


Пару лет назад Kubernetes в официальном блоге GitHub. С тех пор он стал стандартной технологией для развёртывания сервисов. Теперь Kubernetes управляет значительной частью внутренних и публичных служб. Поскольку наши кластеры выросли, а требования к производительности стали более жёсткими, мы стали замечать, что в некоторых службах на Kubernetes спорадически появляются задержки, которые нельзя объяснить нагрузкой самого приложения.
По сути, в приложениях происходит будто случайная сетевая задержка до 100 мс и более, что приводит к тайм-аутам или повторным попыткам. Ожидалось, что службы смогут отвечать на запросы гораздо быстрее 100 мс. Но это невозможно, если само соединение отнимает столько времени. Отдельно мы наблюдали очень быстрые запросы MySQL, которые должны были занимать миллисекунды, и MySQL действительно справлялась за миллисекунды, но с точки зрения запрашивающего приложения ответ занимал 100 мс или больше.
Сразу стало понятно, что проблема возникает только при соединении с узлом Kubernetes, даже если вызов приходил извне Kubernetes. Проще всего воспроизвести проблему в тесте , который запускается с любого внутреннего хоста, тестирует службу Kubernetes на определённом порту, и спорадически регистрирует большую задержку. В этой статье рассмотрим, как нам удалось отследить причину этой проблемы.
Устраняем лишнюю сложность в цепочке к сбою
Воспроизведя один и тот же пример, мы хотели сузить фокус проблемы и удалить лишние слои сложности. Первоначально в потоке между Vegeta и pod’ами на Kubernetes было слишком много элементов. Чтобы определить более глубокую сетевую проблему, нужно исключить некоторые из них.
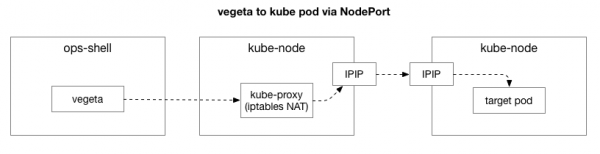
Клиент (Vegeta) создаёт TCP-соединение с любым узлом в кластере. Kubernetes работает как оверлейная сеть (поверх существующей сети дата-центра), которая использует , то есть инкапсулирует IP-пакеты оверлейной сети внутрь IP-пакетов дата-центра. При подключении к первому узлу выполняется преобразование сетевых адресов (NAT) с отслеживанием состояния для преобразования IP-адреса и порта узла Kubernetes в IP-адрес и порт в оверлейной сети (в частности, pod’а с приложением). Для поступивших пакетов выполняется обратная последовательность действий. Это сложная система с большим количеством состояний и множеством элементов, которые постоянно обновляются и изменяются по мере развёртывания и перемещения служб.
Utility tcpdump в тесте Vegeta даёт задержку во время рукопожатия TCP (между SYN и SYN-ACK). Чтобы убрать эту излишнюю сложность, можно использовать hping3 для простых «пингов» пакетами SYN. Проверяем, есть ли задержка в ответном пакете, а затем сбрасываем соединение. Мы можем отфильтровать данные, включив только пакеты более 100 мс, и получить более простой вариант воспроизведения проблемы, чем полный тест сетевого уровня 7 в Vegeta. Вот «пинги» узла Kubernetes с использованием TCP SYN/SYN-ACK на «порту узла» службы (30927) с интервалом 10 мс, отфильтрованные по самым медленным ответам:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -S -p 30927 -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1485 win=29200 rtt=127.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1486 win=29200 rtt=117.0 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1487 win=29200 rtt=106.2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1488 win=29200 rtt=104.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=5024 win=29200 rtt=109.2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=5231 win=29200 rtt=109.2 ms
Сразу может сделать первое наблюдение. По порядковым номерам и таймингам видно, что это не одноразовые заторы. Задержка часто накапливается, и в конечном итоге обрабатывается.
Далее мы хотим выяснить, какие компоненты могут быть причастны к появлению затора. Может, это какие-то из сотен правил iptables в NAT? Или какие-то проблемы с туннелированием IPIP в сети? Один из способов проверить это — проверить каждый шаг системы, исключив его. Что произойдёт, если убрать NAT и логику брандмауэра, оставив только часть IPIP:
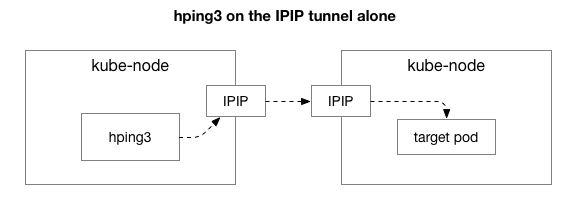
К счастью, Linux позволяет легко обращаться непосредственно к оверлейному слою IP, если машина входит в ту же сеть:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7346 win=0 rtt=127.3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7347 win=0 rtt=117.3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7348 win=0 rtt=107.2 ms
Судя по результатам, проблема всё ещё остаётся! Это исключает iptables и NAT. Значит, проблема в TCP? Посмотрим, как идёт обычный ICMP-пинг:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=28 ip=10.125.20.64 ttl=64 id=42594 icmp_seq=104 rtt=110.0 ms
len=28 ip=10.125.20.64 ttl=64 id=49448 icmp_seq=4022 rtt=141.3 ms
len=28 ip=10.125.20.64 ttl=64 id=49449 icmp_seq=4023 rtt=131.3 ms
len=28 ip=10.125.20.64 ttl=64 id=49450 icmp_seq=4024 rtt=121.2 ms
len=28 ip=10.125.20.64 ttl=64 id=49451 icmp_seq=4025 rtt=111.2 ms
len=28 ip=10.125.20.64 ttl=64 id=49452 icmp_seq=4026 rtt=101.1 ms
len=28 ip=10.125.20.64 ttl=64 id=50023 icmp_seq=4343 rtt=126.8 ms
len=28 ip=10.125.20.64 ttl=64 id=50024 icmp_seq=4344 rtt=116.8 ms
len=28 ip=10.125.20.64 ttl=64 id=50025 icmp_seq=4345 rtt=106.8 ms
len=28 ip=10.125.20.64 ttl=64 id=59727 icmp_seq=9836 rtt=106.1 ms
Результаты показывают, что проблема не исчезла. Возможно, это туннель IPIP? Давайте ещё упростим тест:
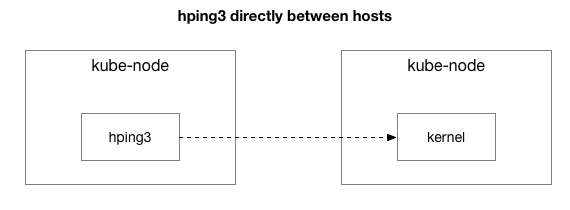
Все пакеты отправляются между этими двумя хостами?
theojulienne@kube-node-client ~ $ sudo hping3 172.16.47.27 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=46 ip=172.16.47.27 ttl=61 id=41127 icmp_seq=12564 rtt=140.9 ms
len=46 ip=172.16.47.27 ttl=61 id=41128 icmp_seq=12565 rtt=130.9 ms
len=46 ip=172.16.47.27 ttl=61 id=41129 icmp_seq=12566 rtt=120.8 ms
len=46 ip=172.16.47.27 ttl=61 id=41130 icmp_seq=12567 rtt=110.8 ms
len=46 ip=172.16.47.27 ttl=61 id=41131 icmp_seq=12568 rtt=100.7 ms
len=46 ip=172.16.47.27 ttl=61 id=9062 icmp_seq=31443 rtt=134.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9063 icmp_seq=31444 rtt=124.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9064 icmp_seq=31445 rtt=114.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9065 icmp_seq=31446 rtt=104.2 ms
Мы упростили ситуацию до двух узлов Kubernetes, отправляющих друг другу любой пакет, даже пинг ICMP. Они всё равно видят задержку, если целевой хост является «плохим» (некоторые хуже, чем другие).
Теперь последний вопрос: почему задержка возникает только на серверах kube-node? И она происходит, когда kube-node является отправителем или получателем? К счастью, это тоже довольно легко выяснить, отправляя пакет с хоста за пределами Kubernetes, но с тем же «известным плохим» получателем. Как видим, проблема не исчезла:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=312 win=0 rtt=108.5 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=5903 win=0 rtt=119.4 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=6227 win=0 rtt=139.9 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=7929 win=0 rtt=131.2 ms
Затем выполним те же запросы от предыдущего исходного kube-node к внешнему хосту (что исключает исходный хост, поскольку пинг включает как компонент RX, так и TX):
theojulienne@kube-node-client ~ $ sudo hping3 172.16.33.44 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
^C
--- 172.16.33.44 hping statistic ---
22352 packets transmitted, 22350 packets received, 1% packet loss
round-trip min/avg/max = 0.2/7.6/1010.6 ms
Изучив захваты пакетов с задержкой, мы получили некоторую дополнительную информацию. В частности, что отправитель (внизу) видит этот тайм-аут, а получатель (вверху) не видит — см. столбец Delta (в секундах):
Кроме того, если посмотреть на разницу в порядке пакетов TCP и ICMP (по порядковым номерам) на стороне получателя, то пакеты ICMP всегда поступают в той же последовательности, в которой они были отправлены, но с разным таймингом. В то же время пакеты TCP иногда чередуются, а часть из них застревает. В частности, если изучить порты пакетов SYN, то на стороне отправителя они идут по порядку, а на стороне получателя нет.
Есть тонкая разница в том, как современных серверов (как в нашем дата-центре) обрабатывают пакеты, содержащие TCP или ICMP. Когда поступает пакет, сетевой адаптер «хэширует его по соединению», то есть пытается разбить соединения по очередям и отправить каждую очередь на отдельное процессорное ядро. Для TCP этот хэш включает в себя как исходный, так и конечный IP-адрес и порт. Другими словами, каждое соединение хэшируется (потенциально) по-разному. Для ICMP хэшируются только IP-адреса, так как нет портов.
Ещё одно новое наблюдение: в течение этого периода мы видим задержки ICMP на всех коммуникациях между двумя хостами, а у TCP нет. Это говорит нам о том, что причина, вероятно, связана с хэшированием очередей RX: почти наверняка затор возникает в обработке пакетов RX, а не в отправке ответов.
Это исключает из списка возможных причин отправку пакетов. Теперь мы знаем, что проблема с обработкой пакетов находится на стороне приёма на некоторых серверах kube-node.
Разбираемся с обработкой пакетов в ядре Linux
Чтобы понять, почему проблема возникает у получателя на некоторых серверах kube-node, давайте посмотрим, как ядро Linux обрабатывает пакеты.
Возвращаясь к самой простой традиционной реализации, сетевая карта получает пакет и отправляет ядру Linux, что есть пакет, который нужно обработать. Ядро останавливает другую работу, переключает контекст на обработчик прерываний, обрабатывает пакет, а затем возвращается к текущим задачам.
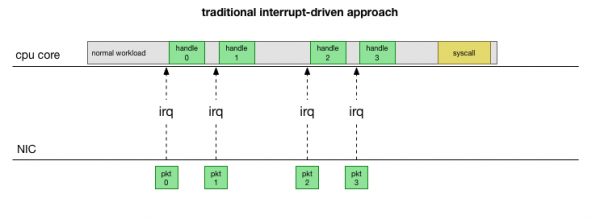
Это переключение контекста происходит медленно: возможно, задержка была незаметна на 10-мегабитных сетевых картах в 90-е годы, но на современных картах 10G с максимальной пропускной способностью 15 миллионов пакетов в секунду каждое ядро маленького восьмиядерного сервера может прерываться миллионы раз в секунду.
Чтобы не заниматься постоянно обработкой прерываний, много лет назад в Linux добавили : сетевой API, который используют все современные драйверы для повышения производительности на высоких скоростях. На низких скоростях ядро всё еще принимает прерывания от сетевой карты старым способом. Как только приходит достаточное количество пакетов, которое превышает порог, ядро отключает прерывания и вместо этого начинает опрашивать сетевой адаптер и забирать пакеты порциями. Обработка выполняется в softirq, то есть в после системных вызовов и аппаратных прерываний, когда ядро (в отличие от пользовательского пространства) уже запущено.
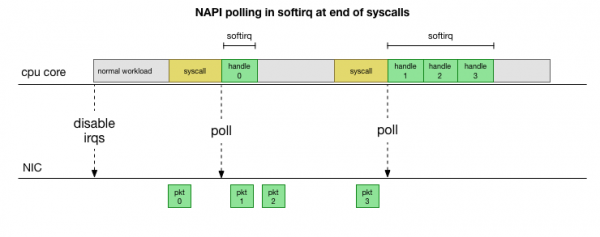
Это намного быстрее, но вызывает другую проблему. Если пакетов слишком много, то всё время уходит на обработку пакетов из сетевой карты, а процессы пользовательского пространства не успевают фактически опустошить эти очереди (чтение из TCP-соединений и т. д.). В конце концов очереди заполняются, и мы начинает отбрасывать пакеты. Пытаясь найти баланс, ядро устанавливает бюджет на максимальное количество пакетов, обрабатываемых в контексте softirq. Как только этот бюджет превышен, пробуждается отдельный поток ksoftirqd (вы увидите один из них в ps для каждого ядра), который обрабатывает эти softirq за пределами обычного пути syscall/interrupt. Этот поток планируется с помощью стандартного планировщика процессов, который пытается справедливо распределять ресурсы.
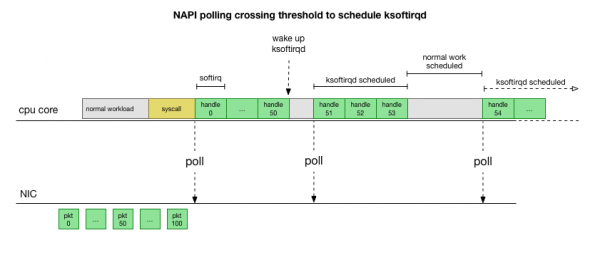
Изучив, как ядро обрабатывает пакеты, можно заметить, что здесь есть определённая вероятность появления заторов. Если вызовы softirq поступают реже, пакетам придётся некоторое время ждать обработки в очереди RX на сетевой карте. Возможно, это происходит из-за какой-то задачи, блокирующей ядро процессора, или что-то другое мешает ядру запускать softirq.
Сужаем обработку до ядра или метода
Задержки softirq — это пока лишь предположение. Но оно имеет смысл, и мы знаем, что у нас наблюдается что-то очень похожее. Поэтому следующий шаг — подтвердить эту теорию. И если она подтвердится, то найти причину задержек.
Вернёмся к нашим медленным пакетам:
len=46 ip=172.16.53.32 ttl=61 id=29573 icmp_seq=1953 rtt=99.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29574 icmp_seq=1954 rtt=89.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29575 icmp_seq=1955 rtt=79.2 ms
len=46 ip=172.16.53.32 ttl=61 id=29576 icmp_seq=1956 rtt=69.1 ms
len=46 ip=172.16.53.32 ttl=61 id=29577 icmp_seq=1957 rtt=59.1 ms
len=46 ip=172.16.53.32 ttl=61 id=29790 icmp_seq=2070 rtt=75.7 ms
len=46 ip=172.16.53.32 ttl=61 id=29791 icmp_seq=2071 rtt=65.6 ms
len=46 ip=172.16.53.32 ttl=61 id=29792 icmp_seq=2072 rtt=55.5 ms
Как обсуждалось ранее, эти пакеты ICMP хэшируются в одну очередь NIC RX и обрабатываются одним ядром CPU. Если мы хотим понять работу Linux, полезно знать, где (на каком ядре CPU) и как (softirq, ksoftirqd) обрабатываются эти пакеты, чтобы отследить процесс.
Теперь пришло время использовать инструменты, которые позволяют в реальном времени отслеживать работу ядра Linux. Здесь мы использовали . Этот набор инструментов позволяет писать небольшие программки на C, которые перехватывают произвольные функции в ядре и буферизуют события в программу Python пользовательского пространства, которая может обрабатывать их и возвращать вам результат. Хуки для произвольных функций в ядре — сложное дело, но утилита спроектирована на максимальную безопасность и предназначена для отслеживания именно таких проблем продакшна, которые непросто воспроизвести в среде тестирования или разработки.
План здесь простой: мы знаем, что ядро обрабатывает эти пинги ICMP, поэтому поставим хук на функцию ядра , которая принимает входящий ICMP-пакет «echo request» и инициирует отправку ICMP-ответа «echo response». Мы можем идентифицировать пакет по увеличению номера icmp_seq, который показывает hping3 superiore.
Codice выглядит сложным, но он не такой страшный, как кажется. Функция icmp_echo trasmette struct sk_buff *skb: это пакет с запросом «echo request». Мы можем отследить его, вытащить последовательность echo.sequence (которая сопоставляется с icmp_seq от hping3 in precedenza), и отправить её в пользовательское пространство. Также удобно захватить текущее имя процесса/идентификатор. Ниже показаны результаты, которые мы видим непосредственно во время обработки пакетов ядром:
TGID PID PROCESS NAME ICMP_SEQ 0 0 swapper/11 770 0 0 swapper/11 771 0 0 swapper/11 772 0 0 swapper/11 773 0 0 swapper/11 774 20041 20086 prometheus 775 0 0 swapper/11 776 0 0 swapper/11 777 0 0 swapper/11 778 4512 4542 spokes-report-s 779
Тут нужно заметить, что в контексте softirq процессы, которые сделали системные вызовы, отобразятся как «процессы», хотя на самом деле это ядро безопасно обрабатывает пакеты в контексте ядра.
С этим инструментом можем установить связь конкретных процессов с конкретными пакетами, которые показывают задержку в hping3. Делаем простой grep на этом захвате для определённых значений icmp_seq. Пакеты, соответствующие вышеуказанным значениям icmp_seq, были отмечены вместе с их RTT, которые мы наблюдали выше (в скобках указаны ожидаемые значения RTT у пакетов, которые мы отфильтровали из-за значений RTT менее 50 мс):
TGID PID PROCESS NAME ICMP_SEQ ** RTT -- 10137 10436 cadvisor 1951 10137 10436 cadvisor 1952 76 76 ksoftirqd/11 1953 ** 99ms 76 76 ksoftirqd/11 1954 ** 89ms 76 76 ksoftirqd/11 1955 ** 79ms 76 76 ksoftirqd/11 1956 ** 69ms 76 76 ksoftirqd/11 1957 ** 59ms 76 76 ksoftirqd/11 1958 ** (49ms) 76 76 ksoftirqd/11 1959 ** (39ms) 76 76 ksoftirqd/11 1960 ** (29ms) 76 76 ksoftirqd/11 1961 ** (19ms) 76 76 ksoftirqd/11 1962 ** (9ms) -- 10137 10436 cadvisor 2068 10137 10436 cadvisor 2069 76 76 ksoftirqd/11 2070 ** 75ms 76 76 ksoftirqd/11 2071 ** 65ms 76 76 ksoftirqd/11 2072 ** 55ms 76 76 ksoftirqd/11 2073 ** (45ms) 76 76 ksoftirqd/11 2074 ** (35ms) 76 76 ksoftirqd/11 2075 ** (25ms) 76 76 ksoftirqd/11 2076 ** (15ms) 76 76 ksoftirqd/11 2077 ** (5ms)
Результаты говорят нам о нескольких вещах. Во-первых, все эти пакеты обрабатывает контекст ksoftirqd/11. Это значит, что для этой конкретной пары машин ICMP-пакеты хэшировались на ядро 11 у принимающей стороны. Мы также видим, что при каждом заторе присутствуют пакеты, которые обрабатываются в контексте системного вызова cadvisor. Затем ksoftirqd берёт задачу на себя и отрабатывает накопленную очередь: именно то количество пакетов, которое накопилось после cadvisor.
Тот факт, что непосредственно перед этим всегда работает cadvisor, подразумевает его причастность в проблеме. По иронии, предназначение — «анализировать использование ресурсов и характеристики производительности запущенных контейнеров», а не вызывать эту проблему с производительностью.
Как и с другими аспектами работы контейнеров, это всё крайне передовой инструментарий, от которого вполне можно ожидать проблем с производительностью в некоторых непредвиденных обстоятельствах.
Что такого делает cadvisor, что тормозит очередь пакетов?
Теперь у нас есть довольно хорошее понимание, как происходит сбой, какой процесс его вызывает и на каком CPU. Мы видим, что из-за жёсткой блокировки ядро Linux не успевает вовремя запланировать ksoftirqd. И мы видим, что пакеты обрабатываются в контексте cadvisor. Логично предположить, что cadvisor запускает медленный syscall, после которого обрабатываются все скопившиеся в это время пакеты:
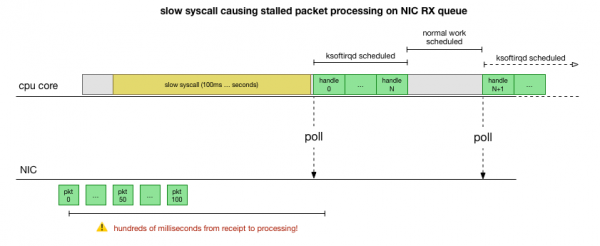
Это теория, но как её проверить? Что мы можем сделать, так это проследить работу ядра CPU на протяжении всего этого процесса, найти точку, где происходит превышение бюджета на количество пакетов и вызывается ksoftirqd, а затем посмотреть чуть раньше — что именно работало на ядре CPU непосредственно перед этим моментом. Это как рентгеновский снимок CPU каждые несколько миллисекунд. Он будет выглядеть примерно так:
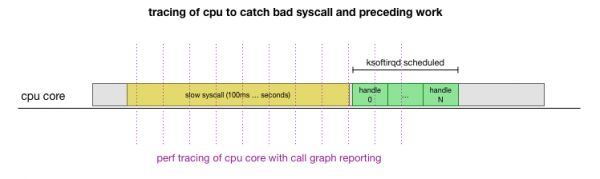
Удобно, что всё это можно сделать существующими инструментами. Например, с указанной периодичностью проверяет заданное ядро CPU и может генерировать график вызовов работающей системы, включая и пространство пользователя, и ядро Linux. Можно взять эту запись и обработать её с помощью небольшого форка программы от Брендана Грегга, который сохраняет порядок трассировки стека. Мы можем сохранять однострочные трассировки стека каждые 1 мс, а затем выделить и сохранить образец за 100 миллисекунд перед тем, как в трассировку попадает ksoftirqd:
# record 999 times a second, or every 1ms with some offset so not to align exactly with timers
sudo perf record -C 11 -g -F 999
# take that recording and make a simpler stack trace.
sudo perf script 2>/dev/null | ./FlameGraph/stackcollapse-perf-ordered.pl | grep ksoftir -B 100
Вот результаты:
(сотни следов, которые выглядят похожими)
cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_iter cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;ixgbe_poll;ixgbe_clean_rx_irq;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;bond_handle_frame;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;ipip_tunnel_xmit;ip_tunnel_xmit;iptunnel_xmit;ip_local_out;dst_output;__ip_local_out;nf_hook_slow;nf_iterate;nf_conntrack_in;generic_packet;ipt_do_table;set_match_v4;ip_set_test;hash_net4_kadt;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;hash_net4_test ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;gro_cell_poll;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;dev_queue_xmit_nit;packet_rcv;tpacket_rcv;sch_direct_xmit;validate_xmit_skb_list;validate_xmit_skb;netif_skb_features;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;__dev_queue_xmit;dev_hard_start_xmit;__bpf_prog_run;__bpf_prog_run
Здесь много чего, но главное, что мы находим шаблон «cadvisor перед ksoftirqd», который видели раньше в трейсере ICMP. Что это значит?
Каждая строка — это трассировка CPU в определённый момент времени. Каждый вызов вниз по стеку в строке разделяется точкой с запятой. В середине строк мы видим вызываемый syscall: read(): .... ;do_syscall_64;sys_read; .... Таким образом, cadvisor тратит много времени на системный вызов read(), относящийся к функциям mem_cgroup_* (верхняя часть стека вызовов/конец строки).
В трассировке вызовов неудобно смотреть, что именно читается, поэтому запустим strace и посмотрим, что делает cadvisor, и найдём системные вызовы дольше 100 мс:
theojulienne@kube-node-bad ~ $ sudo strace -p 10137 -T -ff 2>&1 | egrep '<0.[1-9]'
[pid 10436] <... futex resumed> ) = 0 <0.156784>
[pid 10432] <... futex resumed> ) = 0 <0.258285>
[pid 10137] <... futex resumed> ) = 0 <0.678382>
[pid 10384] <... futex resumed> ) = 0 <0.762328>
[pid 10436] <... read resumed> "cache 154234880nrss 507904nrss_h"..., 4096) = 658 <0.179438>
[pid 10384] <... futex resumed> ) = 0 <0.104614>
[pid 10436] <... futex resumed> ) = 0 <0.175936>
[pid 10436] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 577 <0.228091>
[pid 10427] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 577 <0.207334>
[pid 10411] <... epoll_ctl resumed> ) = 0 <0.118113>
[pid 10382] <... pselect6 resumed> ) = 0 (Timeout) <0.117717>
[pid 10436] <... read resumed> "cache 154234880nrss 507904nrss_h"..., 4096) = 660 <0.159891>
[pid 10417] <... futex resumed> ) = 0 <0.917495>
[pid 10436] <... futex resumed> ) = 0 <0.208172>
[pid 10417] <... futex resumed> ) = 0 <0.190763>
[pid 10417] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 576 <0.154442>
Как и можно было предположить, здесь мы видим медленные вызовы read(). Из содержимого операций чтения и контекста mem_cgroup видно, что эти вызовы read() относятся к файлу memory.stat, который показывает использование памяти и ограничения cgroup (технология изоляции ресурсов в Docker). Инструмент cadvisor опрашивает этот файл, чтобы получить сведения об использовании ресурсов для контейнеров. Давайте проверим, это ядро или cadvisor делает что-то неожиданное:
theojulienne@kube-node-bad ~ $ time cat /sys/fs/cgroup/memory/memory.stat >/dev/null
real 0m0.153s
user 0m0.000s
sys 0m0.152s
theojulienne@kube-node-bad ~ $
Теперь мы можем воспроизвести баг и понимаем, что ядро Linux сталкивается с патологией.
Из-за чего операция чтения настолько медленна?
На этом этапе гораздо проще найти сообщения других пользователей о подобных проблемах. Как оказалось, в трекере cadvisor об этом баге сообщали как о , просто никто не заметил, что задержка также случайным образом отражается в сетевом стеке. Действительно было замечено, что cadvisor потребляет больше процессорного времени, чем ожидалось, но этому не придали особого значения, ведь у наших серверов много процессорных ресурсов, так что проблему тщательно не изучали.
Проблема заключается в том, что контрольные группы (cgroups) учитывают использование памяти внутри пространства имён (контейнера). Когда все процессы в этой cgroup завершаются, Docker освобождает контрольную группу памяти. Однако «память» — это не просто память процесса. Хотя сама память процессов больше не используется, оказывается, ядро назначает ещё кэшированное содержимое, такое как dentries и inodes (метаданные каталогов и файлов), которые кэшируются в memory cgroup. Из описания проблемы:
cgroups-зомби: контрольные группы, в которых нет процессов и они удалены, но для которых всё ещё выделена память (в моём случае, из кэша dentry, но она также может выделяться из кэша страниц или tmpfs).
Проверка ядром всех страниц в кэше при освобождении cgroup может быть очень медленной, поэтому выбран ленивый процесс: подождать, пока эти страницы будут снова запрошены, и уже тогда, когда память действительно потребуется, наконец, очистить cgroup. До этого момента cgroup по-прежнему учитывается при сборе статистики.
С точки зрения производительности, они пожертвовали памятью ради производительности: ускорение первоначальной очистки за счёт того, что остаётся немного кэшированной памяти. Это нормально. Когда ядро использует последнюю часть кэшированной памяти, cgroup в конечном итоге очищается, так что это нельзя назвать «утечкой». К сожалению, конкретная реализация механизма поиска memory.stat в этой версии ядра (4.9), в сочетании с огромным объёмом памяти на наших серверах, приводит к тому, что для восстановления последних кэшированных данных и очистки cgroup-зомби требуется гораздо больше времени.
Оказывается, на некоторых наших узлах было так много cgroup-зомби, что чтение и задержка превышали секунду.
Способ обхода проблемы cadvisor — немедленно освободить кэши dentries/inodes по всей системе, что сразу устраняет задержку чтения, а также сетевую задержку на хосте, так как удаление кэша включает кэшированные страницы cgroup-зомби, а они тоже освобождаются. Это не решение, но подтверждает причину проблемы.
Оказалось, что в более новых версиях ядра (4.19+) улучшена производительность вызова memory.stat, так что переход на это ядро устранял проблему. В то же время у нас был инструментарий для обнаружения проблемных узлов в кластерах Kubernetes, их изящного слива и перезагрузки. Мы прочесали все кластеры, нашли узлы с достаточно высокой задержкой и перезагрузили их. Это дало нам время для обновления ОС на остальных серверах.
In sintesi
Поскольку этот баг останавливал обработку очередей NIC RX на сотни миллисекунд, он одновременно вызывал и большую задержку на коротких соединениях, и задержку в середине соединения, например, между запросами MySQL и ответными пакетами.
Понимание и поддержка производительности самых фундаментальных систем, таких как Kubernetes, имеет решающее значение для надёжности и скорости всех сервисов на их основе. От улучшений производительности Kubernetes выигрывают все запускаемые системы.
Fonte: habr.com
