

La classificazione dei dati basata sul contenuto è una sfida aperta. I tradizionali sistemi di prevenzione della perdita di dati (DLP) affrontano questo problema acquisendo impronte dei dati pertinenti e monitorando i punti finali per tali impronte. Considerando l'enorme quantità di risorse dati in continua evoluzione su Facebook, questo approccio non è solo non scalabile, ma anche inefficace per determinare dove si trovano i dati. Questo articolo è dedicato a un sistema end-to-end progettato per rilevare tipi semantici sensibili su Facebook su larga scala e per garantire automaticamente la conservazione dei dati e il controllo dell'accesso.
L'approccio descritto qui è il nostro primo sistema di privacy completo, che cerca di affrontare questo problema attraverso l'integrazione di segnali di dati, apprendimento automatico e metodi tradizionali di fingerprinting per mostrare e classificare tutti i dati su Facebook. Il sistema descritto è sfruttato in un ambiente di produzione, raggiungendo un punteggio medio F2 di 0,9+ su varie classi di privacy mentre gestisce grandi quantità di risorse dati in decine di archivi. Presentiamo la traduzione della pubblicazione di Facebook su ArXiv sulla classificazione scalabile dei dati per garantire sicurezza e privacy basata sul machine learning.
Introduzione
Oggi le organizzazioni raccolgono e conservano grandi volumi di dati in vari formati e posizioni [1]. Questi dati vengono quindi utilizzati in molti luoghi, a volte copiati o memorizzati in cache più volte, con il risultato che informazioni aziendali preziose e riservate si disperdono in molti archivi aziendali. Quando un'organizzazione è tenuta a soddisfare specifici requisiti legali o normativi, come il rispetto delle normative durante un procedimento civile, nasce l'esigenza di raccogliere dati sulla posizione delle informazioni necessarie. Quando un decreto di riservatezza stabilisce che l'organizzazione deve mascherare tutti i numeri di previdenza sociale (SSN) durante la trasmissione di informazioni personali a soggetti non autorizzati, il primo passo naturale è cercare tutti gli SSN negli archivi dei dati dell'intera organizzazione. In tali circostanze, la classificazione dei dati diventa cruciale [1]. Un sistema di classificazione permetterà alle organizzazioni di garantire automaticamente la conformità alle politiche di riservatezza e di sicurezza, come l'inclusione di politiche di gestione degli accessi e di conservazione dei dati. Facebook presenta un sistema creato da noi in Facebook, che utilizza numerosi segnali dati, un'architettura di sistema scalabile e l'apprendimento automatico per individuare tipologie di dati sensibili e semantici.
La rilevazione e la classificazione dei dati comportano la ricerca e l'etichettatura in modo tale da consentire un rapido ed efficiente recupero delle informazioni pertinenti quando necessario. L'attuale processo è per lo più manuale e consiste nell'esaminare le leggi o le normative pertinenti, determinare quali tipi di informazioni devono essere considerati sensibili e quali sono i diversi livelli di sensibilità, e poi costruire classi e politiche di classificazione di conseguenza [1]. Dopo che i sistemi di prevenzione della perdita di dati (DLP) ottengono le impronte dei dati, monitorano i punti finali a valle per raccogliere le impronte. Con uno storage che gestisce un gran numero di asset e petabyte di dati, questo approccio semplicemente non è scalabile.
Il nostro obiettivo è costruire un sistema di classificazione dei dati che sia scalabile sia per i dati degli utenti stabili che per quelli non stabili, senza alcuna restrizione aggiuntiva sul tipo o sul formato dei dati. È un obiettivo audace e, naturalmente, comporta delle sfide. Qualsiasi registrazione di dati può avere lunghezze di migliaia di caratteri.
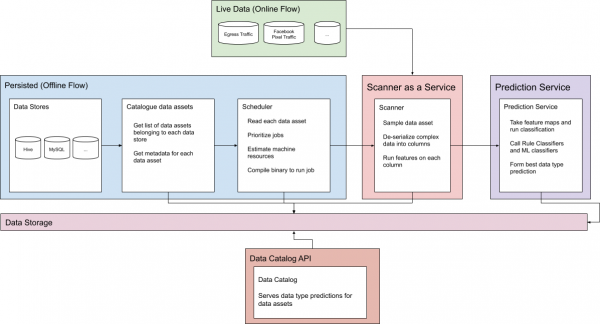
Figura 1. Flussi di previsione online e offline
Pertanto, dobbiamo rappresentarla in modo efficace, utilizzando un insieme comune di caratteristiche che possono essere successivamente integrate e facilmente trasferite. Queste caratteristiche devono non solo garantire una classificazione accurata, ma anche offrire flessibilità ed espandibilità per un facile aggiunta e scoperta di nuovi tipi di dati in futuro. In secondo luogo, è necessario affrontare grandi tabelle autonome. I dati persistenti possono essere archiviati in tabelle di dimensioni multiple petabyte. Ciò può portare a una diminuzione della velocità di scansione. In terzo luogo, dobbiamo mantenere una rigorosa classificazione SLA per i dati non persistenti. Questo costringe il sistema a essere altamente efficiente, veloce e preciso. Infine, dobbiamo garantire la classificazione dei dati con bassa latenza per i dati non persistenti, per effettuare la classificazione in tempo reale, oltre a casi d'uso online.
In questo articolo si descrive come abbiamo affrontato le problematiche sopra e viene presentato un sistema di classificazione veloce e scalabile che classifica elementi di dati di tutti i tipi, formati e fonti in base a un insieme comune di caratteristiche. Abbiamo ampliato l'architettura del sistema e creato un modello di machine learning dedicato per una classificazione rapida dei dati online e offline. Questo articolo è organizzato come segue: nella sezione 2 viene presentato il design generale del sistema. Nella sezione 3 si discutono le parti del sistema di machine learning. Nelle sezioni 4 e 5 si parla del lavoro correlato e si delinea una futura direzione di lavoro.
Architettura
Per affrontare le problematiche dei dati persistenti e dei dati online su larga scala come Facebook, il sistema di classificazione ha due flussi separati di cui discuteremo in dettaglio.
Dati persistenti
Inizialmente, il sistema deve apprendere una varietà di attivi informativi di Facebook. Per ogni repository, viene raccolta una serie di informazioni di base, come il centro dati che contiene tali dati, il sistema che gestisce questi dati e gli attivi situati in uno specifico repository di dati. Questo crea un catalogo di metadati che consente al sistema di estrarre dati in modo efficace senza sovraccaricare i clienti e le risorse utilizzate da altri ingegneri.
Questo catalogo di metadati fornisce una fonte affidabile per tutti gli attivi scansionati e consente di monitorare lo stato di vari attivi. Con queste informazioni, si stabilisce la priorità di pianificazione basata sui dati raccolti e sulle informazioni interne del sistema, come il tempo dell'ultima scansione riuscita dell'attivo e il momento della sua creazione, nonché le passate esigenze di memoria e CPU per quell'attivo, se è stato scansionato in precedenza. Successivamente, per ogni risorsa di dati (man mano che le risorse diventano disponibili) viene richiamato un incarico per la scansione effettiva della risorsa.
Ogni incarico è un file binario compilato che esegue un campionamento di Bernoulli sui dati più recenti disponibili per ogni asset. L'asset viene suddiviso in colonne separate, dove il risultato della classificazione di ogni colonna viene elaborato in modo indipendente. Inoltre, il sistema scansiona qualsiasi dato denso all'interno delle colonne. JSON, array, strutture codificate, URL, dati serializzati in base 64 e molto altro vengono tutti scansionati. Questo può aumentare notevolmente il tempo di esecuzione della scansione, poiché una tabella può contenere migliaia di colonne annidate in un grande oggetto binario. json.
Per ogni riga selezionata nell'asset dati, il sistema di classificazione estrae oggetti fluttuanti e testuali dal contenuto e collega ogni oggetto alla colonna da cui è stato prelevato. Il risultato della fase di estrazione degli oggetti è una mappa di tutti gli oggetti per ogni colonna trovata nell'asset dati.
A cosa servono le caratteristiche?
Il concetto di caratteristiche è fondamentale. Invece delle caratteristiche float e text, possiamo passare campioni grezzi di stringhe che sono estratti direttamente da ciascuna sorgente di dati. Inoltre, i modelli di machine learning possono essere addestrati direttamente su ogni campione, invece che su centinaia di calcoli delle caratteristiche che cercano solo di approssimare il campione. Ci sono diverse ragioni per questo:
- La privacy prima di tutto: ciò che è fondamentale, il concetto di caratteristiche ci consente di memorizzare solo i campioni che estraiamo. Questo garantisce che conserviamo i campioni per un'unica finalità e non li registriamo mai per conto nostro. Questo è particolarmente importante per i dati instabili, poiché il servizio deve mantenere uno stato di classificazione prima di fornire una previsione.
- Memoria: alcuni campioni possono avere una lunghezza di migliaia di caratteri. Memorizzare tali dati e passarli attraverso le parti del sistema senza necessità consuma molti byte aggiuntivi. Due fattori possono unirsi col tempo, considerando che ci sono molte sorgenti di dati con migliaia di colonne.
- Aggregazione delle caratteristiche: utilizzando le caratteristiche, i risultati di ciascuna scansione vengono presentati chiaramente, consentendo al sistema di combinare i risultati delle precedenti scansioni della stessa risorsa dati in un modo conveniente. Questo può essere utile per aggregare i risultati della scansione di una risorsa dati su più esecuzioni.
Successivamente, le caratteristiche vengono inviate al servizio di previsione, dove utilizziamo la classificazione basata su regole e l'apprendimento automatico per prevedere le etichette dei dati di ciascuna colonna. Il servizio si basa sia sui classificatori basati su regole che sull'apprendimento automatico e sceglie la migliore previsione fornita da ciascun oggetto di previsione.
I classificatori basati su regole sono un'euristica manuale, che utilizza calcoli e coefficienti per normalizzare un oggetto su una scala da 0 a 100. Una volta generato un punteggio iniziale per ogni tipo di dato e nome della colonna associata a questi dati, se non rientra in alcun «elenco di divieto», il classificatore basato su regole seleziona il punteggio normalizzato più alto tra tutti i tipi di dati.
A causa della complessità della classificazione, l'uso esclusivo di euristiche manuali porta a bassa precisione nella classificazione, specialmente per i dati non strutturati. Per questo motivo, abbiamo sviluppato un sistema di apprendimento automatico per la classificazione di dati non strutturati, come contenuti degli utenti e indirizzi. L'apprendimento automatico ha consentito di allontanarsi dalle euristiche manuali e di applicare segnali dati aggiuntivi (come i nomi delle colonne, l'origine dei dati), aumentando significativamente la precisione del rilevamento. Ci immergeremo nella nostra architettura di apprendimento automatico più avanti.
Il servizio di previsione memorizza i risultati per ogni colonna insieme ai metadati relativi al tempo e allo stato della scansione. Qualsiasi consumatore e processo sottostante che dipende da questi dati può leggerli dal set di dati pubblicato quotidianamente. Questo set aggrega i risultati di tutti questi compiti di scansione, o API di catalogo dati in tempo reale. Le previsioni pubblicate sono fondamentali per l'applicazione automatica delle politiche di privacy e sicurezza.
Finalmente, dopo che il servizio di previsione ha registrato tutti i dati e tutte le previsioni sono state salvate, la nostra API del catalogo dati può restituire tutte le previsioni dei tipi di dati per la risorsa in tempo reale. Ogni giorno, il sistema pubblica un set di dati contenente tutte le ultime previsioni per ciascun attivo.
Dati instabili
Sebbene il processo descritto sopra sia progettato per gli attivi salvati, il traffico non salvato è anch'esso considerato parte dei dati dell'organizzazione e può essere importante. Per questo motivo, il sistema fornisce un'API online per la generazione di previsioni di classificazione in tempo reale per qualsiasi traffico instabile. Il sistema di previsione in tempo reale è ampiamente utilizzato per la classificazione del traffico in uscita, del traffico in ingresso nei modelli di apprendimento automatico e dei dati degli inserzionisti.
Qui l'API accetta due argomenti principali: la chiave di raggruppamento e i dati grezzi che devono essere previsti. Il servizio esegue la stessa estrazione degli oggetti descritta in precedenza e raggruppa gli oggetti per la stessa chiave. Queste caratteristiche sono anche supportate nella cache salvata per il ripristino dopo un guasto. Per ogni chiave di raggruppamento, il servizio garantisce che prima della chiamata al servizio di previsione abbia visto un numero sufficiente di campioni secondo il processo descritto in precedenza.
Ottimizzazione
Per la scansione di alcuni archivi utilizziamo librerie e metodi di ottimizzazione della lettura dall'archivio attivo [2] e garantiamo che non ci siano interruzioni da parte di altri utenti che accedono allo stesso archivio.
Per tabelle estremamente grandi (oltre 50 petabyte), nonostante tutte le ottimizzazioni e l'efficienza della memoria, il sistema sta lavorando per scansionare e calcolare tutto, prima che la memoria si esaurisca. Alla fine, la scansione viene elaborata completamente in memoria e non viene memorizzata durante l'esecuzione della scansione. Se tabelle di grandi dimensioni contengono migliaia di colonne con agganci di dati non strutturati, il compito può fallire a causa della mancanza di risorse di memoria durante l'esecuzione delle previsioni per l'intera tabella. Questo porterà a una riduzione della copertura. Per affrontare questo problema, abbiamo ottimizzato il sistema per utilizzare la velocità di scansione come intermediario per monitorare quanto bene il sistema gestisce il carico attuale. Utilizziamo la velocità come meccanismo predittivo per individuare problemi di memoria e nel calcolo proattivo della mappa degli oggetti. In questo modo, utilizziamo meno dati del solito.
Segnali di dati
Il sistema di classificazione è buono quanto lo sono i segnali dei dati. Qui esamineremo tutti i segnali utilizzati dal sistema di classificazione.
- Sulla base del contenuto: sicuramente, il primo e più importante segnale è il contenuto. Viene eseguita un'estrazione di Bernoulli per ogni asset di dati che scansioniamo ed estraiamo le caratteristiche in base al contenuto dei dati. Molte caratteristiche derivano dal contenuto. Possono esserci numerosi oggetti fluttuanti che rappresentano i calcoli di quante volte è stato osservato un certo tipo di campione. Ad esempio, possiamo avere conteggi di quante email sono state viste nel campione, o indizi su quanti emoji sono stati notati nel campione. Questi calcoli delle caratteristiche possono essere normalizzati e aggregati attraverso diverse scansioni.
- Origini dei dati: un segnale importante che può aiutare quando il contenuto è cambiato dalla tabella genitore. Un esempio comune sono i dati hashati. Quando i dati nella tabella figlia vengono hashati, spesso provengono dalla tabella genitore, dove rimangono in chiaro. I dati sull'origine aiutano a classificare determinati tipi di dati quando non sono letti chiaramente o trasformati dalla tabella a monte.
- Annotazioni: un ulteriore segnale di alta qualità che aiuta a identificare i dati non strutturati. Infatti, le annotazioni e i dati di origine possono lavorare insieme per distribuire attributi tra vari asset di dati. Le annotazioni aiutano a identificare la fonte dei dati non strutturati, mentre i dati di origine possono aiutare a tracciare il flusso di questi dati attraverso tutto il magazzino.
- Iniezione dei dati è un metodo in cui vengono intenzionalmente inseriti caratteri speciali e illeggibili in fonti note con tipi di dati noti. Dopodiché, ogni volta che scansioniamo il contenuto con la stessa sequenza di caratteri illeggibili, si può dedurre che il contenuto proviene da quel tipo di dati noto. Questo è un ulteriore segnale qualitativo dei dati, simile alle annotazioni. A differenza di queste, la rilevazione basata sul contenuto aiuta a scoprire i dati inseriti.
Misurazione delle metriche
Un componente importante è una rigorosa metodologia di misurazione delle metriche. Le principali metriche dell'iterazione di miglioramento della classificazione sono la precisione e il richiamo di ciascuna etichetta, con la valutazione F2 come la più significativa.
Per calcolare questi indicatori è necessaria una metodologia indipendente per la marcatura degli asset dei dati, che non dipenda dal sistema stesso, ma che possa essere utilizzata per un confronto diretto con esso. Di seguito descriveremo come raccogliamo la verità principale da Facebook e la utilizziamo per addestrare il nostro sistema di classificazione.
Raccolta di dati affidabili
Accumuliamo dati affidabili da ciascuna delle fonti elencate di seguito, in una propria tabella. Ogni tabella è responsabile dell'aggregazione degli ultimi valori osservabili da questa specifica fonte. Ogni fonte ha un controllo della qualità dei dati per garantire che i valori osservati per ciascuna fonte siano di alta qualità e contengano le ultime etichette dei tipi di dati.
- Configurazioni della piattaforma di logging: alcuni campi nelle tabelle dei cluster vengono riempiti con dati relativi a un tipo specifico. L'uso e la diffusione di questi dati servono come fonte affidabile di dati verificabili.
- Marcatura manuale: i programmatori che supportano il sistema, così come i marcatori esterni, sono formati per etichettare le colonne. Questo di solito funziona bene per tutti i tipi di dati nel magazzino e può essere una fonte principale di affidabilità per alcuni dati non strutturati, come i dati dei messaggi o i contenuti generati dagli utenti.
- Le colonne delle tabelle principali possono essere contrassegnate o annotate come contenenti specifici dati e possiamo tracciare questi dati nelle tabelle sottostanti.
- Campionamento dei flussi di esecuzione: i flussi di esecuzione su Facebook portano dati di un certo tipo. Utilizzando il nostro scanner come architettura dei servizi, possiamo campionare i flussi che hanno tipi di dati noti e inviarli attraverso il sistema. Il sistema promette di non memorizzare questi dati.
- Tabelle di campionamento: grandi tabelle alveare, note per contenere l'intero corpus di dati, possono anche essere utilizzate come dati di addestramento e trasferite tramite scanner come servizio. Questo è particolarmente utile per tabelle con un ampio insieme di tipi di dati, quindi il campionamento casuale di una colonna equivale al campionamento dell'intero insieme di quel tipo di dati.
- Dati sintetici: possiamo persino utilizzare librerie che generano dati al volo. Questo funziona bene per tipi di dati semplici e pubblicamente accessibili, come indirizzi o GPS.
- Steward dei dati: i programmi di privacy tipicamente utilizzano steward dei dati per assegnare manualmente le politiche a parti dei dati. Questo serve come fonte ad alta precisione di affidabilità.
Combiniamo ogni fonte principale di dati affidabili in un unico repository con tutte queste informazioni. La maggiore sfida per l'affidabilità è garantire che sia rappresentativa del data warehouse. In caso contrario, i motori di classificazione possono sovradattarsi. Per affrontare questa problematica, tutte le fonti sopra elencate vengono utilizzate per garantire un bilanciamento nell'addestramento dei modelli o nel calcolo delle metriche. Inoltre, i marcatori umani selezionano equamente diverse colonne nel magazzino e contrassegnano i dati di conseguenza, in modo che la raccolta di valori affidabili rimanga imparziale.
Integrazione continua
Per garantire un'iterazione e un miglioramento rapidi, è importante misurare continuamente le prestazioni del sistema in tempo reale. Possiamo misurare ogni miglioramento della classificazione rispetto al sistema di oggi, così da poter orientare tatticamente i dati per futuri miglioramenti. Qui esamineremo come il sistema completa il ciclo di feedback, garantito da dati affidabili.
Quando il sistema di pianificazione incontra un'attività con un'etichetta proveniente da una fonte affidabile, pianifichiamo due compiti. Il primo utilizza il nostro scanner di produzione e, quindi, le nostre capacità di produzione. Il secondo compito utilizza lo scanner dell'ultima versione con le caratteristiche più aggiornate. Ogni compito scrive la propria uscita in una tabella dedicata, etichettando le versioni insieme ai risultati della classificazione.
In questo modo confrontiamo i risultati della classificazione del candidato alla release e del modello di produzione in tempo reale.
Mentre i set di dati confrontano le caratteristiche RC e PROD, vengono registrate molte variazioni del motore di classificazione ML del servizio di previsione. L'ultima versione del modello di machine learning, il modello attualmente in produzione e qualsiasi modello sperimentale. Lo stesso approccio ci consente di "tagliare" diverse versioni del modello (agnostico dei nostri classificatori delle regole) e confrontare le metriche in tempo reale. È così facile determinare quando un esperimento con ML è pronto per essere implementato in produzione.
Ogni notte, i segni RC calcolati per quel giorno vengono inviati al pipeline di formazione ML, dove il modello viene addestrato sugli ultimi segni RC e valuta le proprie prestazioni rispetto a un set di dati affidabile.
Ogni mattina, il modello completa l'addestramento e viene automaticamente pubblicato come sperimentale. Viene automaticamente inserito nell'elenco degli esperimenti.
Alcuni risultati
Vengono etichettati oltre 100 diversi tipi di dati con alta precisione. Tipi ben strutturati, come email e numeri di telefono, vengono classificati con punteggi F2 superiori a 0,95. Tipi di dati non strutturati, come contenuto utente e nomi, funzionano molto bene anch'essi, con punteggi F2 superiori a 0,85.
Ogni giorno, un gran numero di colonne di dati stabili e instabili viene classificato in tutti gli archivi. Oltre 500 terabyte vengono scansionati quotidianamente in più di 10 archivi di dati. La copertura della maggior parte di questi archivi supera il 98%.
Nel tempo, la classificazione è diventata molto efficace, poiché i compiti di classificazione nel flusso autonomo salvato richiedono in media 35 secondi dallo scanning dell'attivo fino al calcolo delle previsioni per ciascuna colonna.
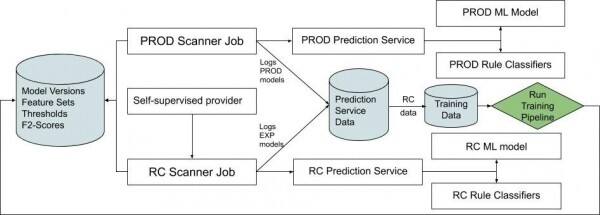
Fig. 2. Diagramma che descrive il flusso continuo di integrazione, per comprendere come gli oggetti RC vengano generati e inviati al modello.
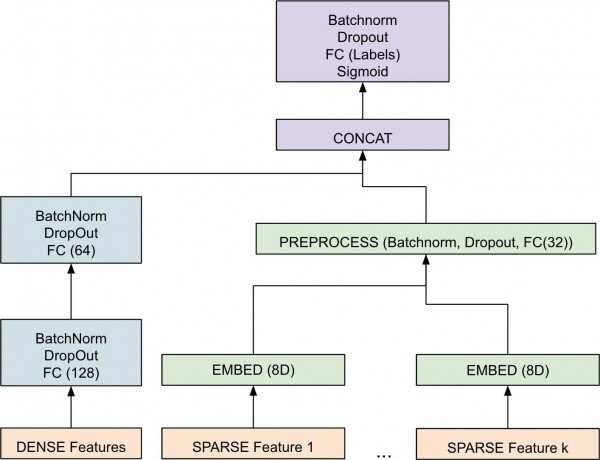
Figura 3. Diagramma ad alto livello del componente di machine learning.
Componente del sistema di machine learning
Nel capitolo precedente abbiamo approfondito l'architettura dell'intero sistema, evidenziando scala, ottimizzazione e flussi di dati in modalità autonoma e online. In questo capitolo esamineremo il servizio di previsione e descriveremo il sistema di machine learning che consente il funzionamento del servizio di previsione.
Con oltre 100 tipi di dati e alcuni contenuti non strutturati, come dati di messaggi e contenuti degli utenti, l'uso esclusivo di euristiche manuali porta a una precisione di classificazione sottoparametrica, specialmente per i dati non strutturati. Per questo motivo, abbiamo anche sviluppato un sistema di apprendimento automatico per affrontare le complessità dei dati non strutturati. L'uso dell'apprendimento automatico consente di iniziare a distaccarsi dall'euristica manuale e di lavorare con caratteristiche e segnali aggiuntivi dei dati (ad esempio, nomi delle colonne, origine dei dati) per migliorare la precisione.
Il modello realizzato esamina le rappresentazioni vettoriali [3] di oggetti densi e sparsi separatamente. Successivamente, vengono uniti per formare un vettore che passa attraverso una serie di fasi di normalizzazione del batch [4] e di non linearità per ottenere il risultato finale. Il risultato finale è un numero a virgola mobile compreso tra [0-1] per ciascuna etichetta, che indica la probabilità che un esempio appartenga a un dato tipo di sensibilità. L'uso di PyTorch per il modello ci ha permesso di muoverci più rapidamente, consentendo ai programmatori al di fuori del team di apportare e testare rapidamente modifiche.
Nella progettazione dell'architettura, era importante modellare separatamente oggetti sparsi (ad esempio, testuali) e densi (ad esempio, numerici) a causa delle loro differenze intrinseche. Per l'architettura finale, era altresì importante svolgere l'ottimizzazione dei parametri, per trovare il valore ottimale della velocità di apprendimento, della dimensione del batch e di altri iperparametri. La scelta dell'ottimizzatore era anch'essa un importante iperparametro. Abbiamo scoperto che l'ottimizzatore popolare Adamporta spesso a overfitting, mentre il modello con SGD più stabile. C'erano ulteriori aspetti che dovevamo integrare direttamente nel modello. Ad esempio, regole statiche che garantivano che il modello producesse una previsione deterministica quando una caratteristica aveva un valore specifico. Queste regole statiche sono definite dai nostri clienti. Abbiamo scoperto che integrare direttamente queste regole nel modello ha portato alla creazione di un'architettura più autonoma e affidabile, anziché implementare una fase di post-elaborazione per gestire questi casi limite speciali. Si prega di notare che durante l'addestramento queste regole sono disattivate per non interferire con il processo di addestramento del gradiente discendente.
Problemi
Una delle problematiche è stata la raccolta di dati affidabili di alta qualità. Il modello ha bisogno di affidabilità per ogni categoria, in modo da apprendere le associazioni tra oggetti ed etichette. Nel capitolo precedente abbiamo discusso i metodi di raccolta dati sia per la misurazione del sistema che per l'apprendimento dei modelli. L'analisi ha evidenziato che categorie di dati come i numeri delle carte di credito e dei conti bancari non sono molto diffuse nel nostro archivio. Questo rende difficile la raccolta di grandi volumi di dati affidabili per l'addestramento dei modelli. Per affrontare questo problema, abbiamo sviluppato processi di ottenimento di dati sintetici affidabili per queste categorie. Generiamo tali dati per tipi sensibili, inclusi SSN, numeri delle carte di credito e IBAN- numeri per i quali il modello non era in grado di fare previsioni precedentemente. Questo approccio consente di gestire tipologie di dati riservati senza il rischio di violare la riservatezza associata alla conservazione di dati riservati reali.
Oltre ai problemi di affidabilità dei dati, ci sono problemi architettonici aperti su cui stiamo lavorando, come l'isolamento delle modifiche e la fermata anticipata. L'isolamento delle modifiche è fondamentale per garantire che le modifiche apportate in diverse parti della rete siano isolate da classi specifiche e non influenzino negativamente le prestazioni complessive della previsione. Migliorare i criteri di early stopping è altrettanto cruciale per permetterci di interrompere il processo di training a un punto stabile per tutte le classi, piuttosto che in un punto in cui alcune classi sono sovradotate e altre no.
L'importanza della caratteristica
Quando una nuova caratteristica viene introdotta nel modello, vogliamo comprendere il suo impatto complessivo sul modello. Vogliamo anche assicurarci che le previsioni siano interpretabili dagli esseri umani, in modo da comprendere esattamente quali caratteristiche vengono utilizzate per ciascun tipo di dati. A tal fine, abbiamo sviluppato e implementato per classe L'importanza delle caratteristiche per il modello PyTorch. Si noti che questo differisce dall'importanza generale della caratteristica, che di solito è supportata, perché non ci dice quali caratteristiche sono importanti per una classe specifica. Misuriamo l'importanza di un oggetto calcolando l'incremento dell'errore di previsione dopo la rimescolatura dell'oggetto. Una caratteristica è "importante" quando la rimescolatura dei valori aumenta l'errore del modello, poiché in questo caso il modello si è basato sulla caratteristica nella previsione. Una caratteristica è "non importante" quando la rimescolatura dei suoi valori lascia invariato l'errore del modello, poiché in questo caso il modello l'ha ignorata [5].
L'importanza della caratteristica per ogni classe rende il modello interpretabile, in modo che possiamo vedere a cosa presta attenzione il modello durante la previsione dell'etichetta. Ad esempio, quando analizziamo ADDR, garantiamo che la caratteristica relativa all'indirizzo, come AddressLinesCount, si posizioni in alto nella tabella di importanza delle caratteristiche per ogni classe, affinché la nostra intuizione umana si accordi bene con ciò che ha appreso il modello.
Valutazione
È importante definire un'unica metrica di successo. Abbiamo scelto F2 — equilibrio tra richiamo e precisione (il richiamo è leggermente più importante). Il richiamo è più cruciale per gli utilizzi legati alla privacy rispetto alla precisione, poiché per il team è fondamentale non mancare alcun dato sensibile (garantendo nel contempo una precisione ragionevole). I dati effettivi sulle prestazioni F2 del nostro modello vanno oltre il presente articolo. Tuttavia, con un'accurata ottimizzazione, possiamo raggiungere un punteggio elevato (0,9+) F2 per le classi sensibili più importanti.
Lavoro correlato
Esistono numerosi algoritmi per la classificazione automatica di documenti non strutturati che utilizzano vari metodi, come il pattern matching, il confronto di similarità di documenti e vari metodi di machine learning (bayesiani, alberi decisionali, k-nearest neighbors e molti altri) [6]. Qualsiasi di essi può essere utilizzato come parte della classificazione. Tuttavia, il problema riguarda la scalabilità. L'approccio alla classificazione in questo articolo è orientato verso flessibilità e prestazioni. Questo ci consente di supportare nuove classi in futuro e mantenere una bassa latenza.
Esistono anche numerosi studi sulla generazione di impronte dai dati. Ad esempio, gli autori in [7] hanno descritto una soluzione che si concentra sul problema della cattura delle fughe di dati sensibili. L'ipotesi di base è che sia possibile generare impronte dai dati per associarle a un insieme di dati sensibili noti. Gli autori in [8] descrivono un problema simile di fuga della privacy, ma la loro soluzione si basa su un'architettura Android specifica e viene classificata solo quando le azioni dell'utente hanno portato all'invio di informazioni personali o se nel'applicazione di base c'è stata una fuga di dati. La situazione qui è leggermente diversa, poiché i dati degli utenti possono anche essere fortemente non strutturati. Pertanto, abbiamo bisogno di una tecnica più complessa rispetto alla generazione di impronte.
Infine, per affrontare la carenza di dati per alcuni tipi di dati sensibili, abbiamo introdotto dati sintetici. Esiste una vasta letteratura sull'aumento dei dati; ad esempio, gli autori in [9] hanno esaminato il ruolo dell'iniezione di rumore durante l'apprendimento e hanno osservato risultati positivi nell'apprendimento controllato. Il nostro approccio alla privacy è diverso, perché l'introduzione di dati rumorosi può essere controproducente, e ci concentriamo invece su dati sintetici di alta qualità.
Conclusione
In questo articolo, abbiamo presentato un sistema in grado di classificare un frammento di dati. Questo ci consente di creare sistemi per garantire il rispetto delle politiche di privacy e di sicurezza. Abbiamo dimostrato che un'infrastruttura scalabile, integrazione continua, machine learning e dati di alta qualità sulla veridicità delle informazioni giocano un ruolo chiave nel successo di molte delle nostre iniziative relative alla privacy.
Ci sono molte direzioni per lavori futuri. Questi possono includere fornire supporto per dati non strutturati (file), classificare non solo il tipo di dati ma anche il livello di sensibilità, e utilizzare l'apprendimento auto-supervisionato direttamente durante l'allenamento generando esempi sintetici accurati. Questi, a loro volta, aiuteranno il modello a ridurre le perdite al livello massimo. I lavori futuri possono anche concentrarsi sui flussi di lavoro investigativi, dove andiamo oltre la semplice rilevazione fornendo un'analisi delle cause profonde di varie violazioni della privacy. Questo sarà utile in casi come l'analisi della sensibilità (cioè se la sensibilità della privacy del tipo di dati è alta (ad esempio, l'indirizzo IP dell'utente) o bassa (ad esempio, l'indirizzo IP interno di Facebook)).
Bibliografia
- David Ben-David, Tamar Domany e Abigail Tarem. Classificazione dei dati enterprise utilizzando tecnologie del semantic web. In Peter F. Patel-Schneider, Yue Pan, Pascal Hitzler, Peter Mika, Lei Zhang, Jeff Z. Pan, Ian Horrocks e Birte Glimm, redattori, Il Semantic Web – ISWC 2010, pagine 66–81, Berlino, Heidelberg, 2010. Springer Berlin Heidelberg.
- Subramanian Muralidhar, Wyatt Lloyd, Sabyasachi Roy, Cory Hill, Ernest Lin, Weiwen Liu, Satadru Pan, Shiva Shankar, Viswanath Sivakumar, Linpeng Tang e Sanjeev Kumar. f4: Il sistema di storage BLOB caldo di Facebook. In 11° Simposio USENIX sulla progettazione e implementazione dei sistemi operativi (OSDI 14), pagine 383–398, Broomfield, CO, ottobre 2014. USENIX Association.
- Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado e Jeff Dean. Rappresentazioni distribuite di parole e frasi e la loro composizionalità. In C. J. C. Burges, L. Bottou, M. Welling, Z. Ghahramani e K. Q. Weinberger, redattori, Advances in Neural Information Processing Systems 26, pagine 3111–3119. Curran Associates, Inc., 2013.
- Sergey Ioffe e Christian Szegedy. Normalizzazione batch: Accelerazione dell'addestramento di reti neurali profonde riducendo lo shift interno delle covariate. In Francis Bach e David Blei, redattori, Atti della 32ª Conferenza Internazionale sull'Apprendimento Automatico, volume 37 di Atti della Ricerca sull'Apprendimento Automatico, pagine 448–456, Lille, Francia, 07–09 luglio 2015. PMLR.
- Leo Breiman. Foreste casuali. Mach. Appr., 45(1):5–32, ottobre 2001.
- Thair Nu Phyu. Rassegna delle tecniche di classificazione nel data mining.
- X. Shu, D. Yao e E. Bertino. Rilevamento a preservazione della privacy dell'esposizione di dati sensibili. IEEE Transactions on Information Forensics and Security, 10(5):1092–1103, 2015.
- Zhemin Yang, Min Yang, Yuan Zhang, Guofei Gu, Peng Ning e Xiaoyang Wang. Appintent: Analisi della trasmissione di dati sensibili in Android per la rilevazione di perdite di privacy. pagine 1043–1054, 11 2013.
- Qizhe Xie, Zihang Dai, Eduard H. Hovy, Minh-Thang Luong e Quoc V. Le. Aumento dei dati non supervisionato.
Scopri di più su come ottenere una professione richiesta da zero o migliorare le tue abilità e il tuo stipendio, seguendo i corsi online di SkillFactory:
- (12 mesi)
- (12 settimane)
- (20 settimane)
- (20 settimane)
Altri corsi
- (9 mesi)
- (8 mesi)
- (9 mesi)
- (12 mesi)
- (18 mesi)
- (12 mesi)
- (9 mesi)
- (7 mesi)

Fonte: habr.com
