

In questo articolo parlerò di una situazione che è recentemente accaduta a uno dei server del nostro cloud VPS, mettendomi in difficoltà per diverse ore. Ho circa 15 anni di esperienza nella configurazione e nel troubleshooting di server Linux, ma questo caso non rientra affatto nella mia pratica — ho fatto alcune supposizioni errate e sono stato un po' scoraggiato prima di riuscire a identificare correttamente la causa del problema e risolverlo.
Premessa
Gestiamo un cloud di dimensioni medie, costruito su server standard con la seguente configurazione — 32 core, 256 GB di RAM e un'unità NVMe PCI-E Intel P4500 da 4TB. Ci piace molto questa configurazione, in quanto consente di non preoccuparsi della mancanza di IO, fornendo un corretto limite a livello di tipi di istanze VM. Poiché NVMe Intel ha prestazioni straordinarie, possiamo fornire sia un'assegnazione completa degli IOPS alle macchine, sia un backup dello storage su un server di backup con zero IOWAIT.
Siamo del tipo di tradizionalisti che non usano SDN iperconvergenti e altre cose alla moda per la gestione dei volumi VM, ritenendo che più semplice è il sistema, più facile è risolverne i problemi in situazioni di "il guru è andato in montagna". Di conseguenza, memorizziamo i volumi VM in formato QCOW2 su XFS o EXT4, che è implementato sopra LVM2.
L'uso di QCOW2 è imposto anche dal prodotto che utilizziamo per l'orchestrazione — Apache CloudStack.
Per eseguire il backup, creiamo un'immagine completa del volume, come uno snapshot LVM2 (sì, sappiamo che gli snapshot LVM2 sono lenti, ma Intel P4500 ci aiuta anche qui). Facciamo lvmcreate -s .. e con dd invio il backup a un server remoto con storage ZFS. Qui siamo un po' più progressisti — ZFS è capace di memorizzare i dati in modo compresso, e possiamo recuperarli rapidamente usando attacchi DD o estrarre singoli volumi VM usando mount -o loop ....
Certo, sarebbe possibile fare un'immagine non completa del volume LVM2, montando il file system in modalità
ROe copiando le immagini QCOW2, tuttavia, abbiamo riscontrato che XFS ne risente, non immediatamente, ma in modo imprevedibile. Non ci piacciono quando i server hypervisor "si bloccano" improvvisamente nei fine settimana, di notte o durante le festività a causa di errori che non si sa quando si verificheranno. Pertanto, per XFS non utilizziamo il montaggio degli snapshot in modalitàROper estrarre i volumi, ma semplicemente copiamo l'intero volume LVM2.
La velocità di backup sul server di backup è determinata nel nostro caso dalle prestazioni del server di backup, che si attestano a circa 600-800 MB/s per dati non compressi, il successivo vincolante è la connessione 10Gbit/s, con cui il server di backup è collegato al cluster.
Nel frattempo, su un singolo server di backup vengono eseguiti simultaneamente backup da 8 server hypervisor. In questo modo, le subsistemi disco e rete del server di backup, essendo più lenti, non sovraccaricano i subsistemi disco degli hypervisor ospiti, poiché non sono in grado di gestire, ad esempio, 8 GB/s, che gli hypervisor ospiti possono fornire senza sforzo.
Il processo di copia sopra descritto è molto importante per la narrazione successiva, compresi i dettagli — l'uso di un'unità veloce Intel P4500, l'uso di NFS e, probabilmente, l'uso di ZFS.
Storia del backup
Su ogni nodo hypervisor abbiamo una piccola partizione SWAP di 8 GB, e l'node hypervisor viene "distribuito" utilizzando attacchi DD da un'immagine di riferimento. Per il volume di sistema sui server utilizziamo 2xSATA SSD RAID1 o 2xSAS HDD RAID1 su un controllore hardware LSI o HP. In generale, non ci interessa cosa ci sia all'interno, poiché il volume di sistema funziona in modalità "quasi readonly", a parte lo SWAP. E poiché abbiamo molta RAM sul server e ne abbiamo libera il 30-40%, non pensiamo allo SWAP.
Il processo di creazione del backup. La procedura sembra circa così:
#!/bin/bash
mkdir -p /mnt/backups/volumes
DIR=/mnt/images-snap
VOL=images/volume
DATE=$(date "+%d")
HOSTNAME=$(hostname)
lvcreate -s -n $VOL-snap -l100%FREE $VOL
ionice -c3 dd iflag=direct if=/dev/$VOL-snap bs=1M of=/mnt/backups/volumes/$HOSTNAME-$DATE.raw
lvremove -f $VOL-snapFai attenzione a ionice -c3, di fatto questa cosa per i dispositivi NVMe è completamente inutile, poiché il pianificatore IO per loro è impostato come:
cat /sys/block/nvme0n1/queue/scheduler
[none] Tuttavia, abbiamo una serie di nodi legacy con RAID SSD normali, per loro è pertinente, ecco perché si adatta AS IS. In generale, è solo un interessante pezzo di codice che spiega l'inutilità di ionice in caso di tale configurazione.
Fate attenzione al flag iflag=direct per attacchi DD. Utilizziamo IO diretto bypassando la cache di buffer, per non creare sostituzioni indesiderate dei buffer IO durante la lettura. Tuttavia, oflag=direct non lo facciamo, poiché abbiamo riscontrato problemi di prestazioni con ZFS durante il suo utilizzo.
Questo schema è utilizzato con successo da noi da diversi anni senza problemi.
E qui è iniziato tutto… Abbiamo scoperto che per uno dei nodi il backup non veniva più eseguito, e quello precedente era stato completato con un IOWAIT tremendo, vicino al 50%. Nel tentativo di capire perché non si stesse eseguendo il backup, ci siamo imbattuti in un fenomeno:
Gruppo di volumi "images" non trovatoAbbiamo cominciato a pensare che "la fine era arrivata per Intel P4500", tuttavia, prima di spegnere il server per sostituire il disco, era comunque necessario eseguire un backup. Abbiamo riparato LVM2 recuperando i metadati da un backup di LVM2:
vgcfgrestore imagesAbbiamo avviato il backup e abbiamo visto questa situazione:
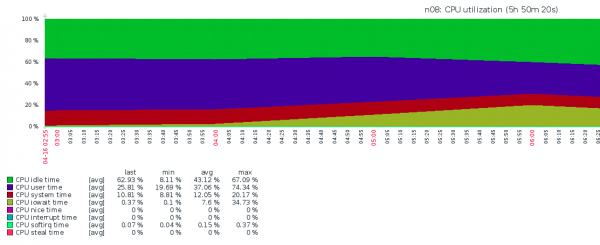
Ci siamo di nuovo molto rattristati — era chiaro che non si poteva andare avanti così, poiché tutti i VPS avrebbero sofferto, e quindi anche noi avremmo dovuto farlo. Cosa stesse succedendo era del tutto incomprensibile — iostat mostrava miseri IOPS e un IOWAIT elevatissimo. Non avevamo altre idee a parte "sostituiamo il NVMe", ma è successo che ci è venuta un'illuminazione in tempo.
Analisi della situazione passo dopo passo
Registro storico. Qualche giorno prima, su questo server, era stato necessario creare un grande VPS con 128 GB di RAM. La memoria sembrava sufficiente, ma per sicurezza erano stati assegnati ulteriori 32 GB per la partizione di swap. Il VPS era stato creato, aveva risolto il suo compito con successo ed era stato dimenticato l'incidente, ma la partizione SWAP era rimasta.
Caratteristiche della configurazione. Per tutti i server nel cloud, il parametro vm.swappiness era stato impostato sul valore predefinito 60. E lo SWAP era stato creato su SAS HDD RAID1.
Cosa stava succedendo (secondo la redazione). Durante il backup attacchi DD veniva generata una grande quantità di dati da scrivere, che venivano memorizzati nei buffer della RAM prima di essere scritti su NFS. Il kernel del sistema, seguendo la politica di swappiness, spostava molte pagine di memoria del VPS nell'area di swap, che si trovava su un volume lento HDD RAID1. Questo portava a un significativo aumento dell'IOWAIT, ma non a causa di IO NVMe, bensì a causa di IO HDD RAID1.
Come è stata risolta la problema. È stata disattivata la partizione di swap da 32GB. Ciò ha richiesto 16 ore; riguardo a come e perché ci si disconnette così lentamente lo SWAP, si può leggere separatamente. I parametri sono stati modificati swappiness sul valore pari a 5 in tutto il cloud.
Come avrebbe potuto non accadere. Innanzitutto, se lo SWAP fosse stato su SSD RAID o dispositivo NVMe, in secondo luogo, se non ci fosse stato un dispositivo NVMe, ma un dispositivo più lento che non avrebbe prodotto un volume così grande di dati — ironia della sorte, il problema è stato causato dal fatto che il NVMe era troppo veloce.
Dopo di ciò, tutto ha ripreso a funzionare come prima — con zero IOWAIT.
Fonte: habr.com
