


Шёл 2019 год, а у нас всё ещё нет стандартного решения для агрегации логов в Kubernetes. В этой статье мы хотели бы, используя примеры из реальной практики, поделиться своими поисками, встречаемыми проблемами и их решениями.
Однако для начала оговорюсь, что разные заказчики под сбором логов понимают очень разное:
- кто-то хочет видеть security- и audit-логи;
- кто-то — централизованное логирование всей инфраструктуры;
- а кому-то достаточно собирать только логи приложения, исключив, например, балансировщики.
О том, как мы реализовывали различные «хотелки» и с какими трудностями столкнулись, — под катом.
Теория: об инструментах для логов
Предыстория о компонентах системы логирования
Логирование прошло долгий путь, в результате которого выработались методологии сбора и анализа логов, что мы и применяем сегодня. Ещё в 1950-х годах в Fortran появился аналог стандартных потоков ввода-вывода, которые помогали программисту в отладке его программы. Это были первые компьютерные логи, которые облегчали жизнь программистам тех времен. На сегодня мы в них видим первый компонент системы логирования — источник или «производитель» (producer) логов.
Компьютерная наука не стояла на месте: появились компьютерные сети, первые кластеры… Начали работать сложные системы, состоящие из нескольких компьютеров. Теперь системные администраторы вынуждены были собирать логи с нескольких машин, а в особых случаях могли добавлять и сообщения ядра ОС на случай, если потребуется расследовать системный сбой. Чтобы описать системы централизованного сбора логов, в начале 2000-х выходит , который стандартизовал remote_syslog. Так появился еще один важный компонент: коллектор (сборщик) логов и их хранилище.
С увеличением объема логов и повсеместным внедрением веб-технологий встал вопрос о том, что логи нужно удобно показать пользователям. На смену простым консольным инструментам (awk/sed/grep) пришли более продвинутые просмотрщики логов — третий компонент.
В связи с увеличением объема логов стало ясно и другое: логи нужны, но не все. А ещё разные логи требуют разного уровня сохранности: одни можно потерять через день, а другие — надо хранить 5 лет. Так в систему логирования добавился компонент фильтрации и маршрутизации потоков данных — назовём его фильтром.
Хранилища тоже сделали серьезный скачок: с обычных файлов перешли на реляционные базы данных, а затем и на документоориентированные хранилища (например, Elasticsearch). Так от коллектора отделилось хранилище.
В конце концов, само понятие лога расширилось до некоего абстрактного потока событий, которые мы хотим сохранять для истории. А точнее — на тот случай, когда потребуется провести расследование или составить аналитический отчет…
В итоге, за сравнительно небольшой промежуток времени, сбор логов развился в важную подсистему, которую по праву можно назвать одним из подразделов в Big Data.
Если когда-то обычных print’ов могло быть достаточно для «системы логирования», то теперь ситуация сильно изменилась.
Kubernetes и логи
Когда в инфраструктуру пришёл Kubernetes, существовавшая и без того проблема сбора логов не обошла стороной и его. В некотором смысле она стала даже более болезненной: управление инфраструктурной платформой было не только упрощено, но и одновременно усложнено. Многие старые сервисы начали миграцию на микросервисные рельсы. В контексте логов это выразилось в растущем числе источников логов, их особом жизненном цикле, и необходимости отслеживать через логи взаимосвязи всех компонентов системы…
Забегая вперёд, могу констатировать, что сейчас, к сожалению, нет стандартизированного варианта логирования для Kubernetes, который бы выгодно отличался от всех остальных. Наиболее популярные в сообществе схемы сводятся к следующим:
- кто-то разворачивает стек EFK (Elasticsearch, Fluentd, Kibana);
- кто-то — пробует недавно выпущенный или использует ;
- нас (а возможно, и не только нас?..) во многом устраивает собственная разработка — …
Как правило, мы используем такие связки в K8s-кластерах (для self-hosted-решений):
- ;
- .
Однако не буду останавливаться на инструкциях по их установке и конфигурации. Вместо этого, сфокусируюсь на их недостатках и более глобальных выводах по ситуации с логами в целом.
Практика с логами в K8s

«Повседневные логи», сколько же вас?..
Централизованный сбор логов с достаточно большой инфраструктуры требует немалых ресурсов, которые уйдут на сбор, хранение и обработку логов. В ходе эксплуатации различных проектов мы столкнулись с различными требованиями и возникающими из-за них проблемами в эксплуатации.
Попробуем ClickHouse
Давайте рассмотрим централизованное хранилище на проекте с приложением, которое довольно активно генерирует логи: более 5000 строк в секунду. Начнём работу с его логами, складывая их в ClickHouse.
Как только потребуется максимальный realtime, 4-ядерный сервер с ClickHouse уже будет перегружен по дисковой подсистеме:
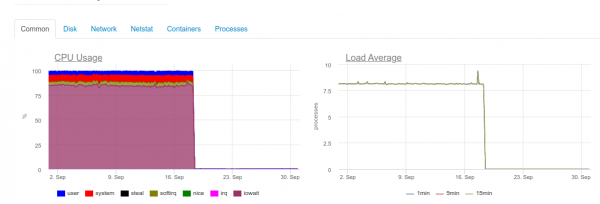
Подобный тип загрузки связан с тем, что мы пытаемся максимально быстро писать в ClickHouse. И на это БД реагирует повышенной дисковой нагрузкой, из-за чего может выдавать такие ошибки:
DB::Exception: Too many parts (300). Merges are processing significantly slower than inserts
Дело в том, что в ClickHouse (в них лежат данные логов) имеют свои сложности при операциях записи. Вставляемые в них данные генерируют временную партицию, которая потом сливается с основной таблицей. В результате, запись получается очень требовательной к диску, а также на неё распространяется ограничение, уведомление о котором мы и получили выше: в 1 секунду могут сливаться не более 300 субпартиций (фактически это 300 insert’ов в секунду).
Чтобы избежать подобного поведения, как можно более большими кусками и не чаще 1 раза в 2 секунды. Однако запись большими пачками предполагает, что мы должны реже писать в ClickHouse. Это, в свою очередь, может привести к переполнению буфера и к потере логов. Решение — увеличить буфер Fluentd, но тогда увеличится и потребление памяти.
Nota: Другая проблемная сторона нашего решения с ClickHouse была связана с тем, что партицирование в нашем случае (loghouse) реализовано через внешние таблицы, связанные . Это приводит к тому, что при выборке больших временных интервалов требуется излишняя оперативная память, поскольку метатаблица перебирает все партиции — даже те, которые заведомо не содержат нужные данные. Впрочем, сейчас такой подход можно смело объявить устаревшим для актуальных версий ClickHouse (c ).
В итоге, становится ясно, что для сбора логов в реальном времени в ClickHouse хватит ресурсов далеко не каждого проекта (точнее, их распределение не будет целесообразным). Кроме того, потребуется использовать аккумулятор, к которому мы ещё вернёмся. Описываемый выше случай — реальный. И на тот момент мы не смогли предложить надежное и стабильное решение, которое бы устраивало заказчика и позволило бы собирать логи с минимальной задержкой…
А Elasticsearch?
Известно, что Elasticsearch справляется с большими нагрузками. Попробуем его в том же проекте. Теперь нагрузка выглядит следующим образом:
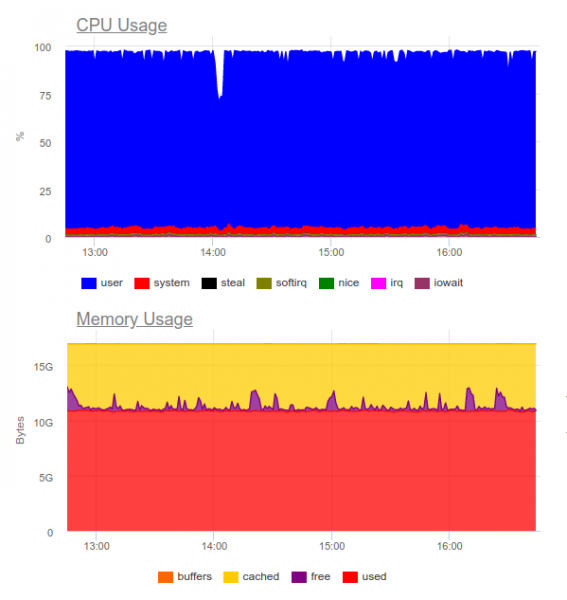
Elasticsearch смог переварить поток данных, однако запись подобных объемов в него сильно утилизирует CPU. Это решается организацией кластера. Чисто технически это не проблема, однако получится, что только для работы системы сбора логов мы уже используем около 8 ядер и имеем дополнительный высоконагруженный компонент в системе…
Итог: такой вариант может быть оправдан, но только в том случае, если проект большой и его руководство готово потратить заметные ресурсы на систему централизованного логирования.
Тогда возникает закономерный вопрос:
Какие логи действительно нужны?
 Попробуем изменить сам подход: логи должны одновременно и быть информативными, и не покрывать каждое событие в системе.
Попробуем изменить сам подход: логи должны одновременно и быть информативными, и не покрывать каждое событие в системе.
Допустим, у нас есть преуспевающий интернет-магазин. Какие логи важны? Собирать максимум информации, например, с платёжного шлюза — отличная идея. А вот от сервиса нарезки изображений в каталоге продуктов нам критичны не все логи: хватит только ошибок и расширенного мониторинга (например, на процент 500-х ошибок, которые генерирует этот компонент).
Вот мы и пришли к тому, что централизованное логирование оправдано далеко не всегда. Очень часто клиент хочет собрать все логи в одном месте, хотя на самом деле из всего лога требуется лишь условные 5% сообщений, которые критичны для бизнеса:
- Иногда достаточно настроить, скажем, только размер лога контейнера и сборщик ошибок (например, Sentry).
- Для расследования инцидентов зачастую может хватить оповещения об ошибке и собственно большого локального лога.
- У нас были проекты, которые и вовсе обходились исключительно функциональными тестами и системами сбора ошибок. Разработчику не требовались логи как таковые — они всё видели по трейсам ошибок.
Иллюстрация из жизни
Хорошим примером может послужить другая история. К нам пришёл запрос от команды безопасников одного из клиентов, у которого уже использовалось коммерческое решение, что было разработано задолго до внедрения Kubernetes.
Потребовалось «подружить» систему централизованного сбора логов с корпоративным сенсором обнаружения проблем — QRadar. Эта система умеет принимать логи по протоколу syslog, забирать c FTP. Однако интегрировать её с плагином remote_syslog для fluentd сразу не получилось (как оказалось, ). Проблемы с настройкой QRadar оказались на стороне команды безопасников клиента.
В результате, часть логов, критичных для бизнеса, выгружалась на FTP QRadar, а другая часть — перенаправлялась через remote syslog напрямую с узлов. Для этого мы даже написали — возможно, он поможет кому-то решить аналогичную задачу… Благодаря получившейся схеме, сам клиент получал и анализировал критичные логи (с помощью своего любимого инструментария), а мы смогли снизить расходы на систему логирования, сохраняя лишь последний месяц.
Ещё один пример довольно показателен в том, как делать не следует. Один из наших клиентов на обработку ogni события, поступающего от пользователя, делал многострочный неструктурированный вывод информации в лог. Как легко догадаться, подобные логи было крайне неудобно и читать, и хранить.
Критерии для логов
Подобные примеры подводят к заключение, что кроме выбора системы сбора логов надо спроектировать еще и сами логи! Какие здесь требования?
- Логи должны быть в машиночитаемом формате (например, JSON).
- Логи должны быть компактными и с возможностью изменения степени логирования, чтобы отладить возможные проблемы. При этом в production-окружениях следует запускать системы с уровнем логирования вроде Attenzione o Error.
- Логи должны быть нормализованными, то есть в объекте лога все строки должны иметь одинаковый тип поля.
Неструктурированные логи могут привести к проблемам с загрузкой логов в хранилище и полной остановкой их обработки. В качестве иллюстрации — пример с ошибкой 400, с которой многие точно сталкивались в логах fluentd:
2019-10-29 13:10:43 +0000 [warn]: dump an error event: error_class=Fluent::Plugin::ElasticsearchErrorHandler::ElasticsearchError error="400 - Rejected by Elasticsearch"
Ошибка означает, что вы отправляете в индекс с готовым mapping’ом поле, тип которого нестабилен. Простейший пример — поле в логе nginx с переменной $upstream_status. В нём может быть как число, так и строка. Например:
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "17ee8a579e833b5ab9843a0aca10b941", "time": "29/Oct/2019:16:18:57 +0300", "method": "GET", "uri": "/staffs/265.png", "protocol": "HTTP/1.1", "status": "200", "body_size": "906", "referrer": "https://example.com/staff", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.001", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "127.0.0.1:9000", "upstream_status": "200", "upstream_response_length": "906", "location": "staff"}
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "47fe42807f2a7d8d5467511d7d553a1b", "time": "29/Oct/2019:16:18:57 +0300", "method": "GET", "uri": "/staff", "protocol": "HTTP/1.1", "status": "200", "body_size": "2984", "referrer": "-", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.010", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "10.100.0.10:9000, 10.100.0.11:9000", "upstream_status": "404, 200", "upstream_response_length": "0, 2984", "location": "staff"}
В логах видно, что сервер 10.100.0.10 ответил 404-й ошибкой и запрос ушел на другое хранилище контента. В результате, в логах значение стало вот таким:
"upstream_response_time": "0.001, 0.007"
Данная ситуация настолько распространённая, что удостоилась даже отдельного .
А что с надёжностью?
Бывают случаи, когда жизненно необходимы все логи без исключения. И с этим у типовых схем сбора логов для K8s, предложенных/рассматриваемых выше, имеются проблемы.
Например, fluentd не может собрать логи с короткоживущих контейнеров. В одном из наших проектов контейнер с миграцией баз данных жил менее 4-х секунд, а затем удалялся — согласно соответствующей аннотации:
"helm.sh/hook-delete-policy": hook-succeeded
Из-за этого лог выполнения миграции не попадал в хранилище. Помочь в данном случае может политика before-hook-creation.
Другой пример — ротация логов Docker. Допустим, есть приложение, которое активно пишет в логи. В обычных условиях мы успеваем обработать все логи, но как только появляется проблема — например, как была описана выше с неправильным форматом, — обработка останавливается, а Docker ротирует файл. Итог — могут быть потеряны критичные для бизнеса логи.
Ecco perché важно разделять потоки логов, встраивая отправку наиболее ценных напрямую в приложение, чтобы обеспечить их сохранность. Кроме того, не будет лишним создание некоего «аккумулятора» логов, который сможет пережить краткую недоступность хранилища при сохранении критичных сообщений.
Наконец, не надо забывать, что любую подсистему важно качественно мониторить. Иначе легко столкнуться с ситуацией, в которой fluentd находится в состоянии CrashLoopBackOff и ничего не отправляет, а это сулит потерей важной информации.
Conclusioni
В данной статье мы не рассматриваем SaaS-решения вроде Datadog. Многие из описанных здесь проблем так или иначе уже решены коммерческими компаниями, специализирующимися на сборе логов, но не все могут использовать SaaS по разным причинам (основные — это стоимость и соблюдение 152-ФЗ).
Централизованный сбор логов сначала выглядит простой задачей, но вовсе таковой не является. Важно помнить, что:
- Логировать подробно стоит только критичные компоненты, а для остальных систем можно настроить мониторинг и сбор ошибок.
- Логи в production стоит делать минимальными, чтобы не давать лишнюю нагрузку.
- Логи должны быть машиночитаемыми, нормализованными, иметь строгий формат.
- Действительно критичные логи стоит отправлять отдельным потоком, который должен быть отделён от основных.
- Стоит продумать аккумулятор логов, который может спасти от всплесков высокой нагрузки и сделает нагрузку на хранилище более равномерной.

Эти простые правила, если их применять везде, позволили бы работать и описанным выше схемам — даже несмотря на то, что в них не хватает важных компонентов (аккумулятора). Если же не придерживаться таких принципов, задача с лёгкостью приведёт вас и инфраструктуру к ещё одному высоконагруженному (и в то же время малоэффективному) компоненту системы.
P.S.
Leggete anche nel nostro blog:
- «»;
- «»;
- «».
Fonte: habr.com
