

Continuando ad esaminare le tecnologie di accelerazione delle operazioni di input/output applicate ai sistemi di archiviazione, iniziate in , è impossibile non soffermarsi su un'opzione piuttosto popolare come il tiering (Auto Tiering). Sebbene l'ideologia di lavoro di questa funzione sia piuttosto simile tra i vari produttori di sistemi di archiviazione, esamineremo le peculiarità dell'implementazione del tiering prendendo come esempio .
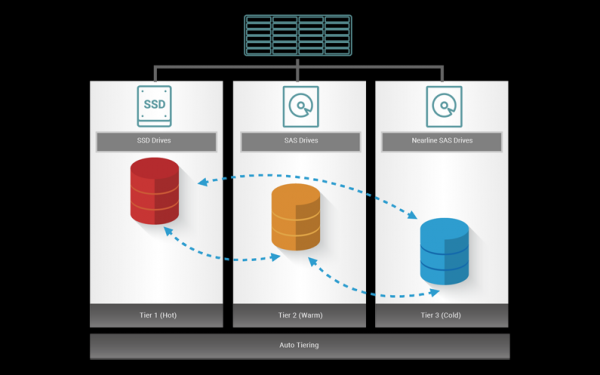
. Nonostante la varietà di dati memorizzati nel sistema di archiviazione, questi dati possono essere suddivisi in diverse categorie, in base alla loro richiesta (frequenza d'uso). È fondamentale garantire un accesso il più veloce possibile ai dati più richiesti (a caldo), mentre l'elaborazione dei dati meno richiesti (a freddo) può essere eseguita con priorità più bassa.
Per organizzare un tale schema si utilizza proprio il funzionamento del tiering. In questo caso, l'array di dati non è composto da dischi omogenei, ma da diversi gruppi di memorizzazione che formano differenti livelli (tier) di archiviazione. Grazie a un algoritmo speciale, i dati vengono automaticamente spostati tra i livelli per garantire la massima performance complessiva.
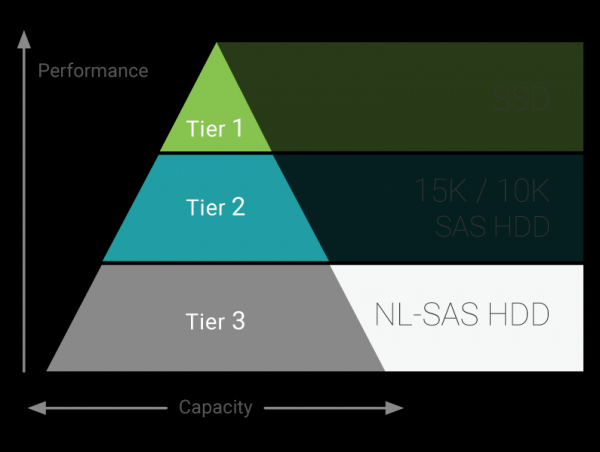
Storage ibrido supportano fino a tre livelli di archiviazione:
- Tier 1: SSD, massime prestazioni
- Tier 2: HDD SAS 10K/15K, elevate prestazioni
- Tier 3: HDD NL-SAS 7.2K, massima capacità
Il pool Auto Tiering può contenere tutti e tre i livelli, oppure solo due in qualsiasi combinazione. All'interno di ogni Tier, i dischi vengono raggruppati in comuni gruppi RAID. Per una massima flessibilità, il livello RAID in ogni Tier può essere diverso. Ad esempio, nulla impedisce di organizzare una struttura del tipo 4x SSD RAID10 + 6x HDD 10K RAID5 + 12 HDD 7.2K RAID6.
Dopo la creazione dei volumi (dischi virtuali) su il pool inizia a raccogliere in background le statistiche su tutte le operazioni di input/output. A tal fine, lo spazio viene "suddiviso" in blocchi di dimensione 1GB (cosiddetti sub LUN). Ad ogni accesso a un tale blocco, viene assegnato un coefficiente di 1. Nel tempo, questo coefficiente diminuisce. Dopo 24 ore, in assenza di richieste di input/output a quel blocco, sarà già pari a 0.5 e continuerà a scendere ogni ora successiva.
In un momento specifico (per impostazione predefinita ogni giorno a mezzanotte) viene effettuata una classificazione dei risultati raccolti per attività del sub LUN in base ai loro coefficienti. Da ciò si decide quali blocchi spostare e in quale direzione. Dopodiché, avviene realmente la rilocalizzazione dei dati tra i livelli.
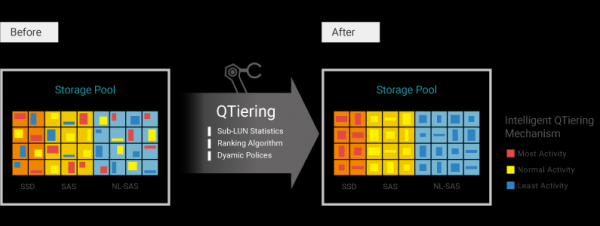
Nella storage array Qsan, la gestione del processo di tiering è implementata eccezionalmente attraverso numerosi parametri, consentendo una configurazione molto flessibile delle performance finali dell'array.
Per determinare la posizione iniziale dei dati e la direzione prioritaria del loro spostamento, vengono utilizzate politiche che sono impostate separatamente per ciascun volume:
- Auto Tiering – la politica predefinita, il posizionamento iniziale e la direzione dei trasferimenti vengono determinati automaticamente, cioè i dati "caldi" tendono a salire ai livelli superiori, mentre i dati "freddi" scendono. Il posizionamento iniziale viene scelto in base allo spazio disponibile a ciascun livello. Tuttavia, è importante comprendere che il sistema cerca innanzitutto di sfruttare al massimo i memorie più veloci. Pertanto, in presenza di spazio libero, i dati verranno posizionati nei livelli superiori. Questa politica è adatta per la maggior parte degli scenari in cui non è possibile prevedere in anticipo la domanda di dati.
- Iniziare in alto, poi Auto Tiering – l'unica differenza rispetto al precedente è il posizionamento iniziale dei dati (nel livello più veloce)
- Livello massimo – i dati cercano sempre di occupare il livello più veloce. Se durante il funzionamento vengono spostati in basso, al primo tentativo utile tornano indietro. Questa politica è adatta per i dati che richiedono accesso molto veloce.
- Livello minimo – i dati tendono sempre a occupare il livello più basso possibile. Questa politica è particolarmente indicata per i dati poco utilizzati (ad esempio, archivi).
- Senza spostamento – il sistema determina automaticamente la posizione originaria dei dati e non ne effettua lo spostamento. Tuttavia, le statistiche continuano a essere raccolte nel caso fosse necessaria una successiva rilocazione.
È importante notare che, sebbene le politiche siano definite al momento della creazione di ogni volume, possono essere modificate ripetutamente 'al volo' durante il ciclo di vita del sistema.
Oltre alle politiche, per il meccanismo di tiering si configurano anche la frequenza e il ritmo degli spostamenti dei dati tra i livelli. È possibile impostare orari specifici per lo spostamento: quotidianamente o in determinati giorni della settimana, così come ridurre l'intervallo di raccolta delle statistiche a poche ore (frequenza minima – 2 ore). Se è necessario limitare il tempo di esecuzione dell'operazione di spostamento dei dati, è possibile impostare delle fasce orarie (finestra per lo spostamento). Inoltre, si specificano anche le velocità di rilocazione – 3 modalità: veloce, media, lenta.
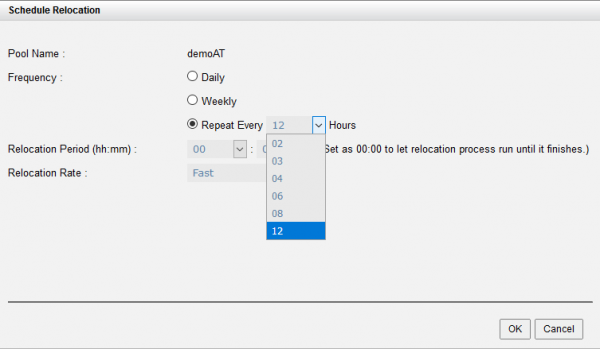
In caso di necessità di un'immediata relocazione dei dati, è possibile eseguirla manualmente in qualsiasi momento su richiesta dell'amministratore.
È evidente che più spesso e rapidamente vengono spostati i dati tra i livelli, più flessibile sarà il sistema di archiviazione in base alle attuali condizioni operative. Tuttavia, è importante ricordare che il trasferimento rappresenta un carico aggiuntivo (soprattutto sui dischi), quindi non è consigliabile 'correre' i dati senza una vera necessità. È meglio pianificare il trasferimento in momenti di carico minimo. Se il sistema di archiviazione richiede costantemente elevate prestazioni 24/7, allora il ritmo di relocation dovrebbe essere ridotto al minimo.
L'abbondanza di impostazioni di tiering sicuramente farà felici gli utenti esperti. Tuttavia, anche per chi si trova di fronte a questa tecnologia per la prima volta, non c'è nulla di cui preoccuparsi. È possibile fidarsi delle impostazioni predefinite (politica di Auto Tiering, trasferimento alla massima velocità una volta al giorno durante la notte) e, man mano che si accumulano statistiche, regolare alcuni parametri per raggiungere il risultato desiderato.
Confrontando il tiering con una tecnologia altrettanto popolare per l'aumento delle prestazioni come , è importante tenere a mente i diversi principi di funzionamento dei loro algoritmi.
caching SSD
Auto Tiering
Tempo di attivazione dell'effetto
Quasi istantaneo. Ma l'effetto tangibile si avverte solo dopo il "riscaldamento" della cache (minuti-ore)
Dopo la raccolta delle statistiche (da 2 ore, idealmente 24 ore) più il tempo necessario per il trasferimento dei dati
Durata dell'effetto
Finché i dati non vengono sostituiti da un nuovo lotto (minuti-ore)
Finché la domanda dei dati rimane valida (24 ore e oltre)
Indicazioni per l'uso
Aumento immediato delle prestazioni per un breve periodo (database, ambienti di virtualizzazione)
Aumento delle prestazioni per un lungo periodo (server di file, web, e-mail)
Inoltre, una delle caratteristiche del tiering è la possibilità di utilizzarlo non solo per scenari tipo "SSD + HDD", ma anche "HDD veloci + HDD lenti" o persino tutti e tre i livelli, il che è fondamentalmente impossibile nel caso dell'uso del caching SSD.
Test
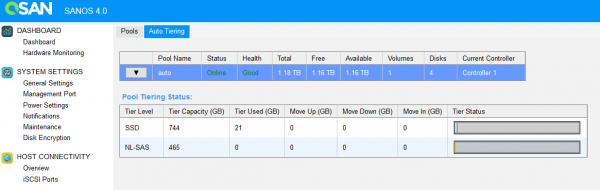
Per verificare il funzionamento degli algoritmi di tiering, abbiamo effettuato un test semplice. È stato creato un pool composto da due livelli SSD (RAID 1) + HDD 7.2K (RAID 1), su cui abbiamo collocato un volume con una politica di "livello minimo". Cioè, i dati devono sempre trovarsi sui dischi più lenti.
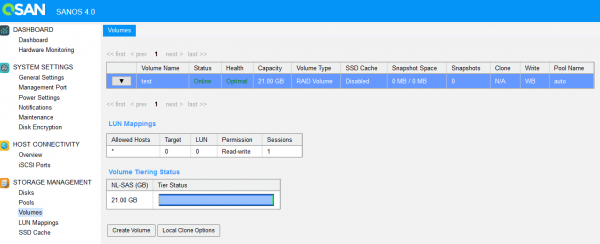
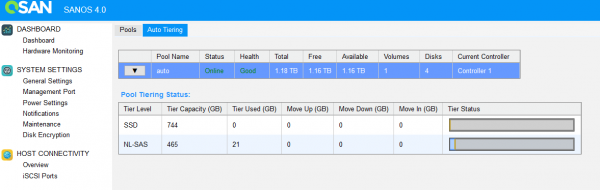
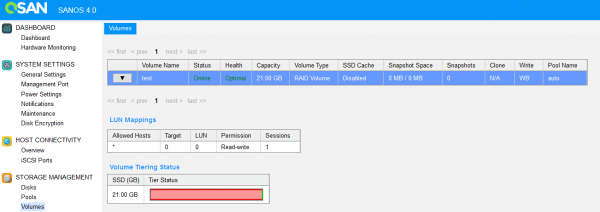
L'interfaccia di gestione mostra chiaramente la collocazione dei dati tra i livelli.
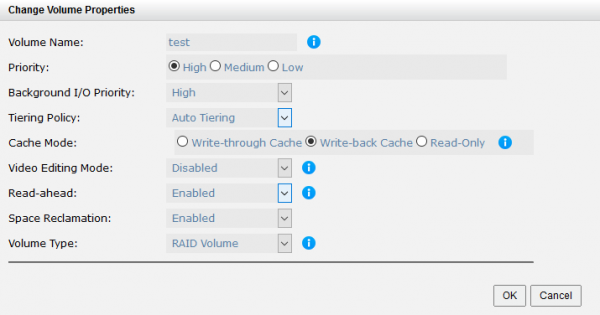
Dopo aver riempito il volume di dati, abbiamo cambiato la politica di collocazione in Auto Tiering e avviato il test IOmeter.
Dopo alcune ore di test, quando il sistema è riuscito a raccogliere statistiche, è iniziato il processo di rilocazione.
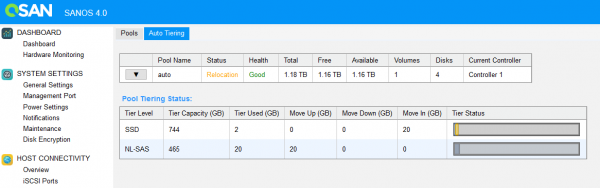
Al termine del trasferimento dei dati, il nostro volume di test si è completamente "trasferito" al livello superiore (SSD).
Verdetto
Auto Tiering è una tecnologia straordinaria che consente di aumentare le prestazioni del sistema di storage con costi e tempi minimi, grazie a un utilizzo più intensivo delle unità veloci. Applicabile a L'unico investimento è la licenza, acquistata una volta per tutte senza limiti di volume / numero di dischi / scaffali / ecc. Questa funzionalità è dotata di impostazioni così ricche da soddisfare praticamente qualsiasi esigenza aziendale. Inoltre, la visualizzazione dei processi nell'interfaccia consente una gestione efficiente del dispositivo.
Fonte: habr.com
