

Ciao a tutti! Mi chiamo Nikolai Golov. In passato ho lavorato in Avito e ho diretto per sei anni la Data Platform, occupandomi di tutti i database: analitici (Vertica, ClickHouse), in streaming e OLTP (Redis, Tarantool, VoltDB, MongoDB, PostgreSQL). In questo periodo mi sono familiarizzato con un gran numero di database — dei più vari e insoliti, affrontando casi d'uso non standard.
Attualmente lavoro in ManyChat. Praticamente si tratta di una startup — nuova, ambiziosa e in rapida crescita. E quando sono entrato in azienda, è emersa la classica domanda: "Cosa dovrebbe considerare un giovane startup sul mercato dei DBMS e dei database?".
In questo articolo, basato sulla mia presentazione a , risponderò a questa domanda. La versione video della presentazione è disponibile su .
Database noti del 2020
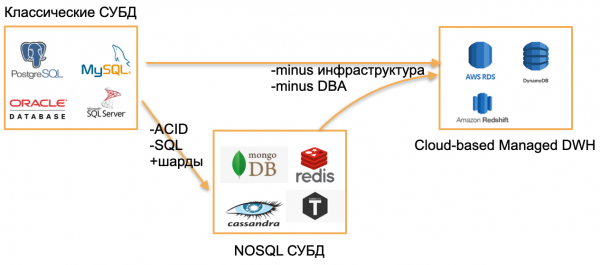
Siamo nel 2020, mi sono guardato intorno e ho identificato tre tipi di DB.
Il primo tipo — database OLTP classici: PostgreSQL, SQL Server, Oracle, MySQL. Sono stati scritti molto tempo fa, ma sono ancora attuali, perchè ben noti alla comunità di sviluppatori.
Il secondo tipo — database degli anni 2000. Hanno cercato di allontanarsi dai modelli tradizionali eliminando SQL, le strutture tradizionali e ACID, integrando sharding e altre funzionalità attraenti. Ad esempio, ci sono Cassandra, MongoDB, Redis o Tarantool. Tutte queste soluzioni volevano offrire al mercato qualcosa di fondamentalmente nuovo e hanno trovato la loro nicchia, risultando estremamente comode in determinate situazioni. Queste banche dati possono essere definite con il termine ombrello NOSQL.
Gli anni '00 sono finiti, le banche dati NOSQL sono diventate familiari, e il mondo, dal mio punto di vista, ha fatto il passo successivo - verso banche dati managed. Queste banche hanno un nucleo simile a quello delle tradizionali banche OLTP o delle nuove NoSQL. Tuttavia, non hanno bisogno di DBA e DevOps e funzionano su hardware gestito nel cloud. Per lo sviluppatore, è «solo una banca dati», che opera da qualche parte, e come è installata sul server, chi ha configurato il server e chi lo aggiorna non interessa a nessuno.
Esempi di tali banche:
- AWS RDS — un wrapper managed su PostgreSQL/MySQL.
- DynamoDB — l'analogo AWS di una banca dati basata su documenti, simile a Redis e MongoDB.
- Amazon Redshift — una banca dati analitica managed.
Alla base ci sono banche dati tradizionali, ma portate in un ambiente managed, senza la necessità di lavorare con l'hardware.
Nota. Gli esempi sono tratti dall'ambiente AWS, ma ne esistono anche analoghi in Microsoft Azure, Google Cloud o Yandex.Cloud.
Cosa c'è di nuovo? Nel 2020, niente di tutto ciò.
Il concetto di Serverless
La vera novità sul mercato nel 2020 è costituita dalle soluzioni serverless.
Cercherò di spiegare cosa significa, usando l'esempio di un servizio tradizionale o di un'applicazione backend.
Per distribuire un'applicazione backend tradizionale, acquistiamo o affittiamo un server, copiamo il codice su di esso, pubblichiamo un endpoint e paghiamo regolarmente per l'affitto, l'elettricità e i servizi del data center. Questo è lo schema standard.
È possibile fare diversamente? Con i servizi serverless, sì.
Qual è il focus di questo approccio: nessun server, nemmeno l'affitto di un'istanza virtuale nel cloud. Per distribuire un servizio, copiamo il codice (funzioni) in un repository e pubblichiamo un endpoint. Successivamente, paghiamo solo per ogni chiamata a questa funzione, ignorando completamente l'hardware su cui viene eseguita.
Cercherò di illustrare questo approccio con delle immagini.
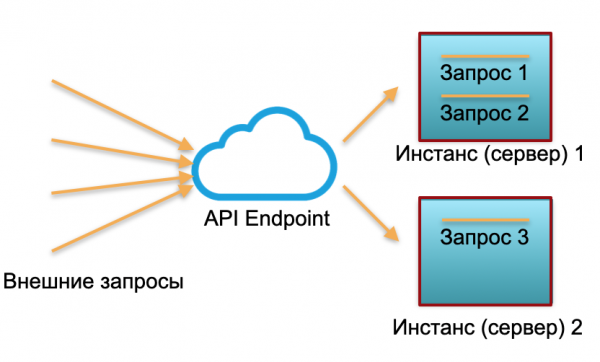
Distribuzione classica. Abbiamo un servizio con un carico specifico. Avviamo due istanze: server fisici o istanze in AWS. Su queste istanze vengono instradate le richieste esterne, che vengono elaborate lì.
Come si può vedere nell'immagine, i server sono utilizzati in modo diverso. Uno è utillizato al 100%, con due richieste, mentre l'altro solo al 50% — parzialmente inattivo. Se arrivano non tre richieste, ma 30, l'intero sistema non riuscirà a gestire il carico e comincerà a rallentare.
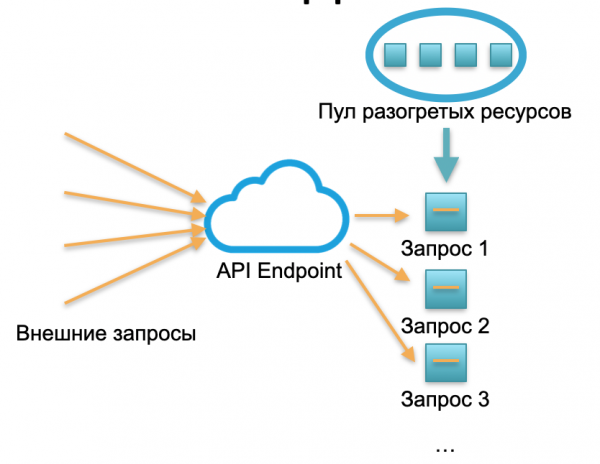
Deploy senza server. In un ambiente senza server, questo tipo di servizio non ha istanze o server. C'è un certo pool di risorse pronte — piccoli container Docker preparati con il codice della funzione distribuito. Il sistema riceve le richieste esterne e per ciascuna di esse il framework senza server avvia un piccolo container con il codice: elabora quella specifica richiesta e termina il container.
Una richiesta corrisponde a un contenitore sollevato, 1000 richieste corrispondono a 1000 contenitori. La distribuzione su server fisici è già un lavoro da fornitore cloud. È completamente mascherata da un framework serverless. In questa concezione, paghiamo per ogni invocazione. Ad esempio, se arriva un invocazione al giorno, paghiamo per un invocazione; se arriva un milione al minuto, paghiamo per un milione. Oppure al secondo, può succedere anche questo.
Il concetto di pubblicazione di una funzione serverless è adatto per un servizio stateless. Ma se hai bisogno di un servizio stateful, allora aggiungiamo un database al servizio. In questo caso, quando si tratta di gestire lo stato, ogni funzione stateful semplicemente scrive e legge dal database. E si può utilizzare qualsiasi dei tre tipi di database descritti all'inizio dell'articolo.
Qual è il limite comune a tutti questi database? Sono i costi di un server cloud o hardware utilizzato in modo permanente (o di più server). Non importa se utilizziamo un database tradizionale o un managed, che ci sia DevOps e un admin o meno, paghiamo comunque 24 ore su 24, 7 giorni su 7 per l'hardware, l'elettricità e l'affitto del centro dati. Se abbiamo un database tradizionale, paghiamo per master e slave. Se è un database shardato ad alto carico, paghiamo per 10, 20 o 30 server e lo facciamo continuamente.
La presenza di server riservati costantemente nella struttura dei costi è stata in passato considerata un male necessario. I database tradizionali hanno anche altre complessità, come i limiti sul numero di connessioni, le restrizioni di scalabilità e il consenso geograficamente distribuito: alcune di queste problematiche possono essere affrontate con specifici database, ma non tutte contemporaneamente e non in modo ideale.
Database serverless — teoria
Domanda del 2020: è possibile rendere serverless anche un database? Tutti hanno sentito parlare di backend serverless... proviamo a fare lo stesso con un database serverless?
Questo suona strano, perché un database è un servizio stateful, non proprio adatto a un'infrastruttura serverless. Inoltre, lo stato di un database è molto grande: gigabyte, terabyte, e anche petabyte nelle basi di dati analitiche. Non è facile implementarlo in leggeri container Docker.
D'altra parte, praticamente tutti i database moderni contengono una grande quantità di logica e componenti: transazioni, gestione della coerenza, procedure, dipendenze relazionali e molta logica. Un'ampia parte della logica del database richiede uno stato relativamente piccolo. Solo una piccola parte della logica del database, legata all'esecuzione delle query, utilizza direttamente gigabyte e terabyte.
Di conseguenza, l'idea è: se parte della logica consente un'esecuzione stateless, perché non suddividere il database in parti Stateful e Stateless?
Serverless per soluzioni OLAP
Vediamo come può apparire la suddivisione di un database in parti Stateful e Stateless attraverso esempi pratici.
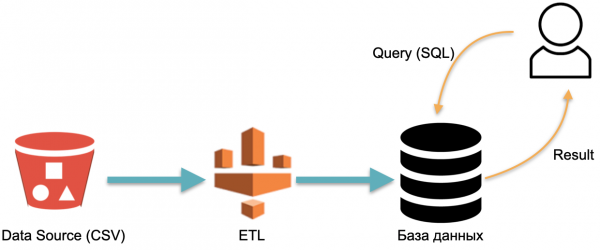
Ad esempio, abbiamo un database analitico: dati esterni (cilindro rosso a sinistra), processo ETL che carica i dati nel database e analista che invia query SQL al database. Questo è uno schema classico di funzionamento di un magazzino dati.
In questo schema, condizionatamente, l'ETL viene eseguito una sola volta. Dopo, è necessario pagare costantemente per i server su cui funziona il database con i dati caricati dall'ETL, affinché ci sia un posto dove inviare le query.
Consideriamo un approccio alternativo realizzato nella base AWS Athena Serverless. Qui non ci sono hardware dedicato continuamente su cui vengono archiviati i dati caricati. Invece:
- L'utente invia una query SQL ad Athena. L'ottimizzatore di Athena analizza la query SQL e cerca nello storage dei metadati (Metadata) i dati specifici necessari per eseguire la query.
- L'ottimizzatore, basandosi sui dati raccolti, estrae i dati necessari da fonti esterne in uno storage temporaneo (database temporaneo).
- Nello storage temporaneo viene eseguita la query SQL dell'utente, e il risultato viene restituito all'utente.
- Lo storage temporaneo viene pulito, le risorse vengono liberate.
In questa architettura paghiamo solo per il processo di esecuzione della query. Nessuna query — nessuna spesa.
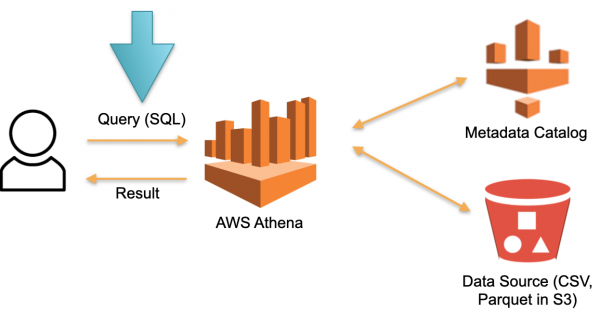
Questo approccio funziona e si realizza non solo in Athena Serverless, ma anche in Redshift Spectrum (su AWS).
L'esempio di Athena dimostra che un database Serverless opera su richieste reali con decine e centinaia di terabyte di dati. Per centinaia di terabyte sono necessari centinaia di server, ma non dobbiamo pagarli — paghiamo solo per le richieste. La velocità di ogni richiesta è (molto) bassa rispetto ai database analitici specializzati come Vertica, ma non paghiamo i tempi di inattività.
Questo tipo di database è applicabile per richieste analitiche ad-hoc rare. Ad esempio, quando decidiamo spontaneamente di testare un'ipotesi su un'enorme quantità di dati. Per questi casi, Athena è perfetta. Per richieste regolari, questo sistema diventa costoso. In tal caso, memorizza i dati in una soluzione specializzata.
Serverless per soluzioni OLTP
Nell'esempio precedente, abbiamo esaminato compiti OLAP (analitici). Ora consideriamo i compiti OLTP.
Immaginiamo un'istanza PostgreSQL o MySQL scalabile. Creiamo un'istanza gestita di PostgreSQL o MySQL con risorse minime. Quando l'istanza riceve un carico maggiore, possiamo aggiungere repliche supplementari per distribuire parte del carico di lettura. Se non ci sono richieste o carico, disattiviamo le repliche. La prima istanza è il master, mentre le altre sono repliche.
Questa idea è realizzata in un database chiamato Aurora Serverless AWS. Il principio è semplice: le richieste da applicazioni esterne vengono gestite da un proxy fleet. Con l'aumento del carico, vengono allocate risorse di calcolo da istanze minime già pronte — la connessione avviene nel modo più rapido possibile. Anche la disattivazione delle istanze avviene allo stesso modo.
All'interno di Aurora esiste il concetto di Aurora Capacity Unit, ACU. Questo è (in termini generali) un'istanza (server). Ogni singolo ACU può essere master o slave. Ogni Capacity Unit ha la propria memoria, processore e disco minimo. Di conseguenza, esiste un master, mentre le altre sono repliche in sola lettura.
Il numero di Aurora Capacity Units attive è un parametro configurabile. Il valore minimo può essere uno o zero (in tal caso il database non è operativo se non ci sono richieste).
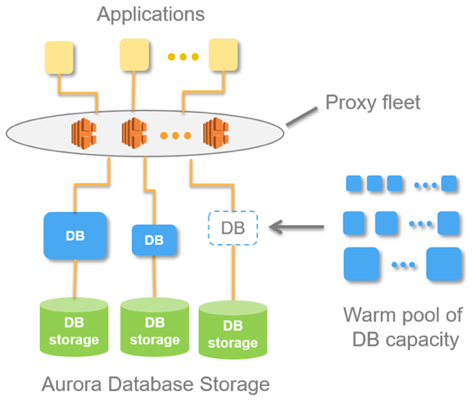
Quando il database riceve richieste, il fleet proxy attiva Aurora Capacity Units, aumentando le risorse produttive del sistema. La possibilità di aumentare e diminuire le risorse consente al sistema di "giocolare" con le risorse: disattivando automaticamente singole ACU (sostituendole con nuove) e applicando a quelle disattivate tutti gli aggiornamenti attuali.
Il database Aurora Serverless può scalare il carico di lettura. Tuttavia, questo non è specificato chiaramente nella documentazione. Potrebbe sembrare che possano attivare il multi-master. Ma non ci sono magie.
Questa base è ideale per evitare di spendere grandi somme per sistemi con accesso imprevedibile. Ad esempio, nella creazione di MVP o siti web di marketing, di solito non ci aspettiamo un carico stabile. Pertanto, in assenza di accesso, non paghiamo per le istanze. Quando sorge un carico imprevisto, ad esempio dopo una conferenza o una campagna pubblicitaria, grandi gruppi di persone accedono al sito e il carico aumenta drasticamente; Aurora Serverless gestisce automaticamente questo carico e connette rapidamente le risorse necessarie (ACU). Poi, dopo la conferenza, tutti dimenticano il prototipo, i server (ACU) si spengono e i costi cadono a zero — molto comodo.
Questa soluzione non è adatta per carichi stabili e elevati, perché non è in grado di scalare il carico di scrittura. Tutte queste connessioni e disconnessioni delle risorse avvengono nel momento chiamato 'scale point' — un momento in cui il database non è bloccato da una transazione e non ha tabelle temporanee. Ad esempio, nel corso di una settimana potrebbe non verificarsi alcuno 'scale point', e il database funziona con le stesse risorse, non potendo né espandersi né ridursi.
Non c'è magia: si tratta di un normale PostgreSQL. Tuttavia, il processo di aggiunta di macchine e disattivazione è parzialmente automatizzato.
Serverless per design
Aurora Serverless è un database vecchio adattato al cloud per sfruttare i vantaggi di Serverless. Ora, parlerò di un database progettato fin dall'inizio per il cloud e per un approccio serverless: Serverless-by-design. È stato sviluppato sin dall'inizio senza l'assunzione di essere eseguito su server fisici.
Questo database si chiama Snowflake. Esso è composto da tre blocchi chiave.
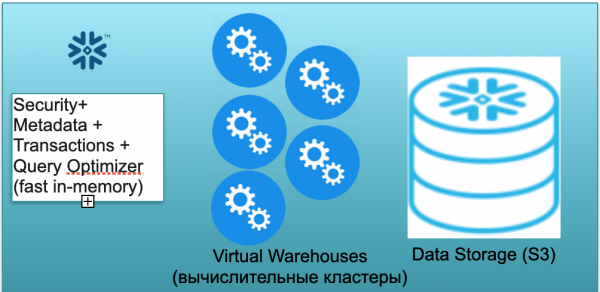
Il primo blocco è il blocco dei metadati. Si tratta di un servizio in-memory veloce che si occupa di sicurezza, metadati, transazioni, ottimizzazione delle query (nella illustrazione a sinistra).
Il secondo blocco consiste in numerosi cluster di calcolo virtuali per le elaborazioni (nell'illustrazione — un insieme di cerchi blu).
Il terzo blocco è il sistema di archiviazione dei dati basato su S3. S3 è uno spazio di archiviazione oggetti illimitato in AWS, simile a un Dropbox illimitato per il business.
Vediamo come funziona Snowflake assumendo un avvio a freddo. Cioè, il database esiste, i dati sono stati caricati, ma non ci sono query attive. Di conseguenza, se non ci sono query, abbiamo un veloce servizio di Metadata in memoria (il primo blocco). E abbiamo uno storage S3 dove sono conservati i dati delle tabelle, suddivisi in quelle che chiamiamo micro-partizioni. Per semplicità: se nella tabella ci sono transazioni, le micro-partizioni corrispondono ai giorni delle transazioni. Ogni giorno è una micro-partizione separata, un file separato. E quando il database funziona in questo modo, paghi solo per lo spazio occupato dai dati. Inoltre, la tariffa per lo spazio è molto bassa (soprattutto considerando la significativa compressione). Il servizio di metadati è sempre attivo, ma per ottimizzare le query non richiede molte risorse, e possiamo considerarlo a costo zero.
Immaginiamo ora che un utente si connetta al nostro database e invii una query SQL. La query SQL viene subito inviata al servizio di Metadata per l'elaborazione. Di conseguenza, ricevuta la query, questo servizio la analizza, insieme ai dati disponibili e alle autorizzazioni dell'utente, e, se tutto è a posto, elabora un piano di esecuzione della query.
Successivamente, il servizio avvia il lancio del cluster di calcolo. Un cluster di calcolo è un insieme di server che esegue elaborazioni. Ciò significa che può includere 1 server, 2 server, 4, 8, 16, 32 — quanti ne desiderate. Inviate una richiesta e il lancio di questo cluster inizia immediatamente. Questo richiede davvero solo pochi secondi.
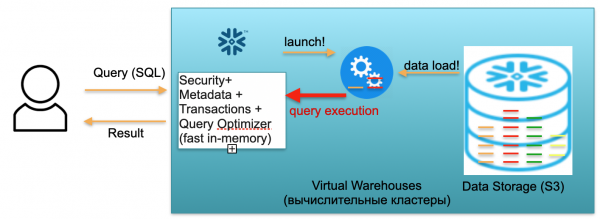
Dopo che il cluster è stato avviato, le micro-partizioni necessarie per elaborare la tua richiesta vengono copiate dal S3 nel cluster. Supponiamo che per eseguire una query SQL siano necessarie due partizioni da una tabella e una da un'altra. In questo caso, verranno copiate nel cluster solo le tre partizioni richieste, e non tutte le tabelle intere. È proprio per questo motivo, e perché tutto è situato all'interno dello stesso data center e collegato tramite canali molto veloci, che l'intero processo di trasferimento avviene rapidamente: in pochi secondi, molto raramente in minuti, a meno che non si tratti di richieste particolarmente complesse. Le micro-partizioni vengono quindi copiate nel cluster di calcolo, e, una volta completato, la query SQL viene eseguita su questo cluster. Il risultato di questa query può essere una singola riga, più righe o una tabella — che vengono inviate all'esterno all'utente, affinché possa scaricarle, visualizzarle nel proprio strumento di BI, o utilizzarle in altro modo.
Ogni richiesta SQL non solo può calcolare aggregati dai dati precedentemente caricati, ma può anche caricare/formare nuovi dati nel database. In altre parole, può trattarsi di una richiesta che, ad esempio, esegue un'inserimento in un'altra tabella di nuovi record, il che porta alla creazione di una nuova partizione nel cluster di calcolo, che a sua volta viene automaticamente salvata in un unico storage S3.
Lo scenario descritto sopra, dalla connessione dell'utente fino all'attivazione del cluster, il caricamento dei dati, l'esecuzione delle query e la ricezione dei risultati, è fatturato a una tariffa per minuti di utilizzo del cluster di calcolo virtuale attivato, virtual warehouse. La tariffa varia in base alla regione AWS e alle dimensioni del cluster, ma in media è di alcuni dollari all'ora. Un cluster di quattro macchine costa il doppio rispetto a uno di due macchine, e uno di otto macchine costa ancora il doppio. Sono disponibili opzioni da 16 o 32 macchine, a seconda della complessità delle query. Ma paghi solo per i minuti in cui il cluster è effettivamente attivo, perché, quando non ci sono richieste, puoi semplicemente allontanarti e dopo 5-10 minuti di attesa (parametro configurabile) si spegnerà automaticamente, liberando risorse e diventando gratuito.
È assolutamente realistico che tu invii una richiesta, il cluster si attivi, per così dire, in un minuto, poi un minuto per eseguire i calcoli, successivamente cinque minuti per lo spegnimento, e alla fine paghi solo per sette minuti di funzionamento di questo cluster, non per mesi o anni.
Il primo scenario descriveva l'uso di Snowflake in modalità singolo utente. Ora immaginiamo che ci siano molti utenti, che si avvicina di più a uno scenario reale.
Supponiamo di avere molti analisti e report di Tableau che bombardano costantemente il nostro database con un gran numero di semplici query SQL analitiche.
In aggiunta, ipotizziamo di avere data scientist ingegnosi che cercano di fare cose incredibili con i dati, operando con decine di terabyte e analizzando miliardi e trilioni di righe di dati.
Per i due tipi di carico descritti sopra, Snowflake consente di attivare più cluster di calcolo indipendenti di diversa potenza. Questi cluster di calcolo funzionano in modo indipendente ma condividono dati coerenti.
Per un numero elevato di richieste leggere, è possibile attivare 2-3 piccoli cluster, ognuno composto da, diciamo, 2 macchine. Questo comportamento è realizzabile anche attraverso impostazioni automatiche. In altre parole, si può semplicemente dire: «Snowflake, avvia un piccolo cluster. Se il carico supera un certo parametro, avvia un secondo e un terzo simili. Quando il carico inizia a diminuire, spegni quelli in più». Così, indipendentemente dal numero di analisti che accedono e iniziano a consultare i report, ci saranno sempre risorse sufficienti.
D'altra parte, se gli analisti sono inattivi e nessuno consulta i report, i cluster possono essere completamente spenti, e non si paga per loro.
Per le richieste pesanti (da parte dei Data Scientists), è possibile attivare un cluster molto grande con circa 32 macchine. Questo cluster sarà addebitato solo per i minuti e le ore in cui il vostro grosso comando è in esecuzione.
La possibilità descritta sopra consente di separare i carichi in cluster non solo su 2, ma anche su più tipi di carico (ETL, monitoraggio, materializzazione dei report,…).
Riassumiamo riguardo a Snowflake. La piattaforma combina un'idea accattivante con un'implementazione funzionale. In ManyChat utilizziamo Snowflake per analizzare tutti i dati disponibili. Non abbiamo tre cluster come nell'esempio, ma tra 5 e 9, di diverse dimensioni. Abbiamo cluster convenzionali da 16 macchine, cluster da 2 macchine e anche super piccoli cluster da 1 macchina per alcune attività. Questi gestiscono efficacemente il carico e ci permettono di risparmiare significativamente.
La piattaforma scalda con successo il carico di lettura e scrittura. Questa è una grande differenza e una grande innovazione rispetto a "Aurora", che gestiva solo il carico di lettura. Snowflake consente di scalare anche il carico di scrittura con questi cluster computazionali. Come ho accennato, in ManyChat utilizziamo diversi cluster; i cluster piccoli e super piccoli sono principalmente utilizzati per ETL, per il caricamento dei dati. Gli analisti operano su cluster medi, che non sono affatto influenzati dal carico ETL, quindi lavorano molto velocemente.
Pertanto, il database è ben adatto per compiti OLAP. Tuttavia, sfortunatamente, non è ancora applicabile ai carichi di lavoro OLTP. Innanzitutto, questo database è colonnare, con tutte le conseguenze del caso. In secondo luogo, l'approccio stesso, in cui si attiva un cluster computazionale per ogni richiesta e si riversano i dati, purtroppo, non è ancora sufficientemente veloce per carichi di lavoro OLTP. Attendere alcuni secondi per compiti OLAP è normale, ma inaccettabile per OLTP; sarebbe meglio avere 100 ms, e ancor meglio — 10 ms.
Risultato
Un database serverless è possibile grazie alla separazione del database in parti Stateless e Stateful. Avrete notato che, in tutti gli esempi forniti, la parte Stateful è, per così dire, la memorizzazione delle micro-partizioni in S3, mentre Stateless riguarda l'ottimizzatore, la gestione dei metadati, il trattamento delle questioni di sicurezza, che possono essere attivate come servizi Stateless leggeri e indipendenti.
L'esecuzione di query SQL può essere vista anch'essa come servizi con uno stato leggero, che possono attivarsi in modalità serverless, come i cluster computazionali di Snowflake, scaricando solo i dati necessari, eseguendo la query e 'spegnendosi'.
Le banche dati serverless di livello enterprise sono ora disponibili per l'uso e funzionano. Queste banche serverless sono già pronte a gestire compiti OLAP. Purtroppo, per i compiti OLTP, vengono utilizzate… con delle problematiche, poiché ci sono delle limitazioni. Da un lato, è un aspetto negativo. Dall'altro, è un'opportunità. Forse qualcuno dei lettori troverà un modo per rendere una banca dati OLTP completamente serverless, senza limitazioni Aurora.
Spero che sia stato interessante. Per un futuro Serverless 🙂
Fonte: habr.com
