

1. Dati iniziali
La pulizia dei dati è una delle sfide che devono affrontare le attività di analisi dei dati. Questo materiale riflette gli sviluppi e le soluzioni emersi come risultato della risoluzione di un problema pratico di analisi del database nella formazione del valore catastale. Fonti qui .
È stato preso in considerazione il file "Modello comparativo total.ods" nell'"Appendice B. Risultati della determinazione del KS 5. Informazioni sul metodo di determinazione del valore catastale 5.1 Approccio comparativo".
Tabella 1. Indicatori statistici del dataset nel file “Modello comparativo total.ods”
Numero totale di campi, pz. —44
Numero totale di record, pz. — 365 490
Numero totale di caratteri, pz. — 101 714 693
Numero medio di caratteri in un record, pz. — 278,297
Deviazione standard dei caratteri in un record, pz. — 15,510
Numero minimo di caratteri in una voce, pz. —198
Numero massimo di caratteri in una voce, pz. — 363
2. Parte introduttiva. Standard di base
Durante l'analisi del database specificato, è stato creato il compito di specificare i requisiti per il grado di purificazione, poiché, come è chiaro a tutti, il database specificato crea conseguenze legali ed economiche per gli utenti. Durante il lavoro si è scoperto che non esistevano requisiti specifici per il grado di pulizia dei big data. Analizzando le norme legali in questa materia, sono giunto alla conclusione che sono tutte formate da possibilità. Cioè, è apparsa una determinata attività, vengono compilate le fonti di informazione per l'attività, quindi viene formato un set di dati e, sulla base del set di dati creato, strumenti per risolvere il problema. Le soluzioni risultanti sono punti di riferimento nella scelta tra alternative. L'ho presentato nella Figura 1.
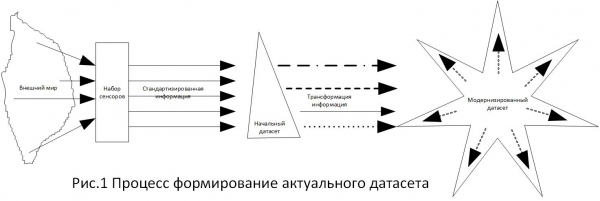
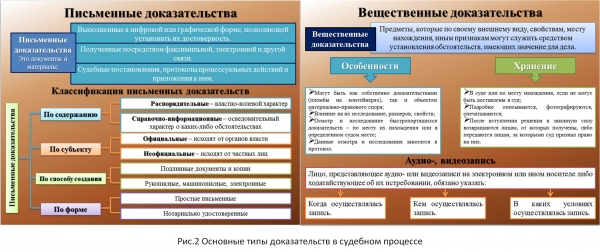
Poiché, in materia di determinazione di eventuali standard, è preferibile fare affidamento su tecnologie comprovate, ho scelto i requisiti stabiliti in , perché ho considerato questo documento il più completo per questo problema. In particolare, in questo documento la sezione recita “Va notato che i requisiti di integrità dei dati si applicano ugualmente ai dati manuali (cartacei) ed elettronici”. (traduzione: “...i requisiti di integrità dei dati si applicano ugualmente ai dati manuali (cartacei) ed elettronici”). Tale formulazione è ben specificatamente associata al concetto di “prova scritta”, nel disposto dell'art. 71 cpc, art. 70 TAS, Art. 75 APC, “per iscritto” art. 84 codice di procedura civile.
La Figura 2 presenta un diagramma della formazione degli approcci ai tipi di informazione in giurisprudenza.
Riso. 2. Fonte .
La Figura 3 mostra il meccanismo della Figura 1, per i compiti della suddetta “Guida”. È facile, facendo un confronto, vedere che gli approcci utilizzati per soddisfare i requisiti di integrità dell'informazione negli standard moderni per i sistemi informativi sono significativamente limitati rispetto al concetto legale di informazione.
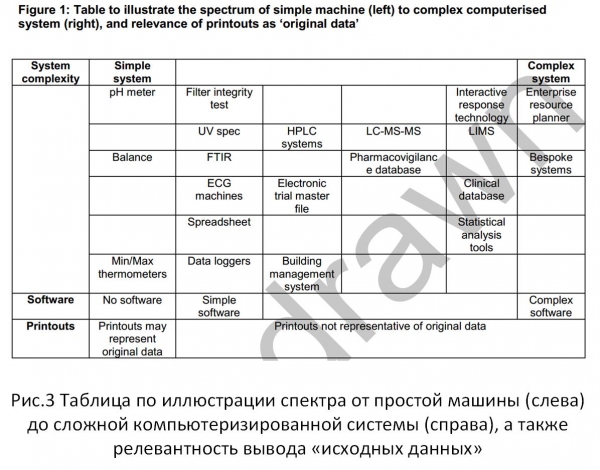
Ris.3
Nel documento specificato (Guida), il collegamento alla parte tecnica, alle capacità di elaborazione e archiviazione dei dati, è ben confermato da una citazione dal capitolo 18.2. Database relazionale: "Questa struttura di file è intrinsecamente più sicura, poiché i dati sono conservati in un formato di file di grandi dimensioni che preserva la relazione tra dati e metadati."
In effetti, in questo approccio, rispetto alle capacità tecniche esistenti, non c'è nulla di anormale e, di per sé, questo è un processo naturale, poiché l'espansione dei concetti deriva dall'attività più studiata: la progettazione di database. Ma, d'altra parte, appaiono norme legali che non prevedono sconti sulle capacità tecniche dei sistemi esistenti, ad esempio: .

Riso. 4. Imbuto di capacità tecniche ().
In questi aspetti, diventa chiaro che il set di dati originale (Fig. 1) dovrà, prima di tutto, essere salvato e, in secondo luogo, costituire la base per estrarne ulteriori informazioni. Ebbene, ad esempio: le telecamere che registrano le regole del traffico sono onnipresenti, i sistemi di elaborazione delle informazioni eliminano i trasgressori, ma anche altre informazioni possono essere offerte ad altri consumatori, ad esempio come monitoraggio di marketing della struttura del flusso di clienti verso un centro commerciale. E questo è fonte di ulteriore valore aggiunto nell’utilizzo di BigDat. È del tutto possibile che i set di dati raccolti ora, da qualche parte in futuro, avranno valore secondo un meccanismo simile al valore delle edizioni rare del 1700 al momento attuale. Dopotutto, infatti, i set di dati temporanei sono unici ed è improbabile che si ripetano in futuro.
3. Parte introduttiva. Criteri di valutazione
Durante il processo di elaborazione è stata sviluppata la seguente classificazione degli errori.
1. Classe di errore (basata su GOST R 8.736-2011): a) errori sistematici; b) errori casuali; c) un errore.
2. Per molteplicità: a) distorsione mono; b) multi-distorsione.
3. Secondo la criticità delle conseguenze: a) critiche; b) non critico.
4. Per fonte dell'evento:
A) Tecnico – errori che si verificano durante il funzionamento dell'apparecchiatura. Un errore abbastanza rilevante per i sistemi IoT, sistemi con un grado significativo di influenza sulla qualità della comunicazione, apparecchiature (hardware).
B) Errori dell'operatore: errori in un'ampia gamma, dagli errori di battitura dell'operatore durante l'input agli errori nelle specifiche tecniche per la progettazione del database.
C) Errori dell'utente: ecco gli errori dell'utente nell'intera gamma, da "ho dimenticato di cambiare layout" allo scambio di metri per piedi.
5. Separato in una classe separata:
a) il “compito del separatore”, cioè lo spazio e il “:” (nel nostro caso) quando è stato duplicato;
b) parole scritte insieme;
c) nessuno spazio dopo i caratteri di servizio
d) simboli simmetricamente multipli: (), "", "...".
Nel complesso, con la sistematizzazione degli errori del database presentata nella Figura 5, si forma un sistema di coordinate abbastanza efficace per la ricerca degli errori e lo sviluppo di un algoritmo di pulizia dei dati per questo esempio.
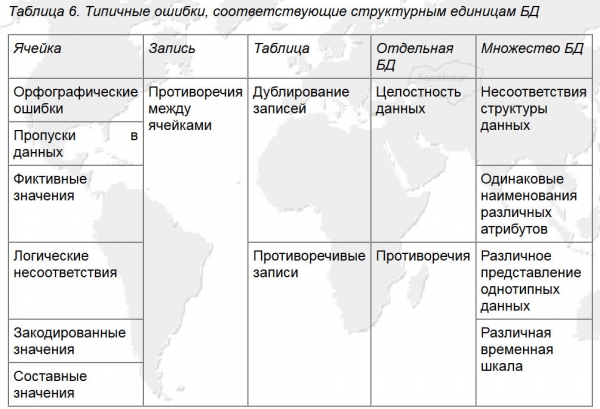
Riso. 5. Errori tipici corrispondenti alle unità strutturali del database (Fonte: ).
Accuratezza, integrità del dominio, tipo di dati, coerenza, ridondanza, completezza, duplicazione, conformità alle regole aziendali, definizione strutturale, anomalia dei dati, chiarezza, tempestività, aderenza alle regole di integrità dei dati. (Pagina 334. Fondamenti di data warehousing per professionisti IT / Paulraj Ponniah.—2a ed.)
Presentata la formulazione inglese e la traduzione automatica russa tra parentesi.
Precisione. Il valore memorizzato nel sistema per un elemento dati è il valore corretto per quella occorrenza dell'elemento dati. Se in un record sono archiviati il nome di un cliente e un indirizzo, l'indirizzo è l'indirizzo corretto per il cliente con quel nome. Se trovi la quantità ordinata pari a 1000 unità nel record per il numero d'ordine 12345678, quella quantità è la quantità esatta per quell'ordine.
[Precisione. Il valore memorizzato nel sistema per un elemento dati è il valore corretto per quella occorrenza dell'elemento dati. Se in un record sono memorizzati il nome e l'indirizzo di un cliente, l'indirizzo è l'indirizzo corretto per il cliente con quel nome. Se trovi la quantità ordinata come 1000 unità nel record per il numero d'ordine 12345678, quella quantità è la quantità esatta per quell'ordine.]
Integrità del dominio. Il valore dei dati di un attributo rientra nell'intervallo di valori consentiti e definiti. L'esempio comune sono i valori consentiti "maschio" e "femmina" per l'elemento dei dati di genere.
[Integrità del dominio. Il valore dei dati dell'attributo rientra nell'intervallo di valori validi e definiti. Un esempio generale sono i valori validi "maschio" e "femmina" per un elemento di dati di genere.]
Tipo di dati. Il valore per un attributo di dati viene effettivamente memorizzato come il tipo di dati definito per quell'attributo. Quando il tipo di dati del campo del nome del negozio è definito come "testo", tutte le istanze di quel campo contengono il nome del negozio mostrato in formato testuale e non codici numerici.
[Tipo di dati. Il valore di un attributo di dati viene effettivamente memorizzato come il tipo di dati definito per quell'attributo. Se il tipo di dati del campo Nome negozio è definito come "testo", tutte le istanze di questo campo contengono il nome del negozio visualizzato in formato testo anziché in codici numerici.]
Consistenza. La forma e il contenuto di un campo dati sono gli stessi su più sistemi di origine. Se il codice prodotto per il prodotto ABC in un sistema è 1234, il codice per questo prodotto sarà 1234 in ogni sistema di origine.
[Consistenza. La forma e il contenuto del campo dati sono gli stessi nei diversi sistemi di origine. Se il codice prodotto per il prodotto ABC su un sistema è 1234, il codice per quel prodotto è 1234 su ciascun sistema di origine.]
Ridondanza. Gli stessi dati non devono essere archiviati in più di un posto all'interno di un sistema. Se, per ragioni di efficienza, un dato viene intenzionalmente memorizzato in più di un posto in un sistema, la ridondanza deve essere chiaramente identificata e verificata.
[Ridondanza. Gli stessi dati non dovrebbero essere archiviati in più di un posto nel sistema. Se, per ragioni di efficienza, un dato viene intenzionalmente memorizzato in più posizioni in un sistema, la ridondanza deve essere chiaramente definita e verificata.]
Completezza. Non ci sono valori mancanti per un dato attributo nel sistema. Ad esempio, in un file cliente, deve essere presente un valore valido per il campo "stato" per ogni cliente. Nel file di dettaglio ordine, ogni record di dettaglio relativo ad un ordine deve essere interamente compilato.
[Completezza. Non ci sono valori mancanti nel sistema per questo attributo. Ad esempio, il file cliente deve avere un valore valido per il campo "stato" per ciascun cliente. Nel file di dettaglio dell'ordine, ogni record di dettaglio dell'ordine deve essere completamente completato.]
Duplicazione. La duplicazione dei record in un sistema è completamente risolta. Se è noto che il file del prodotto contiene record duplicati, vengono identificati tutti i record duplicati per ciascun prodotto e viene creato un riferimento incrociato.
[Duplicare. La duplicazione dei record nel sistema è stata completamente eliminata. Se è noto che un file di prodotto contiene voci duplicate, vengono identificate tutte le voci duplicate per ciascun prodotto e viene creato un riferimento incrociato.]
Conformità alle regole aziendali. I valori di ciascun elemento di dati aderiscono alle regole aziendali prescritte. In un sistema d'asta, il prezzo di aggiudicazione o di vendita non può essere inferiore al prezzo di riserva. In un sistema di prestito bancario, il saldo del prestito deve essere sempre positivo o pari a zero.
[Rispetto delle regole aziendali. I valori di ciascun elemento di dati sono conformi alle regole aziendali stabilite. In un sistema d'asta, il prezzo di aggiudicazione o di vendita non può essere inferiore al prezzo di riserva. In un sistema di credito bancario, il saldo del prestito deve essere sempre positivo o pari a zero.]
Definitività strutturale. Laddove un dato può essere naturalmente strutturato in singoli componenti, l'elemento deve contenere questa struttura ben definita. Ad esempio, il nome di una persona si divide naturalmente in nome, iniziale del secondo nome e cognome. I valori per i nomi delle persone devono essere memorizzati come nome, iniziale del secondo nome e cognome. Questa caratteristica della qualità dei dati semplifica l'applicazione degli standard e riduce i valori mancanti.
[Certezza strutturale. Laddove un elemento di dati può essere strutturato naturalmente in singoli componenti, l'elemento deve contenere questa struttura ben definita. Ad esempio, il nome di una persona è naturalmente diviso in nome, iniziale del secondo nome e cognome. I valori per i singoli nomi devono essere memorizzati come nome, iniziale del secondo nome e cognome. Questa caratteristica di qualità dei dati semplifica l'applicazione degli standard e riduce i valori mancanti.]
Anomalia dei dati. Un campo deve essere utilizzato solo per lo scopo per il quale è definito. Se per indirizzi lunghi è definito il campo Indirizzo-3 per un'eventuale terza riga di indirizzo, questo campo deve essere utilizzato solo per la registrazione della terza riga di indirizzo. Non deve essere utilizzato per inserire il numero di telefono o di fax del cliente.
[Anomalia dei dati. Un campo deve essere utilizzato solo per lo scopo per il quale è definito. Se il campo Indirizzo-3 è definito per un'eventuale terza riga di indirizzo per indirizzi lunghi, questo campo deve essere utilizzato solo per registrare la terza riga di indirizzo. Non deve essere utilizzato per inserire il numero di telefono o di fax di un cliente.]
Chiarezza. Un dato può possedere tutte le altre caratteristiche dei dati di qualità, ma se gli utenti non ne comprendono chiaramente il significato, il dato non ha alcun valore per gli utenti. Convenzioni di denominazione adeguate aiutano a rendere gli elementi dei dati ben compresi dagli utenti.
[Chiarezza. Un elemento di dati può avere tutte le altre caratteristiche di dati validi, ma se gli utenti non ne comprendono chiaramente il significato, l'elemento di dati non ha alcun valore per gli utenti. Le convenzioni di denominazione corrette aiutano a rendere gli elementi dei dati ben compresi dagli utenti.]
Puntuale. Gli utenti determinano la tempestività dei dati. Se gli utenti si aspettano che i dati della dimensione cliente non siano più vecchi di un giorno, le modifiche ai dati cliente nei sistemi di origine devono essere applicate quotidianamente al data warehouse.
[In modo tempestivo. Gli utenti determinano la tempestività dei dati. Se gli utenti prevedono che i dati della dimensione cliente non risalgano a più di un giorno, le modifiche ai dati cliente nei sistemi di origine dovrebbero essere applicate al data warehouse su base giornaliera.]
Utilità. Ogni elemento di dati nel data warehouse deve soddisfare alcuni requisiti della raccolta di utenti. Un elemento di dati può essere accurato e di alta qualità, ma se non ha alcun valore per gli utenti, non è assolutamente necessario che quell'elemento di dati si trovi nel data warehouse.
[Utilità. Ogni elemento di dati nell'archivio dati deve soddisfare alcuni requisiti della raccolta utente. Un elemento di dati può essere accurato e di alta qualità, ma se non fornisce valore agli utenti, non è necessario che tale elemento di dati si trovi nel data warehouse.]
Rispetto delle regole di integrità dei dati. I dati archiviati nei database relazionali dei sistemi sorgente devono rispettare le regole di integrità dell'entità e integrità referenziale. Qualsiasi tabella che consente null come chiave primaria non ha l'integrità dell'entità. L'integrità referenziale impone la corretta creazione delle relazioni genitore-figlio. In una relazione cliente-ordine, l'integrità referenziale garantisce l'esistenza di un cliente per ogni ordine nel database.
[Rispetto delle norme sull'integrità dei dati. I dati archiviati nei database relazionali dei sistemi sorgente devono rispettare le regole di integrità dell'entità e integrità referenziale. Qualsiasi tabella che consente null come chiave primaria non ha l'integrità dell'entità. L’integrità referenziale obbliga a stabilire correttamente la relazione tra genitori e figli. In una relazione cliente-ordine, l'integrità referenziale garantisce che esista un cliente per ogni ordine nel database.]
4. Qualità della pulizia dei dati
La qualità della pulizia dei dati è una questione piuttosto problematica nei bigdata. Rispondere alla domanda su quale grado di pulizia dei dati sia necessario per completare l'attività è fondamentale per ogni analista di dati. Nella maggior parte dei problemi attuali, ogni analista lo determina da solo ed è improbabile che qualcuno dall'esterno sia in grado di valutare questo aspetto nella sua soluzione. Ma per il compito da svolgere in questo caso, la questione era estremamente importante, poiché l'affidabilità dei dati legali dovrebbe tendere a uno.
Considerare le tecnologie di test del software per determinare l'affidabilità operativa. Oggi ci sono più di questi modelli . Molti modelli utilizzano un modello di gestione dei sinistri:
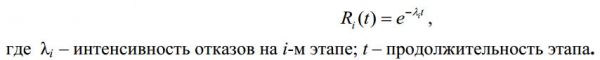
Fig. 6
Pensando come segue: "Se l'errore trovato è un evento simile all'evento di guasto in questo modello, come trovare un analogo del parametro t?" Ed ho compilato il seguente modello: Immaginiamo che il tempo impiegato da un tester per verificare un record sia 1 minuto (per il database in questione), poi per trovare tutti gli errori gli serviranno 365 minuti, ovvero circa 494 anni e 3 mesi di orario di lavoro. Come abbiamo capito, si tratta di una mole di lavoro molto elevata e i costi di controllo del database saranno proibitivi per il compilatore di questo database. In questa riflessione appare il concetto economico di costi e dopo l'analisi sono giunto alla conclusione che si tratta di uno strumento abbastanza efficace. Basato sulla legge dell’economia: “Il volume di produzione (in unità) al quale viene raggiunto il massimo profitto di un’impresa è situato nel punto in cui il costo marginale di produzione di una nuova unità di output viene confrontato con il prezzo che questa impresa può ricevere per una nuova unità." Sulla base del postulato secondo cui per individuare ogni errore successivo è necessario un controllo sempre maggiore dei record, questo è un fattore di costo. Cioè, il postulato adottato nei modelli di test assume un significato fisico nel seguente schema: se per trovare l'i-esimo errore è necessario controllare n record, allora per trovare l'errore successivo (i+3) sarà necessario per controllare m record e contemporaneamente n
- Quando il numero di record controllati prima che venga rilevato un nuovo errore si stabilizza;
- Quando il numero di record controllati prima di trovare l'errore successivo aumenterà.
Per determinare il valore critico, mi sono rivolto al concetto di fattibilità economica, che in questo caso, utilizzando il concetto di costi sociali, può essere formulato come segue: “I costi di correzione dell’errore dovrebbero essere sostenuti dall’agente economico che può fare al minor costo." Abbiamo un agente, un tester che impiega 1 minuto a controllare un record. In termini monetari, se guadagni 6000 rubli al giorno, saranno 12,2 rubli. (circa oggi). Resta da determinare il secondo lato dell'equilibrio nel diritto economico. Ho ragionato così. Un errore esistente richiederà l'impegno della persona interessata, vale a dire del proprietario dell'immobile, per correggerlo. Diciamo che questo richiede 1 giorno di azione (inviare una domanda, ricevere un documento corretto). Quindi, da un punto di vista sociale, i suoi costi saranno pari allo stipendio medio giornaliero. Stipendio medio maturato nell'Okrug autonomo dei Khanty-Mansi 73285 strofinare. ovvero 3053,542 rubli/giorno. Di conseguenza, otteniamo un valore critico pari a:
3053,542: 12,2 = 250,4 unità di record.
Ciò significa, da un punto di vista sociale, che se un tester controlla 251 record e trova un errore, equivale a che l'utente risolva da solo l'errore. Di conseguenza, se il tester ha impiegato un tempo pari a controllare 252 record per trovare l'errore successivo, in questo caso è meglio trasferire il costo della correzione all'utente.
Qui viene presentato un approccio semplificato, poiché da un punto di vista sociale è necessario tenere conto di tutto il valore aggiuntivo generato da ciascuno specialista, ovvero dei costi comprensivi di tasse e pagamenti sociali, ma il modello è chiaro. Una conseguenza di questo rapporto è il seguente requisito per gli specialisti: uno specialista del settore IT deve avere uno stipendio superiore alla media nazionale. Se il suo stipendio è inferiore allo stipendio medio dei potenziali utenti del database, deve controllare personalmente l'intero database.
Quando si utilizza il criterio descritto, si forma il primo requisito per la qualità del database:
Io(tr). La quota di errori critici non deve superare 1/250,4 = 0,39938%. Un po' meno di oro nell’industria. E in termini fisici non ci sono più di 1459 record con errori.
Ritiro economico.
Infatti, commettendo un tale numero di errori nei registri, la società accetta perdite economiche pari a:
1459*3053,542 = 4 rubli.
Questo importo è determinato dal fatto che la società non ha gli strumenti per ridurre questi costi. Ne consegue che se qualcuno dispone di una tecnologia che gli consente di ridurre il numero di record con errori, ad esempio, a 259, ciò consentirà alla società di risparmiare:
1200*3053,542 = 3 rubli.
Ma allo stesso tempo può chiedere il suo talento e il suo lavoro, beh, diciamo, 1 milione di rubli.
I costi sociali si riducono cioè:
3 – 664 = 250 rubli.
In sostanza, questo effetto è il valore aggiunto derivante dall’utilizzo delle tecnologie BigDat.
Ma qui va tenuto presente che si tratta di un effetto sociale, e il proprietario del database sono le autorità comunali, il loro reddito derivante dall'uso dei beni registrati in questo database, ad un tasso dello 0,3%, è: 2,778 miliardi di rubli/ anno. E questi costi (4 rubli) non gli danno molto fastidio, poiché vengono trasferiti ai proprietari degli immobili. E, sotto questo aspetto, lo sviluppatore di tecnologie più raffinate in Bigdata dovrà mostrare la capacità di convincere il proprietario di questo database, e queste cose richiedono un talento considerevole.
In questo esempio, l'algoritmo di valutazione dell'errore è stato scelto in base al modello Schumann [2] di verifica del software durante i test di affidabilità. A causa della sua prevalenza su Internet e della capacità di ottenere gli indicatori statistici necessari. La metodologia è presa da Monakhov Yu.M. “Stabilità funzionale dei sistemi informativi”, vedi sotto lo spoiler in Fig. 7-9.
Riso. 7 – 9 Metodologia del modello Schumann


La seconda parte di questo materiale presenta un esempio di pulizia dei dati, in cui si ottengono i risultati dell'utilizzo del modello di Schumann.
Vi presento i risultati ottenuti:
Numero stimato di errori N = 3167 n.
Parametro C, lambda e funzione affidabilità:
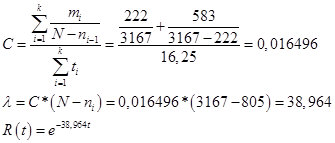
Ris.17
In sostanza, lambda è un vero e proprio indicatore dell'intensità con cui vengono rilevati gli errori in ogni fase. Se si guarda la seconda parte, la stima per questo indicatore era di 42,4 errori all'ora, che è abbastanza paragonabile all'indicatore Schumann. In precedenza, è stato stabilito che la velocità con cui gli sviluppatori rilevano gli errori non dovrebbe essere inferiore a 1 errore ogni 250,4 record, quando si controlla 1 record al minuto. Da qui il valore critico di lambda per il modello di Schumann:
60 / 250,4 = 0,239617.
Cioè, la necessità di eseguire procedure di rilevamento degli errori deve essere eseguita fino a quando lambda, dall'attuale 38,964, non scende a 0,239617.
Oppure fino a quando l'indicatore N (numero potenziale di errori) meno n (numero di errori corretto) scende al di sotto della nostra soglia accettata - 1459 pz.
Letteratura
- Monakhov, Yu. M. Stabilità funzionale dei sistemi informativi. In 3 ore Parte 1. Affidabilità del software: libro di testo. indennità / Yu. M. Monakhov; Vladim. stato univ. –Vladimir: Izvo Vladim. stato Università, 2011. – 60 pag. – ISBN 978-5-9984-0189-3.
- Martin L. Shooman, "Modelli probabilistici per la previsione dell'affidabilità del software".
- Fondamenti del data warehousing per professionisti IT / Paulraj Ponniah.—2a ed.
Fonte: habr.com
