

Questo articolo è la traduzione del mio articolo su Medium — , che si è rivelato piuttosto popolare, probabilmente a causa della sua semplicità. Ho deciso quindi di scriverlo in italiano e di aggiungere alcune informazioni, affinché anche le persone non esperte in sistemi di dati possano comprendere cos'è un data warehouse (DW), cos'è un data lake, e come coesistono.
Perché ho voluto scrivere del data lake? Lavoro con i dati e l'analisi da oltre 10 anni e ora mi occupo di big data in Amazon Alexa AI a Cambridge, vicino a Boston, anche se vivo a Victoria, sull'isola di Vancouver, e spesso mi reco a Boston, Seattle e Vancouver, a volte addirittura parlo a conferenze a Mosca. Inoltre, di tanto in tanto scrivo, principalmente in inglese, e ho già scritto , e ho anche la necessità di condividere le tendenze analitiche del Nord America, e ogni tanto scrivo per .
Ho sempre lavorato con i data warehouse, e dal 2015 mi sono dedicato intensamente ad Amazon Web Services, passando in generale all'analisi nel cloud (AWS, Azure, GCP). Ho osservato l'evoluzione delle soluzioni di analytics dal 2007 e ho anche lavorato per il fornitore di data warehouse Teradata, implementandolo in Sberbank; è allora che è emerso il concetto di Big Data con Hadoop. Tutti hanno iniziato a dire che era finita l'era dei data warehouse e che ora tutto si basava su Hadoop, poi hanno iniziato a parlare di Data Lake, dicendo che ormai era davvero finita per i data warehouse. Ma per fortuna (forse per sfortuna di chi guadagnava bene configurando Hadoop), i data warehouse non sono scomparsi.
In questo articolo esploreremo cos'è un data lake. L'articolo è rivolto a persone che hanno poca o nessuna esperienza con i data warehouse.

Nell'immagine si vede il Lago di Bled, uno dei miei laghi preferiti, anche se ci sono stato solo una volta, ma lo ricordo per tutta la vita. Ma parleremo di un altro tipo di lago: il data lake. Forse molti di voi hanno già sentito questo termine, ma un'altra definizione non fa mai male.
Per iniziare, ecco le definizioni più popolari di Data Lake:
«un repository di tutti i tipi di dati grezzi, accessibili per l'analisi da chiunque nell'organizzazione» — Martin Fowler.
«Se pensate a un data mart come a una bottiglia d'acqua — pura, confezionata e preparata per un consumo comodo, allora un lago di dati è un enorme serbatoio d'acqua nella sua forma naturale. Gli utenti possono attingere acqua per sé, immergersi in profondità, esplorare» — James Dixon.
Ora sappiamo con certezza che un lago di dati riguarda l'analitica, ci permette di conservare grandi volumi di dati nella loro forma originale e abbiamo accesso facile e necessario ai dati.
Mi piace spesso semplificare le cose; se riesco a spiegare un termine complesso con parole semplici, significa che ho capito come funziona e a cosa serve. Un giorno, mentre scorrevo il mio iPhone nella galleria fotografica, ho avuto un’illuminazione: questo è un vero lago di dati, tanto che ho persino creato una slide per conferenze:
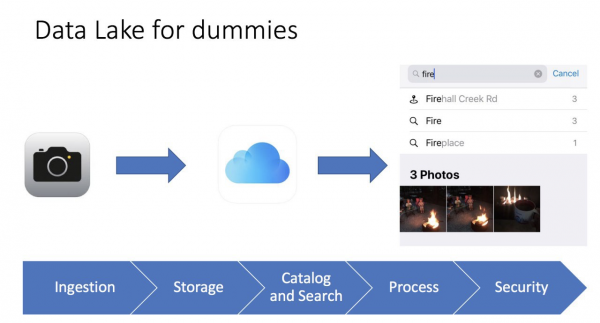
È tutto molto semplice. Scattiamo una foto con il telefono, la foto viene salvata nel telefono e può essere archiviata su iCloud (archiviazione cloud). Inoltre, il telefono raccoglie i metadati della foto: cosa è rappresentato, geotag, orario. Come risultato, possiamo usare l'interfaccia intuitiva dell'iPhone per trovare la nostra foto e mentre lo facciamo, vediamo anche le statistiche; ad esempio, quando cerco foto con la parola fuoco (fire), trovo 3 foto di un falò. Per me è proprio come uno strumento di Business Intelligence che funziona molto rapidamente e con precisione.
E naturalmente non dobbiamo dimenticare la sicurezza (autenticazione e autorizzazione), altrimenti i nostri dati potrebbero facilmente diventare accessibili al pubblico. Ci sono molte notizie di grandi aziende e startup i cui dati sono stati esposti a causa della negligenza degli sviluppatori e della mancata osservanza di semplici regole.
Anche una semplice immagine ci aiuta a capire cosa sia un lago di dati, le sue differenze rispetto a un tradizionale datastore e i suoi elementi principali:
- Caricamento dati (Ingestion) — un componente chiave del lago di dati. I dati possono essere caricati nel data store in due modi: batch (caricamento a intervalli) e streaming (flusso di dati).
- Archiviazione file (Storage) — il componente principale del Lago Dati. È fondamentale che lo storage sia facilmente scalabile, estremamente affidabile e con costi contenuti. Ad esempio, in AWS, si utilizza S3.
- Catalogo e Ricerca (Catalog and Search) — per evitare il Lago di Dati (quando accumuliamo tutti i dati in un unico posto rendendoli difficili da gestire), è necessario creare uno strato di metadati per classificare i dati, affinché gli utenti possano facilmente trovare le informazioni necessarie per l'analisi. Inoltre, è possibile utilizzare soluzioni aggiuntive per la ricerca, come ElasticSearch. La ricerca facilita agli utenti il reperimento dei dati tramite interfacce intuitivi.
- Elaborazione (Process) — questo passo si occupa della lavorazione e della trasformazione dei dati. Possiamo trasformare i dati, modificarne le strutture, pulirli e molto altro.
- Sicurezza (Sicurezza) — è importante dedicare tempo alla progettazione della sicurezza della soluzione. Ad esempio, la crittografia dei dati durante la conservazione, l'elaborazione e il caricamento. È fondamentale utilizzare metodi di autenticazione e autorizzazione. Infine, serve uno strumento di auditing.
Da un punto di vista pratico, possiamo caratterizzare un data lake tramite tre attributi:
- Raccogliete e memorizzate qualsiasi cosa — un data lake contiene tutti i dati, sia i dati grezzi non elaborati di qualsiasi periodo di tempo, sia i dati elaborati/puliti.
- Analisi approfondita — il data lake consente agli utenti di esaminare e analizzare i dati.
- Accesso flessibile — il data lake fornisce accesso flessibile a diversi dati e vari scenari.
Ora possiamo parlare della differenza tra un data warehouse e un data lake. Di solito le persone chiedono:
- E il data warehouse?
- Sostituiamo il data warehouse con un data lake o lo estendiamo?
- Possiamo davvero fare a meno del data lake?
In breve, non c'è una risposta chiara. Tutto dipende dalla situazione specifica, dalle competenze del team e dal budget. Ad esempio, la migrazione di uno storage dati su Oracle in AWS e la creazione di un data lake da parte della sussidiaria di Amazon, Woot. .
D'altra parte, il fornitore Snowflake afferma che non dovete più preoccuparvi del data lake, poiché la loro piattaforma dati (fino al 2020 era uno storage dati) vi consente di unire sia il data lake che lo storage dati. Ho lavorato un po' con Snowflake e si tratta davvero di un prodotto unico che può fare questo. Il costo è un'altra questione.
In conclusione, sono convinto che abbiamo ancora bisogno di un data warehouse come principale fonte di dati per i nostri report, mentre ciò che non rientra lo conserviamo in un data lake. Il compito dell'analisi è fornire accesso semplice alle informazioni per le decisioni aziendali. In effetti, gli utenti aziendali lavorano in modo più efficiente con un data warehouse rispetto a un data lake; per esempio, in Amazon ci sono Redshift (data warehouse analitico) e Redshift Spectrum/Athena (interfaccia SQL per data lake in S3 basata su Hive/Presto). Lo stesso vale per altri moderni data warehouse analitici.
Esaminiamo l'architettura tipica di un data warehouse:
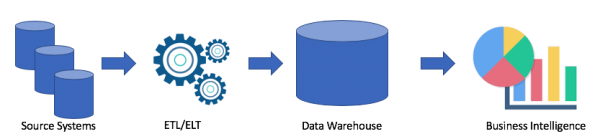
Questa è una soluzione classica. Abbiamo sistemi di origine, e mediante ETL/ELT copiamo i dati nel data warehouse analitico e li colleghiamo alla soluzione di Business Intelligence (il mio preferito è Tableau, e il vostro?).
Questa soluzione presenta i seguenti svantaggi:
- Le operazioni ETL/ELT richiedono tempo e risorse.
- In genere, lo spazio di archiviazione all'interno di un data warehouse analitico non è economico (ad esempio Redshift, BigQuery, Teradata), poiché dobbiamo acquistare un intero cluster.
- Gli utenti aziendali hanno accesso a dati puliti e spesso aggregati e non hanno la possibilità di ottenere i dati grezzi.
Certo, tutto dipende dal tuo caso. Se non hai problemi con il tuo data warehouse, non hai affatto bisogno di un lago di dati. Ma quando emergono problemi di spazio, potenza o quando il costo gioca un ruolo chiave, allora si può considerare l'opzione di un lago di dati. Proprio per questo motivo, i laghi di dati sono molto popolari. Ecco un esempio di architettura di un lago di dati:
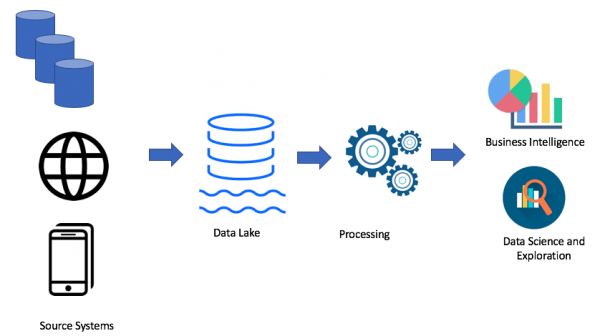
Utilizzando l'approccio del lago di dati, carichiamo dati grezzi nel nostro lago di dati (in batch o in streaming), quindi elaboriamo i dati secondo necessità. Il lago di dati consente agli utenti aziendali di creare le proprie trasformazioni dei dati (ETL/ELT) o di analizzare i dati in soluzioni di Business Intelligence (se c'è il driver necessario).
L'obiettivo di qualsiasi soluzione analitica è servire gli utenti aziendali. Pertanto, dobbiamo sempre lavorare a partire dalle esigenze del business. (In Amazon è uno dei principi — working backwards).
Lavorando sia con il data warehouse che con il lago di dati, possiamo confrontare entrambe le soluzioni:
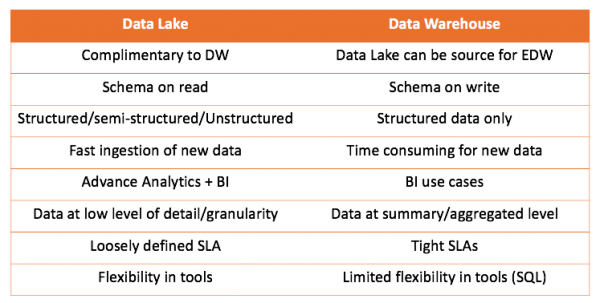
La conclusione principale da trarre è che un data warehouse non compete affatto con un data lake, ma lo integra. Tuttavia, spetta a te decidere cosa sia più adatto al tuo caso. È sempre interessante provare personalmente e trarre le giuste conclusioni.
Vorrei anche parlare di uno dei casi in cui ho iniziato a utilizzare l'approccio del data lake. Tutto è piuttosto banale, ho cercato di utilizzare uno strumento ELT (avevamo Matillion ETL) insieme ad Amazon Redshift; la mia soluzione funzionava, ma non soddisfaceva i requisiti.
Avevo la necessità di prendere i log web, trasformarli e aggregarli per fornire dati per due casi d'uso:
- Il team marketing voleva analizzare l'attività dei bot per la SEO
- L'IT voleva monitorare le metriche sulle prestazioni dei siti web
Log molto semplici, davvero semplici. Ecco un esempio:
https 2018-07-02T22:23:00.186641Z app/my-loadbalancer/50dc6c495c0c9188
192.168.131.39:2817 10.0.0.1:80 0.086 0.048 0.037 200 200 0 57
"GET https://www.example.com:443/ HTTP/1.1" "curl/7.46.0" ECDHE-RSA-AES128-GCM-SHA256 TLSv1.2
arn:aws:elasticloadbalancing:us-east-2:123456789012:targetgroup/my-targets/73e2d6bc24d8a067
"Root=1-58337281-1d84f3d73c47ec4e58577259" "www.example.com" "arn:aws:acm:us-east-2:123456789012:certificate/12345678-1234-1234-1234-123456789012"
1 2018-07-02T22:22:48.364000Z "authenticate,forward" "-" "-"Un file pesava tra 1 e 4 megabyte.
C'era però una difficoltà. Avevamo 7 domini in tutto il mondo e venivano creati 7000 file in un giorno. Non sono volumi molto elevati, solo 50 gigabyte. Ma anche la dimensione del nostro cluster Redshift era ridotta (4 nodi). Caricare tradizionalmente un file richiedeva circa un minuto. Quindi, il problema non si risolveva direttamente. Era il momento di adottare un approccio al lake data. La soluzione si presentava più o meno così:
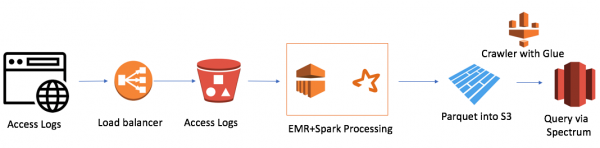
È abbastanza semplice (voglio sottolineare che uno dei vantaggi del lavoro nel cloud è la semplicità). Ho utilizzato:
- AWS Elastic Map Reduce (Hadoop) come potenza di calcolo
- AWS S3 come storage per file con la possibilità di crittografia dei dati e controllo degli accessi
- Spark come potenza di calcolo InMemory e PySpark per la logica e la trasformazione dei dati
- Parquet come risultato del lavoro di Spark
- AWS Glue Crawler come raccoglitore di metadati sui nuovi dati e partizioni
- Redshift Spectrum come interfaccia SQL per il lake data per gli utenti esistenti di Redshift
Il cluster EMR+Spark più piccolo elaborava un'intera serie di file in 30 minuti. Ci sono anche altri casi d'uso per AWS, specialmente molti legati ad Alexa, dove ci sono enormi quantità di dati.
Recentemente ho scoperto uno svantaggio del lago di dati: è il GDPR. Il problema è che quando il cliente richiede di eliminarlo, e i dati si trovano in uno dei file, non possiamo utilizzare il Data Manipulation Language e l'operazione DELETE come in un database.
Spero che l'articolo abbia chiarito la differenza tra un data warehouse e un data lake. Se è stato interessante, posso tradurre altri miei articoli o articoli di professionisti che leggo. Posso anche parlare delle soluzioni con cui lavoro e della loro architettura.
Fonte: habr.com
