


Introduzione
Ciao!
In questo articolo condividerò l'esperienza nella costruzione di un'architettura microservizi per un progetto che utilizza reti neurali.
Discuteremo i requisiti architetturali, analizzeremo vari diagrammi strutturali, esamineremo ciascun componente dell'architettura già pronta e valuteremo le metriche tecniche della soluzione.
Buona lettura!
Un paio di parole sul compito e sulla sua soluzione
L'idea principale è fornire una valutazione dell'attrattività di una persona basata su una foto, utilizzando una scala da uno a dieci.
In questo articolo non ci concentreremo sulla descrizione delle reti neurali utilizzate né sul processo di preparazione dei dati e dell'addestramento. Tuttavia, in una delle prossime pubblicazioni, torneremo sicuramente ad analizzare il pipeline di valutazione a un livello più approfondito.
Ora daremo un'occhiata al pipeline di valutazione a un livello alto, ponendo l'accento sull'interazione dei microservizi nel contesto dell'architettura generale del progetto.
Nell'affrontare il pipeline di valutazione dell'attrattività, il compito è stato decomposto nei seguenti elementi:
- Riconoscimento dei volti nelle foto
- Valutazione di ciascun volto
- Rendering del risultato
Il primo è risolto da un modello pre-addestrato . Per il secondo è stata addestrata una rete neurale convoluzionale su PyTorch, utilizzando come backbone – in bilanciamento tra «qualità / velocità di inferenza su CPU»

Diagramma funzionale del pipeline di valutazione
Analisi dei requisiti per l'architettura del progetto
Nel ciclo di vita del progetto, le fasi di lavoro sulla progettazione e automazione del deployment del modello sono spesso le più dispendiose in termini di tempo e risorse.
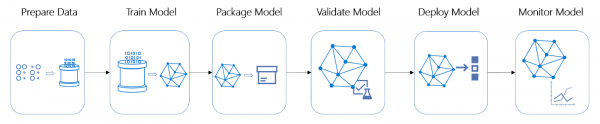
Ciclo di vita del progetto ML
Questo progetto non fa eccezione – è stata presa la decisione di avvolgere il pipeline di valutazione in un servizio online, il che ha richiesto un'immersione nell'architettura. Sono stati definiti i seguenti requisiti di base:
- Un'unica repository dei log – tutti i servizi devono scrivere i log in un unico posto, rendendo facile l'analisi
- Possibilità di scalabilità orizzontale del servizio di valutazione — come il possibile colosso Bottleneck
- A ciascuna immagine deve essere dedicata la stessa quantità di risorse del processore — per evitare outlier nella distribuzione dei tempi di inferenza
- Velocità di (ri)distribuzione sia di servizi specifici che dell'intero stack
- Possibilità di utilizzare oggetti comuni in diversi servizi, se necessario
Architettura
Dall'analisi dei requisiti, è diventato chiaro che l'architettura a microservizi si adatta praticamente alla perfezione.
Per eliminare il fastidio, è stato scelto Telegram API come frontend.
Iniziamo esaminando il diagramma strutturale dell'architettura pronta, quindi passeremo alla descrizione di ciascun componente e formuleremo il processo per una corretta elaborazione dell'immagine.
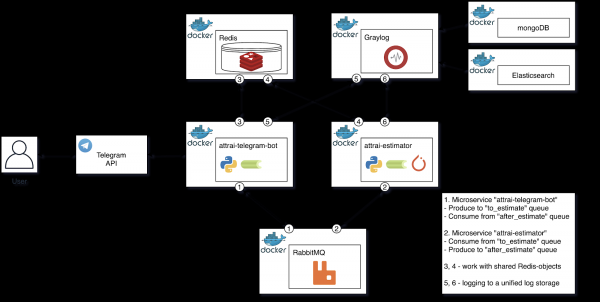
Diagramma strutturale dell'architettura pronta
Parliamo più nel dettaglio di ciascun componente del diagramma e definiamo la loro Responsabilità Singola nel processo di valutazione dell'immagine.
Microservizio «attrai-telegram-bot»
Questo microservizio incapsula tutte le interazioni con Telegram API. Si possono distinguere due scenari principali: elaborazione dell'immagine dell'utente e gestione dei risultati della pipeline di valutazione. Analizziamo entrambi gli scenari in modo generale.
Quando si riceve un messaggio dall'utente con un'immagine:
- Si esegue un filtraggio che consiste nelle seguenti verifiche:
- Presenza di immagini di dimensioni ottimali
- Numero di immagini dell'utente già in coda
- Durante la filtrazione iniziale, l'immagine viene salvata in un volume docker
- Nella coda “to_estimate” viene prodotto un task, che include il percorso dell'immagine presente nel nostro volume
- Se i passaggi sopra menzionati vengono completati con successo, l'utente riceverà un messaggio con il tempo approssimativo di elaborazione dell'immagine, calcolato in base al numero di task in coda. In caso di errore, l'utente sarà chiaramente informato con un messaggio che indica cosa potrebbe essere andato storto.
Inoltre, questo microservizio, come worker celery, ascolta la coda «after_estimate», progettata per i task che hanno superato il pipeline di valutazione.
Alla ricezione di un nuovo task da “after_estimate”:
- Se l'immagine è stata elaborata con successo, inviamo il risultato all'utente; in caso contrario, notifichiamo l'errore
- Rimuoviamo l'immagine che è il risultato del pipeline di valutazione
Microservizio di valutazione «attrai-estimator»
Questo microservizio è un worker celery e racchiude tutto ciò che riguarda il pipeline di valutazione dell'immagine. L'algoritmo di funzionamento qui è uno solo – esaminiamolo.
Alla ricezione di un nuovo task da “to_estimate”:
- Passiamo l'immagine attraverso il pipeline di valutazione:
- Carichiamo l'immagine in memoria
- Adattiamo l'immagine alle dimensioni corrette
- Identifichiamo tutti i volti (MTCNN)
- Valutiamo tutti i volti (raggruppiamo i volti trovati nel passaggio precedente e facciamo inferenze con ResNet34)
- Renderizziamo l'immagine finale
- Disegniamo i bounding box
- Disegniamo le valutazioni
- Rimuoviamo l'immagine utente (originale)
- Salviamo l'uscita del pipeline di valutazione
- Mettiamo il task in coda "after_estimate", che viene ascoltato dal microservizio "attrai-telegram-bot" sopra menzionato
Graylog (+ mongoDB + Elasticsearch)
— è una soluzione per la gestione centralizzata dei log. In questo progetto, è stata utilizzata per il suo scopo principale.
La scelta è ricaduta proprio su di esso, anziché sul noto stack, a causa della facilità di utilizzo con Python. Tutto ciò che è necessario fare per il logging in Graylog è aggiungere GELFTCPHandler dal pacchetto ai restanti root logger handlers del nostro microservizio Python.
Io, come persona che aveva lavorato solo con l'ELK stack in precedenza, ho avuto un'esperienza positiva lavorando con Graylog. L'unica cosa che delude è il predominio delle funzionalità di Kibana rispetto all'interfaccia web di Graylog.
RabbitMQ
— è un broker di messaggi basato sul protocollo AMQP.
In questo progetto è stato utilizzato come per Celery e ha funzionato in modalità durabile.
Redis
— è un DBMS NoSQL che lavora con strutture di dati di tipo «chiave — valore».
A volte è necessario utilizzare in diversi microservizi Python oggetti condivisi che implementano determinate strutture di dati.
Ad esempio, in Redis si conserva una hashmap del tipo «telegram_user_id => numero di task attivi in coda», il che consente di limitare il numero di richieste da un utente a un determinato valore, evitando così attacchi DoS.
Formalizziamo il processo di elaborazione delle immagini
- L'utente invia un'immagine al bot di Telegram
- «attrai-telegram-bot» riceve il messaggio dall'API di Telegram e lo analizza
- Il task con l'immagine viene aggiunto alla coda asincrona «to_estimate»
- L'utente riceve un messaggio con il tempo previsto di valutazione
- «attrai-estimator» prende il task dalla coda «to_estimate», lo elabora attraverso il pipeline di valutazione e produce il task nella coda «after_estimate»
- «attrai-telegram-bot», che ascolta la coda «after_estimate», invia il risultato all'utente
DevOps
Infine, dopo aver esaminato l'architettura, possiamo passare a una parte non meno interessante: il DevOps.
Docker Swarm

— un sistema di clustering le cui funzionalità sono integrate nel Docker Engine e disponibili out-of-the-box.
Con l'ausilio del "gruppo", tutti i nodi del nostro cluster possono essere suddivisi in 2 tipi: worker e manager. Sulle macchine del primo tipo vengono distribuiti gruppi di container (stack), mentre le macchine del secondo tipo si occupano di scalabilità, bilanciamento e I manager sono per impostazione predefinita anche worker.
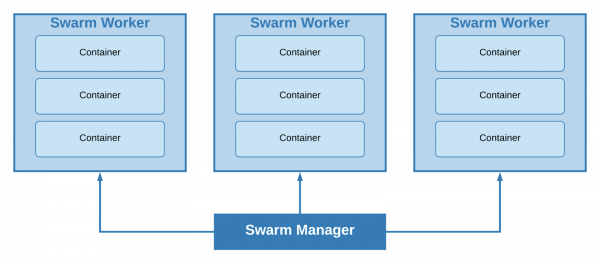
Un cluster con un leader manager e tre worker.
La dimensione minima possibile del cluster è di 1 nodo; l'unica macchina fungerà da leader manager e worker. In base alla dimensione del progetto e ai requisiti minimi di tolleranza ai guasti, è stata presa la decisione di utilizzare proprio questo approccio.
Anticipando, dico che dalla prima consegna in produzione, avvenuta a metà giugno, non ci sono stati problemi correlati a questa organizzazione del cluster (ma ciò non significa che tale configurazione sia in alcun modo accettabile per progetti di media-grande dimensione, che presentano requisiti di tolleranza ai guasti).
Docker Stack
In modalità 'stack', è responsabile del deployment degli stack (insiemi di servizi Docker)
Supporta i file di configurazione docker-compose, permettendo di utilizzare anche parametri di deploy.
Ad esempio, attraverso questi parametri sono state limitate le risorse per ciascuno degli istanziamenti del microservizio di valutazione (assegniamo N istanze a N core; nel microservizio limitiamo il numero di core utilizzato da PyTorch a uno)
attrai_estimator:
image: 'erqups/attrai_estimator:1.2'
deploy:
replicas: 4
resources:
limits:
cpus: '4'
restart_policy:
condition: on-failure
…È importante notare che Redis, RabbitMQ e Graylog sono servizi stateful e non è così semplice scalare come per 'attrai-estimator'.
Prevedendo la domanda: perché non Kubernetes?
Sembra che utilizzare Kubernetes in progetti piccoli e medi sia un sovraccarico; tutte le funzionalità necessarie possono essere ottenute da Docker Swarm, che è abbastanza user-friendly come orchestratore di container e ha una bassa barriera all'ingresso.
Infrastruttura
Tutto questo è stato implementato su un VDS con le seguenti caratteristiche:
- CPU: 4 core Intel® Xeon® Gold 5120 CPU @ 2.20GHz
- RAM: 8 GB
- SSD: 160 GB
Dopo il test di carico locale, sembrava che questa macchina potesse reggere solo con il minimo sforzo durante un afflusso significativo di utenti.
Ma subito dopo il deployment, ho condiviso il link su uno dei più popolari imageboard nella CSI (sì, quello stesso), e le persone si sono mostrate interessate; nel giro di poche ore, il servizio ha elaborato con successo decine di migliaia di immagini. Anche nei momenti di picco, le risorse CPU e RAM non erano nemmeno utilizzate a metà.
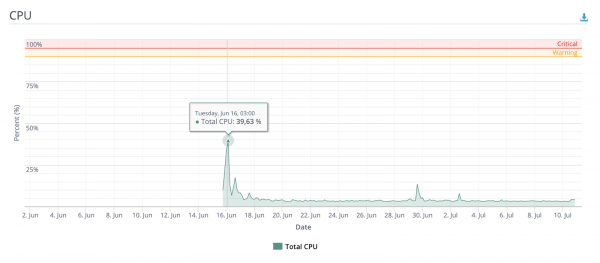
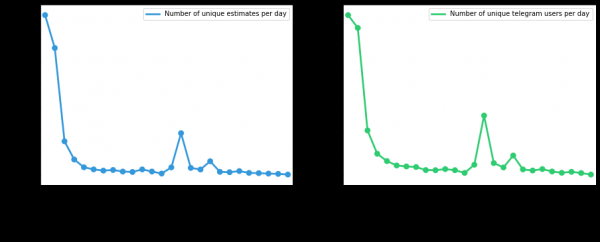
Ancora un po' di grafica
Numero di utenti unici e richieste di valutazione, dal momento del deployment, a seconda del giorno
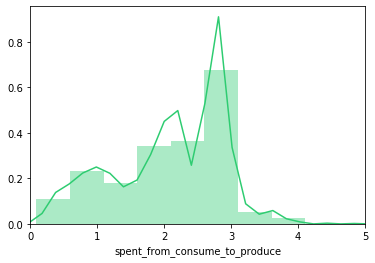
Distribuzione del tempo di inferenza del pipeline di valutazione
Conclusioni
In sintesi, posso dire che l'architettura e l'approccio all'orchestrazione dei container si sono rivelati completamente efficaci: anche nei momenti di picco non ci sono stati cali o ritardi nel tempo di elaborazione.
Penso che progetti di piccole e medie dimensioni, che utilizzano inferenze in tempo reale di reti neurali su CPU, possano adottare con successo le pratiche descritte in questo articolo.
Aggiungo che inizialmente l'articolo era più lungo, ma per evitare di pubblicare un lungo testo ho deciso di omettere alcuni punti in questo articolo — ne riparleremo nei prossimi post.
Puoi provare il bot su Telegram — @AttraiBot, funzionerà almeno fino alla fine dell'autunno 2020. Ricordo che nessun dato dell'utente viene memorizzato — né le immagini originali, né i risultati del processo di valutazione — tutto viene eliminato dopo l'elaborazione.
Fonte: habr.com
