

Introduzione ai sistemi operativi
Ciao, Habr! Vorrei presentarvi una serie di articoli tradotti su una libreria che trovo interessante: OSTEP. In questo materiale si analizza in profondità il funzionamento dei sistemi operativi simili a Unix, in particolare la gestione dei processi, vari pianificatori, la memoria e altri componenti simili che costituiscono un moderno sistema operativo. Potete visualizzare l'originale di tutti i materiali qui . Si prega di notare che la traduzione non è stata eseguita da un professionista (è abbastanza libera), ma spero di aver mantenuto il significato generale.
Le esercitazioni su questo argomento possono essere trovate qui:
Altre parti:
E potete anche dare un'occhiata al mio canale su =)
Introduzione al pianificatore
La questione fondamentale: come sviluppare una politica del pianificatore
Come dovrebbero essere sviluppati i framework di base delle politiche del pianificatore? Quali devono essere le assunzioni chiave? Quali metriche sono importanti? Quali tecniche di base sono state utilizzate nei primi sistemi di calcolo?
Assunzioni del carico di lavoro
Prima di discutere le possibili politiche, iniziamo con alcune semplificazioni sui processi in esecuzione nel sistema, che insieme vengono chiamati carico di lavoro. Definendo il carico di lavoro come parte critica nella definizione delle politiche, più conoscenze hai sul carico, più qualitativa sarà la politica che potrai redigere.
Faremo le seguenti assunzioni sui processi in esecuzione nel sistema, a volte chiamati jobs (compiti). Queste assunzioni sono quasi tutte irrealistiche, ma necessarie per sviluppare il pensiero.
- Ogni compito è in esecuzione per lo stesso intervallo di tempo,
- Tutti i compiti vengono avviati simultaneamente,
- Il compito avviato continua fino al suo completamento,
- Tutti i compiti utilizzano solo la CPU,
- Il tempo di esecuzione di ogni compito è noto.
Metriche del Pianificatore
Oltre ad alcune assunzioni sul carico, è necessario avere anche uno strumento per confrontare diverse politiche di pianificazione: le metriche del pianificatore. Una metrica è semplicemente una misura di qualcosa. Ci sono diverse metriche che possono essere utilizzate per confrontare i pianificatori.
Per esempio, utilizzeremo una metrica chiamata tempo di turnaround (turnaround time). Il tempo di turnaround di un compito è definito come la differenza tra il tempo di completamento del compito e il tempo di arrivo del compito nel sistema.
Tempo di completamento = Tempo di arrivo
Poiché abbiamo ipotizzato che tutte le attività siano arrivate contemporaneamente, Ta = 0 e dunque Tt = Tc. Questo valore cambierà naturalmente quando modificheremo le ipotesi sopra elencate.
Un'altra metrica è equità (equità, giustizia). Le performance e l’equità sono spesso caratteristiche contrastanti nella pianificazione. Ad esempio, un pianificatore può ottimizzare le performance, ma a scapito dell'attesa dell'avvio di altre attività, riducendo così l'equità.
PRIMO ARRIVATO, PRIMO SERVITO (FIFO)
L'algoritmo più semplice che possiamo implementare si chiama FIFO o primo arrivato (in), primo servito (fuori). Questo algoritmo ha diversi vantaggi: è molto semplice da implementare e si adatta a tutte le nostre ipotesi, svolgendo il lavoro piuttosto bene.
Consideriamo un semplice esempio. Supponiamo che 3 compiti siano stati assegnati contemporaneamente. Ma supponiamo che il compito A sia arrivato leggermente prima degli altri, quindi sarà prima nella lista di esecuzione, proprio come B rispetto a C. Supponiamo che ciascuno di essi richieda 10 secondi per essere completato. Quale sarà quindi il tempo medio di esecuzione di questi compiti?
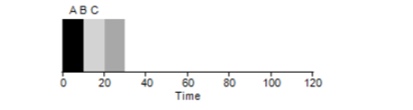
Calcolando i valori — 10+20+30 e dividendo per 3, otteniamo un tempo medio di esecuzione del programma pari a 20 secondi.
Ora proviamo a modificare le nostre ipotesi. In particolare, l'ipotesi 1, e quindi non presumeremo più che ciascun compito richieda lo stesso tempo di esecuzione. Come si comporterà FIFO questa volta?
Si rivela che tempi di esecuzione diversi per i compiti hanno un impatto estremamente negativo sulla produttività dell'algoritmo FIFO. Supponiamo che il compito A richieda 100 secondi, mentre B e C continuano a richiedere 10 secondi ciascuno.
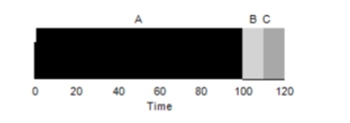
Come si può vedere dall'immagine, il tempo medio per il sistema sarà (100+110+120)/3=110. Questo effetto è chiamato effetto convoglio, quando alcuni utenti temporanei di una risorsa si trovano in fila dietro a un utente pesante. È simile a una coda in un supermercato, in cui davanti a te c'è un cliente con un carrello pieno. La soluzione migliore a questo problema è cercare di cambiare cassa o rilassarsi e respirare profondamente.
Shortest Job First
È possibile risolvere situazioni simili con processi pesanti? Certamente. Un altro tipo di pianificazione è chiamatoShortest Job First (SJF). Il suo algoritmo è piuttosto semplice: come suggerisce il nome, verranno eseguiti per primi i compiti più brevi uno dopo l'altro.
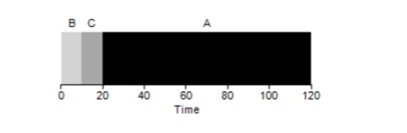
In questo esempio, il risultato dell'esecuzione degli stessi processi sarà un miglioramento della media del tempo di turnaround dei programmi, che sarà pari a 50 invece di 110, che è praticamente il doppio migliore.
In questo modo, data l'assunzione che tutti i compiti arrivino contemporaneamente, l'algoritmo SJF sembra essere il più ottimale. Tuttavia, le nostre assunzioni non sembrano ancora realistiche. Questa volta modificheremo l'assunzione 2 e presumeremo che i compiti possano arrivare in qualsiasi momento, e non tutti insieme. A quali problemi potrebbe portare ciò?
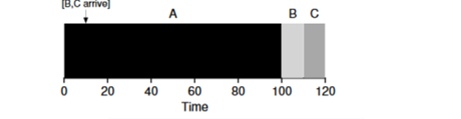
Immaginiamo che il compito A (100s) arrivi per primo e inizi a essere eseguito. Al momento t=10 arrivano i compiti B e C, ognuno dei quali richiederà 10 secondi. Pertanto, il tempo medio di esecuzione è (100 + (110 - 10) + (120 - 10))3 = 103. Cosa potrebbe fare il pianificatore per migliorare la situazione?
Shortest Time-to-Completion First (STCF)
Per migliorare la situazione, elimineremo l'assunzione 3 che prevede che il programma sia avviato e funzionante fino al completamento. Inoltre, avremo bisogno di supporto hardware e, come potreste immaginare, utilizzeremo un timer per interrompere il compito in esecuzione e cambiare i contesti. In questo modo, il pianificatore può adottare delle misure non appena arrivano i task B e C — interrompere l'esecuzione del task A e iniziare a elaborare i task B e C, per poi continuare l'esecuzione del task A una volta completati. Tale pianificatore è chiamato STCFo Preemptive Job First.
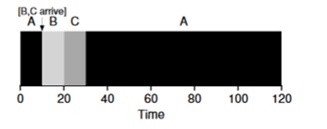
Il risultato del funzionamento di questo pianificatore sarà il seguente: ((120-0)+(20-10)+(30-10))/3=50. Così, questo pianificatore diventa ancora più ottimale per i nostri compiti.
Metrica Tempo di risposta (Response Time)
Pertanto, se conosciamo i tempi di esecuzione dei task e sappiamo che questi task utilizzano solo la CPU, STCF sarà la soluzione migliore. In tempi passati, questi algoritmi funzionavano piuttosto bene. Tuttavia, ora l'utente trascorre la maggior parte del suo tempo al terminale e si aspetta un'interazione interattiva performante. Così è nata una nuova metrica — tempo di risposta (response).
Il tempo di risposta si calcola nel seguente modo:
Tresponse=Tfirstrun−Tarrival
Così, per l'esempio precedente, il tempo di risposta sarà: A=0, B=0, C=10 (abg=3,33).
E si scopre che l'algoritmo STCF non è così efficace quando 3 compiti arrivano contemporaneamente: dovrà attendere che i compiti più piccoli siano completati. Pertanto, l'algoritmo è buono per la metrica del tempo di rotazione, ma scarso per la metrica dell'interattività. Immaginate di essere al terminale e di dover aspettare più di 10 secondi per digitare caratteri in un editor, perché un'altra attività occupa la CPU. Non è affatto piacevole.
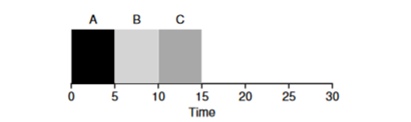
Pertanto, ci troviamo di fronte a un'altra problematica: come possiamo costruire un pianificatore sensibile al tempo di risposta?
Round Robin
Per risolvere questo problema è stato sviluppato un algoritmo Round Robin (RR). L'idea principale è piuttosto semplice: invece di avviare i compiti fino al loro completamento, avvieremo il compito per un certo intervallo di tempo (chiamato quantum di tempo) e poi passeremo a un altro compito in coda. L'algoritmo ripete il suo lavoro finché tutti i compiti non sono completati. Nel frattempo, il tempo di esecuzione del programma deve essere un multiplo del tempo dopo il quale il timer interromperà il processo. Ad esempio, se il timer interrompe il processo ogni x=10ms, allora la dimensione della finestra di esecuzione del processo deve essere un multiplo di 10 e può essere 10, 20 o x*10.
Consideriamo un esempio: i compiti A, B e C arrivano contemporaneamente nel sistema e ciascuno di essi desidera funzionare per 5 secondi. L'algoritmo SJF eseguirà ciascun compito fino alla fine prima di avviarne un altro. In contrasto, l'algoritmo RR con finestra di avvio=1s si occuperà dei compiti nel seguente modo (fig. 4.3):
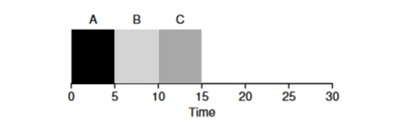
(SJF Ancora (Cattivo per il Tempo di Risposta)
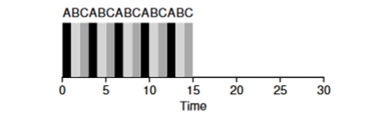
(Round Robin (Buono per il Tempo di Risposta)
Il tempo medio di risposta per l'algoritmo RR (0+1+2)/3=1, mentre per SJF (0+5+10)/3=5.
È logico supporre che la finestra temporale sia un parametro molto importante per il RR; più è piccola, più veloce sarà il tempo di risposta. Tuttavia, non può essere troppo ridotta, poiché il tempo di switching del contesto gioca anch'esso un ruolo nelle prestazioni generali. Pertanto, la scelta del tempo della finestra di esecuzione è determinata dall'architetto del sistema operativo e dipende dalle attività che si intendono eseguire. Il switching del contesto non è l'unica operazione di servizio che richiede tempo; un programma in esecuzione gestisce anche vari cache, e ad ogni switching è necessario salvare e ripristinare questo ambiente, il che può richiedere molto tempo.
Il RR è un ottimo pianificatore, se consideriamo solo la metrica del tempo di risposta. Ma come si comporterà la metrica del tempo di turnaround con questo algoritmo? Consideriamo l'esempio sopra, dove i tempi di esecuzione per A, B e C sono di 5 secondi e arrivano contemporaneamente. Il compito A si concluderà a 13 secondi, B a 14 secondi, e C a 15 secondi, con una media di turnaround di 14 secondi. Così, il RR è il peggior algoritmo per la metrica di turnaround.
In altre parole, qualsiasi algoritmo del tipo RR è equo, poiché suddivide il tempo di utilizzo della CPU equamente tra tutti i processi. In questo modo, queste metriche confliggono costantemente tra loro.
Pertanto, abbiamo diversi algoritmi contrapposti e rimangono alcune ipotesi — che il tempo di esecuzione sia noto e che il processo utilizzi esclusivamente la CPU.
Integrazione con I/O
Innanzitutto, eliminiamo l'ipotesi 4, secondo cui il processo utilizza solo la CPU; naturalmente, non è così e i processi possono accedere anche ad altre risorse hardware.
Quando un processo richiede un'operazione di input-output, il processo passa allo stato di bloccato, in attesa che l'I/O venga completato. Se l'I/O è diretto a un disco rigido, tale operazione può richiedere anche diversi millisecondi o più a lungo, e in quel momento la CPU resterà inattiva. Durante questo tempo, il pianificatore può assegnare la CPU a un altro processo. La prossima decisione che dovrà prendere il pianificatore è quando il processo completerà il suo I/O. Quando ciò accade, si verifica un'interruzione e il sistema operativo ripristina il processo che ha richiesto l'I/O nello stato di pronto.
Consideriamo un esempio composto da più compiti. Ognuno di essi necessita di 50 ms di tempo di CPU. Tuttavia, il primo accederà all'I/O ogni 10 ms (che sarà anch'esso eseguito ogni 10 ms). Il processo B, invece, utilizza semplicemente 50 ms di CPU senza I/O.
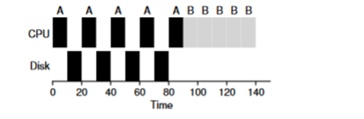
In questo esempio utilizzeremo il pianificatore STCF. Come si comporterà il pianificatore se avviamo un processo come A? Agirà nel modo seguente: prima completerà interamente il processo A e poi il processo B.
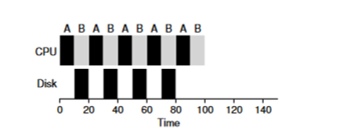
L'approccio tradizionale per risolvere questo problema è interpretare ogni sotto-compito di 10 ms del processo A come un compito separato. In questo modo, all'avvio con l'algoritmo STJF, la scelta tra il compito di 50 ms e quello di 10 ms è evidente. Poi, quando il sotto-compito A è completato, verrà avviato il processo B e l'I/O. Dopo il completamento dell'I/O, verrà deciso di riavviare il processo A da 10 ms invece del processo B. In questo modo è possibile realizzare sovrapposizioni, in cui la CPU è utilizzata da un altro processo mentre il primo attende l'I/O. Di conseguenza, il sistema è meglio utilizzato: nel momento in cui i processi interattivi attendono l'I/O, possono essere eseguiti altri processi sulla CPU.
L'oracolo non c'è più.
Adesso proviamo a liberarci dell'ipotesi che il tempo di esecuzione di un compito sia noto. In generale, questa è l'ipotesi più pessima e irreale dell'intero elenco. Infatti, nei sistemi operativi mediamente comuni, il sistema operativo stesso conosce molto poco sul tempo di esecuzione dei compiti; come possiamo quindi costruire un pianificatore senza sapere quanto tempo impiegherà un compito? Forse potremmo utilizzare alcuni principi del RR per risolvere questo problema?
Risultato
Abbiamo esaminato le idee di base della pianificazione dei compiti e considerato due famiglie di pianificatori. Il primo avvia il compito più breve per primo, migliorando così il tempo di turnaround; il secondo, invece, suddivide equamente il tempo tra tutti i compiti, migliorando il tempo di risposta. Entrali algoritmi sono inefficaci nelle situazioni in cui le prestazioni degli altri algoritmi eccellono. Abbiamo anche esaminato come l'uso parallelo della CPU e dell'I/O possa migliorare le prestazioni, ma non abbiamo risolto il problema della chiarezza da parte del sistema operativo. Nella prossima lezione, esamineremo un pianificatore che guarda al passato recente e cerca di prevedere il futuro, e si chiama multi-level feedback queue.
Fonte: habr.com
