

Il rapporto presenta alcuni approcci che permettono di monitorare le prestazioni delle query SQL, quando queste sono milioni al giorno, e i server PostgreSQL controllati sono centinaia.
Quali soluzioni tecniche ci permettono di gestire efficacemente tale volume di informazioni e come questo facilita la vita ai normali sviluppatori.

A chi può interessare l'analisi di problemi specifici e diverse tecniche di ottimizzazione delle query SQL e delle soluzioni a compiti tipici di DBA in PostgreSQL — si può anche su questo argomento.
Mi chiamo Kirill Borovikov, rappresento . In particolare, mi specializzo nel lavoro con i database nella nostra azienda.
Oggi vi parlerò di come ci occupiamo dell'ottimizzazione delle query quando non è necessario 'scavare' la prestazione di una singola query, ma risolvere il problema in modo massiccio. Quando le query sono milioni e bisogna trovare alcuni approcci alla soluzione di questo grande problema.
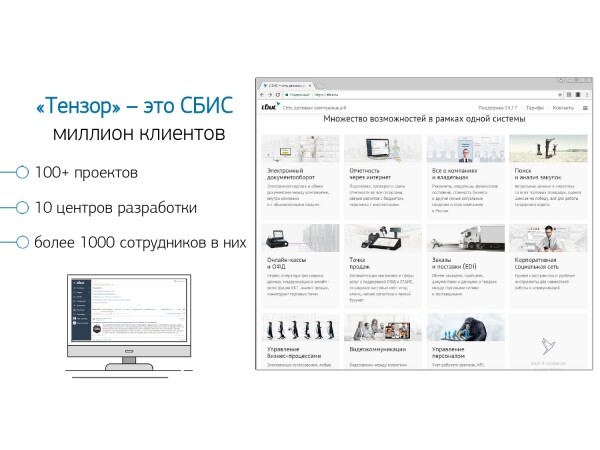
In generale, 'Tensor' per un milione dei nostri clienti è : social network aziendale, soluzioni per videoconferenze, per la gestione documentale interna ed esterna, sistemi di contabilità e magazzino,… Ovvero un 'megacomposto' per la gestione complessiva del business, che comprende più di 100 progetti interni diversi.
Affinché tutto ciò funzioni correttamente e si sviluppi — abbiamo 10 centri di sviluppo in tutto il paese, con più di 1000 sviluppatori.
Lavoriamo con PostgreSQL dal 2008 e abbiamo accumulato un grande volume di dati che gestiamo — dati dei clienti, statistiche, analisi, dati da sistemi informativi esterni — oltre 400TB.Solo 'in produzione' ci sono circa 250 server, e in totale i server DB che monitoriamo sono circa 1000.

SQL è un linguaggio dichiarativo. Descrivete non 'come' qualcosa deve funzionare, ma 'cosa' volete ottenere. Il DBMS sa meglio come fare un JOIN — come unire le vostre tabelle, quali condizioni applicare, cosa passerà per l'indice e cosa no…
Alcuni DBMS accettano suggerimenti: 'No, unisci queste due tabelle in questo ordine', ma PostgreSQL non lo fa. Questa è una posizione consapevole dei principali sviluppatori: 'Meglio che miglioriamo l'ottimizzatore di query, piuttosto che permettere agli sviluppatori di usare qualche hint.'
Ma, nonostante PostgreSQL non consenta di 'gestirlo dall'esterno', permette ottimamente di vedere cosa succede 'internamente', quando eseguite la vostra query, e dove sorgono i problemi.

In generale, quali problemi classici si presenta di solito a un DBA? 'Abbiamo eseguito una query, e tutto è lento, tutto è bloccato, qualcosa sta succedendo… È un vero disastro!'Le cause sono quasi sempre le stesse:
algoritmo di query inefficace
- Sviluppatore: 'Ora ho 10 tabelle in SQL tramite JOIN…' — e si aspetta che le sue condizioni in modo miracoloso 'si sciolgano' in modo efficiente e che ottenga tutto rapidamente. Ma non ci sono miracoli, e qualsiasi sistema, data la tale variabilità (10 tabelle in un solo FROM), dà sempre una certa imprecisione. [
Sviluppatore: «Adesso in SQL ho 10 tabelle tramite JOIN...» e si aspetta che le sue condizioni si 'sbrogliino' magicamente, ottenendo tutto rapidamente. Ma non ci sono magie, e qualsiasi sistema, con una tale variabilità (10 tabelle in un unico FROM), presenterà sempre un certo margine d'errore. [] - statistiche obsolete
Il problema è particolarmente rilevante per PostgreSQL, quando caricate un grande set di dati sul server, fate una query — e lui sta 'scansionando' una tabella. Perché ieri c'erano 10 record, e oggi 10 milioni, ma PostgreSQL non ne è ancora a conoscenza, e bisogna farglielo sapere. [] - strozzature delle risorse
Avete messo un grande e pesante database carico su un server debole, che non ha abbastanza disco, memoria, prestazioni della CPU. E basta… C'è sempre un limite nelle prestazioni, oltre il quale non potete andare. - blocco
Un momento complicato, ma è più rilevante per le query modificanti (INSERT, UPDATE, DELETE) — è un tema ampio.
Ottimizzare il piano
… E per il resto abbiamo bisogno di un piano! Abbiamo bisogno di vedere cosa succede dentro il server.

Il piano di esecuzione della query per PostgreSQL è un albero dell'algoritmo di esecuzione della query in forma testuale. È proprio quell'algoritmo che a seguito dell'analisi da parte del pianificatore è stato riconosciuto come il più efficiente.
Ogni nodo dell'albero è un'operazione: estrazione dei dati da una tabella o indice, costruzione di una bitmap, unione di due tabelle, combinazione, intersezione o esclusione di campioni. L'esecuzione della query implica il passaggio attraverso i nodi di questo albero.
Per ottenere il piano della query, il modo più semplice è eseguire l'operatore EXPLAIN.Per ottenerlo con tutti gli attributi reali, cioè per eseguire effettivamente la query sul database — EXPLAIN (ANALYZE, BUFFERS) SELECT ....
Momento negativo: quando lo esegui, accade 'qui e ora', quindi è adatto solo per il debug locale. Se invece prendi un server ad alta intensità di carico, che sta subendo un forte flusso di modifiche ai dati, e vedi: 'Oh! Qui abbiamo una richiesta lenta.è una richiesta.' Mezz'ora, un'ora fa — mentre cercavi di estrarre questa richiesta dai log e riportarla di nuovo sul server, l'intero dataset e le statistiche sono cambiate. La esegui per il debug — e viene eseguita velocemente! E non riesci a capire 'perché', perché stato è lenta.

Per capire cosa stava accadendo proprio in quel momento in cui la richiesta viene eseguita sul server, persone intelligenti hanno scritto . È presente praticamente in tutte le distribuzioni più comuni di PostgreSQL e può essere semplicemente attivato nel file di configurazione.
Se rileva che una richiesta impiega più tempo del limite che gli hai impostato, fa 'uno scatto' del piano di quella richiesta e lo scrive insieme nel log.

Sembra che tutto sia a posto, andiamo nel log e vediamo… [una grande quantità di testo]. Ma non possiamo dire nulla su di esso, oltre al fatto che è un ottimo piano, perché è stato eseguito in 11ms.
Sembra che tutto vada bene — ma non capiamo nulla su cosa sia realmente accaduto. Oltre al tempo totale, non vediamo nulla di particolare. Perché guardare una 'latuga' di testo semplice è davvero poco intuitivo.
Ma anche se non è intuitivo, ci sono problemi più gravi:
- Nel nodo viene indicata la somma delle risorse dell'intero sottoalbero sotto di esso. Cioè, non è possibile sapere quanto tempo è stato speso esattamente in questo Index Scan — se ci sono condizioni annidate sotto di esso. Dobbiamo controllare dinamicamente se ci sono 'figli' e variabili condizionali, CTE — e sottrarre tutto questo 'mentalmente'.
- Un secondo punto: il tempo indicato nel nodo è il tempo di esecuzione singola del nodo.Se questo nodo è stato eseguito a seguito, ad esempio, di un ciclo su record della tabella, più volte, il piano aumenta il numero di loops — cicli di quel nodo. Ma il tempo di esecuzione atomica rimane invariato nel piano. Quindi, per capire quanto è stato eseguito complessivamente, devi moltiplicare uno per l'altro — di nuovo 'mentalmente'.
Con queste condizioni, capire 'Chi è il punto più debole?' è praticamente impossibile. Pertanto, anche gli stessi sviluppatori scrivono nel 'manuale' che 'Comprendere il piano è un'arte che si deve imparare, esperienza...'.
Ma abbiamo 1000 sviluppatori, e non puoi trasferire quell'esperienza a ciascuno di loro. Io, tu, lui — lo sanno, ma qualcun altro lì — già no. Forse imparerà, forse no, ma deve già lavorare — da dove prendere quell'esperienza.
Visualizzazione del piano
Quindi abbiamo capito — per affrontare questi problemi, abbiamo bisogno di una buona visualizzazione del piano.
Siamo andati a cercare 'nel mercato' — vediamo cosa esiste realmente su internet.
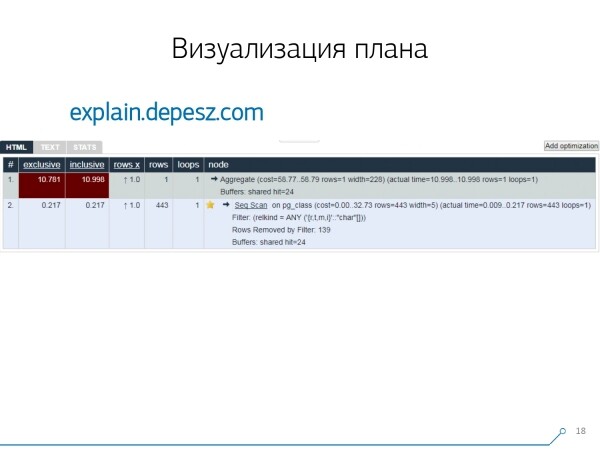
Ma, ci siamo resi conto che le soluzioni 'vive', che si sviluppano più o meno, sono davvero poche — praticamente una: di Hubert Lubaczewski. In input nel campo 'inserisci' una rappresentazione testuale del piano, ti mostra una tabella con i dati analizzati:
- il tempo di esecuzione del nodo
- il tempo totale dell'intero sottoalbero
- il numero di registrazioni estratte e quelle attese statisticamente
- il corpo stesso del nodo
Inoltre, questo servizio ha la possibilità di condividere un archivio di link. Hai inserito lì il tuo piano e dici: 'Ehi, Vasya, ecco il link, qualcosa non va'.

Ma ci sono anche alcuni piccoli problemi.
Prima di tutto, una grande quantità di 'copiaincolla'. Prendi un pezzo di log, lo inserisci lì, di nuovo, e di nuovo.
In secondo luogo, non c'è analisi della quantità di dati letti — quei buffer che vengono fuori EXPLAIN (ANALYZE, BUFFERS), qui non lo vediamo. Semplicemente non sa analizzarli, capirli e lavorarci. Quando leggi molti dati e capisci che potresti non organizzarti correttamente su disco e nella cache di memoria, queste informazioni sono molto importanti.
Un terzo punto negativo — lo sviluppo molto debole di questo progetto. I commit sono molto piccoli, bene se uno ogni sei mesi, e il codice è in Perl.
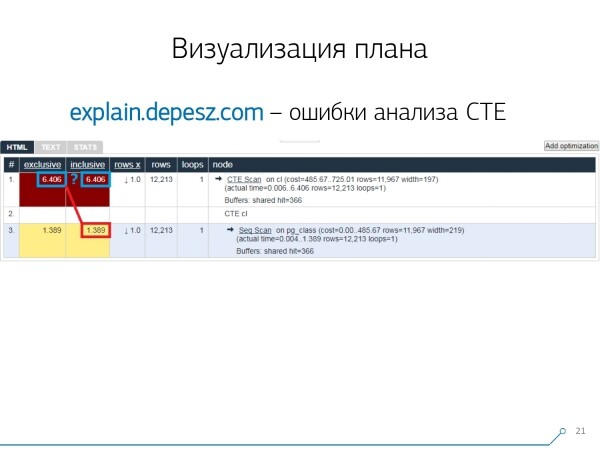
Ma queste sono tutte 'questioni liriche', si potrebbe in qualche modo vivere con questo, ma c'è una cosa che ci ha allontanato fortemente da questo servizio. Sono gli errori nell'analisi delle Common Table Expression (CTE) e di diversi nodi dinamici come InitPlan/SubPlan.
Se crediamo a questa immagine, il tempo totale di esecuzione di ciascun nodo individuale è maggiore del tempo totale di esecuzione dell'intera richiesta. È semplice — non è stato sottratto dal nodo CTE Scan il tempo di generazione di questo CTE.Quindi non sappiamo già qual è la risposta corretta, quanto tempo ha richiesto realmente la scansione CTE.

Qui abbiamo capito che era ora di scrivere il nostro — evviva! Ogni sviluppatore dice: «Adesso scriviamo qualcosa di nostro, sarà super facile!»
Abbiamo preso un stack tipico per i servizi web: core su Node.js + Express, abbiamo applicato Bootstrap e per belle diagrammi — D3.js. E le nostre aspettative sono state ampiamente soddisfatte — abbiamo ottenuto il primo prototipo in 2 settimane:
- il nostro parser del piano
Cioè, ora possiamo analizzare qualsiasi piano generato da PostgreSQL. - analisi corretta dei nodi dinamici — CTE Scan, InitPlan, SubPlan
- analisi della distribuzione dei buffers — dove le pagine dei dati vengono lette dalla memoria, dove dal cache locale, dove dal disco
- abbiamo ottenuto visibilità
Per non dover cercare tutto questo nel log, ma vedere immediatamente il «collo di bottiglia» direttamente nell'immagine.
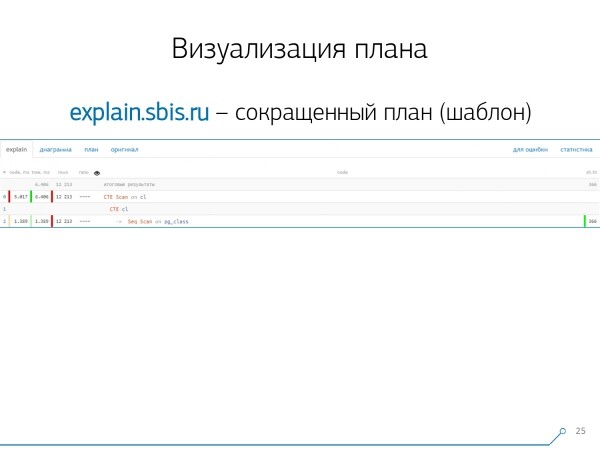
Abbiamo ottenuto un'immagine del genere — subito con la sintassi evidenziata. Ma di solito i nostri sviluppatori lavorano già non con l'intero schema, ma con qualcosa di più breve. Dopotutto, tutti noi abbiamo già analizzato i numeri e li abbiamo messi da parte, lasciando nel mezzo solo la prima riga, che indicava che nodo era: CTE Scan, generazione CTE o Seq Scan su qualche tabella.
Questa rappresentazione ridotta la chiamiamo modello di piano.
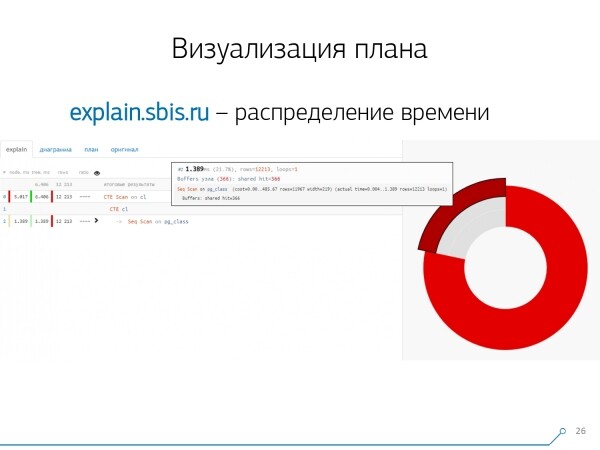
Cosa sarebbe utile avere? Sarebbe utile vedere qual è la percentuale di tempo totale spesa su ogni nodo — e l'abbiamo «incollato» di lato grafico a torta.
Passando il mouse sopra un nodo, scopriamo — in realtà il Seq Scan ha preso meno di un quarto del tempo totale, mentre il CTE Scan ha occupato i restanti 3/4. Terribile! Questo piccolo commento riguarda la «velocità» di CTE Scan, se li usate attivamente nelle vostre query. Non sono molto veloci — perdono anche contro una semplice scansione tabellare.
Ma di solito quei grafici sono più interessanti e complessi, quando passiamo il mouse sopra un segmento e vediamo, per esempio, che più della metà del tempo è stata «mangiata» da un Seq Scan. E c'era anche un Filter all'interno, molti record sono stati scartati da esso… Possiamo prendere questa immagine e mostrarla agli sviluppatori dicendo: «Vanya, qui hai problemi! Analizza, guarda — qualcosa non va!»

Naturalmente, non siamo stati esenti da «tranelli».
La prima cosa su cui «siamo inciampati» è stata il problema dell'arrotondamento. Il tempo di ciascun nodo nel piano è indicato con precisione di 1 microsecondo. E quando il numero di cicli di un nodo supera, per esempio, 1000 — dopo l'esecuzione PostgreSQL ha diviso «con precisione», quindi nel calcolo inverso otteniamo un tempo totale «tra 0.95ms e 1.05ms». Quando si parla di microsecondi, non è un problema, ma quando già si parla di [millisecondi] — durante l'«analisi» delle risorse nei nodi del piano «chi ha consumato cosa», questa informazione deve essere considerata.

Il secondo punto, più complesso, è la distribuzione delle risorse (quei buffers) sui nodi dinamici. Ci sono volute altre 4 settimane ai nostri primi 2 prototipi.
È abbastanza semplice ottenere un problema del genere — facciamo un CTE e qualcosa che sembra leggere. In realtà, PostgreSQL è «intelligente» e non leggerà nulla direttamente lì. Poi prendiamo il primo record da esso e con esso — il centesimo dallo stesso CTE.
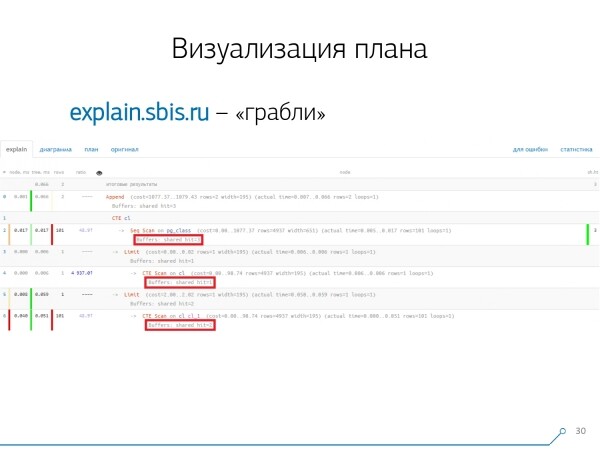
Guardiamo il piano e capiamo — strano, abbiamo 3 buffers (pagine di dati) «consumati» nel Seq Scan, 1 nel CTE Scan, e 2 nel secondo CTE Scan. Quindi, se sommiamo tutto, otteniamo 6, ma in realtà abbiamo letto solo 3 dalla tabella! CTE Scan non legge nulla da nessuna parte, ma lavora direttamente con la memoria del processo. Quindi qui chiaramente qualcosa non va!
In realtà, risulta che tutte e 3 le pagine di dati richieste dal Seq Scan sono state prima richieste dal primo CTE Scan, e poi dal secondo, e a lui sono state lette ulteriori 2. In totale, sono state lette 3 pagine di dati, non 6.
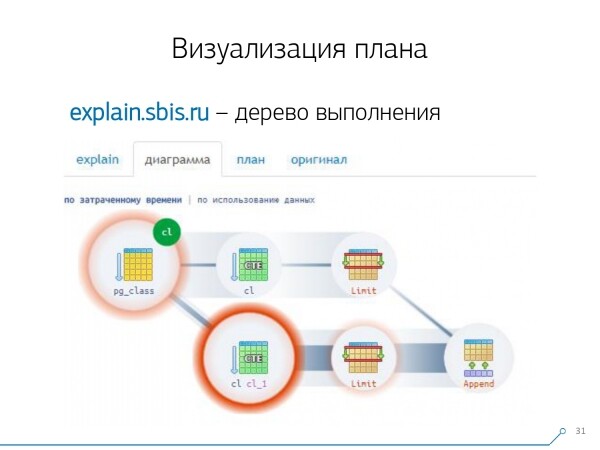
E questa immagine ci ha portato a comprendere che l'esecuzione del piano non è più un albero, ma un grafo aciclico. E abbiamo ottenuto un diagramma simile per capire «da dove arriva cosa». Cioè, qui abbiamo creato un CTE di pg_class, e l'abbiamo richiesto due volte, e praticamente tutto il nostro tempo è andato nella seconda richiesta. È chiaro che leggere la 101ª riga è molto più costoso che semplicemente leggere la prima dalla tabella.

Per un momento abbiamo tirato un sospiro di sollievo. Abbiamo detto: «Ora, Neo, sai il kung fu! Ora la nostra esperienza è proprio sul tuo schermo. Ora puoi utilizzarla.»
Consolidamento dei log
I nostri 1000 sviluppatori hanno tirato un sospiro di sollievo. Ma noi capivamo che avevamo solo un centinaio di server «operativi», e tutto questo «copia e incolla» da parte degli sviluppatori non era affatto conveniente. Abbiamo capito che dovevamo raccoglierlo noi.

In effetti, c'è un modulo di sistema che raccoglie le statistiche, ma deve essere attivato nel config — è il . Ma non ci ha soddisfatti.
In primo luogo, assegna a richieste identiche in schemi diversi all'interno della stessa base diversi QueryId. Quindi, se inizialmente eseguiamo SET search_path = '01'; SELECT * FROM user LIMIT 1;, e poi SET search_path = '02'; e facciamo la stessa richiesta, nella statistica di questo modulo ci saranno registrazioni diverse, e non riuscirò a raccogliere statistiche complessive precisamente in base a questo profilo di richiesta, senza considerare gli schemi.
Il secondo aspetto che ci ha ostacolato nell'utilizzarlo è l'assenza di piani. Cioè, non c'è un piano, c'è solo la richiesta stessa. Vediamo cosa ha rallentato, ma non comprendiamo perché. E qui torniamo al problema del dataset in rapido cambiamento.
E l'ultimo punto è l'assenza di "fatti". Non è possibile fare riferimento a una specifica istanza dell'esecuzione della richiesta — non esiste, c'è solo statistica aggregata. Anche se ci si può lavorare, è semplicemente molto complicato.
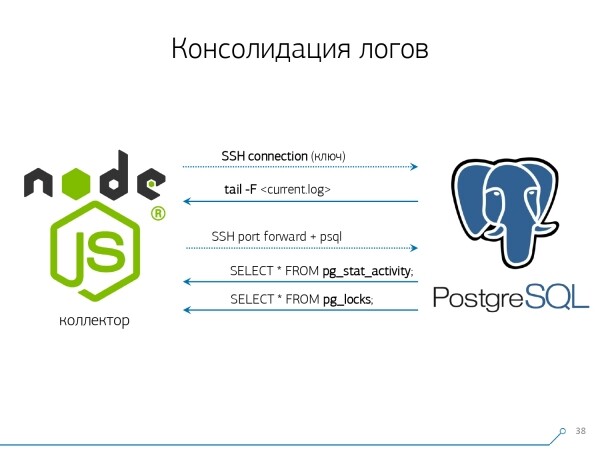
Pertanto, abbiamo deciso di combattere con il "copia e incolla" e abbiamo iniziato a scrivere un collettore.
. Il collettore si collega tramite SSH, stabilisce una connessione sicura con certificato fino al server con la base e tail -F si aggancia a esso per il file di log. In questo modo, in questa sessione otteniamo un "mirror" completo di tutto il file di log, che genera il server. Il carico sul server stesso è minimo, poiché non facciamo altro che rispecchiare il traffico.
Poiché abbiamo già iniziato a scrivere un'interfaccia su Node.js, abbiamo continuato a scrivere anche il collettore su di essa. E questa tecnologia si è dimostrata valida, perché per lavorare con dati testuali poco strutturati, che è ciò che è il log, è molto conveniente utilizzare JavaScript. Inoltre, l'infrastruttura Node.js come piattaforma backend consente di lavorare in modo semplice e comodo con connessioni di rete e, in generale, con flussi di dati.
Di conseguenza, "tiriamo" due connessioni: la prima, per "ascoltare" il log stesso e prelevarlo, e la seconda, per chiedere periodicamente alla base. "Ecco, nel log è arrivato che la tabella con oid 123 è stata bloccata", ma questo non significa nulla per lo sviluppatore, e sarebbe bene chiedere alla base "Che cos'è quindi OID = 123?" E così chiediamo periodicamente alla base ciò che non sappiamo ancora.

"Solo una cosa non hai considerato, ci sono api a forma di elefante!.." Abbiamo iniziato a sviluppare questo sistema quando volevamo monitorare 10 server. I più critici secondo la nostra comprensione, sui quali si verificavano problemi che era difficile risolvere. Ma nel primo trimestre abbiamo ricevuto da monitorare cento — perché il sistema ha "preso piede", tutti lo hanno voluto, a tutti è sembrato comodo.
Tutto questo deve essere raccolto, il flusso di dati è grande e attivo. Proprio ciò che monitoriamo, con cui abbiamo familiarità, è ciò che utilizziamo. Utilizziamo PostgreSQL anche come archivio dati. E non c'è nulla di più veloce per "versare" dati su di esso rispetto a un operatore COPY non ce n'è.
Ma semplicemente "versare" dati non è esattamente la nostra tecnologia. Perché se su cento server ci sono circa 50k richieste al secondo, ciò genera 100-150GB di log al giorno. Pertanto abbiamo dovuto "piallare" con attenzione il database.
In primo luogo, abbiamo fatto partizionamento per giorni, perché, in fin dei conti, a nessuno interessa la correlazione tra i giorni. Qual è la differenza se ieri hai avuto qualcosa, se stanotte hai rilasciato una nuova versione dell'applicazione — e già ci sono nuove statistiche.
In secondo luogo, abbiamo imparato (eravamo costretti a) a scrivere in modo molto, molto veloce COPY. Cioè, non solo COPY, perché è più veloce di INSERT, ma ancora più veloce.

Il terzo punto è che siamo dovuti rinunciare ai trigger, di conseguenza anche ai Foreign Keys. Cioè, non abbiamo affatto integrità referenziale. Perché se hai una tabella su cui ci sono un paio di FK, e dici nella struttura del DB che "questa voce dal log fa riferimento per FK, ad esempio, a un gruppo di voci", quando la inserisci, PostgreSQL non ha di meglio da fare che prendere e onestamente eseguire SELECT 1 FROM master_fk1_table WHERE ... con l'identificatore che stai cercando di inserire — giusto per verificare che quella voce sia presente e che tu non stia "bloccando" il Foreign Key con la tua inserzione.
Otteniamo invece di una voce nella tabella target e i suoi indici, in più letture da tutte le tabelle a cui fa riferimento. E a noi non interessa affatto: il nostro obiettivo è registrare quanti più dati possibile e il più velocemente possibile con il minimo carico. Quindi via i FK!
Il punto successivo è aggregazione e hashing. Inizialmente erano implementati nel DB — perché è comodo, quando arriva una registrazione, fare in qualche tabella "più uno" direttamente nel trigger.. Bene, comodo, ma complicato per lo stesso motivo: si inserisce una registrazione e si è costretti a leggere e registrare qualcos'altro da un'altra tabella. Inoltre, non solo si deve leggere e registrare, ma bisogna farlo ogni volta.
E ora immaginate di avere un foglio di calcolo in cui contate semplicemente il numero di richieste passate attraverso un determinato host: +1, +1, +1, ..., +1. E in realtà, questo non è necessario — tutto questo si può sommare in memoria sul collettore e inviare al database tutto in una volta +10.
Sì, nel caso di malfunzionamenti, l'integrità logica potrebbe "rompersi", ma è un caso praticamente irrealistico — perché avete un server normale, con una batteria nel controller, un log delle transazioni, un log nel file system… Insomma, non ne vale la pena. Non vale la perdita di prestazioni che si ottiene a causa del funzionamento dei trigger / FK, i costi che si sostengono in questo caso.
Lo stesso vale per l'hashing. Arriva una richiesta e calcoli un identificatore nel DB, lo scrivi nel database e poi lo comunichi a tutti. Tutto funziona bene, finché non arriva un secondo tentativo di scrivere lo stesso identificatore — e avrai un blocco, che è già un problema. Quindi, se puoi spostare la generazione di alcuni ID sul client (rispetto al database), è meglio farlo.
A noi è sembrata l'ideale utilizzare MD5 del testo — della richiesta, del piano, del modello,… Lo calcoliamo dal lato del collettore, e "inviamo" nel database già l'ID pronto. La lunghezza di MD5 e la partizione giornaliera ci consentono di non preoccuparci di possibili collisioni.
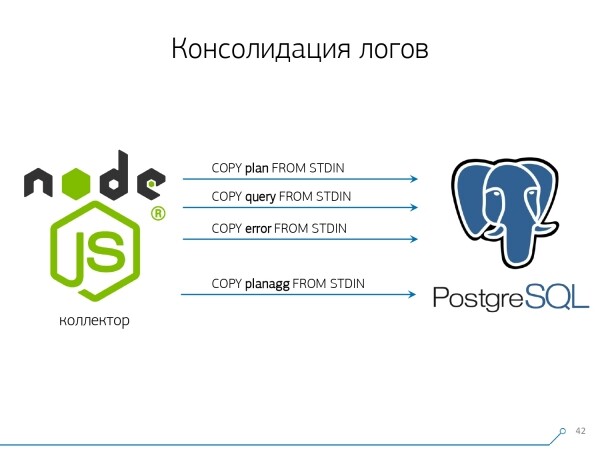
Ma per scrivere tutto questo rapidamente, è stato necessario modificare la procedura di scrittura stessa.
Come vengono solitamente scritti i dati? Abbiamo un dataset, lo suddividiamo in diverse tabelle, e poi COPY — prima nella prima, poi nella seconda, e nella terza… Scomodo, perché stiamo scrivendo un flusso di dati in tre passaggi consecutivi. Sgradevole. Si può fare più velocemente? Certo!
È sufficiente disporre questi flussi in parallelo. Risultato: abbiamo errori, richieste, modelli, blocchi, che vengono gestiti in flussi separati… e scriviamo tutto in parallelo. Per questo è necessario mantenere continuamente aperto un canale COPY per ciascuna tabella di destinazione separata.

Cioè, il collettore ha sempre uno stream , nel quale posso registrare i dati di cui ho bisogno. Ma affinché il database veda questi dati, e che qualcuno non resti bloccato in attesa che vengano scritti,COPY deve essere interrotto con una certa periodicità . Per noi, il periodo più efficiente si è rivelato essere circa 100 ms — chiudiamo e subito riapriamo sulla stessa tabella. E se un flusso non è sufficiente in caso di picchi, facciamo polling fino a un certo limite.In aggiunta, abbiamo scoperto che per questo profilo di carico qualsiasi aggregazione, quando le registrazioni vengono raccolte in pacchetti, è dannosa. Un classico problema è
INSERT ... VALUES seguito da 1000 registrazioni. Perché in quel momento si verifica un picco di scrittura su disco e tutti gli altri, che cercano di scrivere qualcosa su disco, dovranno aspettare. Per eliminare tali anomalie, non aggregare nulla,
non bufferizzare affatto . E se si verifica comunque una bufferizzazione su disco (fortunatamente, lo Stream API in Node.js lo consente), ritardate quella connessione. Solo quando riuscite a ricevere un evento che è di nuovo libero — scrivete da essa nella coda accumulata. E finché è occupata — prendete il successivo disponibile dal pool e scrivete in esso.Prima dell'implementazione di questo approccio alla scrittura dei dati, avevamo circa 4K write ops, mentre con questo metodo abbiamo ridotto il carico di 4 volte. Ora siamo aumentati di altre 6 volte grazie a nuove basi osservabili — fino a 100MB/s. E ora conserviamo i log degli ultimi 3 mesi in un volume di circa 10-15TB, sperando che per tre mesi qualsiasi problema possa essere risolto da qualsiasi sviluppatore.
Comprendiamo i problemi
Ma raccogliere tutti questi dati — è bene, utile, pertinente, ma non basta — devono essere compresi. Perché sono milioni di diversi piani al giorno.
Ma milioni — sono ingestibili, prima di tutto, è necessario ridurre questa mole. E, in primo luogo, è necessario decidere come organizzare questo "di meno".

Abbiamo identificato tre punti chiave:
questa richiesta è stata inviata
- chi Cioè, da quale applicazione 'è giunta': interfaccia web, backend, sistema di pagamento o altro.
questo è accaduto - dove Su quale server specifico. Perché se avete più server sotto una singola applicazione, e improvvisamente uno “esita” (perché il “disco è danneggiato”, “la memoria è perduta”, qualche altro problema), è necessario indirizzarsi esattamente al server.
il problema si manifestava in un determinato piano - ZFS archivia i dati su disco. è proprio qui che si manifesta il problema in un modo o nell'altro
Per capire «chi» ci ha inviato la richiesta, utilizziamo uno strumento standard: impostiamo una variabile di sessione: SET application_name = '{bl-host}:{bl-method}'; — registriamo il nome dell'host della logica di business da cui arriva la richiesta e il nome del metodo o dell'applicazione che l'ha generata.
Dopo aver passato il «proprietario» della richiesta, dobbiamo registrarlo nel log — per questo configuriamo la variabile log_line_prefix = ' %m [%p:%v] [%d] %r %a'. Chi è interessato può , cosa significhi tutto ciò. Risultato: nel log vediamo:
- il tempo
- gli identificatori di processo e transazione
- il nome del database
- l'IP di chi ha inviato questa richiesta
- e il nome del metodo
Poi abbiamo capito che non è molto interessante guardare la correlazione di una singola richiesta tra diversi server. Raramente si verifica una situazione in cui una stessa applicazione fallisce allo stesso modo qui e lì. Ma anche se lo fa — guarda uno qualsiasi di questi server.
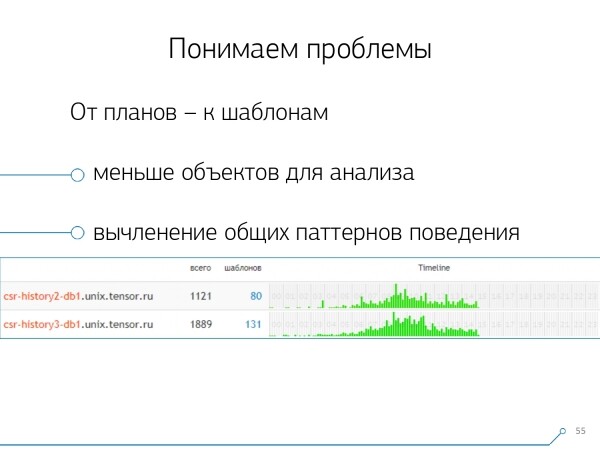
Ecco, il nostro taglio «un server — un giorno» si è rivelato sufficiente per qualsiasi analisi.
Il primo taglio analitico è proprio quel «modello» — una forma ridotta di rappresentazione del piano, depurata da tutti i dati numerici. Il secondo taglio — applicazione o metodo, e il terzo — è il nodo specifico del piano che ci ha causato dei problemi.
Quando siamo passati dagli istanziali specifici ai modelli, abbiamo subito ottenuto due vantaggi:
- una drastica riduzione del numero di oggetti da analizzare
Non dobbiamo più esaminare problemi in base a migliaia di richieste o piani, ma possiamo concentrarci su decine di modelli. - timeline
Cioè, riassumendo i «fatti» all'interno di un dato taglio, possiamo mostrarne l'emergere nel corso della giornata. E qui puoi capire che se un certo modello si presenta, ad esempio, una volta all'ora, mentre dovrebbe apparire una volta al giorno, è il caso di riflettere su cosa sia andato storto — chi e perché lo ha chiamato, forse non dovrebbe nemmeno trovarsi qui. Questa è un'altra modalità di analisi non numerica, puramente visiva.

Le altre modalità si basano sui parametri che estraiamo dal piano: quante volte si è verificato quel modello, il tempo totale e medio, quanti dati sono stati letti dal disco e quanti dalla memoria...
Perché tu, ad esempio, accedi alla pagina di analisi per l'host e noti che c'è un eccesso di letture da disco. Il disco sul server non riesce a gestire — e chi sta leggendo da esso?
E puoi ordinare per qualsiasi colonna e decidere con cosa ti occuperai subito — con il carico della CPU o del disco, o con il numero complessivo di richieste… Hai ordinato, hai visto i «top», hai sistemato — e hai rilasciato una nuova versione dell'applicazione.
E subito puoi vedere diverse applicazioni che effettuano richieste con lo stesso modello di richiesta SELECT * FROM users WHERE login = 'Vasya'. Frontend, backend, processing… E inizi a chiederti, perché il processing dovrebbe leggere l'utente, se non sta interagendo con lui.
Il modo inverso — vedere subito cosa sta facendo l'applicazione. Ad esempio, il frontend — questo, questo, quello, e anche questo una volta all'ora (il timeline aiuta). E subito sorge la domanda — sembra che non sia compito del frontend fare qualcosa una volta all'ora…

Dopo un po' abbiamo capito che ci manca una statistica aggregata nel taglio per nodi del piano. Abbiamo estratto dai piani solo i nodi che fanno qualcosa con i dati delle tabelle stesse (leggono/scrivono tramite indice o meno). In sostanza, rispetto all'immagine precedente, c'è solo un aspetto in più —quante righe questo nodo ci ha fornito , e quante ha scartato (Rows Removed by Filter).Non hai un indice adeguato sulla tabella, fai una richiesta e essa bypassa l'indice, finendo in Seq Scan… tutte le righe, tranne una, sono state filtrate. E perché hai bisogno in un giorno di 100M di righe filtrate, non sarebbe meglio avere un indice?
Analizzando tutti i piani per nodi, abbiamo capito che ci sono alcune strutture tipiche nei piani che hanno un'alta probabilità di apparire sospette. Sarebbe utile suggerire al разработчик: «Amico, qui leggi prima per indice, poi ordini e infine filtri» — di solito, lì c'è una sola riga.

Tutti coloro che hanno scritto richieste con tale pattern, sicuramente, si sono trovati di fronte a: «Dammi l'ultimo ordine di Vasya, la sua data» E se non hai un indice sulla data, o nell'indice utilizzato non è presente la data, allora proprio su tali «pietre» inciampa.
Ma sappiamo che queste sono «pietre» — quindi perché non suggerire subito al разработчик cosa debba fare. Pertanto, aprendo ora il piano, il nostro разработчик vede subito un'immagine chiara con suggerimenti, dove gli viene detto: «Hai problemi qui e qui, e possono essere risolti in questo e quel modo.»
Ma sappiamo che è una 'trappola' — quindi perché non suggerire subito allo sviluppatore cosa dovrebbe fare. Di conseguenza, aprendo adesso il piano, il nostro sviluppatore vede subito un'immagine chiara con suggerimenti, dove gli viene detto: «Hai problemi qui e qui, e si risolvono in questo modo e in quest'altro.»
Di conseguenza, il volume dell'esperienza necessaria per risolvere i problemi all'inizio e ora è diminuito drasticamente. Ecco lo strumento che abbiamo creato.

Fonte: habr.com
