

Ciao, Habr! Mi chiamo Maxim Vasilyev, lavoro come analista e project manager in FINCH. Oggi vorrei raccontarvi come, grazie ad ElasticSearch, siamo riusciti a gestire 15 milioni di richieste in 6 minuti e ottimizzare i carichi quotidiani sul sito di un nostro cliente. Purtroppo, dobbiamo evitare di menzionare nomi specifici, poiché abbiamo un NDA, ma speriamo che il contenuto dell'articolo non ne risenta. Iniziamo.
Come è organizzato il progetto
Sul nostro backend creiamo servizi che garantiscono il funzionamento dei siti web e dell'app mobile del nostro cliente. La struttura generale è visibile nello schema:
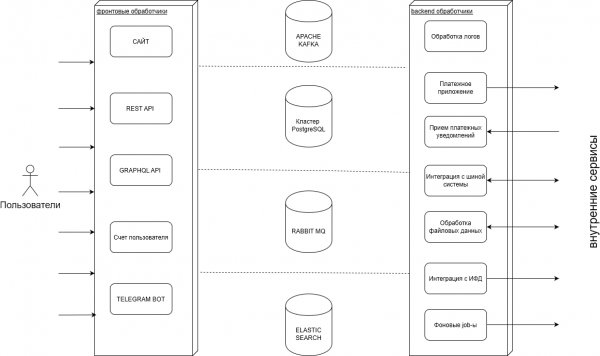
Durante il nostro lavoro gestiamo un gran numero di transazioni: acquisti, pagamenti, operazioni sui saldi degli utenti, per le quali conserviamo molti log, oltre a importare ed esportare questi dati verso sistemi esterni.
Ci sono anche processi inversi, in cui riceviamo dati dal cliente e li trasferiamo agli utenti. Inoltre, esistono processi legati ai pagamenti e ai programmi di fidelizzazione.
Una breve introduzione
Inizialmente, abbiamo utilizzato PostgreSQL come unico sistema di archiviazione dei dati. I suoi vantaggi standard come DBMS, inclusi le transazioni, un linguaggio di query avanzato e una vasta gamma di strumenti per l'integrazione, combinati con buone prestazioni, hanno soddisfatto le nostre esigenze per un periodo considerevole.
Abbiamo memorizzato in Postgres tutti i dati: dalle transazioni alle notizie. Tuttavia, il numero di utenti cresceva, così come il numero delle richieste.
Per dare un'idea, nel 2017 il numero annuale di sessioni sul sito desktop era di 131 milioni. Nel 2018 sono stati 125 milioni e nel 2019 di nuovo 130 milioni. Aggiungi altri 100-200 milioni dalla versione mobile del sito e dall'app mobile, e otterrai un'enorme quantità di richieste.
Con la crescita del progetto, Postgres ha smesso di reggere il carico; non riuscivamo a stare al passo con l'aumento delle richieste, e c'era un gran numero di richieste varie per le quali non eravamo in grado di creare un numero sufficiente di indici.
Abbiamo compreso la necessità di archivi dati alternativi che soddisfacessero le nostre esigenze e alleggerissero il carico su PostgreSQL. Tra le opzioni considerate c'erano Elasticsearch e MongoDB. Quest'ultmo presentava i seguenti svantaggi:
- Velocità di indicizzazione lenta con l'aumento del volume dei dati negli indici. Con Elastic, la velocità non dipende dal volume dei dati.
- Nessuna ricerca a testo libero
Così abbiamo scelto Elastic e ci siamo preparati per la migrazione.
Migrazione a Elastic
1. Abbiamo iniziato il passaggio con il servizio di ricerca punti vendita. Il nostro cliente ha complessivamente circa 70.000 punti vendita, e sono necessari diversi tipi di ricerca sul sito e nell'app:
- Ricerca di testo per nome della località
- Georicerche in un raggio specifico da un determinato punto. Ad esempio, se l'utente desidera vedere quali punti vendita sono più vicini a casa sua.
- Ricerca all'interno di un quadrato specifico – l'utente disegna un quadrato sulla mappa, e gli vengono mostrati tutti i punti in quella area.
- Ricerca con filtri aggiuntivi. I punti vendita si differenziano l'uno dall'altro per assortimento.
Parlando dell'organizzazione, in Postgres abbiamo la fonte dei dati sia per la mappa che per le notizie, mentre in Elastic vengono effettuati snapshot dei dati originali. Il fatto è che inizialmente Postgres non riusciva a cercare in base a tutti i criteri. Non solo c'erano molti indici, ma potevano anche sovrapporsi, quindi il planner di Postgres si confondeva e non sapeva quale indice utilizzare.
2. Successivamente è stato il turno della sezione notizie. Ogni giorno sul sito vengono pubblicate nuove informazioni e, affinché l'utente non si perda nel flusso di dati, è necessario ordinare le informazioni prima della visualizzazione. Ecco perché è necessario un sistema di ricerca: sul sito è possibile cercare per corrispondenza testuale e, allo stesso tempo, attivare filtri aggiuntivi, poiché anch'essi sono implementati tramite Elastic.
3. Poi abbiamo trasferito l'elaborazione delle transazioni. Gli utenti possono acquistare un prodotto specifico sul sito e partecipare all'estrazione di premi. Dopo tali acquisti, gestiamo un grande volume di dati, specialmente durante i fine settimana e le festività. A titolo di confronto, nei giorni normali il numero degli acquisti è di circa 1,5-2 milioni, mentre durante le festività può arrivare a 53 milioni.
In questo modo, i dati devono essere elaborati rapidamente — gli utenti non amano aspettare giorni per un risultato. Con Postgres, tali tempi non sono raggiungibili — abbiamo spesso ricevuto blocchi, e mentre elaboravamo tutte le richieste, gli utenti non potevano verificare se avevano ricevuto premi o meno. Questo non è molto piacevole per il business, quindi abbiamo trasferito l'elaborazione in Elasticsearch.
Frequenza
Attualmente, gli aggiornamenti sono impostati in modo eventi, secondo le seguenti condizioni:
- Punti vendita. Non appena riceviamo dati da una fonte esterna, avviamo immediatamente l'aggiornamento.
- Notizie. Non appena viene modificata una notizia sul sito, viene automaticamente inviata a Elastic.
Qui vale la pena ribadire i vantaggi di Elastic. In Postgres, durante l'invio della richiesta, si deve attendere che elabori correttamente tutti i record. In Elastic, è possibile inviare 10.000 record e iniziare subito a lavorare, senza dover aspettare che i record siano distribuiti su tutti i Shard. Naturalmente, un certo Shard o Replica potrebbero non vedere i dati immediatamente, ma molto presto tutto sarà disponibile.
Metodi di integrazione
Ci sono 2 metodi di integrazione con Elastic:
- Attraverso il client nativo TCP. Il driver nativo sta lentamente scomparendo: non viene più supportato e ha una sintassi molto scomoda. Pertanto, lo utilizziamo praticamente poco e cerchiamo di abbandonarlo del tutto.
- Attraverso l'interfaccia HTTP, dove è possibile utilizzare sia richieste JSON che la sintassi Lucene. Quest'ultima è un motore di testo utilizzato da Elastic. In questa modalità, otteniamo la possibilità di Batch tramite richieste JSON su HTTP. Questo è il metodo che cerchiamo di utilizzare.
Grazie all'interfaccia HTTP, possiamo utilizzare librerie che offrono un'implementazione asincrona del client HTTP. Possiamo sfruttare il vantaggio del Batch e dell'API asincrona, il che ci fornisce elevate prestazioni, molto utili durante i giorni di grandi promozioni (di questo parleremo più avanti).
Alcuni numeri per il confronto:
- Salvataggio degli utenti premiati in Postgres con 20 thread senza raggruppamenti: 460713 registrazioni in 42 secondi.
- Elastic + client reattivo su 10 thread + batch di 1000 elementi: 596749 registrazioni in 11 secondi.
- Elastic + client reattivo su 10 thread + batch di 1000 elementi: 23801684 registrazioni in 4 minuti.
Recentemente abbiamo sviluppato un gestore di richieste HTTP che costruisce JSON, sia in modalità Batch che non, e lo invia tramite qualsiasi client HTTP, indipendentemente dalla libreria. È possibile scegliere anche di inviare le richieste in modo sincrono o asincrono.
In alcune integrazioni utilizziamo ancora il client transport ufficiale, ma si tratta solo di un tema di prossima revisione. Tuttavia, per l'elaborazione utilizziamo un client proprietario basato su Spring WebClient.
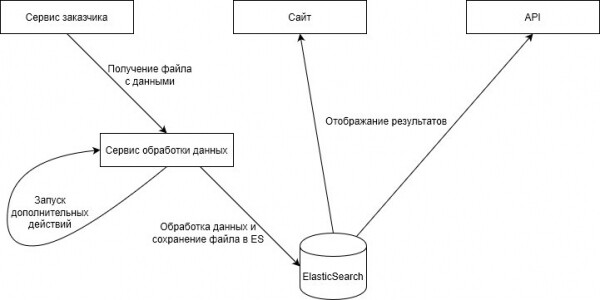
Grande promozione
Una volta all'anno si tiene una grande promozione per gli utenti: è l'Highload, poiché in quel periodo lavoriamo con decine di milioni di utenti contemporaneamente.
Di solito i picchi di carico si verificano durante le festività, ma questa promozione è a un livello completamente diverso. Due anni fa, nel giorno della promozione, abbiamo venduto 27.580.890 articoli. I dati sono stati elaborati per oltre mezz'ora, il che ha causato disagi agli utenti. Gli utenti hanno ricevuto premi per la partecipazione, ma è diventato chiaro che il processo doveva essere accelerato.
All'inizio del 2019, abbiamo deciso che avevamo bisogno di ElasticSearch. Per un intero anno, abbiamo organizzato l'elaborazione dei dati ricevuti in Elastic e la loro fornitura all'API dell'app mobile e del sito web. Di conseguenza, l'anno successivo, durante una promozione, abbiamo elaborato 15.131.783 record in 6 minuti.
Poiché abbiamo molti interessati a comprare beni e partecipare a estrazioni di premi durante le promozioni, questa è una misura temporanea. Attualmente inviamo informazioni aggiornate a Elastic, ma in futuro prevediamo di trasferire le informazioni archiviate dei mesi scorsi in Postgres come deposito permanente. Ciò per non saturare l'indice Elastic, che ha anch'esso le sue limitazioni.
Conclusioni/risultati
Attualmente abbiamo trasferito su Elastic tutti i servizi che volevamo e per ora abbiamo fatto una pausa. Adesso stiamo costruendo un indice in Elastic sopra il nostro principale deposito persistente in Postgres, che gestisce il carico degli utenti.
In futuro prevediamo di trasferire i servizi se capiamo che le richieste di dati diventano troppo variegate e vengono cercate su un numero illimitato di colonne. Questo è già un compito non adatto a Postgres.
Se avremo bisogno di una ricerca full-text nelle funzionalità o se ci saranno molti criteri di ricerca diversi, sappiamo già che sarà necessario tradurlo in Elastic.
⌘⌘⌘
Grazie per aver letto. Se nella tua azienda utilizzate anche ElasticSearch e avete casi d'uso specifici, fatecelo sapere. Saremmo interessati a sapere come lavorano gli altri 🙂
Fonte: habr.com
