

Ingegnere — dal latino — ispirato.
L'ingegnere può fare tutto. (c) R.Diesel.
Epigrafi.

O è la storia di perché un amministratore di database dovrebbe ricordare il suo passato da programmatore.
Prefazione
Tutti i nomi sono cambiati. I coincidenze sono puramente casuali. Il materiale rappresenta esclusivamente l'opinione personale dell'autore.
Disclaimer di garanzie: nella prevista serie di articoli non ci sarà una descrizione dettagliata e precisa delle tabelle e degli script utilizzati. I materiali non possono essere utilizzati immediatamente «AS IS».
In primo luogo, a causa del grande volume di materiali,
in secondo luogo a causa della specializzazione con il database di produzione del cliente reale.
Pertanto, negli articoli saranno fornite solo idee e descrizioni in termini molto generali.
Forse in futuro il sistema evolverà al punto da essere pubblicato su GitHub, ma forse no. Il tempo dirà.
Inizio della storia — «».
Qual è il risultato, in termini molto generali — «»
Perché tutto questo?
Beh, innanzitutto per non dimenticare, ricordando durante la pensione i bei vecchi tempi.
In secondo luogo, è necessario sistematizzare quanto scritto. Infatti, a volte inizio a confondermi e dimentico parti specifiche.
E la cosa più importante è che potrebbe essere utile a qualcuno, evitando di reinventare la ruota e di incappare in problemi già noti. In altre parole, migliorare la propria karma (non quella di Habr). Infatti, ciò che è più prezioso in questo mondo sono le idee. La cosa principale è trovare un'idea. Realizzare un'idea nella realtà è già una questione puramente tecnica.
Allora, cominciamo, lentamente...
Definizione del problema.
C'è:
Un database PostgreSQL (10.5), di tipo di carico misto (OLTP+DSS), con carico medio-basso, situato nel cloud AWS.
La monitorizzazione del database è assente, il monitoraggio dell'infrastruttura è fornito tramite strumenti standard di AWS in configurazione minima.
Requisiti:
Monitorare le prestazioni e lo stato del database, raccogliere e avere informazioni iniziali per ottimizzare le query pesanti al DB.
Breve prefazione o analisi delle opzioni di soluzione.
Iniziamo a esaminare le opzioni per affrontare il problema dal punto di vista di un'analisi comparativa tra vantaggi e svantaggi per l'ingegnere, mentre i benefici e le perdite per la direzione sono affare di chi di dovere secondo il contratto di lavoro.
Opzione 1 - «Lavorare su richiesta»
Lasciamo tutto com'è. Se il cliente ha dei problemi con la funzionalità, le prestazioni del database o dell'applicazione, informerà gli ingegneri DBA tramite e-mail o creando un incidente nella piattaforma di ticketing.
L'ingegnere, ricevuta la notifica, si occupa del problema, propone una soluzione o rimanda la questione, sperando che si risolva da sola, tanto prima o poi ci si dimenticherà.
Frittelle e schiene blu, lividi e bozzeFrittelle e schiene blu:
1. Non è necessario fare nulla di superfluo
2. C'è sempre la possibilità di giustificarsi e tirarsela.
3. Una montagna di tempo da spendere a propria discrezione.
Lividi e bozze:
1. Prima o poi, un cliente rifletterà sull'essenza dell'esistenza e sulla giustizia universale in questo mondo e si porrà di nuovo la domanda: perché sto pagando per questo? La conseguenza è sempre la stessa: l'unica domanda è quando il cliente si annoierà e abbandonerà. E il rubinetto si svuoterà. È triste.
2. Lo sviluppo dell'ingegnere è nullo.
3. Le difficoltà nella pianificazione del lavoro e del carico.
Opzione 2 - «Balliamo con i tamburi, vendiamo e calziamo»
Punto 1- Perché abbiamo bisogno di un sistema di monitoraggio? Riceveremo tutto tramite richieste. Lanciamo una marea di richieste al dizionario dei dati e alle rappresentazioni dinamiche, accendiamo vari contatori, riuniamo tutto in tabelle, e periodicamente analizziamo a modo nostro liste e tabelle. Il risultato è che abbiamo grafici, tabelle e rapporti belli o meno belli. L'importante è avere di più, di più.
Punto 2- Generiamo attività: avviamo l'analisi di tutto questo.
Punto 3- Prepareremo un documento, semplicemente chiamato: «come organizzare il nostro database».
Punto 4-Il cliente, vedendo tutta questa meraviglia di grafici e numeri, vive nella naivete di un bambino, convinto che ora tutto funzionerà, a breve. E si separa facilmente e senza dolori dalle sue risorse finanziarie. Anche il management è certo — i nostri ingegneri fanno un ottimo lavoro. Il carico è al massimo.
Punto 5-Ripetere regolarmente il Punto 1.
Frittelle e schiene blu, lividi e bozzeFrittelle e schiene blu:
1. La vita dei manager e degli ingegneri è semplice, prevedibile e piena di attività. Tutto ronzante, tutti impegnati.
2. Anche la vita del cliente non è male — è sempre convinto che basta avere un po' di pazienza e tutto si sistemerà. Se non si sistema, beh, che ci vuoi fare — il mondo è ingiusto, nella prossima vita andrà meglio.
Lividi e bozze:
1. Prima o poi, troverà un fornitore più veloce di servizi simili, che farà le stesse cose a un costo leggermente inferiore. E se il risultato è lo stesso, perché pagare di più? Questo porterà nuovamente alla scomparsa di opportunità.
2. È noioso. Come è noiosa qualsiasi attività poco significativa.
3. Come nel caso precedente, non ci sono sviluppi. Tuttavia, per un ingegnere, c’è uno svantaggio: a differenza della prima opzione, qui è necessario generare costantemente il database. E questo richiede tempo, tempo che potrebbe essere speso per il proprio bene. Perché, alla fine dei conti, se non ti prendi cura di te stesso, nessuno lo farà per te.
Opzione 3: Non c'è bisogno di inventare la ruota, è sufficiente comprarla e andare.
Non è un caso che gli ingegneri di altre aziende mangino pizza bevendo birra (ah, i bei tempi di Pietroburgo degli anni '90). Utilizziamo i sistemi di monitoraggio, che sono stati creati, testati e funzionano, e che apportano realmente dei vantaggi (almeno per i loro creatori).
Frittelle e schiene blu, lividi e bozzeFrittelle e schiene blu:
1. Non perdere tempo a reinventare ciò che è già stato inventato. Prendi e utilizza.
2. I sistemi di monitoraggio non sono scritti da sciocchi e sono certamente utili.
3. I sistemi di monitoraggio operativi tendono a fornire informazioni utili e filtrate.
Lividi e bozze:
1. In questo caso, l'ingegnere non è un ingegnere, ma semplicemente un utente di un prodotto altrui. O un user.
2. È necessario convincere il cliente della necessità di acquistare qualcosa di cui, in generale, non vuole nemmeno sapere, e che, in effetti, il budget annuale è approvato e non cambierà. Poi è necessario dedicare una risorsa separata e configurarla per un sistema specifico. Cioè, prima bisogna pagare, pagare e ancora pagare. Ma il cliente è avaro. Questa è la norma della vita.
Cosa fare, Černyševskij? La tua domanda è molto pertinente. (c)
In questo caso specifico e nella situazione attuale, possiamo comportarci in modo un po' diverso — e se creassimo il nostro sistema di monitoraggio?

Beh, non un sistema nel senso completo della parola, sarebbe troppo presuntuoso dirlo, ma in qualche modo alleviare il nostro compito e raccogliere più informazioni per risolvere gli incidenti di prestazioni. Per non trovarsi nella situazione — "vai là, non so dove, trova quella cosa, non so che."
Quali sono i vantaggi e gli svantaggi di questa opzione:
Vantaggi:
1. È interessante. Almeno è più interessante rispetto a costanti "shrink datafile, alter tablespace, ecc."
2. Sono nuove competenze e nuova crescita. Che, a lungo termine, prima o poi darà i giusti riconoscimenti e successi.
Contro:
1. Bisognerà lavorare. Lavorare molto.
2. Dovrà essere spiegato regolarmente il significato e le prospettive di tutte le attività.
3. Bisognerà sacrificare qualcosa, poiché l'unica risorsa a disposizione dell'ingegnere, il tempo, è limitata dall'Universo.
4. La cosa più spaventosa e spiacevole — può risultare qualcosa di simile a 'Non un topolino, non una rana, ma una creatura sconosciuta'.
Chi non rischia non beve champagne.
Ecco quindi che inizia la parte più interessante.
L'idea generale è schematica
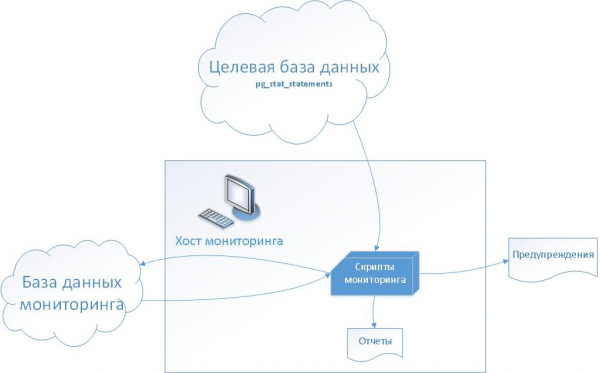
(L'illustrazione è tratta dall'articolo «»)
Spiegazione:
- Nel database di destinazione si installa l'estensione standard di PostgreSQL — 'pg_stat_statements'.
- Nel database di monitoraggio creiamo un insieme di tabelle di servizio per memorizzare la cronologia di pg_stat_statements nella fase iniziale e per configurare metriche e monitoraggio successivamente.
- Sul host di monitoraggio creiamo un insieme di script bash, inclusi quelli per generare incidenti nel sistema di ticket.
Tabelle di servizio
Per cominciare, una ERD schematicamente semplificata, ecco cosa è stato ottenuto alla fine:
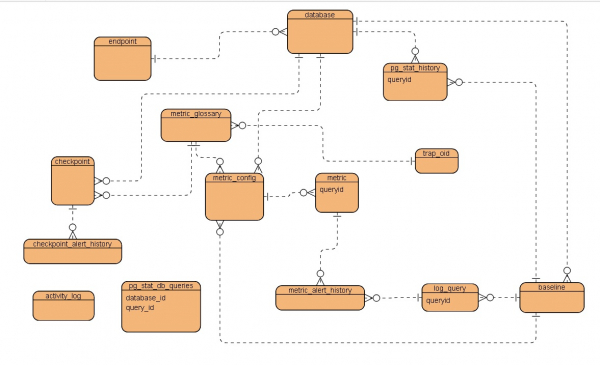
Breve descrizione delle tabelleendpoint — host, punto di connessione all'istanza
database — parametri del database
pg_stat_history — tabella storica per conservare istantanee temporali della vista pg_stat_statements del database di destinazione
metric_glossary — glossario delle metriche di prestazione
metric_config — configurazione delle metriche specifiche
metric — metrica specifica per la richiesta monitorata
metric_alert_history — cronologia degli avvisi sulle prestazioni
log_query — tabella di sistema per memorizzare i record analizzati dal file di log di PostgreSQL caricato da AWS
baseline — parametri del periodo di tempo utilizzato come base
checkpoint — configurazione delle metriche di controllo dello stato del database
checkpoint_alert_history — cronologia degli avvisi delle metriche di controllo dello stato del database
pg_stat_db_queries — tabella di sistema delle query attive
activity_log — tabella di sistema del registro attività
trap_oid — tabella di sistema per la configurazione del trap
Fase 1 — raccogliamo informazioni statistiche sulle prestazioni e otteniamo report
La tabella serve per conservare informazioni statistiche pg_stat_history
Struttura della tabella pg_stat_history
Tabella "public.pg_stat_history"
Colonna | Tipo | Modificatori
---------------------+-----------------------------+-------------------------------------------
id | intero | non nullo, valore di default nextval('pg_stat_history_id_seq'::regclass)
timestamp_snapshot | timestamp senza fuso orario |
database_id | intero |
dbid | oid |
userid | oid |
queryid | bigint |
query | testo |
calls | bigint |
tempo_totale | doppia precisione |
tempo_minimo | doppia precisione |
tempo_massimo | doppia precisione |
tempo_medio | doppia precisione |
stddev_time | doppia precisione |
righe | bigint |
shared_blks_hit | bigint |
shared_blks_read | bigint |
shared_blks_dirtied | bigint |
shared_blks_written | bigint |
local_blks_hit | bigint |
local_blks_read | bigint |
local_blks_dirtied | bigint |
local_blks_written | bigint |
temp_blks_read | bigint |
temp_blks_written | bigint |
blk_read_time | doppia precisione |
blk_write_time | doppia precisione |
baseline_id | intero |
Indici:
"pg_stat_history_pkey" CHIAVE PRIMARIA, btree (id)
"database_idx" btree (database_id)
"queryid_idx" btree (queryid)
"snapshot_timestamp_idx" btree (snapshot_timestamp)
Vincoli di chiave esterna:
"database_id_fk" CHIAVE ESTERNA (database_id) RIFERISCE a database(id) ON DELETE CASCADECome si può vedere, la tabella rappresenta solo dati cumulativi di visualizzazione. pg_stat_statements nella base dati target.
L'utilizzo di questa tabella è molto semplice.
pg_stat_history rappresenterà le statistiche accumulate di esecuzione delle query per ogni ora. All'inizio di ogni ora, dopo che la tabella è stata riempita, le statistiche pg_stat_statements vengono azzerate con pg_stat_statements_reset().
Nota: le statistiche vengono raccolte per le query con una durata di esecuzione superiore a 1 secondo.
Il riempimento della tabella pg_stat_history
--pg_stat_history.sql
CREATE OR REPLACE FUNCTION pg_stat_history( ) RETURNS boolean AS $$
DECLARE
endpoint_rec record ;
database_rec record ;
pg_stat_snapshot record ;
current_snapshot_timestamp timestamp without time zone;
BEGIN
current_snapshot_timestamp = date_trunc('minute',now());
FOR endpoint_rec IN SELECT * FROM endpoint
LOOP
FOR database_rec IN SELECT * FROM database WHERE endpoint_id = endpoint_rec.id
LOOP
RAISE NOTICE 'NUOVO SHAPSHOT IN CORSO DI CREAZIONE';
--Collegati al DB target
EXECUTE 'SELECT dblink_connect(''LINK1'',''host='||endpoint_rec.host||' dbname='||database_rec.name||' user=USER password=PASSWORD '')';
RAISE NOTICE 'host % e dbname % ',endpoint_rec.host,database_rec.name;
RAISE NOTICE 'Creazione snapshot di pg_stat_statements per il database %',database_rec.name;
SELECT
*
INTO
pg_stat_snapshot
FROM dblink('LINK1',
'SELECT
dbid , SUM(calls),SUM(total_time),SUM(rows) ,SUM(shared_blks_hit) ,SUM(shared_blks_read) ,SUM(shared_blks_dirtied) ,SUM(shared_blks_written) ,
SUM(local_blks_hit) , SUM(local_blks_read) , SUM(local_blks_dirtied) , SUM(local_blks_written) , SUM(temp_blks_read) , SUM(temp_blks_written) , SUM(blk_read_time) , SUM(blk_write_time)
FROM pg_stat_statements WHERE dbid=(SELECT oid from pg_database where datname=current_database() )
GROUP BY dbid
'
)
AS t
( dbid oid , calls bigint ,
total_time double precision ,
rows bigint , shared_blks_hit bigint , shared_blks_read bigint ,shared_blks_dirtied bigint ,shared_blks_written bigint ,
local_blks_hit bigint ,local_blks_read bigint , local_blks_dirtied bigint ,local_blks_written bigint ,
temp_blks_read bigint ,temp_blks_written bigint ,
blk_read_time double precision , blk_write_time double precision
);
INSERT INTO pg_stat_history
(
snapshot_timestamp ,database_id ,
dbid , calls ,total_time ,
rows ,shared_blks_hit ,shared_blks_read ,shared_blks_dirtied ,shared_blks_written ,local_blks_hit ,
local_blks_read,local_blks_dirtied,local_blks_written,temp_blks_read,temp_blks_written,
blk_read_time, blk_write_time
)
VALUES
(
current_snapshot_timestamp ,
database_rec.id ,
pg_stat_snapshot.dbid ,pg_stat_snapshot.calls,
pg_stat_snapshot.total_time,
pg_stat_snapshot.rows ,pg_stat_snapshot.shared_blks_hit ,pg_stat_snapshot.shared_blks_read ,pg_stat_snapshot.shared_blks_dirtied ,pg_stat_snapshot.shared_blks_written ,
pg_stat_snapshot.local_blks_hit , pg_stat_snapshot.local_blks_read , pg_stat_snapshot.local_blks_dirtied , pg_stat_snapshot.local_blks_written ,
pg_stat_snapshot.temp_blks_read , pg_stat_snapshot.temp_blks_written , pg_stat_snapshot.blk_read_time , pg_stat_snapshot.blk_write_time
);
RAISE NOTICE 'Creazione snapshot di pg_stat_statements per le query con min_time superiore a 1000ms';
FOR pg_stat_snapshot IN
--Tutte le query con max_time maggiore di 1000 ms
SELECT
*
FROM dblink('LINK1',
'SELECT
dbid , userid ,queryid,query,calls,total_time,min_time ,max_time,mean_time, stddev_time ,rows ,shared_blks_hit ,
shared_blks_read ,shared_blks_dirtied ,shared_blks_written ,
local_blks_hit , local_blks_read , local_blks_dirtied ,
local_blks_written , temp_blks_read , temp_blks_written , blk_read_time ,
blk_write_time
FROM pg_stat_statements
WHERE dbid=(SELECT oid from pg_database where datname=current_database() AND min_time >= 1000 )
'
)
AS t
( dbid oid , userid oid , queryid bigint ,query text , calls bigint ,
total_time double precision ,min_time double precision ,max_time double precision , mean_time double precision , stddev_time double precision ,
rows bigint , shared_blks_hit bigint , shared_blks_read bigint ,shared_blks_dirtied bigint ,shared_blks_written bigint ,
local_blks_hit bigint ,local_blks_read bigint , local_blks_dirtied bigint ,local_blks_written bigint ,
temp_blks_read bigint ,temp_blks_written bigint ,
blk_read_time double precision , blk_write_time double precision
)
LOOP
INSERT INTO pg_stat_history
(
snapshot_timestamp ,database_id ,
dbid ,userid , queryid , query , calls ,total_time ,min_time ,max_time ,mean_time ,stddev_time ,
rows ,shared_blks_hit ,shared_blks_read ,shared_blks_dirtied ,shared_blks_written ,local_blks_hit ,
local_blks_read,local_blks_dirtied,local_blks_written,temp_blks_read,temp_blks_written,
blk_read_time, blk_write_time
)
VALUES
(
current_snapshot_timestamp ,
database_rec.id ,
pg_stat_snapshot.dbid ,pg_stat_snapshot.userid ,pg_stat_snapshot.queryid,pg_stat_snapshot.query,pg_stat_snapshot.calls,
pg_stat_snapshot.total_time,pg_stat_snapshot.min_time ,pg_stat_snapshot.max_time,pg_stat_snapshot.mean_time, pg_stat_snapshot.stddev_time ,
pg_stat_snapshot.rows ,pg_stat_snapshot.shared_blks_hit ,pg_stat_snapshot.shared_blks_read ,pg_stat_snapshot.shared_blks_dirtied ,pg_stat_snapshot.shared_blks_written ,
pg_stat_snapshot.local_blks_hit , pg_stat_snapshot.local_blks_read , pg_stat_snapshot.local_blks_dirtied , pg_stat_snapshot.local_blks_written ,
pg_stat_snapshot.temp_blks_read , pg_stat_snapshot.temp_blks_written , pg_stat_snapshot.blk_read_time , pg_stat_snapshot.blk_write_time
);
END LOOP;
PERFORM dblink_disconnect('LINK1');
END LOOP ;--FOR database_rec IN SELECT * FROM database WHERE endpoint_id = endpoint_rec.id
END LOOP;
RETURN TRUE;
END
$$ LANGUAGE plpgsql;Di conseguenza, dopo un certo periodo di tempo nella tabella pg_stat_history avremo un insieme di istantanee del contenuto della tabella pg_stat_statements del database di destinazione.
Generazione di report
Utilizzando query semplici, è possibile ottenere report piuttosto utili e interessanti.
Dati aggregati per un intervallo di tempo specificato
Richiesta
SELECT
database_id ,
SUM(calls) AS calls ,SUM(total_time) AS total_time ,
SUM(rows) AS rows , SUM(shared_blks_hit) AS shared_blks_hit,
SUM(shared_blks_read) AS shared_blks_read ,
SUM(shared_blks_dirtied) AS shared_blks_dirtied,
SUM(shared_blks_written) AS shared_blks_written ,
SUM(local_blks_hit) AS local_blks_hit ,
SUM(local_blks_read) AS local_blks_read ,
SUM(local_blks_dirtied) AS local_blks_dirtied ,
SUM(local_blks_written) AS local_blks_written,
SUM(temp_blks_read) AS temp_blks_read,
SUM(temp_blks_written) temp_blks_written ,
SUM(blk_read_time) AS blk_read_time ,
SUM(blk_write_time) AS blk_write_time
FROM
pg_stat_history
WHERE
queryid IS NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT
GROUP BY database_id ;Tempo DB
to_char(interval '1 millisecond' * pg_total_stat_history_rec.total_time, 'HH24:MI:SS.MS')
Tempo I/O
to_char(interval '1 millisecond' * ( pg_total_stat_history_rec.blk_read_time + pg_total_stat_history_rec.blk_write_time ), 'HH24:MI:SS.MS')
TOP10 SQL per total_time
Richiesta
SELECT
queryid ,
SUM(calls) AS calls ,
SUM(total_time) AS total_time
FROM
pg_stat_history
WHERE
queryid IS NOT NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT
GROUP BY queryid
ORDER BY 3 DESC
LIMIT 10------------------------------------------------------------------------------------- | TOP10 SQL PER TEMPO TOTALE DI ESECUZIONE | #| queryid| chiamate| % chiamate| tempo_totale (ms) | % dbtime +----+-----------+-----------+-----------+--------------------------------+---------- | 1| 821760255| 2| .00001|00:03:23.141( 203141.681 ms.)| 5.42 | 2| 4152624390| 2| .00001|00:03:13.929( 193929.215 ms.)| 5.17 | 3| 1484454471| 4| .00001|00:02:09.129( 129129.057 ms.)| 3.44 | 4| 655729273| 1| .00000|00:02:01.869( 121869.981 ms.)| 3.25 | 5| 2460318461| 1| .00000|00:01:33.113( 93113.835 ms.)| 2.48 | 6| 2194493487| 4| .00001|00:00:17.377( 17377.868 ms.)| .46 | 7| 1053044345| 1| .00000|00:00:06.156( 6156.352 ms.)| .16 | 8| 3644780286| 1| .00000|00:00:01.063( 1063.830 ms.)| .03
TOP10 SQL per tempo totale di I/O
Richiesta
SELECT
queryid ,
SUM(calls) AS chiamate ,
SUM(blk_read_time + blk_write_time) AS io_time
FROM
pg_stat_history
WHERE
queryid IS NOT NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT
GROUP BY queryid
ORDER BY 3 DESC
LIMIT 10---------------------------------------------------------------------------------------- | TOP10 SQL PER TEMPO TOTALE I/O | #| queryid| chiamate| % chiamate| Tempo I/O (ms)|% tempo I/O db +----+-----------+-----------+-----------+--------------------------------+------------- | 1| 4152624390| 2| .00001|00:08:31.616( 511616.592 ms.)| 31.06 | 2| 821760255| 2| .00001|00:08:27.099( 507099.036 ms.)| 30.78 | 3| 655729273| 1| .00000|00:05:02.209( 302209.137 ms.)| 18.35 | 4| 2460318461| 1| .00000|00:04:05.981( 245981.117 ms.)| 14.93 | 5| 1484454471| 4| .00001|00:00:39.144( 39144.221 ms.)| 2.38 | 6| 2194493487| 4| .00001|00:00:18.182( 18182.816 ms.)| 1.10 | 7| 1053044345| 1| .00000|00:00:16.611( 16611.722 ms.)| 1.01 | 8| 3644780286| 1| .00000|00:00:00.436( 436.205 ms.)| .03
TOP10 SQL per tempo massimo di esecuzione
Richiesta
SELECT
id AS snapshotid ,
queryid ,
snapshot_timestamp ,
max_time
FROM
pg_stat_history
WHERE
queryid IS NOT NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT
ORDER BY 4 DESC
LIMIT 10----------------------------------------------------------------------------------------- | TOP10 SQL PER TEMPO DI ESECUZIONE MASSIMO | #| snapshot| snapshotID| queryid| max_time (ms) +----+------------------+-----------+-----------+---------------------------------------- | 1| 05.04.2019 01:03| 4169| 655729273| 00:02:01.869( 121869.981 ms.) | 2| 04.04.2019 17:00| 4153| 821760255| 00:01:41.570( 101570.841 ms.) | 3| 04.04.2019 16:00| 4146| 821760255| 00:01:41.570( 101570.841 ms.) | 4| 04.04.2019 16:00| 4144| 4152624390| 00:01:36.964( 96964.607 ms.) | 5| 04.04.2019 17:00| 4151| 4152624390| 00:01:36.964( 96964.607 ms.) | 6| 05.04.2019 10:00| 4188| 1484454471| 00:01:33.452( 93452.150 ms.) | 7| 04.04.2019 17:00| 4150| 2460318461| 00:01:33.113( 93113.835 ms.) | 8| 04.04.2019 15:00| 4140| 1484454471| 00:00:11.892( 11892.302 ms.) | 9| 04.04.2019 16:00| 4145| 1484454471| 00:00:11.892( 11892.302 ms.) | 10| 04.04.2019 17:00| 4152| 1484454471| 00:00:11.892( 11892.302 ms.)
TOP10 SQL per lettura/scrittura buffer CONDIVISI
Richiesta
SELEZIONA
id AS snapshotid ,
queryid ,
snapshot_timestamp ,
shared_blks_read ,
shared_blks_written
DA
pg_stat_history
DOVE
queryid NON È NULL E
database_id = DATABASE_ID E
snapshot_timestamp TRA BEGIN_TIMEPOINT E END_TIMEPOINT E
( shared_blks_read > 0 OPPURE shared_blks_written > 0 )
ORDINA PER 4 DESC , 5 DESC
LIMITA 10-------------------------------------------------------------------------------------------- | TOP10 SQL PER LETTURE/SCRITTURE BUFFERS CONDIVISI | #| istantanea| snapshotID| queryid| blocchi condivisi letti| blocchi condivisi scritti +----+------------------+-----------+-----------+---------------------+--------------------- | 1| 04.04.2019 17:00| 4153| 821760255| 797308| 0 | 2| 04.04.2019 16:00| 4146| 821760255| 797308| 0 | 3| 05.04.2019 01:03| 4169| 655729273| 797158| 0 | 4| 04.04.2019 16:00| 4144| 4152624390| 756514| 0 | 5| 04.04.2019 17:00| 4151| 4152624390| 756514| 0 | 6| 04.04.2019 17:00| 4150| 2460318461| 734117| 0 | 7| 04.04.2019 17:00| 4155| 3644780286| 52973| 0 | 8| 05.04.2019 01:03| 4168| 1053044345| 52818| 0 | 9| 04.04.2019 15:00| 4141| 2194493487| 52813| 0 | 10| 04.04.2019 16:00| 4147| 2194493487| 52813| 0 --------------------------------------------------------------------------------------------
Istogramma della distribuzione delle query in base al tempo massimo di esecuzione
Richieste
SELEZIONA
MIN(max_time) AS hist_min ,
MAX(max_time) AS hist_max ,
(( MAX(max_time) - MIN(min_time) ) / hist_columns ) AS hist_width
DA
pg_stat_history
DOVE
queryid È NON NULL E
database_id = DATABASE_ID E
snapshot_timestamp TRA BEGIN_TIMEPOINT E END_TIMEPOINT ;
SELEZIONA
SOMMA(calls) AS calls
DA
pg_stat_history
DOVE
queryid È NON NULL E
database_id = DATABASE_ID E
snapshot_timestamp TRA BEGIN_TIMEPOINT E END_TIMEPOINT E
( max_time >= hist_current_min E max_time < hist_current_max ) ;
|----------------------------------------------------------------------------------------------- | ISTOGRAMA DEL TEMPO MASSIMO | CHIAMATE TOTALE : 33851920 | TEMPO MINIMO : 00:00:01.063 | TEMPO MASSIMO : 00:02:01.869 --------------------------------------------------------------------------------- | durata minima| durata massima| chiamate +----------------------------------+----------------------------------+---------- | 00:00:01.063( 1063.830 ms.) | 00:00:13.144( 13144.445 ms.) | 9 | 00:00:13.144( 13144.445 ms.) | 00:00:25.225( 25225.060 ms.) | 0 | 00:00:25.225( 25225.060 ms.) | 00:00:37.305( 37305.675 ms.) | 0 | 00:00:37.305( 37305.675 ms.) | 00:00:49.386( 49386.290 ms.) | 0 | 00:00:49.386( 49386.290 ms.) | 00:01:01.466( 61466.906 ms.) | 0 | 00:01:01.466( 61466.906 ms.) | 00:01:13.547( 73547.521 ms.) | 0 | 00:01:13.547( 73547.521 ms.) | 00:01:25.628( 85628.136 ms.) | 0 | 00:01:25.628( 85628.136 ms.) | 00:01:37.708( 97708.751 ms.) | 4 | 00:01:37.708( 97708.751 ms.) | 00:01:49.789( 109789.366 ms.) | 2 | 00:01:49.789( 109789.366 ms.) | 00:02:01.869( 121869.981 ms.) | 0
TOP10 Istogrammi per Secondo per Query
Richieste
--pg_qps.sql
--Calcolare le Query al Secondo
CREATE OR REPLACE FUNCTION pg_qps( pg_stat_history_id integer ) RETURNS double precision AS $$
DECLARE
pg_stat_history_rec record;
prev_pg_stat_history_id integer;
prev_pg_stat_history_rec record;
total_seconds double precision;
result double precision;
BEGIN
result = 0;
SELECT *
INTO pg_stat_history_rec
FROM
pg_stat_history
WHERE id = pg_stat_history_id;
IF pg_stat_history_rec.snapshot_timestamp IS NULL
THEN
RAISE EXCEPTION 'ERRORE - pg_stat_history non trovato per id = %',pg_stat_history_id;
END IF;
--RAISE NOTICE 'pg_stat_history_id = % , snapshot_timestamp = %', pg_stat_history_id ,
pg_stat_history_rec.snapshot_timestamp;
SELECT
MAX(id)
INTO
prev_pg_stat_history_id
FROM
pg_stat_history
WHERE
database_id = pg_stat_history_rec.database_id AND
queryid IS NULL AND
id 0
THEN
result = pg_stat_history_rec.calls / total_seconds;
ELSE
result = 0;
END IF;
RETURN result;
END
$$ LANGUAGE plpgsql;
SELECT
id,
snapshot_timestamp,
calls,
total_time,
( select pg_qps( id )) AS QPS,
blk_read_time,
blk_write_time
FROM
pg_stat_history
WHERE
queryid IS NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT AND
( select pg_qps( id )) IS NOT NULL
ORDER BY 5 DESC
LIMIT 10
|----------------------------------------------------------------------------------------------- | TOP10 Snapshot ordinati per QueryPerSecond ----------------------------------------------------------------------------------------------------------------------------------------------- | #| snapshot| snapshotID| chiamate| tempo totale db| QPS| tempo I/O| Percentuale tempo I/O% +-----+------------------+-----------+-----------+----------------------------------+-----------+----------------------------------+----------- | 1| 04.04.2019 20:04| 4161| 5758631| 00:06:30.513( 390513.926 ms.)| 1573.396| 00:00:01.470( 1470.110 ms.)| .376 | 2| 04.04.2019 17:00| 4149| 3529197| 00:11:48.830( 708830.618 ms.)| 980.332| 00:12:47.834( 767834.052 ms.)| 108.324 | 3| 04.04.2019 16:00| 4143| 3525360| 00:10:13.492( 613492.351 ms.)| 979.267| 00:08:41.396( 521396.555 ms.)| 84.988 | 4| 04.04.2019 21:03| 4163| 2781536| 00:03:06.470( 186470.979 ms.)| 785.745| 00:00:00.249( 249.865 ms.)| .134 | 5| 04.04.2019 19:03| 4159| 2890362| 00:03:16.784( 196784.755 ms.)| 776.979| 00:00:01.441( 1441.386 ms.)| .732 | 6| 04.04.2019 14:00| 4137| 2397326| 00:04:43.033( 283033.854 ms.)| 665.924| 00:00:00.024( 24.505 ms.)| .009 | 7| 04.04.2019 15:00| 4139| 2394416| 00:04:51.435( 291435.010 ms.)| 665.116| 00:00:12.025( 12025.895 ms.)| 4.126 | 8| 04.04.2019 13:00| 4135| 2373043| 00:04:26.791( 266791.988 ms.)| 659.179| 00:00:00.064( 64.261 ms.)| .024 | 9| 05.04.2019 01:03| 4167| 4387191| 00:06:51.380( 411380.293 ms.)| 609.332| 00:05:18.847( 318847.407 ms.)| 77.507 | 10| 04.04.2019 18:01| 4157| 1145596| 00:01:19.217( 79217.372 ms.)| 313.004| 00:00:01.319( 1319.676 ms.)| 1.666
Cronologia Esecuzioni Orarie con QueryPerSecondi e Tempo I/O
Richiesta
SELEZIONA
id ,
snapshot_timestamp ,
chiamate ,
tempo_totale ,
( seleziona pg_qps( id )) COME QPS ,
blk_read_time ,
blk_write_time
DA
pg_stat_history
DOVE
queryid È NULL E
database_id = DATABASE_ID E
snapshot_timestamp TRA BEGIN_TIMEPOINT E END_TIMEPOINT
ORDINA PER 2
|----------------------------------------------------------------------------------------------- | STORIA DI ESECUZIONE ORARIA CON QueryPerSecondo e Tempo I/O ----------------------------------------------------------------------------------------------------------------------------------------------- | STORIA DELLE QUERY PER SECONDO | #| istantanea| ID_istantanea| chiamate| tempo db totale| QPS| tempo I/O| % tempo I/O +-----+------------------+-----------+-----------+----------------------------------+-----------+----------------------------------+----------- | 1| 04.04.2019 11:00| 4131| 3747| 00:00:00.835( 835.374 ms.)| 1.041| 00:00:00.000( .000 ms.)| .000 | 2| 04.04.2019 12:00| 4133| 1002722| 00:01:52.419( 112419.376 ms.)| 278.534| 00:00:00.149( 149.105 ms.)| .133 | 3| 04.04.2019 13:00| 4135| 2373043| 00:04:26.791( 266791.988 ms.)| 659.179| 00:00:00.064( 64.261 ms.)| .024 | 4| 04.04.2019 14:00| 4137| 2397326| 00:04:43.033( 283033.854 ms.)| 665.924| 00:00:00.024( 24.505 ms.)| .009 | 5| 04.04.2019 15:00| 4139| 2394416| 00:04:51.435( 291435.010 ms.)| 665.116| 00:00:12.025( 12025.895 ms.)| 4.126 | 6| 04.04.2019 16:00| 4143| 3525360| 00:10:13.492( 613492.351 ms.)| 979.267| 00:08:41.396( 521396.555 ms.)| 84.988 | 7| 04.04.2019 17:00| 4149| 3529197| 00:11:48.830( 708830.618 ms.)| 980.332| 00:12:47.834( 767834.052 ms.)| 108.324 | 8| 04.04.2019 18:01| 4157| 1145596| 00:01:19.217( 79217.372 ms.)| 313.004| 00:00:01.319( 1319.676 ms.)| 1.666 | 9| 04.04.2019 19:03| 4159| 2890362| 00:03:16.784( 196784.755 ms.)| 776.979| 00:00:01.441( 1441.386 ms.)| .732 | 10| 04.04.2019 20:04| 4161| 5758631| 00:06:30.513( 390513.926 ms.)| 1573.396| 00:00:01.470( 1470.110 ms.)| .376 | 11| 04.04.2019 21:03| 4163| 2781536| 00:03:06.470( 186470.979 ms.)| 785.745| 00:00:00.249( 249.865 ms.)| .134 | 12| 04.04.2019 23:03| 4165| 1443155| 00:01:34.467( 94467.539 ms.)| 200.438| 00:00:00.015( 15.287 ms.)| .016 | 13| 05.04.2019 01:03| 4167| 4387191| 00:06:51.380( 411380.293 ms.)| 609.332| 00:05:18.847( 318847.407 ms.)| 77.507 | 14| 05.04.2019 02:03| 4171| 189852| 00:00:10.989( 10989.899 ms.)| 52.737| 00:00:00.539( 539.110 ms.)| 4.906 | 15| 05.04.2019 03:01| 4173| 3627| 00:00:00.103( 103.000 ms.)| 1.042| 00:00:00.004( 4.131 ms.)| 4.010 | 16| 05.04.2019 04:00| 4175| 3627| 00:00:00.085( 85.235 ms.)| 1.025| 00:00:00.003( 3.811 ms.)| 4.471 | 17| 05.04.2019 05:00| 4177| 3747| 00:00:00.849( 849.454 ms.)| 1.041| 00:00:00.006( 6.124 ms.)| .721 | 18| 05.04.2019 06:00| 4179| 3747| 00:00:00.849( 849.561 ms.)| 1.041| 00:00:00.000( .051 ms.)| .006 | 19| 05.04.2019 07:00| 4181| 3747| 00:00:00.839( 839.416 ms.)| 1.041| 00:00:00.000( .062 ms.)| .007 | 20| 05.04.2019 08:00| 4183| 3747| 00:00:00.846( 846.382 ms.)| 1.041| 00:00:00.000( .007 ms.)| .001 | 21| 05.04.2019 09:00| 4185| 3747| 00:00:00.855( 855.426 ms.)| 1.041| 00:00:00.000( .065 ms.)| .008 | 22| 05.04.2019 10:00| 4187| 3797| 00:01:40.150( 100150.165 ms.)| 1.055| 00:00:21.845( 21845.217 ms.)| 21.812
Testo di tutte le selezioni SQL
Richiesta
SELECT
queryid ,
query
FROM
pg_stat_history
WHERE
queryid IS NOT NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT
GROUP BY queryid , query
Risultato
Come si può vedere, con strumenti piuttosto semplici, è possibile ottenere molte informazioni utili sul carico e sulla stato del database.
Nota:Se nei query si registra il queryid, si otterrà la cronologia per singolo query (per risparmiare spazio, i report per singolo query sono stati omessi).
Quindi, i dati sulle prestazioni delle query sono disponibili e vengono raccolti.
La prima fase "raccolta dei dati statistici" è completata.
Si può passare alla seconda fase – "impostazione delle metriche di prestazione".

Ma questa è già tutta un'altra storia.
Continua...
Fonte: habr.com
