

In questo articolo, parlerò di come abbiamo affrontato il problema della resilienza di PostgreSQL, perché è diventato importante per noi e quali risultati abbiamo ottenuto.
Gestiamo un servizio ad alta intensità di carico: 2,5 milioni di utenti in tutto il mondo, con oltre 50.000 utenti attivi ogni giorno. I server sono situati in Amazon in un'unica regione dell'Irlanda: sono sempre in funzione più di 100 server, di cui quasi 50 dedicati a basi di dati.
L'intero backend è un grande applicativo monolitico stateful in Java, che mantiene una connessione websocket costante con il cliente. Quando più utenti lavorano contemporaneamente su una bacheca, vedono tutti le modifiche in tempo reale, perché ogni cambiamento viene registrato nel database. Riceviamo circa 10.000 richieste al secondo ai nostri database. Durante i picchi di carico, in Redis scriviamo tra 80.000 e 100.000 richieste al secondo.
Perché siamo passati da Redis a PostgreSQL
Inizialmente, il nostro servizio operava con Redis, un archivio key-value che memorizza tutti i dati in memoria. server.
Vantaggi di Redis:
- Alta velocità di risposta, poiché tutto è memorizzato nella memoria;
- Facilità di backup e replicazione.
Svantaggi di Redis per noi:
- Non ci sono transazioni reali. Abbiamo cercato di simularle a livello della nostra applicazione. Sfortunatamente, non sempre ha funzionato bene e ha richiesto la scrittura di codice molto complesso.
- Il volume dei dati è limitato dalla quantità di memoria. Aumentando la quantità di dati, la memoria crescerà e, alla fine, ci imbatteremo nelle caratteristiche dell'istanza selezionata, il che su AWS richiede l'interruzione del nostro servizio per modificare il tipo di istanza.
- È necessario mantenere costantemente un basso livello di latenza, poiché abbiamo un numero molto elevato di richieste. Il nostro livello di latenza ottimale è di 17-20 ms. A livelli di 30-40 ms, riceviamo risposte lente alle richieste della nostra applicazione e un degrado del servizio. Sfortunatamente, è successo a settembre 2018, quando uno degli istanze con Redis ha ricevuto per qualche motivo una latenza doppia rispetto al normale. Per risolvere il problema, abbiamo interrotto il servizio a metà giornata per una manutenzione straordinaria e sostituito l'istanza Redis problematica.
- È facile avere incoerenza nei dati anche con piccoli errori nel codice e poi spendere molto tempo a scrivere codice per correggere questi dati.
Abbiamo preso in considerazione gli svantaggi e abbiamo capito che era necessario migrare verso qualcosa di più conveniente, con transazioni adeguate e minore dipendenza dalla latenza. Abbiamo condotto ricerche, analizzato molte opzioni e scelto PostgreSQL.
Stiamo migrando verso il nuovo database da 1,5 anni e abbiamo trasferito solo una piccola parte dei dati, quindi ora stiamo lavorando contemporaneamente con Redis e PostgreSQL. Maggiori dettagli sulle fasi della migrazione e sul passaggio dei dati tra i database sono riportati in un articolo del mio collega.
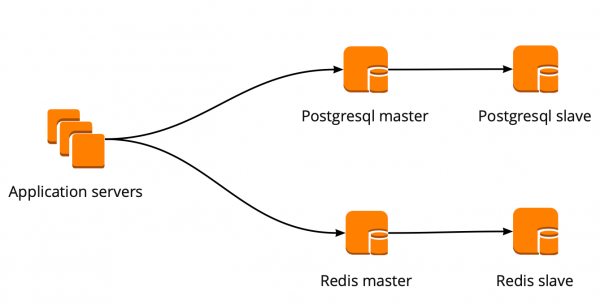
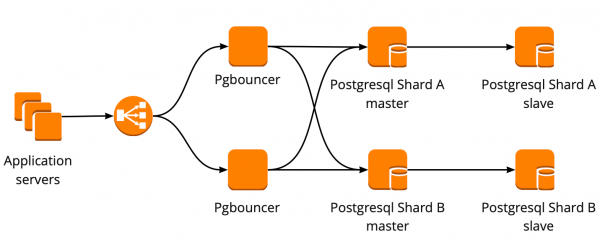
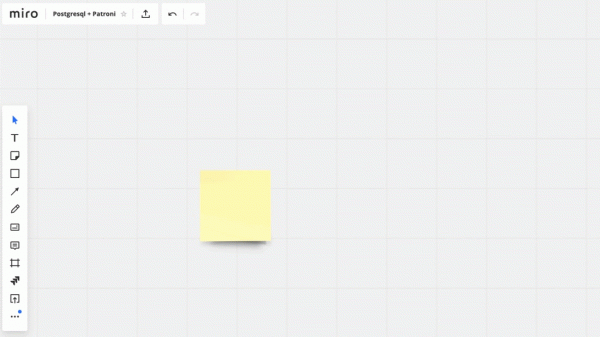
Quando abbiamo iniziato a migrare, la nostra applicazione interagiva direttamente con il database e si collegava al master Redis e PostgreSQL. Il cluster PostgreSQL era composto da un master e una replica con replica asincrona. Questo è come appariva lo schema di funzionamento con i database:
Implementazione di PgBouncer
Mentre ci trasferivamo, anche il prodotto si è evoluto: il numero di utenti e di server che lavoravano con PostgreSQL è aumentato, e abbiamo cominciato a sperimentare carenze di connessioni. PostgreSQL crea un processo separato per ogni connessione e consuma risorse. È possibile aumentare il numero di connessioni solo fino a un certo punto, altrimenti si rischia di avere prestazioni non ottimali del DB. In una situazione simile, la scelta di un gestore di connessioni che si interponga tra l'applicazione e il database è l'opzione migliore.
Avevamo due opzioni per il gestore di connessioni: Pgpool e PgBouncer. Tuttavia, il primo non supporta la modalità di lavoro transazionale con il database, quindi abbiamo scelto PgBouncer.
Abbiamo impostato il seguente schema di lavoro: la nostra applicazione si connette a un PgBouncer, dietro il quale ci sono i master di PostgreSQL, e dietro ogni master c'è una replica con replica asincrona.
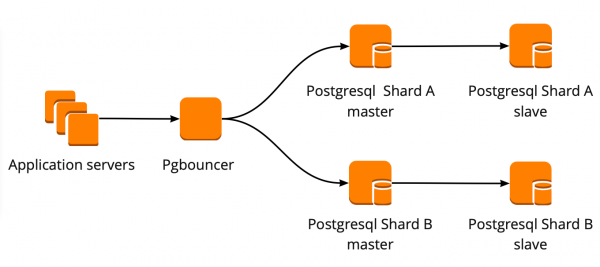
Tuttavia, non potevamo memorizzare l'intero volume di dati in PostgreSQL e per noi era importante la velocità del lavoro con il database, quindi abbiamo iniziato a shardare PostgreSQL a livello applicativo. Lo schema descritto sopra è relativamente comodo per questo: aggiungendo un nuovo shard, è sufficiente aggiornare la configurazione di PgBouncer e l'applicazione può subito lavorare con il nuovo shard.
Affidabilità di PgBouncer
Questo schema ha funzionato fino a quando l'unico istanza di PgBouncer non è andata in down. Siamo su AWS, dove tutte le istanze sono eseguite su hardware che periodicamente può guastarsi. In questi casi, l'istanza semplicemente si sposta su un nuovo hardware e riprende a funzionare. È successo anche con PgBouncer, ma è diventato inaccessibile. Come risultato di questo guasto, il nostro servizio è stato inattivo per 25 minuti. AWS consiglia di utilizzare la ridondanza dal lato dell'utente per tali situazioni, ma noi non l'avevamo implementata in quel momento.
Dopo ciò, abbiamo seriamente considerato l'affidabilità di PgBouncer e dei cluster PostgreSQL, poiché una situazione del genere potrebbe ripetersi con qualsiasi istanza nel nostro account AWS.
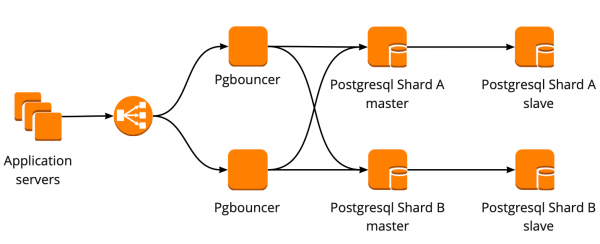
Abbiamo costruito lo schema di alta disponibilità per PgBouncer nel seguente modo: tutti i server applicativi fanno riferimento a un Network Load Balancer, dietro il quale si trovano due PgBouncer. Ognuno dei PgBouncer punta ai medesimi master PostgreSQL di ciascuno shard. In caso di ripetizione della situazione di inattività di un'istanza AWS, tutto il traffico viene reindirizzato attraverso un altro PgBouncer. L'alta disponibilità del Network Load Balancer è garantita da AWS.
Questo schema consente di aggiungere nuovi server PgBouncer senza problemi.
Creazione di un cluster PostgreSQL ad alta disponibilità
Nella risoluzione di questo compito, abbiamo considerato diverse opzioni: failover personalizzato, repmgr, AWS RDS, Patroni.
Script personalizzati
Possono monitorare il funzionamento del master e, in caso di caduta, promuovere la replica a master e aggiornare la configurazione di PgBouncer.
I vantaggi di questo approccio risiedono nella massima semplicità, poiché scrivete voi stessi gli script e capite esattamente come funzionano.
Contro:
- Il master potrebbe non essere morto; invece, potrebbe essersi verificato un guasto di rete. Il failover, ignaro di ciò, promuoverà la replica a master, mentre il vecchio master continuerà a funzionare. Di conseguenza, avremo due server in modalità master e non sapremo su quale di essi siano i dati più recenti. Questa situazione è anche chiamata split-brain.
- Siamo rimasti senza replica. Nella nostra configurazione, ci sono un master e una replica, e dopo il failover la replica viene promossa a master, quindi non abbiamo più repliche e dobbiamo aggiungere manualmente una nuova replica.
- È necessario un monitoraggio aggiuntivo del failover; abbiamo 12 shard PostgreSQL, quindi dobbiamo monitorare 12 cluster. Aumentando il numero di shard, non dimentichiamo di aggiornare il failover.
Un failover personalizzato sembra molto complesso e richiede manutenzione non banale. Con un solo cluster PostgreSQL, sarebbe l'opzione più semplice, ma non è scalabile, quindi non è adatta a noi.
Repmgr
Replication Manager per cluster PostgreSQL, che gestisce il funzionamento del cluster PostgreSQL. Tuttavia, non dispone di failover automatico “di serie”, quindi sarà necessario scrivere un proprio “wrapper” sopra la soluzione esistente. Quindi, potrebbe risultare anche più complesso rispetto a script scritti da zero, motivo per cui non abbiamo nemmeno provato Repmgr.
AWS RDS
Supporta tutto il necessario per noi, è in grado di fare backup e gestisce un pool di connessioni. Ha uno switch automatico: alla morte del master, la replica diventa il nuovo master, e AWS cambia il record DNS al nuovo master, mentre le repliche possono trovarsi in diverse AZ.
Tra i lati negativi si può citare l'assenza di impostazioni dettagliate. Ad esempio, impostazioni dettagliate: sulle nostre istanze ci sono limitazioni per le connessioni TCP, cosa che purtroppo non possiamo fare in RDS:
net.ipv4.tcp_keepalive_time=10
net.ipv4.tcp_keepalive_intvl=1
net.ipv4.tcp_keepalive_probes=5
net.ipv4.tcp_retries2=3
Inoltre, il prezzo di AWS RDS è quasi il doppio del prezzo normale delle istanze, che è stata la principale causa del rifiuto di questa soluzione.
Patroni
È un template in Python per gestire PostgreSQL con una buona documentazione, failover automatico e codice sorgente su GitHub.
Vantaggi di Patroni:
- Ogni parametro di configurazione è dettagliato, rendendo chiaro come funziona ogni parte.
- Il failover automatico funziona out-of-the-box.
- Scritto in Python, e poiché anche noi scriviamo molto in Python, sarà più facile risolvere problemi e, forse, anche aiutare lo sviluppo del progetto.
- Gestisce completamente PostgreSQL, permette di modificare la configurazione su tutti i nodi del cluster e, se è necessario riavviare il cluster per applicare la nuova configurazione, questo può essere fatto ancora con Patroni.
Contro:
- Dalla documentazione non è chiaro come lavorare correttamente con PgBouncer. Sebbene non sia facile definire questo un difetto, perché il compito di Patroni è gestire PostgreSQL, mentre gestire come avvengono le connessioni a Patroni è già un nostro problema.
- Ci sono pochi esempi di implementazione di Patroni su larga scala, mentre ci sono molti esempi di implementazione da zero.
In definitiva, per creare un cluster ad alta disponibilità abbiamo scelto proprio Patroni.
Il processo di implementazione di Patroni.
Prima di Patroni avevamo 12 shard di PostgreSQL in una configurazione con un master e una replica con replica asincrona. I server delle applicazioni si collegavano ai database tramite un Network Load Balancer, dietro al quale c'erano due istanze con PgBouncer, e dietro di essi si trovavano tutti i server PostgreSQL.
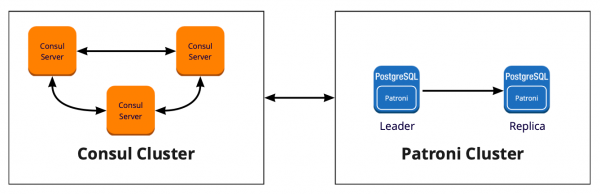
Per implementare Patroni, abbiamo dovuto scegliere uno storage distribuito per la configurazione del cluster. Patroni funziona con sistemi distribuiti di storage della configurazione, come etcd, Zookeeper e Consul. Abbiamo infatti un cluster Consul completamente operativo in produzione, che lavora in sinergia con Vault e non lo utilizziamo in altro modo. È un'ottima occasione per iniziare a usare Consul come previsto.
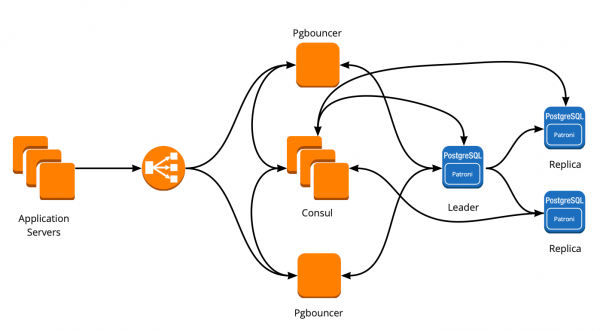
Come funziona Patroni con Consul
Abbiamo un cluster Consul composto da tre nodi e un cluster Patroni, costituito da un leader e da repliche (in Patroni, il master è chiamato leader del cluster e gli slave sono repliche). Ogni istanza del cluster Patroni invia continuamente a Consul informazioni sullo stato del cluster. Pertanto, da Consul è sempre possibile conoscere la configurazione attuale del cluster Patroni e chi è il leader in quel momento.
Per connettere Patroni a Consul, è sufficiente consultare la documentazione ufficiale, che specifica che è necessario indicare l'host nel formato http o https a seconda di come lavoriamo con Consul, e lo schema di connessione, opzionalmente:
host: l'host:port per il punto finale di Consul, nel formato: http(s)://host:port
schema: (opzionale) http o https, predefinito a httpSembra semplice, ma qui iniziano le insidie. Con Consul lavoriamo tramite una connessione sicura https e la nostra configurazione di connessione sarà simile a questa:
consul:
host: https://server.production.consul:8080
verify: true
cacert: {{ consul_cacert }}
cert: {{ consul_cert }}
key: {{ consul_key }}Ma così non funziona. All'avvio, Patroni non riesce a connettersi a Consul perché continua a tentare di utilizzare http.
Comprendere il problema è stato possibile grazie al codice sorgente di Patroni. È un bene che sia scritto in Python. Risulta che il parametro host non venga elaborato e il protocollo debba essere specificato in scheme. Ecco come appare un blocco di configurazione funzionante per l'uso con Consul:
consul:
host: server.production.consul:8080
scheme: https
verify: true
cacert: {{ consul_cacert }}
cert: {{ consul_cert }}
key: {{ consul_key }}Consul-template
Quindi, abbiamo scelto un archivio per la configurazione. Ora è necessario capire come PgBouncer cambierà la sua configurazione al cambiamento del leader nel cluster di Patroni. Nella documentazione non c'è una risposta a questa domanda, poiché in generale non viene descritta l'interazione con PgBouncer.
Nella ricerca di una soluzione, abbiamo trovato un articolo (purtroppo non ricordo il titolo) che affermava che Consul-template fosse molto utile nell'integrazione tra PgBouncer e Patroni. Questo ci ha spinto ad esplorare il funzionamento di Consul-template.
Si è scoperto che il Consul-template monitora continuamente la configurazione del cluster PostgreSQL su Consul. Quando cambia il leader, aggiorna la configurazione di PgBouncer e invia il comando per il suo riavvio.
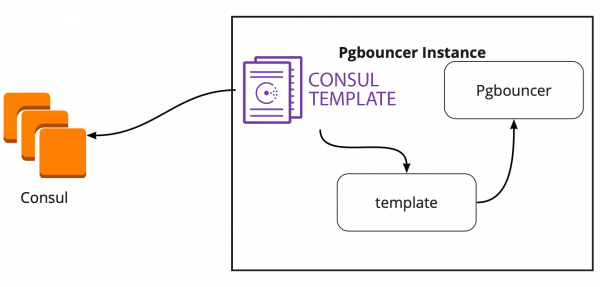
Un grande vantaggio del template è che è memorizzato come codice, quindi quando si aggiunge un nuovo shard, è sufficiente effettuare un nuovo commit e aggiornare automaticamente il template, mantenendo il principio dell'infrastruttura come codice.
Nuova architettura con Patroni
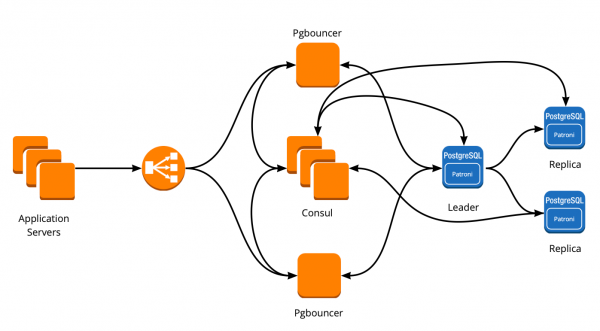
Di conseguenza, abbiamo ottenuto questo schema di lavoro:
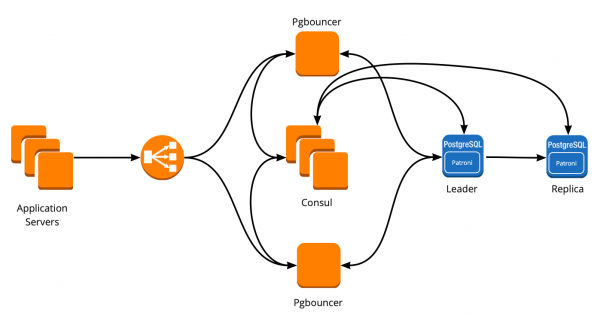
Tutti i server dell'applicazione si collegano al bilanciatore → dietro di esso ci sono due istanze di PgBouncer → in ogni istanza è in esecuzione Consul-template, che monitora lo stato di ogni cluster Patroni e verifica la validità della configurazione di PgBouncer, che indirizza le richieste al leader attuale di ogni cluster.
Test manuale
Prima di passare alla produzione, abbiamo eseguito questo schema in un piccolo ambiente di test e abbiamo verificato il funzionamento del passaggio automatico. Abbiamo aperto la bacheca, spostato un adesivo e in quel momento 'abbiamo ucciso' il leader del cluster. In AWS, per fare questo, è sufficiente spegnere l'istanza tramite la console.
L'adesivo tornava indietro per 10-20 secondi e poi iniziava a muoversi normalmente. Questo significa che il cluster Patroni ha funzionato correttamente: ha cambiato leader, ha inviato informazioni a Consul, e il template Consul ha subito acquisito queste informazioni, aggiornando la configurazione di PgBouncer e inviando il comando di reload.
Come sopravvivere a carichi elevati e mantenere un downtime minimo?
Tutto funziona alla grande! Ma sorgono nuove domande: come funzionerà sotto carico elevato? Come distribuire tutto in produzione in modo rapido e sicuro?
Per rispondere alla prima domanda, ci aiuta un ambiente di test in cui eseguiamo test di carico. È completamente identico alla produzione per architettura e dispone di dati di test generati, che hanno un volume approssimativamente uguale alla produzione. Decidiamo semplicemente di 'uccidere' uno dei master PostgreSQL durante il test e vedere cosa succede. Ma prima è importante verificare il rollout automatico, poiché in questo ambiente abbiamo diversi shard PostgreSQL, quindi avremo un ottimo test degli script di configurazione prima della produzione.
Entrambi i compiti sembrano ambiziosi, ma abbiamo PostgreSQL 9.6. Forse aggiorniamo subito alla 11.2?
Ci proponiamo di farlo in 2 fasi: prima aggiornare la versione a 11.2, poi avviare Patroni.
Aggiornamento di PostgreSQL
Per un aggiornamento rapido della versione di PostgreSQL è necessario utilizzare l’opzione -k, che crea hard link sul disco ed elimina la necessità di copiare i tuoi dati. Su database da 300-400 GB, l'aggiornamento richiede 1 secondo.
Abbiamo molti shard, quindi l'aggiornamento deve essere fatto in modo automatico. A tal fine, abbiamo scritto un playbook Ansible che esegue l'intero processo di aggiornamento per noi:
/usr/lib/postgresql/11/bin/pg_upgrade
<b>--link </b>
--old-datadir='' --new-datadir=''
--old-bindir='' --new-bindir=''
--old-options=' -c config_file='
--new-options=' -c config_file='È importante notare che prima di avviare l'aggiornamento, è necessario eseguirlo con il parametro —check, per essere certi della possibilità di aggiornamento. Inoltre, il nostro script fa il cambio delle configurazioni durante l'aggiornamento. Il nostro script è stato eseguito in 30 secondi, un ottimo risultato.
Avvio di Patroni
Per risolvere il secondo problema, basta dare un'occhiata alla configurazione di Patroni. Nel repository ufficiale c'è un esempio di configurazione con initdb, che si occupa di inizializzare un nuovo database al primo avvio di Patroni. Ma poiché abbiamo già un database pronto, abbiamo semplicemente rimosso questa sezione dalla configurazione.
Quando abbiamo iniziato a installare Patroni su un cluster PostgreSQL esistente e ad avviarlo, ci siamo imbattuti in un nuovo problema: entrambi i server si avviavano come leader. Patroni non conosce lo stato precedente del cluster e cerca di avviare entrambi i server come due cluster separati con lo stesso nome. Per risolvere questo problema, è necessario eliminare la directory dei dati sul server secondario:
rm -rf /var/lib/postgresql/Questo deve essere fatto solo sul server secondario!
Quando si connette una replica pulita, Patroni esegue il basebackup del leader e lo ripristina sulla replica, quindi recupera lo stato attuale attraverso i log WAL.
Un'altra difficoltà che abbiamo incontrato è che tutti i cluster PostgreSQL sono chiamati main per impostazione predefinita. Quando ogni cluster non sa nulla dell'altro, va bene. Ma quando si desidera utilizzare Patroni, tutti i cluster devono avere un nome unico. La soluzione è cambiare il nome del cluster nella configurazione di PostgreSQL.
Test di carico
Abbiamo avviato un test che simula l'attività degli utenti sui server. Quando il carico ha raggiunto la nostra media giornaliera, abbiamo ripetuto esattamente lo stesso test, disattivando un'istanza con leader PostgreSQL. Il failover automatico ha funzionato come previsto: Patroni ha cambiato leader, Consul-template ha aggiornato la configurazione di PgBouncer e ha inviato il comando per il reload. Dai nostri grafici in Grafana si vedeva che c'erano ritardi di 20-30 secondi e un piccolo numero di errori dai server, legati alla connessione al database. Questa è una situazione normale, tali valori sono accettabili per il nostro failover e sono sicuramente migliori di un downtime del servizio.
Output di Patroni in produzione
Alla fine, abbiamo ottenuto il seguente piano:
- Deployment di Consul-template sui server PgBouncer e avvio;
- Aggiornamenti di PostgreSQL alla versione 11.2;
- Cambio del nome del cluster;
- Avvio del cluster Patroni.
In questo modo, il nostro schema consente di eseguire il primo punto praticamente in qualsiasi momento, possiamo rimuovere ogni PgBouncer a turno e procedere con il deployment e l'avvio di consul-template. E così abbiamo fatto.
Per una rapida implementazione, abbiamo utilizzato Ansible, poiché avevamo già testato tutti i playbook in un ambiente di test, e il tempo di esecuzione dell'intero scenario variava da 1,5 a 2 minuti per ogni shard. Avevamo la possibilità di rilasciarli uno dopo l'altro per ogni shard senza interrompere il nostro servizio, ma avremmo dovuto spegnere brevemente ciascun PostgreSQL. In tal caso, gli utenti i cui dati erano su quel shard non sarebbero stati in grado di lavorare correttamente in quel momento, il che è inaccettabile per noi.
La soluzione a questa situazione è stata una manutenzione programmata, che si tiene ogni 3 mesi. Questo è un intervallo per lavori pianificati, durante il quale spegniamo completamente il nostro servizio e aggiorniamo le istanze dei database. Una settimana prima della prossima finestra, abbiamo deciso di aspettare e prepararci ulteriormente. Durante il periodo di attesa, abbiamo preso ulteriori precauzioni: per ogni shard PostgreSQL abbiamo attivato una replica di backup in caso di guasti, per mantenere i dati più recenti, e abbiamo aggiunto una nuova istanza per ciascuno shard, che diventerà la nuova replica nel cluster Patroni, evitando così di eseguire il comando per eliminare i dati. Tutto ciò ha contribuito a ridurre al minimo il rischio di errore.
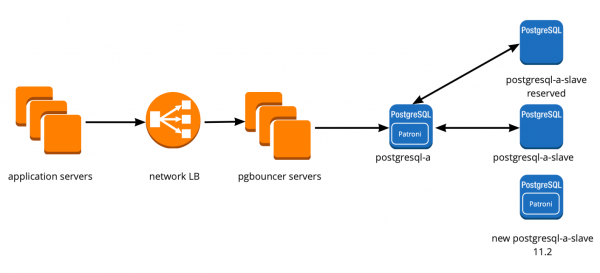
Abbiamo riavviato il nostro servizio, tutto ha funzionato come previsto, gli utenti hanno continuato a lavorare, ma nei grafici abbiamo notato un carico anomalo sui server Consul.
Perché non abbiamo visto questo nell'ambiente di test? Questo problema illustra chiaramente la necessità di seguire il principio di Infrastructure as code e di migliorare tutta l'infrastruttura, partendo dagli ambienti di test fino alla produzione. Altrimenti, è molto facile imbattersi in un problema come quello che abbiamo avuto. Cosa è successo? Consul è stato inizialmente implementato in produzione e poi negli ambienti di test; alla fine, la versione di Consul negli ambienti di test era superiore a quella in produzione. Proprio in uno degli aggiornamenti è stata risolta una perdita di CPU durante l'uso di consul-template. Pertanto, abbiamo semplicemente aggiornato Consul, risolvendo così il problema.
Riavviare il cluster Patroni
Tuttavia, abbiamo riscontrato un nuovo problema di cui non sospettavamo nemmeno. Durante l'aggiornamento di Consul, rimuoviamo semplicemente il nodo Consul dal cluster con il comando consul leave → Patroni si collega a un altro server Consul → tutto funziona. Ma quando siamo arrivati all'ultimo nodo del cluster Consul e abbiamo inviato il comando consul leave, tutti i cluster Patroni si sono semplicemente riavviati e nei log abbiamo visto il seguente errore:
ERRORE: get_cluster
Traccia (chiamata più recente in alto):
...
RetryFailedError: 'Scadenza di ripetizione superata'
ERRORE: Errore nella comunicazione con DCS
<b>LOG: il sistema del database è stato chiuso</b>Il cluster Patroni non è riuscito a ottenere informazioni sul proprio cluster ed è stato riavviato.
Per cercare una soluzione, ci siamo rivolti agli autori di Patroni tramite issue su GitHub. Hanno suggerito di migliorare i nostri file di configurazione:
consul:
consul.checks: []
bootstrap:
dcs:
retry_timeout: 8Siamo riusciti a riprodurre il problema in un ambiente di test e abbiamo testato questi parametri, ma, sfortunatamente, non hanno funzionato.
Il problema rimane irrisolto. Prevediamo di provare le seguenti opzioni per risolverlo:
- Utilizzare il Consul-agent su ogni istanza del cluster Patroni;
- Correggere il problema nel codice.
Ci è chiaro il luogo di provenienza dell'errore: probabilmente, il problema è nell'uso del timeout predefinito, che non viene sovrascritto dal file di configurazione. Quando si rimuove l'ultimo server Consul dal cluster, si verifica un blocco dell'intero cluster Consul, che dura più di un secondo, impedendo così a Patroni di ottenere lo stato del cluster e costringendo il riavvio completo dell'intero cluster.
Fortunatamente, non abbiamo riscontrato ulteriori errori.
Sintesi dell'utilizzo di Patroni
Dopo il successo del lancio di Patroni, abbiamo aggiunto un'ulteriore replica in ogni cluster. Ora, in ogni cluster esiste una sorta di quorum: un leader e due repliche, per una maggiore sicurezza in caso di split-brain durante il failover.
In produzione, Patroni è attivo da oltre tre mesi. Durante questo periodo, ci ha già salvati. Recentemente, in AWS, il leader di uno dei cluster è andato offline, il failover automatico ha funzionato e gli utenti hanno potuto continuare a lavorare. Patroni ha svolto il suo compito principale.
Un breve riepilogo dell'utilizzo di Patroni:
- Comodità nel cambiare la configurazione. È sufficiente modificare la configurazione su un'istanza e questa si propagherà a tutto il cluster. Se è necessario un riavvio per applicare la nuova configurazione, Patroni lo segnalerà. Patroni può riavviare l'intero cluster con un solo comando, il che è molto comodo.
- Il failover automatico funziona e ci ha già salvati.
- Aggiornamento di PostgreSQL senza downtime per l'applicazione. È necessario aggiornare prima le repliche alla nuova versione, poi cambiare il leader nel cluster Patroni e aggiornare il vecchio leader. Durante questo procedimento, avviene il necessario test del failover automatico.
Fonte: habr.com
