

Lo sviluppo di un data warehouse è un'impresa lunga e seria.
Molto nella vita di un progetto dipende da quanto bene è pensato il modello degli oggetti e la struttura del database sin dall'inizio.
Il metodo comunemente adottato rimane un mix di schemi a "stella" con la terza forma normale. In genere, secondo il principio: dati sorgente — 3NF, data mart — stella. Questo approccio, ampiamente testato nel tempo e supportato da numerosi studi, è il primo (e a volte l'unico) pensiero di un esperto DWH quando si tratta di concepire come dovrebbe apparire un data warehouse analitico.
D'altra parte, le esigenze del business generalmente e quelle dei clienti in particolare tendono a cambiare rapidamente, e i dati non smettono di crescere sia “in profondità” che “in ampiezza”. Qui emerge il principale svantaggio dello schema a stella: la sua limitatezza. flessibilità.
E se nella vostra vita tranquilla e serena di sviluppatore DWH si presenta all'improvviso:
- la necessità di "fare qualcosa in fretta, poi vedremo";
- un progetto in rapida espansione, con l'integrazione di nuove fonti e la modifica del modello di business almeno una volta alla settimana;
- è comparso un cliente che non ha idea di come dovrebbe apparire il sistema e quali funzioni dovrebbe svolgere alla fine, ma è disposto a sperimentare e a chiarire progressivamente il risultato desiderato avvicinandosi ad esso con gradualità;
- è stato da noi un manager di progetto con una lieta notizia: “E ora abbiamo l'agile!”.
Oppure se siete semplicemente curiosi di scoprire altri modi di costruire archivi — benvenuti sotto il cat!
Cosa significa 'flessibilità'
Iniziamo definendo quali caratteristiche deve avere un sistema per potersi definire 'flessibile'.
Vale la pena sottolineare che le proprietà descritte devono riferirsi specificamente a un sistema, e non a un processo la sua sviluppo. Pertanto, se volevate leggere su Agile come metodologia di sviluppo, è meglio consultare altri articoli. Ad esempio, qui su Habr ci sono molti materiali interessanti (come e , sia ).
Questo non significa che il processo di sviluppo e la struttura del Data Warehouse non siano affatto correlati. In generale, sviluppare un repository di architettura flessibile seguendo il modello Agile dovrebbe essere sostanzialmente più facile. Tuttavia, nella pratica, si incontrano più frequentemente casi di sviluppo di un DWH tradizionale basato su Agile secondo Kimball e DataVault — secondo il waterfall, piuttosto che fortunate coincidenze di flessibilità in entrambe le sue forme in un unico progetto.
Quindi, quali sono le caratteristiche che un repository flessibile dovrebbe possedere? Possiamo evidenziare tre punti:
- Consegna precoce e rapida modifica — questo significa che idealmente il primo risultato di business (ad esempio, i primi report funzionanti) dovrebbe essere ottenuto il prima possibile, cioè ancora prima che il sistema sia completamente progettato e implementato. Inoltre, ogni successiva modifica dovrebbe richiedere il minor tempo possibile.
- Modifica iterativa — significa che ogni successivo sviluppo non dovrebbe idealmente influenzare le funzionalità già funzionanti. Questo aspetto si trasforma spesso nel maggior incubo nei grandi progetti: prima o poi, singoli elementi iniziano ad avere così tante interconnessioni che diventa più semplice replicare completamente la logica accanto, piuttosto che aggiungere un campo nella tabella esistente. E se vi sorprende che l'analisi dell'impatto di un'evoluzione su oggetti esistenti possa richiedere più tempo dello sviluppo stesso, è probabile che non abbiate ancora lavorato con grandi HD in ambito bancario o telecomunicazioni.
- Adattamento costante ai requisiti aziendali in evoluzione — la struttura generale degli oggetti deve essere progettata non solo tenendo conto di un possibile ampliamento, ma anche prevedendo che la direzione di questo prossimo ampliamento non poteva nemmeno venirvi in mente nella fase di progettazione.
E sì, soddisfare tutti questi requisiti all'interno di un unico sistema è possibile (ovviamente, in determinati casi e con alcune riserve).
Di seguito esplorerò due delle metodologie di progettazione agili più popolari per HD — Modulo Anchor e Data Vault. Rimangono fuori tecniche affascinanti come EAV, 6NF (nella sua forma pura) e tutto ciò che riguarda le soluzioni NoSQL - non perché siano in qualche modo inferiori, né perché in questo caso l'articolo rischierebbe di diventare lungo come una tesi di laurea media. Semplicemente, tutto ciò appartiene a soluzioni di un'altra categoria - o a tecniche che possono essere applicate in casi specifici, indipendentemente dall'architettura generale del vostro progetto (come EAV), o a paradigmi di archiviazione delle informazioni globalmente diversi (come ad esempio i database a grafo e altre opzioni NoSQL).
Problemi del approccio “classico” e le loro soluzioni nelle metodologie agili
Con approccio “classico” intendo la vecchia cara stella (indipendentemente dalla specifica implementazione dei livelli sottostanti, che i seguaci di Kimball, Inmon e CDM mi perdonino).
1. Cardinalità rigida delle relazioni
Alla base di questo modello c'è una chiara separazione dei dati in dimensioni (Dimension) e fatti (Fact). E questo, diamine, ha senso — poiché l'analisi dei dati si riduce nella stragrande maggioranza dei casi all'analisi di specifici indicatori numerici (fatti) in determinati contesti (dimensioni).
In questo caso, le relazioni tra gli oggetti sono stabilite sotto forma di legami tra le tabelle tramite chiavi esterne. Questo appare del tutto naturale, ma porta immediatamente al primo vincolo di flessibilità — una rigorosa definizione della cardinalità delle relazioni.
Ciò significa che nella fase di progettazione delle tabelle devi determinare con precisione se ogni coppia di oggetti correlati possa essere considerata come molti-a-molti, oppure solo 1-a-molti, e 'in quale direzione'. Questo influirà direttamente su quale tabella conterrà la chiave primaria e quale la chiave esterna. Una modifica di questa relazione in seguito a nuovi requisiti con alta probabilità porterà a una revisione del database.
Ad esempio, progettando l'oggetto 'scontrino', ti sei basato sulle assicuratissime affermazioni del reparto vendite per prevedere la possibilità di un'azione di una promozione su più posizioni dello scontrino (ma non viceversa):
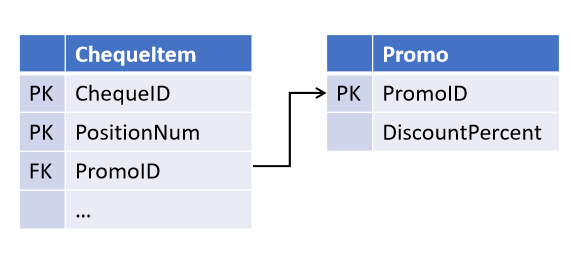
Dopo un po', i colleghi hanno introdotto una nuova strategia di marketing, in cui possono concorrere più promozioni contemporaneamente. Ora è necessario rielaborare le tabelle, evidenziando il legame in un oggetto separato.
(Tutti gli oggetti derivati in cui avviene il check di join sulle promozioni necessitano ora di una revisione).
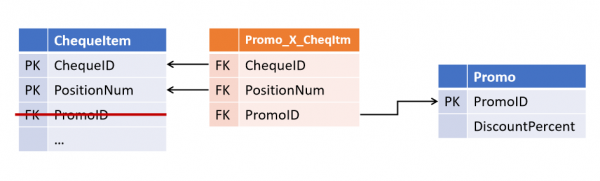
Relazioni nel Data Vault e Modello Anchor
Evitare tale situazione è risultato piuttosto semplice: non bisogna fidarsi del reparto vendite, è sufficiente memorizzare tutte le relazioni inizialmente in tabelle separate e gestirle come molti-a-molti.
Questo approccio è stato proposto da Dan Linstedt come parte della paradigmi Data Vault ed è stato completamente supportato da Lars Rönnbäck in del Modello Anchor.
Di conseguenza, otteniamo la prima caratteristica distintiva delle metodologie agili:
Le relazioni tra gli oggetti non sono memorizzate negli attributi delle entità genitrici, ma rappresentano un tipo separato di oggetti.
In Data Vault Tali tabelle di legame sono chiamate Link, e nella Modello Anchor — Tie. A prima vista sembrano molto simili, ma le loro differenze non si esauriscono nel nome (di cui si parlerà più avanti). In entrambe le architetture, le tabelle di collegamento possono connettere un numero qualsiasi di entità (non necessariamente 2).
Questa apparente ridondanza offre una notevole flessibilità nelle modifiche. Tale struttura diventa tollerante non solo ai cambiamenti delle cardinalità delle relazioni esistenti, ma anche all'aggiunta di nuove: se ora un articolo di scontrino avrà un link al cassiere che lo ha registrato, l'emergere di tale collegamento diventerà solo un'estensione delle tabelle esistenti senza influire su oggetti e processi attualmente esistenti.
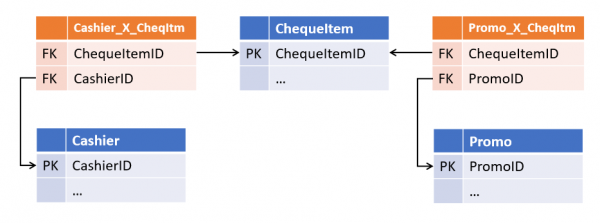
2. Duplicazione dei dati
Il secondo problema affrontato dalle architetture flessibili è meno ovvio e caratteristico, principalmente delle misure di tipo SCD2 (dimensioni lentamente mutevoli di secondo tipo), anche se non solo di esse.
In un classico data warehouse, una dimensione è solitamente rappresentata da una tabella che contiene una chiave surrogata (come PK) e anche un insieme di chiavi aziendali e attributi in colonne separate.

Se la misura supporta la versioning, al set standard di campi vengono aggiunti i confini temporali della versione, e in una riga della fonte appaiono più versioni nel repository (una per ogni modifica degli attributi di versioning).
Se la misura contiene almeno un attributo di versioning frequentemente modificato, il numero di versioni di tale misura sarà notevole (anche se gli altri attributi non sono versionati, o non vengono mai modificati), e se ci sono più di tali attributi, il numero di versioni può crescere in progressione geometrica in base al loro numero. Tale misura può occupare una quantità sostanziale di spazio su disco, anche se la maggior parte dei dati memorizzati consiste semplicemente in duplicati dei valori degli attributi immutabili di altre righe.
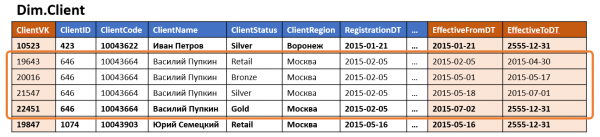
A tale proposito, si applica molto frequentemente anche denormalizzazione — parte degli attributi viene intenzionalmente memorizzata come valore, non come riferimento a un dizionario o ad un'altra misura. Questo approccio accelera l'accesso ai dati, riducendo il numero di join quando si accede alla misura.
In genere, ciò porta a la stessa informazione è memorizzata contemporaneamente in più posti. Ad esempio, le informazioni sulla regione di residenza e sulla categoria del cliente possono essere memorizzate simultaneamente nelle misurazioni “Cliente” e nei fatti “Acquisto”, “Consegna” e “Richieste al call center”, così come nella tabella di collegamento “Cliente — Manager del cliente”.
In generale, quanto descritto sopra si applica anche alle misurazioni normali (non versionate), ma nelle versionate può avere un'altra portata: l'emergere di una nuova versione dell'oggetto (soprattutto retroattivamente) non porta semplicemente all'aggiornamento di tutte le tabelle correlate, ma a un'emergenza a cascata di nuove versioni di oggetti correlati — quando la Tabella 1 è utilizzata nella costruzione della Tabella 2, e la Tabella 2 è utilizzata nella costruzione della Tabella 3, ecc. Anche se nessun attributo della Tabella 1 partecipa alla costruzione della Tabella 3 (ma partecipano altri attributi della Tabella 2, ottenuti da altre fonti), l'aggiornamento versionato di questa struttura comporterà almeno costi aggiuntivi, e al massimo versioni inutili nella Tabella 3, che qui è del tutto “non pertinente” e così via nella catena.
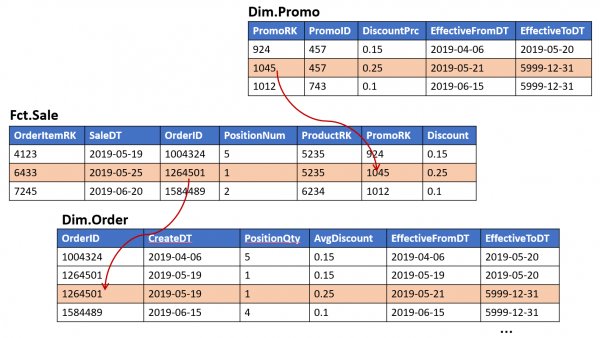
3. Complessità non lineare nell'implementazione
Ogni nuova vetrina, costruita sulla base di un'altra, aumenta il numero di punti in cui i dati possono 'divergere' quando si apportano modifiche all'ETL. Questo, a sua volta, porta a un aumento della complessità (e della durata) di ogni successiva modifica.
Se quanto descritto sopra riguarda sistemi con processi ETL raramente modificati, vivere in tale paradigma è possibile: basta prestare attenzione affinché le nuove modifiche vengano applicate correttamente a tutti gli oggetti collegati. Tuttavia, se le modifiche avvengono frequentemente, la probabilità di 'perdere' accidentalmente alcune connessioni aumenta significativamente.
Se poi si considera che l'ETL 'versionato' è sostanzialmente più complesso rispetto a quello 'non versionato', evitare errori durante le modifiche frequenti diventa piuttosto difficile.
Archiviazione degli oggetti e attributi nel Data Vault e Anchor Model
L'approccio proposto dagli autori delle architetture flessibili può essere formulato come segue:
È necessario separare ciò che cambia da ciò che rimane invariato. Vale a dire, archiviare le chiavi separatamente dagli attributi.
Tuttavia, non bisogna confondere non versionato attributo con immutabile: il primo non conserva la cronologia delle sue modifiche, ma può cambiare (ad esempio, in caso di correzione di un errore di input o ricezione di nuovi dati) il secondo - non cambia mai.
Le opinioni su cosa si possa considerare immutabile nel Data Vault e nel modello Anchor divergono.
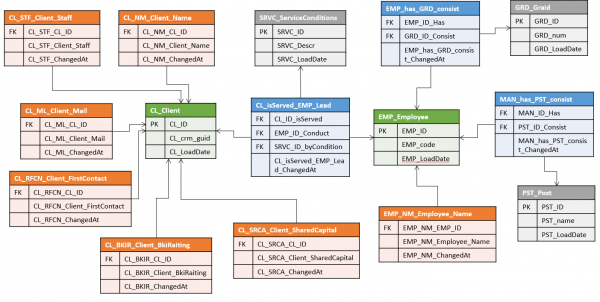
Dal punto di vista architettonico Data Vault, si può considerare immutabile l'intero insieme di chiavi — naturali (Codice Fiscale dell'organizzazione, codice prodotto nel sistema sorgente, ecc.) e surrogate. In questo caso, gli altri attributi possono essere divisi in gruppi in base alla fonte e/o alla frequenza delle modifiche e per ogni gruppo mantenere una tabella separata con un insieme di versioni indipendente.
Nella parbidigma Anchor Model si considera immutabile solo la chiave surrogata dell'entità. Tutto il resto (inclusi i tasti naturali) è semplicemente un caso particolare dei suoi attributi. In questo senso tutti gli attributi per impostazione predefinita sono indipendenti l'uno dall'altro, pertanto per ogni attributo deve essere creata una tabella separata.
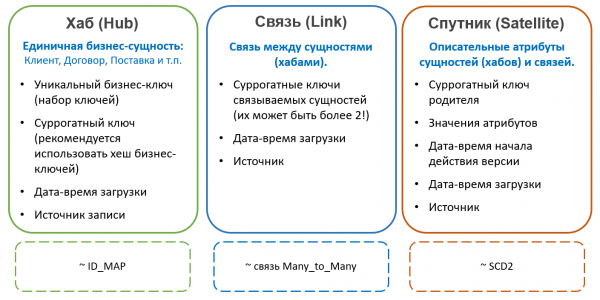
In Data Vault le tabelle contenenti le chiavi delle entità sono chiamate Hub. Gli Hub contengono sempre un insieme fisso di campi:
- Chiavi naturali dell'entità
- Chiave surrogata
- Riferimento alla fonte
- Tempo di aggiunta della registrazione
Le registrazioni negli Hub non cambiano mai e non hanno versioni. Esternamente, gli hub assomigliano molto a tabelle di tipo ID-map, utilizzate in alcuni sistemi per generare surrogate, tuttavia, per le surrogate nel Data Vault si raccomanda di utilizzare non una sequenza intera, ma un hash basato su un insieme di chiavi di business. Questo approccio semplifica il caricamento delle relazioni e degli attributi dalle fonti (non è necessario unire gli hub per ottenere la surrogata, basta calcolare l'hash della chiave naturale), ma può causare altri problemi (legati, ad esempio, a collisioni, maiuscole e caratteri non stampabili nelle chiavi stringa, ecc.), quindi non è universalmente accettato.
Tutti gli altri attributi delle entità sono memorizzati in tabelle speciali, chiamate Satellite (Satellit). Un hub può avere più satelliti che memorizzano diversi insiemi di attributi.
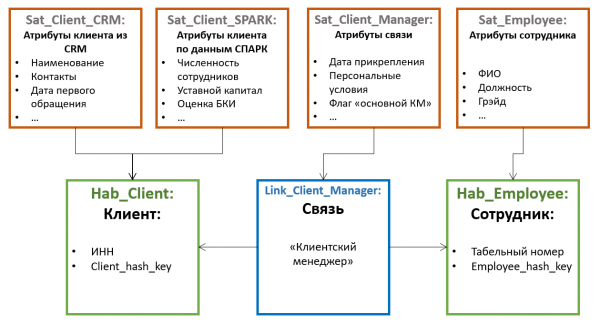
La distribuzione degli attributi tra i satelliti avviene secondo il principio di cambiamento congiunto — in un satellite possono essere memorizzati attributi non versionati (ad esempio, la data di nascita e il codice fiscale per le persone fisiche), in un altro quelli versionati che cambiano raramente (come il cognome e il numero del passaporto), in un terzo quelli che cambiano frequentemente (per esempio, l'indirizzo di spedizione, la categoria, la data dell'ultimo ordine, ecc.). La versioning è gestita a livello di singoli satelliti e non dell'entità nel suo complesso, pertanto è opportuno distribuire gli attributi in modo tale che l'intersezione delle versioni all'interno di uno stesso satellite sia minima (riducendo il numero totale delle versioni memorizzate).
Inoltre, per ottimizzare il processo di caricamento dei dati, gli attributi provenienti da diverse fonti vengono spesso estratti in satelliti separati.
I satelliti sono collegati al Hub tramite chiave esterna (che corrisponde a una cardinalità 1-a-molti). Questo significa che valori multipli di un attributo (ad esempio, diversi numeri di telefono di un singolo cliente) sono supportati da questa architettura 'per impostazione predefinita'.
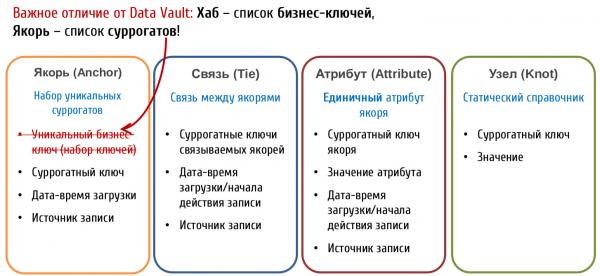
In Modello Anchor le tabelle che memorizzano le chiavi sono chiamate Ancora. E memorizzano:
- Solo chiavi surrogate
- Riferimento alla fonte
- Tempo di aggiunta della registrazione
Le chiavi naturali, secondo il Modello Anchor, sono considerate attributi comuni. Questa opzione può sembrare più complessa da comprendere, ma offre sicuramente maggiore libertà per l'identificazione dell'oggetto.
Ad esempio, se i dati relativi alla stessa entità possono provenire da sistemi diversi, ognuno dei quali utilizza la propria chiave naturale. Nel Data Vault ciò può portare a costruzioni piuttosto ingombranti che comprendono più hub (uno per fonte + una versione master unificata), mentre nel modello Anchor la chiave naturale di ciascuna fonte entra nel proprio attributo e può essere utilizzata al caricamento indipendentemente da tutti gli altri.
Ma qui si nasconde un punto insidioso: se in un'unica entità si uniscono attributi provenienti da sistemi diversi, è probabile che esistano alcune regole di 'fusionè, secondo cui il sistema deve comprendere che i record provenienti da fonti diverse corrispondono a un'unica istanza dell'entità.
In Data Vault Queste regole probabilmente determineranno la formazione di un 'hub surrogato' dell'entità master e non influenzare i Hub, che memorizzano le chiavi naturali delle fonti e i loro attributi originali. Se in qualche momento le regole di fusione cambiano (o arriva un aggiornamento degli attributi secondo cui avviene), sarà sufficiente riformare i hub surrogati.
In Modello ancorato tale entità sarà probabilmente memorizzata in un unico ancoraggio. Questo significa che tutti gli attributi, indipendentemente dalla fonte di provenienza, saranno legati allo stesso surrogato. Separare le registrazioni erroneamente fuse e monitorare l'attualità della fusione in un sistema del genere potrebbe risultare notevolmente più difficile, soprattutto se le regole sono abbastanza complesse e cambiano frequentemente, e lo stesso attributo potrebbe provenire da diverse fonti (anche se è possibile, poiché ogni versione dell'attributo mantiene un riferimento alla propria sorgente).
In ogni caso, se nella vostra sistema è prevista l'implementazione di funzionalità di deduplicazione, fusione di registri e altri elementi MDM, è particolarmente importante fare attenzione agli aspetti di conservazione delle chiavi naturali nelle metodologie agili. È probabile che una struttura più complessa come il Data Vault si dimostri improvvisamente più sicura in termini di errori di fusione.
Modello ancorato prevede anche un tipo aggiuntivo di oggetto chiamato Nodo (Knot) fondamentalmente è un tipo speciale di ancoraggio degenerato, che può contenere solo un attributo. I nodi sono pensati per l'archiviazione di dizionari piatti (ad esempio sesso, stato civile, categoria di assistenza ai clienti, ecc.). A differenza dell'ancora, il nodo non ha tabelle di attributi correlate, e il suo unico attributo (nome) è sempre conservato nella stessa tabella con la chiave. I nodi sono collegati agli ancoraggi tramite tabelle di relazione (Tie) proprio come gli ancoraggi tra di loro.
Non esiste un'opinione univoca sull'uso dei nodi. Ad esempio, , che promuove attivamente l'uso del modello ancorato in Russia, ritiene (non senza fondamento) che non si possa affermare con certezza per nessun dizionario che esso sempre sarà statico e unidimensionale, quindi per tutti gli oggetti è meglio utilizzare subito un Anchor completo.
Un'altra importante differenza tra Data Vault e il modello Anchor è la presenza di attributi nelle relazioni.:
In Data Vault Le relazioni sono oggetti a pieno titolo, proprio come gli Hub, e possono avere i propri attributi.. In Modello ancorato Le relazioni vengono utilizzate solo per collegare gli Anchors e non possono avere i propri attributi.Questa differenza produce approcci sostanzialmente diversi alla modellazione dei fatti,di cui si parlerà in seguito.
Memorizzazione dei fatti.
Fino ad ora abbiamo parlato principalmente della modellazione delle misure. I fatti presentano una situazione leggermente meno chiara.
In Data Vault Un oggetto tipico per la memorizzazione dei fatti è la Relazione (Link),nelle cui Satelliti si accumulano indicatori misurabili.
Questo approccio sembra intuitivo. Fornisce un accesso semplice agli indicatori analizzati ed è generalmente simile a una tradizionale tabella dei fatti (solo che gli indicatori non sono memorizzati nella tabella stessa, ma in "una tabella vicina"). Tuttavia, ci sono anche delle insidie: una delle modifiche tipiche del modello — l'espansione della chiave di fatto — comporta la necessità di aggiungere una nuova chiave esterna nel Link.. Questo, a sua volta, “complica” la modularità e potrebbe richiedere modifiche ad altri oggetti.
In Modello ancorato Una relazione non può avere attributi propri, quindi questo approccio non funzionerà — tutti gli attributi e gli indicatori devono essere collegati a un singolo ancoraggio specifico. La conclusione è semplice — ogni fatto ha bisogno del suo ancoraggio. Per alcune cose che consideriamo fatti, può sembrare naturale — ad esempio, il fatto di acquistare si traduce perfettamente in un oggetto “ordine” o “ricevuta”, la visita a un sito — in una sessione e così via. Ma ci sono anche fatti per i quali non è così semplice trovare un “oggetto portante” naturale — ad esempio, le giacenze di merce nei magazzini all'inizio di ogni giorno.
Pertanto, non ci sono problemi di modularità nell'espandere la chiave del fatto nel modello Ancoraggio (è sufficiente aggiungere una nuova Relazione all'ancoraggio corrispondente), ma la progettazione del modello per visualizzare i fatti è meno univoca, possono apparire “ancoraggi” “artificiali” che non rappresentano chiaramente il modello aziendale.
Come si raggiunge la flessibilità
La struttura risultante in entrambi i casi contiene significativamente più tabelle, rispetto a una misurazione tradizionale. Ma può occupare notevolmente meno spazio su disco con lo stesso insieme di attributi di versione della misurazione tradizionale. Non c'è niente di magico, naturalmente — si tratta di normalizzazione. Distribuendo gli attributi tra i Satelliti (in Data Vault) o in tabelle separate (Anchor Model), riduciamo (o eliminiamo del tutto) la duplicazione dei valori di alcuni attributi quando altri cambiano.
Per Data Vault il guadagno dipenderà dalla distribuzione degli attributi tra i Satelliti, e per Modello ancorato è praticamente direttamente proporzionale al numero medio di versioni per oggetto di misurazione.
Tuttavia, il risparmio di spazio — è un vantaggio importante, ma non il principale vantaggio della memorizzazione separata degli attributi. Insieme alla memorizzazione separata delle relazioni, questo approccio rende il magazzino una costruzione modulare. Ciò significa che l'aggiunta sia di singoli attributi che di intere nuove aree tematiche in tale modello appare come un'estensione sul set esistente di oggetti senza modificarli. Ed è proprio questo che rende le metodologie descritte flessibili.
Questo ricorda anche il passaggio dalla produzione artigianale a quella di massa: se nell'approccio tradizionale ogni tabella modello è unica e richiede attenzione separata, nelle metodologie agili si tratta già di un insieme di “componenti” standardizzati. Da un lato, ci sono più tabelle, i processi di caricamento e di estrazione dei dati devono apparire più complessi. Dall'altro lato, esse diventano standardizzate. Questo significa che possono essere automatizzate e gestite tramite metadati. La domanda “come organizzeremo tutto?”, la cui risposta richiedeva una parte consistente del lavoro di progettazione delle modifiche, ora non si pone più (come non si pone la questione dell'impatto delle modifiche del modello sui processi esistenti).
Ciò non significa che gli analisti in un sistema di questo tipo non siano affatto necessari: qualcuno deve comunque elaborare un insieme di oggetti con attributi e capire da dove e come caricare tutto questo. Tuttavia, il volume di lavoro, così come la probabilità e il costo di un errore, si riducono notevolmente. Sia nella fase di analisi che nello sviluppo di ETL, che in gran parte può essere ridotto all'editing di metadati.
Il lato oscuro
Tutto quanto sopra rende entrambi gli approcci davvero flessibili, tecnologici e adatti a sviluppi iterativi. Naturalmente, c'è anche un “barile di mele marce”, di cui penso vi siate già accorti.
La decomposizione dei dati, che sta alla base della modularità delle architetture flessibili, porta a un aumento del numero di tabelle e, di conseguenza, di costi indiretti per i join durante le query. Per ottenere semplicemente tutti gli attributi della dimensione, in un magazzino classico è sufficiente un solo select, mentre un'architettura flessibile richiederà una serie di join. E se per i report questi join possono essere scritti in anticipo, gli analisti, abituati a scrivere SQL manualmente, subiranno un doppio svantaggio.
Ci sono diversi fatti che rendono questa situazione più gestibile:
Quando si lavora con dimensioni grandi, raramente vengono utilizzati tutti i suoi attributi contemporaneamente. Questo significa che i join possono essere inferiori a quanto sembri a prima vista nel modello. In Data Vault si può anche considerare la frequenza prevista di utilizzo nella distribuzione degli attributi tra i satelliti. I hub o ancore sono necessari principalmente per la generazione e il mapping dei surrogate durante il caricamento e sono raramente utilizzati nelle query (soprattutto per quanto riguarda le ancore).
Tutti i join sono basati su chiave. Inoltre, un modo di archiviazione più "compresso" riduce le spese generali per la scansione delle tabelle dove necessario (ad esempio, durante il filtraggio per valore dell'attributo). Ciò può portare a una selezione da un database normalizzato con molti join che risulta persino più veloce della scansione di una sola dimensione pesante con molte versioni per riga.
Ad esempio, in questo articolo c'è un dettagliato test comparativo delle prestazioni del modello ad ancore con una selezione da una singola tabella.
Molto dipende dal motore. Molte moderne piattaforme dispongono di meccanismi interni per ottimizzare le join. Ad esempio, MS SQL e Oracle possono 'saltare' le join su tabelle se i loro dati non vengono utilizzati da nessun'altra parte, eccetto in altre join e non influiscono sul risultato finale (eliminazione delle tabelle/join), mentre MPP Vertica ha , di essere un eccellente motore per il Modello Anchora, tenendo conto di una certa ottimizzazione manuale del piano di query. D'altra parte, memorizzare il Modello Anchora, ad esempio, su Click House, che ha un supporto limitato per le join, sembra attualmente non essere una buona idea.
Inoltre, per entrambe le architetture esistono tecniche speciali, che semplificano l'accesso ai dati (sia dal punto di vista delle prestazioni delle query, sia per gli utenti finali). Ad esempio, le tabelle Point-In-Time nel Data Vault o funzioni di tabella speciali nel Modello Anchora.
Totale
La sostanza principale delle architetture flessibili discusse è la modularità della loro 'costruzione'.
Questa proprietà consente di:
- Dopo una certa preparazione iniziale, legata al dispiegamento dei metadati e alla scrittura di algoritmi ETL di base, fornire rapidamente al cliente il primo risultato come una coppia di rapporti che contengono dati di solo alcuni oggetti sorgenti. Non è necessario pianificare completamente (anche a livello alto) l'intero modello di oggetti per questo.
- Il modello di dati può iniziare a funzionare (e portare vantaggi) con soli 2-3 oggetti, per poi espandersi gradualmente (relativamente al Modello Anchor Nikolaj una bella analogia con il micelio).
- La maggior parte delle modifiche, incluso l'ampliamento dell'area tematica e l'aggiunta di nuove sorgenti non influisce sulle funzionalità esistenti e non comporta il rischio di rompere qualcosa già funzionante..
- Grazie alla decomposizione in elementi standard, i processi ETL in tali sistemi appaiono omogenei, la loro scrittura può essere algoritmizzata e, infine, automatizzata..
Il prezzo di tale flessibilità è prestazioni. Ciò non significa che ottenere prestazioni accettabili su tali modelli sia impossibile. Nella maggior parte dei casi, potrebbero semplicemente essere necessari più sforzi e attenzione ai dettagli per raggiungere le metriche desiderate.
Applicazioni
Tipi di entità Data Vault
Ulteriori informazioni su Data Vault:
Tipi di entità Anchor Model
Ulteriori informazioni sul Modello Anchor:
Tabella riassuntiva con somiglianze e differenze dei metodi esaminati:

Fonte: habr.com
