

Se la tua infrastruttura IT cresce troppo rapidamente, prima o poi ti troverai di fronte a una scelta: aumentare linearmente le risorse umane per supportarla o iniziare ad automatizzarla. Fino a un certo punto, abbiamo vissuto nella prima parabola, e poi è iniziato un lungo percorso verso l'Infrastructure-as-Code.

Naturalmente, NSPK non è una startup, ma un'atmosfera simile regnava in azienda nei primi anni della sua esistenza, ed erano anni molto interessanti. Mi chiamo , da oltre 10 anni supporto un'infrastruttura Linux con elevate esigenze di disponibilità. Sono entrato a far parte del team di NSPK a gennaio 2016 e, purtroppo, non ho vissuto l'inizio dell'esistenza dell'azienda, ma ho fatto il mio ingresso in un periodo di grandi cambiamenti.
In generale, si può dire che il nostro team fornisce due prodotti per l'azienda. Il primo è l'infrastruttura. La posta deve funzionare, il DNS deve essere attivo e i controller di dominio devono permettervi di accedere ai server, i quali non devono mai andare offline. Il panorama IT dell'azienda è vasto! Si tratta di sistemi critici per il business e la missione, con requisiti di disponibilità per alcuni pari al 99,999. Il secondo prodotto sono i server stessi, fisici e virtuali. È necessario monitorare quelli esistenti e fornire regolarmente nuovi server ai clienti di diversi dipartimenti. In questo articolo voglio mettere in evidenza come abbiamo sviluppato l'infrastruttura che gestisce il ciclo di vita. server.
Inizio del viaggio
All'inizio del percorso, il nostro stack tecnologico era così composto:
OS CentOS 7
Controller di dominio FreeIPA
Automazione — Ansible(+Tower), Cobbler
Tutto ciò era suddiviso in 3 domini, distribuiti su vari data center. In un data center si trovavano i sistemi per ufficio e i laboratori di test, negli altri invece i sistemi di produzione.
La creazione dei server a un certo punto appariva così:
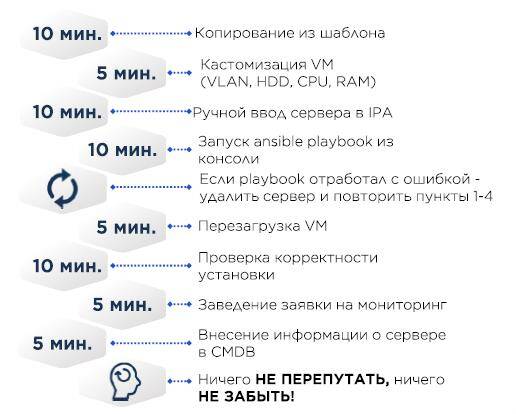
Nel template VM CentOS minimal e il minimo indispensabile come un corretto /etc/resolv.conf, il resto arriva tramite Ansible.
CMDB – Excel.
Se il server è fisico, invece di copiare una macchina virtuale, il sistema operativo veniva installato utilizzando Cobbler: gli indirizzi MAC del server di destinazione vengono aggiunti alla configurazione di Cobbler, il server ottiene un indirizzo IP tramite DHCP e poi viene installato il sistema operativo.
All'inizio abbiamo anche provato a gestire la configurazione tramite Cobbler. Ma col tempo, ciò ha iniziato a causare problemi con la portabilità delle configurazioni, sia per i diversi data center che per il codice Ansible per la preparazione delle VM.
All'epoca, molti di noi consideravano Ansible come un'estensione utile di Bash e non esitavano ad usare costrutti con shell e sed. Insomma, era una specie di Bashsible. Questo portava al fatto che, se un playbook per qualche motivo non funzionava sul server, era più semplice eliminare il server, correggere il playbook e eseguirlo nuovamente. Di fatto non c'era versione dei script e neanche portabilità delle configurazioni.
Ad esempio, abbiamo voluto modificare qualche configurazione su tutti i server:
- Modifichiamo la configurazione sui server esistenti nel segmento logico/CED. A volte non in un giorno: le esigenze di disponibilità e la legge dei grandi numeri non consentono di applicare tutte le modifiche contemporaneamente. Alcuni cambiamenti sono potenzialmente distruttivi e richiedono il riavvio di qualcosa, dai servizi al sistema operativo stesso.
- Correzioni in Ansible
- Correzioni in Cobbler
- Ripetiamo N volte per ogni segmento logico/CED
Per garantire che tutte le modifiche avvengano senza problemi, è necessario considerare numerosi fattori, e i cambiamenti sono costanti.
- Refactoring del codice ansible, dei file di configurazione
- Modifica delle best practice interne
- Modifiche a seguito di incidenti/eventi di emergenza
- Modifica degli standard di sicurezza, sia interni che esterni. Ad esempio, il PCI DSS viene aggiornato ogni anno con nuovi requisiti
Crescita dell'infrastruttura e inizio di un percorso
Il numero di server/domini logici/CED è aumentato, così come il numero di errori nelle configurazioni. A un certo punto siamo giunti a tre direzioni verso cui sviluppare la gestione della configurazione:
- Automazione. Per quanto possibile, è necessario evitare il fattore umano in operazioni ripetitive.
- Ripetibilità. Gestire l'infrastruttura diventa molto più semplice quando è prevedibile. La configurazione dei server e degli strumenti per la loro preparazione deve essere uniforme ovunque. Questo è altrettanto importante per i team di prodotto: l'applicazione deve garantire di passare in produzione, configurata in modo analogo a quella di test dopo i collaudi.
- Semplicità e trasparenza nella gestione delle modifiche nella configuration management.
Manca solo l'aggiunta di alcuni strumenti.
Come repository per il codice abbiamo scelto GitLab CE, non da ultimo per la disponibilità di moduli CI/CD integrati.
Il nostro sistema di gestione delle segreti è Hashicorp Vault, anche per la sua eccellente API.
Testare le configurazioni e i ruoli Ansible – Molecule+Testinfra. I test sono molto più veloci se si usa Ansible con mitogen. Nel frattempo, abbiamo iniziato a scrivere il nostro CMDB e un orchestratore per il deployment automatico (nella figura sopra Cobbler), ma questa è un'altra storia, di cui parlerà in futuro il mio collega e principale sviluppatore di questi sistemi.
La nostra scelta:
Molecule + Testinfra
Ansible + Tower + AWX
Mondo Server + DITNET (sviluppo interno)
Cobbler
GitLab + GitLab runner
Hashicorp Vault

A proposito dei ruoli Ansible. Inizialmente c'era solo un ruolo, dopo diversi refactoring sono diventati 17. Raccomando categoricamente di suddividere il monolite in ruoli idempotenti, che possono poi essere eseguiti separatamente, potete anche aggiungere dei tag. Abbiamo suddiviso i ruoli in base alle funzionalità - rete, logging, pacchetti, hardware, molecola, ecc. In generale, ci siamo attenuti alla strategia qui sotto. Non insisto sul fatto che sia la verità in un'unica istanza, ma ha funzionato per noi.
- La copia dei server da un 'immagine d'oro' è un male!Tra i principali difetti, non sai esattamente in che stato si trovano le immagini attualmente e che tutte le modifiche si riflettono su tutte le immagini in tutte le farm di virtualizzazione.
- Utilizza i file di configurazione di default il meno possibile e accordati con le altre divisioni su quali file di sistema principali sei responsabile tu., ad esempio:
- Tieni vuoto il file /etc/sysctl.conf, le impostazioni devono trovarsi solo in /etc/sysctl.d/. Il tuo default in un file, il custom per l'applicazione in un altro.
- Utilizza file di override per modificare le unità systemd.
- Template tutte le configurazioni e inseriscile interamente, evita in modo possibile comandi sed e simili nei playbook.
- Refactoring del codice del sistema di gestione delle configurazioni:
- Suddividi i compiti in entità logiche e riscrivi il monolite in ruoli
- Usa i linter! Ansible-lint, yaml-lint, ecc.
- Cambia approccio! Niente bashsible. È necessario descrivere lo stato del sistema
- Per ogni ruolo Ansible è necessario scrivere test in molecule e generare report una volta al giorno.
- Nel nostro caso, dopo aver preparato i test (che sono più di 100) sono state trovate circa 70.000 errori. Ci siamo messi a correggere per diversi mesi.

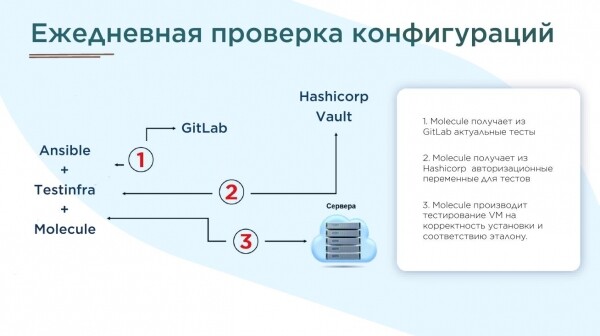
La nostra implementazione
Quindi, i ruoli Ansible erano pronti, templati e controllati dai linter. E anche i repository sono stati sollevati ovunque. Ma la questione della consegna affidabile del codice in diverse aree è rimasta aperta. Abbiamo deciso di sincronizzarci tramite script. Ecco come appare:
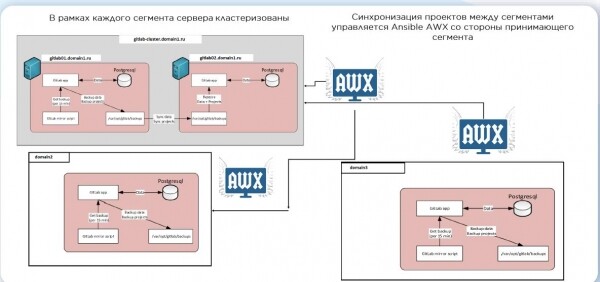
Dopo che la modifica è arrivata, si avvia il CI, si crea un server di test, si applicano i ruoli e si testano le molecole. Se tutto è a posto, il codice viene inviato nel ramo di produzione. Tuttavia, non applichiamo il nuovo codice sui server esistenti in modo automatico. Questo funge da freno, necessario per garantire l'alta disponibilità dei nostri sistemi. E quando l'infrastruttura diventa enorme, entra in gioco anche la legge dei grandi numeri: anche se sei certo che la modifica sia innocua, potrebbe portare a conseguenze spiacevoli.
Esistono molte opzioni per creare server. Alla fine, abbiamo scelto script personalizzati in Python. E per il CI, Ansible:
- name: create1.yml - Creare una VM da un modello
vmware_guest:
hostname: "{{datacenter}}".domain.ru
username: "{{ username_vc }}"
password: "{{ password_vc }}"
validate_certs: no
cluster: "{{cluster}}"
datacenter: "{{datacenter}}"
name: "{{ name }}"
state: poweredon
folder: "/{{folder}}"
template: "{{template}}"
customization:
hostname: "{{ name }}"
domain: domain.ru
dns_servers:
- "{{ ipa1_dns }}"
- "{{ ipa2_dns }}"
networks:
- name: "{{ network }}"
type: static
ip: "{{ip}}"
netmask: "{{netmask}}"
gateway: "{{gateway}}"
wake_on_lan: True
start_connected: True
allow_guest_control: True
wait_for_ip_address: yes
disk:
- size_gb: 1
type: thin
datastore: "{{datastore}}"
- size_gb: 20
type: thin
datastore: "{{datastore}}"Ecco dove siamo arrivati, il sistema continua a vivere e svilupparsi.
- 17 ruoli Ansible per la configurazione del server. Ognuno dei ruoli è progettato per risolvere un compito logico specifico (registrazione, audit, autorizzazione utenti, monitoraggio, ecc.).
- Test dei ruoli. Molecule + TestInfra.
- Sviluppo interno: CMDB + Orchestratore.
- Tempo di creazione del server ~30 minuti, automatizzato e praticamente indipendente dalla coda delle attività.
- Stato e denominazione uniformi dell'infrastruttura in tutti i segmenti – playbook, repository, elementi di virtualizzazione.
- Verifica quotidiana dello stato dei server con generazione di report sulle discrepanze rispetto allo standard.
Spero che la mia esperienza sia utile a chi è all'inizio del proprio percorso. E quale stack di automazione utilizzate voi?
Fonte: habr.com
