

Tre anni fa, Viktor Tarnavskiy e Aleksey Milovidov di Yandex erano sul palco HighLoad++ , di quanto fosse buono ClickHouse e di come non rallentasse. E sul palco accanto c'era Alexander Zaitsev con sul trasferimento da ClickHouse un altro DBMS analitico, con la conclusione che ClickHouse, certamente è buono, ma non molto conveniente. Quando nel 2016 l'azienda LifeStreet, dove allora lavorava Alexander, trasferiva un sistema analitico multiterabyte su ClickHouse, era un affascinante 'viaggio verso il mattoncino giallo', pieno di pericoli sconosciuti — ClickHouse allora sembrava un campo minato.
Tre anni dopo ClickHouse è diventato molto migliore — nel frattempo, Alexander ha fondato l'azienda Altinity, che non solo aiuta a migrarci su ClickHouse decine di progetti, ma migliora anche il prodotto stesso insieme ai colleghi di Yandex. Ora ClickHouse non è ancora una passeggiata senza problemi, ma non è più un campo minato.
Alexander si occupa di sistemi distribuiti dal 2003, ha sviluppato grandi progetti su MySQL, Oracle e Vertica.All'evento HighLoad++ 2019 Alexander, uno dei pionieri nell'uso di ClickHouse, ha spiegato come si presenta ora questo DBMS. Scopriremo le sue caratteristiche principali. ClickHouse: in cosa si differenzia rispetto ad altri sistemi e in quali casi è più efficace utilizzarlo. Esamineremo pratiche recenti e verificate nella costruzione di sistemi su ClickHouse.

Retrospettiva: cosa è successo 3 anni fa
Tre anni fa abbiamo migrato l'azienda LifeStreet con ClickHouse da un'altra base di dati analitica, e la migrazione dell'analisi della rete pubblicitaria si presentava così:
- Giugno 2016. In OpenSource è stato lanciato ClickHouse e il nostro progetto è iniziato;
- Agosto. Proof Of Concept: una grande rete pubblicitaria, infrastruttura e 200-300 terabyte di dati;
- Ottobre. Prime dati in produzione;
- Dicembre. Carico completo del prodotto — 10-50 miliardi di eventi al giorno.
- Giugno 2017. Trasferimento riuscito degli utenti su ClickHouse, 2,5 petabyte di dati su un cluster di 60 server.
Durante il processo di migrazione cresceva la consapevolezza che ClickHouse è un buon sistema, con cui è piacevole lavorare, ma è un progetto interno dell'azienda Yandex. Pertanto ci sono delle peculiarità: Yandex si occuperà prima dei propri committenti interni e solo dopo della comunità e delle esigenze degli utenti esterni, e ClickHouse non raggiungeva allora il livello enterprise in molte aree funzionali. Per questo, nel marzo 2017, abbiamo fondato l'azienda Altinity per rendere ClickHouse ancora più veloce e comodo non solo per Yandex, ma anche per altri utenti. E adesso noi:
- Formiamo e aiutiamo a costruire soluzioni su ClickHouse in modo che i clienti non affrontino difficoltà, e che la soluzione funzioni alla fine;
- Offriamo supporto 24/7 ClickHouse-installazioni;
- Sviluppiamo i nostri progetti ecosistemici;
- Contribuiamo attivamente al ClickHouse, rispondendo alle richieste degli utenti che vogliono vedere determinate funzionalità.
E ovviamente, aiutiamo con la migrazione a ClickHouse con MySQL, Vertica., Oracle, Greenplum, Redshift e ad altri sistemi. Abbiamo partecipato a vari progetti di migrazione, e tutti sono stati un successo.
Perché migrare a ClickHouse
Non rallenta! Questa è la ragione principale. ClickHouse è un database molto veloce per diversi scenari:

Citazioni casuali di persone che lavorano da molto tempo con ClickHouse.
Scalabilità. Su un altro database si possono ottenere buone prestazioni su una singola macchina, ma ClickHouse si può scalare non solo verticalmente, ma anche orizzontalmente, semplicemente aggiungendo server. Non tutto funziona sempre perfettamente, ma funziona. La nostra infrastruttura può crescere insieme all'azienda. È importante notare che non siamo limitati da una soluzione attuale e c'è sempre potenziale per lo sviluppo.
Portabilità. Non ci sono vincoli a un singolo sistema. Per esempio, con Amazon Redshift è difficile migrare. Mentre ClickHouse può essere installato sul proprio laptop, su un server, distribuito nel cloud, senza restrizioni sull'uso dell'infrastruttura. Questo è vantaggioso per tutti e rappresenta un grande vantaggio che molte altre database simili non possono vantare. Kubernetes — non ci sono limiti sull'utilizzo delle infrastrutture. Questo è conveniente per tutti e rappresenta un grande vantaggio che molte altre banche dati simili non possono vantare.
Flessibilità. ClickHouse non si ferma a un singolo strumento, come Yandex.Metrica, ma evolve e viene utilizzato in un numero sempre maggiore di progetti e settori. Può essere ampliato aggiungendo nuove funzionalità per affrontare nuove sfide. Per esempio, si pensa che memorizzare i log in un database sia obsoleto, quindi è stata inventata Elasticsearch. Ma grazie alla flessibilità ClickHouse, in esso è possibile memorizzare anche i log, e spesso è addirittura migliore che in Elasticsearch — in ClickHouse per questo servono dieci volte meno risorse.
Gratuito Open Source. Non c'è bisogno di pagare nulla. Non è necessario ottenere il permesso di installare il sistema sul proprio laptop o server. Non ci sono costi nascosti. Inoltre, nessun'altra tecnologia di database Open Source può compete con ClickHouse. MySQL, MariaDB, Greenplum — tutti sono notevolmente più lenti.
Una community, motivazione e divertimento. Ha ClickHouse una community eccellente: meet-up, chat e Alexey Milovidov, che ci carica tutti con la sua energia e ottimismo.
Passare a ClickHouse
Per passare a ClickHouse qualcosa di diverso, servono solo tre cose:
- Comprendere i limiti ClickHouse e per cosa non è adatto.
- Sfruttare i punti di forza della tecnologia e le sue caratteristiche più forti.
- Sperimentare. Anche capendo come funziona ClickHouse, non è sempre possibile prevedere quando sarà più veloce, quando più lento, quando è migliore e quando è peggiore. Quindi provate.
Il problema del trasferimento
C'è solo un 'ma': se si passa a ClickHouse da qualcos'altro, solitamente qualcosa va storto. Siamo abituati a pratiche e strumenti che funzionano nel nostro database preferito. Ad esempio, chiunque lavori con SQLe basi di dati richiedono un insieme minimo di funzionalità:
- transazioni;
- vincoli;
- consistenza;
- indici;
- UPDATE/DELETE;
- NULL;;
- millisecondi;
- conversioni automatiche;
- join multipli;
- partizioni arbitrarie;
- strumenti di gestione dei cluster.
Il set è obbligatorio, ma tre anni fa ClickHouse non c'era nessuna di queste funzionalità! Oggi ciò che non è implementato è meno della metà: transazioni, vincoli, Consistenza, millisecondi e conversioni.
E la cosa principale è che in ClickHouse alcune pratiche e approcci standard non funzionano o non funzionano come siamo abituati. Tutto ciò che appare in ClickHouse, corrisponde al «ClickHouse way», cioè le funzionalità differiscono da altre basi di dati. Ad esempio:
- Gli indici non scelgono, ma passano.
- UPDATE/DELETE non sono sincroni, ma asincroni.
- Ci sono join multipli, ma non c'è un pianificatore di query. Come vengono quindi eseguiti, non è chiaro alle persone del mondo delle basi di dati.
Scenari di ClickHouse
Nel 1960, il matematico americano di origine ungherese Wigner E. P. scrisse un articolo «L'irragionevole efficacia della matematica nelle scienze naturali» («L'inspiegabile efficacia della matematica nelle scienze naturali») riguarda il fatto che il mondo che ci circonda è descrivibile con leggi matematiche. La matematica è una scienza astratta, e le leggi fisiche espresse in forma matematica non sono banali, e Wigner E. P. ha sottolineato che questo è molto strano.
Dal mio punto di vista, ClickHouse è una stranezza simile. Riformulando Wigner, si potrebbe dire che l'inspiegabile efficacia ClickHouse nelle più diverse applicazioni analitiche è sorprendente!
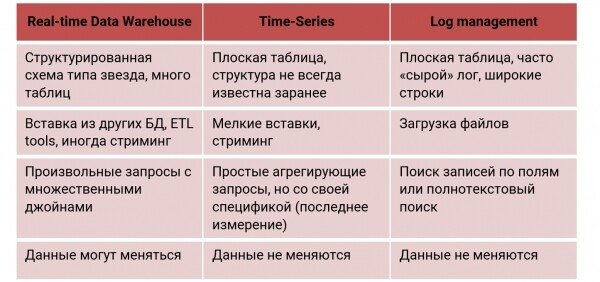
Ad esempio, prendiamo Real-Time Data Warehouse, nel quale i dati vengono caricati praticamente ininterrottamente. Vogliamo ricevere richieste con un ritardo di un secondo. Perfetto — utilizziamo ClickHouse, perché è stato progettato proprio per questo scenario. ClickHouse Viene utilizzato non solo nel web, ma anche nell'analisi di marketing e finanziaria, AdTech, e anche in Fraud detection.Nel Real-time Data Warehouse viene utilizzato uno schema strutturato complesso di tipo «stella» o «fiocco di neve», con molte tabelle di JOIN (a volte multiple), e i dati di solito vengono memorizzati e modificati in determinate sistemi.
Consideriamo un altro scenario — Time Series: monitoraggio di dispositivi, reti, statistiche di utilizzo, Internet delle cose. Qui ci imbattiamo in eventi abbastanza semplici organizzati cronologicamente. ClickHouse non è stato progettato inizialmente per questo, ma ha dimostrato di funzionare bene, quindi le grandi aziende lo utilizzano. ClickHouse come repository per le informazioni di monitoraggio. Per vedere se ClickHouse è adatto ai time-series, abbiamo creato un benchmark basato sull'approccio e sui risultati. InfluxDB e TimescaleDB — database specializzati time-series. Si è scoperto , che ClickHouse, anche senza ottimizzazione per tali compiti, ottiene vantaggi anche in contesti diversi:
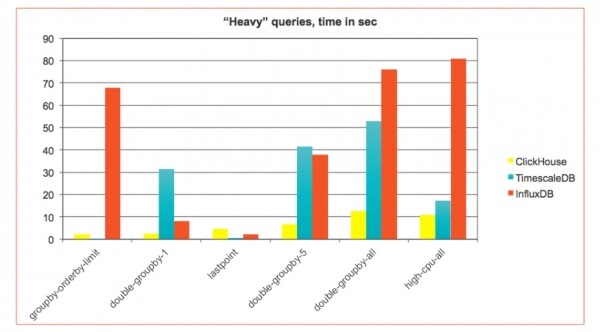
In time-series. di solito si utilizza una tabella ristretta — poche colonne piccole. Dalla monitorizzazione possono arrivare moltissimi dati, — milioni di record al secondo, — e solitamente vengono inviati in piccole integrazioni (real-time streaming). Pertanto, è necessario un diverso scenario di inserzione, e le stesse query presentano alcune specifiche.
Gestione dei Log. La raccolta di log nei database è di solito sconsigliata, ma in ClickHouse è possibile farlo con alcune avvertenze, come descritto sopra. Molte aziende utilizzano ClickHouse proprio per questo. In questo caso si utilizza una tabella piatta e ampia, in cui conserviamo i log integralmente (ad esempio, sotto forma di JSON), o li tagliamo a pezzi. I dati vengono solitamente caricati in grandi batch (file), e li cerchiamo in base a qualche campo.
Per ciascuna di queste funzioni si usano solitamente database specializzati. ClickHouse uno può fare tutto questo così bene da superare le loro prestazioni. Ora esaminiamo in dettaglio time-series. il scenario, e come 'preparare' correttamente ClickHouse per questo scenario.
Time-Series
Attualmente, questo è il principale scenario per cui ClickHouse è considerato una soluzione standard. Time-series è un insieme di eventi ordinati nel tempo che rappresentano le variazioni di un certo processo nel tempo. Ad esempio, può essere la frequenza cardiaca durante il giorno o il numero di processi in un sistema. Tutto ciò che fornisce tick temporali con qualche misura è time-series.:

La maggior parte di questo tipo di eventi proviene dal monitoraggio. Ciò può includere non solo monitoraggio web, ma anche dispositivi reali: automobili, sistemi industriali, IoT, produzioni o taxi senza conducente, nel cui bagagliaio Yandex sta già mettendo ClickHouse-server.
Ad esempio, ci sono aziende che raccolgono dati dalle navi. Ogni pochi secondi, i sensori delle navi portacontainer inviano centinaia di misurazioni diverse. Gli ingegneri le analizzano, costruiscono modelli e cercano di capire quanto efficacemente viene utilizzata la nave, perché una portacontainer non deve rimanere ferma nemmeno per un secondo. Qualsiasi fermo è una perdita di denaro, quindi è importante prevedere il percorso in modo da minimizzare le soste.
Attualmente si osserva una crescita delle banche dati specializzate che misurano time-series.. Sul sito DB-Engines vengono in qualche modo classificate diverse banche dati, che possono essere visualizzate per tipo:
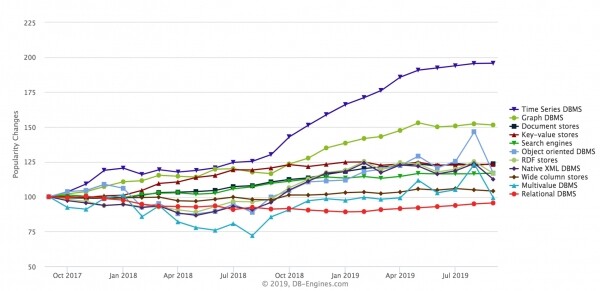
Il tipo in più rapida crescita è time-series. Anche i database a grafo stanno crescendo, ma time-series sono cresciuti più velocemente negli ultimi anni. I rappresentanti tipici di questo tipo di database sono InfluxDB, Prometheus, KDB, TimescaleDB (costruito su PostgreSQL), soluzioni di Amazon. ClickHouse possono essere utilizzate anche qui e lo sono. Faccio alcuni esempi pubblici.
Uno dei pionieri è l'azienda CloudFlare (fornitore di CDN). Monitorano il loro-fornitore). Monitorano il loro fornitore di CDN). Monitorano il loro tramite ClickHouse (DNS-richieste, HTTP-richieste) con un carico enorme — 6 milioni di eventi al secondo. Tutto passa attraverso Kafka, inviato a ClickHouse, che consente di vedere in tempo reale i dashboard degli eventi nel sistema.
Comcast — uno dei leader delle telecomunicazioni negli Stati Uniti: internet, televisione digitale, telefonia. Hanno creato un sistema di gestione simile fornitore di CDN). Monitorano il loro nell'ambito di Open Source progetto Apache Traffic Control per lavorare con i loro enormi dati. ClickHouse viene utilizzato come backend per l'analisi.
Percona hanno integrato ClickHouse all'interno del loro PMM, per monitorare diversi MySQL.
Requisiti specifici
Le basi di dati time-series hanno i loro requisiti specifici.
- Inserimento rapido da più agenti. Dobbiamo inserire molto rapidamente i dati da più flussi. ClickHouse lo fa bene, perché tutte le sue inserzioni sono non bloccanti. Qualsiasi insert è un nuovo file sul disco, e le piccole inserzioni possono essere messe in buffer in vari modi. È ClickHouse meglio inserire i dati in grandi pacchetti piuttosto che una riga alla volta.
- Schema flessibile. In time-series. di solito non conosciamo completamente la struttura dei dati. Si può costruire un sistema di monitoraggio per un'applicazione specifica, ma allora è difficile utilizzarlo per un'altra applicazione. Per questo serve uno schema più flessibile. ClickHouse, consente di farlo, anche se si tratta di un database strettamente tipizzato.
- Archiviazione efficace e 'dimenticanza' dei dati. Di solito in time-series. un volume enorme di dati, pertanto devono essere archiviati nel modo più efficiente possibile. Ad esempio, InfluxDB una buona compressione è la sua caratteristica principale. Ma oltre all'archiviazione, è necessario anche saper 'dimenticare' i dati più vecchi e fare qualche downsampling — calcolo automatico degli aggregati.
- Richieste veloci di dati aggregati. A volte è interessante vedere gli ultimi 5 minuti con una precisione millisecondo, ma per i dati mensili la granularità al minuto o al secondo potrebbe non essere necessaria — è sufficiente una statistica generale. Questo tipo di supporto è necessario, altrimenti la richiesta per 3 mesi richiederà molto tempo anche in ClickHouse.
- Richieste del tipo 'ultimo punto, al». Queste sono richieste tipiche per time-series. : guardiamo l'ultima misurazione o lo stato del sistema in un momento specifico t. Per i database, queste non sono richieste molto piacevoli, ma devono essere eseguite.
- ‘Unione’ delle serie temporali. Time-series — è una serie temporale. Se ci sono due serie temporali, spesso devono essere unite e correlate. Non tutte le basi di dati consentono di farlo comodamente, soprattutto con serie temporali non allineate: qui ci sono un tipo di marcatori temporali, lì un altro. Si possono calcolare le medie, ma se ci sono comunque dei vuoti, non è chiaro.
Diamo un'occhiata a come questi requisiti vengono soddisfatti in ClickHouse.
Schema
In ClickHouse uno schema per time-series. può essere realizzato in diversi modi, a seconda della regolarità dei dati. Si può costruire un sistema con dati regolari, quando conosciamo tutte le metriche in anticipo. Ad esempio, così ha fatto CloudFlare per il monitoraggio fornitore di CDN). Monitorano il loro — è un sistema ben ottimizzato. Si può costruire un sistema più generale che monitora tutta l'infrastruttura, diversi servizi. Nel caso di dati irregolari, non sappiamo anticipatamente cosa monitoriamo — e probabilmente questo è il caso più generale.
Dati regolari. Colonne. Lo schema è semplice: colonne con i tipi necessari:
CREA TABELLA cpu (
created_date Date DEFAULT today(),
created_at DateTime DEFAULT now(),
time String,
tags_id UInt32, /* unisciti a dim_tag */
usage_user Float64,
usage_system Float64,
usage_idle Float64,
usage_nice Float64,
usage_iowait Float64,
usage_irq Float64,
usage_softirq Float64,
usage_steal Float64,
usage_guest Float64,
usage_guest_nice Float64
) ENGINE = MergeTree(created_date, (tags_id, created_at), 8192);Questa è una tabella comune che monitora un'attività relativa al carico del sistema (utente, sistema, idle, nicely). Semplice e comodo, ma non flessibile. Se vogliamo uno schema più flessibile, possiamo usare gli array.
Dati irregolari. Array:
CREA TABELLA cpu_alc (
created_date Date,
created_at DateTime,
time String,
tags_id UInt32,
metrics Nested(
name LowCardinality(String),
value Float64
)
) ENGINE = MergeTree(created_date, (tags_id, created_at), 8192);
SELECT max(metrics.value[indexOf(metrics.name,'usage_user')]) FROM ...
Struttura Nascosto — sono due array: metrics.name e metrics.value. Qui possiamo memorizzare dati di monitoraggio arbitrari, come un array di nomi e un array di misurazioni per ogni evento. Per ulteriori ottimizzazioni, invece di una singola struttura di questo tipo, possiamo crearne diverse. Ad esempio, una per valore-float, un'altra per -int-valore, perché -int vogliamo memorizzare in modo più efficiente.
Ma questa struttura è più complessa da gestire. Sarà necessario utilizzare una costruzione speciale per estrarre i valori prima dall'indice e poi dall'array tramite funzioni specifiche:
SELECT max(metrics.value[indexOf(metrics.name,'usage_user')]) FROM ...Tuttavia, funziona comunque abbastanza rapidamente. Un altro modo per memorizzare dati irregolari è per righe.
Dati irregolari. Righe. In questo metodo tradizionale, senza array, vengono memorizzati sia i nomi che i valori. Se un dispositivo invia subito 5.000 misurazioni, vengono generate 5.000 righe nel DB:
CREATE TABLE cpu_rlc (
created_date Date,
created_at DateTime,
time String,
tags_id UInt32,
metric_name LowCardinality(String),
metric_value Float64
) ENGINE = MergeTree(created_date, (metric_name, tags_id, created_at), 8192);
SELECT
maxIf(metric_value, metric_name = 'usage_user'),
...
FROM cpu_r
WHERE metric_name IN ('usage_user', ...)
ClickHouse questo lo gestisce — ha estensioni speciali ClickHouse SQL. Ad esempio, maxIf — è una funzione speciale che calcola il massimo di una metrica durante l'esecuzione di una certa condizione. È possibile scrivere più di queste espressioni in una sola query e calcolare immediatamente i valori per più metriche.
Confrontiamo tre approcci:
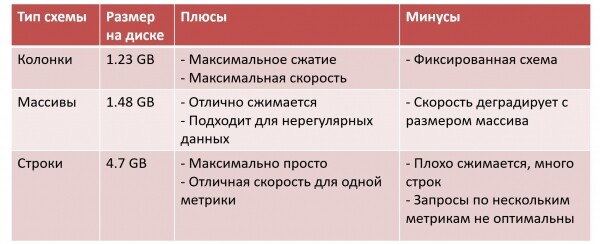
Qui ho aggiunto "Dimensione dei dati su disco" per un certo set di dati di test. Nel caso delle colonne, abbiamo la dimensione dei dati più piccola: massima compressione, massima velocità delle richieste, ma paghiamo con la necessità di dover tutto fissare immediatamente.
Nel caso degli array la situazione è un po' peggiore. I dati si comprimono comunque bene e può essere memorizzato uno schema irregolare. Ma ClickHouse — un database a colonne, e quando iniziamo a memorizzare tutto in un array, esso diventa un database a righe, e paghiamo per la flessibilità con la performance. Per ogni operazione, dobbiamo leggere l'intero array in memoria, dopo di che trovare l'elemento desiderato — e se l'array cresce, la velocità degrada.
In una delle aziende che utilizza tale approccio (ad esempio, ), gli array vengono suddivisi in pezzi da 128 elementi. Dati di diverse migliaia di metriche per un totale di 200 TB di dati/giorno non sono memorizzati in un unico array, ma in 10 o 30 array con una logica speciale per la memorizzazione.
Un approccio estremamente semplice — con le stringhe. Tuttavia, i dati si comprimono male, dimensioni della tabella diventano grandi, e quando le richieste vengono effettuate su più metriche, ClickHouse non funziona in modo ottimale.
Schema ibrido
Supponiamo di aver scelto uno schema con un array. Ma se sappiamo che la maggior parte dei nostri dashboard mostra solo le metriche user e system, possiamo materializzare ulteriormente queste metriche in colonne a livello di tabella in questo modo:
CREATE TABLE cpu_alc (
created_date Date,
created_at DateTime,
time String,
tags_id UInt32,
metrics Nested(
name LowCardinality(String),
value Float64
),
usage_user Float64
MATERIALIZED metrics.value[indexOf(metrics.name,'usage_user')],
usage_system Float64
MATERIALIZED metrics.value[indexOf(metrics.name,'usage_system')]
) ENGINE = MergeTree(created_date, (tags_id, created_at), 8192);
Durante l'inserimento ClickHouse li calcolerà automaticamente. Così possiamo unire l’utile al dilettevole: lo schema è flessibile e generale, ma le colonne più usate sono state estratte. Noterò che questo non ha richiesto di cambiare l'inserimento e ETL, che continua a inserire array nella tabella. Abbiamo semplicemente fatto ALTER TABLE, aggiunto un paio di colonne e abbiamo ottenuto uno schema ibrido e più veloce, che può essere utilizzato immediatamente.
Codec e compressione
Per time-series. è importante quanto bene imballate i dati, poiché un insieme di informazioni può essere molto grande. In ClickHouse è disponibile un insieme di strumenti per ottenere un effetto di compressione 1:10, 1:20, e talvolta anche di più. Ciò significa che i dati non compressi di 1 TB occupano su disco 50-100 GB. Dimensioni più piccole sono un vantaggio, i dati possono essere letti e elaborati più rapidamente.
Per raggiungere un alto livello di compressione, ClickHouse supporta i seguenti codec:
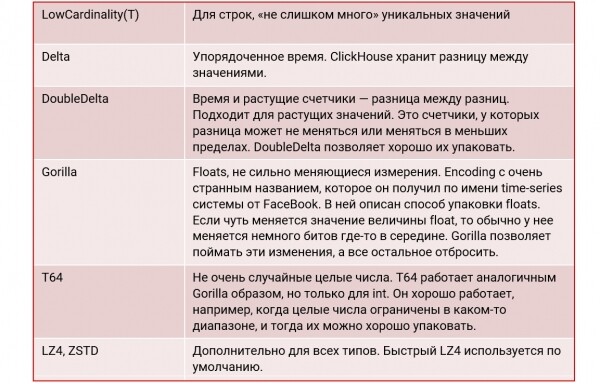
Esempio di tabella:
CREATE TABLE benchmark.cpu_codecs_lz4 (
created_date Date DEFAULT today(),
created_at DateTime DEFAULT now() Codec(DoubleDelta, LZ4),
tags_id UInt32,
usage_user Float64 Codec(Gorilla, LZ4),
usage_system Float64 Codec(Gorilla, LZ4),
usage_idle Float64 Codec(Gorilla, LZ4),
usage_nice Float64 Codec(Gorilla, LZ4),
usage_iowait Float64 Codec(Gorilla, LZ4),
usage_irq Float64 Codec(Gorilla, LZ4),
usage_softirq Float64 Codec(Gorilla, LZ4),
usage_steal Float64 Codec(Gorilla, LZ4),
usage_guest Float64 Codec(Gorilla, LZ4),
usage_guest_nice Float64 Codec(Gorilla, LZ4),
additional_tags String DEFAULT ''
)
ENGINE = MergeTree(created_date, (tags_id, created_at), 8192);Qui definiamo il codec DoubleDelta in un caso, nell'altro — Gorilla, e dobbiamo aggiungere anche LZ4 compressione. Di conseguenza, le dimensioni dei dati su disco si riducono drasticamente:
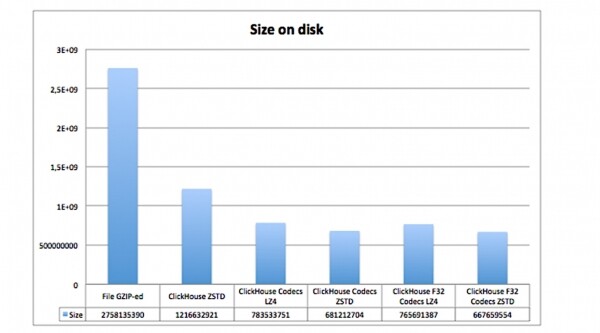
Qui mostra quanto spazio occupano gli stessi dati, ma utilizzando diversi codec e compressioni:
- in un file GZIP compresso sul disco;
- in ClickHouse senza codec, ma con compressione ZSTD;
- in ClickHouse con codec e compressione LZ4 e ZSTD.
È evidente che le tabelle con codec occupano molto meno spazio.
La dimensione conta
È anche molto importante il tipo di dati corretto:
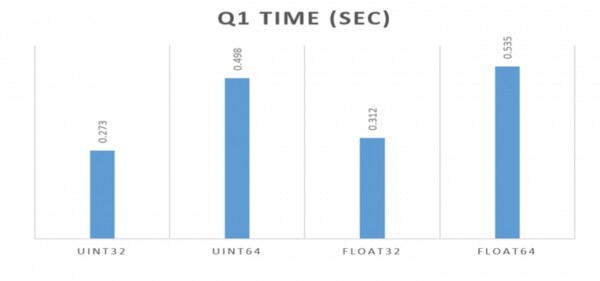
In tutti gli esempi sopra ho utilizzato Float64. Ma se avessimo scelto Float32, sarebbe stato addirittura migliore. Questo è ben dimostrato dai ragazzi di Percona nell'articolo linkato sopra. È importante utilizzare il tipo più compatto adatto all'attività: non tanto per la dimensione su disco, quanto per la velocità delle query. ClickHouse è molto sensibile a questo.
Se puoi usare int32 invece di int64, allora aspettati quasi un raddoppio delle prestazioni. I dati occupano meno memoria e tutta l'«aritmetica» funziona molto più velocemente. ClickHouse internamente - un sistema molto fortemente tipizzato, sfrutta al massimo tutte le opportunità offerte dai sistemi moderni.
Aggregazione e Materialized Views
L'aggregazione e le viste materializzate consentono di creare aggregati per diverse esigenze:
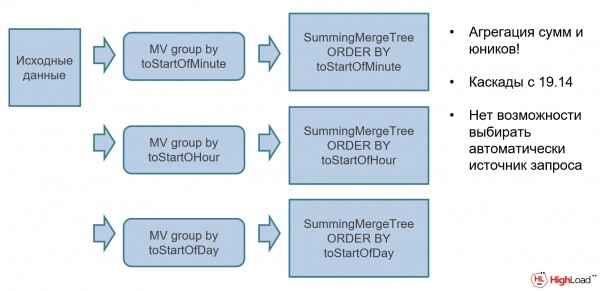
Ad esempio, potresti avere dati di origine non aggregati e su di essi puoi sovrapporre diverse viste materializzate con somma automatica tramite un motore speciale. SummingMergeTree (SMT). SMT è una struttura di dati aggregante speciale che calcola automaticamente gli aggregati. I dati grezzi vengono inseriti nel database, vengono automaticamente aggregati e puoi utilizzarli subito nei dashboard.
TTL significa "dimenticare" i dati obsoleti.
Come "dimenticare" i dati che non sono più necessari? ClickHouse È possibile farlo. Quando si creano tabelle, è possibile specificare TTL espressioni: ad esempio, che i dati al minuto vengono conservati per un giorno, i dati giornalieri per 30 giorni, mentre quelli settimanali o mensili non vengono toccati:
CREATE TABLE aggr_by_minute
…
TTL time + interval 1 day
CREATE TABLE aggr_by_day
…
TTL time + interval 30 day
CREATE TABLE aggr_by_week
…
/* no TTL */
Multi-tier significa separare i dati su dischi diversi.
Sviluppando quest'idea, i dati possono essere archiviati in ClickHouse luoghi diversi. Supponiamo di voler conservare i dati recenti degli ultimi sette giorni su un'unità locale molto veloce, SSDmentre i dati più storici vengono riposti altrove. In ClickHouse adesso è possibile:

È possibile configurare una politica di archiviazione (storage policy) in modo che ClickHouse sposti automaticamente i dati al raggiungimento di alcune condizioni in un altro storage.
Ma non è tutto. A livello di singola tabella è possibile definire regole su quando esattamente, nel tempo, i dati passano in archivio freddo. Ad esempio, i dati vengono mantenuti su un disco molto veloce per 7 giorni e tutto ciò che è più vecchio viene trasferito su uno più lento. Questo è utile perché consente al sistema di mantenere le massime prestazioni, controllando al contempo i costi e senza spendere risorse su dati freddi:
CREATE TABLE
...
TTL date + INTERVAL 7 DAY TO VOLUME 'cold_volume',
date + INTERVAL 180 DAY DELETE
Opportunità uniche ClickHouse
Quasi tutto in ClickHouse ha queste 'chicche', ma sono compensate dall'esclusività — qualcosa che non si trova in altri DB. Ad esempio, ecco alcune delle funzioni uniche ClickHouse:
- Array. In ClickHouse ottima supporto per gli array, così come la possibilità di eseguire su di essi calcoli complessi.
- Strutture di dati aggreganti. Questa è una delle 'killer feature' ClickHouse. Anche se i ragazzi di Yandex dicono che non vogliamo aggregare dati, tutti lo fanno in ClickHouse, perché è veloce e conveniente.
- View materializzati. Insieme alle strutture di aggregazione dei dati, le view materializzate consentono di effettuare una comoda real-time aggregazione.
- ClickHouse SQL. Questa è un'estensione del linguaggio SQL con alcune funzionalità aggiuntive ed esclusive, che si trovano solo in ClickHouse. In passato, questo era considerato da un lato un'estensione, e dall'altro un difetto. Ora abbiamo eliminato quasi tutti i difetti rispetto a SQL 92 , ora è solo un'estensione.
- Lambda-espressioni. Esistono in qualche altro database?
- Supporto ML. Questo è presente in vari DB, in alcuni meglio, in altri peggio.. Questo è presente in diverse banche dati, in alcune meglio, in altre peggio.
- Codice aperto. Possiamo espandere ClickHouse insieme. Attualmente ci sono ClickHouse circa 500 contributori, e questo numero continua a crescere.
Query ingegnose
In ClickHouse ci sono molti modi diversi per fare la stessa cosa. Ad esempio, puoi restituire l'ultimo valore dalla tabella in tre modi diversi per CPU (ce n'è anche un quarto, ma è ancora più esotico).
Il primo mostra quanto sia facile farlo in ClickHouse query, quando vuoi verificare che tuple è presente nella sottoquery. È ciò di cui ho personalmente sentito molto la mancanza in altri database. Se voglio confrontare qualcosa con una sottoquery, in altri database posso confrontare solo uno scalare, mentre per più colonne devo scrivere JOIN. In ClickHouse può essere utilizzato tuple:
SELECT *
FROM cpu
WHERE (tags_id, created_at) IN
(SELECT tags_id, max(created_at)
FROM cpu
GROUP BY tags_id)Il secondo metodo fa la stessa cosa, ma utilizza una funzione aggregata argMax:
SELECT
argMax(usage_user), created_at),
argMax(usage_system), created_at),
...
FROM cpu In ClickHouse ci sono alcune decine di funzioni aggregate, e se usiamo i combinatori, secondo le leggi della combinatoria, ne risulteranno circa mille. ArgMax è una delle funzioni che calcola il valore massimo: la query restituisce il valore usage_user, su cui si raggiunge il valore massimo created_at:
SELECT now() as created_at,
cpu.*
FROM (SELECT DISTINCT tags_id from cpu) base
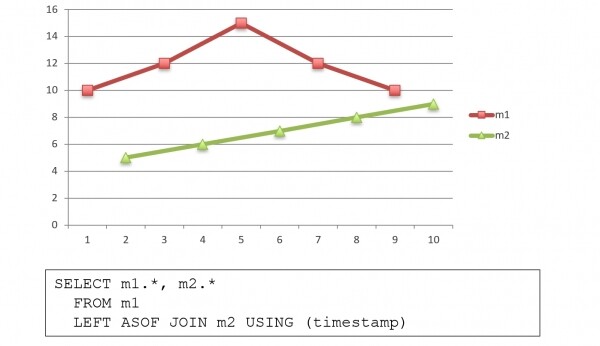
ASOF LEFT JOIN cpu USING (tags_id, created_at)
ASOF JOIN è la "fusione" di righe con tempi diversi. È una funzione unica per i database, che esiste solo in kdb+. Se ci sono due serie temporali con tempi diversi, ASOF JOIN permette di spostarle e unirle in un'unica query. Per ogni valore in una serie temporale, viene restituito il valore più vicino in un'altra, sulla stessa riga:
Funzioni analitiche
Nel standard SQL-2003 si può scrivere così:
SELECT origin,
timestamp,
timestamp -LAG(timestamp, 1) OVER (PARTITION BY origin ORDER BY timestamp) AS duration,
timestamp -MIN(timestamp) OVER (PARTITION BY origin ORDER BY timestamp) AS startseq_duration,
ROW_NUMBER() OVER (PARTITION BY origin ORDER BY timestamp) AS sequence,
COUNT() OVER (PARTITION BY origin ORDER BY timestamp) AS nb
FROM mytable
ORDER BY origin, timestamp;
In ClickHouse non si può fare — non supporta lo standard SQL-2003 e probabilmente non lo farà mai. Al suo posto, ClickHouse è consuetudine scrivere così:

Ho promesso le lambda – ecco qui!
Questo è l'equivalente di una query analitica nello standard SQL-2003: calcola la differenza tra due timestamp, duration, numero di sequenza — tutto ciò che comunemente consideriamo funzioni analitiche. In ClickHouse noi le calcoliamo tramite array: prima aggreggiamo i dati in un array, dopo di che possiamo fare tutto ciò che vogliamo su di esso, e poi lo espandiamo di nuovo. Non è molto comodo, richiede una certa affinità per la programmazione funzionale, almeno, ma è molto flessibile.
Funzioni speciali
Inoltre, in ClickHouse molte funzioni specializzate. Ad esempio, come determinare quante sessioni vengono eseguite simultaneamente? Un compito comune per il monitoraggio è determinare il carico massimo per una singola richiesta. Nel ClickHouse c'è una funzione speciale per questo scopo:

In generale, per molti scopi in ClickHouse ci sono funzioni speciali:
- runningDifference, runningAccumulate, neighbor;
- sumMap(key, value);
- timeSeriesGroupSum(uid, timestamp, value);
- timeSeriesGroupRateSum(uid, timestamp, value);
- skewPop, skewSamp, kurtPop, kurtSamp;
- WITH FILL / WITH TIES;
- simpleLinearRegression, stochasticLinearRegression.
Questa non è una lista completa di funzioni, ce ne sono circa 500-600. Suggerimento: tutte le funzioni in ClickHouse sono nella tabella di sistema (non tutte documentate, ma tutte interessanti):
select * from system.functions order by nameClickHouse stessa contiene molte informazioni su di sé, inclusi log tables, query_log, log di tracciamento, log delle operazioni sui blocchi di dati (part_log), log delle metriche e il log di sistema, che di solito scrive su disco. Il log delle metriche è time-series. in ClickHouse sulla stessa ClickHouse: Il DB stesso può agire come time-series. un database, in questo modo "consumando" sé stesso.

È anche una cosa unica — dal momento che facciamo bene il lavoro per time-series., perché non possiamo conservare tutto ciò che serve dentro di noi? Non abbiamo bisogno di Prometheus, conserviamo tutto dentro di noi. Abbiamo collegato Grafana e monitoriamo noi stessi. Tuttavia, se ClickHouse se cade, non lo vedremo, — perché, — quindi di solito non si fa così.
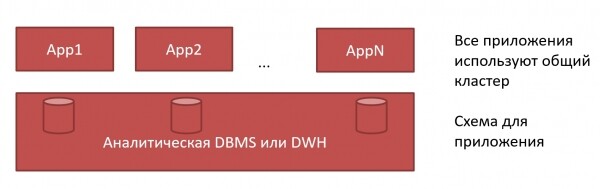
Un grande cluster o molti piccoli ClickHouse
Cosa è meglio — un grande cluster o molti piccoli ClickHouse? L'approccio tradizionale a DWH è un grande cluster, in cui vengono dedicate schemi per ogni applicazione. Siamo andati dall’amministratore del database — datemi uno schema, e ci è stato fornito:
In ClickHouse si può fare diversamente. Si può creare un proprio ClickHouse:
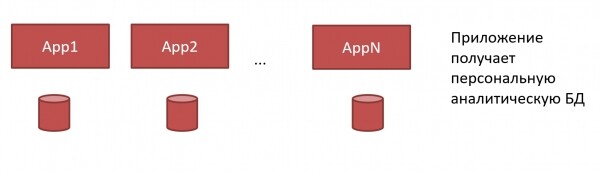
Non abbiamo più bisogno di grandi mostri DWH e amministratori poco cooperativi. Possiamo dare a ciascuna applicazione il proprio ClickHouse, e lo sviluppatore può farlo da solo, poiché ClickHouse è molto semplice da installare e non richiede una gestione complessa:
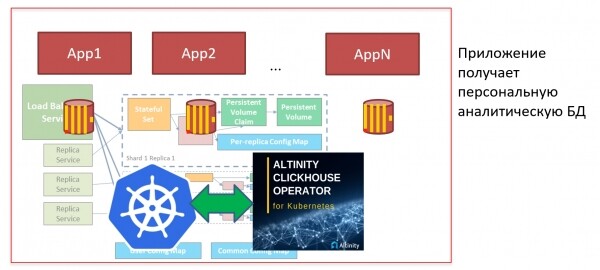
Ma se abbiamo molte ClickHouse, e dobbiamo installarlo spesso, vogliamo automatizzare questo processo. Per questo possiamo, ad esempio, utilizzare Kubernetes e clickhouse-operator. In Kubernetes ClickHouse può essere installato con un 'clic': posso premere un pulsante, avviare il manifesto e il database è pronto. Si può subito creare uno schema, iniziare a caricare metriche, e dopo 5 minuti ho già un dashboard Grafana. È tutto così semplice!
Quali sono i risultati finali?
Quindi, ClickHouse è:
- Veloce. Questo è noto a tutti.
- Semplice. È un po' controverso, ma penso che chi si esercita molto, si trova meglio in battaglia. Se si capisce come ClickHouse funziona, poi tutto diventa molto semplice.
- Universale. Si adatta a diversi scenari: DWH, Time Series, Log Storage. Ma non è un database OLTP , quindi non cercate di effettuare inserimenti e letture brevi.
- È interessante. Probabilmente, chi lavora con ClickHouse, ha vissuto molti momenti interessanti, in senso buono e cattivo. Ad esempio, è uscito un nuovo rilascio e tutto ha smesso di funzionare. O quando hai combattuto su un compito per due giorni, ma dopo aver chiesto nel gruppo Telegram, il problema si è risolto in due minuti. O come durante la conferenza, nella presentazione di Aleksey Milovidov, uno screenshot di ClickHouse ha interrotto la trasmissione HighLoad++. Situazioni di questo tipo accadono costantemente e rendono la nostra vita con ClickHouse vivace e interessante!
La presentazione può essere vista .

L'attesissimo incontro degli sviluppatori di sistemi altamente performanti si svolgerà il 9 e 10 novembre a Skolkovo. Finalmente sarà una conferenza in presenza (anche se rispettando tutte le misure di sicurezza), poiché l'energia di HighLoad++ non può essere confezionata online.
Per la conferenza, troviamo e mostriamo casi sulle massime potenzialità delle tecnologie: HighLoad++ è stato, è e sarà l'unico luogo dove in due giorni puoi scoprire come funzionano Facebook, Yandex, VKontakte, Google e Amazon.
Iniziando i nostri incontri senza interruzione dal 2007, quest'anno ci incontreremo per la 14ª volta. In questo periodo, la conferenza è cresciuta di dieci volte; lo scorso anno l'evento chiave del settore ha riunito 3339 partecipanti, 165 relatori e 16 track in contemporanea.
Lo scorso anno abbiamo avuto 20 bus, 5280 litri di tè e caffè, 1650 litri di succhi e 10200 bottigliette d'acqua. Inoltre, 2640 chili di cibo, 16000 piatti e 25000 bicchieri. A proposito, con i soldi guadagnati dalla carta riciclata abbiamo piantato 100 alberi di quercia 🙂I biglietti possono essere acquistati , ricevere notizie sulla conferenza — , e conversare — su tutti i social media: , , e .
Fonte: habr.com
