

È impossibile spiegare il motivo per cui ho letto questo. Avevo solo tempo ed ero interessato a come funziona il mercato. E questo è già un mercato a tutti gli effetti secondo Gartner dal 2018. Dal 2014 al 2016 si chiamava Advanced Analytics (radici nella BI), nel 2017 - Data Science (non so come tradurlo in russo). Per chi fosse interessato agli spostamenti dei venditori in piazza è possibile Aspetto. E parlerò della piazza del 2020, soprattutto perché i cambiamenti rispetto al 2019 sono minimi: SAP si è trasferita e Altair ha acquistato Datawatch.
Questa non è un'analisi sistematica o una tabella. Una visione individuale, anche dal punto di vista di un geofisico. Ma sono sempre curioso di leggere Gartner MQ, formulano perfettamente alcuni punti. Quindi ecco le cose a cui ho prestato attenzione sia dal punto di vista tecnico, dal punto di vista del mercato che da quello filosofico.
Questo non è per le persone che approfondiscono l'argomento del ML, ma per le persone interessate a ciò che accade generalmente nel mercato.
Lo stesso mercato DSML si annida logicamente tra i servizi per sviluppatori BI e Cloud AI.
Prima le citazioni e i termini preferiti:
- "Un Leader potrebbe non essere la scelta migliore" — Un leader di mercato non è necessariamente ciò di cui hai bisogno. Molto urgente! A causa della mancanza di un cliente funzionale, sono sempre alla ricerca della soluzione “migliore”, piuttosto che di quella “adatta”.
- "Operazionalizzazione del modello" - abbreviato in MOP. E tutti hanno difficoltà con i carlini! – (il bel tema del carlino fa funzionare il modello).
- "Ambiente notebook" è un concetto importante in cui codice, commenti, dati e risultati si uniscono. Questo è molto chiaro, promettente e può ridurre significativamente la quantità di codice dell'interfaccia utente.
- "Radicato nell'OpenSource" - ben detto - affonda le sue radici nell'open source.
- "Scienziati dei dati cittadini" - Ragazzi così facili, così stupidi, non esperti, che hanno bisogno di un ambiente visivo e di ogni sorta di cose ausiliarie. Non codificheranno.
- "Democrazia" – spesso usato per significare “rendere disponibile a una gamma più ampia di persone”. Possiamo dire “democratizzare i dati” invece del pericoloso “liberare i dati” che usavamo in passato. La “democratizzazione” è sempre una lunga coda e tutti i venditori la inseguono. Perdere in intensità di conoscenza – guadagnare in accessibilità!
- "Analisi esplorativa dei dati - EDA" — considerazione dei mezzi disponibili. Alcune statistiche. Una piccola visualizzazione. Qualcosa che tutti fanno, in un modo o nell'altro. Non sapevo ci fosse un nome per questo
- "Riproducibilità" — massima conservazione di tutti i parametri ambientali, input e output in modo che l'esperimento possa essere ripetuto una volta effettuato. Il termine più importante per un ambiente di test sperimentale!
Quindi:
Alteryx
Interfaccia interessante, proprio come un giocattolo. La scalabilità, ovviamente, è un po’ difficile. Di conseguenza, la comunità di ingegneri Citizen ha intorno lo stesso con tchotchkes da giocare. L'analisi è tutta tua in una bottiglia. Mi ha ricordato un complesso di analisi dei dati di correlazione spettrale , programmato negli anni '90.
Anaconda
Comunità di esperti Python e R. Di conseguenza, l'open source è vasto. Si è scoperto che i miei colleghi lo usano sempre. Ma non lo sapevo.
DataBrick
Si compone di tre progetti open source: gli sviluppatori di Spark hanno raccolto un sacco di soldi dal 2013. Devo davvero citare il wiki:
“Nel settembre 2013, Databricks ha annunciato di aver raccolto 13.9 milioni di dollari da Andreessen Horowitz. La società ha raccolto ulteriori 33 milioni di dollari nel 2014, 60 milioni di dollari nel 2016, 140 milioni di dollari nel 2017, 250 milioni di dollari nel 2019 (febbraio) e 400 milioni di dollari nel 2019 (ottobre)”!!!
Alcune persone fantastiche hanno tagliato Spark. Non lo so, mi spiace!
E i progetti sono:
- Delta Lake - ACID su Spark è stato recentemente rilasciato (quello che sognavamo con Elasticsearch) - lo trasforma in un database: schema rigido, ACID, auditing, versioni...
- Flusso di machine learning — tracciabilità, confezionamento, gestione e archiviazione dei modelli.
- koala - API Pandas DataFrame su Spark - Pandas - API Python per lavorare con tabelle e dati in generale.
Puoi guardare Spark per coloro che non lo sanno o lo hanno dimenticato: . Ho guardato video con esempi di picchi di consulenza un po' noiosi ma dettagliati: DataBricks for Data Science () e per l'ingegneria dei dati ().
In breve, Databricks tira fuori Spark. Chiunque voglia utilizzare Spark normalmente nel cloud prende DataBricks senza esitazione, come previsto 🙂 Spark è il principale elemento di differenziazione qui.
Ho imparato che Spark Streaming non è un vero e proprio falso in tempo reale o microbatching. E se hai bisogno del vero Real Real Time, è in Apache STORM. Tutti dicono e scrivono anche che Spark è migliore di MapReduce. Questo è lo slogan.
DATIKU
Bella cosa end-to-end. Ci sono moltissime pubblicità. Non capisco in cosa differisce da Alteryx?
DataRobot
Paxata per la preparazione dei dati è una società separata acquistata da Data Robots nel dicembre 2019. Abbiamo raccolto 20 milioni di dollari e venduto. Tutto in 7 anni.
Preparazione dei dati in Paxata, non in Excel: vedere qui: .
Sono disponibili ricerche e proposte automatiche per unioni tra due set di dati. Una cosa grandiosa: per comprendere i dati, si darebbe ancora più enfasi alle informazioni testuali ().
Data Catalog è un eccellente catalogo di set di dati "live" inutili.
È anche interessante il modo in cui vengono formate le directory in Paxata ().
“Secondo la società di analisi , il software è reso possibile grazie ai progressi in , e metodologia di memorizzazione nella cache dei dati. Il software utilizza algoritmi per comprendere il significato delle colonne di una tabella dati e algoritmi di riconoscimento dei modelli per trovare potenziali duplicati in un set di dati. Utilizza anche l’indicizzazione, il riconoscimento di modelli di testo e altre tecnologie tradizionalmente presenti nei social media e nei software di ricerca”.
Il prodotto principale di Data Robot è . Il loro slogan è dal modello all'applicazione aziendale! Ho trovato consulenze per l'industria petrolifera in relazione alla crisi, ma erano molto banali e poco interessanti: . Ho guardato i loro video su Mops o MLops (). Questo è un Frankenstein assemblato da 6-7 acquisizioni di vari prodotti.
Naturalmente, diventa chiaro che un grande team di data scientist deve disporre proprio di un ambiente del genere per lavorare con i modelli, altrimenti ne produrranno molti e non distribuiranno mai nulla. E nella nostra realtà upstream del petrolio e del gas, se solo potessimo creare un modello di successo, sarebbe un grande progresso!
Il processo in sé ricordava molto, ad esempio, il lavoro con i sistemi di progettazione in geologia e geofisica . Chiunque non sia troppo pigro crea e modifica modelli. Raccogliere i dati nel modello. Quindi hanno realizzato un modello di riferimento e lo hanno inviato alla produzione! Tra, ad esempio, un modello geologico e un modello ML, puoi trovare molto in comune.
Domino
Enfasi sulla piattaforma aperta e sulla collaborazione. Gli utenti aziendali sono ammessi gratuitamente. Il loro Data Lab è molto simile a SharePoint. (E il nome sa fortemente di IBM). Tutti gli esperimenti si collegano al set di dati originale. Quanto è familiare :) Come nella nostra pratica, alcuni dati sono stati trascinati nel modello, quindi sono stati puliti e messi in ordine nel modello, e tutto questo è già presente nel modello e le estremità non possono essere trovate nei dati di origine .
Domino offre una fantastica virtualizzazione dell'infrastruttura. Ho assemblato alla macchina tutti i nuclei necessari in un secondo e sono andato a contare. Come sia stato fatto non è immediatamente chiaro. Docker è ovunque. Molta libertà! È possibile connettere qualsiasi area di lavoro delle versioni più recenti. Avvio parallelo di esperimenti. Monitoraggio e selezione di quelli di successo.
Lo stesso di DataRobot: i risultati vengono pubblicati per gli utenti aziendali sotto forma di applicazioni. Per “stakeholder” particolarmente dotati. E viene monitorato anche l’effettivo utilizzo dei modelli. Tutto per i Carlini!
Non capisco appieno come i modelli complessi finiscano in produzione. Viene fornita una sorta di API per fornire loro dati e ottenere risultati.
H2O
L'intelligenza artificiale driveless è un sistema molto compatto e intuitivo per il ML supervisionato. Tutto in una scatola. Non è del tutto chiaro subito il backend.
Il modello viene automaticamente inserito in un server REST o in un'app Java. Questa è una grande idea. Molto è stato fatto per l’interpretabilità e la spiegabilità. Interpretazione e spiegazione dei risultati del modello (cosa intrinsecamente non dovrebbe essere spiegabile, altrimenti una persona può calcolare lo stesso?).
Per la prima volta, un caso di studio sui dati non strutturati e . Immagine architettonica di alta qualità. E in generale mi sono piaciute le foto.
Esiste un ampio framework H2O open source che non è del tutto chiaro (un insieme di algoritmi/librerie?). Il tuo laptop visivo senza programmazione come Jupiter (). Ho letto anche di Pojo e Mojo: modelli H2O racchiusi in Java. Il primo è semplice, il secondo con ottimizzazione. H20 sono gli unici (!) a cui Gartner ha elencato l'analisi del testo e la PNL come punti di forza, così come i loro sforzi riguardo alla spiegabilità. È molto importante!
Allo stesso tempo: alte prestazioni, ottimizzazione e standard di settore nel campo dell'integrazione con hardware e cloud.
E la debolezza è logica: l'intelligenza artificiale di Driverles è debole e ristretta rispetto al suo open source. La preparazione dei dati è zoppa rispetto a Paxata! E ignorano i dati industriali: flusso, grafico, geografia. Ebbene, non può andare tutto bene.
KNIME
Mi sono piaciuti i 6 casi aziendali molto specifici e molto interessanti nella pagina principale. Forte Open Source.
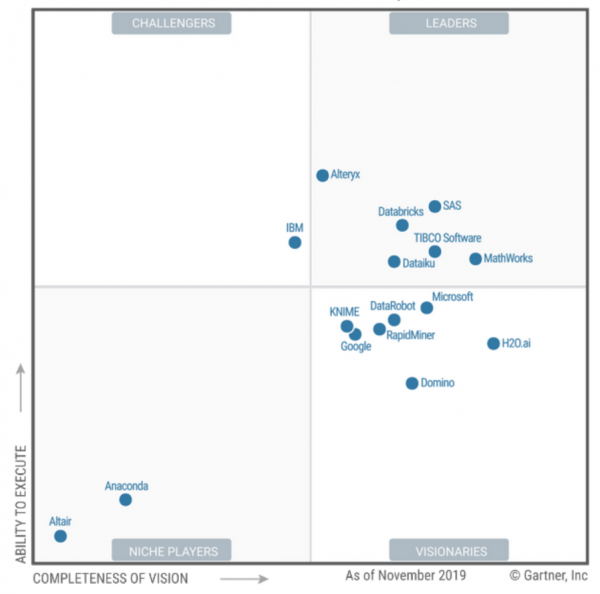
Gartner li ha retrocessi da leader a visionari. Guadagnare poco è un buon segno per gli utenti, dato che non sempre il Leader è la scelta migliore.
La parola chiave, come in H2O, è aumentata, il che significa aiutare i data scientist dei cittadini poveri. Questa è la prima volta che qualcuno viene criticato per la sua performance in una recensione! Interessante? Cioè, c'è così tanta potenza di calcolo che le prestazioni non possono essere affatto un problema sistemico? Gartner ha a che fare con la parola “Augmented” , che non è stato possibile raggiungere.
E KNIME sembra essere il primo non americano nella recensione! (E ai nostri designer è piaciuta molto la loro landing page. Persone strane.
MathWorks
MatLab è un vecchio compagno onorario noto a tutti! Cassette degli attrezzi per tutti gli ambiti e le situazioni della vita. Qualcosa di molto diverso. In effetti, tanta, tanta, tanta matematica per ogni cosa nella vita!
Un prodotto aggiuntivo Simulink per la progettazione di sistemi. Ho scavato nelle cassette degli attrezzi per i gemelli digitali: non ne capisco niente, ma molto è stato scritto. Per . In generale, questo è un prodotto fondamentalmente diverso dalle profondità della matematica e dell'ingegneria. Selezionare toolkit matematici specifici. Secondo Gartner i loro problemi sono gli stessi degli ingegneri intelligenti: nessuna collaborazione, ognuno fruga nel proprio modello, nessuna democrazia, nessuna spiegabilità.
Rapid Miner
Mi sono imbattuto e sentito molto prima (insieme a Matlab) nel contesto di un buon open source. Ho approfondito un po' TurboPrep come al solito. Sono interessato a come ottenere dati puliti da dati sporchi.
Ancora una volta puoi vedere che le persone sono brave in base ai materiali di marketing del 2018 e alle pessime persone che parlano inglese nella demo della funzionalità.
E persone di Dortmund dal 2001 con un forte background tedesco)

Ancora non capisco dal sito cosa sia esattamente disponibile in open source: devi scavare più a fondo. Ottimi video sulla distribuzione e sui concetti di AutoML.
Non c'è niente di speciale nemmeno nel backend di RapidMiner Server. Probabilmente sarà compatto e funzionerà bene su premium fuori dagli schemi. È confezionato in Docker. Ambiente condiviso solo sul server RapidMiner. E poi ci sono Radoop, i dati di Hadoop, il conteggio delle rime dal flusso di lavoro Spark in Studio.
Come previsto, i giovani venditori di "venditori di bastoncini a strisce" li hanno spostati verso il basso. Gartner, tuttavia, prevede il loro futuro successo nel settore Enterprise. Puoi raccogliere fondi lì. I tedeschi sanno come farlo, santo cielo :) Non menzionare SAP!!!
Fanno molto per i cittadini! Ma dalla pagina puoi vedere che Gartner afferma che stanno lottando con l'innovazione delle vendite e non stanno combattendo per l'ampiezza della copertura, ma per la redditività.
rimasto SAS и Tibco tipici fornitori di BI per me... Ed entrambi sono ai vertici, il che conferma la mia fiducia che la normale DataScience stia logicamente crescendo
dalla BI e non da cloud e infrastrutture Hadoop. Dal business, cioè, e non dall'IT. Come ad esempio in Gazpromneft: ,Un ambiente DSML maturo nasce da solide pratiche di BI. Ma forse è schifoso e parziale nei confronti dell’MDM e di altre cose, chi lo sa.
SAS
Non c'è molto da dire. Solo le cose ovvie.
TIBCO
La strategia viene letta in una lista della spesa su una pagina Wiki lunga una pagina. Sì, lunga storia, ma 28!!! Carlo. Ho comprato BI Spotfire (2007) nella mia giovinezza tecnologica. E anche report di Jaspersoft (2014), poi ben tre fornitori di analisi predittiva Insightful (S-plus) (2008), Statistica (2017) e Alpine Data (2017), elaborazione di eventi e streaming Streambase System (2013), MDM Orchestra Piattaforma in-memory Networks (2018) e Snappy Data (2019).
Ciao Frankie!

Fonte: habr.com
