

Ciao a tutti. Prima delle seconde festività di maggio, condividiamo con voi un materiale che abbiamo tradotto in vista del lancio di un nuovo flusso per il corso. .

Gli sviluppatori di applicazioni dedicano molto tempo a confrontare diversi database operativi per scegliere quello più adatto al carico di lavoro previsto. Le esigenze possono includere la semplificazione della modellazione dei dati, garanzie transazionali, performance in lettura/scrittura, scalabilità orizzontale e resilienza. Tradizionalmente, la selezione inizia dalla categoria del database, SQL o NoSQL, poiché ciascuna categoria offre un chiaro insieme di compromessi. Alte prestazioni in termini di bassa latenza e elevata capacità di elaborazione sono generalmente considerate requisiti non negoziabili, e pertanto sono necessarie per ogni database selezionato.
L'obiettivo di questo articolo è assistere gli sviluppatori di applicazioni nella scelta giusta tra SQL e NoSQL nel contesto della modellazione dei dati delle applicazioni. Esamineremo un database SQL, ovvero PostgreSQL, e due database NoSQL – Cassandra e MongoDB – per parlare delle fondamenta del design dei database, come la creazione di tabelle, il loro popolamento, la lettura dei dati dalle tabelle e la loro eliminazione. Nell'articolo successivo, tratteremo sicuramente indici, transazioni, JOIN, direttive TTL e progettazione di database basati su JSON.
Qual è la differenza tra SQL e NoSQL?
I database SQL aumentano la flessibilità delle applicazioni grazie alle garanzie transazionali ACID e alla loro capacità di interrogare dati tramite JOIN in modi inaspettati sopra i modelli normalizzati esistenti dei database relazionali.
Considerando la loro architettura monolitica/single-node e l'uso del modello di replica master-slave per la ridondanza, i tradizionali database SQL mancano di due caratteristiche importanti: scalabilità lineare in scrittura (ovvero partizionamento automatico su più nodi) e perdita automatica/zero di dati. Ciò significa che il volume dei dati ricevuti non può superare la massima capacità di registrazione di un singolo nodo. Inoltre, una certa perdita temporanea di dati deve essere considerata nella tolleranza ai guasti (in architetture senza partizionamento delle risorse). È importante tenere presente che le ultime commit potrebbero non essere ancora riflesse nella copia secondaria (slave). Gli aggiornamenti senza inattività sono anche difficili da ottenere nei database SQL.
Le database NoSQL sono tipicamente distribuite per natura, il che significa che i dati vengono suddivisi in sezioni e distribuiti su più nodi. Queste richiedono denormalizzazione. Ciò implica che i dati inseriti devono essere copiati più volte per rispondere a specifiche query che invii. L'obiettivo principale è ottenere alte prestazioni riducendo il numero di shard disponibili durante la lettura. Da questo si deduce che NoSQL richiede di modellare le tue query, mentre SQL richiede di modellare i tuoi dati.
NoSQL si concentra sul raggiungimento di elevate prestazioni in un cluster distribuito, e questo rappresenta la base di molti compromessi nel design delle basi di dati, che includono la perdita di transazioni ACID, le JOIN e gli indici secondari globali coerenti.
Esiste l'opinione che, sebbene le database NoSQL offrano scalabilità lineare nella scrittura e alta disponibilità, la perdita di garanzie transazionali le renda inadeguate per i dati critici.
La tabella seguente mostra come la modellazione dei dati in NoSQL differisca da SQL.
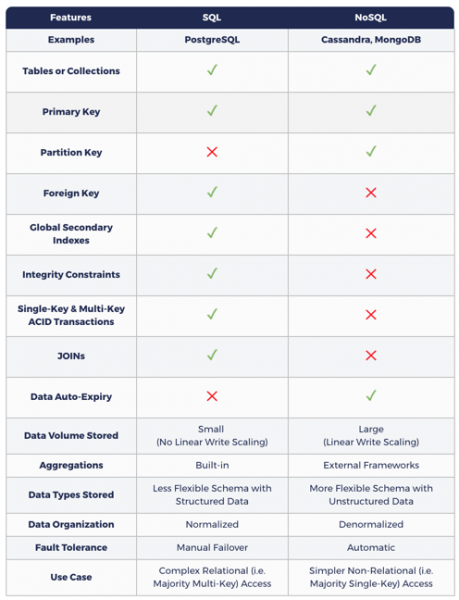
SQL e NoSQL: perché entrambe sono necessarie?
Applicazioni reali con un grande numero di utenti, come Amazon.com, Netflix, Uber e Airbnb, devono gestire complesse attività eterogenee. Ad esempio, un'app di e-commerce simile a Amazon.com deve archiviare dati leggeri e altamente critici, come informazioni su utenti, prodotti, ordini e fatture, insieme a dati più ingombranti ma meno sensibili, come recensioni di prodotti, messaggi del servizio clienti, attività degli utenti, feedback e raccomandazioni. Naturalmente, queste applicazioni si affidano ad almeno un database SQL insieme a almeno un database NoSQL. Nelle federazioni e nei sistemi globali, un database NoSQL funge da cache geodistribuita per i dati memorizzati in una sorgente attendibile, un database SQL operante in un singolo regione.
Come YugaByte DB coniuga SQL e NoSQL?
Costruita su un motore ibrido orientato ai log per la memorizzazione, l'auto-sharding, la replica distribuita con consenso e le transazioni ACID (ispirata a Google Spanner), YugaByte DB è il primo database open source al mondo che è compatibile simultaneamente con NoSQL (Cassandra e Redis) e SQL (PostgreSQL). Come mostrato nella tabella sottostante, YCQL, l'API di YugaByte DB compatibile con Cassandra, introduce concetti di transazioni ACID a chiave singola e multipla e indici secondari globali nell'API NoSQL, aprendo così l'era dei database NoSQL transazionali. Inoltre, YCQL, l'API di YugaByte DB compatibile con PostgreSQL, introduce concetti di scalabilità lineare in scrittura e tolleranza agli errori automatica nell'API SQL, mostrando al mondo i database SQL distribuiti. Poiché il database YugaByte DB è intrinsecamente transazionale, l'API NoSQL può ora essere utilizzata nel contesto di dati critici.
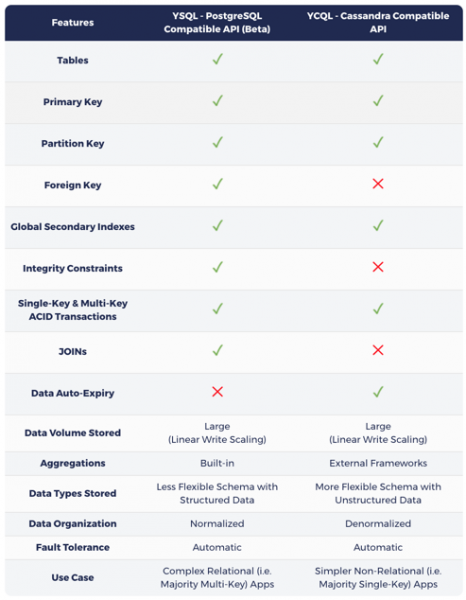
Come precedentemente menzionato nell'articolo , la scelta tra SQL e NoSQL in YugaByte DB dipende completamente dalle caratteristiche del carico di lavoro principale:
- Se il carico di lavoro principale consiste in operazioni multi-chiave con JOIN, quando scegli YSQL, devi considerare che le tue chiavi potrebbero essere distribuite su più nodi, il che porterà a una maggiore latenza e/o a una diminuzione della larghezza di banda rispetto a NoSQL.
- In caso contrario, scegli uno dei due API NoSQL, ricordando che otterrai migliori prestazioni grazie a query servite da un singolo nodo alla volta. YugaByte DB può fungere da unica base operativa per applicazioni complesse in tempo reale che necessitano di gestire più carichi di lavoro contemporaneamente.
Alla base del laboratorio di modellazione dei dati (Data modeling lab) nella sezione seguente ci sono le basi di dati YugaByte DB compatibili con PostgreSQL e Cassandra API, a differenza delle basi di dati originali. Questo approccio mette in risalto la semplicità di interazione con due API diverse (su due porte diverse) dello stesso cluster di database, rispetto all'uso di cluster completamente indipendenti di due database diversi.
Nelle sezioni seguenti esploreremo il laboratorio di modellazione dei dati per illustrare le differenze e alcune caratteristiche comuni dei database trattati.
Laboratorio di modellazione dei dati
Installazione dei database
Considerando l'accento sulla progettazione del modello dati (e non su architetture di distribuzione complesse), installeremo i database in contenitori Docker sul computer locale e poi interagirà con essi utilizzando le relative shell a riga di comando.
Compatibile con PostgreSQL & Cassandra, il database YugaByte DB
mkdir ~/yugabyte && cd ~/yugabyte
wget https://downloads.yugabyte.com/yb-docker-ctl && chmod +x yb-docker-ctl
docker pull yugabytedb/yugabyte
./yb-docker-ctl create --enable_postgresMongoDB
docker run --name my-mongo -d mongo:latestAccesso tramite linea di comando
Colleghiamoci ai database utilizzando la shell a riga di comando per le rispettive API.
PostgreSQL
è la shell a riga di comando per interagire con PostgreSQL. Per facilitare l'uso, YugaByte DB fornisce psql direttamente nella cartella bin.
docker exec -it yb-postgres-n1 /home/yugabyte/postgres/bin/psql -p 5433 -U postgresCassandra
— è una shell a riga di comando per interagire con Cassandra e i suoi database compatibili tramite CQL (Cassandra Query Language). Per facilitare l'uso, YugaByte DB è fornito con cqlsh nella directory bin.
Si noti che CQL è stato ispirato da SQL e ha concetti simili di tabelle, righe, colonne e indici. Tuttavia, come linguaggio NoSQL, aggiunge un insieme specifico di restrizioni, la maggior parte delle quali tratteremo in altri articoli.
docker exec -it yb-tserver-n1 /home/yugabyte/bin/cqlshMongoDB
è una shell a riga di comando per interagire con MongoDB. Può essere trovata nella directory bin dell'installazione di MongoDB.
docker exec -it my-mongo bash
cd bin
mongoCreazione della tabella
Ora possiamo interagire con il database per eseguire varie operazioni tramite la riga di comando. Cominciamo creando una tabella che memorizza informazioni sulle canzoni scritte da vari artisti. Queste canzoni possono essere parte di un album. Gli attributi facoltativi per una canzone comprendono l'anno di pubblicazione, il prezzo, il genere e il punteggio. Dobbiamo considerare ulteriori attributi che potrebbero essere necessari in futuro, attraverso il campo «tags». Questo può memorizzare dati semi-strutturati sotto forma di coppie chiave-valore.
PostgreSQL
CREATE TABLE Music (
Artist VARCHAR(20) NOT NULL,
SongTitle VARCHAR(30) NOT NULL,
AlbumTitle VARCHAR(25),
Year INT,
Price FLOAT,
Genre VARCHAR(10),
CriticRating FLOAT,
Tags TEXT,
PRIMARY KEY(Artist, SongTitle)
); Cassandra
La creazione di una tabella in Cassandra è molto simile a quella in PostgreSQL. Una delle principali differenze è l'assenza di vincoli di integrità (ad esempio, NOT NULL), ma questo è di competenza dell'applicazione e non del database NoSQL.. La chiave primaria è composta dalla chiave di partizione (colonna Artist nell'esempio seguente) e da un insieme di colonne di clustering (colonna SongTitle nell'esempio seguente). La chiave di partizione determina in quale partizione/shard deve essere inserita la riga, mentre le colonne di clustering indicano come devono essere organizzati i dati all'interno dell'attuale shard.
CREATE KEYSPACE myapp;
USE myapp;
CREATE TABLE Music (
Artist TEXT,
SongTitle TEXT,
AlbumTitle TEXT,
Year INT,
Price FLOAT,
Genre TEXT,
CriticRating FLOAT,
Tags TEXT,
PRIMARY KEY(Artist, SongTitle)
);MongoDB
MongoDB organizza i dati in database (Database) (analogo al Keyspace in Cassandra), dove ci sono collezioni (Collections) (analogo alle tabelle), che contengono documenti (Documents) (analogo alle righe in una tabella). In MongoDB non è generalmente necessario definire uno schema iniziale. Comando «use database», mostrata di seguito, crea un'istanza del database al primo utilizzo e cambia il contesto per il nuovo database creato. Non è necessario creare esplicitamente le collezioni, vengono create automaticamente semplicemente aggiungendo il primo documento a una nuova collezione. Si noti che MongoDB utilizza per impostazione predefinita un database di test, quindi qualsiasi operazione a livello di collezione senza specificare un database specifico verrà eseguita su di esso per impostazione predefinita.
use myNewDatabase;Recupero informazioni sulla tabella
PostgreSQL
d Music
Table "public.music"
Column | Type | Collation | Nullable | Default
--------------+-----------------------+-----------+----------+--------
artist | character varying(20) | | not null |
songtitle | character varying(30) | | not null |
albumtitle | character varying(25) | | |
year | integer | | |
price | double precision | | |
genre | character varying(10) | | |
criticrating | double precision | | |
tags | text | | |
Indexes:
"music_pkey" PRIMARY KEY, btree (artist, songtitle)Cassandra
DESCRIBE TABLE MUSIC;
CREATE TABLE myapp.music (
artist text,
songtitle text,
albumtitle text,
year int,
price float,
genre text,
tags text,
PRIMARY KEY (artist, songtitle)
) WITH CLUSTERING ORDER BY (songtitle ASC)
AND default_time_to_live = 0
AND transactions = {'enabled': 'false'};MongoDB
use myNewDatabase;
show collections;Inserimento dei dati nella tabella
PostgreSQL
INSERT INTO Music
(Artist, SongTitle, AlbumTitle,
Year, Price, Genre, CriticRating,
Tags)
VALUES(
'No One You Know', 'Call Me Today', 'Somewhat Famous',
2015, 2.14, 'Country', 7.8,
'{"Composers": ["Smith", "Jones", "Davis"],"LengthInSeconds": 214}'
);
INSERT INTO Music
(Artist, SongTitle, AlbumTitle,
Price, Genre, CriticRating)
VALUES(
'No One You Know', 'My Dog Spot', 'Hey Now',
1.98, 'Country', 8.4
);
INSERT INTO Music
(Artist, SongTitle, AlbumTitle,
Price, Genre)
VALUES(
'The Acme Band', 'Look Out, World', 'The Buck Starts Here',
0.99, 'Rock'
);
INSERT INTO Music
(Artist, SongTitle, AlbumTitle,
Price, Genre,
Tags)
VALUES(
'The Acme Band', 'Still In Love', 'The Buck Starts Here',
2.47, 'Rock',
'{"radioStationsPlaying": ["KHCR", "KBQX", "WTNR", "WJJH"], "tourDates": { "Seattle": "20150625", "Cleveland": "20150630"}, "rotation": Heavy}'
);Cassandra
In generale, l'espressione INSERT in Cassandra appare molto simile all'analogo in PostgreSQL. Tuttavia, c'è una grande differenza nella semantica. In Cassandra INSERT è in effetti un'operazione UPSERT, dove vengono aggiunti gli ultimi valori nella riga, nel caso in cui la riga esista già.
L'inserimento dei dati avviene in modo simile a PostgreSQL
INSERTin precedenza
.
MongoDB
Nonostante MongoDB sia un database NoSQL, simile a Cassandra, la sua operazione di inserimento dei dati non ha nulla a che fare con il comportamento semantico in Cassandra. In MongoDB non ha funzionalità UPSERT, rendendolo simile a PostgreSQL. L'aggiunta di dati avviene per impostazione predefinita senza _idspecified porterà all'aggiunta di un nuovo documento nella collezione.
db.music.insert( {
artista: "No One You Know",
titoloCanzone: "Call Me Today",
titoloAlbum: "Somewhat Famous",
anno: 2015,
prezzo: 2.14,
genere: "Country",
tag: {
Compositori: ["Smith", "Jones", "Davis"],
DurataInSecondi: 214
}
}
);
db.music.insert( {
artista: "No One You Know",
titoloCanzone: "My Dog Spot",
titoloAlbum: "Hey Now",
prezzo: 1.98,
genere: "Country",
valutazioneCritica: 8.4
}
);
db.music.insert( {
artista: "The Acme Band",
titoloCanzone: "Look Out, World",
titoloAlbum:"The Buck Starts Here",
prezzo: 0.99,
genere: "Rock"
}
);
db.music.insert( {
artista: "The Acme Band",
titoloCanzone: "Still In Love",
titoloAlbum:"The Buck Starts Here",
prezzo: 2.47,
genere: "Rock",
tag: {
stazioniRadioInRiproduzione:["KHCR", "KBQX", "WTNR", "WJJH"],
dateTour: {
Seattle: "20150625",
Cleveland: "20150630"
},
rotazione: "Heavy"
}
}
);
Richiesta tabella
La differenza più significativa tra SQL e NoSQL in termini di scrittura delle query risiede nell'uso delle formulazioni DA e DOVE. SQL consente di selezionare più tabelle dopo l'espressione DA , e l'espressione con DOVE può essere di qualsiasi complessità (incluse operazioni JOIN tra le tabelle). Tuttavia, NoSQL tende a imporre un rigido vincolo su DA, e lavora solo con una tabella specificata, mentre in DOVE, deve sempre essere specificata la chiave primaria. Questo è dovuto alla ricerca di migliorare le prestazioni di NoSQL, di cui abbiamo parlato in precedenza. Questa ricerca porta a ridurre al minimo qualsiasi interazione tra tabelle e chiavi. Ciò può causare un'alta latenza nella comunicazione inter-nodi durante la risposta a una query e, pertanto, è meglio evitarlo in linea di principio. Ad esempio, Cassandra richiede che le query siano limitate a determinati operatori (sono consentiti solo =, IN, , =>, <=) sulle chiavi delle partizioni, salvo nel caso di query su indici secondari (qui è consentito solo l'operatore =).
PostgreSQL
Di seguito sono riportati tre esempi di query che possono essere facilmente eseguite da un database SQL.
- Elenca tutte le canzoni dell'artista;
- Elenca tutte le canzoni dell'artista che corrispondono alla prima parte del titolo;
- Elenca tutte le canzoni dell'artista che contengono una certa parola nel titolo e hanno un prezzo inferiore a 1,00.
SELECT * FROM Music
WHERE Artist='No One You Know';
SELECT * FROM Music
WHERE Artist='No One You Know' AND SongTitle LIKE 'Call%';
SELECT * FROM Music
WHERE Artist='No One You Know' AND SongTitle LIKE '%Today%'
AND Price < 1.00;Cassandra
Tra le query sopra elencate, solo la prima funzionerà in Cassandra senza modifiche, poiché l'operatore LIKE non può essere applicato a colonne di clustering, come SongTitle. In questo caso, sono consentiti solo operatori = e IN.
SELECT * FROM Music
WHERE Artist='No One You Know';
SELECT * FROM Music
WHERE Artist='No One You Know' AND SongTitle IN ('Call Me Today', 'My Dog Spot')
AND Price < 1.00;MongoDB
Come mostrato negli esempi precedenti, il metodo principale per creare query in MongoDB è . Questo metodo contiene esplicitamente il nome della collezione (music nell'esempio seguente), quindi sono vietate le query su più collezioni.
db.music.find( {
artist: "No One You Know"
}
);
db.music.find( {
artist: "No One You Know",
songTitle: /Call/
}
);Leggi tutte le righe della tabella
La lettura di tutte le righe è semplicemente una particolare istanza del modello di query che abbiamo esaminato in precedenza.
PostgreSQL
SELECT *
FROM Music;Cassandra
Analogamente all'esempio in PostgreSQL sopra.
MongoDB
db.music.find( {} );Modifica dei dati nella tabella
PostgreSQL
PostgreSQL fornisce l'istruzione UPDATE per modificare i dati. Non ha funzionalità UPSERT, quindi l'esecuzione di questa istruzione genererà un errore se le righe non sono più presenti nel database.
UPDATE Music
SET Genre = 'Disco'
WHERE Artist = 'The Acme Band' AND SongTitle = 'Still In Love';Cassandra
In Cassandra c'è UPDATE un analogo di PostgreSQL. UPDATE ha la stessa semantica UPSERT, simile a INSERT.
Analogamente all'esempio in PostgreSQL sopra.
MongoDB
Operazione in MongoDB può aggiornare completamente un documento esistente oppure aggiornare solo determinati campi. Per impostazione predefinita aggiorna solo un documento disabilitando la semantica UPSERT. L'aggiornamento di più documenti e il comportamento simile UPSERT può essere attivato impostando opzioni aggiuntive per l'operazione. Come nel seguente esempio, viene aggiornato il genere di un particolare artista per la sua canzone.
db.music.update(
{"artist": "The Acme Band"},
{
$set: {
"genre": "Disco"
}
},
{"multi": true, "upsert": true}
);Eliminazione dei dati dalla tabella
PostgreSQL
DELETE FROM Music
WHERE Artist = 'The Acme Band' AND SongTitle = 'Look Out, World';Cassandra
Analogamente all'esempio in PostgreSQL sopra.
MongoDB
In MongoDB ci sono due tipi di operazioni per la rimozione dei documenti — e . Entrambi i tipi rimuovono documenti, ma restituiscono risultati diversi.
db.music.deleteMany( {
artist: "The Acme Band"
}
);
Eliminazione della tabella
PostgreSQL
DROP TABLE Music;Cassandra
Analogamente all'esempio in PostgreSQL sopra.
MongoDB
db.music.drop();Conclusione
Le controversie sulla scelta tra SQL e NoSQL infuriano da oltre 10 anni. Ci sono due aspetti principali di questo dibattito: l'architettura del database (SQL monolitico e transazionale contro NoSQL distribuito e non transazionale) e l'approccio alla progettazione del database (modellazione dei dati in SQL contro modellazione delle tue query in NoSQL).
Con un database transazionale distribuito come YugaByte DB, il dibattito sull'architettura del database può essere facilmente risolto. Man mano che i volumi di dati superano ciò che può essere registrato in un singolo nodo, un'architettura completamente distribuita che supporta una scalabilità lineare della scrittura con sharding/rebilanciamento automatico diventa necessaria.
Oltre a quanto detto in uno degli articoli , le architetture transazionali e strettamente definite sono ora più ampiamente utilizzate per garantire una maggiore flessibilità nello sviluppo rispetto a quelle non transazionali, alla fine definite.
Tornando alla discussione sulla progettazione delle basi di dati, è giusto dire che entrambi gli approcci alla progettazione (SQL e NoSQL) sono necessari per qualsiasi applicazione complessa del mondo reale. L'approccio SQL di "modellazione dei dati" consente agli sviluppatori di soddisfare più facilmente le mutevoli esigenze aziendali, mentre l'approccio NoSQL di "modellazione delle query" consente agli stessi sviluppatori di gestire grandi volumi di dati con bassa latenza e alta capacità. È per questo motivo che YugaByte DB offre API SQL e NoSQL in un nucleo comune, senza promuovere uno dei due approcci. Inoltre, garantendo la compatibilità con i linguaggi di database più popolari, inclusi PostgreSQL e Cassandra, YugaByte DB assicura che gli sviluppatori non debbano imparare un altro linguaggio per lavorare con il nucleo della base di dati distribuita e rigorosamente definita.
In questo articolo abbiamo esaminato come le basi del design dei database differiscano tra PostgreSQL, Cassandra e MongoDB. Negli articoli successivi, ci immergeremo in concetti avanzati di design, come indici, transazioni, JOIN, direttive TTL e documenti JSON.
Vi auguriamo un ottimo fine settimana e vi invitiamo a , che si svolgerà il 14 maggio.
Fonte: habr.com
