

Esploreremo le basi del logging in Docker e Kubernetes, quindi esamineremo due strumenti che possono essere utilizzati tranquillamente in produzione: Grafana Loki e lo stack EFK (Elasticsearch + Fluent Bit + Kibana).
Il materiale dell'articolo è un riassunto di . Se c'è interesse e, soprattutto, necessità produttiva, si può seguire un corso completo — iscriviti al corso su .

Logging in Docker
A livello di Kubernetes, le applicazioni sono eseguite nei pod, ma a un livello inferiore funzionano comunque normalmente in Docker. Pertanto, è necessario configurare il logging in modo da raccogliere i log dai contenitori. I contenitori sono avviati da Docker, quindi dobbiamo capire come funziona il logging a livello di Docker.
Spero che ogni lettore sappia: i log delle applicazioni devono essere scritti in stdout/stderr, e non all'interno del container. I log vengono aggregati dal Docker Daemon, che lavora proprio con quei log inviati a stdout/stderr. Inoltre, registrare i log all'interno del container porta a problemi: il container cresce a causa del log in aumento (poiché probabilmente non c'è alcun Logrotate nel container) e il Docker Daemon non è a conoscenza di questo log.
Docker ha diversi driver di log o plugin per la raccolta dei log dei container. Nella versione gratuita Docker Community Edition (CE) ci sono meno driver di log rispetto alla versione commerciale Docker Enterprise Edition (EE).

Non ho mai usato Docker EE nella pratica: in Southbridge cerchiamo di attenerci a soluzioni Open Source, e per i clienti gran parte delle funzionalità aggiuntive di Docker EE non è necessaria.
Driver di log in Docker CE:
local — scrittura dei log in file interni del Docker Daemon;
json-file — creazione di un json-log nella cartella di ogni container;
journald — invio dei log a journald.
Le impostazioni di logging in Docker si trovano nel file daemon.json.
Nel campo “log-driver” si specifica il plugin e nel campo “log-opts” le sue impostazioni. Nell'esempio sopra è indicato il plugin “json-file”, dove il limite delle dimensioni del log è “max-size”: “10m”; il limite del numero di file (impostazioni di rotazione) è “max-file”: “3”; e anche i valori che saranno allegati ai log.

Alcune impostazioni del log-driver possono essere fornite tramite l'utilità da riga di comando. Questo è utile se un contenitore specifico deve essere avviato con un log-driver diverso.
Ecco come appare lo schema di logging in Docker:
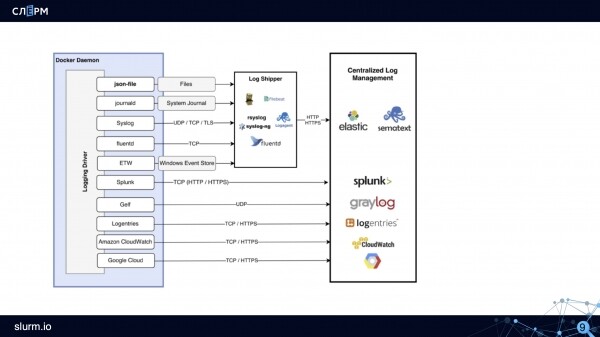
Come funziona lo schema: il log-driver, ad esempio json-file, crea file. I raccoglitori di log (Rsyslog, Fluentd, Logagent e altri) raccolgono questi file e li inviano per l'archiviazione in Elastic, Sematext o altre soluzioni di storage.
Caratteristiche del logging in Kubernetes
In modo semplificato, lo schema di logging in Kubernetes appare così: c'è un pod, in cui è avviato un contenitore, e il contenitore invia i log in stdout/stderr. Poi Docker crea un file e registra i log, che poi possono essere ruotati.
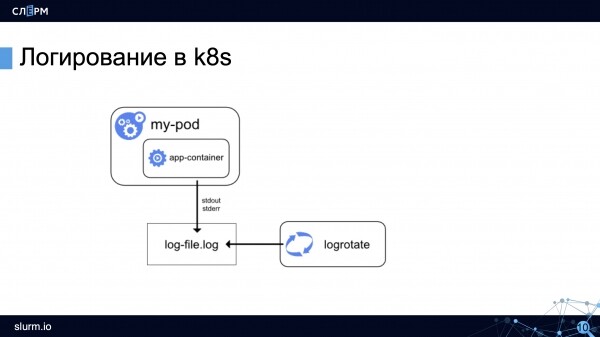
Esaminiamo le caratteristiche del logging in Kubernetes.
Conservare i log tra i deploy. Questa è una condizione necessaria per la corretta configurazione del logging. Se non si salvano i log tra i deployment, con l'uscita di una nuova versione dell'app, i log precedenti verranno sovrascritti; anche il riavvio del contenitore comporta il rischio di perdere i log. Kubernetes ha un flag —previous che permette di visualizzare i log dell'app prima dell'ultimo riavvio del Pod, ma non più indietro.
Aggregare i log da tutte le istanze. Se i microservizi sono ospitati nel cloud, il fornitore di cloud si occupa del monitoraggio del sistema. Se i microservizi sono sul proprio hardware, oltre ai log dei contenitori, è necessario raccogliere anche i log di sistema.
In passato non c'erano strumenti comodi per raccogliere i log sia dal sistema che dai microservizi. Di solito, un strumento raccoglieva i log di sistema (ad esempio, Rsyslog), mentre un altro raccoglieva i log da Docker (ad esempio, journal-bit con la configurazione del log-driver Docker su journald). Hanno provato a utilizzare journal-bit per raccogliere i log sia dai contenitori (specificando nel log-driver Docker che i log devono essere scritti in journald) che dal sistema (in CentOS 7 sono già presenti systemd e journald). La soluzione funziona, ma non è ideale. Se ci sono molti log, journal-bit inizia a laggare e i messaggi si perdono.
Gli esperimenti sono continuati — e è stata trovata un'altra soluzione. In CentOS 7 i log di sistema principali (messages, audit, secure) vengono duplicati in var-log come file. In Docker è anche possibile configurare il salvataggio dei log in file json. Pertanto, questi file di CentOS 7 e Docker possono essere raccolti insieme.
Con il tempo, è diventata popolare la soluzione ELK Stack. Questa è una combinazione di diversi strumenti: Elasticsearch, Logstash e Kibana.
Elasticsearch memorizza i log dai contenitori, Logstash raccoglie i log dalle istanze, Kibana consente di elaborare i log ricevuti e di creare grafici. Per un certo periodo, l'ELK Stack è stato utilizzato attivamente, ma, a mio avviso, il suo tempo sta passando. Più avanti spiegherò il perché.
Aggiungere metadati. I pod, le applicazioni, i contenitori possono essere eseguiti ovunque. Inoltre, un'applicazione può avere più istanze. I log sono registrati in un formato uniforme, ma dobbiamo capire quale replica specifica è, quale Pod sta scrivendo, in quale namespace si trova. Ecco perché è necessario aggiungere metadati ai log.
Analizzare i log. È curioso, ma i costi per il supporto del sistema di logging e monitoraggio possono superare quelli dell'applicazione principale. Quando hai decine e centinaia di migliaia di log al secondo, sembra inevitabile, ma è importante conoscere i limiti. Un modo per trovare questi limiti è l'analisi dei log.
Di norma, non è necessario raccogliere e conservare tutti i log; è sufficiente inviare per la conservazione solo una parte, ad esempio i log con stato 'warning' o 'error'. Se si tratta di log nginx o ingress controller, si possono inviare per la conservazione solo quelli il cui stato è diverso da 200. Ma questo non è un consiglio universale: se stai costruendo in qualche modo un'analisi sui log di Nginx, vale sicuramente la pena raccoglierli.
Non si consiglia di filtrare i log in modo indiscriminato, poiché i dati filtrati potrebbero non essere sufficienti per un'analisi adeguata. D'altro canto, potrebbe essere opportuno condurre l'analisi non a livello di log, ma a livello di raccolta delle metriche. In questo caso, non sarà necessario conservare centinaia di migliaia di righe con codice 200. Uno dei metodi è ottenere informazioni su traffico ed errori dalle metriche degli ingress controller.
In generale, è importante riflettere attentamente su cosa si desidera memorizzare e per quanto tempo, poiché altrimenti si rischia di trovarsi in una situazione in cui il sistema di registrazione consuma più risorse del progetto principale.
Attualmente non esiste una soluzione standard per la registrazione.A differenza del monitoraggio, per il quale esiste una soluzione predominante come Prometheus, non c'è uno standard nella registrazione.
In questa lezione esamineremo due strumenti: uno popolare e l'altro in crescente diffusione. Ce ne sono altri, ma non li considereremo in questo articolo.
Tenendo conto di tutte le caratteristiche sopra menzionate, la registrazione in Kubernetes può ora essere rappresentata in questo modo:
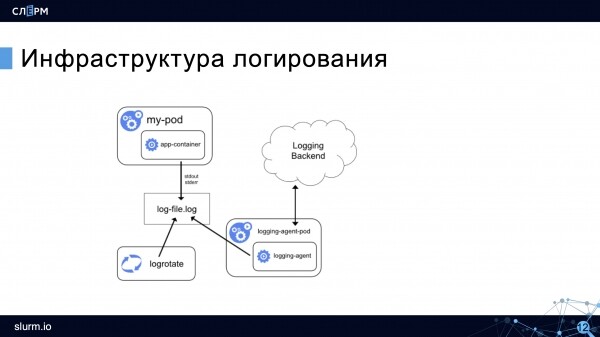
Resta il registro del container e il sistema di rotazione, ma appare un agente di raccolta che raccoglie i log e li invia per la memorizzazione (nello schema — nel Logging Backend). L'agente opera su ogni nodo ed è generalmente avviato in Kubernetes.
Ora esaminiamo gli strumenti per la registrazione.
Grafana Loki
è apparso di recente, ma è già diventato piuttosto noto. I suoi vantaggi: facile da installare, consuma poche risorse, non richiede l'installazione di Elasticsearch, in quanto memorizza i dati in un TSDB (database delle serie temporali). Nel mio articolo precedente, ho scritto che questo tipo di database memorizza dati in Prometheus, ed è una delle numerose somiglianze tra i due prodotti. Gli sviluppatori affermano addirittura che Loki è "Prometheus per il mondo del logging".
Una breve digressione su TSDB per chi non ha letto : il TSDB gestisce bene la memorizzazione di grandi volumi di dati e delle serie temporali, ma non è progettato per la conservazione a lungo termine. Se per qualche motivo hai bisogno di conservare i log per più di due settimane, è meglio configurare il loro invio a un'altra base di dati.
Un altro vantaggio di Loki è che per la visualizzazione dei dati viene utilizzato Grafana. Molto comodo: in Grafana possiamo visualizzare i dati di monitoraggio e, collegando Loki, possiamo anche visualizzare i log. È possibile costruire grafici dai log.
L'architettura di Loki appare all'incirca così:
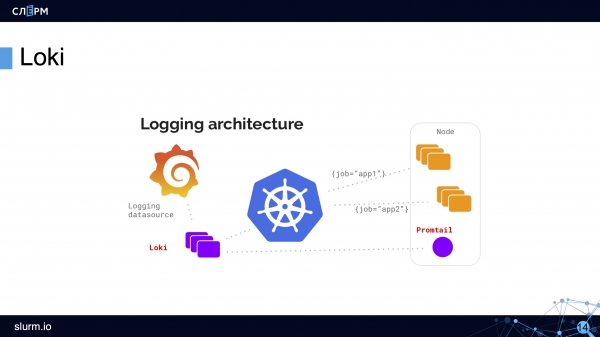
Con DaemonSet, un agente — Promtail o Fluent Bit — viene distribuito su tutti i server del cluster. L'agente raccoglie i log. Loki li riceve e li memorizza nel suo TSDB. Ai log vengono immediatamente aggiunti dei metadati, il che è comodo: si può filtrare per Pods, namespaces, nomi dei contenitori e persino etichette.
Loki funziona con l'interfaccia familiare di Grafana. Loki ha anche il suo linguaggio di query, chiamato LogQL, che per nome e sintassi ricorda PromQL in Prometheus. Nell'interfaccia di Loki ci sono suggerimenti per le query, quindi non è necessario conoscerle a memoria.
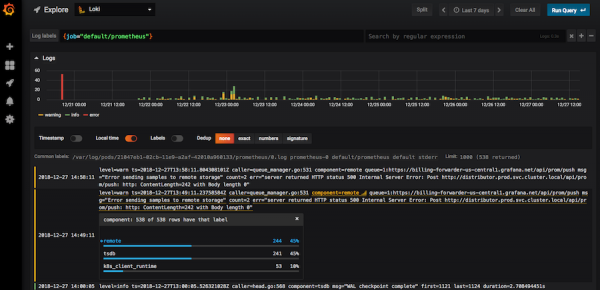
Loki nell'interfaccia di Grafana
Utilizzando i filtri, in Loki è possibile trovare codici ("400", "404" e qualsiasi altro); visualizzare i log di tutto il nodo; filtrare tutti i log che contengono la parola "error". Cliccando su un log, si aprirà una scheda con tutte le informazioni sull'evento.
In Loki ci sono strumenti sufficienti che consentono di estrarre i log necessari, anche se onestamente potrebbero essere più numerosi elettronicamente. Attualmente, Loki si sta sviluppando attivamente e sta guadagnando popolarità.
Elastic + Fluent Bit + Kibana (Stack EFK)
Lo stack EFK è uno strumento di logging più classico, non meno popolare.
All'inizio dell'articolo si parlava di ELK (Elasticsearch + Logstash + Kibana), ma questo stack è diventato obsoleto a causa di un Logstash non molto performante e anche molto esoso in termini di risorse. Al suo posto, si è iniziato a utilizzare il più leggero e performante Fluentd, e dopo un po' di tempo gli è stato affiancato — un agente di raccolta ancora più leggero e performante.
Se si crede agli sviluppatori, Fluent Bit è oltre 100 volte più performante di Fluentd: "dove Fluentd consuma 20 MB di RAM, Fluent Bit consuma 150 KB" — citazione diretta dalla documentazione. Guardando a questi dati, si è iniziato a utilizzare Fluent Bit più spesso.
Fluent Bit ha meno funzionalità rispetto a Fluentd, ma soddisfa le esigenze principali, quindi noi utilizziamo principalmente Fluent Bit.
Schema di funzionamento dello stack EFK: l'agente raccoglie i log da tutti i pod (di solito un DaemonSet eseguito su tutti i server del cluster) e invia i dati a uno storage (Elasticsearch, PostgreSQL o Kafka). Kibana si connette allo storage e recupera tutte le informazioni necessarie.
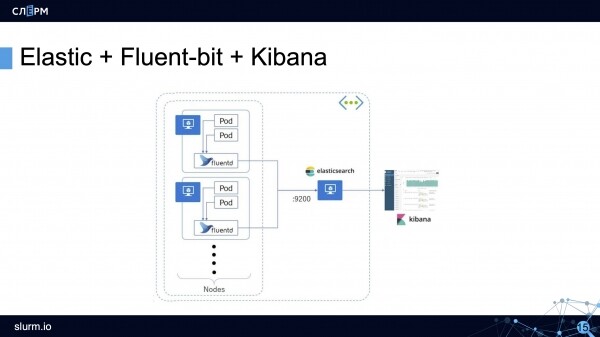
visualizza le informazioni in un'interfaccia web comoda. Ci sono grafici, filtri e molto altro.
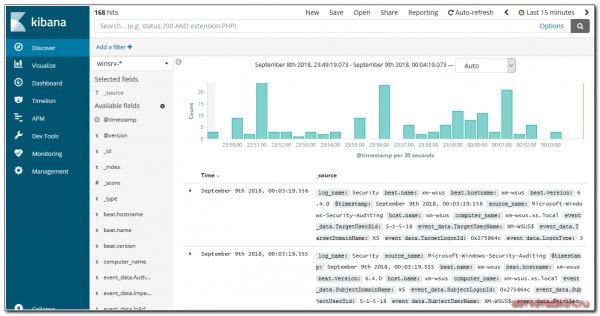
Dai log è possibile creare interi dashboard.
Funzionalità di Fluent Bit
Poiché di Fluent Bit si parla generalmente meno rispetto a Logstash, esaminiamo questo strumento in modo più dettagliato. Fluent Bit può essere logicamente suddiviso in 6 moduli, e alcuni di questi moduli possono essere dotati di plugin che estendono le funzionalità di Fluent Bit.
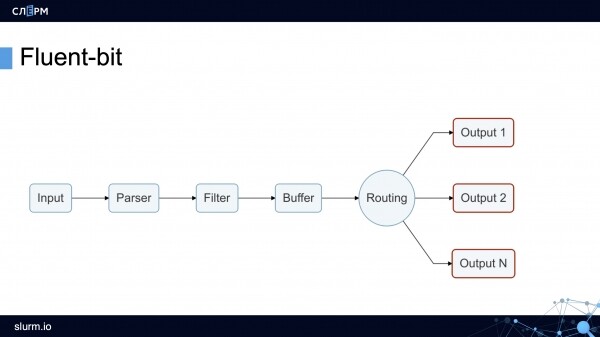
Modulo Input raccoglie i log da file, servizi systemd e anche da tcp-socket (è sufficiente specificare l'endpoint e Fluent Bit inizierà a connettersi). Queste funzionalità sono sufficienti per raccogliere log sia dal sistema che dai contenitori.
In produzione utilizziamo più frequentemente i plugin (che possono essere indirizzati a una cartella con i log) e (a cui può essere indicato da quali servizi raccogliere i log).
Modulo Parser formalizza i log in un formato comune. Per impostazione predefinita, i log di Nginx sono una singola stringa. Con l'aiuto di un plugin, tale stringa può essere trasformata in JSON: è possibile definire campi e valori. Lavorare con il JSON è molto più semplice rispetto ai log in formato stringa, poiché offre maggiore flessibilità nella sorteggiatura.
Modulo Filter. A questo livello si filtrano i log non necessari. Ad esempio, vengono memorizzati solo i log con il valore "warning" o con specifici label. I log selezionati vengono inviati al buffer.
Modulo Buffer. Fluent Bit ha due tipi di buffer: buffer di memoria e buffer su disco. Un buffer è un'area di memorizzazione temporanea per i log, utilizzata in caso di errori o malfunzionamenti. Tutti vogliono risparmiare sulla RAM, quindi di solito si sceglie il buffer su disco. Ma bisogna considerare che prima di andare su disco, i log vengono comunque scaricati in memoria.
Modulo Routing/Output contiene le regole e gli indirizzi per l'invio dei log. Come già detto, i log possono essere inviati a Elasticsearch, PostgreSQL o, ad esempio, Kafka.
È interessante notare che da Fluent Bit i log possono essere inviati a Fluentd. Poiché il primo è più leggero e meno funzionale, attraverso di esso è possibile raccogliere log e inviarli a Fluentd, dove possono essere ulteriormente elaborati e inviati a storage utilizzando plugin aggiuntivi.
Se pianificate di usare Elasticsearch…
Ultimo consiglio per coloro che intendono utilizzare Elasticsearch come storage di log in produzione.
- Configurate le notifiche utilizzando . Questo programma estrae i messaggi importanti dal flusso generale di log e crea avvisi via email o su un altro canale. Tuttavia, recentemente è stata pubblicata .
- Ruota i log utilizzando l'applicazione o tramite chiamate all'API di Elasticsearch. Elastic, in effetti, sta compiendo notevoli passi avanti nella gestione della vita degli indici senza utilizzare strumenti esterni. In generale, non ha senso conservare i log a lungo: è improbabile che un log sia utile dopo due settimane — se è veramente critico, verrà gestito entro quel termine. In caso estremo, i log più vecchi possono essere archiviati e inviati da qualche parte per la conservazione a lungo termine. Ho sentito parlare di log speciali che, per legge, devono essere conservati fino a 5 anni. Personalmente non ho mai avuto a che fare con questo, ma non equiparerei tali informazioni a log normali e probabilmente li conserverei separatamente.
Continua...
Autore: Marsel Ibraev, amministratore certificato Kubernetes, ingegnere praticante presso , relatore e sviluppatore di corsi .
Fonte: habr.com
