

Qualunque grande progetto inizia con un paio di server. All'inizio c'era un server DB, poi sono stati aggiunti degli slave per scalare la lettura. E qui—stop! C'è un solo master e molti slave; se uno degli slave va via, va tutto bene, ma se va via il master—sarà un problema: downtime, gli admin in crisi devono ripristinare il server. Cosa fare? Riservare il master. Il mio collega Pavel ha già scritto di questo, , non lo ripeterò. Invece, vi racconterò perché avete assolutamente bisogno di un Orchestrator per MySQL!
Iniziamo con la domanda principale: «Come passeremo il codice su una nuova macchina in caso di malfunzionamento del master?»
- Lo schema con VIP (Virtual IP) mi piace di più, di questo parleremo più avanti. È il più semplice e ovvio, anche se ha un chiaro limite: il master che riserveremo deve trovarsi nello stesso segmento L2 della nuova macchina, quindi possiamo dimenticare il secondo DC. Inoltre, seguendo la regola che un grande L2 è un male, perché L2 è solo per il rack, mentre tra i rack c'è L3, e tale schema ha ancora più limitazioni.
- È possibile registrare nel codice il nome DNS e risolverlo tramite /etc/hosts. In realtà non ci sarà risoluzione. Il vantaggio di questo schema è che non ci sono limitazioni tipiche del primo metodo, quindi è possibile organizzare un cross-DC. Ma poi sorge la domanda ovvia: quanto velocemente porteremo la modifica in /etc/hosts tramite Puppet-Ansible.
- Il secondo metodo può essere leggermente modificato: su tutti i server web, installiamo un DNS cache, attraverso cui il codice accederà al master database. È possibile impostare un TTL di 60 per questa registrazione nel DNS. Sembra che, se implementato correttamente, sia un buon metodo.
- Schema di service discovery, che prevede l'uso di Consul e etcd.
- Un'opzione interessante con . È necessario instradare tutto il traffico MySQL attraverso ProxySQL, che sa automaticamente chi è attualmente il master. A proposito, si può leggere di una delle modalità di utilizzo di questo prodotto nel mio .
L'autore di Orchestrator, lavorando in Github, ha prima implementato il primo schema con VIP e poi lo ha modificato per un schema con Consul.
Schema tipico di infrastruttura:
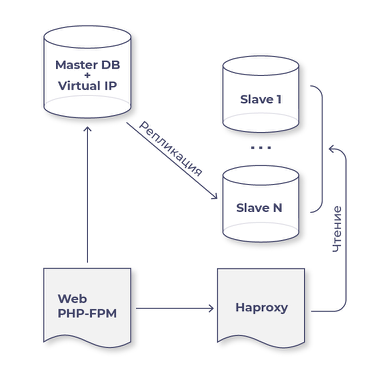
Descriviamo subito le situazioni ovvie che devono essere considerate:
- L'indirizzo VIP non deve essere registrato nella configurazione di nessuno dei server. Immaginiamo una situazione: il master si riavvia, e mentre si avvia, l'Orchestrator passa in modalità failover e rende uno dei slave il nuovo master; poi il vecchio master si riaccende, e ora il VIP è presente su entrambe le macchine. Questo è problematico.
- Per l'orchestratore sarà necessario scrivere uno script che interagisca con il vecchio master e il nuovo master. Sul vecchio è necessario eseguire ifdown, mentre sul nuovo master—ifup vip. Sarebbe utile includere nello script anche che in caso di failover, la porta sullo switch del vecchio master venga disattivata per evitare qualsiasi split-brain.
- Dopo che l'Orchestrator ha eseguito il vostro script per prima disattivare il VIP e/o spegnere la porta sullo switch, e poi invitato il nuovo master a eseguire lo script di attivazione del VIP, non dimenticate di usare il comando arping per avvisare tutti che il nuovo VIP ora è qui.
- Tutti gli slave devono avere read_only=1, e non appena promuovete uno slave a master, deve diventare read_only=0.
- Non dimenticate che qualsiasi slave può diventare master, selezionato per questo (Orchestrator ha un intero meccanismo di preferenze per determinare quale slave considerare prima come candidato a nuovo master, quale in secondo luogo e quale slave non dovrebbe mai essere scelto come master in nessuna circostanza). Se uno slave diventa master, rimarrà con il carico dello slave e si aggiungerà il carico del master, questo deve essere considerato.
Perché avete davvero bisogno di Orchestrator se non lo avete?
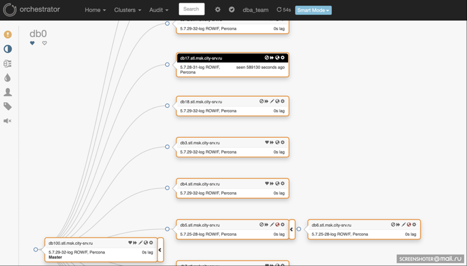
- Orchestrator ha un'interfaccia grafica molto comoda che mostra l'intera topologia (vedi screenshot qui sotto).
- Orchestrator può monitorare quali slave sono in ritardo e dove la replicazione è completamente rotta (abbiamo script per inviare SMS collegati a Orchestrator).
- Orchestrator ti informa su quali slave ci sono errori GTID erranti.
Interfaccia di Orchestrator:
Cos'è il GTID errante?
Ci sono due requisiti principali per l'operatività di Orchestrator:
- È necessario che su tutte le macchine del cluster MySQL sia abilitato il pseudo GTID, noi abbiamo abilitato il GTID.
- È necessario avere un unico tipo di binlog ovunque, si può usare statement. Avevamo una configurazione in cui sul master e sulla maggior parte degli slave era impostato Row, mentre su due è rimasto storicamente il modo Mixed. Di conseguenza, Orchestrator non ha voluto collegare questi slave al nuovo master.
Ricordate che la cosa più importante in uno slave di produzione è la sua coerenza con il master! Se sia sul master che nello slave è abilitato il Global Transaction ID (GTID), attraverso la funzione gtid_subset è possibile verificare se sulle macchine sono stati eseguiti gli stessi comandi di modifica dei dati. Puoi leggere di più su questo. .
Così, Orchestrator ti segnala tramite l'errore GTID errant che nello slave ci sono transazioni che non sono presenti sul master. Perché succede questo?
- Lo slave non ha abilitato read_only=1, qualcuno si è connesso ed ha eseguito una richiesta di modifica dei dati.
- Lo slave non ha abilitato super_read_only=1, quindi un admin, confondendo il server, è entrato ed ha eseguito la richiesta lì.
- Se hai considerato entrambi i punti precedenti, c'è un'altra astuzia: in MySQL, il comando di flush dei binlog viene anch'esso registrato nel binlog, quindi al primo flush sul master e su tutti i slave apparirà un GTID errante. Come evitarlo? Nella versione perona-5.7.25-28 è stata introdotta l'impostazione binlog_skip_flush_commands=1, che vieta di scrivere il flush nei binlog. Sul sito mysql.com è disponibile .
In sintesi, se non vuoi ancora utilizzare Orchestrator in modalità failover, impostalo in modalità monitoraggio. In questo modo avrai sempre davanti a te una mappa delle interazioni delle macchine MySQL e informazioni chiare sul tipo di replicazione presente su ciascuna macchina, se gli slave sono in ritardo e, soprattutto, quanto sono coerenti con il master!
La domanda è ovvia: «Come dovrebbe funzionare Orchestrator?». Dovrebbe selezionare un nuovo master tra gli attuali slave e poi ricollegare tutti gli slave ad esso (è proprio per questo che è necessario il GTID; se si utilizza il vecchio meccanismo con binlog_name e binlog_pos, il passaggio dello slave dall'attuale master al nuovo è semplicemente impossibile!). Prima che avessimo Orchestrator, una volta ho dovuto fare tutto questo manualmente. Il vecchio master si bloccava a causa di un controller Adaptec difettoso, e avevo circa 10 slave. Dovevo trasferire il VIP dal master a uno degli slave e ricollegare a esso tutti gli altri slave. Quante console ho dovuto aprire, quante comandi simultanei eseguire… Ho dovuto aspettare fino alle 3 di notte, alleggerire il carico da tutti gli slave, tranne due, rendere master la prima macchina di due, collegare subito la seconda macchina a essa, e poi ricollegare tutti gli altri slave al nuovo master e ripristinare il carico. In sintesi, un incubo...
Come funziona Orchestrator quando passa in modalità failover? È più facile mostrarlo con un esempio di situazione in cui vogliamo rendere master una macchina più potente e moderna rispetto a quella attuale.
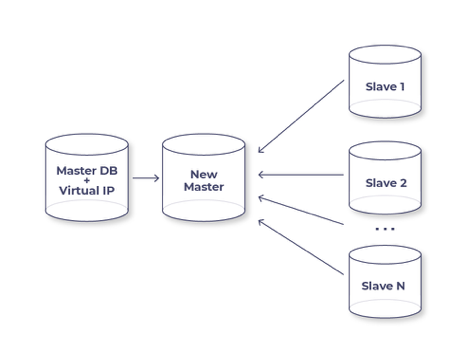
L'immagine mostra il cuore del processo. Cosa è stato fatto fino a questo momento? Abbiamo detto che vogliamo rendere un certo slave il nuovo master, e l'Orchestrator ha iniziato semplicemente a riconnettere tutti gli altri slave a lui, mentre il nuovo master funge da macchina di transito. Con questa configurazione non ci sono errori, tutti gli slave funzionano, l'Orchestrator rimuove il VIP dal vecchio master, lo trasferisce sul nuovo, imposta read_only=0 e dimentica il vecchio master. Fatto! Il downtime del nostro servizio è il tempo necessario per trasferire il VIP, che sono 2-3 secondi.
Questo è tutto per oggi, grazie a tutti. Presto ci sarà un secondo articolo su Orchestrator. In un famoso film sovietico "Garage", un personaggio ha detto: "Non ci andrei in esplorazione con lui!" Ebbene, Orchestrator, con te ci andrei in esplorazione!
Fonte: habr.com
