


L'obiettivo principale di Patroni è garantire l'alta disponibilità per PostgreSQL. Tuttavia, Patroni è solo un template, non uno strumento pronto all'uso (come indicato nella documentazione). A prima vista, configurando Patroni in un laboratorio di test, si può vedere quanto sia uno strumento fantastico e come gestisca facilmente i nostri tentativi di far crollare il cluster. Tuttavia, nella pratica, in un ambiente di produzione, non sempre tutto avviene con la stessa bellezza ed eleganza che si osserva in un laboratorio di test.

Parlerò un po' di me. Ho iniziato come sistemista. Ho lavorato nello sviluppo web. Dal 2014 lavoro in Data Egret. L'azienda si occupa di consulenza nel settore di Postgres. E ci occupiamo specificamente di Postgres, lavorando con esso ogni giorno, quindi abbiamo una varietà di competenze legate alla sua gestione.
Verso la fine del 2018 abbiamo iniziato a utilizzare gradualmente Patroni. E abbiamo accumulato una certa esperienza. Abbiamo diagnosticato, ottimizzato e raggiunto le nostre best practices. In questa presentazione parlerò di esse.
Oltre a Postgres, adoro Linux. Mi piace esplorarlo e approfondirne le funzionalità, adoro compilare kernel. Amo la virtualizzazione, i container, Docker, Kubernetes. Tutto ciò mi interessa perché derivano dalle mie vecchie abitudini da amministratore. Mi piace occuparmi dei sistemi di monitoraggio. E mi piacciono le cose di Postgres legate all'amministrazione, come la replica e il backup. Nel tempo libero scrivo in Go. Non sono un ingegnere del software; scrivo in Go solo per me stesso. E questo mi dà soddisfazione.

- Credo che molti di voi sappiano che in Postgres non c'è HA (Alta Disponibilità) out-of-the-box. Per ottenere l'HA, è necessario installare qualcosa, configurarlo, impegnarsi e raggiungere l'obiettivo.
- Ci sono diversi strumenti e Patroni è uno di essi, che gestisce l'HA in modo piuttosto efficace e molto bene. Ma installando tutto questo in un laboratorio di test e avviandolo, possiamo vedere che funziona, possiamo riprodurre alcuni problemi e osservare come Patroni li gestisce. E scopriremo che tutto funziona perfettamente.
- Tuttavia, nella pratica abbiamo affrontato vari problemi. E parlerò di questi problemi.
- Vi racconterò come li abbiamo diagnosticati, cosa abbiamo modificato e se questo ci ha aiutato o meno.

- Non parlerò di come installare Patroni, perché puoi trovare facilmente informazioni online, puoi anche esaminare i file di configurazione per capire come avviare e configurare tutto. Puoi approfondire gli schemi e le architetture, cercando le informazioni appropriate sul web.
- Non condividerò esperienze altrui. Parlerò solo dei problemi che abbiamo affrontato noi stessi.
- E non discuterò di problemi che esulano da Patroni e PostgreSQL. Ad esempio, per quanto riguarda i problemi legati al bilanciamento, quando il nostro cluster è andato in crash, non ne parlerò.

Ecco un piccolo disclaimer prima di iniziare la nostra presentazione.
Tutti questi problemi che abbiamo riscontrato si sono manifestati nei primi 6-7-8 mesi di utilizzo. Con il tempo, abbiamo sviluppato le nostre best practices interne e i problemi sono scomparsi. Pertanto, la presentazione è stata programmata circa sei mesi fa, quando tutto era ancora fresco nella mia mente e lo ricordavo bene.
Durante la preparazione del rapporto, ho già esaminato i vecchi post-mortem e controllato i log. Alcuni dettagli potrebbero essere dimenticati oppure alcune informazioni potrebbero non essere state approfondite durante l'analisi dei problemi, pertanto potrebbe sembrare che alcune problematiche non siano state completamente trattate o che ci sia una mancanza di informazioni. Pertanto, vi chiedo scusa per questo aspetto.

Che cos'è Patroni?
- È un modello per la creazione di alta disponibilità (HA). Questo è ciò che si afferma nella documentazione. E dal mio punto di vista, è un chiarimento molto importante. Patroni non è una soluzione universale che risolverà tutti i vostri problemi; è necessario infatti fare uno sforzo affinché funzioni e porti benefici.
- È un servizio di agenzia che viene installato su ogni servizio con un database, e che funge da sistema init per il vostro Postgres. Avvia, arresta, riavvia, modifica la configurazione e cambia la topologia del vostro cluster.
- Pertanto, per memorizzare lo stato del cluster e la sua rappresentazione attuale, è necessaria una certa forma di archiviazione. Da questo punto di vista, Patroni ha scelto di conservare lo stato in un sistema esterno. Questo è un sistema di memorizzazione distribuita delle configurazioni. Possono essere Etcd, Consul, ZooKeeper, o l’Etcd di Kubernetes, cioè una di queste opzioni.
- Una delle caratteristiche di Patroni è che l’autofailover è disponibile direttamente 'fuori dalla scatola', una volta configurato. Se facciamo un confronto con Repmgr, lì il failover è incluso. Con Repmgr otteniamo lo switchover, ma se desideriamo l’autofailover, dobbiamo configurarlo ulteriormente. In Patroni, l’autofailover è già incluso.
- E ci sono molte altre cose. Ad esempio, la gestione delle configurazioni, l’aggiunta di nuove repliche, backup, ecc. Ma questo è al di fuori di questa relazione, quindi non ne parlerò.

In sintesi, l'obiettivo principale di Patroni è garantire un autofailover efficace e affidabile, in modo che il cluster rimanga operativo e l'applicazione non percepisca i cambiamenti nella topologia del cluster.

Ma quando iniziamo a utilizzare Patroni, il nostro sistema diventa un po' più complesso. Se in precedenza avevamo Postgres, utilizzando Patroni otteniamo Patrone stesso, otteniamo un DCS dove viene memorizzato lo stato. E tutto questo deve funzionare in qualche modo. Quindi, cosa può andare storto?
Può andare storto:
- Può andare storto Postgres. Può essere il master o una replica, uno dei due potrebbe guastarsi.
- Può andare storto lo stesso Patroni.
- Può andare storto il DCS, dove viene memorizzato lo stato.
- E può andare storto la rete.
Tutti questi aspetti li tratterò nella mia presentazione.

Esaminerò i casi man mano che si complicano, non dal punto di vista che il caso coinvolge molti componenti. Ma dal punto di vista delle sensazioni soggettive, che questo caso è stato difficile per me, è stato complicato da analizzare… e viceversa, un caso è stato facile e l'ho trovato semplice da trattare.

E il primo caso è il più semplice. Questo è il caso in cui abbiamo preso un cluster di database e abbiamo distribuito il nostro DCS su quello stesso cluster. Questo è l'errore più comune. È un errore di architettura, cioè la fusione di diversi componenti nello stesso luogo.
Quindi, si è verificato un file error, andiamo a scoprire cosa è successo.

E qui ci interessa sapere quando è avvenuto il failover. Cioè, ci interessa questo momento preciso in cui è avvenuto il cambiamento dello stato del cluster.
Tuttavia, il failover non è sempre istantaneo, cioè non avviene in un momento definito, ma può richiedere tempo. Può essere un processo prolungato.
Per questo motivo ha un tempo di inizio e un tempo di fine, cioè è un evento di lunga durata. Suddividiamo tutti gli eventi in tre intervalli: abbiamo il tempo prima del failover, durante il failover, e dopo il failover. Cioè, consideriamo tutti gli eventi su questa timeline.

La prima cosa che facciamo quando si verifica il failover è cercare la causa, cioè cosa è successo per provocare il failover.
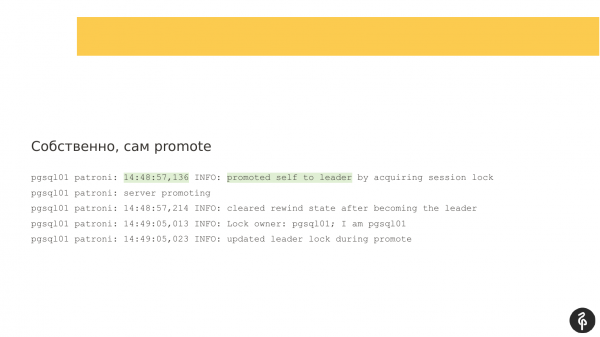
Se guardiamo i log, troveremo i log classici di Patroni. Qui ci informa che il server è diventato master, e il ruolo di master è stato trasferito a questo nodo. Questo è evidenziato qui.

Iniziamo a capire perché si è verificato il failover, ovvero quali eventi hanno causato il passaggio del master da un nodo all'altro. In questo caso, la situazione è chiara. Abbiamo un errore di interazione con il sistema di storage. Il master ha compreso che non può lavorare con il DCS, quindi si è verificato un problema di interazione. E comunica che non può più funzionare come master e si dimette. La riga "demoted self" si riferisce proprio a questo.

Esaminando gli eventi che hanno preceduto il failover, possiamo individuare le cause che hanno ostacolato il funzionamento del master.
Dai log di Patroni, vediamo che ci sono numerosi errori e timeout, cioè l'agente Patroni non riesce a comunicare con il DCS. In questo caso specifico, si tratta dell'agente Consul, con il quale si comunica sulla porta 8500.
Il problema risiede nel fatto che Patroni e il database sono in esecuzione sulla stessa macchina. Inoltre, su questo nodo erano attivi i server Consul. Creando un carico sul server, abbiamo generato problemi anche per server Consul. Non sono riusciti a comunicare correttamente.

Dopo un po', quando il carico si è attenuato, il nostro Patroni è riuscito a comunicare di nuovo con gli agenti. Il funzionamento normale è ripreso. E lo stesso server Pgdb-2 è tornato a essere master. C'è stato quindi un piccolo switch, che ha portato il nodo a rinunciare ai poteri di master, per poi riprenderli, quindi tutto è tornato come prima.

Questo può essere interpretato come un falso allarme, oppure si può considerare che Patroni abbia fatto tutto correttamente. Cioè, ha capito di non poter mantenere lo stato del cluster e ha rinunciato ai poteri.
Il problema è sorto a causa del fatto che i server Consul si trovano sullo stesso hardware delle basi. Di conseguenza, qualsiasi carico, sia su dischi che su processori, influisce anche sull'interazione con il cluster Consul.

Abbiamo deciso che non dovevano coesistere, quindi abbiamo creato un cluster separato per Consul. Patroni ha lavorato quindi con un Consul separato, cioè c'era un cluster Postgres separato e un cluster Consul separato. Questa è l'istruzione di base su come distribuire e gestire tutte queste risorse per evitare che coesistano.
Una possibile soluzione è regolare i parametri ttl, loop_wait, retry_timeout, cioè cercare di gestire questi picchi di carico aumentando tali parametri. Tuttavia, non è la soluzione ideale, poiché questa sovraccarico potrebbe durare nel tempo. Finiremo per superare questi limiti e potrebbe non essere di grande aiuto.
La prima problematica è piuttosto semplice. Abbiamo posizionato il DCS insieme al database, creando un problema.

La seconda problematica è simile alla prima. Ha in comune il fatto che ci sono nuovamente problemi di integrazione con il sistema DCS.

Se diamo un'occhiata ai log, possiamo notare che c'è di nuovo un errore di comunicazione. Patroni segnala che non riesce a interagire con il DCS, quindi il master attuale passa in modalità replica.
Il vecchio master diventa una replica; qui Patroni funziona come previsto. Avvia pg_rewind per ripristinare il registro delle transazioni e poi si collega al nuovo master per raggiungerlo. Patroni gestisce questa operazione come dovrebbe.

Qui dobbiamo trovare il punto precedente al failover, ovvero quegli errori che hanno causato il nostro failover. In questo senso, i log di Patroni sono piuttosto facili da gestire. Scrive gli stessi messaggi a intervalli regolari. E se cominciamo a scorrere rapidamente questi log, notiamo che i messaggi cambiano, il che indica che sono iniziati dei problemi. Torniamo rapidamente a quel punto e vediamo cosa sta succedendo.
In una situazione normale, i log appaiono più o meno in questo modo. Viene controllato il proprietario del blocco. Se il proprietario, ad esempio, è cambiato, possono verificarsi eventi a cui Patroni deve reagire. Ma in questo caso, tutto va bene. Stiamo cercando il punto in cui sono iniziati gli errori.

Scorrendo fino al punto in cui sono iniziati gli errori, vediamo che si è verificato un auto-failover. Poiché gli errori erano legati all'interazione con DCS e nel nostro caso abbiamo utilizzato Consul, guardiamo anche nei log di Consul per vedere cosa è successo lì.
Confrontando approssimativamente l'orario del file server con l'orario nei log di Consul, notiamo che i nostri vicini nel cluster Consul iniziano a dubitare dell'esistenza di altri membri del cluster Consul.

E se diamo un'occhiata ai log di altri agenti di Consul, si nota anche che c'è qualche collasso di rete in corso. E tutti i membri del cluster Consul dubitano della presenza reciproca. Questo ha innescato una problematica per il file server.
Se analizziamo cosa è successo prima di questi errori, possiamo vedere che ci sono vari errori, come deadline e RPC failed, cioè è chiaramente emersa qualche problematica nella comunicazione tra i membri del cluster Consul.

La risposta più semplice è riparare la rete. Ma per me, qui sulla piattaforma, è facile dirlo. Tuttavia, le circostanze sono tali che non sempre il cliente può permettersi di riparare la rete. Potrebbe trovarsi in un data center e non avere possibilità di intervenire sulla rete o di influenzare l'hardware. Pertanto, sono necessarie altre opzioni.

Le opzioni sono:
- L'opzione più semplice, che credo sia persino documentata, è disabilitare i controlli di Consul, ossia semplicemente passare un array vuoto. In questo modo diciamo all'agente di Consul di non utilizzare alcun controllo. Grazie a questi controlli, possiamo ignorare queste tempeste di rete e non avviare il file di recovery.
- Un'altra opzione è quella di ricontrollare il raft_multiplier. Questo è un parametro del server Consul. Di default, è impostato su 5. Questo valore è raccomandato dalla documentazione per gli ambienti di staging. Fondamentalmente, influisce sulla frequenza di scambio di messaggi tra i membri della rete Consul. In sostanza, questo parametro incide sulla velocità della comunicazione fra i nodi del cluster Consul. Per l'ambiente di produzione, è consigliato diminuirlo affinché i nodi comunichino più frequentemente.
- Un'altra opzione che abbiamo iniziato a utilizzare è l'aumento della priorità dei processi di Consul rispetto agli altri processi per il pianificatore di processi del sistema operativo. Esiste un parametro chiamato «nice», che determina appunto la priorità dei processi considerata dal pianificatore OS durante la pianificazione. Abbiamo quindi ridotto il valore di nice per gli agenti di Consul, ossia abbiamo aumentato la priorità, affinché il sistema operativo concedesse ai processi di Consul più tempo per svolgere il proprio lavoro ed eseguire il proprio codice. Nel nostro caso, questo ha risolto il nostro problema.
- Un'altra opzione è non utilizzare Consul. Ho un amico che è un grande sostenitore di Etcd. E discutiamo regolarmente su quale sia migliore, Etcd o Consul. Ma per quanto riguarda qual è il migliore, di solito ci accordiamo sul fatto che Consul ha un agente che deve essere eseguito su ogni nodo con il database. Cioè, l'interazione di Patroni con il cluster Consul avviene tramite questo agente. E questo agente diventa un collo di bottiglia. Se succede qualcosa all'agente, Patroni non può più lavorare con il cluster Consul. Questo è un problema. Per quanto riguarda Etcd, non c'è alcun agente. Patroni può lavorare direttamente con l'elenco dei server Etcd e comunicare con loro. In questo senso, se utilizzi Etcd nella tua azienda, Etcd sarà probabilmente una scelta migliore rispetto a Consul. Ma siamo sempre limitati da ciò che il cliente ha scelto e sta utilizzando. E per la maggior parte dei nostri clienti utilizziamo Consul.
- L'ultimo punto è rivedere i valori dei parametri. Possiamo aumentare questi parametri nella speranza che i nostri problemi di rete temporanei siano brevi e non superino l'intervallo di questi parametri. In questo modo possiamo ridurre l'aggressività di Patroni nell'esecuzione dell'auto-failover, se si verificano problemi di rete.
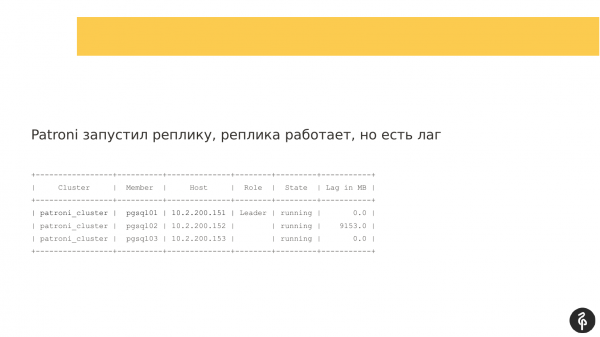
Penso che molti di coloro che utilizzano Patroni siano familiari con questo comando.
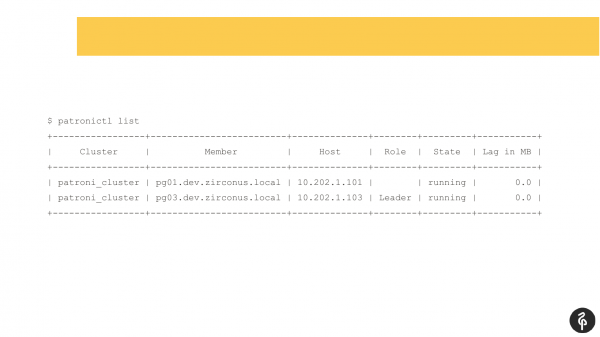
Questo comando mostra lo stato attuale del cluster. E a prima vista, questa immagine può sembrare normale. Abbiamo un master, abbiamo una replica, non ci sono lag nella replica. Ma questa situazione è normale solo finché non sappiamo che in questo cluster dovrebbero esserci tre nodi, non due.

Di conseguenza, si è verificato un auto-failover. E dopo questo auto-failover, la nostra replica è scomparsa. Dobbiamo scoprire perché è scomparsa e riportarla indietro, ripristinarla. E torniamo ai log per vedere perché si è verificato il failover automatico.

In questo caso, la seconda replica è diventata il master. Qui va tutto bene.

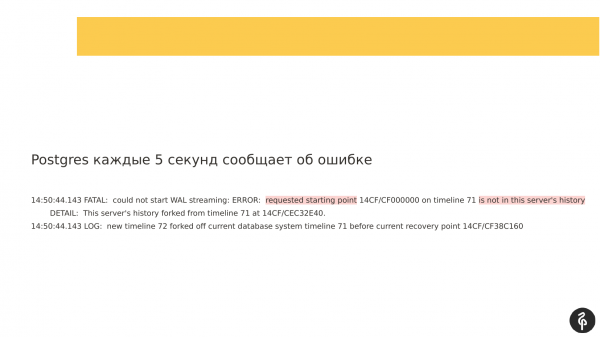
Dobbiamo esaminare la replica che si è disconnessa e che non è nel cluster. Apriamo i log di Patroni e vediamo che abbiamo avuto un problema durante la connessione al cluster nella fase di pg_rewind. Per connettersi al cluster è necessario ripristinare il registro delle transazioni, richiedere il registro delle transazioni corretto dal master e sincronizzarsi con il master.
In questo caso non abbiamo il registro delle transazioni, e la replica non può avviarsi. Di conseguenza, fermiamo Postgres con un errore. Pertanto, non è presente nel cluster.

Dobbiamo capire perché non è presente nel cluster e perché non ci sono log. Andiamo sul nuovo master e controlliamo cosa c'è nei suoi log. Si scopre che durante l'operazione di pg_rewind si è verificato un checkpoint. Parte dei vecchi registri delle transazioni è stata semplicemente rinominata. Quando il vecchio master ha tentato di connettersi al nuovo master e richiedere questi log, erano già stati rinominati e quindi non esistevano più.

Ho confrontato i timestamp in cui si sono verificati questi eventi. La differenza è di appena 150 millisecondi, ovvero il checkpoint è stato completato in 369 millisecondi e i segmenti WAL sono stati rinominati. E letteralmente, dopo 150 millisecondi, nel momento 517, è stata avviata la rewind sul vecchio replica. Cioè, ci sono bastati 150 millisecondi affinché il replica non riuscisse a connettersi e avviarsi.

Quali sono le opzioni disponibili?
All'inizio abbiamo utilizzato le slot di replicazione. Pensavamo fosse una buona idea. Anche se nella fase iniziale dell'utilizzo, abbiamo disattivato le slot. Credevamo che, se le slot accumulassero troppi segmenti WAL, avremmo potuto compromettere il master. Sarebbe crollato. Abbiamo lottato per un po' senza slot. E abbiamo capito che ci servivano le slot, quindi le abbiamo riattivate.
Ma qui c'è un problema: quando il master passa al replica, elimina le slot e, insieme alle slot, elimina i segmenti WAL. Per evitare questa problematica, abbiamo deciso di aumentare il parametro wal_keep_segments. Il valore predefinito è di 8 segmenti. Lo abbiamo aumentato a 1.000 e controllato quanto spazio libero avevamo. E abbiamo riservato 16 gigabyte per wal_keep_segments. Cioè, durante il commutazione, abbiamo sempre a disposizione 16 gigabyte di registri delle transazioni su tutti i nodi.
Inoltre, questo è ancora valido per compiti di manutenzione prolungati. Supponiamo di dover aggiornare una delle repliche. Vogliamo spegnerla. Dobbiamo aggiornare il software, magari il sistema operativo o qualcos'altro. Quando spegniamo la replica, anche lo slot per quella replica viene rimosso. E se utilizziamo un basso numero di wal_keep_segments, in caso di assenza prolungata della replica, i registri delle transazioni verranno riprodotti. Riavvieremo la replica, richiederà quei registri delle transazioni in cui si era fermata, ma potrebbero non essere disponibili sul master. E anche la replica non riuscirà a connettersi. Pertanto, manteniamo una scorta abbondante di registri.

Abbiamo un database di produzione. I progetti sono già operativi lì.
Si è verificato un file error. Siamo entrati e abbiamo controllato: tutto in ordine, le repliche sono al loro posto, non ci sono ritardi nella replicazione. Non ci sono errori nei registri, tutto è a posto.
Il team del prodotto dice che dovrebbero esserci dei dati, ma li vediamo solo in una fonte, mentre nel database non li troviamo. Dobbiamo capire cosa sia successo con quei dati.

È chiaro che pg_rewind li ha sovrascritti. Lo abbiamo subito capito, ma siamo andati a vedere cosa era successo.

Nei log possiamo sempre trovare quando è avvenuto il failover, chi è diventato il master e possiamo determinare chi era il vecchio master e quando ha voluto diventare replica, cioè abbiamo bisogno di questi log per scoprire il volume dei log delle transazioni che è stato perso.
Il nostro vecchio master si è riavviato. E nel startup automatico era configurato Patroni. Patroni è stato avviato. Successivamente ha avviato Postgres. Più precisamente, prima di avviare Postgres e prima di farlo diventare replica, Patroni ha avviato il processo pg_rewind. Di conseguenza, ha cancellato parte dei log delle transazioni, ha scaricato nuovi log e si è connesso. Qui Patroni ha funzionato alla grande, cioè come doveva. Il cluster si è ripristinato. Avevamo 3 nodi, dopo il failover abbiamo avuto 3 nodi – tutto perfetto.

Abbiamo perso parte dei dati. E dobbiamo capire quanto ne abbiamo perso. Stiamo cercando proprio quel momento in cui è avvenuto il rewind. Possiamo trovarlo tramite queste registrazioni nel log. È partito il rewind, ha fatto qualcosa e si è concluso.

Dobbiamo trovare la posizione nel log delle transazioni in cui si è fermato il vecchio master. In questo caso, è questo contrassegno. E abbiamo bisogno di un secondo contrassegno, cioè della distanza in cui il vecchio master si differenzia dal nuovo.
Confrontiamo le due posizioni usando un normale pg_wal_lsn_diff. In questo caso, otteniamo 17 megabyte. Se siano tanti o pochi, ognuno lo stabilisce secondo la propria valutazione. Per alcuni 17 megabyte possono sembrare pochi, per altri sono un valore significativo e inaccettabile. Qui ognuno deve decidere in base alle esigenze del proprio business.

Ma cosa abbiamo scoperto per noi?
Innanzitutto, dobbiamo decidere se abbiamo sempre bisogno dell'avvio automatico di Patroni dopo il riavvio del sistema. Spesso è necessario accedere al vecchio master e vedere fin dove è arrivato. Potrebbe essere utile ispezionare i segmenti del log delle transazioni e capire cosa ci sia. E comprendere se possiamo perdere questi dati o se dobbiamo avviare il vecchio master in modalità standalone per recuperare queste informazioni.
Solo dopo aver fatto questo possiamo prendere decisioni su ciò che possiamo scartare o su ciò che possiamo recuperare, connettere questo nodo come replica al nostro cluster.
In aggiunta, c'è il parametro 'maximum_lag_on_failover'. Se non ricordo male, di default questo parametro è impostato a 1 megabyte.
Come funziona? Se la nostra replica è in ritardo di 1 megabyte di dati a causa del lag di replicazione, questa replica non partecipa alle elezioni. E se si verifica un failover, Patroni verifica quali repliche sono in ritardo. Se sono in ritardo di un gran numero di registri delle transazioni, non possono diventare master. Questa è una funzione di protezione molto valida, che consente di non perdere molti dati.
Ma c'è un problema: il lag di replicazione nel cluster Patroni e DCS viene aggiornato a intervalli specifici. Credo che il valore ttl predefinito sia di 30 secondi.
Di conseguenza, può verificarsi una situazione in cui il lag di replicazione per le repliche in DCS è uno, ma in realtà potrebbe esserci un lag completamente diverso o addirittura non ci potrebbe essere affatto, cioè questa cosa non è in tempo reale. E non riflette sempre la situazione reale. Quindi non ha senso basare logiche complesse su di essa.
E il rischio di perdite rimane sempre. Nel peggior caso una formula, mentre nel caso medio un'altra formula. Cioè, quando pianifichiamo l'implementazione di Patroni e valutiamo quanti dati possiamo perdere, dobbiamo considerare queste formule e avere un'idea di quanti dati possiamo effettivamente perdere.
E c'è una buona notizia. Quando il vecchio master è andato avanti, può farlo grazie a qualche processo in background. C'era un certo auto-vacuum, ha registrato i dati e li ha salvati nel log delle transazioni. Possiamo tranquillamente ignorare questi dati e perderli. Non ci sono problemi in questo.

Ecco come appaiono i log nel caso in cui sia impostato maximum_lag_on_failover e si sia verificato un failover dei file, e sia necessario scegliere un nuovo master. La replica si valuta come incapace di partecipare alle elezioni. Si ritira dalla corsa per diventare leader. Aspetta che venga scelto un nuovo master per poi connettersi a lui. Questa è una misura aggiuntiva contro la perdita di dati.

Qui il nostro team prodotto ha scritto che il loro prodotto ha problemi con Postgres. Nel frattempo, non possiamo accedere al master stesso, perché non è disponibile tramite SSH. E non si verifica neppure l'auto-failover.
Questo host è stato forzato a riavviarsi. A causa del riavvio si è verificato un auto-failover, anche se potevo fare un failover manuale, come capisco ora. E dopo il riavvio andiamo a controllare cosa è successo con il master attuale.
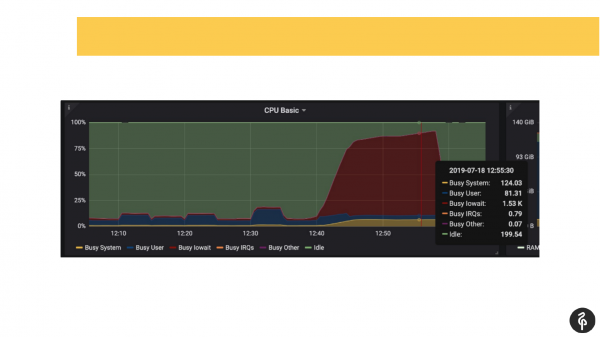
Sapevamo in anticipo che avevamo problemi con i dischi, quindi avevamo già delle indicazioni da monitoraggio su dove intervenire e cosa cercare.

Abbiamo esaminato il log di PostgreSQL e iniziato a controllare cosa stesse accadendo. Abbiamo notato commit che duravano da una a tre secondi, il che non è affatto normale. Abbiamo visto che l'autovacuum impiegava molto tempo e in modo anomalo. Inoltre, abbiamo riscontrato file temporanei sul disco. Questi sono tutti segnali di problemi con i dischi.

Abbiamo controllato il dmesg di sistema (il log dei messaggi del kernel). Abbiamo constatato che c'era un problema con uno dei dischi. Il sistema di dischi era un software RAID. Abbiamo esaminato /proc/mdstat e abbiamo visto che ci mancava un disco. Quindi, avevamo un RAID composto da 8 dischi, ma uno era assente. Se si guarda attentamente la slide, si può vedere che sde è mancante. In sostanza, un disco è andato perso. Questo ha innescato problemi ai dischi e le applicazioni hanno riscontrato difficoltà nella gestione del cluster PostgreSQL.

In this case, Patroni wouldn't help us because it doesn't track the server status or disk condition. We must monitor such situations externally. We promptly added disk monitoring to our external monitoring.
We had the thought—could fencing or a watchdog software assist us? We concluded it probably wouldn't be helpful because, during the issues, Patroni continued to interact with the DCS cluster and didn't see any problems. From the DCS and Patroni perspective, everything was fine with the cluster, even though there were actual disk issues and database availability problems.
In my opinion, this is one of the most peculiar issues I have researched for a long time; I read through many logs, sifted through them extensively, and I called it the cluster-simulant.

The issue was that the old master couldn't become a proper replica. Patroni would start it and indicate that this node was present as a replica, but at the same time, it wasn't a valid replica. You'll see why shortly. I kept this from the analysis of that problem.

E da dove è iniziato tutto? È iniziato, come nel problema precedente, con i freni a disco. Avevamo commit al secondo, due.

Ci sono stati disservizi di connessione, cioè i clienti si disconnettevano.

Ci sono state interruzioni di varia gravità.

E, di conseguenza, il sistema dei dischi non era molto reattivo.

E la cosa più enigmatica per me è stata la richiesta di spegnimento immediato. Postgres ha tre modalità di spegnimento:
- C'è la modalità elegante, quando aspettiamo che tutti i clienti si disconnettano da soli.
- C'è la modalità veloce, quando costringiamo i clienti a disconnettersi perché stiamo per spegnere.
- E c'è la modalità immediata. In questo caso, immediata non informa nemmeno i clienti che devono disconnettersi, si spegne semplicemente senza preavviso. A tutti i clienti, il sistema operativo invia un messaggio RST (un messaggio TCP che comunica che la connessione è stata interrotta e il cliente non ha più nulla da fare).
Chi ha inviato questo segnale? I processi di background di Postgres non si inviano segnali reciproci, cioè è un kill-9. Non si inviano segnali di questo tipo, ma reagiscono solamente a essi, quindi è un riavvio emergenziale di Postgres. Chi l'ha inviato, non lo so.
Ho controllato con il comando «last» e ho visto una persona che ha effettuato il login su questo server insieme a noi, ma ho esitato a fare una domanda. Potrebbe essere stato un kill -9. Avrei visto un kill -9 nei log, poiché Postgres riporta di aver ricevuto un kill -9, ma non l'ho visto nei log.

Proseguendo, ho notato che Patroni non ha scritto nei log per un periodo piuttosto lungo – 54 secondi. Se confronto i due timestamp, ci sono circa 54 secondi senza messaggi.
E in quel tempo c'è stata un'auto-failover. Patroni ha funzionato di nuovo perfettamente. Il nostro vecchio master non era disponibile, qualcosa stava succedendo. E sono iniziate le elezioni per il nuovo master. Qui tutto ha funzionato bene. pgsql01 è diventato il nuovo leader.

Abbiamo una replica che è diventata master. E c'è un secondo replica. Ci sono stati problemi con il secondo replica. Stava tentando di riconfigurarsi. Come capisco, stava cercando di cambiare recovery.conf, riavviare Postgres e connettersi al nuovo master. Ogni 10 secondi scrive messaggi che sta provando, ma non ci riesce.

Durante questi tentativi, il vecchio master riceve un segnale di spegnimento immediato. Il master si riavvia. Inoltre, il recovery si interrompe perché il vecchio master sta per riavviarsi. Ciò significa che la replica non può connettersi a lui, poiché è in modalità di spegnimento.

A un certo punto ha funzionato, ma la replica non si è avviata.
Ho una sola ipotesi: che in recovery.conf ci fosse l'indirizzo del vecchio master. Quando è apparso il nuovo master, la seconda replica continuava a cercare di connettersi al vecchio master.
Quando Patroni è stato avviato sulla seconda replica, il nodo si è avviato, ma non è riuscito a connettersi in replica. Questo ha creato un ritardo di replica, che appariva in questo modo. Cioè, tutti e tre i nodi erano presenti, ma il secondo nodo ritardava.
Tuttavia, guardando i log che venivano generati, si poteva vedere che la replica non riusciva ad avviarsi perché i log delle transazioni erano diversi. E i log delle transazioni forniti dal master, indicati in recovery.conf, semplicemente non corrispondevano al nostro nodo attuale.

E qui ho commesso un errore. Avrei dovuto controllare cosa c'era in recovery.conf per verificare la mia ipotesi che ci stavamo connettendo al master sbagliato. Ma all'epoca ero ancora alle prime armi e non mi è venuto in mente, oppure ho notato che la replica era in ritardo e che sarebbe stato necessario ripristinarla, cioè l'ho gestita in modo un po' superficiale. È stata una mia svista.

Dopo 30 minuti è arrivato l'amministratore, cioè ho riavviato Patroni sulla replica. La consideravo già compromessa, pensavo che sarebbe stata necessaria una ripristino. Ho pensato – riavvierò Patroni, forse verrà fuori qualcosa di buono. Il recovery è partito. E il database si è anche aperto, era pronto a ricevere connessioni.
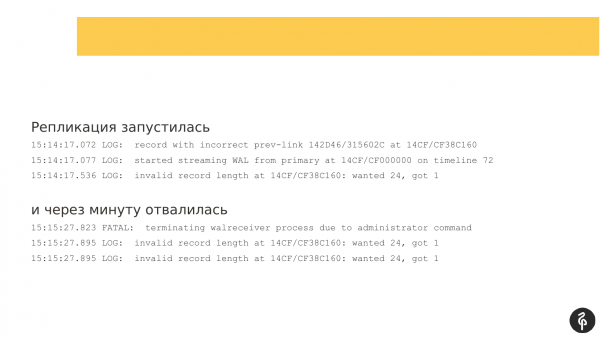
La replica si è avviata. Ma dopo un minuto si è disconnessa con un errore, indicando che i registri delle transazioni non erano compatibili.

Ho pensato di riavviare di nuovo. Ho riavviato nuovamente Patroni, e non ho riavviato Postgres, ma ho riavviato proprio Patroni sperando che potesse avviare il database in modo magico.

La replica è ripartita, ma i registri delle transazioni erano differenti, non corrispondevano a quelli del tentativo precedente. La replica si è fermata di nuovo. E il messaggio era leggermente diverso, non era molto informativo per me.

E mi è venuta in mente un'idea: e se riavviassi Postgres, mentre faccio un checkpoint corrente sul master, per spostare leggermente il punto nei registri delle transazioni in modo che il recovery inizi da un altro momento? Inoltre, avevamo anche delle riserve di WAL.

Ho riavviato Patroni, ho fatto un paio di checkpoint sul master e un paio di punti di riavvio sulla replica, quando è stata attivata. E questo ha funzionato. Ho pensato a lungo a perché ha funzionato e come sia successo. E la replica si è avviata. La replicazione non si è più interrotta.

Questo problema è per me uno dei più misteriosi, su cui sto ancora riflettendo, su cosa stesse realmente accadendo.
Quali sono le conclusioni qui? Patroni può funzionare come previsto e senza errori. Tuttavia, ciò non garantisce al 100% che tutto vada bene. La replica può avviarsi, ma può anche trovarsi in uno stato semi-funzionale, e l'applicazione non può lavorare con tale replica, perché conterrà dati obsoleti.
E dopo ogni failover è sempre necessario controllare che tutto sia a posto con il cluster, ossia che ci sia il numero corretto di repliche e che non ci sia un ritardo nella replicazione.
E durante l'esame di questi problemi, formulerò delle raccomandazioni. Ho cercato di riunirle in due slide. Probabilmente, tutte le storie avrebbero potuto essere riassunte in due slide e semplicemente raccontate.

Quando usate Patroni, è fondamentale avere un monitoraggio. È necessario sapere sempre quando si è verificato un failover automatico, perché se non sapete che si è verificato un failover automatico, non controllate il cluster. E questo è problematico.
Dopo ogni failover, dobbiamo sempre verificare manualmente il cluster. Dobbiamo assicurarci che ci sia sempre il numero corretto di repliche, che non ci siano ritardi nella replicazione e che nei log non ci siano errori relativi alla replicazione in streaming, a Patroni o al sistema DCS.
L'automazione può funzionare con successo, Patroni è uno strumento molto utile. Può operare, ma ciò non porterà il cluster allo stato desiderato. E se non ce ne rendiamo conto, avremo dei problemi.
E Patroni non è una soluzione miracolosa. Dobbiamo comunque avere una comprensione di come funziona Postgres, come avviene la replica e come Patroni interagisce con Postgres, oltre a come viene garantita l'interazione tra i nodi. Questo è necessario per poter risolvere manualmente i problemi che sorgono.

Come mi approccio alla diagnosi? È così che lavoriamo con diversi clienti e nessuno ha un stack ELK, quindi dobbiamo analizzare i log aprendo 6 console e 2 schede. In una scheda ci sono i log di Patroni per ogni nodo, nell'altra scheda i log di Consul o di Postgres se necessario. Diagnosticarlo è molto difficile.
Quali approcci ho sviluppato? In primo luogo, guardo sempre quando è arrivato il failover. E per me questo è un punto di svolta. Osservo cosa è successo prima del failover, durante il failover e dopo il failover. Il failover ha due marcatori: l'orario di inizio e quello di fine.
Successivamente, controllo nei log gli eventi precedenti al failover, cercando di capire le cause del failover.
Questo mi offre una visione di ciò che è accaduto e cosa si può fare in futuro per evitare che si verifichino circostanze simili (e quindi impedire future interruzioni).
E dove di solito guardiamo? Io guardo:
- Innanzitutto nei log di Patroni.
- Successivamente, controllo i log di Postgres o i log del DCS, a seconda di ciò che è emerso nei log di Patroni.
- A volte anche i log di sistema offrono indicazioni su cosa abbia causato il failover.

Qual è la mia opinione su Patroni? Ho una grande considerazione per Patroni. A mio avviso, è la soluzione migliore disponibile attualmente. Conosco molti altri strumenti, come Stolon, Repmgr, Pg_auto_failover, PAF. Ho provato tutti e quattro. Patroni mi è piaciuto di più.
Se qualcuno mi chiedesse: 'Consiglieresti Patroni?'. Risponderei di sì, perché mi piace Patroni. E credo di aver imparato a configurarlo.
Se sei interessato a scoprire quali altri problemi possono sorgere con Patroni, oltre a quelli che ho menzionato, puoi sempre visitare la pagina su GitHub. Ci sono molte storie diverse e si discutono molti problemi interessanti. Alla fine, alcuni bug sono stati individuati e risolti, quindi è una lettura affascinante.
Ci sono storie intriganti su come le persone si sparano sui piedi. È molto istruttivo. Leggi e capisci che non dovresti farlo. Ti segni la cosa.
Vorrei esprimere un grande grazie a Zalando per lo sviluppo di questo progetto, in particolare ad Aleksandr Kukushkin e Aleksei Klyukin. Aleksei Klyukin è uno dei coautori, non lavora più in Zalando, ma sono due persone che hanno iniziato a lavorare su questo prodotto.
Ritengo che Patroni sia davvero una cosa fantastica. Sono contento che esista, è interessante. E un grande grazie a tutti i contributori che scrivono patch per Patroni. Spero che Patroni diventi più maturo, fantastico e funzionale con il tempo. È già funzionale, ma spero che diventi ancora migliore. Quindi, se pianificate di utilizzare Patroni, non abbiate paura. È una buona soluzione, può essere implementata e utilizzata.
Questo è tutto. Se avete domande, chiedete.

Domande
Grazie per il report! Se dopo il file manager dobbiamo comunque controllare attentamente, perché abbiamo bisogno di un file manager automatico?
Perché è una cosa nuova. Lavoriamo con esso da solo un anno. È meglio essere cauti. Vogliamo entrarci e assicurarci che tutto funzioni come deve. È un livello di sfiducia adulta — è meglio ricontrollare e verificare.
Per esempio, ci siamo entrati e abbiamo controllato, giusto?
Non al mattino, di solito veniamo a sapere dell'auto-file manager praticamente subito. Riceviamo notifiche, vediamo che c'è stato un auto-file manager. Entro quasi subito e controllo. Ma tutti questi controlli devono essere portati a un livello di monitoraggio. Se ci si rivolge a Patroni tramite REST API, c'è la cronologia. Dalla cronologia si possono vedere i timestamp di quando è avvenuto il file manager. Sulla base di questo si può fare monitoraggio. Possiamo visualizzare la cronologia e vedere quanti eventi ci sono stati. Se abbiamo avuto più eventi, significa che c'è stato un auto-file manager. Possiamo andare e controllare. Oppure la nostra automazione nel monitoraggio ha verificato che tutte le repliche sono al loro posto, non ci sono ritardi e tutto va bene.
Grazie!
Grazie mille per il fantastico racconto! Se abbiamo spostato il cluster DCS lontano dal cluster Postgres, deve essere comunque manutenuto periodicamente? Quali sono le best practices per gestire parti del cluster DCS, spegnere alcune sezioni e così via? Come funziona l'intero sistema in questo caso? E in che modo si può procedere con queste operazioni?
Per una azienda, era necessario sviluppare una matrice di problemi, per comprendere cosa succede se uno o più componenti smettono di funzionare. Con questa matrice, esaminiamo sistematicamente tutti i componenti e creiamo scenari in caso di guasto. Pertanto, per ogni scenario di guasto è possibile avere un piano d'azione per il ripristino. Nel caso del DCS, questo rientra come parte dell'infrastruttura standard. L'amministratore si occupa della gestione e ci affidiamo già agli amministratori che lo gestiscono e alle loro capacità di ripararlo in caso di emergenza. Se il DCS non esiste affatto, lo implementiamo noi, ma non ne monitoriamo particolarmente il funzionamento, poiché non siamo responsabili dell'infrastruttura, ma forniamo raccomandazioni su come e cosa monitorare.
Cioè, ho capito bene che devo disattivare Patroni, disattivare il file manager e disattivare tutto prima di fare qualcosa con gli host?
Questo dipende da quanti nodi abbiamo nel cluster DCS. Se ci sono molti nodi e se disattiviamo solo uno dei nodi (replica), il quorum rimane attivo nel cluster. E Patroni rimane funzionante. E non si attiva nulla. Se abbiamo operazioni complesse che coinvolgono più nodi, la cui assenza potrebbe far crollare il quorum, allora sì, potrebbe avere senso mettere in pausa Patroni. Ha un comando corrispondente – patronictl pause, patronictl resume. Semplicemente lo mettiamo in pausa, e il file manager automatico non si attiva in quel momento. Facciamo la manutenzione sul cluster DCS, poi ripristiniamo la pausa e continuiamo a vivere.
Grazie mille!
Grazie mille per la presentazione! Come si sente il team di prodotto riguardo al fatto che i dati possano andare persi?
Ai team di prodotto non importa, mentre ai team leader preoccupa.
Quali garanzie ci sono?
Le garanzie sono molto difficili. C'è un rapporto di Aleksandr Kukushkin su "Come calcolare RPO e RTO", cioè il tempo di ripristino e la quantità di dati che possiamo perdere. Penso che sia necessario trovare queste diapositive e studiarle. Da quanto ricordo, ci sono passi specifici su come calcolare queste cose. Quante transazioni possiamo perdere, quanti dati possiamo perdere. Come opzione, possiamo utilizzare la replica sincrona a livello di Patroni, ma è un'arma a doppio taglio: abbiamo affidabilità dei dati oppure perdiamo in velocità. Esiste la replica sincrona, ma questa non garantisce nemmeno una protezione al 100% contro la perdita di dati.
Alexey, grazie per la tua presentazione fantastica! Hai esperienza nell'uso di Patroni per la protezione a zero livelli? Cioè, in abbinamento con un standby sincrono? Questa è la prima domanda. E la seconda domanda. Hai utilizzato diverse soluzioni. Noi abbiamo usato Repmgr, ma senza failover automatico e ora stiamo pianificando di collegare il failover automatico. Consideriamo Patroni come un'alternativa. Cosa puoi dire riguardo ai vantaggi rispetto a Repmgr?
Il primo quesito riguardava le repliche sincrone. Qui da noi nessuno utilizza la replicazione sincrona, perché è motivo di paura (alcuni clienti la usano già e non hanno riscontrato problemi di prestazioni — Nota del relatore). Tuttavia, abbiamo stabilito una regola: nel cluster di replicazione sincrona devono esserci almeno tre nodi, perché se abbiamo solo due nodi e uno dei due, master o replica, si guasta, Patroni porta quel nodo in modalità Standalone, così l'applicazione continua a funzionare. In questo caso, ci sono rischi di perdita di dati.
Per quanto riguarda la seconda domanda, abbiamo utilizzato Repmgr e continuiamo ad usarlo per alcuni clienti per motivi storici. Cosa si può dire? In Patroni l'auto failover è incluso di default, mentre in Repmgr l'auto failover è una funzionalità aggiuntiva che deve essere attivata. È necessario avviare il demone Repmgr su ogni nodo e allora possiamo configurare l'auto failover.
Repmgr controlla se i nodi Postgres sono attivi. I processi di Repmgr verificano l'esistenza reciproca, il che non è un approccio molto efficace, poiché possono verificarsi casi complessi di isolamento di rete in cui un grande cluster di Repmgr può dividersi in più piccoli e continuare a funzionare. Non seguo più Repmgr da un po', forse hanno risolto questo problema... o forse no. Tuttavia, esternalizzare le informazioni sullo stato del cluster in DCS, come fa Stolon o Patroni, è l'alternativa più valida.
Alexey, ho una domanda, potrebbe essere un po' basilare. In uno dei primi esempi DCS, hai spostato da una macchina locale a un nodo remoto. Comprendiamo che la rete ha le sue peculiarità e vive di vita propria. Cosa succede se per qualche motivo il cluster DCS diventa inaccessibile? Non dirò le cause, possono essere molte: da problemi legati ai tecnici di rete a vere e proprie difficoltà.
Non l'ho detto ad alta voce, ma il cluster DCS deve essere anch'esso resistente ai guasti, cioè deve avere un numero dispari di nodi per permettere la formazione del quorum. Cosa succede se il cluster DCS diventa non disponibile o non riesce a formare il quorum, ad esempio in caso di una divisione di rete o guasto di nodi? In tal caso, il cluster Patroni passa alla modalità di sola lettura. Il cluster Patroni non può determinare lo stato del cluster e cosa deve fare. Non riesce a contattare il DCS per salvare il nuovo stato del cluster, quindi l'intero cluster passa alla modalità di sola lettura. E aspetta un intervento manuale da parte dell'operatore o il ripristino del DCS.
In sostanza, il DCS diventa per noi un servizio altrettanto importante quanto il database stesso?
Sì, in molte aziende moderne il Service Discovery è una parte essenziale dell'infrastruttura. Viene implementato anche prima che venga creata la base dati nell'infrastruttura. In parole semplici, si avvia l'infrastruttura, si realizza nel data center e subito c'è il Service Discovery. Se si tratta di Consul, può essere costruito anche su di esso il DNS. Se si tratta di Etcd, potrebbe far parte di un cluster Kubernetes, dove verrà distribuito tutto il resto. Penso che il Service Discovery sia già una parte integrante delle infrastrutture moderne, e ci si pensa molto prima rispetto alle basi dati.
Grazie!
Fonte: habr.com
