


Questa primavera abbiamo già discusso alcuni argomenti introduttivi, ad esempio, и . Nel secondo, abbiamo persino promesso di continuare a studiare le prestazioni di varie topologie multidisco in ZFS. Questo è il file system di nuova generazione che ora viene implementato ovunque: from a .
Bene, oggi è il giorno migliore per conoscere ZFS, lettori curiosi. Sappi solo che, secondo l'umile opinione dello sviluppatore di OpenZFS Matt Ahrens, "è davvero difficile".
Ma prima di arrivare ai numeri - e lo prometto - per tutte le opzioni per una configurazione ZFS a otto dischi, dobbiamo parlare di come In generale, ZFS memorizza i dati su disco.
Zpool, vdev e dispositivo
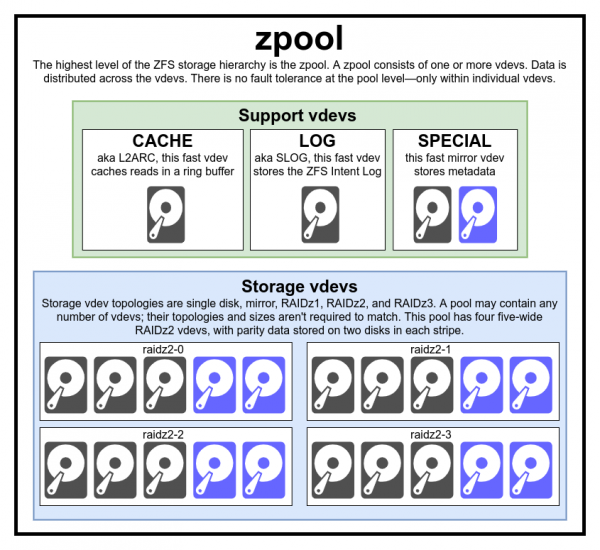
Questo diagramma di pool completo include tre vdev ausiliari, uno per ogni classe e quattro per RAIDz2

Di solito non c'è motivo di creare un pool di tipi e dimensioni vdev non corrispondenti, ma non c'è nulla che ti impedisca di farlo se lo desideri.
Per comprendere veramente il file system ZFS, è necessario dare un'occhiata da vicino alla sua struttura effettiva. Innanzitutto, ZFS unifica i livelli tradizionali di gestione del volume e del file system. In secondo luogo, utilizza un meccanismo transazionale di copia su scrittura. Queste caratteristiche significano che il sistema è strutturalmente molto diverso dai file system convenzionali e dagli array RAID. La prima serie di elementi costitutivi di base da comprendere sono il pool di archiviazione (zpool), il dispositivo virtuale (vdev) e il dispositivo reale (dispositivo).
zpool
Il pool di archiviazione zpool è la struttura ZFS più in alto. Ogni pool contiene uno o più dispositivi virtuali. Ciascuno di essi contiene a sua volta uno o più dispositivi reali (dispositivo). I pool virtuali sono blocchi autonomi. Un computer fisico può contenere due o più pool separati, ma ognuno è completamente indipendente dagli altri. I pool non possono condividere dispositivi virtuali.
La ridondanza di ZFS è a livello di dispositivo virtuale, non a livello di pool. Non c'è assolutamente alcuna ridondanza a livello di pool: se si perde un drive vdev o un vdev speciale, l'intero pool viene perso insieme ad esso.
I pool di archiviazione moderni possono sopravvivere alla perdita di una cache o di un registro del dispositivo virtuale, sebbene possano perdere una piccola quantità di dati sporchi se perdono il registro vdev durante un'interruzione dell'alimentazione o un arresto anomalo del sistema.
C'è un malinteso comune secondo cui le "strisce di dati" ZFS vengono scritte sull'intero pool. Questo non è vero. Zpool non è affatto divertente RAID0, è piuttosto divertente con un complesso meccanismo di distribuzione variabile.
Per la maggior parte, i record sono distribuiti tra i dispositivi virtuali disponibili in base allo spazio libero disponibile, quindi in teoria verranno riempiti tutti contemporaneamente. Nelle versioni successive di ZFS, viene preso in considerazione l'attuale utilizzo (utilizzo) di vdev: se un dispositivo virtuale è significativamente più occupato di un altro (ad esempio, a causa del carico di lettura), verrà temporaneamente ignorato per la scrittura, nonostante abbia il più alto libero rapporto spaziale.
Il meccanismo di rilevamento dell'utilizzo integrato nei moderni metodi di allocazione della scrittura ZFS può ridurre la latenza e aumentare il throughput durante periodi di carico insolitamente elevato, ma non carta bianca sulla combinazione involontaria di HDD lenti e SSD veloci in un pool. Un tale pool disuguale funzionerà comunque alla velocità del dispositivo più lento, cioè come se fosse interamente composto da tali dispositivi.
vdev
Ciascun pool di archiviazione è costituito da uno o più dispositivi virtuali (dispositivo virtuale, vdev). A sua volta, ogni vdev contiene uno o più dispositivi reali. La maggior parte dei dispositivi virtuali viene utilizzata per l'archiviazione semplice dei dati, ma esistono diverse classi helper vdev, tra cui CACHE, LOG e SPECIAL. Ciascuno di questi tipi di vdev può avere una delle cinque topologie: dispositivo singolo (dispositivo singolo), RAIDz1, RAIDz2, RAIDz3 o mirror (mirror).
RAIDz1, RAIDz2 e RAIDz3 sono varietà speciali di ciò che i veterani chiamerebbero RAID a parità doppia (diagonale). 1, 2 e 3 si riferiscono a quanti blocchi di parità sono allocati per ciascuna striscia di dati. Invece di dischi separati per la parità, i dispositivi virtuali RAIDz distribuiscono questa parità in modo semi-uniforme tra i dischi. Un array RAIDz può perdere tanti dischi quanti sono i blocchi di parità; se ne perde un altro, andrà in crash e porterà con sé lo storage pool.
Nei dispositivi virtuali con mirroring (mirror vdev), ogni blocco viene archiviato su ogni dispositivo nel vdev. Sebbene i mirror a due larghezze siano i più comuni, qualsiasi numero arbitrario di dispositivi può trovarsi in un mirror: i tripli vengono spesso utilizzati in installazioni di grandi dimensioni per migliorare le prestazioni di lettura e la tolleranza agli errori. Un mirror vdev può sopravvivere a qualsiasi guasto purché almeno un dispositivo nel vdev continui a funzionare.
I singoli vdev sono intrinsecamente pericolosi. Un tale dispositivo virtuale non sopravviverà a un singolo guasto e, se utilizzato come archivio o come vdev speciale, il suo guasto porterà alla distruzione dell'intero pool. Stai molto, molto attento qui.
CACHE, LOG e SPECIAL VA possono essere creati utilizzando una qualsiasi delle topologie di cui sopra, ma ricorda che la perdita di SPECIAL VA comporta la perdita del pool, pertanto è altamente consigliata una topologia ridondante.
dispositivo
Questo è probabilmente il termine più semplice da comprendere in ZFS: è letteralmente un dispositivo di accesso casuale a blocchi. Ricorda che i dispositivi virtuali sono costituiti da singoli dispositivi, mentre un pool è costituito da dispositivi virtuali.
I dischi, magnetici oa stato solido, sono i dispositivi a blocchi più comuni utilizzati come elementi costitutivi di vdev. Tuttavia, qualsiasi dispositivo con un descrittore in /dev funzionerà, quindi è possibile utilizzare interi array RAID hardware come dispositivi separati.
Un semplice file raw è uno dei dispositivi a blocchi alternativi più importanti da cui è possibile creare un vdev. Pool di prova da è un modo molto utile per controllare i comandi del pool e vedere quanto spazio è disponibile in un pool o in un dispositivo virtuale di una data topologia.
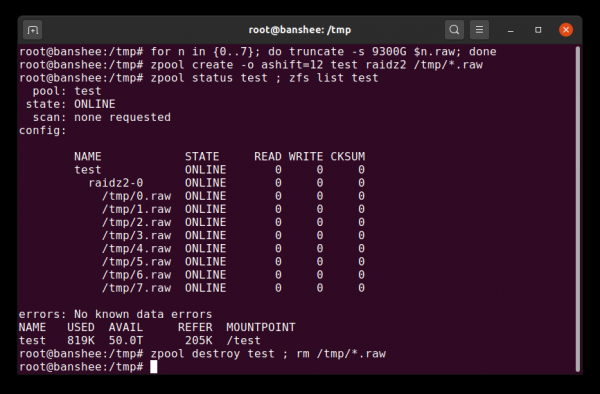
Puoi creare un pool di test da file sparsi in pochi secondi, ma non dimenticare di eliminare l'intero pool e i suoi componenti in seguito
Supponiamo che tu voglia mettere un server su otto dischi e prevedi di utilizzare dischi da 10 TB (~ 9300 GiB), ma non sei sicuro di quale topologia si adatta meglio alle tue esigenze. Nell'esempio sopra, creiamo un pool di test da file sparsi in pochi secondi e ora sappiamo che un vdev RAIDz2 di otto dischi da 10 TB fornisce 50 TiB di capacità utilizzabile.
Un'altra classe speciale di dispositivi è SPARE (ricambio). I dispositivi hot-swap, a differenza dei normali dispositivi, appartengono all'intero pool e non a un singolo dispositivo virtuale. Se un vdev nel pool ha esito negativo e un dispositivo di riserva è connesso al pool e disponibile, si unirà automaticamente al vdev interessato.
Dopo la connessione al vdev interessato, il dispositivo di riserva inizia a ricevere copie o ricostruzioni dei dati che dovrebbero trovarsi sul dispositivo mancante. Nel RAID tradizionale questo si chiama ricostruzione, mentre in ZFS si chiama resilvering.
È importante notare che i dispositivi di riserva non sostituiscono in modo permanente i dispositivi guasti. Questa è solo una sostituzione temporanea per ridurre il tempo di degradazione di vdev. Dopo che l'amministratore ha sostituito il vdev guasto, la ridondanza viene ripristinata su quel dispositivo permanente e SPARE viene disconnesso dal vdev e ripristinato per funzionare come riserva per l'intero pool.
Insiemi di dati, blocchi e settori
La prossima serie di elementi costitutivi da comprendere nel nostro viaggio ZFS riguarda meno l'hardware e più il modo in cui i dati stessi sono organizzati e archiviati. Stiamo saltando alcuni livelli qui, come metaslab, per non ingombrare i dettagli pur mantenendo una comprensione della struttura generale.
Set di dati (set di dati)
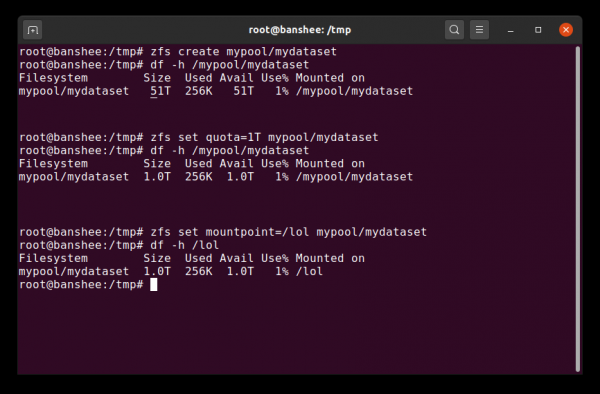
Quando creiamo per la prima volta un set di dati, mostra tutto lo spazio del pool disponibile. Quindi impostiamo la quota e cambiamo il punto di montaggio. Magia!
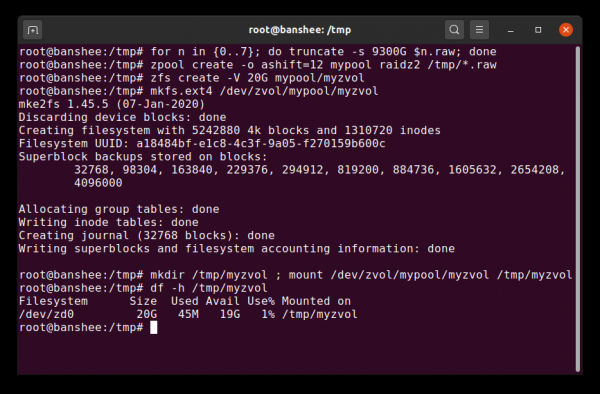
Zvol è per la maggior parte solo un set di dati privato del suo livello di filesystem, che stiamo sostituendo qui con un filesystem ext4 perfettamente normale.
Un set di dati ZFS è all'incirca uguale a un file system montato standard. Come un normale file system, a prima vista sembra "solo un'altra cartella". Ma proprio come i normali filesystem montabili, ogni set di dati ZFS ha il proprio set di proprietà di base.
Prima di tutto, un set di dati può avere una quota assegnata. Se impostato zfs set quota=100G poolname/datasetname, non sarai in grado di scrivere nella cartella montata /poolname/datasetname più di 100 GiB.
Notate la presenza - e l'assenza - di barre all'inizio di ogni riga? Ogni set di dati ha il proprio posto sia nella gerarchia ZFS che nella gerarchia di montaggio del sistema. Non esiste una barra iniziale nella gerarchia ZFS: si inizia con il nome del pool e quindi il percorso da un set di dati a quello successivo. Per esempio, pool/parent/child per un set di dati denominato child sotto il set di dati principale parent in un pool con un nome creativo pool.
Per impostazione predefinita, il punto di montaggio del set di dati sarà equivalente al suo nome nella gerarchia ZFS, con una barra iniziale: il pool denominato pool montato come /pool, set di dati parent montato dentro /pool/parente il set di dati figlio child montato dentro /pool/parent/child. Tuttavia, il punto di montaggio del sistema del set di dati può essere modificato.
Se specifichiamo zfs set mountpoint=/lol pool/parent/child, quindi il set di dati pool/parent/child montato sul sistema come /lol.
Oltre ai set di dati, dovremmo menzionare i volumi (zvols). Un volume è all'incirca uguale a un set di dati, tranne per il fatto che in realtà non ha un file system: è solo un dispositivo a blocchi. Puoi, ad esempio, creare zvol Con nome mypool/myzvol, quindi formattalo con un file system ext4 e quindi monta quel file system: ora hai un file system ext4, ma con tutte le funzionalità di sicurezza di ZFS! Questo può sembrare sciocco su una singola macchina, ma ha molto più senso come back-end quando si esporta un dispositivo iSCSI.
Blocchi
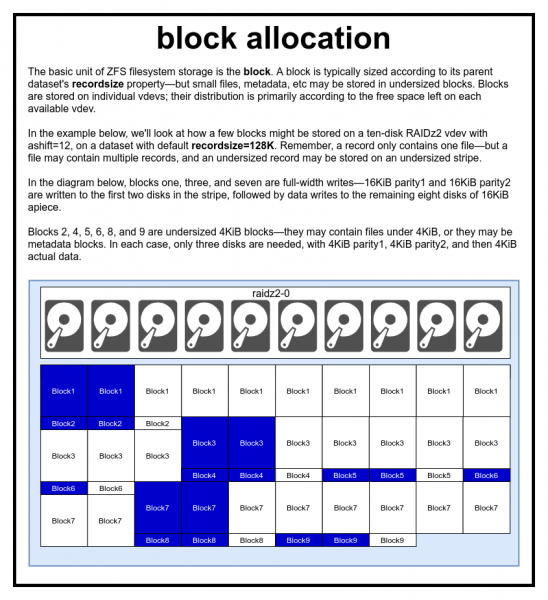
Il file è rappresentato da uno o più blocchi. Ogni blocco è memorizzato su un dispositivo virtuale. La dimensione del blocco è solitamente uguale al parametro recordsize, ma può essere ridotto a 2^turnose contiene metadati o un piccolo file.

Noi veramente davvero non scherzando sull'enorme penalizzazione delle prestazioni se si imposta un cambio troppo piccolo
In un pool ZFS, tutti i dati, inclusi i metadati, vengono archiviati in blocchi. La dimensione massima del blocco per ogni set di dati è definita nella proprietà recordsize (dimensione del registro). La dimensione del record può essere modificata, ma ciò non cambierà la dimensione o la posizione di eventuali blocchi che sono già stati scritti nel set di dati: influisce solo sui nuovi blocchi mentre vengono scritti.
Se non diversamente specificato, la dimensione del record predefinita corrente è 128 KiB. È una specie di difficile compromesso in cui le prestazioni non sono perfette, ma nella maggior parte dei casi non è nemmeno terribile. Recordsize può essere impostato su qualsiasi valore da 4K a 1M (con impostazioni avanzate recordsize puoi installarne ancora di più, ma raramente è una buona idea).
Qualsiasi blocco si riferisce ai dati di un solo file: non puoi raggruppare due file diversi in un blocco. Ogni file è composto da uno o più blocchi, a seconda delle dimensioni. Se la dimensione del file è inferiore alla dimensione del record, verrà archiviata in un blocco di dimensioni inferiori, ad esempio un blocco con un file da 2 KiB occuperà solo un settore da 4 KiB sul disco.
Se il file è abbastanza grande e richiede diversi blocchi, tutti i record con questo file saranno di dimensione recordsize - compresa l'ultima voce, la cui parte principale potrebbe essere .
zvols non hanno una proprietà recordsize - hanno invece una proprietà equivalente volblocksize.
Settori
L'ultimo elemento fondamentale è il settore. È l'unità fisica più piccola che può essere scritta o letta dal dispositivo sottostante. Per diversi decenni, la maggior parte dei dischi ha utilizzato settori da 512 byte. Di recente, la maggior parte dei dischi è configurata per settori da 4 KiB e alcuni, in particolare gli SSD, hanno settori da 8 KiB o anche di più.
Il sistema ZFS ha una proprietà che consente di impostare manualmente la dimensione del settore. Questa proprietà ashift. Un po' confusamente, ashift è una potenza di due. Per esempio, ashift=9 indica una dimensione del settore di 2 ^ 9 o 512 byte.
ZFS interroga il sistema operativo per informazioni dettagliate su ciascun dispositivo a blocchi quando viene aggiunto a un nuovo vdev e, in teoria, imposta automaticamente ashift in modo appropriato in base a queste informazioni. Sfortunatamente, molte unità mentono sulla dimensione del loro settore per mantenere la compatibilità con Windows XP (che non era in grado di riconoscere unità con dimensioni di settore diverse).
Ciò significa che si consiglia vivamente a un amministratore ZFS di conoscere la dimensione effettiva del settore dei propri dispositivi e impostarla manualmente ashift. Se ashift è impostato su un valore troppo basso, il numero di operazioni di lettura/scrittura aumenta in modo astronomico. Quindi, scrivere "settori" da 512 byte in un vero settore da 4 KiB significa dover scrivere il primo "settore", quindi leggere il settore da 4 KiB, modificarlo con un secondo "settore" da 512 byte, riscriverlo nel nuovo settore 4 KiB, e così via per ogni voce.
Nel mondo reale, una tale penalità colpisce gli SSD Samsung EVO, per i quali ashift=13, ma questi SSD mentono sulla dimensione del loro settore e pertanto l'impostazione predefinita è impostata su ashift=9. Se un amministratore di sistema esperto non modifica questa impostazione, questo SSD funziona più lento HDD magnetico convenzionale.
Per confronto, per dimensioni troppo grandi ashift non c'è praticamente nessuna sanzione. Non c'è una reale riduzione delle prestazioni e l'aumento dello spazio inutilizzato è infinitesimale (o zero con la compressione abilitata). Pertanto, consigliamo vivamente di installare anche quelle unità che utilizzano settori a 512 byte ashift=12 o ashift=13per affrontare il futuro con fiducia.
proprietà ashift è impostato per ogni dispositivo virtuale vdev e non per la piscina, come molti pensano erroneamente - e non cambia dopo l'installazione. Se colpisci accidentalmente ashift quando aggiungi un nuovo vdev a un pool, hai irrimediabilmente inquinato quel pool con un dispositivo a basse prestazioni e di solito non c'è altra scelta che distruggere il pool e ricominciare da capo. Anche la rimozione di vdev non ti salverà da una configurazione non funzionante ashift!
Meccanismo di copia su scrittura
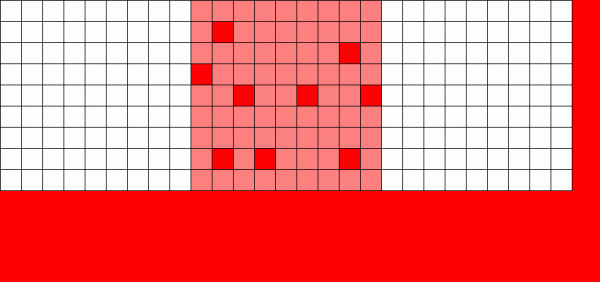
Se un normale file system deve sovrascrivere i dati, cambia ogni blocco in cui si trova
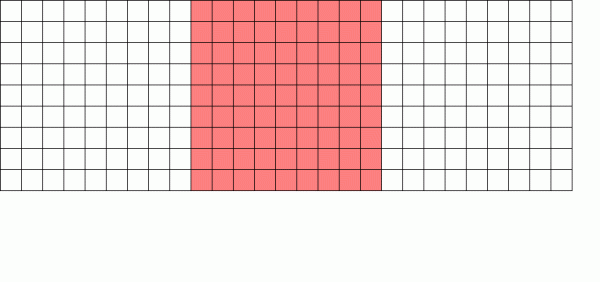
Un file system copy-on-write scrive una nuova versione del blocco e quindi sblocca la vecchia versione

In astratto, se ignoriamo l'effettiva posizione fisica dei blocchi, la nostra "cometa di dati" viene semplificata in un "worm di dati" che si sposta da sinistra a destra lungo la mappa dello spazio disponibile

Ora possiamo avere una buona idea di come funzionano le istantanee copia su scrittura: ogni blocco può appartenere a più istantanee e persisterà fino a quando tutte le istantanee associate non verranno distrutte
Il meccanismo Copy on Write (CoW) è la base fondamentale di ciò che rende ZFS un sistema così straordinario. Il concetto di base è semplice: se chiedi a un file system tradizionale di modificare un file, farà esattamente quello che hai chiesto. Se chiedi a un file system copy-on-write di fare lo stesso, dirà "ok" ma ti mentirà.
Invece, un file system copy-on-write scrive una nuova versione del blocco modificato e quindi aggiorna i metadati del file per scollegare il vecchio blocco e associare il nuovo blocco appena scritto.
Il distacco del vecchio blocco e il collegamento del nuovo viene eseguito in un'unica operazione, quindi non può essere interrotto: se si spegne dopo che ciò accade, si ha una nuova versione del file e se si spegne prima, si ha la vecchia versione . In ogni caso, non ci saranno conflitti nel file system.
La copia su scrittura in ZFS si verifica non solo a livello di file system, ma anche a livello di gestione del disco. Ciò significa che ZFS non è influenzato dallo spazio bianco () - un fenomeno in cui la striscia ha avuto il tempo di registrare solo parzialmente prima che il sistema andasse in crash, con danni all'array dopo il riavvio. Qui la striscia è scritta in modo atomico, vdev è sempre sequenziale e .
ZIL: registro degli intenti ZFS
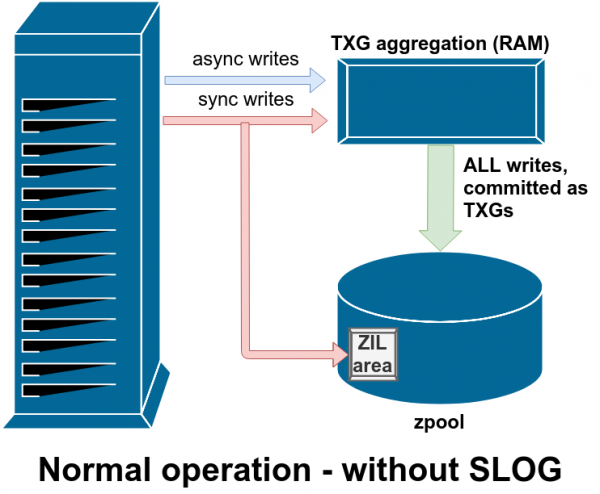
Il sistema ZFS tratta le scritture sincrone in un modo speciale: le memorizza temporaneamente ma immediatamente in ZIL prima di scriverle in modo permanente in un secondo momento insieme alle scritture asincrone.
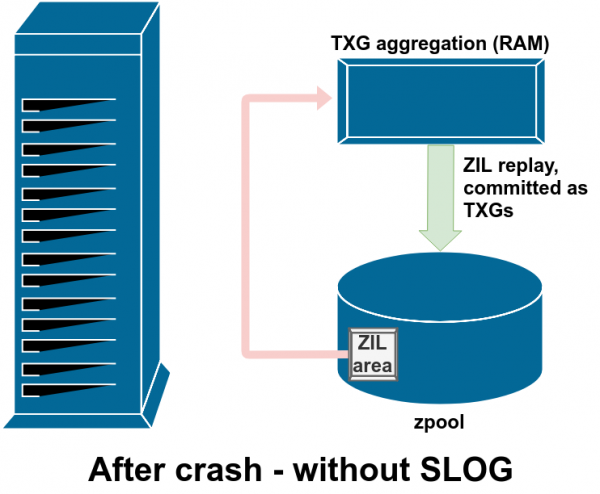
In genere, i dati scritti in un ZIL non vengono mai più letti. Ma è possibile dopo un arresto anomalo del sistema
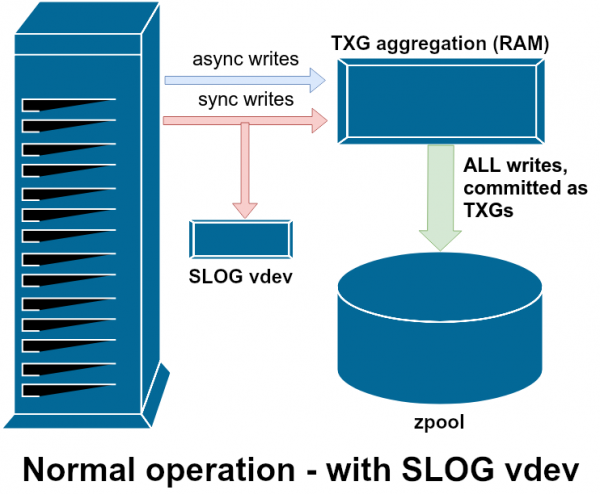
SLOG, o dispositivo LOG secondario, è solo un vdev speciale, e preferibilmente molto veloce, in cui lo ZIL può essere memorizzato separatamente dalla memoria principale
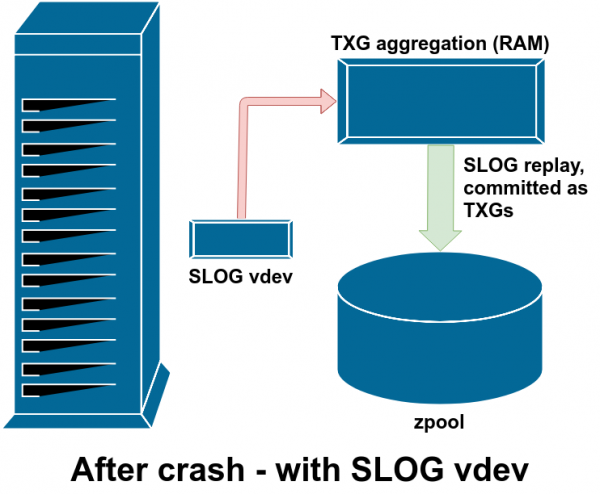
Dopo un arresto anomalo, vengono riprodotti tutti i dati sporchi in ZIL: in questo caso, ZIL è su SLOG, quindi viene riprodotto da lì
Esistono due categorie principali di operazioni di scrittura: sincrone (sync) e asincrone (async). Per la maggior parte dei carichi di lavoro, la stragrande maggioranza delle scritture è asincrona: il file system ne consente l'aggregazione e l'emissione in batch, riducendo la frammentazione e aumentando notevolmente il throughput.
Le registrazioni sincronizzate sono una questione completamente diversa. Quando un'applicazione richiede una scrittura sincrona, dice al file system: "È necessario eseguire il commit nella memoria non volatile adessofino ad allora, non posso fare altro". Pertanto, le scritture sincrone dovrebbero essere salvate immediatamente sul disco e se ciò aumenta la frammentazione o riduce il throughput, allora così sia.
ZFS gestisce le scritture sincrone in modo diverso rispetto ai normali file system: invece di impegnarle immediatamente nell'archiviazione regolare, ZFS le impegna in un'area di archiviazione speciale chiamata ZFS Intent Log o ZIL. Il trucco è che questi record anche rimangono in memoria, essendo aggregati insieme alle normali richieste di scrittura asincrona, per essere successivamente scaricati nello storage come normalissimi TXG (Transaction Group).
Durante il normale funzionamento, lo ZIL viene scritto e mai più letto. Quando, dopo pochi istanti, i record della ZIL vengono assegnati alla memoria principale nei normali TXG dalla RAM, vengono staccati dalla ZIL. L'unica volta che qualcosa viene letto dallo ZIL è quando il pool viene importato.
Se ZFS non riesce (arresto anomalo del sistema operativo o interruzione dell'alimentazione) mentre sono presenti dati in ZIL, tali dati verranno letti durante la successiva importazione del pool (ad esempio, quando il sistema di emergenza viene riavviato). Qualsiasi cosa nella ZIL verrà letta, raggruppata in TXG, impegnata nella memoria principale e quindi staccata dalla ZIL durante il processo di importazione.
Una delle classi helper vdev si chiama LOG o SLOG, il dispositivo secondario di LOG. Ha uno scopo: fornire al pool un vdev separato, e preferibilmente molto più veloce, molto resistente alla scrittura per archiviare lo ZIL, invece di archiviare lo ZIL nell'archivio vdev principale. Lo stesso ZIL si comporta allo stesso modo indipendentemente da dove è archiviato, ma se LOG vdev ha prestazioni di scrittura molto elevate, le scritture sincrone saranno più veloci.
L'aggiunta di un vdev con LOG al pool non funziona non si può migliorare le prestazioni di scrittura asincrona, anche se forzi tutte le scritture su ZIL con zfs set sync=always, saranno comunque collegati alla memoria principale in TXG nello stesso modo e allo stesso ritmo come senza il registro. L'unico miglioramento diretto delle prestazioni è la latenza delle scritture sincrone (poiché un registro più veloce accelera le operazioni). sync).
Tuttavia, in un ambiente che richiede già molte scritture sincrone, vdev LOG può velocizzare indirettamente le scritture asincrone e le letture non memorizzate nella cache. L'offload delle voci ZIL in un vdev LOG separato significa meno contesa per IOPS sullo storage primario, che migliora in una certa misura le prestazioni di tutte le letture e scritture.
Istantanee
Il meccanismo di copia su scrittura è anche una base necessaria per gli snapshot atomici ZFS e la replica asincrona incrementale. Il file system attivo ha un albero di puntatori che contrassegna tutti i record con i dati correnti: quando scatti un'istantanea, fai semplicemente una copia di questo albero di puntatori.
Quando un record viene sovrascritto sul file system attivo, ZFS scrive prima la nuova versione del blocco nello spazio inutilizzato. Quindi stacca la vecchia versione del blocco dal file system corrente. Ma se qualche istantanea si riferisce al vecchio blocco, rimane comunque invariato. Il vecchio blocco non verrà effettivamente ripristinato come spazio libero fino a quando tutte le istantanee che fanno riferimento a questo blocco non verranno distrutte!
Replica
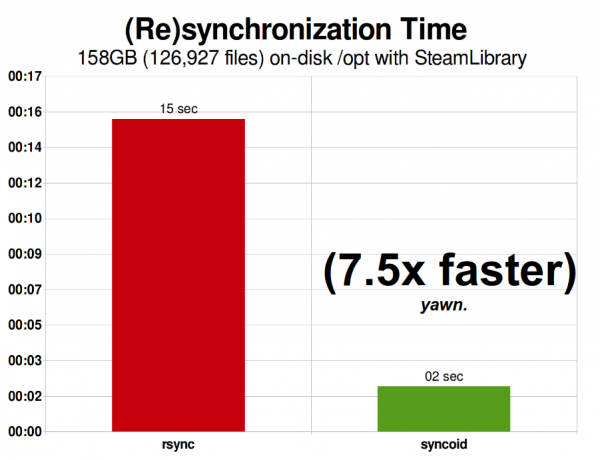
La mia libreria Steam nel 2015 era di 158 GiB e includeva 126 file. Questo è abbastanza vicino alla situazione ottimale per rsync: la replica ZFS sulla rete era "solo" più veloce del 927%.
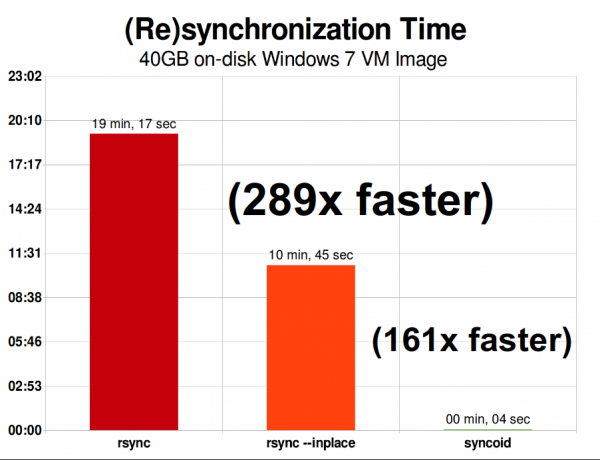
Sulla stessa rete, replica di un singolo file immagine di macchina virtuale da 40 gigabyte Windows Il punto 7 è tutta un'altra storia. La replica ZFS è 289 volte più veloce di rsync, o "solo" 161 volte più veloce se si è abbastanza esperti da richiamare rsync con l'opzione --inplace.
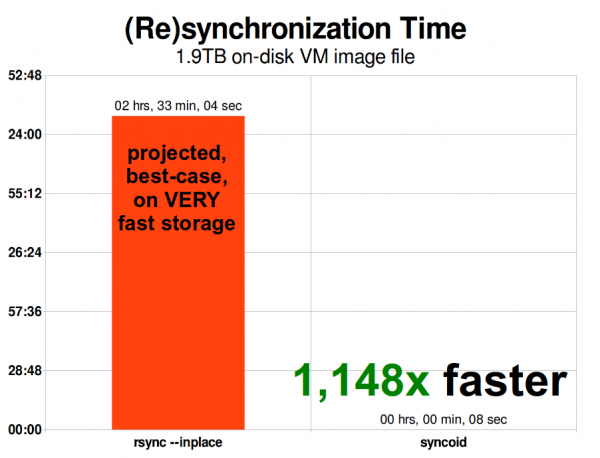
Quando un'immagine della macchina virtuale viene ridimensionata, rsync emette il ridimensionamento con essa. 1,9 TiB non è così grande per un'immagine VM moderna, ma è abbastanza grande che la replica ZFS è 1148 volte più veloce di rsync, anche con l'argomento --inplace di rsync
Una volta capito come funzionano gli snapshot, dovrebbe essere facile cogliere l'essenza della replica. Poiché uno snapshot è solo un albero di puntatori ai record, ne consegue che se lo facciamo zfs send snapshot, quindi inviamo sia questo albero che tutti i record ad esso associati. Quando inviamo questo zfs send в zfs receive sul target, scrive sia il contenuto effettivo del blocco che l'albero dei puntatori che fanno riferimento ai blocchi al dataset di destinazione.
Le cose si fanno ancora più interessanti nel secondo zfs send. Ora abbiamo due sistemi, ciascuno contenente poolname/datasetname@1e acquisisci una nuova istantanea poolname/datasetname@2. Pertanto, nel pool originale che hai datasetname@1 и datasetname@2e finora nel pool di destinazione solo il primo snapshot datasetname@1.
Poiché abbiamo un'istantanea comune tra l'origine e la destinazione datasetname@1, possiamo farlo incrementale zfs send sopra. Quando diciamo al sistema zfs send -i poolname/datasetname@1 poolname/datasetname@2, confronta due alberi di puntatori. Tutti i puntatori che esistono solo in @2, ovviamente si riferiscono a nuovi blocchi, quindi abbiamo bisogno del contenuto di questi blocchi.
Su un sistema remoto, elaborazione di un incrementale send altrettanto semplice. Per prima cosa scriviamo tutte le nuove voci incluse nello stream send, quindi aggiungi i puntatori a tali blocchi. Voilà, abbiamo @2 nel nuovo sistema!
La replica incrementale asincrona ZFS è un enorme miglioramento rispetto ai precedenti metodi non basati su snapshot come rsync. In entrambi i casi, vengono trasferiti solo i dati modificati, ma rsync deve prima leggere dal disco tutti i dati su entrambi i lati per controllare la somma e confrontarla. Al contrario, la replica ZFS non legge altro che alberi di puntatori e tutti i blocchi che non sono presenti nello snapshot condiviso.
Compressione incorporata
Il meccanismo di copia su scrittura semplifica anche il sistema di compressione in linea. In un file system tradizionale, la compressione è problematica: sia la vecchia versione che la nuova versione dei dati modificati risiedono nello stesso spazio.
Se consideriamo un pezzo di dati nel mezzo di un file che inizia la vita come un megabyte di zeri da 0x00000000 e così via, è molto facile comprimerlo in un settore su disco. Ma cosa succede se sostituiamo quel megabyte di zeri con un megabyte di dati incomprimibili come JPEG o rumore pseudo-casuale? Inaspettatamente, questo megabyte di dati richiederà non uno, ma 256 settori da 4 KiB, e in questo posto sul disco è riservato solo un settore.
ZFS non ha questo problema, poiché i record modificati vengono sempre scritti nello spazio inutilizzato: il blocco originale occupa solo un settore da 4 KiB e il nuovo record ne occuperà 256, ma questo non è un problema: un frammento modificato di recente dal " middle" del file verrebbe scritto nello spazio inutilizzato indipendentemente dal fatto che la sua dimensione sia cambiata o meno, quindi per ZFS questa è una situazione abbastanza normale.
La compressione ZFS nativa è disabilitata per impostazione predefinita e il sistema offre algoritmi collegabili, attualmente LZ4, gzip (1-9), LZJB e ZLE.
- LZ4 è un algoritmo di streaming che offre compressione e decompressione estremamente veloci e vantaggi in termini di prestazioni per la maggior parte dei casi d'uso, anche su CPU piuttosto lente.
- GZIP è un venerabile algoritmo che tutti gli utenti Unix conoscono e amano. Può essere implementato con i livelli di compressione 1-9, con rapporto di compressione e utilizzo della CPU in aumento man mano che si avvicina al livello 9. L'algoritmo è adatto per tutti i casi d'uso di testo (o altri casi altamente comprimibili), ma per il resto spesso causa problemi alla CPU - usalo con cura, specialmente ai livelli più alti.
- LZJB è l'algoritmo originale in ZFS. È deprecato e non dovrebbe più essere utilizzato, l'LZ4 lo supera in ogni modo.
- SBAGLIATO - codifica a livello zero, codifica a livello zero. Non tocca affatto i dati normali, ma comprime grandi sequenze di zeri. Utile per set di dati completamente incomprimibili (come JPEG, MP4 o altri formati già compressi) poiché ignora i dati incomprimibili ma comprime lo spazio inutilizzato nei record risultanti.
Raccomandiamo la compressione LZ4 per quasi tutti i casi d'uso; la riduzione delle prestazioni quando si incontrano dati incomprimibili è molto piccola e crescita L'impatto sulle prestazioni per i dati tipici è significativo. Copia di un'immagine di macchina virtuale per l'installazione di un nuovo sistema operativo. Windows (sistema operativo appena installato, ancora privo di dati) compression=lz4 superato il 27% più velocemente rispetto a compression=noneIn .
ARC - cache sostitutiva adattiva
ZFS è l'unico file system moderno che conosciamo che utilizza il proprio meccanismo di memorizzazione nella cache di lettura, piuttosto che fare affidamento sulla cache delle pagine del sistema operativo per archiviare copie dei blocchi letti di recente nella RAM.
Sebbene la cache nativa non sia priva di problemi, ZFS non può rispondere alle nuove richieste di allocazione della memoria con la stessa rapidità del kernel, quindi la nuova sfida malloc() sull'allocazione della memoria potrebbe fallire se necessita della RAM attualmente occupata da ARC. Ma ci sono buoni motivi per utilizzare la propria cache, almeno per ora.
Tutti i sistemi operativi moderni conosciuti, incluso MacOS, Windows, Linux BSD utilizza l'algoritmo LRU (Least Recently Used) per implementare la cache di pagina. Si tratta di un algoritmo primitivo che sposta un blocco memorizzato nella cache "in cima alla coda" dopo ogni lettura e rimuove i blocchi "in fondo alla coda" quando necessario per aggiungere in cima i nuovi cache miss (blocchi che avrebbero dovuto essere letti dal disco anziché dalla cache).
L'algoritmo di solito funziona bene, ma su sistemi con set di dati funzionanti di grandi dimensioni, LRU porta facilmente al thrashing, eliminando i blocchi necessari di frequente per fare spazio a blocchi che non verranno mai più letti dalla cache.
è un algoritmo molto meno ingenuo che può essere pensato come una cache "ponderata". Ogni volta che viene letto un blocco memorizzato nella cache, diventa un po' più "pesante" e più difficile da sfrattare - e anche dopo aver sfrattato un blocco tracciato entro un certo periodo di tempo. Anche un blocco che è stato rimosso ma che deve essere riletto nella cache diventerà "più pesante".
Il risultato finale di tutto ciò è una cache con una percentuale di riscontri molto più elevata, il rapporto tra riscontri nella cache (letture eseguite dalla cache) e riscontri nella cache (letture dal disco). Questa è una statistica estremamente importante: non solo i riscontri nella cache vengono serviti ordini di grandezza più velocemente, ma anche i mancati riscontri nella cache possono essere serviti più velocemente, poiché maggiore è il numero di riscontri nella cache, minore è il numero di richieste di disco simultanee e minore è la latenza per i mancati mancati rimanenti che devono essere servito con il disco.
conclusione
Dopo aver appreso la semantica di base di ZFS - come funziona il copy-on-write, nonché le relazioni tra pool di archiviazione, dispositivi virtuali, blocchi, settori e file - siamo pronti a discutere le prestazioni del mondo reale con numeri reali.
Nella prossima sezione, analizzeremo le prestazioni effettive dei pool con vdev in mirroring e RAIDz, confrontandole tra loro e con le topologie RAID del kernel tradizionali. Linuxche abbiamo studiato .
All'inizio, volevamo coprire solo le basi - le stesse topologie ZFS - ma dopo così prepariamoci a parlare di configurazione e messa a punto più avanzate di ZFS, incluso l'uso di tipi di vdev ausiliari come L2ARC, SLOG e allocazione speciale.
Fonte: habr.com
