

Vi invitiamo a leggere la trascrizione della presentazione di Alexey Lesovskiy di Data Egret "Fondamenti del monitoraggio di PostgreSQL"
In questa presentazione, Alexey Lesovskiy discuterà i punti chiave delle statistiche di PostgreSQL, cosa significano e perché dovrebbero essere inclusi nel monitoraggio; quali grafici sono necessari nel monitoraggio, come aggiungerli e come interpretarli. La presentazione sarà utile per amministratori di database, amministratori di sistema e sviluppatori interessati alla risoluzione dei problemi di Postgres.


Mi chiamo Alexey Lesovskiy e rappresento l'azienda Data Egret.
Un po' di parole su di me. Ho iniziato tanto tempo fa come amministratore di sistema.
Ho gestito vari sistemi Linux, occupandomi di diverse attività legate a Linux, come virtualizzazione, monitoraggio, lavoro con proxy, ecc. Ma a un certo punto ho iniziato a concentrarmi di più sui database, in particolare su PostgreSQL, che mi è sempre piaciuto. Così, col tempo, sono diventato un DBA di PostgreSQL.
Nel corso della mia carriera, sono sempre stato interessato a temi come la statistica, il monitoraggio e la raccolta di telemetria. Quando ero amministratore di sistema, ho lavorato intensamente con Zabbix e ho scritto un piccolo insieme di script come . Era piuttosto popolare nel suo periodo. Con esso, era possibile monitorare molte cose importanti, non solo Linux, ma anche diversi altri componenti.
Attualmente mi occupo di PostgreSQL. Sto sviluppando un altro strumento che permette di lavorare con le statistiche di PostgreSQL. Si chiama (articolo su Habré — ).

Una breve introduzione. Quali situazioni possono presentarsi per i nostri clienti? Si verifica un malfunzionamento relativo al database. E quando il database è stato ripristinato, il capo del dipartimento o il project manager dice: «Amici, dovremmo monitorare il database, perché è successo qualcosa di brutto e dobbiamo evitare che accada di nuovo in futuro». Qui inizia un interessante processo di scelta del sistema di monitoraggio o di adattamento del sistema di monitoraggio esistente per monitorare il proprio database – PostgreSQL, MySQL o altri. E i colleghi iniziano a suggerire: «Ho sentito dire che esiste un certo database. Utilizziamolo». I colleghi iniziano a discutere tra loro. Alla fine, scegliamo un database, ma il monitoraggio di PostgreSQL è rappresentato in modo piuttosto scarso e dobbiamo sempre fare qualche aggiustamento. Prendiamo alcune repository da GitHub, le cloniamo, adattiamo gli script e facciamo delle impostazioni. Alla fine, questo si traduce in un certo lavoro manuale.

In questo documento cercherò di fornirvi alcune informazioni su come scegliere il monitoraggio non solo per PostgreSQL, ma anche per i database in generale. Voglio darvi le conoscenze necessarie per affinare il vostro monitoraggio, in modo da ottenere un reale beneficio, consentendovi di monitorare il vostro database in maniera utile e di avvisarvi in tempo di eventuali situazioni critiche che potrebbero presentarsi.
Le idee che presenterò in questo documento possono essere adattate direttamente a qualsiasi database, sia esso un DBMS tradizionale o un noSQL. Pertanto, ci sarà molto più di PostgreSQL, con molte ricette su come implementare queste idee in PostgreSQL. Vi fornirò esempi di query, esempi di entità che esistono in PostgreSQL per il monitoraggio. E se il vostro DBMS ha elementi simili che possono essere integrati nel monitoraggio, anche voi potrete adattarli e aggiungerli.
 Nel documento non tratterò
Nel documento non tratterò
come raccogliere e memorizzare le metriche. Non parlerò della post-elaborazione dei dati e della loro presentazione all'utente. E non dirò nulla sugli avvisi.
Durante la narrazione, mostrerò vari screenshot di monitoraggi esistenti e li criticherò. Tuttavia, cercherò di non nominare i marchi, in modo da non promuovere o denigrare quei prodotti. Pertanto, tutte le somiglianze sono casuali e rimangono nella vostra immaginazione.

Iniziamo a capire cosa sia il monitoraggio. Il monitoraggio è una cosa molto importante da avere. Tutti lo comprendono. Tuttavia, allo stesso tempo, il monitoraggio non è un prodotto di business e non influisce direttamente sul profitto dell'azienda, perciò viene sempre considerato come una priorità secondaria. Se abbiamo tempo, ci dedichiamo al monitoraggio, se non abbiamo tempo, va bene, lo mettiamo in backlog e un giorno torneremo su queste attività.
Pertanto, dalla nostra esperienza, quando ci rechiamo dai clienti, il monitoraggio è spesso carente e non presenta elementi interessanti che ci aiuterebbero a lavorare meglio con il database. Per questo motivo, il monitoraggio deve sempre essere perfezionato.
I database sono sistemi complessi che richiedono monitoraggio, poiché rappresentano un deposito di informazioni. Queste informazioni sono essenziali per un'azienda e non devono essere mai perse. Al tempo stesso, i database sono pezzi di software molto sofisticati, composti da numerosi componenti, molti dei quali necessitano di essere monitorati.
 Se parliamo specificamente di PostgreSQL, possiamo rappresentarlo come uno schema composto da tanti componenti che interagiscono tra loro. Allo stesso tempo, in PostgreSQL esiste una sottosistema chiamata Stats Collector, che consente di raccogliere statistiche sul funzionamento di questi sottosistemi e fornisce un'interfaccia all'amministratore o all'utente per visualizzare queste statistiche.
Se parliamo specificamente di PostgreSQL, possiamo rappresentarlo come uno schema composto da tanti componenti che interagiscono tra loro. Allo stesso tempo, in PostgreSQL esiste una sottosistema chiamata Stats Collector, che consente di raccogliere statistiche sul funzionamento di questi sottosistemi e fornisce un'interfaccia all'amministratore o all'utente per visualizzare queste statistiche.
Queste statistiche vengono presentate tramite un insieme di funzioni e viste (view), che possono essere considerate come tabelle. Pertanto, utilizzando un normale client psql, puoi collegarti al database, eseguire select su queste funzioni e viste e ottenere numeri specifici riguardanti il funzionamento dei sottosistemi di PostgreSQL.
Puoi aggiungere questi numeri al tuo sistema di monitoraggio preferito, tracciare grafici, aggiungere funzioni e ottenere analisi a lungo termine.
Tuttavia, in questa relazione non tratterò tutte queste funzioni, poiché ciò potrebbe richiedere un'intera giornata. Mi concentrerò su due, tre o quattro cose specifiche e spiegherò come possono migliorare il monitoraggio.

E parlando del monitoraggio del database, cosa bisogna monitorare? Innanzitutto, è fondamentale monitorare la disponibilità, poiché il database è un servizio che fornisce accesso ai dati ai clienti, e dobbiamo assicurarti che la disponibilità venga mantenuta, insieme ad alcune sue caratteristiche qualitative e quantitative.

Inoltre, è importante monitorare i clienti che si connettono al nostro database, poiché possono essere sia clienti normali che clienti dannosi in grado di compromettere il database. Anche la loro attività deve essere monitorata e tracciata.

Quando i clienti si connettono al database, è evidente che iniziano a lavorare con i nostri dati. Pertanto, dobbiamo monitorare anche come i clienti interagiscono con i dati: quali tabelle utilizzano e, in misura minore, quali indici. In altre parole, dobbiamo valutare il carico di lavoro (workload) generato dai nostri clienti.

Ma anche il workload è composto, ovviamente, da richieste. Le applicazioni si connettono al database e accedono ai dati tramite richieste, quindi è importante valutare quali richieste abbiamo nel database, monitorarne l'adeguatezza, assicurandoci che non siano scritte in modo errato, e che alcune opzioni necessitino di essere riscritte per garantire una maggiore velocità e prestazioni migliori.

E poiché parliamo di database, un database è sempre costituito da processi in background. I processi in background consentono di mantenere le prestazioni del database a un buon livello, quindi per funzionare richiedono una certa quantità di risorse. Allo stesso tempo, possono sovrapporsi alle risorse delle richieste dei clienti, quindi un'operazione troppo intensiva dei processi in background può influenzare direttamente le prestazioni delle richieste dei clienti. Pertanto, è necessario monitorarli e verificare che non ci siano squilibri riguardo ai processi in background.

E tutto ciò in termini di monitoraggio del database rimane nelle metriche di sistema. Ma considerando che gran parte della nostra infrastruttura si sposta nel cloud, le metriche di sistema di un host individuale passano sempre in secondo piano. Tuttavia, nei database rimangono comunque rilevanti, e il monitoraggio delle metriche di sistema è certamente necessario.

Con le metriche di sistema, in generale, tutto è abbastanza a posto; tutti i moderni sistemi di monitoraggio già supportano queste metriche, ma ci sono comunque alcune componenti che mancano e che devono essere aggiunte. Ne parlerò anche, ci saranno alcuni slide su di esse.

Il primo punto del piano è la disponibilità. Cosa significa disponibilità? Nel mio concetto, la disponibilità è la capacità di un database di gestire le connessioni, ovvero il database è attivo e accetta connessioni dai clienti come un servizio. Questa disponibilità può essere valutata tramite alcune caratteristiche. È molto utile visualizzare queste caratteristiche nei dashboard.

Tutti sanno cosa sono i dashboard. È quando dai un'occhiata a uno schermo su cui è sintetizzata l'informazione necessaria. E puoi subito capire se c'è un problema nel database o meno.
Pertanto, la disponibilità del database e altre caratteristiche chiave devono sempre essere visualizzate nei dashboard, affinché queste informazioni siano a portata di mano, sempre disponibili per te. Ulteriori dettagli, che aiutano nelle indagini sugli incidenti e sulle situazioni di emergenza, devono essere inseriti in dashboard secondari o nascosti in link drilldown che portano a sistemi di monitoraggio esterni.
Esempio di un noto sistema di monitoraggio. Si tratta di un sistema di monitoraggio davvero interessante. Raccoglie un'enorme quantità di dati, ma dal mio punto di vista, ha una concezione strana dei cruscotti. C'è un link per "creare un cruscotto". Ma quando crei un cruscotto, stai creando un elenco, composto da due colonne, un elenco di grafici. E quando devi controllare qualcosa, inizi a cliccare con il mouse, a scorrere, a cercare il grafico desiderato. E questo richiede tempo, cioè, non ci sono cruscotti veri e propri. Ci sono solo elenchi di grafici.

Cosa bisogna aggiungere a questi cruscotti? Puoi iniziare con una caratteristica come il tempo di risposta. In PostgreSQL c'è la vista pg_stat_statements. Di default è disabilitata, ma è una delle viste sistemiche più importanti che deve sempre essere attivata e utilizzata. Contiene informazioni su tutte le query eseguite che sono state effettuate nel database.
Pertanto, possiamo partire dall'idea di sommare il tempo totale di tutte le query e dividerlo per il numero di query utilizzando i campi di cui sopra. Ma è una temperatura media per tutta la situazione. Possiamo basarci su altri campi – il tempo minimo di esecuzione delle query, il massimo e la mediana. Possiamo persino costruire percentili, in PostgreSQL ci sono funzioni specifiche per questo. E possiamo ottenere alcune cifre che caratterizzano il tempo di risposta del nostro database in base alle query già eseguite, cioè non eseguiamo una query fittizia ‘select 1’ e controlliamo il tempo di risposta, ma analizziamo i tempi delle risposte delle query già eseguite e le rappresentiamo come un singolo numero o costruiamo un grafico basato su di esse.
È altrettanto importante tenere traccia del numero di errori attualmente generati dal sistema. Per fare ciò, possiamo utilizzare la vista pg_stat_database. Ci concentriamo sul campo xact_rollback. Questo campo non solo mostra il numero di rollback che si verificano nel database, ma tiene anche conto del numero di errori. In altre parole, possiamo visualizzare questo dato nel nostro dashboard e monitorare quanti errori abbiamo attualmente. Se ci sono molti errori, è un buon motivo per dare un'occhiata ai log e vedere quali sono questi errori e perché si verificano, e poi indagare e risolverli.

È possibile aggiungere un elemento come il Tachimetro. Questo misura il numero di transazioni al secondo e il numero di richieste al secondo. In altre parole, puoi utilizzare questi numeri come indicatore delle prestazioni attuali del tuo database e osservare se ci sono picchi nelle richieste, picchi nelle transazioni o, al contrario, se il database è sottoutilizzato a causa di qualche malfunzionamento nel backend. È importante monitorare sempre questo valore e tenere a mente che per il nostro progetto, questa è considerata una prestazione normale, mentre valori superiori o inferiori sono problematici e non chiari, il che implica la necessità di indagare il motivo di tali numeri.
Per valutare il numero di transazioni, possiamo nuovamente fare riferimento alla vista pg_stat_database. Possiamo sommare il numero di commit e il numero di rollback per ottenere il numero di transazioni al secondo.
Tutti capiscono che in una transazione possono rientrare più richieste, vero? Quindi TPS e QPS sono leggermente diversi.
Il numero di richieste al secondo può essere ottenuto tramite pg_stat_statements e semplicemente calcolando la somma di tutte le richieste eseguite. È chiaro che confrontiamo il valore attuale con quello precedente, sottraiamo e otteniamo la variazione, arrivando così al numero.

È possibile aggiungere ulteriori metriche a piacere, che aiutano anche a valutare la disponibilità del nostro database e a monitorare eventuali downtime.
Una di queste metriche è l'uptime. Ma l'uptime in PostgreSQL è una questione un po' complicata. Ecco perché. Quando PostgreSQL viene avviato, inizia a registrare l'uptime. Ma se in un certo momento, ad esempio, di notte viene eseguita un'operazione e l'OOM-killer termina forzatamente un processo figlio di PostgreSQL, in questo caso PostgreSQL chiude tutte le connessioni dei client, svuota la zona di memoria shardata e inizia il ripristino dall'ultimo checkpoint. E mentre dura questo ripristino dal checkpoint, il database non accetta connessioni, il che significa che questa situazione può essere considerata un downtime. Tuttavia, il contatore dell'uptime non si azzera, poiché tiene conto del tempo di avvio del postmaster fin dal primo momento. Pertanto, situazioni di questo tipo possono passare inosservate.
È importante monitorare il numero di worker del vacuum. Tutti sanno cos'è l'autovacuum in PostgreSQL? È un sistema secondario interessante in PostgreSQL. Sono stati scritti molti articoli su di essa, con molte presentazioni fatte. Ci sono stata molte discussioni sul vacuum e su come dovrebbe funzionare. Molti lo considerano un male necessario. Ma è così. È una sorta di equivalente di un garbage collector, che pulisce le versioni obsolete delle righe che non sono più necessarie per nessuna delle transazioni e liberano spazio nelle tabelle e negli indici per nuove righe.
Perché è necessario monitorarlo? Perché il vacuum a volte può causare problemi seri. Consuma molte risorse, e le richieste dei clienti iniziano a soffrirne.
Bisogna monitorarlo tramite la vista pg_stat_activity, di cui parlerò nel prossimo capitolo. Questa vista mostra l'attività corrente nel database. Attraverso quest'attività possiamo tracciare il numero di vacuums che stanno lavorando in questo momento. Possiamo tenere traccia dei vacuum e vedere che, se superiamo il limite, è un motivo per dare un'occhiata alle impostazioni di PostgreSQL e ottimizzare il funzionamento del vacuum.
Un'altra caratteristica di PostgreSQL è che soffre molto per le transazioni lunghe. In particolare, per le transazioni che rimangono in attesa senza eseguire alcuna operazione. Queste vengono chiamate stat idle-in-transaction. Una transazione di questo tipo trattiene i lock e interferisce con il funzionamento del vacuum. Di conseguenza, le tabelle crescono e aumentano di dimensione. Le query che lavorano su queste tabelle iniziano a rallentare perché bisogna scavare tutte le vecchie versioni delle righe dalla memoria al disco e viceversa. Pertanto, è importante monitorare il tempo e la durata delle transazioni più lunghe e delle query più lunghe del vacuum. Se osserviamo processi che stanno funzionando da molto tempo, già oltre 10-20-30 minuti per carichi OLTP, è necessario prestare attenzione e forzarne la chiusura, oppure ottimizzare l'applicazione affinché non vengano attivate e non rimangano in attesa per così tanto tempo. Per i carichi analitici, 10-20-30 minuti sono normali; ci possono essere anche tempi più lunghi.

Passiamo ora a una situazione con i clienti connessi. Una volta creato il dashboard e visualizzate le metriche chiave di disponibilità, possiamo anche aggiungere ulteriori informazioni sui clienti connessi.
Le informazioni sui clienti connessi sono importanti, perché, dal punto di vista di PostgreSQL, i clienti possono essere diversi. Ci sono clienti buoni e clienti cattivi.
Un esempio semplice. Con cliente intendo un'applicazione. L'applicazione si è connessa al database e inizia subito a inviare le sue richieste; il database le elabora e esegue, restituendo i risultati al cliente. Questi sono clienti buoni e corretti.
Ci sono situazioni in cui il cliente si è connesso, mantiene la connessione, ma nel frattempo non fa nulla. Si trova in uno stato di inattività.
Ma ci sono clienti problematici. Ad esempio, un cliente si connette, apre una transazione, fa qualcosa nel database e poi passa al codice, magari per accedere a una fonte esterna o per elaborare i dati ricevuti. Tuttavia, non chiude la transazione. Così, la transazione rimane aperta nel database, bloccando la riga. Questa è una situazione negativa. Se l'applicazione, per qualche motivo, si interrompe a causa di un'eccezione, la transazione potrebbe rimanere aperta per molto tempo. Questo influisce direttamente sulle prestazioni di PostgreSQL, rallentando il suo funzionamento. È quindi fondamentale monitorare questi clienti e terminare forzatamente la loro sessione quando necessario. È essenziale ottimizzare la propria applicazione per evitare tali situazioni.
Altri cattivi clienti sono quelli in attesa. Ma diventano cattivi a causa delle circostanze. Ad esempio, una semplice transazione in attesa: può aprire una transazione, prendere blocchi su alcune righe e poi cadere da qualche parte nel codice, lasciando una transazione appesa. Arriverà un altro cliente, richiederà gli stessi dati, ma si imbatterà in un blocco perché quella transazione appesa ha già bloccato alcune righe necessarie. E la seconda transazione rimarrà in attesa che la prima si concluda o venga forzatamente chiusa dall'amministratore. Così le transazioni in attesa possono accumularsi e riempire il limite di connessioni al database. Quando il limite è superato, l'applicazione non può più lavorare con il database. Questa è una situazione di emergenza per il progetto. Pertanto, è necessario monitorare i cattivi clienti e reagire tempestivamente.
Un altro esempio di monitoraggio. E qui c'è già un bel dashboard. Ci sono informazioni sulle connessioni in alto. Connessioni DB – 8 unità. Ecco tutto. Non abbiamo informazioni sui clienti attivi, né su quelli che sono semplicemente inattivi, senza fare nulla. Non ci sono informazioni sulle transazioni in sospeso e sulle connessioni in attesa, quindi è un dato che mostra solo il numero di connessioni e nulla più. Poi indovinate voi.

Per aggiungere queste informazioni al monitoraggio, è necessario fare riferimento alla vista pg_stat_activity. Se trascorri molto tempo in PostgreSQL, questa è una vista molto utile che dovrebbe diventare la tua alleata, poiché mostra l'attività attuale in PostgreSQL, ossia cosa sta succedendo. Ogni processo ha una propria riga che visualizza informazioni su di esso: da quale host è stata effettuata la connessione, quale utente ha effettuato l'accesso, con quale nome, quando è stata avviata la transazione, quale query sta attualmente eseguendo, e quale query è stata eseguita per ultima. Di conseguenza, possiamo valutare lo stato del client in base al campo stat. Possiamo, in un certo senso, raggruppare in base a questo campo e ottenere le statistiche attualmente presenti nel database e il numero di connessioni associate a queste statistiche. I numeri ottenuti possono quindi essere inviati al nostro monitoraggio e utilizzati per generare grafici.
È anche importante valutare la durata delle transazioni. Ho già accennato all'importanza di considerare la durata delle interruzioni, ma lo stesso vale per le transazioni. Ci sono i campi xact_start e query_start. Questi, per così dire, mostrano il momento di inizio della transazione e il momento di inizio della query. Usando la funzione now(), che mostra il timestamp corrente, sottraiamo il timestamp della transazione e della query. Così otteniamo la durata della transazione e la durata della query.
Se vediamo transazioni lunghe, dovremmo già completarle. Per carichi OLTP, le transazioni lunghe sono quelle che superano 1-2-3 minuti.. Per carichi OLAP, le transazioni lunghe sono normali, ma se superano le due ore, questo è anche un segnale che da qualche parte abbiamo uno sbilanciamento.

Quando i clienti si connettono al database, iniziano a lavorare con i nostri dati. Accedono alle tabelle e agli indici per ottenere dati dalla tabella. È importante valutare come i clienti interagiscono con questi dati.
Questo è necessario per valutare il nostro carico di lavoro e comprendere quali tabelle siano le più "calde". Ad esempio, questo è utile quando vogliamo posizionare le tabelle "calde" su un'archiviazione SSD veloce. D'altra parte, le tabelle archiviate che non utilizziamo da tempo possono essere spostate in un'archiviazione "fredda", su dischi SATA, e possono rimanere lì, con accesso solo quando necessario.
È anche utile per rilevare anomalie dopo vari rilasci e deployment. Ad esempio, un progetto potrebbe aver lanciato una nuova funzionalità. Se abbiamo aggiunto nuove funzionalità per lavorare con il database e costruiamo grafici sull'uso delle tabelle, possiamo facilmente individuare queste anomalie grazie ai grafici. Ad esempio, picchi di update o picchi di delete saranno chiaramente visibili.
È possibile anche rilevare anomali nella statistica "distorta". Cosa significa? PostgreSQL ha un pianificatore di query molto potente e ben progettato. Gli sviluppatori dedicano molto tempo al suo sviluppo. Come funziona? Per creare buoni piani, PostgreSQL raccoglie periodicamente statistiche sulla distribuzione dei dati nelle tabelle. Questi dati includono i valori più comuni: il numero di valori unici, informazioni sui NULL nella tabella e molte altre informazioni.
Basandosi su queste statistiche, il pianificatore crea diverse query, seleziona la più ottimale e utilizza questo piano di query per eseguire la query stessa e restituire i dati.
A volte le statistiche possono essere imprecise. Le informazioni sulla qualità e sulla quantità possono cambiare in una tabella, ma la statistica non viene aggiornata. I piani definiti potrebbero non essere ottimali. Se i nostri piani si rivelassero non ottimali in base al monitoraggio effettuato, potremmo notare queste anomalie. Ad esempio, dove i dati sono cambiati qualitativamente e insieme all'indice è iniziato a essere utilizzato un passaggio sequenziale nella tabella, ovvero, se la richiesta deve restituire solo 100 righe (c'è un limite di 100), per questa richiesta verrà eseguita una scansione completa. Questo influisce sempre negativamente sulle prestazioni.
E saremo in grado di vedere questo nel monitoraggio. Potremo quindi esaminare questa richiesta, eseguire un explain, raccogliere statistiche e costruire un nuovo indice aggiuntivo. E quindi reagire al problema. Per questo è importante.
Un altro esempio di monitoraggio. Penso che molti lo riconoscano, perché è molto popolare. Chi lo usa nei propri progetti ? А кто использует этот продукт совместно с Prometheus? Дело в том, что в стандартном репозитории этого мониторинга есть дашборд для работы с PostgreSQL – Prometheus. Ma c'è un aspetto negativo.
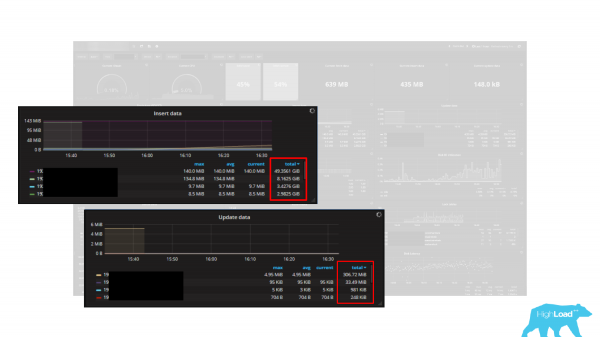
Ci sono diversi grafici, e come unità sono indicati i byte, cioè ci sono 5 grafici: Insert data, Update data, Delete data, Fetch data e Return data. Come unità di misura sono indicati i byte. Tuttavia, il problema è che la statistica in PostgreSQL restituisce dati in tuple (righe). Di conseguenza, questi grafici rappresentano un modo molto efficace per ridurre il vostro carico di lavoro di diverse volte, anche decine di volte, poiché una tuple non è un byte, ma è una riga, che è composta da molti byte e ha sempre una lunghezza variabile. Pertanto, calcolare il carico di lavoro in byte utilizzando le tuple è un compito irrealizzabile o molto complesso. Quindi, quando utilizzate il dashboard o il monitoraggio integrato, è sempre importante capire che funzionano correttamente e restituiscono dati valutati in modo preciso.

Come si ottiene la statistica su queste tabelle? A tal fine, PostgreSQL ha un certo numero di viste. E la vista principale è . User_tables – significa che le tabelle sono create per conto dell'utente. In contrapposizione, ci sono le viste di sistema, che vengono utilizzate da PostgreSQL stesso. E c'è una tabella riepilogativa Alltables, che include sia le tabelle di sistema che quelle degli utenti. Puoi partire da una delle due, quella che preferisci di più.
Sui campi sopra indicati è possibile valutare il numero di insert, update e delete. L'esempio di dashboard che ho utilizzato sfrutta proprio questi campi per valutare le caratteristiche del carico di lavoro. Pertanto, possiamo anche basarci su di essi. Ma è importante ricordare che si tratta di tuple, non di byte, quindi non possiamo semplicemente convertirli in byte.
Sulla base di questi dati, possiamo creare, così chiamate, tabelle TopN. Ad esempio, Top-5, Top-10. E possiamo monitorare quelle tabelle più attive, quelle che vengono utilizzate di più. Ad esempio, le 5 tabelle ‘calde’ per le inserzioni. E su queste tabelle TopN valutiamo il nostro carico di lavoro e possiamo monitorare i picchi di carico di lavoro dopo vari rilasci, aggiornamenti e deployment.
È anche importante valutare le dimensioni della tabella, perché a volte gli sviluppatori rilasciano una nuova funzione e le nostre tabelle iniziano ad aumentare considerevolmente, poiché decidono di aggiungere ulteriore volume di dati, senza prevedere come questo influenzerà le dimensioni del database. Anche questi casi ci prendono di sorpresa.

E ora una piccola domanda per voi. Qual è la domanda che sorge quando notate un carico sul server con il database? Qual è la successiva domanda che vi viene in mente?

Ma in realtà la domanda successiva è: quali sono le query che causano il carico? Cioè, non è interessante osservare i processi che provocano il carico. È chiaro che se hostiamo un database, lì ci sarà in esecuzione un database e solo il database verrà utilizzato. Se apriamo Top, vedremo un elenco di processi in PostgreSQL che stanno eseguendo delle operazioni. Da Top non sarà chiaro cosa stanno facendo.

Pertanto, è importante identificare le query che generano il maggior carico, poiché l'ottimizzazione delle query di solito offre un beneficio maggiore rispetto all'ottimizzazione della configurazione di PostgreSQL, del sistema operativo o addirittura dell'hardware. A mio avviso, si tratta di circa l'80-85-90%. E questo può essere fatto molto più rapidamente. È più veloce correggere una query piuttosto che risistemare la configurazione, pianificare un riavvio, soprattutto se non è possibile riavviare il database o aggiungere hardware. È più semplice riscrivere una query o aggiungere un indice per ottenere un risultato migliore da quella query.
Di conseguenza, è necessario monitorare le query e la loro adeguatezza. Prendiamo un altro esempio di monitoraggio. Anche qui sembra esserci un monitoraggio eccellente. Ci sono informazioni sulla replicazione, sulla capacità di throughput, sui lock e sull'utilizzo delle risorse. Tutto sembra perfetto, ma mancano informazioni sulle query. Non è chiaro quali query vengano eseguite nel nostro database, quanto tempo impiegano e quante sono. Abbiamo sempre bisogno di avere queste informazioni nel monitoraggio.

Possiamo utilizzare il modulo pg_stat_statements per ottenere queste informazioni. Da questo si possono costruire vari grafici. Ad esempio, è possibile ottenere informazioni sulle query più frequenti, cioè su quelle eseguite più spesso. Sì, dopo i deployment è anche molto utile guardarlo e capire se ci sono picchi di richieste.
È possibile monitorare le query più lunghe, cioè quelle che richiedono più tempo per essere eseguite. Esse utilizzano la CPU e consumano operazioni di input/output. Possiamo valutarle anche tramite i campi total_time, mean_time, blk_write_time e blk_read_time.
Possiamo valutare e monitorare le query più pesanti in termini di utilizzo delle risorse, quelle che leggono dal disco, che utilizzano la memoria o, al contrario, creano un carico di scrittura.
Possiamo valutare le query più gravose. Queste sono quelle query che restituiscono un numero elevato di righe. Ad esempio, può trattarsi di una query in cui si è dimenticato di impostare un limite. Essa restituirà semplicemente tutto il contenuto della tabella o della query sulle tabelle richieste.
Si può anche monitorare le query che utilizzano file temporanei o tabelle temporanee.

E abbiamo anche processi in background. I processi in background sono innanzitutto i checkpoint, o come vengono anche chiamati, i punti di controllo, l'autovacuum e la replica.
Un altro esempio di monitoraggio. A sinistra c'è la scheda Manutenzione, ci spostiamo su di essa e speriamo di vedere qualcosa di utile. Ma qui ci sono solo i dati sul tempo di funzionamento del vacuum e sulla raccolta delle statistiche, nient'altro. Queste sono informazioni molto scarne, quindi è sempre necessario avere informazioni su come funzionano i processi in background nel nostro database e se ci sono problemi legati al loro funzionamento.

Quando consideriamo i punti di controllo, dobbiamo ricordare che i punti di controllo scaricano le pagine "sporche" dalla memoria shardata su disco, quindi creano un checkpoint. E questo checkpoint può essere utilizzato come un punto di riferimento per il ripristino, nel caso in cui PostgreSQL venga chiuso in modo imprevisto.
Pertanto, per scrivere tutte le pagine "sporche" su disco, è necessario eseguire un certo volume di scrittura. E, di regola, nei sistemi con grande capacità di memoria, si tratta di un'importante quantità. Se i nostri checkpoint vengono effettuati molto frequentemente in un intervallo di tempo breve, le prestazioni del disco subiranno notevolmente. E le richieste dei clienti soffriranno per la mancanza di risorse. Combatteranno per le risorse e mancheranno di prestazioni.
Di conseguenza, attraverso pg_stat_bgwriter, possiamo monitorare il numero di checkpoint che si verificano in base ai campi specificati. E se in un certo intervallo di tempo (10-15-20 minuti, mezz'ora) ci sono molti checkpoint, per esempio, 3-4-5, questo può già essere un problema. È necessario esaminare il database, controllare la configurazione per capire cosa causa tale abbondanza di checkpoint. Potrebbe essere che si stia effettuando una grande scrittura. Possiamo valutare il carico di lavoro, poiché abbiamo già aggiunto i grafici del carico di lavoro. Possiamo già ottimizzare i parametri dei checkpoint e fare in modo che non influiscano troppo sulle prestazioni delle richieste.

Torno a parlare di autovacuum, perché è un aspetto che, come già detto, può influenzare notevolmente le prestazioni sia dei dischi che delle query. È quindi sempre importante valutare la quantità di autovacuum.
Il numero di worker autovacuum in un database è limitato. Di default ci sono tre worker; quindi, se abbiamo continuamente tre worker attivi nel database, significa che autovacuum è sottovuoto, è necessario aumentare i limiti, rivedere le impostazioni di autovacuum e accedere alla configurazione.
È importante valutare quali worker di vacuum sono attivi. Può essere che uno sia stato avviato manualmente da un DBA, creando quindi un carico aggiuntivo. Possiamo avere dei problemi. Oppure, ci sono i vacuum che registrano il conteggio delle transazioni. Per alcune versioni di PostgreSQL, questi vacuum possono essere molto pesanti. Possono influenzare notevolmente le prestazioni, poiché leggono l'intera tabella e scandagliano tutti i blocchi in essa.
E, naturalmente, la durata dei processi di vacuum. Se abbiamo vacuum prolungati che funzionano per molto tempo, significa che è nuovamente il momento di esaminare la configurazione del vacuum e forse rivederne le impostazioni. Perché potrebbe verificarsi una situazione in cui il vacuum lavora su una tabella per un lungo periodo (3-4 ore), ma durante il funzionamento del vacuum si accumulano di nuovo un grande volume di righe morte. E non appena il vacuum termina, deve nuovamente eseguire il vacuum su questa tabella. Ci troviamo quindi nella situazione di un vacuum infinito. In questo caso, il vacuum non riesce a svolgere il proprio lavoro e le tabelle iniziano gradualmente a gonfiarsi in dimensioni, anche se il volume di dati utili in esse rimane lo stesso. Pertanto, in caso di vacuum prolungati, monitoriamo sempre la configurazione e cerchiamo di ottimizzarla, ma senza compromettere le prestazioni delle richieste dei clienti.

Attualmente, praticamente non esistono installazioni di PostgreSQL senza la replica streaming. La replica è il processo di trasferimento dei dati dal master alla replica.
La replica in PostgreSQL è gestita attraverso il log delle transazioni. Il master genera il log delle transazioni. Il log viene trasmesso alla replica tramite la connessione di rete, dove viene poi riprodotto. È tutto molto semplice.
Pertanto, per monitorare il lag della replica si utilizza la vista pg_stat_replication. Tuttavia, non è tutto così semplice. Nella versione 10, la vista ha subito diverse modifiche. In primo luogo, alcuni campi sono stati rinominati. Inoltre, sono stati aggiunti nuovi campi. Nella versione 10 sono stati introdotti campi che permettono di valutare il lag della replica in secondi. Questo è molto comodo. Fino alla versione 10 era possibile valutare il lag della replica in byte. Questa opzione è rimasta anche nella versione 10, quindi è possibile scegliere se è più comodo valutare il lag in byte o in secondi. Molti utilizzano entrambe le modalità.
Tuttavia, per valutare il lag di replica, è necessario conoscere la posizione del log nella transazione. Queste posizioni del log delle transazioni sono presenti nella vista pg_stat_replication. In altre parole, possiamo utilizzare la funzione pg_xlog_location_diff() per prendere due punti nel log della transazione. Calcoliamo la differenza tra di essi e otteniamo il lag di replica in byte. È molto comodo e semplice.
Nella versione 10, questa funzione è stata rinominata in pg_wal_lsn_diff(). In generale, in tutte le funzioni, viste, utilità in cui appariva la parola "xlog", è stata sostituita con il termine "wal". Questo sia nelle viste che nelle funzioni. È una novità.
In aggiunta, nella versione 10 sono state introdotte righe che mostrano specificamente il lag. Si tratta di write lag, flush lag, replay lag. Cioè, queste metriche sono importanti da monitorare. Se vediamo che c'è un lag di replica, dobbiamo indagare sul motivo per cui è emerso, da dove deriva e risolvere il problema.

Con le metriche di sistema, praticamente tutto funziona correttamente. Quando inizia qualsiasi monitoraggio, parte dalle metriche di sistema. Questi includono l'utilizzo della CPU, della memoria, dello swap, della rete e del disco. Tuttavia, mancano di molti parametri per impostazione predefinita.
Se la gestione del processo è a posto, ci sono problemi con la gestione del disco. Di solito, gli sviluppatori degli strumenti di monitoraggio aggiungono informazioni sulla larghezza di banda. Queste possono essere in iops o byte. Ma dimenticano la latenza e l'utilizzo dei dispositivi di archiviazione. Questi sono parametri più importanti che consentono di valutare quanto siano occupati i dischi e quanto rallentano le operazioni. Se abbiamo un'alta latenza, significa che ci sono problemi con i dischi. Se abbiamo un'alta percentuale di utilizzo, significa che i dischi non riescono a gestire il carico. Queste sono caratteristiche di qualità superiore rispetto alla larghezza di banda.
Anche se queste statistiche possono essere ottenute dal filesystem /proc, come avviene per l'utilizzo della CPU. Non so perché questa informazione non venga aggiunta nei monitoraggi. Tuttavia, è importante includerla nel proprio monitoraggio.
Lo stesso vale per le interfacce di rete. Ci sono informazioni sulla larghezza di banda della rete in pacchetti e byte, ma non ci sono informazioni sulla latenza e sull'utilizzo, anche se queste sarebbero anch'esse utili.

Ogni monitoraggio ha i suoi difetti. Qualunque monitoraggio tu scelga, non soddisferà sempre determinati criteri. Tuttavia, si stanno sviluppando, vengono aggiunte nuove funzionalità, quindi scegli qualcosa e migliora.
E per migliorare, è sempre necessario avere una chiara comprensione di cosa significhi la statistica fornita e come questa possa essere utilizzata per risolvere i problemi.
Ecco alcuni punti chiave:
- È sempre necessario monitorare la disponibilità, avere dashboard che ti permettano di valutare rapidamente che tutto vada bene con il database.
- È essenziale avere una comprensione di quali clienti interagiscano con il tuo database, per escludere quelli problematici.
- È importante valutare come questi clienti interagiscono con i dati. Devi avere consapevolezza del tuo carico di lavoro.
- È fondamentale monitorare come si forma questo carico di lavoro e quali richieste vengono effettuate. Puoi valutare le richieste, ottimizzarle, rifattorizzarle e costruire indici per esse. Questo è molto importante.
- I processi in background possono influire negativamente sulle richieste dei clienti, quindi è importante monitorarli per assicurarsi che non consumino troppe risorse.
- Le metriche di sistema ti consentono di pianificare la scalabilità e l'aumento della capacità dei tuoi server, quindi è importante monitorarle e valutarle.

Se sei interessato a questo argomento, puoi esplorare questi link.
— è la documentazione ufficiale dei collezionisti di statistiche. Qui trovi la descrizione di tutte le viste statistiche e di tutti i campi. Puoi leggerli, comprenderli e analizzarli, e basandoti su di essi costruire i tuoi grafici e integrarli nei tuoi monitoraggi.
Esempi di query:
Questo è il nostro repository aziendale e il mio personale. Contiene esempi di query. Non ci sono query del tipo select * from qualcosa. Ci sono già query pronte con join e funzioni interessanti che trasformano i dati grezzi in valori leggibili e utili, ad esempio, byte, tempo. Puoi esplorarli, guardarli, analizzarli, aggiungerli ai tuoi monitoraggi e costruire i tuoi monitoraggi su questa base.
Domande
Domanda: Hai detto che non promuoverai i marchi, ma sono comunque curioso: quali dashboard usi nei tuoi progetti?
Risposta: In vari modi. A volte andiamo dal cliente e lui ha già il proprio monitoraggio. E noi forniamo consulenza al cliente su cosa dovrebbe aggiungere al suo monitoraggio. La situazione peggiore riguarda Zabbiх. Perché non ha la possibilità di costruire grafici TopN. Noi usiamo , perché abbiamo fornito consulenze a questi ragazzi sul monitoraggio. Hanno realizzato un monitoraggio PostgreSQL basato sul nostro specifico. Sto scrivendo il mio pet-project, che raccoglie dati tramite Prometheus e li visualizza in . Ho l'obiettivo di creare il mio esportatore in Prometheus e poi visualizzare tutto in Grafana.
Domanda: Ci sono analoghi ai rapporti AWR o … aggregazioni? Ne siete a conoscenza?
Risposta: Sì, so cos'è l'AWR, è una cosa davvero utile. Attualmente ci sono diversi strumenti che implementano un modello simile. A intervalli di tempo regolari, vengono scritti dei baseline nello stesso PostgreSQL o in un'archivio separato. Si possono trovare su internet, ci sono. Uno degli sviluppatori di uno di questi strumenti è attivo nel forum sql.ru nella discussione su PostgreSQL. Lo si può contattare lì. Sì, esistono strumenti simili, possono essere utilizzati. Inoltre, nel proprio Anch'io sto scrivendo uno strumento che permette di fare la stessa cosa.
P.S.1 Se usi postgres_exporter, quale dashboard stai utilizzando? Ce ne sono diverse. Sono già obsolete. Forse la comunità potrebbe creare un modello aggiornato?
P.S.2 Ho rimosso pganalyze, poiché è un'offerta SaaS proprietaria che si concentra sul monitoraggio delle performance e sulle suggerimenti automatizzati per la messa a punto.
Solo gli utenti registrati possono partecipare al sondaggio. , per favore.
Quale monitoraggio self-hosted per PostgreSQL (con dashboard) consideri il migliore?
30,0%Zabbix + plugin di Alexey Lesovsky oppure zabbix 4.4 o libzbxpgsql + zabbix libzbxpgsql + zabbix3
0,0%https://github.com/lesovsky/pgcenter0
0,0%https://github.com/pg-monz/pg_monz0
20,0%https://github.com/cybertec-postgresql/pgwatch22
20,0%https://github.com/postgrespro/mamonsu2
0,0%https://www.percona.com/doc/percona-monitoring-and-management/conf-postgres.html0
10,0%pganalyze è un SaaS proprietario — non posso eliminarlo1
10,0%https://github.com/powa-team/powa1
0,0%https://github.com/darold/pgbadger0
0,0%https://github.com/darold/pgcluu0
0,0%https://github.com/zalando/PGObserver0
10,0%https://github.com/spotify/postgresql-metrics1
Hanno votato 10 utenti. 26 utenti si sono astenuti.
Fonte: habr.com
