


In Linux, there are many tools for debugging the kernel and applications. Most of them negatively affect application performance and cannot be used in production.
A couple of years ago, — eBPF. It allows for tracing the kernel and user applications with low overhead and without the need to rebuild programs or load third-party modules into the kernel.
Now there are many application utilities that use eBPF, and in this article, we will look at how to write your own profiling utility based on the . The article is based on real events. We will go through the process from the emergence of the problem to its resolution, demonstrating how existing utilities can be utilized in specific situations.
Ceph Is Slow
A new host was added to the Ceph cluster. After migrating part of the data to it, we noticed that the write request processing speed was much lower than on other servers.
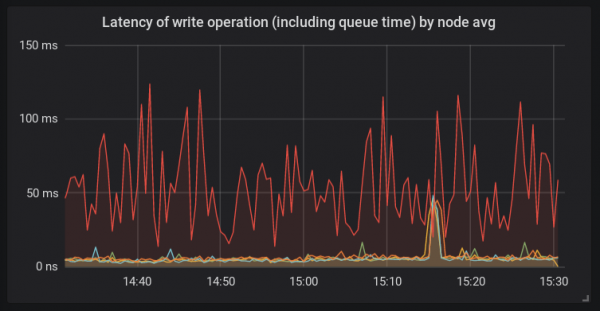
A differenza di altre piattaforme, su questo host è stato utilizzato bcache e il nuovo kernel Linux 4.15. Questa configurazione è stata utilizzata qui per la prima volta. E a quel punto era chiaro che la causa del problema poteva teoricamente essere qualsiasi cosa.
Investigando l'Host
Iniziamo osservando cosa sta succedendo all'interno del processo ceph-osd. A tal fine, utilizzeremo e (di cui puoi leggere di più ):

L'immagine ci dice che la funzione fdatasync() ha impiegato molto tempo per inviare una richiesta nella funzione generic_make_request(). Questo significa che la causa dei problemi si trova probabilmente al di fuori del demone osd stesso. Potrebbe essere il kernel o i dischi. L'output di iostat mostrava un'alta latenza nel trattamento delle richieste dai dischi bcache.
Durante il controllo dell'host, abbiamo scoperto che il demone systemd-udevd consuma una grande quantità di tempo CPU — circa il 20% su più core. Questo comportamento è strano, quindi è necessario scoprirne la causa. Poiché Systemd-udevd lavora con gli uevent, abbiamo deciso di guardarli attraverso udevadm monitor. Si è scoperto che venivano generati un gran numero di eventi di cambio per ogni dispositivo bloccato nel sistema. Questo è piuttosto insolito, quindi dovremo vedere cosa genera tutti questi eventi.
Utilizzando il BCC Toolkit
Come abbiamo già scoperto, il kernel (e il demone ceph nelle chiamate di sistema) impiega molto tempo in generic_make_request(). Provando a misurare la velocità di questa funzione. In c'è già un'ottima utility — funclatency. Tracceremo il demone tramite il suo PID con un intervallo di output di informazioni di 1 secondo, e riporteremo il risultato in millisecondi.
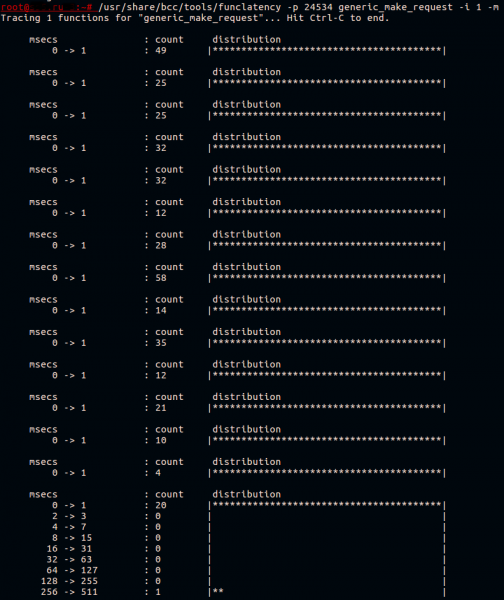
Di solito questa funzione lavora velocemente. Tutto ciò che fa è inviare la richiesta in coda al driver del dispositivo.
Bcache è un dispositivo complesso che in realtà consiste in tre dischi:
- dispositivo di backing (disco cacheabile), in questo caso un HDD lento;
- dispositivo di caching (disco cache), qui è una partizione di un dispositivo NVMe;
- dispositivo virtuale bcache, con cui lavora l'applicazione.
Sappiamo che l'invio della richiesta rallenta, ma per quale di questi dispositivi? Scopriremo questo tra poco.
Ora sappiamo che gli eventi uevent possono portare a problemi. Capire cosa li causa non è così semplice. Supponiamo che sia qualche software che viene eseguito periodicamente. Vediamo quale software viene avviato nel sistema utilizzando uno script. execsnoop dello stesso . Avviamolo e indirizziamo l'output in un file.
Ad esempio in questo modo:
/usr/share/bcc/tools/execsnoop | tee ./execdump
Non citeremo qui l'output completo di execsnoop, ma una riga di nostro interesse è apparsa come segue:
sh 1764905 5802 0 sudo arcconf getconfig 1 AD | grep Temperature | awk -F '[:/]' '{print $2}' | sed 's/^ ([0-9]*) C.*/1/'
La terza colonna è il PPID (parent PID) del processo. Il processo con PID 5802 si è rivelato essere uno dei thread del nostro sistema di monitoraggio. Controllando la configurazione del sistema di monitoraggio, sono stati trovati parametri impostati erroneamente. La temperatura del dispositivo HBA veniva registrata ogni 30 secondi, molto più frequentemente del necessario. Dopo aver cambiato l'intervallo di controllo a uno più lungo, abbiamo scoperto che il ritardo nell'elaborazione delle richieste su questo host non si distingue più rispetto agli altri host.
Ma è ancora poco chiaro perché il dispositivo bcache fosse così lento. Abbiamo preparato una piattaforma di test con configurazione identica e abbiamo provato a riprodurre il problema eseguendo fio su bcache, avviando periodicamente udevadm trigger per generare eventi udev.
Scrivere strumenti basati su BCC
Proviamo a scrivere una semplice utility per tracciare e visualizzare le chiamate più lente generic_make_request(). Siamo anche interessati al nome del disco per cui è stata chiamata questa funzione.
Il piano è semplice:
- Registriamo kprobe con generic_make_request():
- Salviamo in memoria il nome del disco, disponibile tramite l'argomento della funzione;
- Salviamo il timestamp.
- Registriamo kretprobe al ritorno da generic_make_request():
- Otteniamo il timestamp attuale;
- Cerchiamo il timestamp salvato e confrontiamo con quello attuale;
- Se il risultato è maggiore di quello specificato, allora troviamo il nome del disco salvato e lo visualizziamo nel terminale.
Kprobes e kretprobes utilizzano un meccanismo di breakpoint per modificare il codice delle funzioni al volo. Puoi leggere e articolo su questo tema. Se guardiamo il codice di varie utility in , possiamo notare che hanno una struttura identica. Quindi in questo articolo ometteremo il parsing degli argomenti dello script e passeremo direttamente al programma BPF.
Il testo eBPF all'interno di uno script Python appare come segue:
bpf_text = ''' # Qui ci sarà il codice del programma bpf '''
Per lo scambio di dati tra le funzioni, i programmi eBPF utilizzano . Procediamo in questo modo. Come chiave utilizzeremo il PID del processo e come valore definiremo la struttura:
struct data_t {
u64 pid;
u64 ts;
char comm[TASK_COMM_LEN];
u64 lat;
char disk[DISK_NAME_LEN];
};
BPF_HASH(p, u64, struct data_t);
BPF_PERF_OUTPUT(events);
Qui registriamo una tabella hash che si chiama p, con una chiave di tipo u64 e un valore di tipo struct data_t. La tabella sarà disponibile nel contesto del nostro programma BPF. Il macro BPF_PERF_OUTPUT registra un'altra tabella, chiamata events, che viene utilizzata per allo spazio utente.
Quando misuri i ritardi tra la chiamata a una funzione e il ritorno da essa, oppure tra le chiamate a diverse funzioni, è necessario tenere conto che i dati ottenuti devono appartenere a un unico contesto. In altre parole, è importante considerare le possibili esecuzioni parallele delle funzioni. Abbiamo la possibilità di misurare il ritardo tra la chiamata a una funzione nel contesto di un processo e il ritorno da questa funzione nel contesto di un altro processo, ma questo è probabilmente inutile. Un buon esempio in questo caso è , dove come chiave nella tabella hash viene impostato un puntatore a struct request, che rappresenta una singola richiesta al disco.
Successivamente, dobbiamo scrivere il codice che verrà eseguito all'invocazione della funzione esaminata:
void start(struct pt_regs *ctx, struct bio *bio) {
u64 pid = bpf_get_current_pid_tgid();
struct data_t data = {};
u64 ts = bpf_ktime_get_ns();
data.pid = pid;
data.ts = ts;
bpf_probe_read_str(&data.disk, sizeof(data.disk), (void*)bio->bi_disk->disk_name);
p.update(&pid, &data);
}
Qui il secondo argomento sarà sostituito con il primo argomento della funzione chiamata . Dopo di ciò, otteniamo il PID del processo nel contesto del quale operiamo e il timestamp corrente in nanosecondi. Registriamo tutto questo in un'area di memoria appena allocata. struct data_t data. Il nome del disco lo otteniamo dalla struttura bio, che viene passata all'invocazione generic_make_request(), e lo salviamo nella stessa struttura data. L'ultimo passo consiste nell'aggiungere una registrazione nella tabella hash di cui si parlava in precedenza.
La funzione successiva verrà chiamata al ritorno da generic_make_request():
void stop(struct pt_regs *ctx) {
u64 pid = bpf_get_current_pid_tgid();
u64 ts = bpf_ktime_get_ns();
struct data_t* data = p.lookup(&pid);
if (data != 0 && data->ts > 0) {
bpf_get_current_comm(&data->comm, sizeof(data->comm));
data->lat = (ts - data->ts) / 1000;
if (data->lat > MIN_US) {
FACTOR
data->pid >>= 32;
events.perf_submit(ctx, data, sizeof(struct data_t));
}
p.delete(&pid);
}
}
Questa funzione è simile alla precedente: otteniamo il PID del processo e il timestamp, ma non allochiamo memoria per una nuova struttura data. Invece, cerchiamo nella tabella hash una struttura esistente con la chiave == il PID corrente. Se troviamo la struttura, otteniamo il nome del processo in esecuzione e lo aggiungiamo.
Lo spostamento binario che utilizziamo qui serve per ottenere il GID del thread, cioè il PID del processo principale che ha avviato il thread, nel contesto del quale stiamo operando. La funzione che chiamiamo restituisce sia il GID del thread che il suo PID in un unico valore a 64 bit.
Quando eseguiamo l'output nel terminale, ora non siamo interessati al flusso, ma al processo principale. Dopo aver confrontato il ritardo ottenuto con una soglia prestabilita, trasferiamo la nostra struttura data nello spazio utente tramite una tabella events, dopodiché eliminiamo la registrazione da p.
Nello script Python che caricherà questo codice, dobbiamo sostituire MIN_US e FACTOR con le soglie di ritardo e unità di tempo che passeremo tramite argomenti:
bpf_text = bpf_text.replace('MIN_US',str(min_usec))
if args.milliseconds:
bpf_text = bpf_text.replace('FACTOR','data->lat /= 1000;')
label = "msec"
else:
bpf_text = bpf_text.replace('FACTOR','')
label = "usec"
Ora dobbiamo preparare il programma BPF tramite e registrare i campioni:
b = BPF(text=bpf_text)
b.attach_kprobe(event="generic_make_request",fn_name="start")
b.attach_kretprobe(event="generic_make_request",fn_name="stop")
Dovremo anche definire struct data_t nel nostro script, altrimenti non riusciremo a leggere nulla:
TASK_COMM_LEN = 16 # linux/sched.h
DISK_NAME_LEN = 32 # linux/genhd.h
class Data(ct.Structure):
_fields_ = [("pid", ct.c_ulonglong),
("ts", ct.c_ulonglong),
("comm", ct.c_char * TASK_COMM_LEN),
("lat", ct.c_ulonglong),
("disk",ct.c_char * DISK_NAME_LEN)]
L'ultimo passo è l'output dei dati nel terminale:
def print_event(cpu, data, size):
global start
event = ct.cast(data, ct.POINTER(Data)).contents
if start == 0:
start = event.ts
time_s = (float(event.ts - start)) / 1000000000
print("%-18.9f %-16s %-6d %-1s %s %s" % (time_s, event.comm, event.pid, event.lat, label, event.disk))
b["events"].open_perf_buffer(print_event)
# format output
start = 0
while 1:
try:
b.perf_buffer_poll()
except KeyboardInterrupt:
exit()
Lo script è disponibile su . Proviamo a eseguirlo su una piattaforma di test in cui è in esecuzione fio, che scrive su bcache, e chiamiamo udevadm monitor:
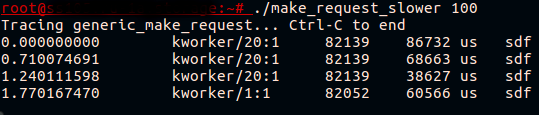
Finalmente! Ora vediamo che ciò che sembrava un dispositivo bcache in rallentamento è in realtà una chiamata rallentata generic_make_request() per il disco in cache.
Approfondiamo il Kernel
Cosa rallenta esattamente durante la trasmissione della richiesta? Vediamo che il ritardo si verifica anche prima dell'inizio del conteggio della richiesta, cioè il conteggio della specifica richiesta per ulteriori output statistici (/proc/diskstats o iostat) non è ancora iniziato. È facile verificare eseguendo iostat durante la riproduzione del problema, oppure , che si basa sull'inizio e la fine del conteggio delle richieste. Nessuno di questi strumenti mostrerà problemi per le richieste al disco in cache.
Se guardiamo alla funzione generic_make_request(), noteremo che prima dell'inizio del conteggio della richiesta vengono chiamate altre due funzioni. La prima — generic_make_request_checks(), esegue controlli di legittimità della richiesta rispetto alle impostazioni del disco. La seconda — , in cui c'è una chiamata interessante a :
ret = wait_event_interruptible(q->mq_freeze_wq,
(atomic_read(&q->mq_freeze_depth) == 0 &&
(preempt || !blk_queue_preempt_only(q))) ||
blk_queue_dying(q));
In essa, il kernel attende lo sblocco della coda. Misuriamo il ritardo blk_queue_enter():
~# /usr/share/bcc/tools/funclatency blk_queue_enter -i 1 -m
Tracciamento di 1 funzione per "blk_queue_enter"... Premi Ctrl-C per terminare.
msecs : conteggio distribuzione
0 -> 1 : 341 |****************************************|
msecs : conteggio distribuzione
0 -> 1 : 316 |****************************************|
msecs : conteggio distribuzione
0 -> 1 : 255 |****************************************|
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 1 | |
Sembra che siamo vicini a risolvere il mistero. Le funzioni utilizzate per "congelare/scongelare" la coda sono e . Vengono utilizzate quando è necessario modificare le impostazioni della coda di richieste, potenzialmente pericolose per le richieste in coda. Quando si chiama blk_mq_freeze_queue() con la funzione il contatore viene incrementato q->mq_freeze_depth. Dopo di che, il kernel attende lo svuotamento della coda in .
Il tempo di attesa per ripulire questa coda è equivalente al ritardo del disco, poiché il kernel aspetta il completamento di tutte le operazioni messe in coda. Una volta che la coda è vuota, vengono applicate le modifiche alle impostazioni. Successivamente viene chiamato , decrementando il contatore freeze_depth.
Ora sappiamo abbastanza per risolvere la situazione. Il comando udevadm trigger porta quindi all'applicazione delle impostazioni per il dispositivo di blocco. Queste impostazioni sono descritte nelle regole di udev. Possiamo scoprire quali impostazioni "congelano" la coda provando a modificarle tramite sysfs oppure esaminando il codice sorgente del kernel. Inoltre, possiamo provare l'utilità BCC , che stamperà nel terminale i trace dello stack del kernel e dello spazio utente per ogni chiamata blk_freeze_queue, ad esempio:
~# /usr/share/bcc/tools/trace blk_freeze_queue -K -U
PID TID COMM FUNC
3809642 3809642 systemd-udevd blk_freeze_queue
blk_freeze_queue+0x1 [kernel]
elevator_switch+0x29 [kernel]
elv_iosched_store+0x197 [kernel]
queue_attr_store+0x5c [kernel]
sysfs_kf_write+0x3c [kernel]
kernfs_fop_write+0x125 [kernel]
__vfs_write+0x1b [kernel]
vfs_write+0xb8 [kernel]
sys_write+0x55 [kernel]
do_syscall_64+0x73 [kernel]
entry_SYSCALL_64_after_hwframe+0x3d [kernel]
__write_nocancel+0x7 [libc-2.23.so]
[unknown]
3809631 3809631 systemd-udevd blk_freeze_queue
blk_freeze_queue+0x1 [kernel]
queue_requests_store+0xb6 [kernel]
queue_attr_store+0x5c [kernel]
sysfs_kf_write+0x3c [kernel]
kernfs_fop_write+0x125 [kernel]
__vfs_write+0x1b [kernel]
vfs_write+0xb8 [kernel]
sys_write+0x55 [kernel]
do_syscall_64+0x73 [kernel]
entry_SYSCALL_64_after_hwframe+0x3d [kernel]
__write_nocancel+0x7 [libc-2.23.so]
[unknown]
Le regole di Udev cambiano piuttosto raramente e di solito lo fanno sotto controllo. Quindi vediamo che anche l'applicazione di valori già definiti provoca un picco nei ritardi nella trasmissione delle richieste dall'applicazione al disco. Certamente, generare eventi udev quando non ci sono cambiamenti nella configurazione dei dischi (ad esempio, il dispositivo non viene collegato/disconnesso) non è una pratica molto buona. Tuttavia, possiamo aiutare il kernel a non svolgere lavoro inutile e a non "congelare" la coda delle richieste quando non ce n'è necessità. risolvono la situazione.
Conclusione
eBPF è uno strumento estremamente flessibile e potente. In questo articolo abbiamo esaminato un caso pratico e dimostrato solo una piccola parte di ciò che è possibile fare. Se sei interessato allo sviluppo di utility BCC, vale la pena dare un'occhiata al , che descrive bene le basi del suo funzionamento.
Ci sono anche altri strumenti interessanti per il debug e il profiling basati su eBPF. Uno di essi è , che consente di scrivere potenti one-liner e piccoli programmi in un linguaggio simile ad awk. L'altro è , che consente di raccogliere metriche a livello basso ad alta risoluzione direttamente sul tuo server Prometheus, con la possibilità di ottenere in seguito una visione grafica e persino allerta.
Fonte: habr.com
