


Il monitoraggio è diventato un componente fondamentale per le crescenti soluzioni cloud, a causa dell'aumento della complessità dei sistemi distribuiti. È necessario per comprendere il loro comportamento. Servono strumenti scalabili in grado di raccogliere dati da tutti i servizi e fornire ai professionisti un'interfaccia unica per l'analisi delle prestazioni, la visualizzazione degli errori, la disponibilità e i registri.
Questi strumenti devono essere anche efficienti e performanti. In questo articolo, esamineremo due stack tecnologici popolari: EFK (Elasticsearch) e PLG (Loki), analizzando le loro architetture e differenze.
Stack EFK
Probabilmente avete già sentito parlare del molto conosciuto ELK o EFK. Lo stack è composto da diverse parti distinte: Elasticsearch (storage di oggetti), Logstash o FluentD (raccolta e aggregazione dei registri) e Kibana per la visualizzazione.
Uno schema di lavoro tipico è il seguente:

Elasticsearch — storage distribuito di oggetti con ricerca e analisi in tempo reale. Una soluzione eccellente per dati parzialmente strutturati, come i log. Le informazioni sono archiviate in documenti JSON, indicizzate in tempo reale e distribuite attraverso i nodi del cluster. Viene applicato un indice invertito che contiene tutte le parole uniche e i documenti associati per la ricerca full-text, basata a sua volta sul motore di ricerca Apache Lucene.
FluentD — è un raccoglitore di dati che unifica i dati durante la loro raccolta e utilizzo. Cerca di strutturare i dati in JSON quanto più possibile. La sua architettura è estensibile, esistono più di , supportate dalla community, per ogni esigenza.
Kibana — uno strumento di visualizzazione dei dati per Elasticsearch con varie funzionalità aggiuntive, ad esempio analisi di serie temporali, grafici, apprendimento automatico e altro.
Architettura Elasticsearch
I dati del cluster Elasticsearch sono distribuiti su tutti i suoi nodi. Il cluster è composto da diversi nodi per migliorare la disponibilità e la resilienza. Ogni nodo può svolgere tutti i ruoli del cluster, ma nelle distribuzioni scalabili di grandi dimensioni, ai nodi vengono solitamente assegnati compiti distinti.
Tipi di nodi del cluster:
- nodo master — gestisce il cluster, ne servono almeno tre, uno è sempre attivo;
- nodo dati — memorizza i dati indicizzati ed esegue varie operazioni su di essi;
- nodo ingest — organizza pipeline per la trasformazione dei dati prima dell'indicizzazione;
- nodo di coordinamento — instradamento delle richieste, riduzione della fase di elaborazione della ricerca, coordinazione dell'indicizzazione di massa;
- nodo di allerta — avvio di attività di notifica;
- nodo di machine learning — elaborazione delle attività di apprendimento automatico.
Nella diagramma sottostante si mostra come i dati vengano memorizzati e replicati sui nodi per garantire una maggiore disponibilità dei dati.
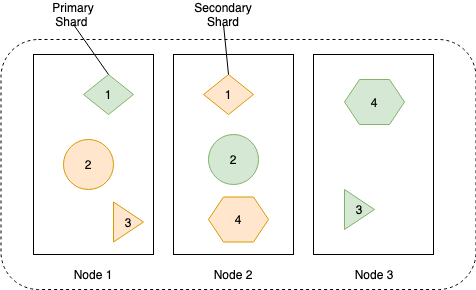
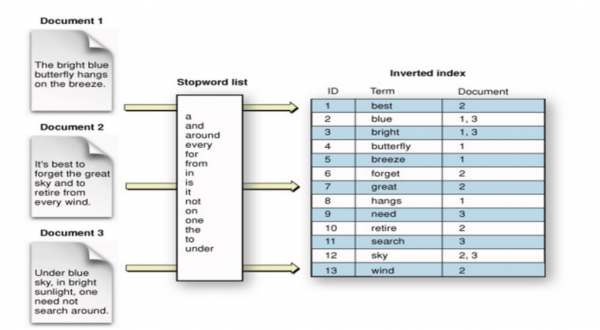
I dati di ogni replica vengono memorizzati in un indice invertito, lo schema sottostante mostra come avviene:
Installazione
Puoi visualizzare i dettagli , utilizzerò il chart helm:
$ helm install efk-stack stable/elastic-stack --set logstash.enabled=false --set fluentd.enabled=true --set fluentd-elasticsStack PLG
Non sorprendere se non riesci a trovare questo acronimo, è più conosciuto come Grafana Loki. In ogni caso, questo stack sta guadagnando popolarità grazie alle sue soluzioni tecniche ben congegnate. Potresti già aver sentito parlare di Grafana, un popolare strumento di visualizzazione. I suoi creatori, ispirandosi a Prometheus, hanno sviluppato Loki, un sistema di aggregazione dei log ad alte prestazioni e scalabile orizzontalmente. Loki indicizza solo i metadati, non i log stessi; questa soluzione tecnica lo rende semplice da utilizzare ed economicamente vantaggioso.
Promtail — un agente per l'invio dei log dal sistema operativo al cluster Loki. Grafana — uno strumento di visualizzazione basato sui dati di Loki.

Loki è costruito sugli stessi principi di Prometheus, quindi è ben adatto per lo storage e l'analisi dei log di Kubernetes.
Architettura di Loki
Loki può essere eseguito sia in modalità singolo processo che come più processi, garantendo scalabilità orizzontale.
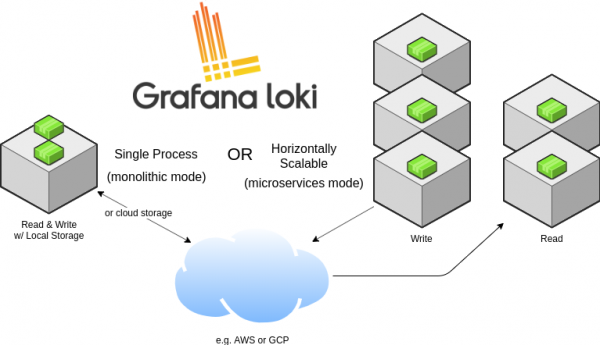
Può funzionare sia come un'applicazione monolitica che come microservizio. L'esecuzione come processo unico può essere utile per lo sviluppo locale o per un monitoraggio leggero. Per l'implementazione industriale e i carichi scalabili, è consigliato utilizzare l'opzione microservizio. Le vie di scrittura e lettura dei dati sono separate, consentendo una configurazione e una scalabilità sufficientemente flessibili.
Esaminiamo l'architettura del sistema di raccolta dei log senza entrare nei dettagli:
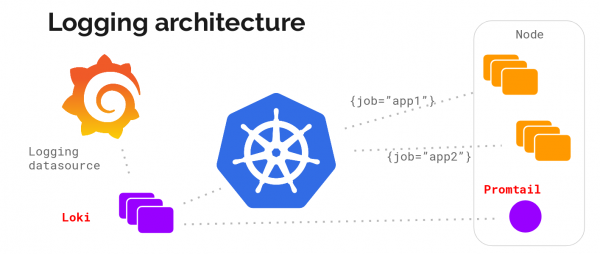
Ecco una descrizione (architettura a microservizi):
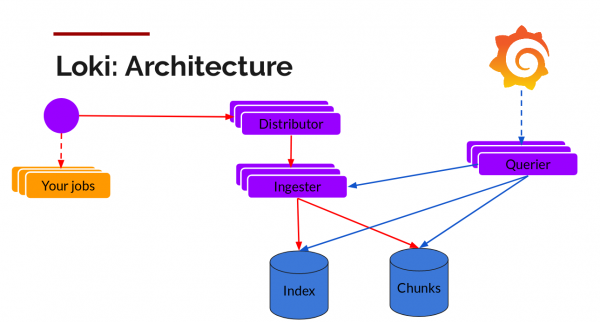
Componenti:
Promtail — un agente, installato sui nodi (sotto forma di un insieme di servizi), raccoglie i log dalle attività e si rivolge all'API Kubernetes per ottenere i metadati che contrassegneranno i log. Successivamente, invia i log al servizio principale Loki. Le stesse regole di etichettatura utilizzate in Prometheus vengono applicate per la corrispondenza dei metadati.
Distributor — un servizio distribuitore che funziona come buffer. Per elaborare milioni di record, impacchetta i dati in arrivo, comprimendoli a blocchi man mano che vengono ricevuti. Funzionano simultaneamente più ricevitori di dati, ma i log appartenenti a un singolo flusso di dati in arrivo devono trovarsi solo in uno di essi per tutti i suoi blocchi. Questo è organizzato come un anello di ricevitori e hashing sequenziale. Per la tolleranza ai guasti e la ridondanza, viene eseguito n volte (3 se non configurato).
Ingester — un servizio ricevitore. I blocchi di dati arrivano compressi con log aggiunti. Una volta che un blocco raggiunge una dimensione sufficiente, il blocco viene scaricato nel database. I metadati vanno nell'indice, mentre i dati del blocco con il log finiscono in Chunks (di solito è uno storage a oggetti). Dopo il caricamento, il ricevitore crea un nuovo blocco nel quale verranno aggiunti nuovi record.

Index — database, DynamoDB, Cassandra, Google BigTable e altro ancora.
Chunks — blocchi di log compressi, di solito memorizzati in uno storage a oggetti, ad esempio, S3.
Querier — un percorso di lettura che svolge tutto il lavoro sporco. Analizza l'intervallo di tempo e le etichette, quindi verifica l'indice per cercare corrispondenze. Successivamente, legge i blocchi di dati e li filtra per ottenere i risultati.
Ora diamo un'occhiata a tutto questo in azione.
Installazione
Per l'installazione in Kubernetes, il modo più semplice è utilizzare helm. Presumiamo che tu lo abbia già installato e configurato ( nota del traduttore)
Aggiungiamo il repository e installiamo il stack.
$ helm repo add loki https://grafana.github.io/loki/charts
$ helm repo update
$ helm upgrade --install loki loki/loki-stack --set grafana.enabled=true,prometheus.enabled=true,prometheus.alertmanager.persistentVolume.enabled=false,prometheus.server.persistentVolume.enabled=falseDi seguito è riportato un esempio di dashboard che mostra i dati da Prometheus per le metriche Etcd e Loki per i log dei pod Etcd.
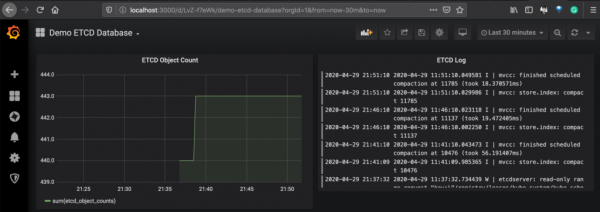
Ora discutiamo dell'architettura di entrambi i sistemi e confrontiamo le loro funzionalità.
Confronto
Linguaggio di query
In Elasticsearch si utilizza Query DSL e Lucene query language, che consentono la ricerca full-text. Questo è un motore di ricerca consolidato e potente, con ampio supporto per gli operatori. Con esso, puoi cercare nel contesto e ordinare per rilevanza.
Dall'altra parte del ring c'è LogQL, utilizzato in Loki, erede di PromQL (linguaggio di query di Prometheus). Esso impiega le etichette dei log per filtrare e recuperare i dati dai log. È possibile usare alcuni operatori e fare delle operazioni aritmetiche, come descritto , ma per capacità rimane indietro rispetto al linguaggio Elastic.
Poiché le query in Loki sono legate alle etichette, è facile correlare queste ultime con le metriche, rendendo così più semplice organizzare il monitoraggio operativo.
Scalabilità
Entrambi gli stack sono scalabili orizzontalmente, ma con Loki è più semplice, poiché ha percorsi di lettura e scrittura dei dati separati, oltre a un'architettura a microservizi. Loki può essere configurato in base alle tue esigenze e può gestire volumi molto elevati di dati di log.
Multi-tenancy
La multi-tenancy del cluster è un tema comune per ridurre l'OPEX, entrambi gli stack supportano la multi-tenancy. Per Elasticsearch ci sono diverse di separazione dei clienti: un indice separato per ogni cliente, instradamento basato sul cliente, campi unici per il cliente, filtri di ricerca. In Loki c'è sotto forma dell'intestazione HTTP X-Scope-OrgID.
Costo
Loki è molto efficiente dal punto di vista economico poiché non indicizza i dati, ma solo i metadati. In questo modo si ottiene e di memoria (cache), in quanto l'archiviazione a oggetti è più economica rispetto a quella a blocchi utilizzata nei cluster Elasticsearch.
Conclusione
Il stack EFK può essere utilizzato per diverse finalità, fornendo la massima flessibilità e un'interfaccia multifunzionale di Kibana per analisi, visualizzazioni e query. Inoltre, può essere potenziato con capacità di apprendimento automatico.
Il stack Loki è utile nell'ecosistema Kubernetes grazie al meccanismo di scoperta dei metadati. È possibile facilmente mappare i dati per il monitoraggio basato su serie temporali in Grafana e nei log.
Quando si tratta di costi e di archiviazione a lungo termine dei log, Loki rappresenta un'ottima scelta per l'ingresso nelle soluzioni cloud.
Ci sono più alternative sul mercato, alcune delle quali potrebbero essere migliori per te. Ad esempio, per GKE c'è integrazione con Stackdriver, che offre un'ottima soluzione per il monitoraggio. Non le abbiamo incluse nella nostra analisi in questo articolo.
Link:
L'articolo è stato tradotto e preparato per Habr dai collaboratori — corsi intensivi, videoconferenze e formazione aziendale da esperti praticanti (Kubernetes, DevOps, Docker, Ansible, Ceph, SRE, Agile)
Fonte: habr.com
