


Nella prima parte abbiamo spiegato perché abbiamo deciso di sostituire il vecchio sistema BMS nei nostri data center con uno nuovo. E non solo sostituirlo, ma svilupparlo da zero secondo le nostre esigenze. Nella seconda parte raccontiamo come lo abbiamo fatto.
Analisi del mercato
Tenendo conto di quanto descritto in richieste e della decisione di rinunciare all'aggiornamento del sistema esistente, abbiamo redatto un documento di specifiche per la ricerca di una soluzione sul mercato e abbiamo inviato richieste a diverse grandi aziende specializzate nella creazione di sistemi SCADA industriali.
Le prime risposte ci hanno mostrato che i leader del mercato dei sistemi di monitoraggio continuano prevalentemente a lavorare su server fisici, anche se il processo di migrazione verso il cloud è già iniziato in questo settore. Per quanto riguarda il ripristino delle macchine virtuali, nessuno ha supportato questa opzione. Inoltre, sembrava che nessuno dei noti sviluppatori sul mercato avesse dimostrato una comprensione anche della necessità di ripristino: "il cloud non va mai giù" era la risposta più comune. Di fatto, ci veniva proposto di ospitare il monitoraggio del data center nel cloud, fisicamente situato nello stesso data center.
Qui è necessario fare una piccola digressione sul processo di selezione del fornitore. Certo, il prezzo conta, ma durante qualsiasi gara per l'implementazione di un progetto complesso, nella fase di dialogo con i fornitori, inizi a percepire chi tra i candidati è più motivato e in grado di realizzarlo.
Questo è particolarmente evidente nei progetti complessi.
In base alla tipologia delle domande di chiarimento sul capitolato, è possibile suddividere i fornitori in quelli interessati solo a vendere (si percepisce un’approccio standard da parte del responsabile commerciale) e in quelli che vogliono davvero sviluppare un prodotto, ascoltando e comprendendo il committente, apportando modifiche costruttive al capitolato anche prima della selezione finale (anche se c'è il reale rischio di migliorare un capitolato altrui e perdere la gara), in fin dei conti, pronti ad accettare la sfida professionale e a realizzare un buon prodotto.
Tutto ciò ci ha portato a prestare attenzione a un relativamente piccolo sviluppatore locale - il gruppo di aziende «Sanline», che ha risposto a gran parte delle nostre esigenze fin da subito ed era pronto a soddisfare tutte le necessità relative al nuovo BMS.
Rischi
Mentre i grandi attori cercavano di capire cosa volessimo, portando avanti con noi una corrispondenza lenta coinvolgendo specialisti di livello pre-vendita, uno sviluppatore locale ha organizzato un incontro nel nostro ufficio con il suo team tecnico. Durante questo incontro, l'appaltatore ha riaffermato la sua volontà di partecipare al progetto e, soprattutto, ha spiegato come il sistema richiesto sarà realizzato.
Prima dell'incontro, abbiamo identificato due rischi nel lavorare con un team privo del supporto di una grande azienda nazionale o internazionale:
- Gli specialisti potrebbero sovrastimare le proprie capacità e, di conseguenza, non riuscire a portare a termine il lavoro, ad esempio utilizzando software complessi o progettando algoritmi di partizionamento non fattibili.
- Dopo la realizzazione del progetto, il team potrebbe disintegrarsi e, di conseguenza, il supporto del prodotto risulterebbe a rischio.
Per ridurre questi rischi, abbiamo invitato ai nostri incontri i nostri specialisti di sviluppo. I dipendenti del potenziale appaltatore sono stati attentamente interrogati su cosa costituisca il sistema, come si prevede di realizzare il backup e su altre questioni in cui, come servizio operativo, non siamo abbastanza competenti.
Il verdetto è stato positivo: l'architettura della piattaforma BMS esistente è moderna, semplice e affidabile, può essere migliorata, lo schema proposto per il backup e la sincronizzazione è logico e funzionante.
Abbiamo affrontato il primo rischio. Il secondo è stato escluso, ricevendo dall'appaltatore conferma della disponibilità a fornirci il codice sorgente del sistema e la documentazione, oltre alla scelta del linguaggio di programmazione Python, ben noto ai nostri specialisti. Questo ci ha garantito la possibilità di mantenere il sistema autonomamente senza alcuna difficoltà e senza un lungo periodo di formazione del personale nel caso in cui l'azienda sviluppatrice abbandonasse il mercato.
Un ulteriore vantaggio della piattaforma era che era implementata in contenitori Docker: in questo ambiente funzionano il kernel, l'interfaccia web e il database del prodotto. Questo approccio offre numerosi vantaggi, tra cui una configurazione preimpostata per la massima velocità di distribuzione della soluzione rispetto al "classico" e un'aggiunta semplice di nuovi dispositivi nel sistema. Il principio del "tutto insieme" semplifica al massimo l'implementazione del sistema: basta decomprimere il sistema e può essere subito utilizzato.
Con questa soluzione è più facile fare copie del sistema, e migliorarne e implementarne gli aggiornamenti è possibile in un ambiente separato, senza fermare il funzionamento della soluzione nel suo complesso.
Dopo che entrambi i rischi sono stati minimizzati, il contraente ha fornito il preventivo. Questo ha affrontato tutti i parametri più importanti per noi del sistema BMS.
Riserva
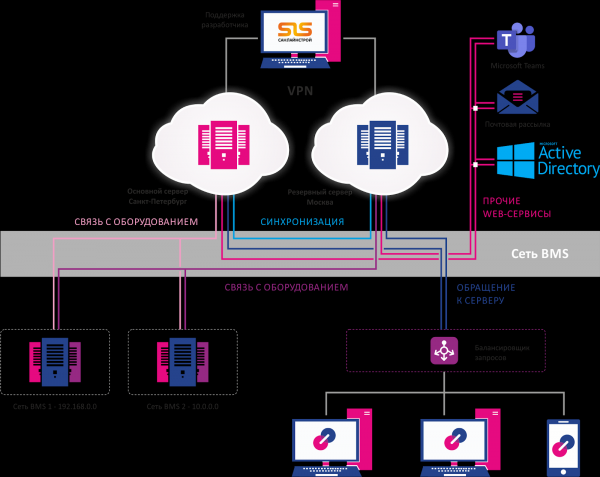
Il nuovo sistema BMS doveva trovarsi nel cloud, su una macchina virtuale.
Nessun hardware, nessun server e tutti i disagi e rischi legati a questo modello di distribuzione – la soluzione cloud ci ha permesso di eliminarli per sempre. È stato deciso che il sistema funzionerà nel nostro cloud su due sedi di data center a San Pietroburgo e Mosca. Questi sono due sistemi completamente funzionali che operano in modalità attiva standby con accesso per tutti i professionisti autorizzati.
I due sistemi si proteggono a vicenda, garantendo una piena riserva sia delle capacità di calcolo che dei canali di trasmissione dati. Sono state inoltre configurate ulteriori misure di sicurezza, compresi il backup dei dati e dei canali, dei sistemi e delle macchine virtuali nel loro complesso, e un backup separato del database una volta al mese (il più prezioso delle risorse in prospettiva di gestione e analisi).
Va notato che la riserva come opzione della soluzione BMS è stata sviluppata specificamente su nostra richiesta. Lo schema di riserva appariva in questo modo:
Supporto
Un punto fondamentale per un'efficace operazione della soluzione BMS è il supporto tecnico.
È tutto semplice: il nuovo sistema ci costerebbe 35.000 rubli al mese per un SLA di "risposta entro 8 ore", ovvero 35.000 x 12 / 80 = $5.250 all'anno. Il primo anno è gratuito.
A titolo di confronto: il supporto del vecchio BMS del fornitore ci costava 18.000 dollari all'anno, con un aumento della somma per ogni nuovo dispositivo aggiunto! Inoltre, l'azienda non forniva un manager dedicato; tutta l'interazione avveniva attraverso il manager delle vendite, il quale era interessato a noi come potenziale acquirente, con un corrispondente accentuato nella gestione delle richieste.
Per una spesa inferiore abbiamo ottenuto un supporto completo del prodotto, con un account manager che partecipava attivamente allo sviluppo, con un unico punto di accesso, ecc. Il supporto è diventato notevolmente più flessibile, grazie all'accesso diretto agli sviluppatori per correzioni rapide in qualsiasi aspetto del funzionamento del sistema, integrazione tramite API, ecc.
Aggiornamenti
Nel nuovo sistema BMS proposto, tutti gli aggiornamenti sono inclusi nel costo del supporto, ovvero non richiedono un pagamento aggiuntivo. L'unica eccezione riguarda lo sviluppo di funzionalità aggiuntive, al di fuori di quelle indicate nel documento dei requisiti.
Il sistema precedente prevedeva il pagamento sia per l'aggiornamento del software incorporato gratuito (come Java) sia per la correzione di errori. Non era possibile rinunciarvi; in assenza di aggiornamenti, il sistema in generale "rallentava" a causa delle vecchie versioni dei componenti interni.
E, ovviamente, non era possibile aggiornare il software senza acquistare un pacchetto di supporto.
Approccio flessibile
Un'altra esigenza fondamentale riguardava l'interfaccia. Volevamo garantire l'accesso tramite browser web da qualsiasi punto, senza la necessità della presenza di un ingegnere presso il centro dati. Inoltre, puntavamo a creare un'interfaccia animata, affinché la dinamica di funzionamento dell'infrastruttura fosse più visibile per gli ingegneri di guardia.
Inoltre, nel nuovo sistema era necessario garantire il supporto per le formule per il calcolo del funzionamento dei sensori virtuali nei sistemi ingegneristici – ad esempio, per la distribuzione ottimale delle potenze elettriche nelle rack con attrezzature. A tal fine, è necessario avere a disposizione tutte le operazioni matematiche abituali applicabili alle letture dei sensori.
In seguito, era necessario avere accesso a un database SQL con la possibilità di estrarre i dati necessari sul funzionamento delle attrezzature – in particolare, tutte le registrazioni sul monitoraggio di duemila dispositivi e duemila sensori virtuali, che generano circa ventimila variabili.
Era inoltre necessario un modulo di inventario delle attrezzature nel rack, in grado di fornire una rappresentazione grafica della disposizione dei dispositivi in ciascun'unità, con il calcolo del peso totale dell'hardware, la gestione della biblioteca dei dispositivi e informazioni dettagliate su ciascun elemento.
Conferma delle specifiche tecniche e firma del contratto
Quando è stato necessario iniziare a lavorare su un nuovo sistema, la corrispondenza con le 'grandi' aziende era ancora lontana dalla discussione sui costi delle loro offerte, quindi abbiamo confrontato l'allocazione ricevuta con i costi di aggiornamento del vecchio BMS (cfr. ), e alla fine si è rivelato più conveniente e conforme alle nostre esigenze.
È stata fatta la scelta.
Dopo la scelta del fornitore, gli avvocati hanno iniziato a redigere il contratto, mentre i team tecnici di entrambe le parti perfezionavano il capitolato tecnico. Come è noto, un capitolato tecnico dettagliato e ben redatto è la base del successo di qualsiasi lavoro. Maggiore è la specificità nel capitolato, minori saranno le delusioni, come 'ma noi volevamo diversamente'.
Fornirò due esempi di livello di dettaglio dei requisiti nel capitolato:
- I Centri Dati di vigilanza hanno l'autorità di aggiungere nuovi dispositivi al BMS, di solito si tratta di PDU. Nella vecchia BMS, questo corrispondeva al livello "administratore", che consentiva anche di modificare le impostazioni variabili di tutti i dispositivi, e non era possibile separare le funzioni. Questo non ci soddisfaceva. Nella versione base della nuova piattaforma, il sistema era simile. Abbiamo subito specificato nel documento di specifiche che volevamo separare questi ruoli: solo un dipendente autorizzato deve modificare le impostazioni, mentre i turni devono poter continuare ad aggiungere dispositivi. Questo schema è stato accettato per l'implementazione.
- In any standard BMS, there are three typical notification categories: RED – immediate action required, YELLOW – can be monitored, BLUE – "Informational." We have traditionally used "blue" notifications for monitoring the exceeding of commercial parameters, for example, exceeding the power limit of a client's rack. This type of notification was intended for managers and was not of interest to the operations staff; however, in the old BMS, it regularly cluttered the list of active incidents and hindered operational work. We considered the logic and color differentiation of the notification banners to be successful and retained it, but in the specifications, we specifically indicated that "blue" notifications should fall silently into a separate section without distracting the duty personnel, where they would be handled by commercial specialists.
Formats for building charts and generating reports, interface outlines, a list of devices to be monitored, and many other things were stipulated with a similar level of detail.
È stato un lavoro veramente creativo di tre gruppi di lavoro: il servizio clienti, che ha dettato le proprie esigenze e condizioni; i tecnici di entrambe le parti, incaricati di trasformare queste esigenze in documentazione tecnica; e il team di programmatori dell'appaltatore, che ha realizzato le richieste del cliente secondo la documentazione tecnica sviluppata... Alla fine, abbiamo adattato alcune delle nostre richieste non fondamentali alle funzionalità già esistenti della piattaforma, e l'appaltatore si è impegnato a scrivere quanto necessario per noi.
Lavoro parallelo di due sistemi
È giunto il momento di mettere in pratica. In termini pratici, significa che diamo all'appaltatore la possibilità di implementare un prototipo BMS nel nostro cloud virtuale e forniamo accesso di rete a tutti i dispositivi che necessitano di monitoraggio.
Tuttavia, il nuovo sistema non era ancora pronto per funzionare. In questa fase, era importante per noi mantenere il monitoraggio nel vecchio sistema e allo stesso tempo consentire l'accesso ai dispositivi nel nuovo sistema. Non è possibile costruire correttamente un sistema senza vedere i dispositivi in esso, che a loro volta non possono essere disconnessi dal monitoraggio del vecchio sistema.
Era incerto se i dispositivi avrebbero sopportato un'interrogazione simultanea da due sistemi senza prove reali. C'era la probabilità che un'interrogazione simultanea doppia portasse a frequenti mancate risposte dai dispositivi, e avremmo ricevuto numerosi errori riguardanti l'inaccessibilità dei dispositivi, il che avrebbe bloccato il funzionamento del vecchio sistema di monitoraggio.
Il reparto di rete ha creato percorsi virtuali dal prototipo del nuovo BMS, distribuito nel cloud, ai dispositivi, e abbiamo ottenuto risultati:
- i dispositivi collegati tramite il protocollo SNMP praticamente non si disconnettevano a causa delle richieste simultanee,
- i dispositivi collegati attraverso gateway con i protocolli modbus-TCP avevano problemi, che sono stati risolti con una riduzione ragionevole della loro frequenza di interrogazione.
E poi abbiamo iniziato a osservare come si stesse costruendo un nuovo sistema davanti ai nostri occhi, con dispositivi a noi già familiari, ma in un'interfaccia diversa: comoda, veloce e accessibile anche da telefono.
Di ciò che è stato ottenuto alla fine, parleremo nella terza parte del nostro articolo.
Fonte: habr.com
