

L'implementazione di una nuova release in produzione richiede un attento equilibrio tra velocità di distribuzione e affidabilità della soluzione. In Slack si apprezzano iterazioni rapide, brevi cicli di feedback e una risposta tempestiva alle richieste degli utenti. Inoltre, ci sono centinaia di programmatori in azienda che puntano a massimizzare la propria produttività.
Gli autori del materiale, il cui traduzione pubblichiamo oggi, affermano che un'azienda che cerca di mantenere tali valori e allo stesso tempo cresce deve costantemente migliorare il proprio sistema di distribuzione dei progetti. L'azienda deve investire nello sviluppo della trasparenza e dell'affidabilità dei propri processi lavorativi, affinché questi siano allineati alle dimensioni del progetto. Qui si parlerà dei processi di lavoro stabiliti in Slack e di alcune soluzioni che hanno portato l'azienda all'adozione dell'attuale sistema di distribuzione dei progetti.
Come funzionano oggi i processi di distribuzione dei progetti
Ogni PR (pull request) in Slack deve essere sottoposta a revisione del codice e deve superare tutti i test con successo. Solo dopo aver soddisfatto queste condizioni, il programmatore può unire il proprio codice al branch master del progetto. Tuttavia, la distribuzione di quel codice avviene solo durante l'orario lavorativo secondo il fuso orario nordamericano. Di conseguenza, grazie alla presenza dei nostri dipendenti in ufficio, siamo completamente pronti a risolvere eventuali problemi imprevisti.
Ogni giorno effettuiamo circa 12 distribuzioni programmate. Durante ogni distribuzione, il programmatore incaricato come principale responsabile della distribuzione si occupa di implementare la nuova build in produzione. Questo è un processo a più fasi che garantisce una transizione fluida della build in modalità operativa. Grazie a questo approccio, possiamo individuare errori prima che colpiscano tutti i nostri utenti. Se gli errori sono troppi, la distribuzione della build può essere annullata. Se, tuttavia, un problema specifico viene scoperto dopo il rilascio, è facile rilasciare una correzione.
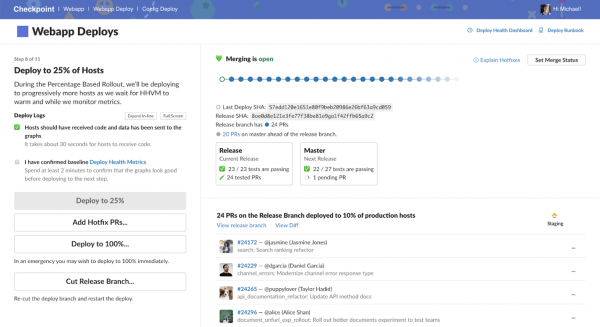
Interfaccia del sistema Checkpoint, utilizzata in Slack per la distribuzione dei progetti
Il processo di distribuzione di una nuova release in produzione può essere suddiviso in quattro fasi.
▍1. Creazione del branch di rilascio
Ogni release inizia con un nuovo branch di rilascio, a partire da un punto nella nostra storia Git. Questo consente di assegnare tag alla release e offre uno spazio per apportare correzioni rapide agli errori riscontrati durante la preparazione della release per il rilascio in produzione.
▍2. Distribuzione nell'ambiente di staging
Il passo successivo consiste nella distribuzione della build sui server di staging e nell'esecuzione di un test automatico di funzionalità generale del progetto (smoke test). L'ambiente di staging è un ambiente di produzione privo di traffico esterno. In questo ambiente eseguiamo ulteriori test manuali. Questo ci fornisce maggiore fiducia nel fatto che il progetto modificato funzioni correttamente. Solo i test automatizzati non sono sufficienti per ottenere tale sicurezza.
▍3. Distribuzione negli ambienti dogfood e canary
La distribuzione in produzione inizia con l'ambiente dogfood, composto da un insieme di host che servono i nostri spazi di lavoro interni su Slack. Poiché siamo utenti molto attivi di Slack, questo approccio ha aiutato a scoprire molti errori nelle fasi iniziali della distribuzione. Dopo aver verificato che le funzionalità di base del sistema non siano compromesse, procediamo a distribuire la build nell'ambiente canary. Questo rappresenta i sistemi che ricevono circa il 2% del traffico in produzione.
▍4. Rilascio graduale in produzione
Se gli indicatori di monitoraggio della nuova release rimangono stabili e se dopo la distribuzione nell'ambiente canary non riceviamo lamentele, continuiamo il rilascio graduale dei server di produzione sulla nuova release. Il processo di distribuzione è suddiviso in fasi: 10%, 25%, 50%, 75% e 100%. In questo modo possiamo trasferire lentamente il traffico di produzione alla nuova release del sistema. Allo stesso tempo, abbiamo tempo per esaminare la situazione in caso di anomalie.
▍Cosa fare se qualcosa va storto durante la distribuzione?
Le modifiche al codice comportano sempre dei rischi. Tuttavia, li gestiamo grazie alla presenza di esperti ben preparati nel processo di distribuzione, che guidano il lancio delle nuove versioni in produzione, monitorano le metriche di controllo e coordinano il lavoro degli sviluppatori che rilasciano il codice.
Nel caso in cui qualcosa vada realmente storto, cerchiamo di identificare il problema il prima possibile. Esaminiamo il problema, troviamo il PR che causa gli errori, lo annulliamo, analizziamo attentamente e creiamo una nuova build. A volte, tuttavia, il problema non viene notato fino al lancio del progetto in produzione. In tale situazione, la cosa più importante è ripristinare il servizio. Pertanto, prima di iniziare a indagare sul problema, torniamo immediatamente alla versione precedente funzionante.
Mattoni del sistema di distribuzione
Esaminiamo le tecnologie alla base del nostro sistema di distribuzione dei progetti.
▍Distribuzioni rapide
Il workflow descritto sopra potrebbe sembrare, a posteriori, piuttosto ovvio. Tuttavia, il nostro sistema di distribuzione non è diventato tale dall'oggi al domani.
Quando l'azienda era significativamente più piccola, tutta la nostra applicazione poteva funzionare su 10 istanze Amazon EC2. In questa situazione, distribuire un progetto significava utilizzare rsync per sincronizzare rapidamente tutti i server. In passato, ci voleva solo un passaggio, rappresentato dall'ambiente intermedio, per separare il nuovo codice dalla produzione. Le build venivano create e testate in quell'ambiente e poi andavano direttamente in produzione. Era molto facile capire un sistema del genere; consentiva a qualsiasi sviluppatore di distribuire il codice che aveva scritto in qualsiasi momento.
Ma man mano che aumentava il numero dei nostri clienti, cresceva anche l'infrastruttura necessaria per mantenere il progetto funzionante. Presto, data la crescita costante del sistema, il nostro modello di distribuzione, basato sull'invio di nuovo codice ai server, non era più in grado di svolgere il proprio compito. Infatti, aggiungere ogni nuovo server significava aumentare il tempo richiesto per completare la distribuzione. Anche le strategie che si basano sull'applicazione parallela di rsync presentano alcune limitazioni.
Di conseguenza, abbiamo risolto il problema passando a un sistema di distribuzione completamente parallelo, organizzato in modo diverso rispetto al sistema precedente. Ora non inviavamo più il codice ai server utilizzando uno script di sincronizzazione. Ogni server ora scaricava autonomamente la nuova build, sapendo che doveva farlo grazie al monitoraggio della modifica della chiave Consul. I server scaricavano il codice in parallelo. Questo ci ha permesso di mantenere alta la velocità di distribuzione anche in un contesto di crescita continua del sistema.

1. I server di produzione monitorano la chiave Consul. 2. La chiave viene modificata, informando i server di avviare il download del nuovo codice. 3. I server caricano i file tarball con il codice dell'applicazione.
▍Distribuzioni atomiche
Un'altra soluzione che ci ha aiutato a raggiungere un sistema di distribuzione multilivello è stata la distribuzione atomica.
Prima di utilizzare distribuzioni atomiche, ogni distribuzione poteva generare numerosi messaggi di errore. Infatti, il processo di copia di nuovi file sui server di produzione non era atomico. Questo portava a un breve intervallo temporale in cui il codice che chiamava nuove funzioni era disponibile prima che le stesse funzioni fossero pronte. Quando tale codice veniva chiamato, portava al ritorno di errori interni. Ciò si manifestava in richieste API fallite e pagine web 'rotte'.
Il team incaricato di questo problema lo ha risolto introducendo i concetti di directory 'calde' (hot) e 'fredde' (cold). Il codice nella directory 'calda' gestisce il traffico di produzione. Nelle directory 'fredde', il codice viene preparato per l'uso durante il funzionamento del sistema. Durante la distribuzione, il nuovo codice viene copiato in una directory 'fredda' non utilizzata. Poi, quando non ci sono processi attivi sul server, avviene il passaggio istantaneo delle directory.
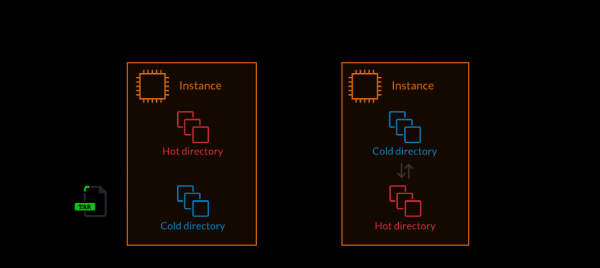
1. Estrarre il codice dell'applicazione nella directory 'fredda'. 2. Passare il sistema dalla directory 'fredda', che diventa 'calda' (operazione atomica).
Risultati: spostamento dell'accento verso l'affidabilità.
Nel 2018, il progetto ha raggiunto dimensioni tale che un'implementazione molto rapida ha iniziato a compromettere la stabilità del prodotto. Avevamo un sistema di distribuzione piuttosto avanzato, in cui abbiamo investito molto impegno e tempo. Dobbiamo solo riorganizzare e perfezionare i processi di distribuzione. Siamo diventati un'azienda di dimensioni considerevoli, le cui soluzioni sono state utilizzate in tutto il mondo per garantire comunicazioni ininterrotte e risolvere problemi importanti. Pertanto, l'affidabilità è diventata la nostra principale preoccupazione.
Dovevamo rendere il processo di distribuzione delle nuove versioni di Slack più sicuro. Questa esigenza ci ha portato a migliorare il nostro sistema di distribuzione. In effetti, abbiamo già discusso di questo sistema avanzato. Nel cuore del sistema continuiamo a fare uso di tecnologie di distribuzione rapida e atomica. Ciò che è cambiato è il modo in cui viene eseguita la distribuzione. Il nostro nuovo sistema è progettato per eseguire gradualmente la distribuzione del nuovo codice a diversi livelli e in ambienti diversi. Ora utilizziamo strumenti ausiliari e risorse di monitoraggio più sofisticati rispetto a prima. Questo ci consente di identificare e risolvere errori molto tempo prima che abbiano la possibilità di raggiungere l'utente finale.
Ma non intendiamo fermarci qui. Stiamo costantemente migliorando questo sistema, applicando strumenti ausiliari e risorse di automazione più avanzati.
Gentili lettori! Come funziona il processo di distribuzione delle nuove versioni dei progetti nel vostro ambiente di lavoro?
Fonte: habr.com
