатки. Из-за того, что management plane остаётся у вендора, то вендор не дает полный доступ клиенту, и это снижает гибкость в работе с Kubernetes. Иногда бывает, что клиент хочет прикрутить к Kubernetes какой-то специфичный функционал, например, аутентификацию через LDAP, а конфигурация management plane этого не позволяет.
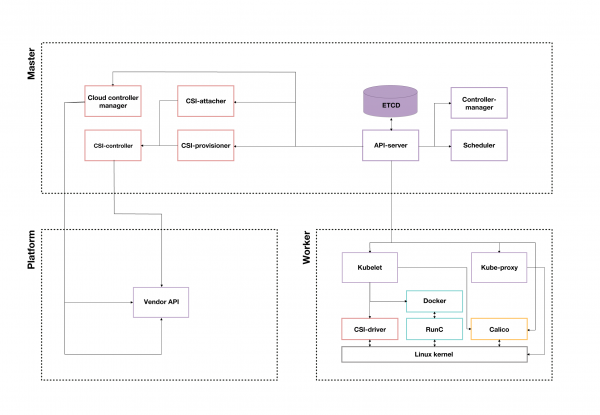
Рисунок 3. Пример кластера Kubernetes от облачного провайдера
Что выбрать: open source или вендорский
Итак, open source Kubernetes или вендорский? Если брать open source Kubernetes, то пользователь что хочет, то с ним и делает. Но велик шанс самому себе выстрелить в ногу. С вендорским это сложнее, потому как за компанию все продумано и настроено. Самым большим недостатком опенсорсного Kubernetes является требование к специалистам. С вендорским компания от этой головной боли избавлена, но ей придется решать: платить своим специалистам или вендору.
Ну что, плюсы очевидны, минусы тоже известны. Неизменно одно: Kubernetes решает массу проблем, автоматизируя управление множеством контейнеров. А какой выбрать, open source или вендорский, — каждый принимает решение сам.
Статью подготовил Дмитрий Краснов, ведущий архитектор сервиса Containerum провайдера #CloudMTS
Fonte: habr.com
