

Ciao, Habr!
Ricordiamo che è stata pubblicata un'altra interessante e utile sui pattern di Kubernetes. Tutto è iniziato con "" di Brendan Burns, e, in effetti, il lavoro in questo settore è . Oggi ti proponiamo di leggere un articolo del blog di MinIO, che riassume le tendenze e le specifiche dei pattern di archiviazione dati in Kubernetes.
Kubernetes ha cambiato fondamentalmente i tradizionali pattern di sviluppo e distribuzione delle applicazioni. Ora il team può impiegare solo pochi giorni per sviluppare, testare e distribuire un'applicazione – in ambienti diversi, il tutto all'interno dei cluster Kubernetes. Tale lavoro con le tecnologie delle generazioni precedenti richiedeva di solito settimane, se non mesi.
Questa accelerazione è stata possibile grazie all'astrazione fornita da Kubernetes, ovvero al fatto che Kubernetes gestisce autonomamente l'interazione con i dettagli a basso livello delle macchine fisiche o virtuali, permettendo agli utenti di dichiarare tra gli altri parametri la CPU desiderata, la quantità di memoria necessaria e il numero di istanze dei contenitori. Poiché un'enorme comunità è coinvolta nel supporto di Kubernetes e l'uso di Kubernetes continua ad espandersi, esso guida con ampio margine tra tutte le piattaforme di orchestrazione dei contenitori.
Con l'espansione dell'uso di Kubernetes cresce anche la confusione riguardo ai modelli di archiviazione dei dati utilizzati..
In un contesto di forte concorrenza per un pezzo di torta in Kubernetes (cioè, per lo storage dei dati), quando si parla di archiviazione dei dati, il segnale qui si perde in un forte rumore.
Kubernetes incarna un modello moderno per lo sviluppo, il deployment e la gestione delle applicazioni. Questo modello all'avanguardia separa lo storage dei dati dall'elaborazione. Per comprendere appieno questa separazione nel contesto di Kubernetes, è fondamentale anche capire cosa intendiamo per applicazioni a stato e senza stato, e come questo si integra con lo storage dei dati. Qui, l'approccio REST API utilizzato da S3 offre vantaggi chiari rispetto all'approccio POSIX/CSI comune in altre soluzioni.
In questo articolo parleremo dei modelli di storage dei dati in Kubernetes e affronteremo la questione delle applicazioni a stato e senza stato, per comprendere bene le differenze tra di esse e perché queste differenze siano importanti. Successivamente, discuteremo le applicazioni e i modelli di storage dati utilizzati in esse alla luce delle migliori pratiche per il lavoro con i container e Kubernetes.
Container senza stato
I contenitori sono per loro natura leggeri ed efimeri. Possono essere facilmente fermati, rimossi o distribuiti su un altro nodo - il tutto richiede solo pochi secondi. In un grande sistema di orchestrazione dei contenitori, queste operazioni avvengono continuamente e gli utenti nemmeno notano tali cambiamenti. Tuttavia, i spostamenti sono possibili solo se il contenitore non ha dipendenze dal nodo su cui si trova. Si dice che tali contenitori funzionino senza stato.
Contenitori con stato
Se un contenitore memorizza dati su dispositivi collegati localmente (o su un dispositivo di blocco), lo storage dei dati deve essere spostato su un nuovo nodo insieme al contenitore stesso in caso di guasto. Questo è importante, altrimenti l'applicazione in esecuzione nel contenitore non potrà funzionare correttamente, poiché deve accedere ai dati salvati su supporti locali. Si dice che tali contenitori funzionino con stato.
Dal punto di vista tecnico, i contenitori con stato possono essere spostati anche su altri nodi. Di solito, questo è garantito tramite sistemi di archiviazione distribuiti o storage di rete a blocchi collegati a tutti i nodi su cui operano i contenitori. In questo modo, i contenitori ottengono accesso ai volumi per la persistenza dei dati, e le informazioni sono memorizzate su dischi distribuiti in tutta la rete. Questo metodo lo chiamerò "approccio ai contenitori con stato", e d'ora in poi lo designerò in questo modo per coerenza.
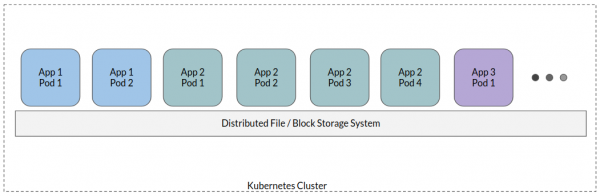
Nel tipico approccio ai contenitori con stato, tutti i pod delle applicazioni si collegano a un’unica file system distribuito – si crea una sorta di storage condiviso, dove sono conservati tutti i dati delle applicazioni. Pur essendo possibili alcune variazioni, questo è un approccio di alto livello.
Ora, vediamo perché l'approccio ai contenitori con stato nel mondo orientato al cloud è considerato un antipattern.
Progettazione di applicazioni orientate al cloud
Tradizionalmente, le applicazioni utilizzavano database per lo storage strutturato delle informazioni e dischi locali o sistemi di file distribuiti per archiviare tutti i dati non strutturati o persino semistrutturati. Con l'aumento dei volumi di dati non strutturati, gli sviluppatori hanno compreso che POSIX era eccessivamente "verbose", comportando costi significativi e, in ultima analisi, ostacolando le prestazioni delle applicazioni quando si passava a realmente grandi scalabilità.
Questo ha principalmente contribuito all'emergere di un nuovo standard per lo storage dei dati, ossia i sistemi di storage orientati al cloud, che operano prevalentemente su basi di REST API e liberano l'applicazione dalla pesante gestione dello storage locale. In questo caso, l'applicazione si trova effettivamente a operare in modalità senza stato (poiché lo stato è conservato in storage remoto). Le moderne applicazioni sono progettate fin dall'inizio tenendo conto di questo fattore. In generale, qualsiasi applicazione moderna che gestisce dati di vario tipo (log, metadati, blob, ecc.) è costruita secondo la paradigmatica orientata al cloud, dove lo stato viene trasferito in un sistema software appositamente designato per la sua conservazione.
L'approccio containerizzato con stato fa retrocedere tutta questa paradigmatica esattamente a dove era iniziata!
Quando si utilizzano le interfacce POSIX per archiviare i dati, le applicazioni funzionano come se stessero salvando lo stato e, per questo motivo, si allontanano dai principi fondamentali della progettazione cloud-oriented, cioè dalla possibilità di variare le dimensioni dei flussi di lavoro dell'applicazione in base al carico in entrata, di spostarsi su un nuovo nodo non appena il nodo attuale fallisce, e così via.
Esaminando più da vicino questa situazione, scopriamo che nella scelta della soluzione per l'archiviazione dei dati ci troviamo ripetutamente di fronte al dilemma "POSIX contro REST API", MA con un ulteriore aggravamento dei problemi legati a POSIX, dovuto alla natura distribuita degli ambienti Kubernetes. In particolare,
- POSIX è chiacchierone: la semantica POSIX richiede di associare a ogni operazione metadati e descrittori di file, che aiutano a mantenere lo stato dell'operazione. Questo porta a costi significativi, privi di reale valore. Le API per lo storage di oggetti, in particolare l'API S3, hanno eliminato questi requisiti, consentendo all'applicazione di eseguire l'operazione e poi "dimenticare" la chiamata. La risposta del sistema di archiviazione indica se l'azione è stata eseguita con successo o meno. In caso di fallimento, l'applicazione può riprovare.
- Limitazioni di rete: In un sistema distribuito, si intende che possono esistere molteplici applicazioni che cercano di scrivere dati su un unico supporto allegato. Pertanto, non solo le applicazioni competono tra loro per la larghezza di banda (per inviare dati al supporto), ma anche il sistema di archiviazione stesso competirà per questa larghezza di banda, distribuendo i dati attraverso i dischi fisici. A causa della verbosità di POSIX, il numero di chiamate di rete aumenta di diversi ordini di grandezza. D'altra parte, l'API S3 garantisce una chiara separazione delle chiamate di rete tra quelle che provengono dal client al server e quelle che avvengono all'interno del server.
- Sicurezza: Il modello di sicurezza POSIX è progettato per richiedere un'attiva partecipazione umana: gli amministratori configurano livelli specifici di accesso per ciascun utente o gruppo. Questa paradossi è difficile da adattare a un mondo orientato al cloud. Le applicazioni moderne si basano su modelli di sicurezza legati alle API, in cui i diritti di accesso sono definiti come un insieme di politiche, con account di servizio, credenziali temporanee, ecc.
- Gestibilità: I container con stato implicano costi specifici legati alla gestione. Si tratta della sincronizzazione dell'accesso parallelo ai dati e della garanzia della coerenza dei dati; tutto questo richiede di considerare attentamente quali schemi di accesso ai dati adottare. È necessario installare, monitorare e configurare programmi extra, senza contare gli sforzi aggiuntivi richiesti per lo sviluppo.
Interfaccia del contenitore per lo storage dei dati
Mentre l'interfaccia del contenitore per lo storage dei dati (CSI) ha notevolmente semplificato la diffusione del livello dei volumi di Kubernetes, trasferendoli parzialmente a fornitori di archiviazione esterni, ha anche accidentalmente contribuito a rafforzare la convinzione che l'approccio contenitorizzato con stato rappresenti il metodo raccomandato per l'archiviazione dei dati in Kubernetes.
CSI è stato sviluppato come standard per la fornitura di sistemi di archiviazione dei dati a blocchi e file per applicazioni legacy quando si lavora con Kubernetes. Come mostrato in questo articolo, l'unica situazione in cui l'approccio contenitorizzato con stato (e CSI nella sua forma attuale) è sensato è quando l'applicazione stessa è un sistema legacy, dove non è possibile aggiungere il supporto per l'API di archiviazione a oggetti.
È importante comprendere che, utilizzando CSI nella sua forma attuale, ovvero montando volumi lavorando con applicazioni moderne, ci troveremo ad affrontare più o meno gli stessi problemi che si sono verificati nei sistemi dove l'archiviazione dei dati era organizzata in stile POSIX.
Un approccio di qualità superiore
In questo caso, è importante capire che la maggior parte delle applicazioni non è intrinsecamente progettata per lavorare con stato o senza stato. Questo comportamento dipende dall'architettura generale del sistema e dalle specifiche scelte fatte durante il design. Parliamo un po' delle applicazioni a stato.
In linea di principio, tutti i dati delle applicazioni possono essere suddivisi in diversi ampi tipi:
- Dati di log
- Dati di timestamp
- Dati delle transazioni
- Metadati
- Immagini dei contenitori
- Dati blob (oggetti binari di grandi dimensioni)
Tutti questi tipi di dati sono ben supportati sulle moderne piattaforme di archiviazione dati, e ci sono diverse piattaforme orientate al cloud progettate per fornire dati in ciascuno di questi formati specifici. Ad esempio, i dati delle transazioni e i metadati possono risiedere in un moderno database cloud-oriented come CockroachDB, YugaByte, ecc. Le immagini dei contenitori o i dati blob possono essere memorizzati in un registro docker basato su MinIO. I dati dei timestamp possono essere conservati in un database di serie temporali, come InfluxDB, ecc. Non approfondiamo qui i dettagli di ciascun tipo di dato e delle relative applicazioni, ma l'idea generale è di evitare la memorizzazione persistente dei dati basata sul montaggio locale dei dischi.
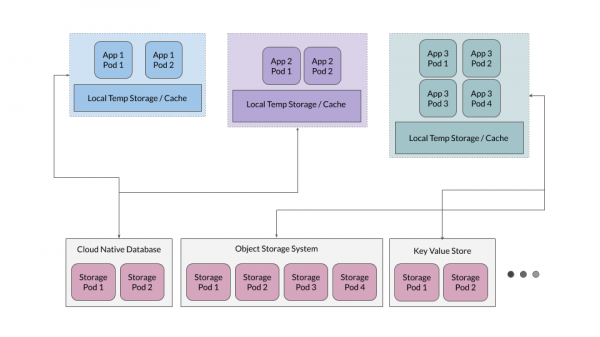
Inoltre, spesso si rivela efficace fornire un livello di caching temporaneo, che funge da una sorta di archivio per i file temporanei delle applicazioni, ma le applicazioni non devono dipendere da questo livello come fonte di verità.
Archiviazione per applicazioni con stato mantenuto
Sebbene nella maggior parte dei casi sia utile mantenere le applicazioni senza stato, quelle progettate per memorizzare dati – come database, archivi di oggetti, archivi di chiavi e valori – devono mantenere lo stato. Analizziamo perché queste applicazioni vengono implementate su Kubernetes. Come esempio, prendiamo MinIO, ma principi simili si applicano a qualsiasi altro grande sistema di archiviazione cloud-oriented.
Le applicazioni orientate al cloud sono progettate per massimizzare l'efficienza nell'utilizzo della flessibilità tipica dei container. Ciò significa che non ci sono assunzioni sulla tipologia di ambiente in cui verranno implementate. Ad esempio, MinIO utilizza un meccanismo interno di codifica ridondante (erasure coding) che conferisce al sistema la resilienza necessaria per rimanere operativo anche in caso di guasto della metà dei dischi. Inoltre, MinIO gestisce l'integrità e la sicurezza dei dati mediante un proprio sistema di hashing e crittografia lato server.
Per queste applicazioni orientate al cloud, i volumi persistenti locali (PV) sono la soluzione più pratica per l'archiviazione di backup. Un PV locale offre la possibilità di memorizzare dati grezzi, mentre le applicazioni che operano su questi PV raccolgono autonomamente informazioni che consentono di scalare i dati e gestire le crescenti esigenze relative ai dati.
Questo approccio è molto più semplice e scalabile rispetto a PV basato su CSI, che introducono nel sistema i propri livelli di gestione dei dati e ridondanza; il problema è che questi livelli di solito confliggono con le applicazioni progettate secondo il principio di mantenimento dello stato.
Un passo deciso verso il distacco dei dati dai calcoli
In questo articolo abbiamo parlato di come le applicazioni si stanno orientando verso il funzionamento senza mantenimento dello stato, o in altre parole, separando la memorizzazione dei dati dai calcoli su di essi. In conclusione, vediamo alcuni esempi reali di questa tendenza.
, la celebre piattaforma per l'analisi dei dati, è tradizionalmente stata utilizzata con mantenimento dello stato e distribuzione nel file system HDFS. Tuttavia, con il passaggio di Spark a un mondo orientato al cloud, questa piattaforma è sempre più utilizzata senza mantenimento dello stato utilizzando `s3a`. Spark utilizza s3a per trasferire lo stato ad altri sistemi, mentre i contenitori stessi di Spark operano completamente senza mantenimento dello stato. Altri grandi attori aziendali nel campo dell'analisi dei big data, in particolare, , , si occupano anche della separazione tra archiviazione dei dati e calcolo.
Pattern simili si possono osservare anche su altre grandi piattaforme analitiche, tra cui Presto, Tensorflow per R, Jupyter. Esportando lo stato in sistemi di archiviazione dati cloud remoti, diventa molto più facile gestire e scalare la tua applicazione. Inoltre, questo contribuisce alla portabilità dell'applicazione in diversi ambienti.
Fonte: habr.com
