


La relazione si concentra su questioni pratiche nello sviluppo di un operatore in Kubernetes, progettando la sua architettura e i principi fondamentali del suo funzionamento.
Nella prima parte della relazione esamineremo:
- cosa sia un operatore in Kubernetes e a cosa serva;
- come un operatore semplifica la gestione di sistemi complessi;
- cosa può e cosa non può fare un operatore.
Successivamente, passeremo alla discussione della struttura interna dell'operatore. Esamineremo l'architettura e il funzionamento dell'operatore passo dopo passo. Approfondiremo:
- l'interazione tra l'operatore e Kubernetes;
- quali funzioni l'operatore assume e quali delega a Kubernetes.
Analizzeremo la gestione di shard e repliche del database in Kubernetes.
Poi, discuteremo questioni relative allo storage dei dati:
- come lavorare con Persistent Storage dal punto di vista dell'operatore;
- insidie nell'uso di Local Storage.
Nella parte conclusiva della relazione esamineremo esempi pratici di applicazione con Amazon o Google Cloud Service. La relazione si basa sull'esempio dello sviluppo e dell'esperienza di utilizzo dell'operatore per ClickHouse.
Video:

Mi chiamo Vladislav Klimenko. Oggi vorrei condividere la nostra esperienza nello sviluppo e nell'operazione di un operatore, specificamente un operatore per la gestione dei cluster di database. Userò come esempio per gestire un cluster ClickHouse.

Perché abbiamo la possibilità di parlare dell'operatore e di ClickHouse?
- Ci occupiamo del supporto e dello sviluppo di ClickHouse.
- Attualmente cerchiamo di dare il nostro contributo allo sviluppo di ClickHouse. Siamo i secondi dopo Yandex per volume di modifiche apportate a ClickHouse.
- Cerchiamo di realizzare progetti aggiuntivi per l'ecosistema di ClickHouse.
Di uno di questi progetti vorrei parlarvi. Riguarda il ClickHouse-operator per Kubernetes.
Nel mio intervento vorrei affrontare due argomenti:
- Il primo argomento è come funziona il nostro operatore per la gestione dei database ClickHouse in Kubernetes.
- Il secondo argomento è come funziona un operatore in generale, cioè come interagisce con Kubernetes.
Questi due aspetti saranno collegati per tutto il mio intervento.

A chi potrebbe interessare ascoltare ciò che sto cercando di condividere?
- Sarà particolarmente interessante per chi gestisce operatori.
- Oppure per chi desidera costruirne uno proprio, per comprendere come funziona internamente, come l'operatore interagisce con Kubernetes e quali insidie potrebbero emergere.

Per comprendere al meglio ciò di cui parleremo oggi, sarebbe utile avere una conoscenza di base su come funziona Kubernetes e una preparazione di base sulle tecnologie cloud.
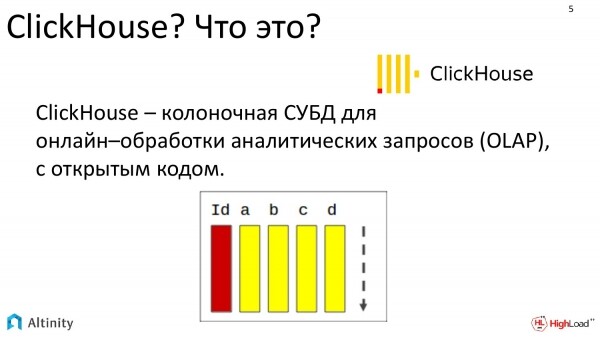
Che cos'è ClickHouse? È un database colonnare specializzato nell'elaborazione online di query analitiche. Ed è completamente open source.
E dobbiamo sapere solo due cose. Dobbiamo sapere che si tratta di un database, quindi ciò di cui parlerò sarà applicabile praticamente a qualsiasi database. E che il DBMS ClickHouse si scala molto bene, offrendo quasi linearità nella scalabilità. Pertanto, lo stato del cluster è una condizione naturale per ClickHouse. Ci interessa discutere principalmente come gestire un cluster ClickHouse in Kubernetes.

Perché è necessario? Perché non possiamo continuare a gestirlo da soli? Le risposte sono parzialmente tecniche e parzialmente organizzative.
- Nella pratica, ci troviamo sempre più spesso di fronte a situazioni in cui nelle grandi aziende praticamente tutti i componenti sono già in Kubernetes. Rimangono escluse solo le basi di dati.
- E la domanda che si pone sempre più spesso è: «È possibile inserirlo all'interno?». Pertanto, le grandi aziende cercano di massimizzare l'unificazione della gestione per poter gestire rapidamente i propri archivi di dati.
- Questo è particolarmente utile quando è necessaria la massima ripetibilità in una nuova posizione, cioè la massima portabilità.

Quanto è semplice o complesso? Certo, è possibile farlo manualmente. Ma non è così semplice, poiché ci sono già le complessità nella gestione di Kubernetes, mentre si sovrappongono le specificità di ClickHouse. Questo porta a una sorta di aggregazione.
E tutto ciò crea un insieme piuttosto ampio di tecnologie, la cui gestione diventa già piuttosto complessa, poiché Kubernetes porta le sue questioni quotidiane di sfruttamento, e ClickHouse porta le sue questioni quotidiane di gestione. Specialmente se abbiamo più istanze di ClickHouse e dobbiamo costantemente occuparci di loro.

In ClickHouse, when configuring dynamically, there are numerous questions that create a constant burden on DevOps.
- When we want to change something in ClickHouse, for instance, adding a replica or a shard, we need to manage the configuration.
- Then we must adjust the data schema because ClickHouse has a specific way of sharding. We need to lay out the data schema and the configurations.
- Monitoring must be set up.
- Logging collection for new shards and new replicas.
- Ensuring recovery.
- And restarting.
These are routine tasks that we wish to simplify in operations.

Kubernetes assists well in operations, but only for basic system tasks.
Kubernetes effectively alleviates and automates tasks such as:
- Recovery.
- Restarting.
- Storage management.
This is good; it's the right direction, but it has no comprehensive understanding of how to operate a database cluster.
We desire more; we want our entire database to function within Kubernetes.

Vorresti qualcosa come un grande pulsante rosso magico su cui premi e ottieni un cluster che si sviluppa e si gestisce per tutto il suo ciclo di vita, affrontando compiti quotidiani da risolvere. Cluster ClickHouse in Kubernetes.
Abbiamo cercato di realizzare una soluzione che rendesse il lavoro più facile. Questo è ClickHouse-operator per Kubernetes di Altinity.

Un operatore è un programma la cui principale responsabilità è gestire altri programmi, ovvero è un gestore.
Contiene modelli di comportamento. Questo può essere definito come conoscenze codificate sulla materia.
Il suo compito principale è semplificare la vita ai DevOps e ridurre il micromanagement, affinché possano già pensare in termini di alto livello, evitando di doversi occupare del micromanagement e di configurare manualmente tutti i dettagli.
E l'operatore funge da assistente robotico che si occupa delle micro-attività e supporta i DevOps.

A cosa serve un operatore? Si dimostra particolarmente efficace in due aspetti:
- Quando un esperto di ClickHouse non ha abbastanza esperienza, ma è necessario utilizzare ClickHouse, l'operatore semplifica la gestione e consente l'esecuzione di un cluster ClickHouse con una configurazione piuttosto complessa, senza addentrarsi troppo nei dettagli su come funziona internamente. Basta dargli incarichi di alto livello e tutto funziona.
- E il secondo compito in cui si distingue di più è quando è necessario automatizzare un gran numero di compiti standard. Rimuove le microattività dagli amministratori di sistema.

Questo è particolarmente utile sia per chi sta appena iniziando il proprio percorso, sia per chi deve dedicarsi molto all'automazione.

Qual è quindi la differenza tra un approccio basato sugli operatori e altri sistemi? C'è anche Helm. Anche questo aiuta a installare ClickHouse e si possono creare helm charts che installano persino un intero cluster di ClickHouse. Qual è quindi la differenza tra l'operatore e, ad esempio, Helm?
La fondamentale differenza è che Helm è un gestore di pacchetti, mentre l'operatore va oltre. Si occupa dell'intero ciclo di vita. Non si tratta solo di installazione, ma di attività quotidiane che comprendono scalabilità, sharding e tutto ciò che deve essere eseguito nel processo di vita (inclusa eventualmente anche la rimozione) – tutto questo lo gestisce l'operatore. Cerca di automatizzare e mantenere l'intero ciclo di vita del software. Questo è il suo fondamentale distinto rispetto ad altre soluzioni disponibili.
Questa è stata la parte introduttiva, ora andiamo avanti.
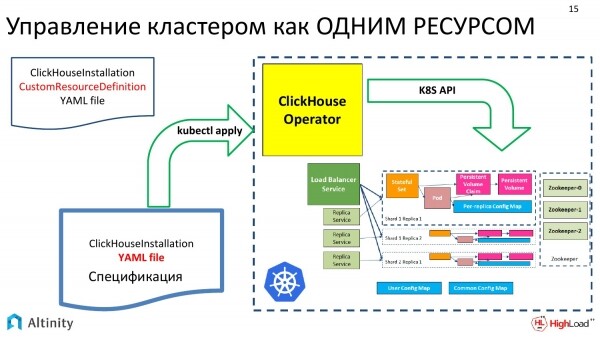
Come costruiamo il nostro operatore? Cerchiamo di gestire il cluster ClickHouse come una risorsa unica.
Qui sulla sinistra abbiamo i dati in ingresso. È un YAML con la specifica del cluster, che viene tradizionalmente inviato a Kubernetes tramite kubectl. Qui l'operatore coglie il tutto e fa la sua magia. E in uscita abbiamo uno schema come questo. È l'implementazione di ClickHouse in Kubernetes.
E successivamente cominceremo a esaminare lentamente come funziona l'operatore e quali compiti tipici possono essere risolti. Esamineremo solo i compiti tipici, poiché abbiamo tempo limitato. E non parleremo di tutto ciò che l'operatore può gestire.

Partiamo dalla pratica. Il nostro progetto è completamente open source, quindi puoi vedere su GitHub come funziona. E puoi considerare che, se vuoi semplicemente avviare, puoi iniziare con la Quick Start Guide.
Se vuoi approfondire, ci impegniamo a mantenere la documentazione in uno stato più o meno decente.

Iniziamo con un compito pratico. La prima cosa da cui tutti vogliamo partire è lanciare il primo esempio in qualche modo. Come avviare ClickHouse utilizzando l'operatore, anche senza sapere molto su come funziona? Scriviamo un manifesto, poiché tutta la comunicazione con k8s avviene tramite manifesti.

Ecco un manifesto complesso. Ciò che abbiamo evidenziato in rosso è su cui dobbiamo concentrarci. Chiediamo all'operatore di creare un cluster di nome demo.
Questi sono solo esempi di base. Lo Storage non è ancora descritto, ma torneremo a parlarne più tardi. Nel frattempo, osserviamo come evolve il cluster.
Abbiamo creato questo manifesto. Lo stiamo dando in pasto al nostro operatore. Ha lavorato e ha fatto la sua magia.

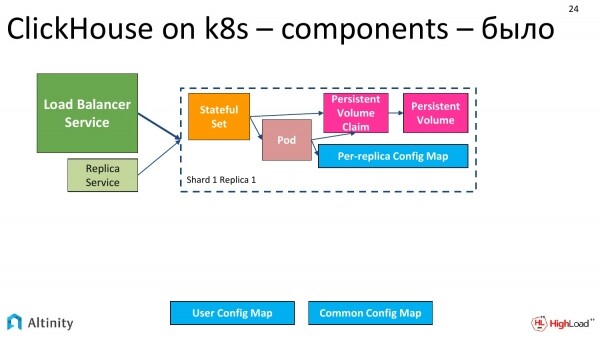
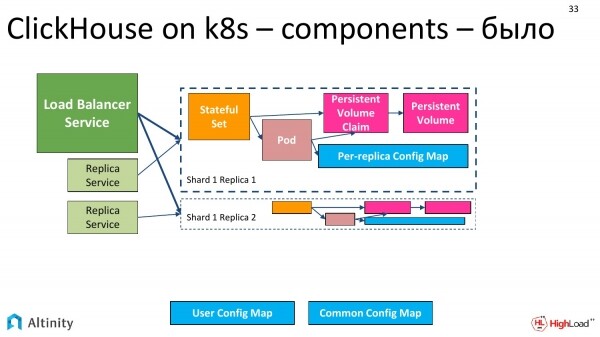
Guardiamo la console. Tre componenti catturano l'attenzione: il Pod, i due Service e lo StatefulSet.
L'operatore ha fatto il suo lavoro, e possiamo vedere cosa ha esattamente creato.
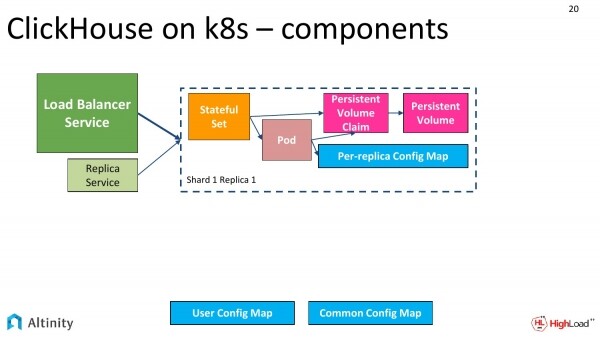
Crea una struttura simile a questa. Abbiamo uno StatefulSet, un Pod, un ConfigMap per ogni replica e un ConfigMap per l'intero cluster. Servizi obbligatori come punti di ingresso nel cluster.
I servizi comprendono il Load Balancer Service centrale e si possono avere anche per ogni replica, per ogni shardo.
Ecco come appare il nostro cluster di base. È composto da un'unica nod.

Andiamo avanti, lo complicheremo. Dobbiamo shardizzare il cluster.
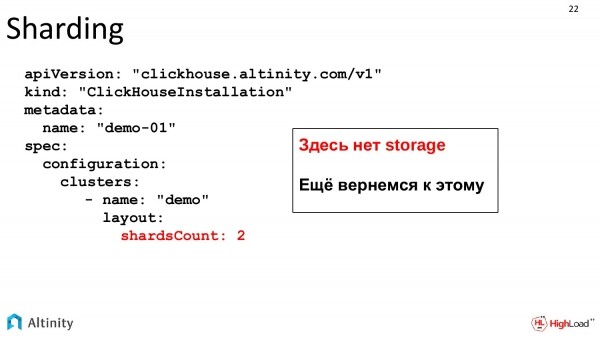
Le nostre esigenze stanno crescendo, c'è dinamica. Vogliamo aggiungere uno shardo. Seguiamo lo sviluppo. Cambiamo la nostra specifica. Indichiamo che desideriamo due shard.
Questo è lo stesso file, che si evolve dinamicamente con la crescita del sistema. Lo Storage non è trattato, ma ne discuteremo più avanti, è un argomento a parte.
Diamo in pasto l'operatore YAML e vediamo cosa succede.

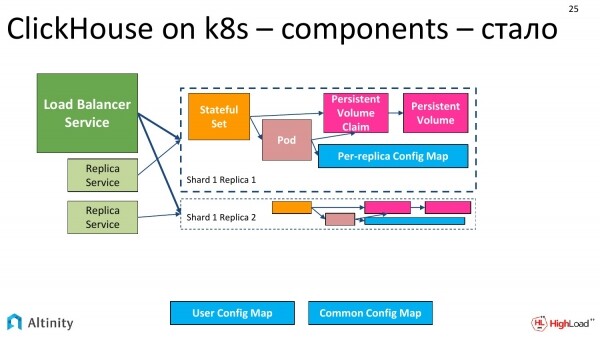
L'operatore ha riflettuto e ha creato le seguenti entità. Abbiamo già due Pod, tre Service e, improvvisamente, due StatefulSet. Perché due StatefulSet?
Nello schema era così: questa è la nostra condizione iniziale, quando avevamo un solo pod.
Adesso è diventato così. Finora è tutto semplice, si è duplicato.
E perché ci sono due StatefulSet? Qui bisogna divagare e discutere come in Kubernetes avviene la gestione dei Pod.
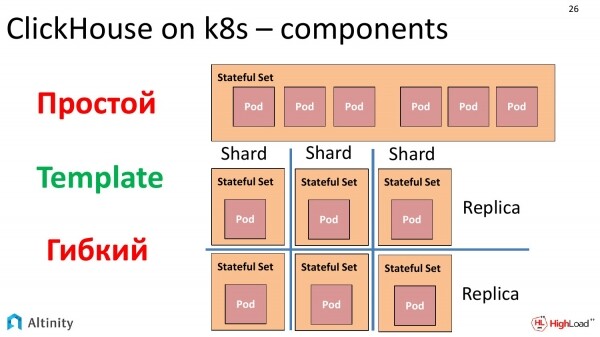
Esiste un oggetto chiamato StatefulSet, che consente di creare un insieme di Pod da un modello. Qui il fattore chiave è il Template. E in un unico StatefulSet si possono avviare molti Pod da un solo modello. E la frase chiave qui è «molti Pod da un solo modello».
C'era una grande tentazione di creare l'intero cluster, impacchettandolo in un unico StatefulSet. Questo funzionerebbe, non ci sono problemi. Ma c'è un piccolo dettaglio. Se vogliamo assemblare un cluster eterogeneo, cioè composto da più versioni di ClickHouse, qui iniziano i problemi. Sì, StatefulSet può fare un aggiornamento rolling, sì, si può applicare una nuova versione, specificando che non è consigliabile provare più di un certo numero di nodi contemporaneamente.
Ma se extrapoliamo il compito e diciamo che vogliamo creare un cluster completamente eterogeneo, e non vogliamo semplicemente eseguire un rolling update dalla vecchia versione alla nuova, ma vogliamo creare un cluster eterogeneo sia in termini di diverse versioni di ClickHouse che di storage. Vogliamo, ad esempio, creare alcune repliche su dischi separati, su dischi più lenti, insomma, costruire completamente un cluster eterogeneo. Poiché lo StatefulSet realizza una soluzione standardizzata da un singolo modello, non è possibile fare tutto ciò.
Dopo alcune riflessioni, è stata presa la decisione di procedere in questo modo. Ogni replica avrà il proprio StatefulSet. Ci sono alcuni svantaggi in questa soluzione, ma in pratica tutto è completamente racchiuso nell'operatore. E ci sono molti vantaggi. Possiamo costruire un cluster esattamente come lo desideriamo, ad esempio, assolutamente eterogeneo. Pertanto, nel cluster in cui abbiamo due shard con una replica ciascuno, avremo 2 StatefulSet e 2 Pod, proprio perché abbiamo scelto questo approccio per le ragioni sopra menzionate che ci consentono di costruire un cluster eterogeneo.

Torniamo alle applicazioni pratiche. Nel nostro cluster dobbiamo configurare gli utenti, cioè dobbiamo effettuare alcune configurazioni di ClickHouse in Kubernetes. L'operatore offre tutte le possibilità per farlo.

Possiamo scrivere direttamente in YAML quello che vogliamo. Tutte le opzioni di configurazione si mappano direttamente da questo YAML ai file di configurazione di ClickHouse, che poi vengono distribuiti su tutto il cluster.
Possiamo scrivere anche in questo modo. Questo è solo un esempio. È possibile fare una password criptata. Tutte le opzioni di configurazione di ClickHouse sono supportate. Qui c'è solo un esempio.
La configurazione del cluster viene distribuita come ConfigMap. Nella pratica, l'aggiornamento di ConfigMap non avviene istantaneamente, quindi se il cluster è grande, il processo di immissione della configurazione richiede del tempo. Ma tutto ciò è molto comodo da gestire.

Complichiamo il compito. Il cluster si sta sviluppando. Vogliamo replicare i dati. Cioè, abbiamo già due shard, con una replica, e gli utenti sono configurati. Stiamo crescendo e vogliamo occupentrarci della replicazione.

Cosa ci serve per la replicazione?
Abbiamo bisogno di ZooKeeper. In ClickHouse, la replicazione è costruita utilizzando ZooKeeper. ZooKeeper è necessario affinché diverse repliche di ClickHouse raggiungano un consenso su quali blocchi di dati siano presenti in ciascun ClickHouse.
Si può utilizzare qualsiasi versione di ZooKeeper. Se l'azienda ha un ZooKeeper esterno, può essere utilizzato. In caso contrario, possiamo installarlo dal nostro repository. Esiste un installatore che semplifica tutto questo.
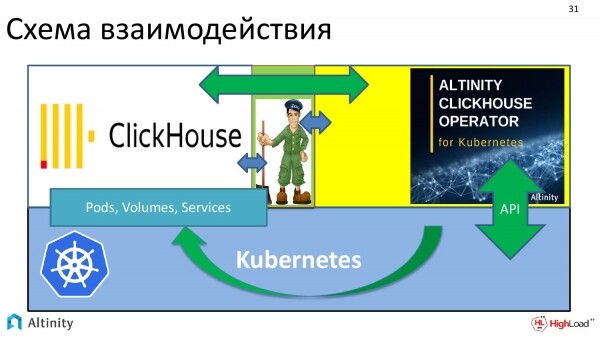
La schema di interazione dell'intero sistema è la seguente. Abbiamo Kubernetes come piattaforma. Su di essa eseguiamo l'operatore ClickHouse. Ho rappresentato ZooKeeper qui. L'operatore interagisce sia con ClickHouse che con ZooKeeper. Quindi, si ottiene un'interazione.
Tutto ciò è necessario affinché ClickHouse replichi con successo i dati in k8s.

Ora diamo un'occhiata al compito stesso, a come apparirà il manifesto per la replicazione.
Aggiungiamo due sezioni al nostro manifesto. La prima riguarda da dove ottenere ZooKeeper, che può essere sia interno a Kubernetes che esterno. È semplicemente una descrizione. E richiediamo repliche. Vale a dire, vogliamo due repliche. In totale, quindi, avremo 4 pod. Ricordiamo lo storage, che verrà menzionato più avanti. Lo storage è un argomento a parte.
Era così.
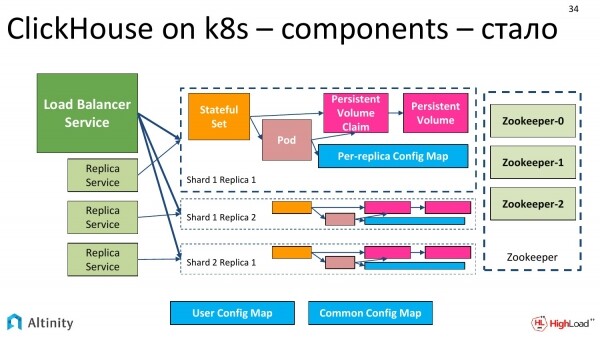
Diventa così. Vengono aggiunte delle repliche. La quarta non ci stava, crediamo che ce ne possano essere molte. E viene aggiunto ZooKeeper di lato. Gli schemi diventano più complessi.

È arrivato il momento di aggiungere il prossimo compito. Aggiungeremo Storage Persistente.
 Per quanto riguarda lo Storage Persistente, abbiamo diverse opzioni di implementazione.
Per quanto riguarda lo Storage Persistente, abbiamo diverse opzioni di implementazione.
Nel caso in cui ci troviamo su un provider cloud, ad esempio, utilizzando Amazon o Google, c'è una grande tentazione di utilizzare lo storage cloud. È molto comodo, è vantaggioso.
E c'è una seconda opzione. Questa è per lo storage locale, quando abbiamo dischi locali su ciascun nodo. Questa opzione è molto più complessa da implementare, ma è più performante.
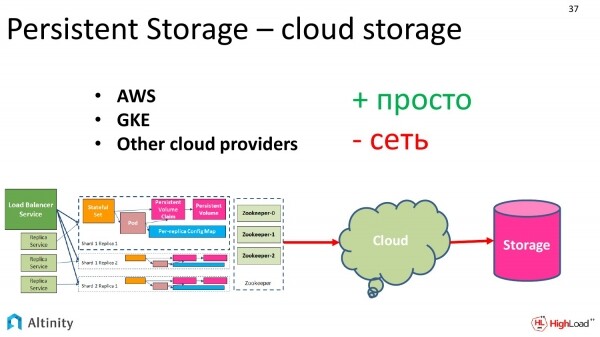
Diamo un'occhiata a cosa abbiamo riguardo allo storage cloud.
Ci sono vantaggi. È molto semplice da configurare. Ordiniamo semplicemente al provider cloud di fornirci uno storage di una certa capacità, di una certa classe. Le classi sono definite dai provider stessi.
E c'è uno svantaggio. Per qualcuno questo svantaggio non è critico. Certamente, ci saranno alcune problematiche di prestazioni. È molto comodo in uso, affidabile, ma ci sono potenziali cali di prestazioni.

Poiché ClickHouse si concentra principalmente sulle prestazioni, si può dire che sfrutti al massimo ogni risorsa; per questo molte aziende cercano di ottenere il massimo delle prestazioni.
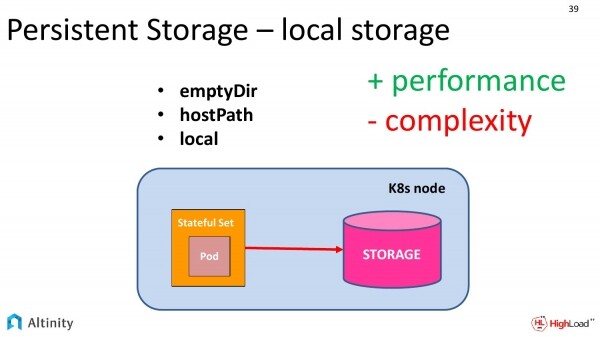
Per ottenere il massimo, abbiamo bisogno di storage locale.
Kubernetes fornisce tre astrazioni per l'uso dello storage locale in Kubernetes. Queste sono:
- EmptyDir
- HostPath.
- Locale
Esaminiamo in che modo si differenziano e in cosa sono simili.
Innanzitutto, in tutti e tre gli approcci, lo storage si basa su dischi locali che si trovano sulla stessa nodo fisica di k8s. Tuttavia, ci sono alcune differenze.
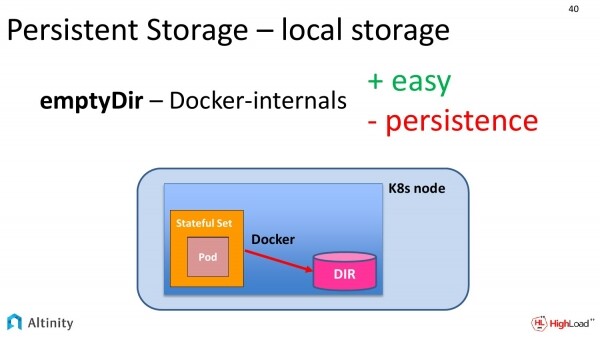
Iniziamo con il più semplice, ovvero emptyDir. Di cosa si tratta nella pratica? In sostanza, chiediamo al nostro specifica al sistema di containerizzazione (che più spesso è Docker) di fornirci accesso a una cartella sul disco locale.
In pratica, Docker crea una cartella temporanea da qualche parte, assegnandole un lungo hash come nome. E fornisce un'interfaccia per accedervi.
Come funzionerà in termini di prestazioni? Funzionerà alla velocità del disco locale, quindi si tratta di un accesso completo al proprio hardware.
Tuttavia, questa modalità presenta uno svantaggio. Persistent è piuttosto discutibile in questo caso. Alla prima azione del docker con i container, Persistent si perde. Se a Kubernetes venisse in mente di spostare questo Pod su un altro disco per qualche motivo, i dati andrebbero perduti.
Questo approccio è buono per i test, perché mostra già una velocità normale, ma per qualcosa di serio questa soluzione non è adatta.
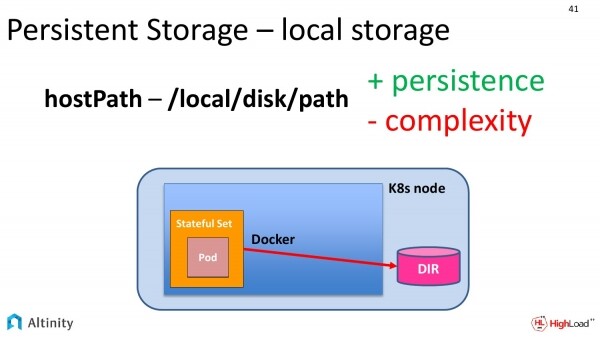
Ecco quindi un secondo approccio. Si tratta di hostPath. Se guardiamo il diapositiva precedente e questa, possiamo notare una sola differenza. La nostra cartella è uscita dal docker direttamente sulla nodi Kubernetes. È un po' più semplice. Scriviamo direttamente il percorso nel file system locale, dove vorremmo memorizzare i nostri dati.
Questo metodo ha i suoi vantaggi. È già un vero Persistent, e per di più classico. I dati saranno registrati su disco in un certo indirizzo.
Ci sono anche degli svantaggi. La complessità nella gestione è uno di essi. Il nostro Kubernetes potrebbe decidere di spostare un Pod su un'altra nodo fisica. Qui entra in gioco il DevOps. Deve spiegare correttamente all'intero sistema che questi pod possono essere spostati solo su nodi in cui hai qualcosa montato lungo quei percorsi, e non più di un nodo alla volta. È piuttosto complesso.
Proprio per questi scopi, noi come operatori abbiamo creato dei modelli per nascondere tutta questa complessità. Così si potrebbe semplicemente dire: «Voglio avere un'istanza di ClickHouse su ogni nodo fisico e su un determinato percorso».
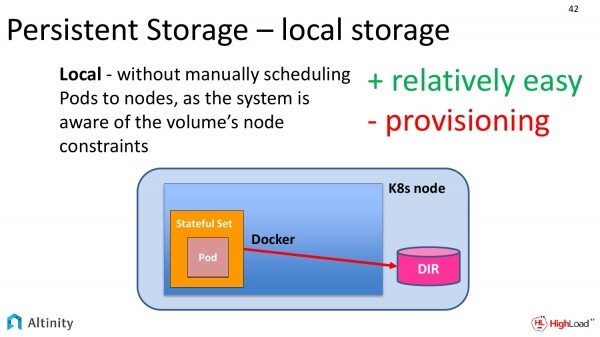
Ma questa necessità non è solo nostra, quindi i gentiluomini di Kubernetes capiscono anche che gli utenti vogliono avere accesso ai dischi fisici, e per questo forniscono un terzo livello.
Si chiama local. Le differenze rispetto alla diapositiva precedente sono praticamente nulle. Prima era necessario gestire manualmente il trasferimento dei pod da un nodo all'altro, poiché dovevano essere collegati in un percorso specifico a un disco fisico locale, mentre ora tutte queste conoscenze sono incorporate in Kubernetes stesso. Risulta quindi molto più semplice configurare.

Torniamo al nostro compito pratico. Torniamo al template YAML. Qui abbiamo un vero storage. Siamo tornati su questo. Stiamo impostando un template di VolumeClaim classico come in k8s. E descriviamo quale storage vogliamo.
Dopo di ciò, k8s richiederà storage. Ce ne fornirà uno in StatefulSet. E alla fine questo sarà a disposizione di ClickHouse.
Avevamo questo schema. Il nostro Persistent Storage era rosso, il che lasciava intendere che dovesse essere reso.
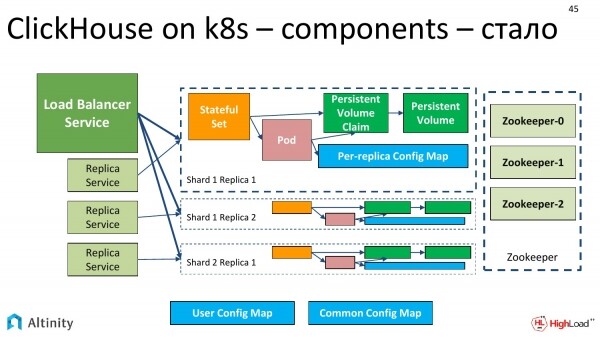
E diventa verde. Ora lo schema del cluster ClickHouse su k8s è completamente finalizzato. Abbiamo shard, repliche, ZooKeeper e un vero Persistent, realizzato in un modo o nell'altro. Lo schema è già completamente funzionante.

Continuiamo a progredire. Il nostro cluster si evolve. E Alexey si impegna e rilascia una nuova versione di ClickHouse.
Si presenta un compito pratico: testare la nuova versione di ClickHouse sul nostro cluster. Naturalmente, non vogliamo aggiornare tutto, ma preferiremmo installare la nuova versione in un angolo remoto, e magari anche non solo una nuova versione, ma ben due, visto che escono frequentemente.
Cosa possiamo dire al riguardo?

Abbiamo proprio questa opportunità. Ci sono dei modelli di pod. Possiamo elaborare la configurazione poiché il nostro operatore consente di costruire un cluster eterogeneo. Cioè, possiamo configurarlo a partire da tutte le repliche insieme, fino a ogni singola replica specificando quale versione di ClickHouse vogliamo e quale versione di storage desideriamo. Possiamo configurare completamente il cluster secondo le nostre necessità.

Adesso ci addentriamo un po' di più. Prima abbiamo parlato di come funziona ClickHouse-Operator in relazione alle specifiche di ClickHouse.
Ora vorrei dire alcune parole su come funziona generalmente qualsiasi operatore, e su come interagisce con K8s.
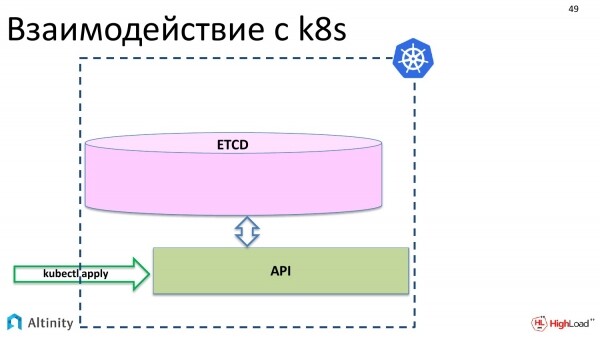
Iniziamo esaminando l'interazione con K8s. Cosa succede quando eseguiamo kubectl apply? I nostri oggetti appaiono in etcd tramite l'API.
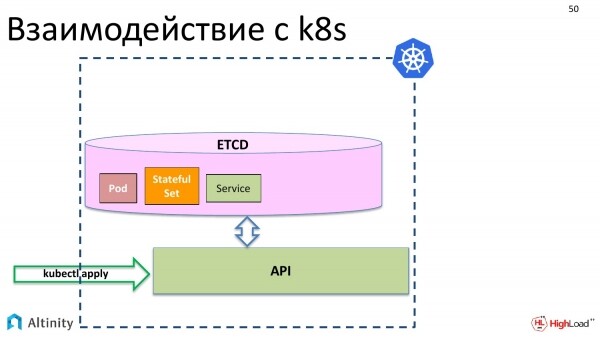
Ad esempio, i componenti di base di Kubernetes: pod, StatefulSet, servizio e così via.
Tuttavia, non sta ancora accadendo nulla di fisico. Questi oggetti devono essere materializzati nel cluster.
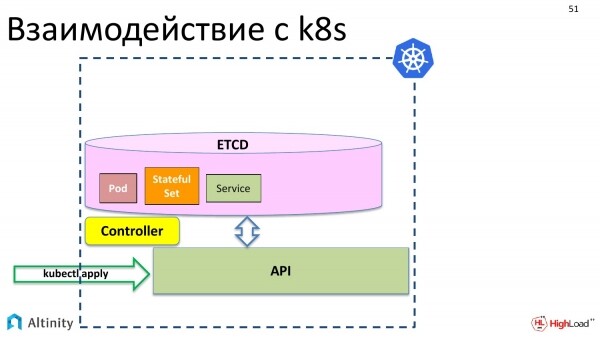
A questo serve il controller. Il controller è un componente speciale di k8s che sa come materializzare queste descrizioni. Sa come fare fisicamente e come avviare i container, cosa deve essere configurato affinché il server funzioni.
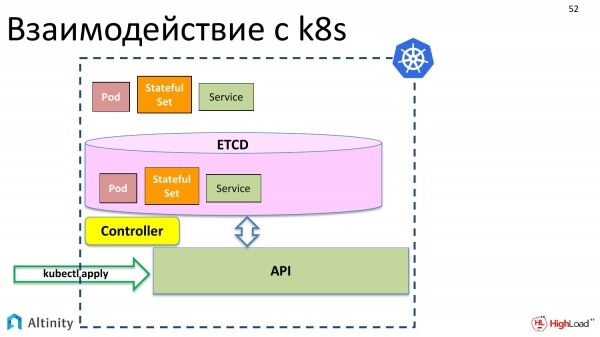
E materializza i nostri oggetti in K8s.
Ma non vogliamo operare solo con pod e StatefulSet, vogliamo creare un ClickHouseInstallation, cioè un oggetto di tipo ClickHouse, per operarlo come un'unica entità. Al momento, questa possibilità non esiste.
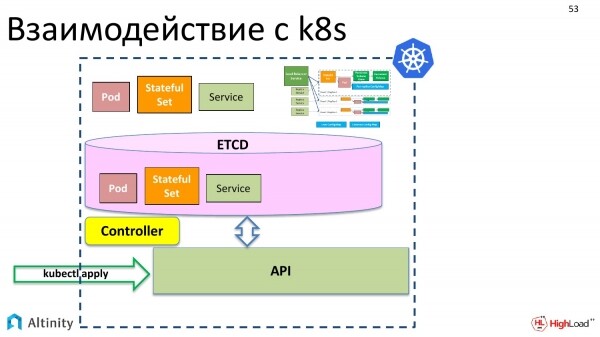
Ma K8s ha una cosa piacevole. Vogliamo che emerga un'entità complessa da qualche parte, che integri pod e StatefulSet nel nostro cluster.
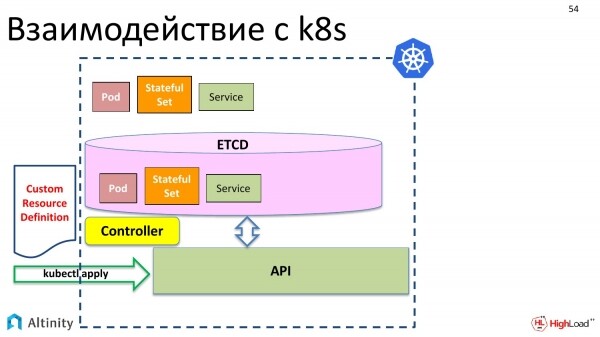
E cosa bisogna fare per questo? Innanzitutto, entra in scena la Custom Resource Definition. Cos'è? È una descrizione per K8s, che stabilisce che avremo un ulteriore tipo di dati, e che vogliamo aggiungere una risorsa personalizzata che sarà complessa all'interno di pod e StatefulSet. Questa è la descrizione della struttura dei dati.
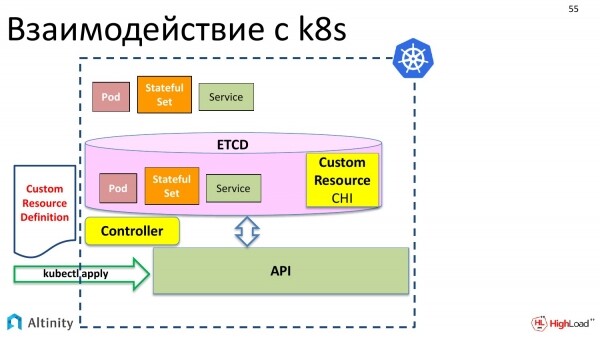
Lo inviamo anche noi tramite kubectl apply. Kubernetes lo ha accolto con gioia.
E ora nella nostra archiviazione, l'oggetto in etcd ha la possibilità di registrare una risorsa personalizzata chiamata ClickHouseInstallation.
Ma fino ad ora non succederà niente di più. Cioè, se adesso creiamo un file YAML, come abbiamo visto, descrivendo shard, repliche e diciamo 'kubectl apply', Kubernetes lo accetterà, lo metterà in etcd e dirà: 'Ottimo, ma non so cosa farne. Non so come gestire ClickHouseInstallation'.
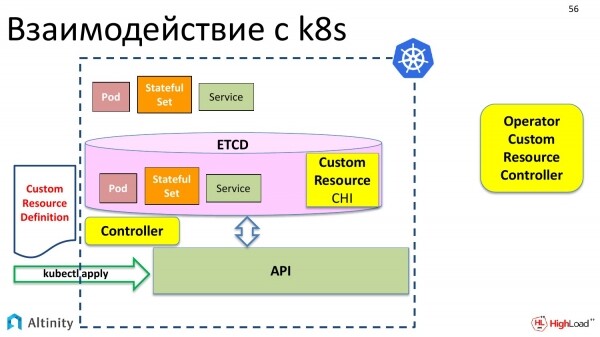
Pertanto, abbiamo bisogno di qualcuno che aiuti Kubernetes a gestire un nuovo tipo di dati. A sinistra abbiamo un controller Kubernetes predefinito che lavora con i tipi di dati standard. E a destra deve comparire un controller personalizzato che sa lavorare con i tipi di dati personalizzati.
E in un altro modo si chiama operatore. L'ho messo qui appositamente al di fuori di Kubernetes perché può essere eseguito anche esternamente a K8s. Spesso, naturalmente, tutti gli operatori vengono eseguiti in Kubernetes, ma niente impedisce di posizionarlo all'esterno, quindi qui è stato appositamente spostato all'esterno.
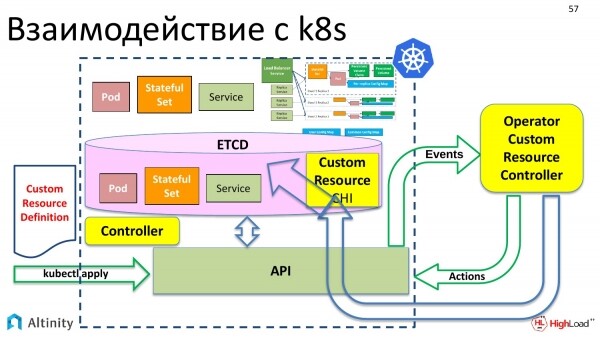
E nel suo turno, il controller personalizzato, noto anche come operatore, interagisce con Kubernetes attraverso l'API. Sa già come interagire con l'API e conosce già come materializzare uno schema complesso a partire da una risorsa personalizzata, ciò che vogliamo realizzare. È proprio di questo che si occupa l'operatore.
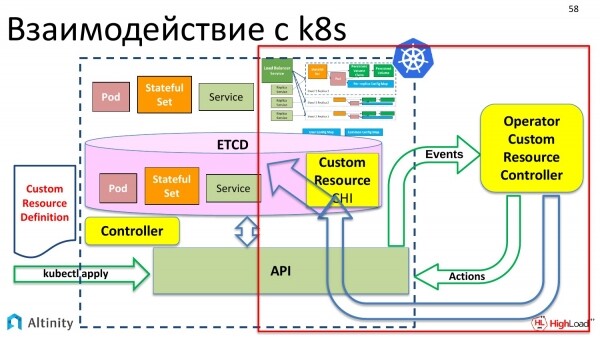
Come funziona l'operatore? Diamo un'occhiata alla parte destra per scoprire come fa. Scopriamo come l'operatore materializza tutto questo e come avviene ulteriormente l'interazione con K8s.
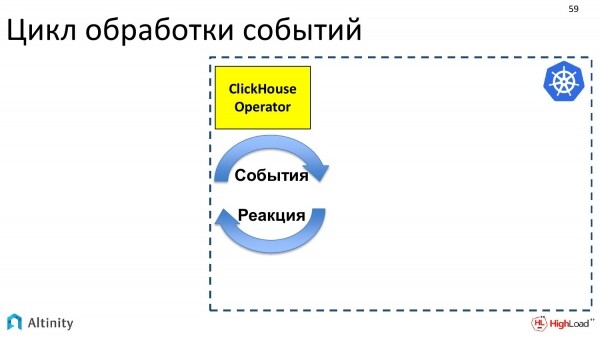
L'operatore è un programma. È orientato agli eventi. Utilizzando l'API di Kubernetes, l'operatore si iscrive agli eventi. Nell'API di Kubernetes ci sono punti di entrata dove ci si può iscrivere agli eventi. E se qualcosa cambia in K8s, Kubernetes invia eventi a tutti gli interessati, ovvero chi si è iscritto a quel punto dell'API riceverà notifiche.
L'operatore si iscrive agli eventi e deve reagire in qualche modo. Il suo compito è reagire agli eventi che si presentano.
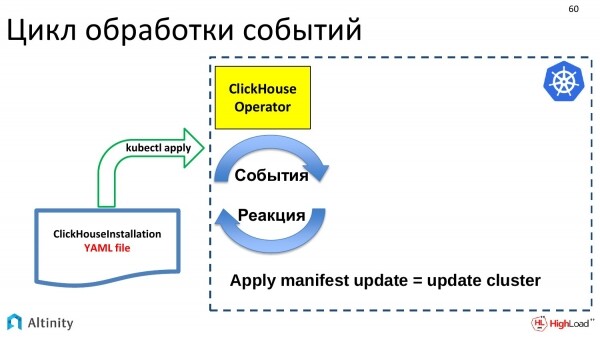
Gli eventi vengono generati da alcuni aggiornamenti. Arriva il nostro file YAML con la descrizione di ClickHouseInstallation. Questo è passato a etcd tramite kubectl apply. Qui si è attivato un evento, che è arrivato al ClickHouse-operator. L'operatore ha ricevuto questa descrizione. E ora ha qualcosa da fare. Se è arrivato un aggiornamento per l'oggetto ClickHouseInstallation, bisogna aggiornare il cluster. Il compito dell'operatore è quello di aggiornare il cluster.
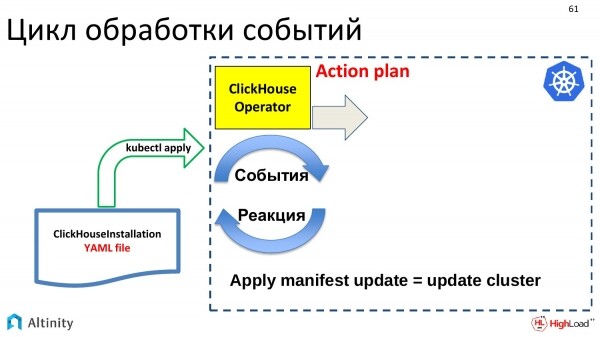
Cosa fa? In primo luogo, deve elaborare un piano d'azione per gestire questo aggiornamento. Gli aggiornamenti possono essere molto piccoli, cioè ridotti nell'esecuzione YAML, ma possono comportare cambiamenti molto grandi nel cluster. Perciò, l'operatore crea un piano e poi lo segue.
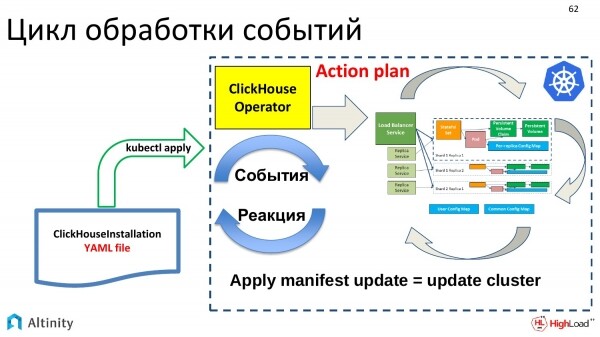
Inizia a lavorare su questa struttura secondo il piano, per materializzare i pod, i servizi, cioè per fare ciò che è il suo compito principale. È come costruire un cluster ClickHouse in Kubernetes.
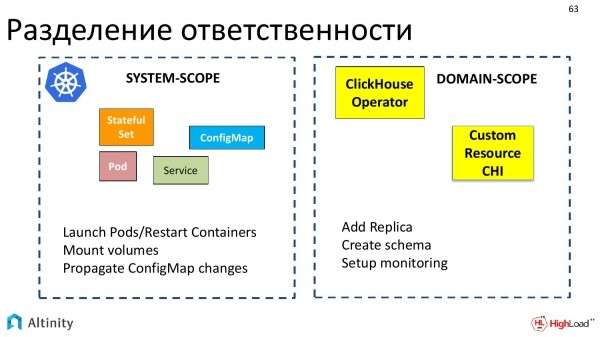
Ora parliamo di un aspetto interessante. Questa è la suddivisione delle responsabilità tra Kubernetes e l'operatore, cioè cosa fa Kubernetes, cosa fa l'operatore e come interagiscono tra loro.
Kubernetes si occupa delle operazioni di sistema, ovvero del set base di oggetti che può essere interpretato come ambito di sistema. Kubernetes sa come avviare pod, riavviare container, montare volumi e gestire ConfigMap, cioè tutto ciò che può essere definito come sistema.
Gli operatori operano in settori specifici. Ogni operatore è creato per il proprio settore. Ne abbiamo realizzato uno per ClickHouse.
E l'operatore interagisce precisamente in termini del settore, come aggiungere una replica, creare uno schema, configurare il monitoraggio. Questo porta a una chiara distinzione.

Vediamo un esempio pratico di come avviene questa suddivisione delle responsabilità quando eseguiamo l'azione di aggiungere una replica.
L'operatore riceve la richiesta di aggiungere una replica. Cosa fa l'operatore? Calcola che deve creare un nuovo StatefulSet, in cui deve descrivere determinati modelli e richieste di volume.

Ha preparato tutto questo e lo passa a K8s. Dice che ha bisogno di ConfigMap, StatefulSet e Volume. Kubernetes elabora la richiesta. Materializza le unità fondamentali con cui opera.
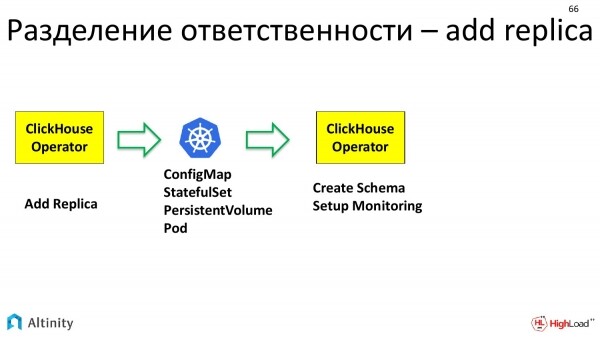
E così entra in gioco di nuovo il ClickHouse-operator. Ha già un pod fisico su cui può iniziare a lavorare. E il ClickHouse-operator opera di nuovo in termini della specifica del dominio. Cioè, specificamente per ClickHouse, per includere una replica nel cluster è necessario, prima di tutto, configurare lo schema dei dati presente in quel cluster. In secondo luogo, questa replica deve essere inclusa nel monitoraggio per garantirne un buon tracciamento. L'operatore si occupa di questa configurazione.
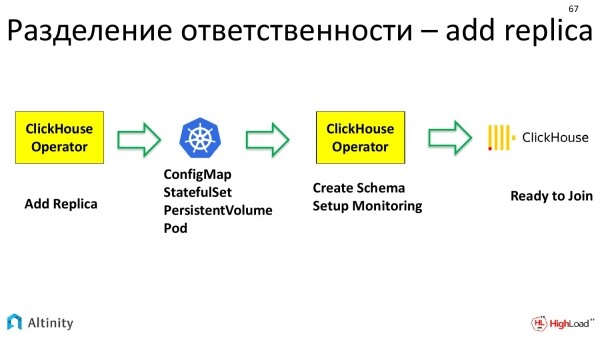
E solo dopo questo entra in gioco il ClickHouse stesso, cioè un'entità di livello superiore. Questa è già un database. Ha il proprio instance, un'altra replica configurata, pronta per entrare nel cluster.
Si ha così una catena di esecuzione e divisione delle responsabilità piuttosto lunga quando si aggiunge una replica.

Continuiamo con i nostri esercizi pratici. Se il cluster è già esistente, si può procedere con la migrazione della configurazione.

Abbiamo fatto in modo che nel file xml esistente, che ClickHouse comprende, si possa passare attraverso.

È possibile effettuare un fine-tuning di ClickHouse. Proprio il zoned deployment è ciò di cui parlavo spiegando il hostPath e lo storage locale. È come configurare correttamente il zoned deployment.

Il prossimo compito pratico è il monitoraggio.
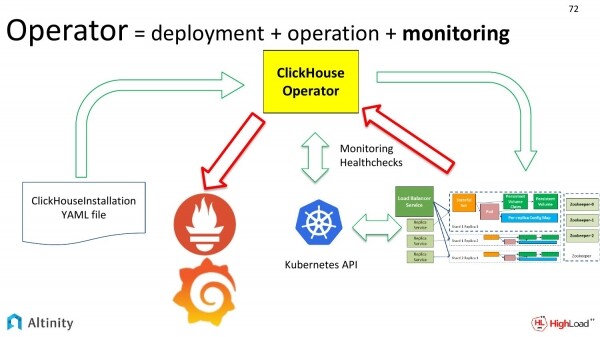
Se il nostro cluster cambia, è necessario configurare periodicamente il monitoraggio.
Esaminiamo lo schema. Abbiamo già analizzato le frecce verdi. Ora consideriamo le frecce rosse. Questo è come vogliamo monitorare il nostro cluster. Come le metriche dal cluster ClickHouse arrivano a Prometheus e poi a Grafana.

Qual è la difficoltà nel monitoraggio? Perché è considerato un risultato? La difficoltà risiede nella dinamica. Quando abbiamo un cluster singolo e statico, possiamo configurare il monitoraggio una volta e non pensarci più.
Ma se abbiamo molti cluster, o se qualcosa cambia continuamente, il processo diventa dinamico. E occuparsi costantemente della riconfigurazione del monitoraggio è uno spreco di risorse e tempo, ovvero anche solo una fonte di pigrizia. Questo deve essere automatizzato. La difficoltà sta nella dinamicità del processo. E l'operatore lo automatizza molto bene.
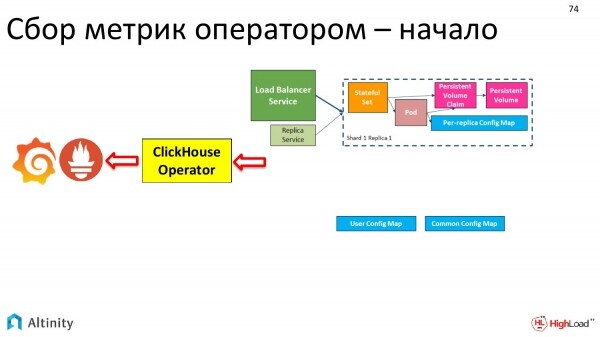
Come si è evoluto il nostro cluster? All'inizio era così.
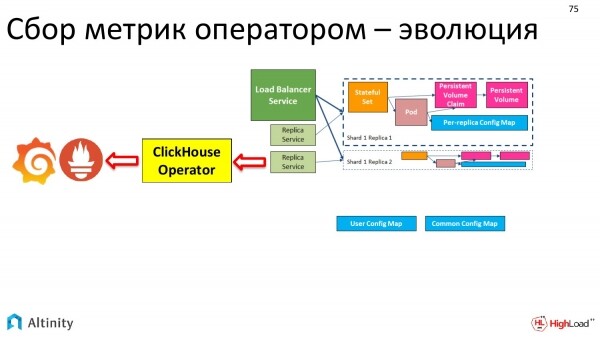
Poi è diventato così.
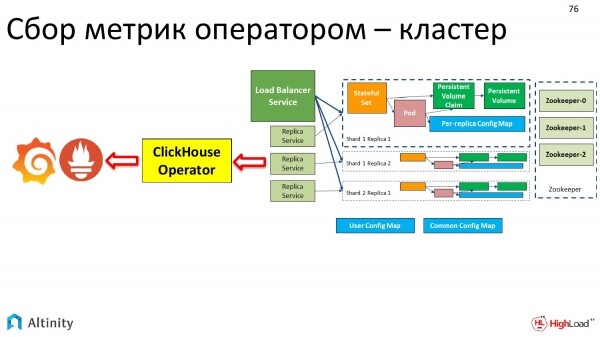
Alla fine è diventato in questo modo.
Il monitoraggio è fatto automaticamente dall'operatore. Unico punto di accesso.
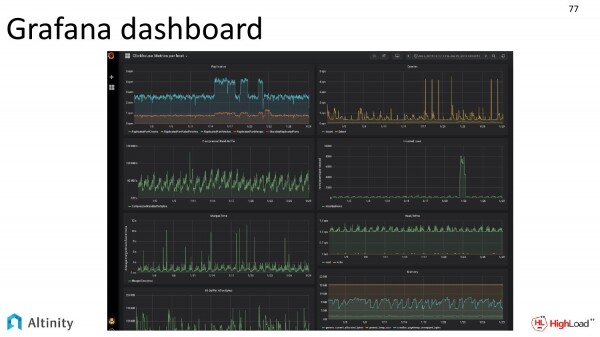
E noi guardiamo solo il dashboard Grafana, osservando la vita pulsante del nostro cluster.
A proposito, anche il dashboard Grafana viene fornito con il nostro operatore direttamente nel codice sorgente. È possibile collegarlo e utilizzarlo. Questo screenshot è stato fornito dai nostri DevOps.

Qual è la nostra prossima direzione? Questo è:
- Sviluppare l'automazione dei test. L'obiettivo principale è il test automatizzato delle nuove versioni.
- Vogliamo anche automatizzare l'integrazione con ZooKeeper. Abbiamo in programma di integrarci con lo ZooKeeper-operator. Cioè, per ZooKeeper è stato scritto un operatore, ed è logico che i due operatori inizino a integrarsi per costruire una soluzione più comoda.
- Vogliamo implementare controlli più complessi per la vitalità.
- In verde ho evidenziato ciò che ha già raggiunto l'eredità dei Templates – FATTO, cioè con il prossimo rilascio dell'operatore avremo già l'eredità dei template. Questo è uno strumento potente che consente di costruire configurazioni complesse da pezzi.
- E vogliamo l'automazione di compiti complessi. Il principale di cui stiamo parlando è la Re-sharding.

Facciamo un riepilogo intermedio.

Cosa otteniamo alla fine? È conveniente farlo o no? È necessario tentare di portare un database in Kubernetes e applicare l'operatore in generale e l'operatore Alitnity in particolare?
Alla fine otteniamo:
- Una significativa semplificazione e automazione della configurazione, del deployment e della manutenzione.
- Monitoraggio integrato fin da subito.
- E modelli codificati pronti all'uso per situazioni complesse. Non è più necessario aggiungere manualmente una replica. Questo è compito dell'operatore.

Rimane solo un'ultima domanda. Abbiamo già un database in Kubernetes, virtualizzazione. Qual è la performance di tale soluzione, specialmente considerando che ClickHouse è ottimizzato per le performance?
La risposta è: tutto funziona bene! Non entrerò nei dettagli, è un argomento di un intervento separato.

Ma esiste un progetto chiamato TSBS. Qual è il suo obiettivo principale? È un test per valutare le performance dei database. È un tentativo di confrontare il caldo con il caldo, il morbido con il morbido.
Come funziona? Viene generato un insieme di dati. Successivamente, questo set di dati viene eseguito su un insieme di test identico su diverse basi di dati. E ogni database risolve un compito secondo le proprie capacità. Poi è possibile confrontare i risultati.
Supporta già un ampio numero di database. Ne ho evidenziati tre principali. Questi sono:
- TimescaleDB.
- InfluxDB.
- ClickHouse.
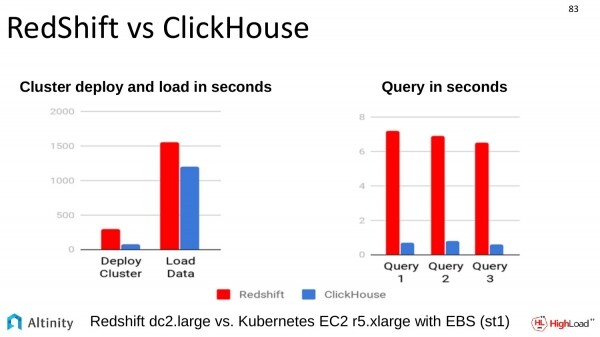
È stato inoltre effettuato un confronto con un'altra soluzione simile. Il confronto con RedShift. L'analisi è stata condotta su Amazon. Anche ClickHouse supera tutti in questo ambito.

Quali conclusioni possiamo trarre da quanto ho detto?
- DB può essere utilizzato in Kubernetes. Probabilmente, si possono utilizzare tutti, ma in generale sembra che sia possibile. ClickHouse in Kubernetes è certamente utilizzabile tramite il nostro operatore.
- L'operatore aiuta ad automatizzare i processi e semplifica davvero la vita.
- Le performance sono buone.
- E, riteniamo, che sia possibile e necessario utilizzarlo.
Open source – unitevi a noi!
Come ho già detto, l'operatore è un prodotto completamente open source, quindi sarebbe davvero fantastico se il maggior numero possibile di persone lo utilizzasse. Unitevi a noi! Vi aspettiamo tutti!
Grazie a tutti!
Domande

Grazie per la presentazione! Mi chiamo Anton e vengo dall'azienda SEMrush. Sono curioso riguardo al logging. Sento parlare di monitoraggio, ma riguardo al logging non si dice nulla, parlando del cluster nel suo insieme. Noi, ad esempio, abbiamo sollevato un cluster sull'hardware. E utilizziamo il logging centralizzato, raccogliendo standardmente in un unico luogo. E poi da lì estraiamo i dati che ci interessano.
Ottima domanda, cioè il logging è nella lista delle cose da fare. Il nostro operatore per ora non lo automatizza. È ancora in fase di sviluppo, il progetto è abbastanza giovane. Comprendiamo l'importanza del logging. È un tema molto rilevante. E probabilmente è almeno importante quanto il monitoraggio. Ma il monitoraggio è stato il primo in lista per l'implementazione. Il logging ci sarà. Naturalmente, ci sforziamo di automatizzare tutti gli aspetti della vita del cluster. Quindi la risposta è: al momento l'operatore purtroppo non è in grado di farlo, ma è nei nostri piani, lo faremo. Se c'è interesse a partecipare, per favore fai un pull request.
Ciao! Grazie per la presentazione! Ho una domanda standard riguardante i Persistent Volumes. Quando creiamo una configurazione con quest'operatore, come fa l'operatore a determinare su quale nodo abbiamo montato un disco o una cartella? Dobbiamo spiegarli in anticipo che, per favore, posizioni il nostro ClickHouse precisamente su quei nodi dove c'è un disco?
Se non erro, questa domanda è un proseguimento dello storage locale, in particolare della parte relativa a hostPath. È come spiegare all'intero sistema che vogliamo che un pod venga eseguito su un determinato nodo, sul quale abbiamo un disco fisicamente collegato, montato in un determinato percorso. È un'intera sezione che ho toccato in modo molto superficiale, perché la risposta è piuttosto complessa.
In breve, funziona in questo modo. Naturalmente, dobbiamo fare il provisioning di questi volumi. Attualmente, non c'è provisioning dinamico nello storage locale, quindi i DevOps devono creare manualmente i dischi, ossia questi volumi. Devono anche spiegare a Kubernetes il provisioning, indicando che ci saranno Persistent volumes di un certo tipo, localizzati su specifici nodi. Dopodiché, sarà necessario spiegare a Kubernetes che i pod che richiedono un certo tipo di storage locale devono essere schedulati solo su determinati nodi mediante labels. A tal fine, l'operatore ha la possibilità di assegnare etichette specifiche e una per istanza host. Di conseguenza, i pod verranno instradati da Kubernetes per avviarsi solo su nodi che soddisfano i requisiti delle etichette, per dirla in termini semplici. Gli amministratori assegnano le labels e fanno il provisioning dei dischi manualmente. In questo modo, si riesce a scalare.
E infatti, la terza opzione locale aiuta un po' a semplificare questo lavoro. Come ho già sottolineato, si tratta di un lavoro meticoloso di configurazione che, alla fine, contribuisce a ottenere la massima performance.
Ho una seconda domanda relativa a questo. Kubernetes è stato progettato in modo che non ci importi se perdiamo un nodo o meno. Cosa dobbiamo fare in questo caso, se perdiamo il nodo in cui è ospitato uno shard?
Sì, Kubernetes è stato inizialmente concepito con l'idea che il nostro rapporto con i nostri pod sia simile a quello con il bestiame, mentre ogni disco diventa qualcosa di simile a un animale domestico. C'è un problema: non possiamo semplicemente buttarli via. Lo sviluppo di Kubernetes sta andando verso la direzione in cui non è possibile considerare tutto questo in modo puramente filosofico, come risorse completamente usa e getta.
Ora, una domanda pratica. Cosa fare se hai perso un nodo su cui si trovava un disco? Qui la questione viene risolta a un livello più alto. Nel caso di ClickHouse, abbiamo delle repliche che operano a un livello superiore, cioè a livello di ClickHouse.
Qual è la disposizione finale? È responsabilità del DevOps assicurarsi che i dati non vengano persi. Deve configurare correttamente la replica e deve monitorare che essa funzioni. I dati devono essere duplicati nella replica a livello di ClickHouse. Non è un compito che risolve l'operatore e nemmeno Kubernetes. È una questione a livello di ClickHouse.
Cosa fare se il tuo nodo fisico è andato giù? Dobbiamo quindi installare un secondo nodo, configurare correttamente il disco e applicare le etichette. Solo così potrà soddisfare i requisiti affinché Kubernetes possa avviare un'istanza del pod. Kubernetes lo avvierà. Hai un numero insufficiente di pod rispetto a quello richiesto. Passerà attraverso il ciclo che ti ho mostrato. A un livello superiore, ClickHouse capirà che è stata aggiunta una replica, che è ancora vuota e da cui iniziare a trasferire i dati. Questo processo, però, è ancora poco automatizzato.
Grazie per la presentazione! Quando accadono inconvenienti e l'operatore si blocca e si riavvia, nel frattempo arrivano eventi. Come gestisci questa situazione?
Cosa succede se l'operatore si blocca e si riavvia, giusto?
Esatto. E in quel momento sono arrivati eventi.
Il compito di gestire questa situazione è parzialmente suddiviso tra l'operatore e Kubernetes. Kubernetes ha la capacità di riprodurre l'evento che si è verificato. Lo riproduce. Compito dell'operatore è garantire che, quando viene eseguito un replay del log degli eventi, questi eventi siano idempotenti. Questo significa che la ripetizione dello stesso evento non deve danneggiare il nostro sistema. E il nostro operatore gestisce bene questo compito.
Buongiorno! Grazie per la presentazione! Dmitrij Zavjalov, azienda Smedova. È prevista l'aggiunta di funzionalità di configurazione dell'operatore con haproxy? Sarei interessato a un altro bilanciatore oltre a quello standard, che sia intelligente e comprenda che si tratta di ClickHouse.
Stai parlando di Ingress?
Sì, sostituisci Ingress con haproxy. In haproxy puoi specificare la topologia del cluster, dove ha le repliche.
Per ora non ci abbiamo pensato. Se hai bisogno di questa funzione e puoi spiegare perché ti serve, possiamo implementarla, soprattutto se desideri partecipare. Saremmo felici di considerare questa opzione. In breve, no, al momento non abbiamo questa funzionalità. Grazie per il suggerimento, ci daremo un'occhiata. Se puoi anche spiegare il caso d'uso e perché è necessario nella pratica, ad esempio creando dei problemi su GitHub, sarebbe ottimo.
Esiste già.
Va bene. Siamo aperti a qualsiasi proposta. E haproxy è inserito nella lista todo. La lista todo cresce, e non diminuisce per ora. Ma va bene, significa che il prodotto è richiesto.
Fonte: habr.com
