

Sfondo
Ci sono distributori automatici di nostra progettazione. All'interno c'è un Raspberry Pi e alcuni dispositivi di fissaggio su una scheda separata. Sono collegati un accettatore di monete, un accettatore di banconote, un terminale bancario... Tutto è controllato da un programma autoprodotto. L'intera cronologia delle attività è registrata in un registro su una chiavetta USB (MicroSD), che viene poi trasmessa via Internet (tramite un modem USB) al server, dove viene memorizzata in un database. Le informazioni sulle vendite vengono caricate in 1C; è disponibile anche una semplice interfaccia web per il monitoraggio, ecc.
In altre parole, il giornale è di vitale importanza: per la contabilità (ricavi, vendite, ecc.), per il monitoraggio (tutti i tipi di guasti e altre circostanze di forza maggiore); si potrebbe dire che queste sono tutte le informazioni che abbiamo su questa macchina.
Problema
Le unità flash si dimostrano dispositivi molto inaffidabili. Si guastano con invidiabile regolarità. Questo porta sia a tempi di inattività del computer che (se per qualche motivo il log non può essere trasferito online) alla perdita di dati.
Questa non è la prima volta che utilizzo le chiavette USB. Prima di allora, c'era stato un altro progetto con più di cento dispositivi, in cui il diario era memorizzato su chiavette USB. Anche in questo caso, si sono verificati problemi di affidabilità: a volte il numero di dispositivi guasti al mese era di decine. Abbiamo provato diverse chiavette USB, comprese quelle di marca con memoria SLC, e alcuni modelli sono più affidabili di altri, ma la sostituzione delle chiavette non ha risolto radicalmente il problema.
Attenzione! Leggi tutto! Se non ti interessa il "perché", ma solo il "come", puoi andare direttamente a articolo.
Soluzione
La prima cosa che viene in mente è abbandonare la MicroSD, installare, ad esempio, un SSD e avviare il sistema da lì. Teoricamente possibile, forse, ma relativamente costoso e non così affidabile (viene aggiunto un adattatore USB-SATA; anche le statistiche di guasto degli SSD economici non sono incoraggianti).
Anche gli HDD USB non sembrano una soluzione particolarmente allettante.
Pertanto, siamo giunti a questa opzione: lasciare l'avvio da MicroSD, ma utilizzarle in modalità di sola lettura e memorizzare il registro di lavoro (e altre informazioni esclusive di un particolare componente hardware, come numero di serie, calibrazioni dei sensori, ecc.) da qualche altra parte.
L'argomento del FS di sola lettura per Raspberry Pi è già stato ampiamente studiato, in questo articolo non mi soffermerò sui dettagli dell'implementazione. (ma se c'è interesse, forse scriverò un mini-articolo su questo argomento)L'unica cosa che vorrei sottolineare è che, sia dall'esperienza personale che dalle recensioni di chi l'ha già implementata, si nota un guadagno in termini di affidabilità. Certo, è impossibile eliminare completamente i guasti, ma è possibile ridurne significativamente la frequenza. E le schede stanno diventando unificate, il che semplifica notevolmente la sostituzione per il personale di assistenza.
La parte hardware
Non c'erano particolari dubbi sulla scelta del tipo di memoria: NOR Flash.
argomenti:
- connessione semplice (il più delle volte il bus SPI, che abbiamo già sperimentato, quindi non sono previsti problemi hardware);
- prezzo ridicolo;
- protocollo operativo standard (l'implementazione è già presente nel kernel) Linux, se vuoi, puoi usarne uno di terze parti, che sono anch'essi presenti, oppure puoi anche scriverne uno tuo, fortunatamente è tutto semplice);
- affidabilità e risorse:
da un tipico foglio dati: i dati vengono memorizzati per 20 anni, 100000 cicli di cancellazione per ogni blocco;
da fonti terze: BER estremamente basso, non si postula la necessità di codici di correzione degli errori (alcuni articoli considerano ECC per NOR, ma di solito intendono MLC NOR, anche questo accade).
Stimiamo i requisiti in termini di volume e risorse.
Vorrei essere sicuro che i dati vengano salvati per diversi giorni. Questo è necessario affinché, in caso di problemi di connessione, la cronologia delle vendite non vada persa. Per questo periodo, ci concentreremo su 5 giorni. (anche tenendo conto dei fine settimana e dei giorni festivi) il problema può essere risolto.
Attualmente disponiamo di circa 100 kb di log al giorno (3-4 mila record), ma questa cifra è in graduale aumento: il dettaglio aumenta e vengono aggiunti nuovi eventi. Inoltre, a volte si verificano picchi di dati (ad esempio, alcuni sensori iniziano a generare falsi positivi). Calcoleremo 10 mila record da 100 byte, ovvero un megabyte al giorno.
In totale, ci sono 5 MB di dati puliti (ben compressi). Oltre a ciò, (stima approssimativa) 1 MB di dati di servizio.
Ciò significa che abbiamo bisogno di un chip da 8 MB se non utilizziamo la compressione, o da 4 MB se la utilizziamo. Cifre abbastanza realistiche per questo tipo di memoria.
Per quanto riguarda la risorsa: se pianifichiamo che la memoria venga completamente riscritta non più spesso di una volta ogni 5 giorni, allora in 10 anni di servizio otterremo meno di mille cicli di riscrittura.
Vi ricordo che il produttore ne promette centomila.
Un po' di informazioni su NOR vs NAND
Oggi, naturalmente, la memoria NAND è molto più diffusa, ma non la utilizzerei per questo progetto: la NAND, a differenza della NOR, richiede necessariamente l'uso di codici di correzione degli errori, una tabella dei blocchi danneggiati, ecc., e i chip NAND solitamente hanno molti più pin.
Gli svantaggi del NOR includono:
- piccolo volume (e, di conseguenza, prezzo elevato per megabyte);
- bassa velocità di scambio (dovuta in gran parte al fatto che viene utilizzata un'interfaccia seriale, solitamente SPI o I2C);
- cancellazione lenta (a seconda della dimensione del blocco, può richiedere da frazioni di secondo a diversi secondi).
Sembra che non ci sia nulla di critico per noi, quindi continuiamo.
Se siete interessati ai dettagli, è stato selezionato un microcircuito (tuttavia, questo non è essenziale, ci sono molti analoghi sul mercato che sono compatibili in termini di pinout e sistema di comando; anche se volessimo installare un microcircuito di un altro produttore e/o di un altro volume, tutto funzionerà senza modificare il codice).
Io uso quello integrato nel kernel Linux Il driver, su Raspberry, grazie al supporto dell'overlay del device tree, è molto semplice: basta inserire l'overlay compilato in /boot/overlays e modificare leggermente /boot/config.txt.
Esempio di file dts
A dire il vero, non sono sicuro che sia scritto senza errori, ma funziona.
/*
* Device tree overlay for at25 at spi0.1
*/
/dts-v1/;
/plugin/;
/ {
compatible = "brcm,bcm2835", "brcm,bcm2836", "brcm,bcm2708", "brcm,bcm2709";
/* disable spi-dev for spi0.1 */
fragment@0 {
target = <&spi0>;
__overlay__ {
status = "okay";
spidev@1{
status = "disabled";
};
};
};
/* the spi config of the at25 */
fragment@1 {
target = <&spi0>;
__overlay__ {
#address-cells = <1>;
#size-cells = <0>;
flash: m25p80@1 {
compatible = "atmel,at25df321a";
reg = <1>;
spi-max-frequency = <50000000>;
/* default to false:
m25p,fast-read ;
*/
};
};
};
__overrides__ {
spimaxfrequency = <&flash>,"spi-max-frequency:0";
fastread = <&flash>,"m25p,fast-read?";
};
};E un'altra riga in config.txt
dtoverlay=at25:spimaxfrequency=50000000Tralascio la descrizione del collegamento del microcircuito al Raspberry Pi. Da un lato, non sono un esperto di elettronica, dall'altro, tutto è banale anche per me: il microcircuito ha solo 8 pin, di cui servono massa, alimentazione, SPI (CS, SI, SO, SCK); i livelli coincidono con quelli del Raspberry Pi, non è necessario alcun ulteriore fissaggio: basta collegare i 6 contatti specificati.
Formulazione del problema
Come al solito, la formulazione del problema passa attraverso diverse iterazioni, e credo sia giunto il momento di un'altra. Quindi fermiamoci, mettiamo insieme quanto già scritto e chiariamo i dettagli che rimangono nell'ombra.
Abbiamo quindi deciso che il registro verrà archiviato in SPI NOR Flash.
Cos'è NOR Flash per chi non lo sapesse
Si tratta di una memoria non volatile con la quale è possibile eseguire tre operazioni:
- lettura:
La lettura più comune: passiamo l'indirizzo e leggiamo tutti i byte di cui abbiamo bisogno; - Запись:
La scrittura su una flash NOR sembra normale, ma ha una particolarità: è possibile modificare solo 1 in 0, ma non viceversa. Ad esempio, se avessimo 0x55 in una cella di memoria, dopo aver scritto 0x0f, 0x05 sarebbe già stato memorizzato lì. (vedi tabella sotto); - Cancellare:
Naturalmente, dobbiamo essere in grado di eseguire l'operazione opposta, ovvero trasformare 0 in 1: a questo serve l'operazione di cancellazione. A differenza delle prime due, questa non opera sui byte, ma sui blocchi (il blocco di cancellazione minimo nel chip selezionato è di 4 KB). La cancellazione distrugge l'intero blocco e questo è l'unico modo per trasformare 0 in 1. Pertanto, quando si lavora con la memoria flash, è spesso necessario allineare le strutture dati al limite del blocco di cancellazione.
Scrivendo a NOR Flash:
dati binari
è stato
01010101
Registrato
00001111
E 'diventato
00000101
Il registro stesso è una sequenza di record di lunghezza variabile. Un record tipico è lungo circa 30 byte (anche se a volte i record sono lunghi diversi kilobyte). In questo caso li utilizziamo semplicemente come un insieme di byte, ma se siete interessati, all'interno dei record viene utilizzato CBOR.
Oltre al registro, dobbiamo memorizzare alcune informazioni di "configurazione", sia aggiornate che non: ID di alcuni dispositivi, calibrazioni dei sensori, flag "dispositivo temporaneamente disabilitato", ecc.
Queste informazioni sono un set di record chiave-valore, anch'essi memorizzati nel CBOR. Non disponiamo di molte di queste informazioni (al massimo pochi kilobyte) e vengono aggiornate raramente.
In futuro lo chiameremo contesto.
Se ricordate come inizia questo articolo, è molto importante garantire un'archiviazione affidabile dei dati e, se possibile, un funzionamento ininterrotto anche in caso di guasti hardware/corruzione dei dati.
Quali fonti di problemi possono essere prese in considerazione?
- Interruzione di corrente durante le operazioni di scrittura/cancellazione. Questo rientra nella categoria "nessuna difesa contro un piede di porco".
Informazioni da su stackexchange: quando l'alimentazione viene interrotta mentre si lavora con la flash, sia la cancellazione (impostata su 1) che la scrittura (impostata su 0) portano a un comportamento indefinito: i dati possono essere scritti, scritti parzialmente (ad esempio, abbiamo trasferito 10 byte/80 bit, ma siamo riusciti a scrivere solo 45 bit), è anche possibile che alcuni bit finiscano in uno stato "intermedio" (la lettura può produrre 0 o 1); - Errori nella memoria flash stessa.
Il BER, sebbene molto basso, non può essere uguale a zero; - Errori del bus
I dati trasmessi tramite SPI non sono protetti in alcun modo; potrebbero verificarsi errori di bit singoli ed errori di sincronizzazione, ovvero perdita o inserimento di bit (che comporta una distorsione massiccia dei dati); - Altri errori/problemi
Errori di codice, problemi del Raspberry, intervento alieno...
Ho formulato i requisiti che, a mio avviso, devono essere soddisfatti per garantire l'affidabilità:
- - i record devono essere scritti immediatamente nella memoria flash; la scrittura ritardata non è considerata; - se si verifica un errore, questo deve essere rilevato ed elaborato il prima possibile; - il sistema deve, se possibile, recuperare dagli errori.
(un esempio tratto dalla vita di “come non dovrebbe essere”, che credo tutti abbiano incontrato: dopo un riavvio di emergenza, il file system è “rotto” e il sistema operativo non si avvia)
Idee, approcci, pensieri
Quando ho iniziato a pensare a questo problema, mi sono venute in mente un sacco di idee, ad esempio:
- utilizzare la compressione dei dati;
- utilizzare strutture dati intelligenti, come ad esempio memorizzare le intestazioni dei record separatamente dai record stessi, in modo che se si verifica un errore in un record, il resto possa essere letto senza problemi;
- utilizzare campi di bit per controllare il completamento della scrittura quando l'alimentazione viene interrotta;
- memorizzare i checksum per tutto e per tutti;
- utilizzare una qualche forma di codifica di correzione degli errori.
Alcune di queste idee sono state utilizzate, altre sono state abbandonate. Esaminiamole in ordine.
Compressione dei dati
Gli eventi stessi che registriamo nel registro sono piuttosto uniformi e ripetibili ("lanciato una moneta da 5 rubli", "premuto il pulsante del cambio", ...). Pertanto, la compressione dovrebbe essere piuttosto efficace.
L'overhead della compressione è insignificante (il nostro processore è piuttosto potente, anche il primo Pi aveva un core con una frequenza di 700 MHz, i modelli attuali hanno diversi core con una frequenza di oltre un gigahertz), la velocità di scambio con l'archiviazione è bassa (diversi megabyte al secondo), la dimensione dei record è ridotta. In generale, se la compressione ha un effetto sulle prestazioni, sarà solo positivo. (assolutamente acritico, sto solo affermando)Inoltre, non ne abbiamo uno veramente integrato, ma uno normale. Linux — quindi l'implementazione non dovrebbe richiedere molto sforzo (è sufficiente collegare la libreria e utilizzare alcune sue funzioni).
È stato preso un pezzo di registro da un dispositivo funzionante (1.7 MB, 70 mila record) e prima è stata verificata la comprimibilità utilizzando gzip, lz4, lzop, bzip2, xz, zstd disponibili sul computer.
- gzip, xz, zstd hanno mostrato risultati simili (40 Kb).
Sono rimasto sorpreso che il famoso xz si sia mostrato qui al livello di gzip o zstd; - lzip con le impostazioni predefinite ha dato risultati leggermente peggiori;
- lz4 e lzop non hanno mostrato risultati molto buoni (150 Kb);
- bzip2 ha mostrato risultati sorprendentemente buoni (18 Kb).
Quindi i dati si comprimono molto bene.
Quindi (se non troviamo difetti fatali) la compressione ci sarà! Semplicemente perché sulla stessa unità flash ci staranno più dati.
Pensiamo agli svantaggi.
Il primo problema: abbiamo già concordato che ogni record debba essere trasferito immediatamente sulla flash. Di solito, l'archiviatore raccoglie i dati dal flusso di input finché non decide che è il momento di scriverli sull'output. Dobbiamo ottenere immediatamente un blocco di dati compresso e salvarlo nella memoria non volatile.
Vedo tre modi:
- Comprimi ogni record utilizzando la compressione del dizionario anziché gli algoritmi discussi sopra.
È un'opzione perfettamente praticabile, ma non mi piace. Per garantire un livello di compressione più o meno decente, il dizionario deve essere "adattato" a dati specifici; qualsiasi modifica comporterà un calo catastrofico del livello di compressione. Sì, il problema può essere risolto creando una nuova versione del dizionario, ma è un vero grattacapo: dovremo memorizzare tutte le versioni del dizionario; in ogni voce, dovremo indicare con quale versione del dizionario è stata compressa... - Comprimere ogni record utilizzando algoritmi "classici", ma indipendentemente dagli altri.
Gli algoritmi di compressione in esame non sono progettati per funzionare con record di queste dimensioni (decine di byte), il rapporto di compressione sarà chiaramente inferiore a 1 (ovvero un aumento del volume dei dati anziché della compressione); - Eseguire un FLUSH dopo ogni inserimento.
Molte librerie di compressione supportano FLUSH. Si tratta di un comando (o parametro della procedura di compressione), ricevuto il quale l'archiviatore forma un flusso compresso in base al quale è possibile ripristinare tutti dati non compressi che sono già stati ricevuti. Questo analogicosyncnei file system ocommitin SQL.
Ciò che è importante è che le successive operazioni di compressione potranno utilizzare il dizionario accumulato e che il rapporto di compressione non ne risentirà tanto quanto nella versione precedente.
Penso che sia ovvio che ho scelto la terza opzione, vediamola più in dettaglio.
L'ho trovato informazioni su FLUSH in zlib.
Ho eseguito un test del ginocchio basato sull'articolo, ho preso 70 mila voci di registro da un dispositivo reale, con una dimensione di pagina di 60 KB (torneremo più avanti sul tema delle dimensioni della pagina) ricevuto:
Dati iniziali
Compressione gzip -9 (senza FLUSH)
zlib con Z_PARTIAL_FLUSH
zlib con Z_SYNC_FLUSH
Volume, Kb
1692
40
352
604
A prima vista, il costo di FLUSH è eccessivamente elevato, ma in realtà ci troviamo di fronte a una scelta difficile: o non comprimere affatto, o comprimere (in modo piuttosto efficace) con FLUSH. Non dobbiamo dimenticare che abbiamo 70 record, la ridondanza introdotta da Z_PARTIAL_FLUSH è di soli 4-5 byte per record. E il rapporto di compressione si è rivelato quasi 5:1, il che è più che un risultato eccellente.
Può sembrare sorprendente, ma Z_SYNC_FLUSH è in realtà un modo più efficiente per eseguire FLUSH
Utilizzando Z_SYNC_FLUSH, gli ultimi 4 byte di ogni record saranno sempre 0x00, 0x00, 0xff, 0xff. Se li conosciamo, non possiamo memorizzarli, quindi la dimensione finale è di soli 324 KB.
L'articolo a cui ho fatto riferimento contiene una spiegazione:
Viene aggiunto un nuovo blocco di tipo 0 con contenuto vuoto.
Un blocco di tipo 0 con contenuto vuoto è costituito da:
- l'intestazione del blocco a tre bit;
- da 0 a 7 bit uguali a zero, per ottenere l'allineamento dei byte;
- la sequenza di quattro byte 00 00 FF FF.
Come si può facilmente vedere, nell'ultimo blocco prima di questi 4 byte ci sono da 3 a 10 bit zero. Tuttavia, la pratica ha dimostrato che in realtà ci sono almeno 10 bit zero.
Si scopre che blocchi di dati così brevi vengono solitamente (sempre?) codificati utilizzando un blocco di tipo 1 (blocco fisso), che termina necessariamente con 7 bit zero, quindi otteniamo 10-17 bit zero garantiti (e il resto sarà zero con una probabilità di circa il 50%).
Quindi, nei dati di prova nel 100% dei casi prima di 0x00, 0x00, 0xff, 0xff c'è un byte zero e in più di un terzo dei casi ci sono due byte zero (forse il punto è che uso CBOR binario e se usassi JSON di testo, incontrerei più spesso blocchi di tipo 2 - blocco dinamico, rispettivamente, incontrerei blocchi senza byte zero aggiuntivi prima di 0x00, 0x00, 0xff, 0xff).
In totale, utilizzando i dati di prova disponibili, è possibile contenere meno di 250 KB di dati compressi.
Possiamo risparmiare ancora un po' manipolando i bit: ora ignoriamo la presenza di alcuni bit zero alla fine di un blocco, e anche alcuni bit all'inizio di un blocco non vengono modificati...
Ma qui ho preso la ferma decisione di fermarmi, altrimenti a questo ritmo avrei potuto ritrovarmi a sviluppare il mio archiviatore.
In totale, ho ottenuto 3-4 byte per record dai miei dati di prova, con un rapporto di compressione superiore a 6:1. Onestamente, non mi aspettavo un risultato del genere; a mio parere, un risultato migliore di 2:1 è già un risultato che giustifica l'uso della compressione.
Tutto è fantastico, ma zlib (deflate) è ancora un algoritmo di compressione arcaico, ben meritato e un po' antiquato. Il fatto che gli ultimi 32K del flusso di dati non compressi vengano utilizzati come dizionario appare strano oggi (ovvero, se un blocco di dati è molto simile a quello presente nel flusso di input 40K fa, l'archiviazione verrà riavviata e non farà riferimento alla voce precedente). Negli archiviatori moderni di tendenza, la dimensione del dizionario è spesso misurata in megabyte, non in kilobyte.
Continuiamo quindi la nostra mini-ricerca sugli archivisti.
Successivamente, ho provato bzip2 (ricordate, senza FLUSH mostrava un rapporto di compressione fantastico, quasi 100:1). Purtroppo, con FLUSH le cose si sono rivelate molto peggiori: la dimensione dei dati compressi era maggiore di quella dei dati non compressi.
Le mie ipotesi sulle ragioni del fallimento
Libbz2 offre solo un'opzione di svuotamento, che sembra svuotare il dizionario (analogamente a Z_FULL_FLUSH in zlib), quindi non ha senso parlare di una compressione efficace dopo questo.
L'ultimo ad essere testato è stato zstd. A seconda dei parametri, comprime allo stesso livello di gzip, ma molto più velocemente, o meglio di gzip.
Purtroppo anche con FLUSH si è dimostrato “non molto buono”: la dimensione dei dati compressi era di circa 700 KB.
Я Nella pagina del progetto su github ho ricevuto la risposta che vale la pena contare fino a 10 byte di dati di servizio per ogni blocco di dati compressi, il che è vicino ai risultati ottenuti, non sarà possibile recuperare con deflate.
A questo punto ho deciso di smettere di sperimentare con gli archiviatori (vi ricordo che xz, lzip, lzo, lz4 non si sono ancora mostrati nella fase di test senza FLUSH e non ho preso in considerazione algoritmi di compressione più esotici).
Torniamo ai problemi dell'archiviazione.
Il secondo problema (come si dice in ordine, non in ordine di importanza) è che i dati compressi costituiscono un flusso unico, in cui vengono costantemente fatti riferimenti a sezioni precedenti. Pertanto, se una sezione di dati compressi viene danneggiata, si perdono non solo i blocchi di dati non compressi ad essa associati, ma anche tutti quelli successivi.
Esistono diversi approcci per risolvere questo problema:
- Prevenire il verificarsi del problema: aggiungere ridondanza ai dati compressi per consentire il rilevamento e la correzione degli errori; ne parleremo più avanti;
- Ridurre al minimo le conseguenze se si verifica un problema
Abbiamo già detto in precedenza che è possibile comprimere ogni blocco di dati in modo indipendente e che il problema scomparirà da solo (il danneggiamento di un blocco porterà alla perdita dei dati di un solo blocco). Tuttavia, questo è un caso estremo, in cui la compressione dei dati sarà inefficace. L'estremo opposto: utilizzare tutti i 4 MB del nostro chip come un unico archivio, il che ci garantirà un'eccellente compressione, ma conseguenze catastrofiche in caso di danneggiamento dei dati.
Sì, è necessario un compromesso in termini di affidabilità. Ma dobbiamo ricordare che stiamo sviluppando un formato di archiviazione dati per memoria non volatile con un BER estremamente basso e una durata dichiarata di archiviazione dati di 20 anni.
Durante gli esperimenti ho scoperto che perdite più o meno evidenti nel livello di compressione iniziano con blocchi di dati compressi di dimensioni inferiori a 10 KB.
In precedenza è stato detto che la memoria utilizzata è di tipo paging, non vedo alcun motivo per cui non si dovrebbe usare la mappatura "una pagina - un blocco di dati compressi".
Ciò significa che la dimensione minima ragionevole di una pagina è di 16 KB (con una riserva per le informazioni di servizio). Tuttavia, una dimensione di pagina così ridotta impone restrizioni significative alla dimensione massima dei record.
Sebbene non mi aspetti di avere record più grandi di qualche kilobyte in formato compresso, ho deciso di utilizzare 32K pagine (il che mi dà 128 pagine per chip).
Sommario:
- Memorizziamo i dati compressi utilizzando zlib (deflate);
- Per ogni voce impostiamo Z_SYNC_FLUSH;
- Per ogni record compresso, tagliamo i byte finali (ad esempio 0x00, 0x00, 0xff, 0xff); nell'intestazione indichiamo quanti byte tagliamo;
- Memorizziamo i dati in pagine da 32 Kb; all'interno di ogni pagina c'è un singolo flusso di dati compressi; su ogni pagina iniziamo nuovamente la compressione.
E, prima di concludere con la compressione, vorrei richiamare l'attenzione sul fatto che otteniamo solo pochi byte di dati compressi per record, quindi è estremamente importante non gonfiare le informazioni del servizio: ogni byte conta.
Memorizzazione delle intestazioni dei dati
Poiché disponiamo di record di lunghezza variabile, dobbiamo in qualche modo determinare il posizionamento/i limiti dei record.
Conosco tre approcci:
- Tutti i record vengono memorizzati in un flusso continuo: prima l'intestazione del record contenente la lunghezza, quindi il record stesso.
In questa variante, sia le intestazioni che i dati possono avere lunghezza variabile.
In sostanza, otteniamo un elenco collegato singolarmente che viene utilizzato in ogni momento; - Le intestazioni e i record stessi vengono memorizzati in flussi separati.
Utilizzando intestazioni di lunghezza costante, garantiamo che il danneggiamento di un'intestazione non influisca sulle altre.
Un approccio simile viene utilizzato, ad esempio, in molti file system; - I record vengono memorizzati in un flusso continuo; il confine del record è determinato da un marcatore (un simbolo/sequenza di simboli proibiti all'interno dei blocchi di dati). Se un marcatore viene rilevato all'interno di un record, lo sostituiamo con una sequenza (eseguiamo l'escape).
Un approccio simile viene utilizzato, ad esempio, nel protocollo PPP.
Illustrerò.
Opzione 1:

Qui tutto è molto semplice: conoscendo la lunghezza del record possiamo calcolare l'indirizzo dell'intestazione successiva. Quindi ci spostiamo tra le intestazioni finché non incontriamo un'area riempita con 0xff (area libera) o la fine della pagina.
Opzione 2:

A causa della lunghezza variabile del record, non possiamo prevedere in anticipo quanti record (e quindi intestazioni) saranno necessari per pagina. Possiamo distribuire le intestazioni e i dati stessi su pagine diverse, ma preferisco un altro approccio: posizioniamo sia le intestazioni che i dati su una pagina, ma le intestazioni (di dimensione costante) iniziano dall'inizio della pagina e i dati (di lunghezza variabile) iniziano dalla fine. Non appena si "incontrano" (non c'è abbastanza spazio libero per un nuovo record), consideriamo la pagina piena.
Opzione 3:

Non è necessario memorizzare la lunghezza o altre informazioni sulla posizione dei dati nell'intestazione: sono sufficienti i marcatori che indicano i limiti dei record. Tuttavia, i dati devono essere elaborati durante la scrittura/lettura.
Io userei 0xff (che è ciò con cui viene riempita la pagina dopo la cancellazione) come marcatore, quindi l'area libera non verrà sicuramente trattata come dati.
Tabella comparativa:
opzione 1
opzione 2
opzione 3
Tolleranza agli errori
-
+
+
densità
+
-
+
Complessità di implementazione
*
**
**
L'opzione 1 presenta un difetto fatale: se una delle intestazioni viene danneggiata, l'intera catena successiva viene distrutta. Le altre opzioni consentono di ripristinare parte dei dati anche in caso di danni ingenti.
Ma qui è opportuno ricordare che abbiamo deciso di memorizzare i dati in forma compressa e comunque perdiamo tutti i dati della pagina dopo un record "rotto", quindi anche se c'è un segno meno nella tabella, non ne teniamo conto.
Compattezza:
- nella prima opzione dobbiamo solo memorizzare la lunghezza nell'intestazione, se utilizziamo interi di lunghezza variabile, nella maggior parte dei casi possiamo cavarcela con un byte;
- nella seconda opzione dobbiamo memorizzare l'indirizzo di partenza e la lunghezza; il record deve essere di dimensione costante, stimo 4 byte per record (due byte per l'offset e due byte per la lunghezza);
- La terza opzione richiede solo un carattere per indicare l'inizio della registrazione, inoltre la registrazione stessa aumenterà dell'1-2% a causa dello screening. Nel complesso, è approssimativamente alla pari con la prima opzione.
Inizialmente, ho considerato la seconda opzione come quella principale (e ne ho persino scritto un'implementazione). L'ho abbandonata solo quando ho deciso di usare la compressione.
Forse un giorno utilizzerò anch'io questa opzione. Ad esempio, se dovessi gestire l'archiviazione dei dati di una nave spaziale in viaggio tra la Terra e Marte, i requisiti di affidabilità, radiazioni cosmiche, ecc. sarebbero completamente diversi.
Per quanto riguarda la terza opzione: ho dato due stelle per la complessità dell'implementazione semplicemente perché non mi piace perdere tempo con l'escape, cambiare la lunghezza nel processo, ecc. Sì, forse sono di parte, ma dovrò scrivere il codice: perché costringermi a fare qualcosa che non mi piace?
Sommario: Abbiamo scelto l'opzione di archiviazione sotto forma di catene "intestazione con lunghezza - dati di lunghezza variabile" per la sua efficienza e facilità di implementazione.
Utilizzo di campi di bit per monitorare il successo delle operazioni di scrittura
Non ricordo più da dove ho preso l'idea, ma assomiglia più o meno a questo:
Per ogni voce, allochiamo diversi bit per memorizzare i flag.
Come abbiamo detto prima, dopo la cancellazione tutti i bit vengono riempiti con 1 e possiamo cambiare 1 in 0, ma non viceversa. Quindi per "flag non impostato" utilizziamo 1, per "flag impostato" - 0.
Ecco come potrebbe apparire l'inserimento di un record di lunghezza variabile nella memoria flash:
- Impostare il flag “lunghezza registrazione avviata”;
- Scriviamo la lunghezza;
- Impostare il flag “registrazione dati avviata”;
- Scriviamo dati;
- Impostiamo il flag “registrazione terminata”.
Inoltre, avremo un flag "si è verificato un errore", per un totale di 4 flag bit.
In questo caso abbiamo due stati stabili “1111” – la registrazione non è iniziata e “1000” – la registrazione è avvenuta correttamente; in caso di interruzione imprevista del processo di registrazione otterremo stati intermedi, che potremo rilevare ed elaborare in seguito.
L'approccio è interessante, ma protegge solo da improvvise interruzioni di corrente e guasti simili, il che è ovviamente importante, ma non è l'unica (e nemmeno la principale) causa di possibili guasti.
Sommario: Andiamo avanti alla ricerca di una buona soluzione.
Checksum
I checksum forniscono anche un modo per verificare (con ragionevole probabilità) che stiamo leggendo esattamente ciò che avrebbe dovuto essere scritto. E, a differenza dei campi di bit discussi in precedenza, funzionano sempre.
Se consideriamo l'elenco delle potenziali fonti di problemi di cui abbiamo parlato sopra, il checksum è in grado di riconoscere un errore indipendentemente dalla sua origine. (tranne, forse, per gli alieni malvagi, che possono anche falsificare il checksum).
Quindi, se il nostro obiettivo è verificare che i dati siano integri, i checksum sono un'ottima idea.
La scelta dell'algoritmo per il calcolo del checksum non ha sollevato dubbi: CRC. Da un lato, le proprietà matematiche consentono il rilevamento al 100% di errori di alcuni tipi, dall'altro, su dati casuali, questo algoritmo mostra solitamente una probabilità di collisione non molto superiore al limite teorico.  Potrebbe non essere l'algoritmo più veloce e potrebbe non avere sempre il minor numero di collisioni, ma ha una qualità molto importante: nei test che ho eseguito, non c'erano pattern in base ai quali avrebbe fallito in modo evidente. La stabilità è la qualità principale in questo caso.
Potrebbe non essere l'algoritmo più veloce e potrebbe non avere sempre il minor numero di collisioni, ma ha una qualità molto importante: nei test che ho eseguito, non c'erano pattern in base ai quali avrebbe fallito in modo evidente. La stabilità è la qualità principale in questo caso.
Esempio di studio volumetrico: , (link a narod.ru, mi dispiace).
Tuttavia, il compito di scegliere un checksum non è completo: il CRC è un'intera famiglia di checksum. È necessario decidere la lunghezza e quindi scegliere un polinomio.
Scegliere la lunghezza del checksum non è una questione così semplice come sembra a prima vista.
Lasciatemi spiegare:
Calcoliamo la probabilità di errore in ogni byte  e il checksum ideale, calcoliamo il numero medio di errori per milione di record:
e il checksum ideale, calcoliamo il numero medio di errori per milione di record:
Dati, byte
Somma di controllo, byte
Errori non rilevati
Rilevamento di errori falsi positivi
Numero totale di risposte errate
1
0
1000
0
1000
1
1
4
999
1003
1
2
≈0
1997
1997
1
4
≈0
3990
3990
10
0
9955
0
9955
10
1
39
990
1029
10
2
≈0
1979
1979
10
4
≈0
3954
3954
1000
0
632305
0
632305
1000
1
2470
368
2838
1000
2
10
735
745
1000
4
≈0
1469
1469
Sembrerebbe tutto semplice: basta scegliere la lunghezza del checksum con un minimo di falsi positivi in base alla lunghezza dei dati protetti e il gioco è fatto.
Tuttavia, c'è un problema con i checksum brevi: sebbene siano efficaci nel rilevare errori di singoli bit, possono, con una probabilità piuttosto elevata, accettare dati completamente casuali come corretti. C'era già un articolo su Habr che descriveva .
Pertanto, per rendere praticamente impossibile la corrispondenza casuale dei checksum, è opportuno utilizzare checksum di 32 bit o più. (per lunghezze superiori a 64 bit, vengono solitamente utilizzate funzioni hash crittografiche).
Nonostante avessi scritto in precedenza che dobbiamo risparmiare spazio a tutti i costi, continueremo a usare un checksum a 32 bit (16 bit non sono sufficienti, la probabilità di una collisione è superiore allo 0.01%; e 24 bit, come si dice, non sono né qui né là).
A questo punto potrebbe sorgere un'obiezione: abbiamo risparmiato ogni byte scegliendo la compressione per ottenere ora 4 byte contemporaneamente? Non sarebbe stato meglio non comprimere e non aggiungere un checksum? Certo che no, la mancanza di compressione non significa, che non abbiamo bisogno di controlli di integrità.
Non reinventeremo la ruota quando sceglieremo un polinomio, ma prenderemo il ormai popolare CRC-32C.
Questo codice rileva errori a 6 bit su pacchetti fino a 22 byte (probabilmente il caso più comune per noi), errori a 4 bit su pacchetti fino a 655 byte (anche questo un caso comune per noi), errori a 2 o qualsiasi numero dispari di bit su pacchetti di qualsiasi lunghezza ragionevole.
Se qualcuno è interessato ai dettagli
informazioni su CRC.
su — forse il principale specialista CRC del pianeta.
В c'è , che fornisce parametri leggermente migliori per le lunghezze dei pacchetti che ci interessano, ma non ho ritenuto significativa la differenza e non mi sono ritenuto abbastanza competente da scegliere un codice personalizzato invece di quello standard e ben studiato.
Inoltre, poiché i nostri dati sono compressi, sorge spontanea la domanda: dovremmo calcolare il checksum dei dati compressi o non compressi?
Argomenti a favore del calcolo del checksum dei dati non compressi:
- in ultima analisi dobbiamo verificare la sicurezza dell'archiviazione dei dati, quindi la controlliamo direttamente (allo stesso tempo, verranno controllati eventuali errori nell'implementazione della compressione/decompressione, danni causati da una memoria difettosa, ecc.);
- l'algoritmo deflate in zlib ha un'implementazione abbastanza matura e non dovrebbe cadere con dati di input "storti", inoltre, è spesso in grado di rilevare autonomamente errori nel flusso di input, riducendo la probabilità complessiva di non rilevare un errore (ho condotto un test con l'inversione di un singolo bit in un record breve, zlib ha rilevato un errore in circa un terzo dei casi).
Argomenti contro il calcolo del checksum dei dati non compressi:
- Il CRC è “su misura” specificamente per i pochi errori di bit tipici della memoria flash (un errore di bit in un flusso compresso può causare un cambiamento enorme nel flusso di output, sul quale, in teoria, possiamo “catturare” una collisione);
- Non mi piace molto l'idea di alimentare il decompressore con dati potenzialmente danneggiati, , come reagirà.
In questo progetto ho deciso di allontanarmi dalla pratica comune di memorizzare un checksum di dati non compressi.
Sommario: Utilizziamo CRC-32C, calcoliamo il checksum dai dati nel formato in cui vengono scritti sulla flash (dopo la compressione).
Ridondanza
L'uso di una codifica ridondante non elimina ovviamente la perdita di dati; tuttavia, può ridurre significativamente (spesso di molti ordini di grandezza) la probabilità di una perdita irreparabile di dati.
Per correggere gli errori possiamo utilizzare diversi tipi di ridondanza.
I codici di Hamming possono correggere errori di singoli bit, i codici Reed-Solomon sono simbolici, più copie di dati insieme a checksum o una codifica come RAID-6 possono aiutare a recuperare i dati anche in caso di danneggiamento massiccio.
Inizialmente ero convinto dell'uso diffuso della codifica con correzione degli errori, ma poi ho capito che prima dobbiamo avere un'idea degli errori da cui vogliamo proteggerci e poi scegliere la codifica.
Abbiamo detto prima che gli errori devono essere identificati il più rapidamente possibile. In quali momenti potremmo riscontrare errori?
- Registrazione non completata (per qualche motivo, durante la registrazione è mancata la corrente, il Raspberry si è bloccato, …)
Purtroppo, in caso di un errore del genere, l'unica opzione è ignorare i record non validi e considerare i dati persi; - Errori di scrittura (per qualche motivo, nella memoria flash è stato scritto qualcosa di diverso da ciò che era stato scritto)
Possiamo rilevare immediatamente tali errori se eseguiamo una lettura di controllo subito dopo la registrazione; - Corruzione dei dati nella memoria durante l'archiviazione;
- Errori di lettura
Per correggere l'errore, se il checksum non corrisponde, è sufficiente ripetere la lettura più volte.
In altre parole, solo gli errori del terzo tipo (corruzione spontanea dei dati durante l'archiviazione) non possono essere corretti senza una codifica di correzione degli errori. Sembra che tali errori siano ancora estremamente improbabili.
Sommario: si è deciso di abbandonare la codifica ridondante, ma se l'operazione dimostra l'erroneità di questa decisione, allora si torna a considerare la questione (con le statistiche già accumulate sui fallimenti, che consentiranno di scegliere il tipo di codifica ottimale).
altro
Naturalmente, il formato dell'articolo non consente di giustificare ogni bit nel formato (e sono già senza forze), quindi rivedrò brevemente alcuni punti che non sono stati toccati in precedenza.
- Si è deciso di rendere tutte le pagine "uguali"
Ciò significa che non ci saranno pagine speciali con metadati, flussi separati, ecc., ma ci sarà un unico flusso che riscrive tutte le pagine a turno.
Ciò garantisce un'usura uniforme delle pagine, nessun singolo punto di guasto e semplicemente una bella finitura; - È essenziale prevedere il versioning del formato.
Un formato senza numero di versione nell'intestazione è malvagio!
Basta aggiungere all'intestazione della pagina un campo con un certo Numero Magico (firma), che indicherà la versione del formato utilizzata (Non credo che ce ne saranno nemmeno una dozzina in pratica); - Utilizzare un'intestazione di lunghezza variabile per i record (ce ne sono molti), cercando di renderla lunga 1 byte nella maggior parte dei casi;
- Per codificare la lunghezza dell'intestazione e la lunghezza della parte troncata del record compresso, utilizzare codici binari a lunghezza variabile.
È stato molto utile Codici di Huffman. In pochi minuti siamo riusciti a selezionare i codici di lunghezza variabile richiesti.
Descrizione del formato di archiviazione dei dati
Ordine dei byte
I campi più grandi di un byte vengono memorizzati nel formato big-endian (ordine dei byte di rete), ovvero 0x1234 viene scritto come 0x12, 0x34.
Divisione in pagine
Tutta la memoria flash è divisa in pagine di uguali dimensioni.
La dimensione predefinita della pagina è 32 Kb, ma non più di 1/4 della dimensione totale del chip di memoria (per un chip da 4 MB, ciò equivale a 128 pagine).
Ogni pagina memorizza i dati in modo indipendente dalle altre (vale a dire che i dati di una pagina non fanno riferimento ai dati di un'altra pagina).
Tutte le pagine sono numerate in ordine naturale (in ordine crescente di indirizzi), a partire dal numero 0 (la pagina zero inizia con l'indirizzo 0, la prima con 32 Kb, la seconda con 64 Kb, ecc.)
Il chip di memoria viene utilizzato come buffer ad anello, vale a dire che prima la registrazione va alla pagina numero 0, poi alla pagina numero 1, ..., quando riempiamo l'ultima pagina, inizia un nuovo ciclo e la registrazione continua dalla pagina zero.
All'interno della pagina

All'inizio della pagina viene memorizzata un'intestazione di pagina di 4 byte, quindi un checksum dell'intestazione (CRC-32C), quindi i record vengono memorizzati nel formato "intestazione, dati, checksum".
L'intestazione della pagina (verde sporco nel diagramma) è composta da:
- campo Magic Number a due byte (noto anche come indicatore della versione del formato)
per la versione attuale del formato è considerato come0xed00 ⊕ номер страницы; - contatore a due byte "Versione pagina" (numero del ciclo di riscrittura della memoria).
I record sulla pagina vengono memorizzati in formato compresso (utilizzando l'algoritmo deflate). Tutti i record di una pagina vengono compressi in un unico flusso (utilizzando un dizionario comune) e la compressione ricomincia da capo a ogni nuova pagina. In altre parole, per decomprimere un record, sono richiesti tutti i record precedenti di questa pagina (e solo di questa pagina).
Ogni record viene compresso con il flag Z_SYNC_FLUSH, per cui il flusso compresso termina con 4 byte 0x00, 0x00, 0xff, 0xff, eventualmente preceduti da uno o due byte zero.
Questa sequenza (lunga 4, 5 o 6 byte) viene scartata quando si scrive nella memoria flash.
L'intestazione del record è di 1, 2 o 3 byte e memorizza:
- un bit (T) che indica il tipo di record: 0 - contesto, 1 - registro;
- campo di lunghezza variabile (S) da 1 a 7 bit, che definisce la lunghezza dell'intestazione e della "coda" che deve essere aggiunta al record per la decompressione;
- lunghezza del record (L).
Tabella dei valori S:
S
Lunghezza dell'intestazione, byte
Scartato in scrittura, byte
0
1
5 (00 00 00 ff ff)
10
1
6 (00 00 00 00 ff ff)
110
2
4 (00 00 ff ff)
1110
2
5 (00 00 00 ff ff)
11110
2
6 (00 00 00 00 ff ff)
1111100
3
4 (00 00 ff ff)
1111101
3
5 (00 00 00 ff ff)
1111110
3
6 (00 00 00 00 ff ff)
Ho provato a spiegarlo, non so quanto sia chiaro:
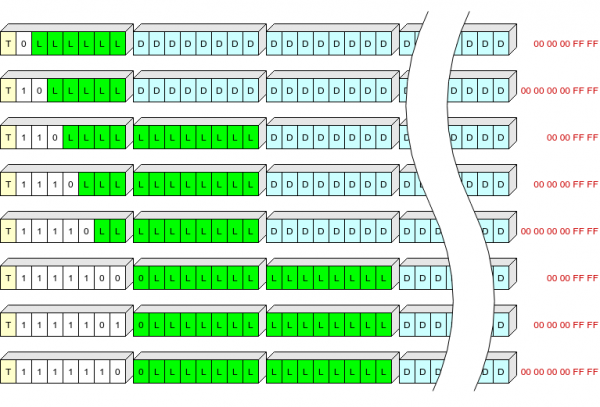
Il colore giallo indica il campo T, il colore bianco indica il campo S, il colore verde indica la L (lunghezza dei dati compressi in byte), il colore blu indica i dati compressi e il colore rosso indica i byte finali dei dati compressi che non vengono scritti nella memoria flash.
In questo modo possiamo scrivere le intestazioni dei record della lunghezza più comune (fino a 63+5 byte in forma compressa) in un byte.
Dopo ogni scrittura, viene memorizzato un checksum CRC-32C, che utilizza il valore invertito del checksum precedente come valore iniziale (init).
Il CRC ha la proprietà di "durata", è valida la seguente formula (inversione di bit più o meno nel processo):  .
.
In altre parole, calcoliamo effettivamente il CRC di tutti i byte di intestazione e dei dati precedenti in questa pagina.
Subito dopo il checksum si trova l'intestazione del record successivo.
L'intestazione è progettata in modo tale che il suo primo byte sia sempre diverso da 0x00 e 0xff (se invece del primo byte dell'intestazione incontriamo 0xff, significa che si tratta di un'area non utilizzata; 0x00 segnala un errore).
Algoritmi di esempio
Lettura dalla memoria flash
Ogni lettura è accompagnata da un controllo del checksum.
Se il checksum non corrisponde, la lettura viene ripetuta più volte nella speranza di leggere i dati corretti.
(che ha senso, Linux Non memorizza nella cache le letture dalla memoria NOR Flash (verificato)
Scrittura sulla memoria flash
Annotiamo i dati.
Leggiamoli.
Se i dati letti non corrispondono a quelli scritti, riempiamo l'area con zeri e segnaliamo un errore.
Preparazione di un nuovo microcircuito per il funzionamento
Per l'inizializzazione, un'intestazione con versione 1 viene scritta nella prima pagina (o più precisamente, zero).
Dopodiché, il contesto iniziale viene scritto in questa pagina (contiene l'UUID della macchina e le impostazioni predefinite).
Ecco fatto, la memoria flash è pronta per funzionare.
Caricamento della macchina
Durante il caricamento vengono letti i primi 8 byte di ogni pagina (intestazione + CRC); le pagine con un numero magico sconosciuto o un CRC errato vengono ignorate.
Dalle pagine “corrette” vengono selezionate le pagine con la versione più alta e da queste viene presa la pagina con il numero più alto.
Viene letto il primo record, viene verificata la correttezza del CRC e viene attivato il flag "contesto". Se tutto è corretto, la pagina viene considerata corrente. In caso contrario, si torna alla pagina precedente finché non si trova una pagina "attiva".
e nella pagina trovata leggiamo tutti i record, quelli che utilizziamo con il flag “contesto”.
Salva il dizionario zlib (sarà necessario aggiungerlo a questa pagina).
Ecco fatto, il caricamento è completo, il contesto è ripristinato, puoi lavorare.
Aggiunta di una voce di registro
Comprimiamo il record con il dizionario corretto, specificando Z_SYNC_FLUSH. Verifichiamo se il record compresso si adatta alla pagina corrente.
Se non si adatta (o se ci sono errori CRC nella pagina), inizia una nuova pagina (vedi sotto).
Scriviamo il record e il CRC. Se si verifica un errore, apriamo una nuova pagina.
Nuova pagina
Selezioniamo una pagina libera con un numero minimo (consideriamo libera una pagina con un checksum errato nell'intestazione o con una versione precedente a quella corrente). Se non ci sono pagine di questo tipo, selezioniamo una pagina con un numero minimo tra quelle che hanno una versione uguale a quella corrente.
Cancelliamo la pagina selezionata. Confrontiamo il contenuto con 0xff. Se qualcosa non va, prendiamo la pagina libera successiva, ecc.
Scriviamo l'intestazione sulla pagina cancellata, la prima voce è lo stato attuale del contesto, la successiva è la voce di registro non scritta (se presente).
Applicabilità del formato
A mio parere, questo è un buon formato per archiviare flussi di informazioni più o meno comprimibili (testo normale, JSON, MessagePack, CBOR, eventualmente protobuf) in NOR Flash.
Naturalmente, il formato è "affinato" per SLC NOR Flash.
Non deve essere utilizzato con supporti ad alto BER come NAND o MLC NOR. (è davvero possibile acquistare una memoria del genere? Ne ho trovato menzione solo in lavori sui codici di correzione).
Inoltre, non dovrebbe essere utilizzato con dispositivi dotati di FTL proprio: flash USB, SD, MicroSD, ecc. (per tale memoria ho creato un formato con una dimensione di pagina di 512 byte, una firma all'inizio di ogni pagina e numeri di record univoci; a volte era possibile recuperare tutti i dati da una chiavetta USB "difettosa" semplicemente leggendola in sequenza).
A seconda delle attività, il formato può essere utilizzato senza modifiche su unità flash da 128 Kbit (16 Kb) a 1 Gbit (128 Mb). Se lo si desidera, può essere utilizzato su chip di capacità maggiore, ma probabilmente sarà necessario adattare le dimensioni della pagina. (Ma qui si pone la questione della fattibilità economica, il prezzo del NOR Flash in grandi volumi non è incoraggiante).
Se qualcuno trova il formato interessante e vuole utilizzarlo in un progetto open source, mi scriva, cercherò di trovare il tempo, rifinire il codice e pubblicarlo su github.
conclusione
Come possiamo vedere, alla fine il formato si è rivelato semplice e anche noioso.
È difficile riflettere l'evoluzione del mio punto di vista in un articolo, ma credetemi: inizialmente volevo creare qualcosa di sofisticato, indistruttibile, in grado di sopravvivere anche dopo un'esplosione nucleare nelle immediate vicinanze. Tuttavia, la ragione (spero) ha comunque prevalso e gradualmente le priorità si sono spostate verso semplicità e compattezza.
È possibile che io abbia commesso un errore? Sì, certo. Potrebbe benissimo essere che abbiamo acquistato un lotto di microcircuiti di bassa qualità. O che per qualche altro motivo l'apparecchiatura non soddisfi le aspettative in termini di affidabilità.
Ho un piano per questo? Credo che dopo aver letto l'articolo non avrai dubbi che ci sia un piano. E nemmeno uno.
Per essere un po' più seri, il formato è stato sviluppato sia come opzione di lavoro che come "pallone di prova".
Al momento, tutto funziona bene sul tavolo, la soluzione verrà implementata letteralmente tra pochi giorni (circa) su un centinaio di dispositivi, vediamo cosa succederà in operazione "combattimento" (fortunatamente, spero, il formato consente un rilevamento affidabile dei guasti; quindi sarà possibile raccogliere statistiche complete). Tra qualche mese sarà possibile trarre conclusioni (e se sei sfortunato, anche prima).
Se dopo averlo utilizzato dovessero emergere problemi seri e fossero necessari dei miglioramenti, ne scriverò sicuramente.
Letteratura
Non volevo fare un lungo e noioso elenco di riferimenti; dopotutto, tutti hanno Google.
Qui ho deciso di lasciare un elenco di reperti che mi sembravano particolarmente interessanti, ma che gradualmente sono migrati direttamente nel testo dell'articolo, e nell'elenco è rimasto solo un elemento:
- Utilità Dall'autore di zlib. Può visualizzare il contenuto degli archivi deflate/zlib/gzip in modo chiaro. Se dovete gestire la struttura interna del formato deflate (o gzip), lo consiglio vivamente.
Fonte: habr.com
