

Сразу объясню название статьи. Изначально планировалось дать хороший, надежный совет по ускорению использования рефлекшена на простом, но реалистичном примере, однако в ходе бенчмаркинга выяснилось, что рефлексия работает не так медленно, как я думал, LINQ работает медленнее, чем снилось в кошмарах. А в итоге оказалось, что мной еще и была допущена ошибка в замерах… Подробности этой жизненной истории под катом и в комментариях. Так как пример достаточно бытовой и реализованный в принципе как обычно делается в энтерпрайзе, получилось достаточно интересная, как мне кажется, демонстрация жизни: влияния на скорость работы основного предмета статьи было не заметно из-за внешней логики: Moq, Autofac, EF Core и прочей «обвязки».
Начал я работу под впечатлением от этой статьи:
Как видно, автор предлагает использовать скомпилированные делегаты вместо прямого обращения к методам типов отражения как отличный способ сильно ускорить работу приложения. Есть там еще, конечно, IL эмиссия, но её хотелось бы избежать, так как это самый трудозатратный способ выполнения задачи, который чреват ошибками.
Учитывая, что я придерживался всегда аналогичного мнения о скорости рефлексии, особо ставить под сомнения выводы автора я не собирался.
Я не редко встречаюсь с наивным использованием рефлексии в энтерпрайзе. Берется тип. Берется информация о свойстве. Вызывается метод SetValue, и все радуются. Значение прилетело в целевое поле, все довольны. Люди весьма неглупые — синиоры и тимлиды — пишут свои расширения на object, основывая на такой наивной реализации «универсальные» мапперы одного типа в другой. Суть такова обычно: берем все поля, берем все свойства, итерируем по ним: при совпадении имен членов типа выполняем SetValue. Периодически ловим исключения на промахах там, где не нашли какое-то свойство у одного из типов, но и тут есть выход, добивающий производительность. Try/catch.
Я видел, как люди переизобретают парсеры и мапперы, не будучи полностью вооруженными информацией о том, как работают изобретенные до них велосипеды. Я видел, как люди прячут свои наивные реализации за стратегиями, за интерфейсами, за инъекциями, как будто это извинит последующую вакханалию. От таких реализаций я воротил нос. По факту, реальную утечку производительности я не замерял, и при возможности просто менял реализацию на более «оптимальную», если руки доходили. Потому первые замеры, о которых идет речь ниже, меня серьёзно смутили.
Думаю, многие из вас, читая Рихтера или других идеологов, сталкивались со вполне справедливым утверждением, что рефлексия в коде — это явление крайне негативно сказывающееся на перформансе приложения.
Вызов отражения вынуждает CLR обходить сборки в поисках нужной, подтягивать их метаданные, парсить их и т.д. Кроме того, рефлексия во время обхода последовательностей приводит к аллокации большого объема памяти. Расходуем память, CLR расчехляет ГЦ и понеслись фризы. Это должно быть заметно медленно, поверьте. Огромные объемы памяти современных продакшен серверов или облачных машин не спасают от высоких задержек в обработке. Фактически, чем больше памяти, тем выше вероятность, что вы ЗАМЕТИТЕ, как работает ГЦ. Рефлексия – это, по идее, лишняя красная тряпка для него.
Тем не менее, все мы используем и IoC контейнеры, и дата мапперы, принцип работы которых так же основан на рефлексии, однако вопросов к их производительности обычно не возникает. Нет, не потому что внедрение зависимостей и абстрагирования от моделей внешнего ограниченного контекста столь необходимые вещи, что перформансом нам приходится жертвовать в любом случае. Все проще – это действительно не сильно сказываются на производительности.
Дело в том, что наиболее распространенные фреймворки, которые основаны на технологии рефлексии, используют всевозможные ухищрения для более оптимальной работы с ней. Обычно это кеш. Обычно — это Expressions и скомпилированные из дерева выражений делегаты. Тот же автомаппер держит под собой конкурентный словарь, сопоставляющий типы с функциями, которые могут один в другой сконвертировать уже без вызова рефлексии.
Как это достигается? По сути, это не отличается от логики, которой пользуется сама платформа для генерации кода JIT. При первом вызове метода, тот компилируется (и, да, этот процесс не быстрый), при последующих вызовах управление передается уже скомпилированному методу, и тут особых просадок производительности не будет.
В нашем случае так же можно воспользоваться JIT компиляцией и потом использовать скомпилированное поведение с той же производительностью, что и его AOT аналоги. На помощь нам в данном случае придут выражения.
Кратко можно сформулировать принцип, о котором идет речь, следующим образом:
Следует кешировать конечный результат работы рефлексии в виде делегата, содержащего скомпилированную функцию. Все необходимые объекты со сведениями о типах тоже имеет смысл кешировать в сохраняемых вне объектов полях вашего типа – воркера.
Логика в этом есть. Здравый смысл нам говорит о том, что если что-то можно скомпилировать и закешировать, то это следует сделать.
Забегая вперед, следует сказать, что кеш в работе с рефлексией имеет свои преимущества, даже если не использовать предложенный метод компиляции выражений. Собственно, тут я прост поовторяю тезисы автора статьи, на которую ссылаюсь выше.
Теперь о коде. Давайте рассмотрим пример, который основан на моей недавней боли, с которой пришлось столкнуться в серьёзном продакшене серьёзной кредитной организации. Все энтити вымышленные, чтобы никто не догадался.
Есть некая сущность. Пусть будет Contact. Есть письма со стандартизированным телом, из которых парсер и гидратор создают эти самые контакты. Пришло письмо, мы его прочитали, разобрали на пары ключ-значение, создали контакт, сохранили в бд.
Это элементарно. Допустим, у контакта есть свойства ФИО, Возраст и контактный телефон. Эти данные и передаются в письме. Так же бизнес хочет, чтобы саппорты могли оперативно добавлять новые ключи для маппинга свойств энтити на пары в теле письма. На тот случай, если кто-то опечатался в шаблоне или если до релиза надо будет срочно запустить маппинг от нового партнера, подстроившись под новый формат. Тогда новую корреляцию маппинга мы сможем добавить как дешевый датафикс. То есть, пример жизненный.
Реализуем, создаем тесты. Работает.
Код я приводить не буду: исходников получилось много, и они доступны на GitHub по ссылке в конце статьи. Вы можете их загрузить, замучить до неузнаваемости и замерить, как это бы сказалось в вашем случае. Приведу только код двух шаблонных методов, которыми отличаются гидратор, который должен был быть быстрым от гидратора, который должен был быть медленным.
Логика следующая: шаблонный метод получает пары, сформированные базовой логикой парсера. Уровень LINQ – это парсер и базовая логика гидратора, делающая запрос к контексту бд и сопоставляющая ключи с парами от парсера (для этих функций есть код без LINQ для сравнения). Далее пары передаются в основной метод гидрации и значения пар устанавливаются в соответствующие свойства энтити.
«Быстрый» (Префикс Fast в бенчмарках):
protected override Contact GetContact(PropertyToValueCorrelation[] correlations)
{
var contact = new Contact();
foreach (var setterMapItem in _proprtySettersMap)
{
var correlation = correlations.FirstOrDefault(x => x.PropertyName == setterMapItem.Key);
setterMapItem.Value(contact, correlation?.Value);
}
return contact;
}
Как мы видим, используется статическая коллекция с сеттерами пропертей – скомпилированными лямбдами, вызывающими сеттер энтити. Создаются следующим кодом:
static FastContactHydrator()
{
var type = typeof(Contact);
foreach (var property in type.GetProperties())
{
_proprtySettersMap[property.Name] = GetSetterAction(property);
}
}
private static Action<Contact, string> GetSetterAction(PropertyInfo property)
{
var setterInfo = property.GetSetMethod();
var paramValueOriginal = Expression.Parameter(property.PropertyType, "value");
var paramEntity = Expression.Parameter(typeof(Contact), "entity");
var setterExp = Expression.Call(paramEntity, setterInfo, paramValueOriginal).Reduce();
var lambda = (Expression<Action<Contact, string>>)Expression.Lambda(setterExp, paramEntity, paramValueOriginal);
return lambda.Compile();
}
В целом понятно. Обходим свойства, создаем по ним делегаты, вызывающие сеттеры, сохраняем. Потом вызываем, когда надо.
«Медленный» (Префикс Slow в бенчмарках):
protected override Contact GetContact(PropertyToValueCorrelation[] correlations)
{
var contact = new Contact();
foreach (var property in _properties)
{
var correlation = correlations.FirstOrDefault(x => x.PropertyName == property.Name);
if (correlation?.Value == null)
continue;
property.SetValue(contact, correlation.Value);
}
return contact;
}
Тут сразу обходим свойства и вызываем напрямую SetValue.
Для наглядности и в качестве эталона реализовал наивный метод, который пишет значения их пар корреляции напрямую в поля энтити. Префикс – Manual.
Теперь берем BenchmarkDotNet и исследуем производительность. И внезапно… (спойлер — это не правильный результат, подробности — ниже)
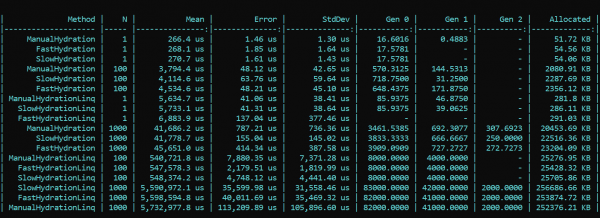
Что мы тут видим? Методы, победоносно носящие префикс Fast, почти при всех проходах оказываются медленнее, чем методы с префиксом Slow. Это справедливо и для аллокации, и для скорости работы. С другой же стороны красивая и элегантная реализация маппинга с использованием везде, где можно, предназначенных для этого методов LINQ, наоборот, сильно отжирает производительность. Разница в порядки. Тенденция не меняется с разным количеством проходов. Разница только в масштабах. С LINQ в 4 — 200 раз медленнее, мусора больше примерно в таких же масштабах.
UPDATED
Я не поверил своим глазам, но что важнее, ни моим глазам, ни моему коду не поверил наш коллега — . Перепроверив мой солюшн он блестяще обнаружил и указал на ошибку, которую я из-за ряда изменений в реализации он начальной к конечной упустил. После исправления найденного бага в настройке Moq, все результаты встали на свои места. По результатам ретеста основная тенденция не меняется — LINQ влияет на производительность все равно сильнее, чем рефлексия. Однако приятно, что работа с компиляцией Expression’ов делается не зря, и результат виден и по аллокации, и по времени выполнения. Первый запуск, когда инициализируются статические поля, закономерно медленней у «быстрого» метода, но дальше ситуация меняется.
Вот результат ретеста:
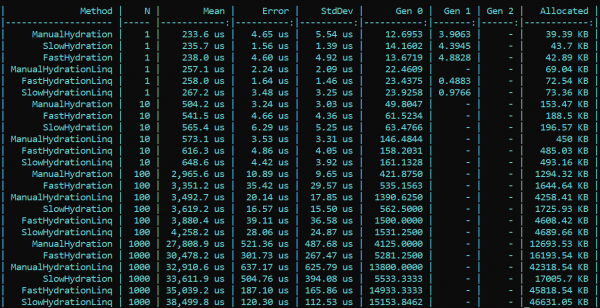
Вывод: при использовании в энтерпрайзе рефлексии прибегать к ухищрениям особо не требуется — LINQ сожрет производительность сильней. Тем не менее, в высоконагруженных методах, требующих оптимизации, можно сохранить рефлексию в виде инициализаторов и компиляторов делегатов, которые будут потом обеспечивать «быструю» логику. Так Вы можете сохранить и гибкость рефлексии, и скорость работы приложения.
Код с бенчмарком доступен тут. Все желающие могут перепроверить мои слова:
PS: код в тестах использует IoC, а в бенчмарках – явную конструкцию. Дело в том, что в конечной реализации я отсек все способные сказаться на производительности и зашумить результат факторы.
PPS: Спасибо пользователю за обнаружение моей ошибки в настройке Moq, которая сказалась на первых замерах. Если у кого-то из читателей будет достаточная карма, лайкните его, пожалуйста. Человек остановился, человек вчитался, человек перепроверил и указал на ошибку. Я считаю, что это достойно уважения и симпатии.
PPPS: спасибо тому дотошному читателю, который докопался к стилистике и оформлению. Я за единообразие и удобство. Дипломатичность подачи оставляет желать лучшего, но критику я учел. Прошу к снаряду.
Fonte: habr.com
